[Python学习日记-73] 面向对象实战1——答题系统
简介
在学习完面向对象之后你会发现,你还是不会自己做软件做系统,这是非常正常的,这是因为计算机软件和系统的制作是一个系统性工程,在大学里面被称为软件工程,如果你是这个专业出身的应该会想到瀑布模型、螺旋模型、迭代开发、敏捷模型、UML等一系列软件工程相关的软件开发流程,不过在一个工程里面往往是一个团队来进行工作的,上述的这些流程可能只有架构师或者是管理人员才会真正的用起来,对于普通程序员来说更多的可能只是看或者是听安排,本篇将会带大家从程序员的视角来走一遍面向对象开发程序的开发流程。
需求模型——5w1h8c
在开始动手变成前无论大小项目,有一项步骤是必然会做的,那就是建立需求模型,什么是需求模型呢?需求模型是指对系统或产品的需求的描述和规范,用于明确系统或产品应具备的功能、性能、约束等要求。简单来说就是问问客户想要什么。这里要注意一点,很多人在进行需求了解的时候可能只关心客户想要达到什么功能,而不关心客户的需求具体是什么,那这里我们要先分清需求和功能到底有什么区别先。
需求和功能:
- 需求:客户想要系统或产品达到的效果,或者其能做到对客户来说有价值的事情
- 功能:系统或产品为实现客户想要的效果或价值而提供的能力或功能
- 举例:人们的需求是出行,而汽车是一个系统或产品,它能满足人们的需求,而具体实现需求的功能就是汽车的刹车、加速和转弯
需求的重要性:
很多项目开发开发着就陷入了开发人员和客户互相扯皮或项目陷入停滞的困境,这是因为前期并没有做好项目的需求。换句俗话来说:牛屎做得再像饼,也始终是牛屎。就跟人生一样,如果选择方向选错了,就会一错再错,而且这种错误到了后期来修正将需要付出极高的成本,下面的表格是总工期20天的工程项目不同阶段修正需求错误所需的成本
| 开发阶段 | 修正成本(1人/天) |
|---|---|
| 需求阶段 | 0.1-0.2 |
| 编码阶段 | 1-5 |
| 测试阶段 | 5-10 |
| 维护阶段 | 10-20 |
从成本的消耗来看,需求是非常重要的,如果需求错了就几乎要把项目重做一遍。
需求分析的目的:
需求那么重要,当然不会是一个人单打独斗就能完成的了,需求分析这一步工作可以分为三个不同的岗位,分别是记录员、分析员、引导员,他们分别的职能如下
- 记录员:负责记录客户的需求
- 分析员:与客户一起分析和完善需求
- 引导员:负责引导客户的需求
为什么要分析客户提出的需求呢?这是因为很多客户并不是专业的,很多可能是业务人员来的,他并不知道计算机能以什么形式来实现,所以需要分析员和引导员来指引客户和分析客户需求。
一、需求分析方法
需求分析的方法其实就跟买东西定制商品是差不多流程的,想要把客户的想法和需求了解清楚具体要问到的就是 5w1h8c(when、where、who、what、why;how;8constrain),其中 5w1h是功能属性,8c是质量属性
1、5w —— when、where、who、what、why
- when:客户想在什么时候使用,例如我们开发的是数据备份的系统,那通常都是半夜执行备份任务的,很明显该需求就需要自动化执行
- where:客户想要在什么地方使用,同样的功能放在不同的环境下用的做法肯定是不一样的,如果是在嵌入式系统使用就需要尽量的轻量化
- who:客户想让谁来使用,这里的谁不特指人,可以是某个系统
- what:客户想要系统或产品输出什么结果,例如输出图片、文档等
- why(核心):客户为什么要这么做,是什么让客户有这个需求,通常这个不问客户也不会主动去说,但是这个确是 5w 中的核心,也是需求的出发点

2、1h —— how
- how:如何实现客户的需求,使用用例方法
3、8c —— 8个约束(constraint)
- performance(性能):指的是系统提供相应服务的效率,主要包含响应时间、吞吐量等,它是系统架构设计的关键约束条件之一
- cost(成本):指的是为了实现系统而需要付出的代价,它是系统架构设计的关键约束条件之一
- time(时间):指的是客户对系统交付的期望时间
- reliability(可靠性):指的是系统长时间正确运行的能力,在银行、证券、电信这类公司对可靠性要求很高,通常会使用多套系统并行的冗余设计来提高稳定性
- security(安全性):指的是对信息安全的保护能力
- compliance(合规性):指的是满足各种行业标准、法律法规、规范等,例如 3C、SOX、3GPP,ITUT 等
- technology(技术性):指的是客户在开发系统时要求采用某些特定的技术
- compatibility(兼容性):指的是开发的产品或系统与原有产品或系统的兼容能力,目前许多企业所开发的新系统都会与旧系统互联交互,避免让各个系统之间形成信息孤岛,所以需要不同系统之间能够相互兼容,一起工作
二、用例写法
用例分析方法(三段法 —— NEA):
其他了解客户需求的方法:调查问卷、头脑风暴、数据分析、数据挖掘、竞争对手分析等
正常处理(Normal):通过和客户沟通,分析需求的正常流程
异常处理(Exception):在正常处理流程的步骤上,分析每一步的各种异常情况和对应的处理
替代处理(Alternative):在正常处理流程的步骤上,分析每一步是否有其他替代方法,以及替代方法如何做
书写格式:
1、用例名称
一般情况下是需求的名称
2、场景
即用例发生的环境,对应 5w 中的 when、where、who
3、用例描述
描述详细的用例内容,对应 5w1h 中的 what 和 how;即用户应该怎么使用,以及用例每一步都会有什么输出
4、用例价值
描述用例对应的客户价值,对应 5w 中的 why
5、约束和限制
描述每个需求流程中的相关约束和限制条件,对应 5w1h8c 中的 8c
领域模型
在需求分析阶段基本是不划分面向对象编程还是面向过程编程的,而领域模型是需求分析到面向对象设计的一座桥梁,它是对领域内的概念或现实世界中对象的可视化表示,又称为观念模型(领域对象模型、分析对象模型),它专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系。
主要作用:
- 发掘重要的业务领域概念
- 建立业务领域概念之间的关系
领域建模的方法:
- 从用例当中寻找领域对象的名词,这一方面不同领域有不同的操作方法,如果像建模建得好需要一定的经验累计,并没有统一的标准
- 添加相应的属性,有些属性会在用例中体现出来,而一些隐性的就需要根据行业经验进行累计才能准确的进行添加了
- 不同领域之间的关系链接,这里需要用 UML 中的用例图来进行体现
设计模型
面向对象类设计的具体步骤:
1、领域类映射
注意:这一步并不是对领域模型中的全盘复制
类筛选:并不是领域模型的每个领域类都会出现在系统中
名称映射:模型中的名称对应到具体的类当中
属性映射:可以照搬领域模型当中对应的
提炼方法:领域类中并没有方法,可以在用例中找动词
2、应用设计原则和设计模式
3、拆分辅助类
在领域模型中有些领域在实现阶段时可以拆分成多少个模型。
实现模型
到了实现模型阶段就是需要正真动手敲代码了,我们只需要选取一种支持面向对象的编程语言来进行编写了,可以选 Python、Java、C++、C# 等等。
案例:年会答题系统
补充:xlrd 的使用方法
# 导入
import xlrd# 打开excel
# 注意:这里的workbook首字母是小写
data = xlrd.open_workbook('demo.xls')# 查看文件中包含sheet的名称
data.sheet_names()# 得到第一个工作表,或者通过索引顺序或工作表名称
table = data.sheets()[0]
table = data.sheet_by_index(0)
table = data.sheet_by_name(u'Sheet1')# 获取行数和列数
nrows = table.nrows
ncols = table.ncols# 获取整行和整列的值(数组)
table.row_values(i)
table.col_values(i)# 循环行,得到索引的列表
for rownum in range(table.nrows):
print table.row_values(rownum)# 单元格
cell_A1 = table.cell(0,0).value
cell_C4 = table.cell(2,3).value# 分别使用行列索引
cell_A1 = table.row(0)[0].value
cell_A2 = table.col(1)[0].value
xlrd 演示代码:
# 使用
import xlrd
data=xlrd.open_workbook(r'G:\joveProject\AnswerSys\test.xls')
table=data.sheets()[0]
print(table.nrows)
print(table.ncols)
print(table.row_values(3))
print(table.col_values(0))
for i in range(table.nrows):
print(table.row_values(i))
print(table.cell(1,1).value)
# 操作test.xls
subject={
'type':None,
'choice':[],
'res':set(),
}
for i in range(2,table.nrows):
row=table.row_values(i)
if len(subject['choice'])==4:
print(subject)
subject={
'type':None,
'choice':[],
'res':set()
}
if row[0]:
subject['type']=row[0]
else:
subject.setdefault('choice').append(row[2])
if row[3] == 1:
res_str=row[2].strip()
res=res_str[0].upper()
subject['res'].add(res)
else:
print(subject)第一步:需求分析
1、用例名称
年会答题系统
2、场景
when:2024.12.20 年会使用
where:公司会议室
who:公司员工
3、用例描述
1.行政部提供50道题目(与公司企业文化相关)
2.每位员工无需输入任何个人信息就可以参与答题,随机选择20道题给员工回答,每道题5分
3.答题结束后,要求输入手机号,然后提交算总分
4.分数达到60分可以参与抽奖,小于60分则赠送参与奖
4、用例价值
答题有奖,答题后输入手机号获取成绩,从而知道具体员工是谁,通过答题成绩可以了解员工对公司的了解程度,可以作为提拔参考
5、约束和限制
无
第二步:领域模型
找名词:
行政部、公司员工、题目、得分、奖、
参与奖(去掉与领域无关的名词,参与奖也属于奖品的一种)
加属性:
| 名词 | 属性 | 备注 |
|---|---|---|
| 行政部 | - | 对于年会答题系统来说,并不需要行政部的属性,因此在领域模型中行政部是没有属性的 |
| 公司员工 | 员工编号,姓名,性别,年龄,手机号 | |
| 题目 | 题目编号,题目类型,题目描述,答题选项,正确答案,分数 | |
| 答题记录 | 记录编号,员工编号,题目编号列表,总分数,时间 | 通过答题记录就可以知道是那个员工答题的,以及用户答过的题目 |
| 奖品 | 奖品编号,奖品名称 | |
| 领奖记录 | 记录编号,员工编号,奖品编号 | 通过领奖记录就可以知道那个员工领过什么奖品 |
找关系:
1、找名词之间的关系
- 公司员工和题目之间的关系类就是答题记录
- 公司员工和奖品之间的关系类就是领奖记录(这样看领奖记录就知道谁领了什么奖品了)
2、找出用例当中的动词
创建题目、随机选择题目、答题、提交、算总分、抽奖
画图:
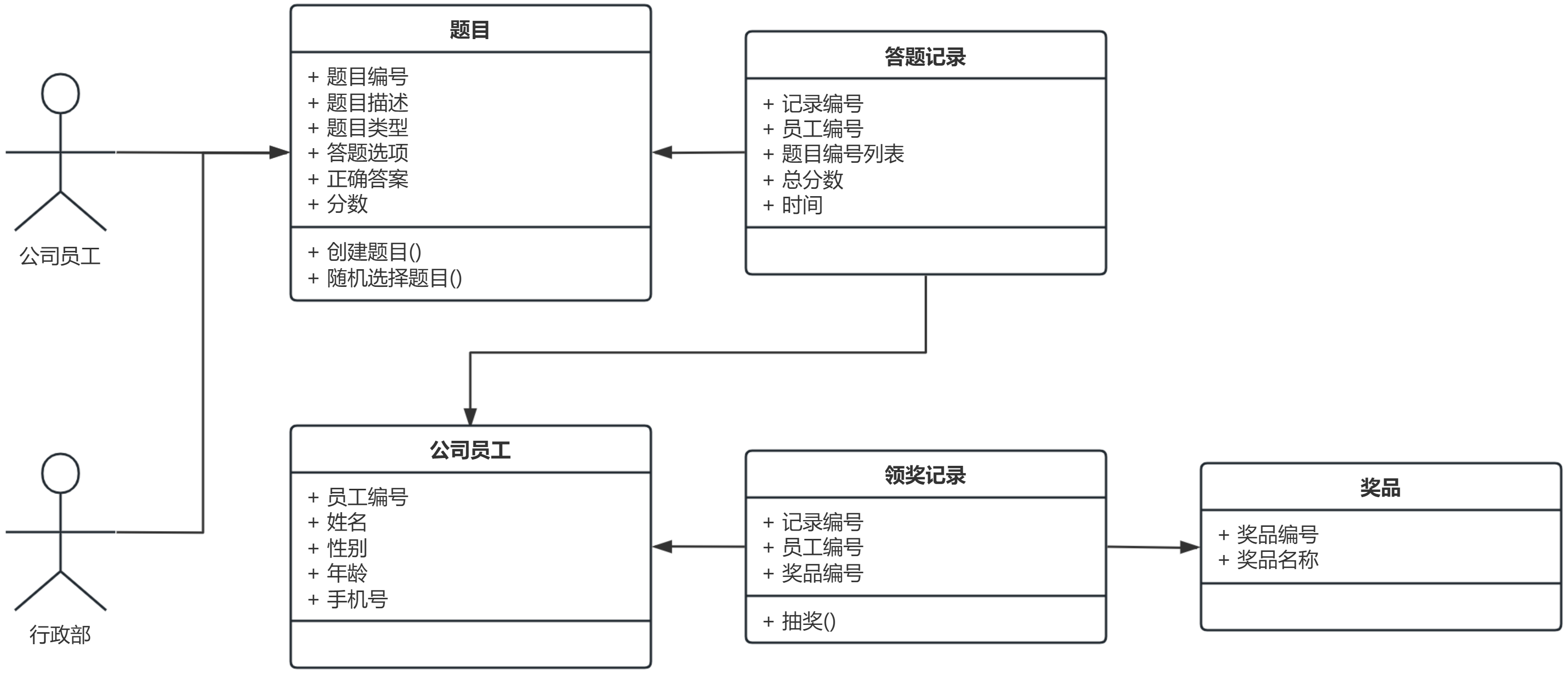
UML 的类图当中:
加号(+)来表示 public 的属性
减号(-)来表示 private 的属性
井号(#)来表示 protected 的属性
第三步:设计模型(略)
第四步:实现模型
目录结构:
AnswerSys/
| -- bin/
| | -- start.py
|
| -- conf/
| | -- settings.py
| |
| -- core/
| | -- models.py
| | -- src.py
|
| -- db/
| | -- customer/
| | -- customer_to_prize/
| | -- prize/
| | -- record/
| | -- subject/
|
| -- lib/
| | -- common.py
|
| -- log/
|
| -- test.xls
| -- requirements.txt
| -- README
start.py:程序入口
#_*_coding:utf-8_*_
import os,sys
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
from core.models import * # 反序列化对象,必须保证类已经在内存中
from core import src
if __name__ == '__main__':
src.run()settings.py:系统的一些设置
import os
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
QUESTION_PATH=os.path.join(BASE_DIR,'db','subject')
CUSTOMER_PATH=os.path.join(BASE_DIR,'db','customer')
RECORD_PATH=os.path.join(BASE_DIR,'db','record')
PRIZE_PATH=os.path.join(BASE_DIR,'db','prize')
C2P_PATH=os.path.join(BASE_DIR,'db','customer_to_prize')models.py:系统的功能组件代码,当 db/subject/ 和 db/prize/ 下没有数据时需要先运行该程序进行系统的初始化
# import os,sys
# BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# sys.path.append(BASE_DIR)
from lib import common
from conf import settings
import random
import pickle
import os
import xlrd # 确保xlrd库已被安装:pip3 install xlrd
import time
class Base:
def save(self):
print(self.DB_PATH)
file_path=r'%s\%s' %(self.DB_PATH,self.id)
pickle.dump(self,open(file_path,'wb'))
@classmethod
def get_obj_by_id(cls,id):
file_path=r'%s\%s' %(cls.DB_PATH,id)
return pickle.load(open(file_path,'rb'))
class Subject(Base):
DB_PATH=settings.QUESTION_PATH
def __init__(self,type,comment,choice,right_res,score=5):
self.id=common.create_id()
self.type=type
self.comment=comment
self.choice=choice
self.right_res=right_res
self.score=score
@classmethod
def create_from_file(cls,src_file):
data=xlrd.open_workbook(src_file)
table=data.sheets()[0]
subject={
'type':None,
'comment':None,
'choice':[],
'res':set(),
}
for i in range(2,table.nrows):
row=table.row_values(i)
if len(subject['choice'])==4:
obj=cls(
subject['type'],
subject['comment'],
subject['choice'],
subject['res']
)
obj.save()
subject={
'type':None,
'comment':None,
'choice':[],
'res':set()
}
if row[0]:
subject['type']=row[0]
subject['comment']=row[1]
else:
subject.setdefault('choice').append(row[2])
if row[3] == 1:
res_str=row[2].strip()
res=res_str[0].upper()
subject['res'].add(res)
else:
obj=cls(
subject['type'],
subject['comment'],
subject['choice'],
subject['res']
)
obj.save()
@classmethod
def filter_question(cls):
id_l=os.listdir(settings.QUESTION_PATH)
r_id_l=random.sample(id_l,3)
return [cls.get_obj_by_id(id) for id in r_id_l]
def __str__(self):
return '<type: %s comment: %s>' %(self.type,self.comment)
class Customer(Base):
DB_PATH=settings.CUSTOMER_PATH
def __init__(self,name,sex,age,phone):
self.id=common.create_id()
self.name=name
self.sex=sex
self.age=age
self.phone=phone
class Record(Base):
DB_PATH=settings.RECORD_PATH
def __init__(self,customer_id,record_list,total_score):
self.id=common.create_id()
self.customer_id=customer_id
self.record_list=record_list
self.total_score=total_score
self.sub_time=time.strftime('%Y-%m-%d %X')
@classmethod
def get_obj_by_phone(cls,phone):
records=(cls.get_obj_by_id(id) for id in os.listdir(cls.DB_PATH))
for record in records:
customer_obj=Customer.get_obj_by_id(record.customer_id)
if phone == customer_obj.phone:
return record
class Prize(Base):
DB_PATH=settings.PRIZE_PATH
def __init__(self,name):
self.id=common.create_id()
self.name=name
@classmethod
def create_prize(cls):
while True:
name=input('奖品名: ').strip()
if not name:continue
obj=Prize(name)
obj.save()
choice=input('继续(Y/N)?: ').strip()
if choice == 'N' or choice == 'n':
break
@classmethod
def get_obj_by_name(cls,name):
prizes=(cls.get_obj_by_id(id) for id in os.listdir(cls.DB_PATH))
for prize in prizes:
if prize.name == name:
return prize
def __str__(self):
return '<%s>' %self.name
class Customer2Prize(Base):
DB_PATH=settings.C2P_PATH
def __init__(self,customer_id,prize_id):
self.id=common.create_id()
self.customer_id=customer_id
self.prize_id=prize_id
@classmethod
def get_obj_by_customer_id(cls,customer_id):
prizes=(cls.get_obj_by_id(id) for id in os.listdir(cls.DB_PATH))
for prize in prizes:
if prize.customer_id == customer_id:
return prize
@classmethod
def draw_prize(cls,customer_id):
"""
奖品概率:
1/100 欧洲十国游
5/100 MAC电脑
10/100 iphone15 pro max
34/100 科比签名一个
50/100 珍藏版写真集一套
"""
num=random.randint(1,100)
if num == 1:
# 欧洲十国游
prize_name='欧洲十国游'
elif 1 < num <=6:
# MAC电脑
prize_name='MAC电脑'
elif 6 < num <=16:
# iphone15 pro max
prize_name='iphone15 pro max'
elif 16 < num <= 50:
# 科比签名一个
prize_name='科比签名一个'
elif num > 50:
# 珍藏版写真集一套
prize_name = '珍藏版写真集一套'
prize=Prize.get_obj_by_name(prize_name)
obj=cls(customer_id,prize.id)
obj.save()
return prize_name
if __name__ == '__main__':
# 通过 xlrd 来操作 excel,从而创建题目,只支持xls,初次运行时要使用以下代码
# Subject.create_from_file(r'G:\joveProject\AnswerSys\test.xls')
# res=Subject.filter_question()
# for i in res:
# print(i)
Prize.create_prize()src.py:系统的主代码
# _*_coding:utf-8_*_
from core import models
import sys
func_dic={}
def make_route(name):
def deco(func):
func_dic[name]=func
return deco
@make_route('1')
def answer():
record_list=[]
questions=models.Subject.filter_question()
num=1
for question in questions:
print('''
%s%s、%s
%s
%s
%s
%s
''' %(question.type,num,question.comment,question.choice[0],
question.choice[1],question.choice[2],question.choice[3]))
user_choice=set(input('选项: ').strip().upper())
score=5 if user_choice == question.right_res else 0
record=(question.id,user_choice,score)
record_list.append(record)
num+=1
choice=input('提交(Y/N)? ').strip()
if choice == "Y" or choice == "y":
commit(record_list)
def commit(record_list):
"""生成公司员工对象,生成答题记录"""
print('\033[45m我们将会根据您提供的信息通知您是否中奖!!!\033[0m')
while True:
name=input('姓名: ')
sex=input('性别: ')
age=input('年龄: ')
phone=input('手机号: ')
record=models.Record.get_obj_by_phone(phone)
if record:
print('该手机号已经被注册')
return
if all([name,sex,age,phone]):
break
else:
print('所有信息不能为空')
obj1=models.Customer(name,sex,age,phone) # 创建公司员工
obj1.save()
total_score=sum(record[2] for record in record_list)
obj2=models.Record(obj1.id,record_list,total_score) # 创建公司员工的答题记录
obj2.save()
@make_route('2')
def search():
while True:
phone=input('输入手机号查询答题结果>>: ').strip()
if phone:break
record=models.Record.get_obj_by_phone(phone)
if not record:
print('您的答题记录不存在')
return
total_score=record.total_score
customer=models.Customer.get_obj_by_id(record.customer_id)
customer_name=customer.name
show_str='您好%s 您的总成绩为:%s' %(customer_name,total_score)
print(show_str.center(80,'='))
num=1
for record in record.record_list:
question=models.Subject.get_obj_by_id(record[0])
print('''
%s%s、%s(%s) 正确答案(%s) 得分:%s
%s
%s
%s
%s
''' %(question.type,num,question.comment,''.join(record[1]),
''.join(question.right_res),record[2],question.choice[0],
question.choice[1],question.choice[2],question.choice[3]))
num+=1
@make_route('3')
def draw_prize():
while True:
phone=input('输入手机号开始抽奖>>: ').strip()
if phone:break
record=models.Record.get_obj_by_phone(phone)
total_score=record.total_score
customer_id=record.customer_id
prize_record=models.Customer2Prize.get_obj_by_customer_id(customer_id)
if prize_record:
print('您已经抽过奖啦,年亲人不要这么贪心,迟早要遭报应的')
return
if total_score < 5:
print('恭喜您获得参与奖:xxx视频一套')
print('视频链接:http://www.xxxx.com')
else:
prize_name=models.Customer2Prize.draw_prize(customer_id)
print('恭喜您中奖:%s' %prize_name)
@make_route('4')
def quit():
sys.exit()
def run():
msg='''
1 答题
2 查看
3 抽奖
4 退出
'''
print(msg)
while True:
choice=input('>>: ').strip()
if choice == '5':break
if choice not in func_dic:continue
func_dic[choice]()common.py:公共功能模块,里面只有一个 hash 生成函数,主要是为生成员工编号、题目编号、答题记录编号、奖品编号、领奖记录编号
#_*_coding:utf-8_*_
import hashlib
import time
def create_id(*args):
m=hashlib.md5()
m.update(str(time.time()).encode('utf-8'))
return m.hexdigest()项目代码:https://pan.baidu.com/s/12jUZq_tgAW28VXTll0Yjkw?pwd=mmus
标签:name,答题,Python,self,choice,record,73,id,prize From: https://blog.csdn.net/zjw529507929/article/details/144368075