把Rust作为动态库或静态库链接到Qt环境中,本就是一件复杂的工作,在此基础上还要引入QRust更是难上加难,因此在这一章我将手把手的引导你向前迈进,并跨过我曾经遇到的坑。
编程环境
Qt环境:Qt6,没错不支持Qt5。因为我发现struct的类型推导在Qt5环境下有错误。
Rust环境:理论上没有限制,但在windows环境下存在Qt链接Rust静态库时链接符号找不到的问题,此问题发生在Rust高版本上,因此我的Rust版本一直保持在1.65.0-nightly,不敢升级,而在MacOS和Linux环境中没有发现问题。
下面列出的是经过我实测的环境,特别说明不在表中并不意味着不支持,只是我个人没有能力进行更多的测试。
| 系统 | 发行版 | C++环境 | CMake版本 | Qt版本 | Rust版本 |
| Windows | X86 windows11 | MSVC2019 | CMake3.29.3 | Qt6.7.2 | 1.65.0-nightly |
| Linux | X86 Kylin V10(SP1) | Kylin 9.3.0 | CMake3.29.3 | Qt6.7.2 | 1.81.0 |
| MacOS | M2 Sonoma 14.5 | Apple clang 15 | CMake3.24.2 | Qt6.5.3 | 1.71.1 |
以上环境中Qt6的安装以及相关配置稍微复杂一些,特别是社区版的Qt6,每次安装可能会遇到不同的问题,耐心多试是成功的关键。
构建项目
QRust源代码中有两个项目:
- 目录rust是Rust端项目,可直接进行cargo build –release的构建。
- 目录qt-window是Qt端项目,为了能更好演示QRust的异步调用,这个项目是个窗口程序,而不是控制台程序。
这两个项目一起构建了演示Qrust的demo程序,强烈建议你的第一个实现在这两个项目基础上进行构建。
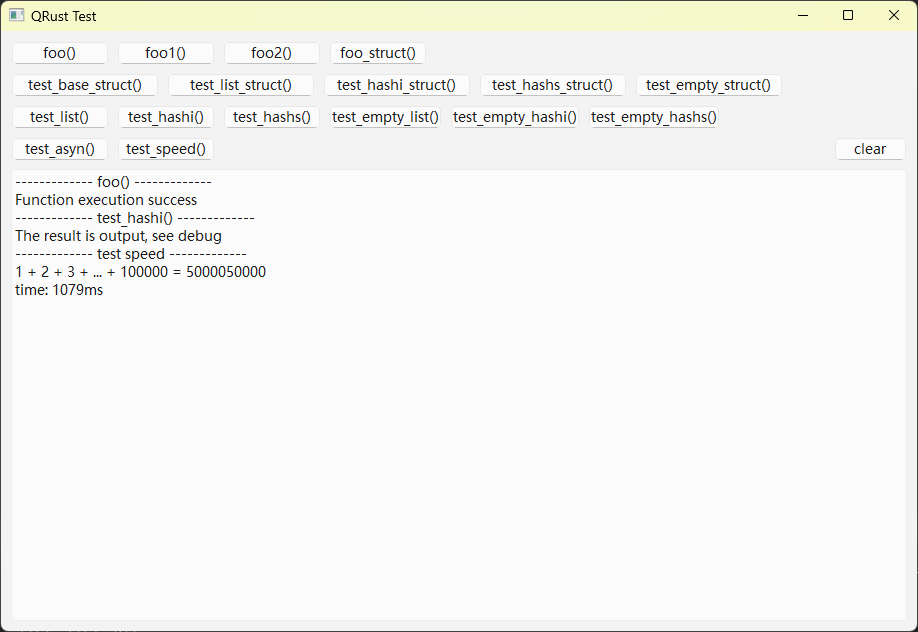
Rust端项目
serde_qrust目录是当前crate包含的一个子crate,是serde的序列化和反序列化的实现,如果你对serde的实现不感兴趣,可以略过这里的代码,我们把眼光聚焦在当前crate中,首先是项目配置文件Cargo.toml:
……
[dependencies]
libc = "*"
log = "0.4"
log4rs = "0.10.0"
serde = {version = "1.0", features = ["derive"]}
serde_qrust = {path = "./serde_qrust"}
[lib]
crate-type = ["staticlib"]
name = "qrust"
[profile.release]
panic = "abort"
[profile.dev]
panic = "abort"
log4rs可以替换成你喜欢的日志库,请聚焦[lib]下的配置:
- crate-type = [“staticlib”] 这一句表示编译的最终目的是静态链接库
- name = “qrust” 这一句表示编译生成的库的名称,输出路径在target目录下,不同系统下库的扩展名可能不同,在windows下最终的输出文件是qrust.lib
src目录中有两个文件,lib.rs和api.rs

api.rs是完全和QRust解耦的,里面是demo函数的实现和所传递struct的定义,没有什么特殊性,当你将程序运行后,结合Qt端的调用,很容易就能理解文件中的每一行代码。这里为了讲述方便,将api.rs中的函数称之为“业务函数”,业务函数是你自己根据需求要实现的部分。现在聚焦到和QRust紧密相关的lib.rs。
fn invoke(fun_name: &str, mut args: Vec<&[u8]>) -> Result<Option<Vec<u8>>>
{
match fun_name
{
"foo" => //无参数、无返回的函数调用示例
{
api::foo(); //调用函数
Ok(None)
}
"foo1" => //有1个参数、无返回的函数调用示例
{
let a1 = de::from_pack(args.pop().unwrap())?; //反序列化获得参数
api::foo1(a1);
Ok(None)
}
"foo2" => //有多个参数、有返回的函数调用示例
{
let a1 = de::from_pack(args.pop().unwrap())?;
let a2 = de::from_pack(args.pop().unwrap())?;
let a3 = de::from_pack(args.pop().unwrap())?;
let ret = api::foo2(a1, a2, a3);
let pack = ser::to_pack(&ret)?; //返回值打包(序列化)
Ok(Some(pack))
}
"foo_struct" => //自定义struct类型的示例
{
let arg = de::from_pack(args.pop().unwrap())?;
let count = de::from_pack(args.pop().unwrap())?;
let ret = api::foo_struct(arg, count);
let pack = ser::to_pack(&ret)?;
Ok(Some(pack))
}
……
}
invoke函数我称之为“手动的运行时反射函数”,在这里做了3件事:
- 根据Qt请求的代表函数的名称字符串,匹配(match)对应的业务函数
- 执行业务函数前,通过from_pack() 解析出函数的参数(反序列化)
- 执行业务函数后,通过to_pack()打包返回值(序列化)
对于一些支持运行时反射的语言(如Java),匹配和调用函数可以做到完全自动化,但Rust是没有这个功能的,所以需要在这里为每一个业务函数手工编写match代码。
如果业务函数数量很多match分支就显得过长,或者业务函数需要分模块处理,统一写在一个match中不太适合,在OnTHeSSH中我是这样处理的:
pub fn invoke(fun_name: &str, args: Vec<&[u8]>) -> Result<Option<Vec<u8>>>
{
if fun_name.starts_with("rhost::") //远端主机管理
{
crate::rhost::api_host::invoke_host(fun_name, args)
}
else if fun_name.starts_with("group::") //远端主机分组管理
{
crate::rhost::api_group::invoke_group(fun_name, args)
}
else if fun_name.starts_with("workhosts::") //multi工作中的远端主机
{
crate::rhost::api_workhosts::invoke(fun_name, args)
}
else if fun_name.starts_with("base::") //基本能力
{
crate::base::api::invoke(fun_name, args)
}
......
}
在请求的函数名称字符串前添加模块前缀,比如遇到以”rhost::”开始的请求转到rhost::api_host::invoke_host函数,这样实现了分模块的处理方式。
仔细观察一下这几行代码(从vscode中截图):
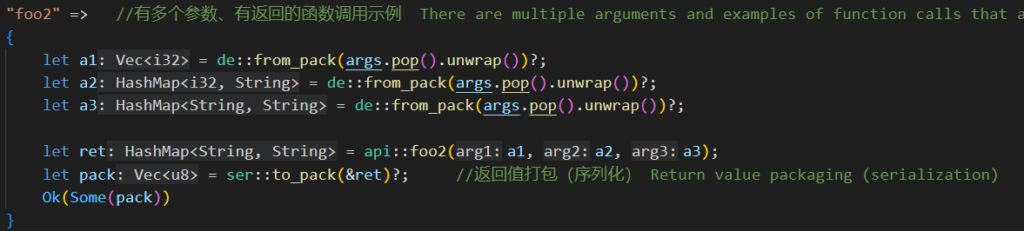
三个参数a1,a2,a3的反序列化代码是完全相同的,但解析出的变量类型分别是Vec<i32>,HashMap<i32,String>和HashMap<String, String>,这是怎么做到的?实际上是由后面这一句 api::foo2(a1, a2, a3)决定的,因为 a1,a2,a3作为业务函数foo2的参数,而foo2的函数定义决定了他们的数据类型,因此在前面的反序列化过程中按对应的类型来求值,这种改变历史行为是否很奇妙?
这可不是量子力学,在Rust中叫做类型推导。类型推导的发生时刻并不在程序的运行期,而是编译期间,这也是Rust编译速度较慢的一个原因,因为编译器做了大量的附加工作。
同理,QRust的Qt端因为泛型模板的使用,编译速度也变得比较缓慢。
FFI接口
Rust端编译成链接库后,面向Qt端有5个定义好的,伪装成C函数的接口,他们的实现代码都在lib.rs文件中:
- pub unsafe extern “C” fn qrust_init()
- pub unsafe extern “C” fn qrust_call(in_ptr: *const c_uchar, size: c_int) -> Ret
- pub unsafe extern “C” fn qrust_free_ret(ret: Ret)
- pub unsafe extern “C” fn qrust_free_str(ptr: *const c_char)
- pub unsafe extern “C” fn qrust_free_bytes(ptr: *const u8, len: c_int)
这5个接口是原始的支持C语言调用Rust的,符合FFI标准的函数,能看到一点FFI的复杂性了吧 :)
如果你只是QRust的使用者,而不关注QRust的设计和实现,这5个接口函数掌握第一个就可以了,下面逐一介绍:
1)qrust_init() – 这个函数的作用是在调用Rust端业务函数之前,可以做点什么预先的事情。在demo中Qt端在开始的main()中调用了此函数,通过进程环境变量给Rust传递了一个路径,Rust端将log4rs产生的日志输出到这个路径下的日志文件中。Qt和Rust各有各的日志框架,不大可能将Rust的日志合并到Qt的qDebug()中,因此日志输出各走各的路。
2) qrust_call() 和 qrust_free_ret() – 这两个函数是QRust的核心。Qt端在调用Rust端业务函数时,将业务函数的名称字符串、序列化后的参数进行二进制打包,并将二进制包的地址作为参数发送给Rust端;业务函数的返回值经过打包(序列化)后,将二进制包地址封装到Ret的结构中返还给Qt端调用者,这个过程由qrust_call()函数实现。
QRust的函数请求包和返回包,都是以地址方式传递的,请求包由Qt端生成,返回包由Rust端生成,在内存布局上这两个包都在堆上,因此函数调用后他们占用的内存需要释放掉。Qt和Rust对内存申请和释放的机制可能存在差异,因此不要去释放对方申请的内存。请求包由Qt端生成,在函数返回时Qt端自己可释放,但返回包由Rust端生成,且Rust端无法知道返回包在Qt端什么时间已使用完毕,因此无法进行释放。所以需要Qt通知Rust:“我已经使用完毕,你可以安全的释放内存了”,qrust_free_ret()函数就是干这个用的。
内存操作总是复杂且容易出错的,这也是C调用Rust的难点之一,好在QRust将这些操作封装在内部,使用者不会接触到这些底层代码。
3)qrust_free_str() 和 qrust_free_bytes() – 这两个接口函数在QRust当前版本中还没有完全实现,他们是配合大数据调用的接口。比如上百兆的字符串或二进制数据在Qt和Rust之间传递时,就不适合采用序列化机制,应该以地址方式直接传递,这两个接口是释放内存使用的。
Qt端项目
我们再把眼光聚焦到Qt端:
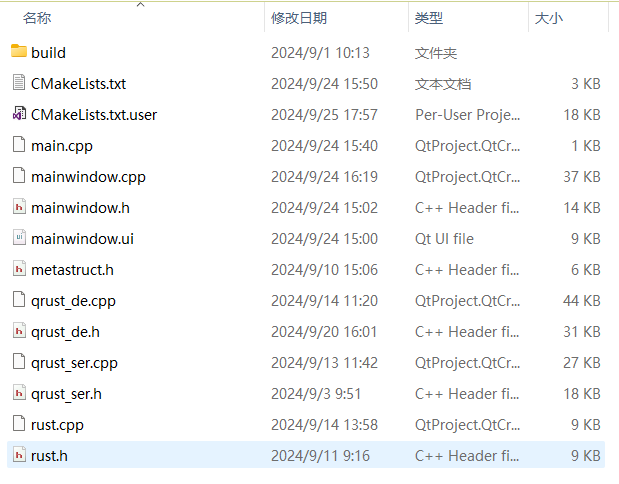
Qt端项目是在Qt Creator中按新建窗口项目方式创建出来的,因此你如果想从一个空项目开始,跟着下面的步骤就可以。
metastruct.h,qrust_de.h|.cpp, qrust_ser.h|.cpp,rust.h|.cpp 这7个文件是QRust在Qt端的实现源码,如果你对QRust的底层实现不感兴趣,可以忽略他们,只需要将这7个文件导入到项目中,且确保不要编辑修改。
首先,聚焦到CMake的配置文件CMakeLists.txt。
1)在find_package中添加’Concurrent’组件,此组件支持异步调用。
2)添加LINK_DIRECTORIES配置,定义qrust静态库路径,注意这个路径在Rust端项目的编译输出路径中。
find_package(QT NAMES Qt6 Qt5 REQUIRED COMPONENTS Widgets Concurrent)
find_package(Qt${QT_VERSION_MAJOR} REQUIRED COMPONENTS Widgets Concurrent)
LINK_DIRECTORIES(D:/MySelf/project/QRust/code/rust/target/release)
3)相应的在target_link_libraries中添加Concurrent组件和qrust静态库:
target_link_libraries(qt_window PRIVATE
Qt${QT_VERSION_MAJOR}::Widgets
Qt${QT_VERSION_MAJOR}::Concurrent
qrust
)
4)复制metastruct.h,qrust_de.h|.cpp, qrust_ser.h|.cpp,rust.h|.cpp 7个文件到项目中,并在cmake配置文件中加载:
set(PROJECT_SOURCES
main.cpp
mainwindow.cpp
mainwindow.h
mainwindow.ui
metastruct.h
qrust_de.cpp qrust_de.h
qrust_ser.cpp qrust_ser.h
rust.cpp rust.h
)
再聚焦到main.cpp文件:
1)在main.cpp中需加载ws2_32.lib和Bcrypt.lib,这是windows环境下编译时链接qrust所依赖的库文件。注意在非windows环境中需要将这两行注释掉。
2)在main()中调用rust端函数qrust_init(),此调用并非必须,但如果想做一些初始化工作,比如rust端的日志配置。
#include "mainwindow.h"
#include <QApplication>
#pragma comment (lib, "ws2_32.lib")
#pragma comment (lib, "Bcrypt.lib")
//qrust_init()是rust端函数,因此声明为 extern "C"
extern "C" {
void qrust_init();
}
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
//在这里通过调用qrust_init(),设置rust的日志输出路径
QString log_path = "d:/TMP/log"; //这个路径要修改
qputenv("LOG_PATH", log_path.toStdString().c_str()); //设置环境变量
qrust_init(); //qrust初始化
MainWindow w;
w.show();
return a.exec();
}
Mainwindow.h|.cpp文件是QRust带的demo,我在下一章讲解。
编译和运行:
编译时需要先编译Rust端,因为它要作为Qt端的链接库。Rust编译命令:
cargo build --release
注意在编译调试的过程中,Qt并不能识别Rust生成的静态链接库的变动,当你重新编译Rust端后紧接着编译Qt,Qt仍按老版本运行。解决这个问题可以在Qt端调用Qrust的代码文件中添加或删除一个空格,让文件发生改变,触发Qt对此文件的重新编译,连带对链接库的重新链接。
Qt端项目编译时,Linux下CMake可能会发生以下错误:
undefined reference to symbol ‘dlsym@@GLIBC_2.4’
解决方法是在target_link_libraries下添加dl库,如下:
target_link_libraries(qt_window PRIVATE
Qt${QT_VERSION_MAJOR}::Widgets
Qt${QT_VERSION_MAJOR}::Concurrent
qrust
dl
)
标签:qrust,Qt,框架,编程,QRust,pack,Rust,函数 From: https://www.cnblogs.com/dyf029/p/18539581