一、从C转向C++
1.1、使用const和inline而不#define
使用const
const int m = 10;
int n = m;
- 上述代码在C中,编译器会先到m的内存中取出数据,再赋值给n; 但在C++中,会直接将10赋值给n。 C++的常量更类似于#define,是一个替换过程。
- #define经常不被认为是语言的一部分。define本质是替换,并不进行计算,并在编译时进行单纯的替换,因为宏定义是预编译指令不是语句,所以后面不加 “;” 分号
-const 常量限定符,声明的常量为只读,不允许修改。但通过指针方式可以修改 - 在 C++ (不是 C) 中可以用 const 值[声明数组]长度
- 对于全局 const 值,C++ 中默认是内部链接(只允许在本文件内可见),而不是 C 中的默认外部链接,若想在其他文件中使用必须在其他文件中重新定义或将 [const 值]中(默认是外部链接放在头文件中编译可能会出现错误,默认是内部链接就不会出错)
- C++ 中推荐使用 const 代替 #define 声明常量
- const 能够明确指定常量类型
- const 能够用于更复杂的数据类型(如:数组,结构体和类)
- const [标识符]遵循变量的作用域规则,可以创建作用域为全局(仅在本文件中使用)、[命名空间]、函数或数据块的常量
- inline(内联) 函数在被调用处进行代码替换
- C++ 中推荐使用 inline 代替 #define 声明函数
- C++ 中使用 inline 定义内联函数(C 语言中一般是使用 #define 定义宏函数)
- 宏函数是简单的文本替换,不是真正的传参数,如果不注意[运算顺序]很容易出错,C++ 使用 inline 定义内联函数,比定义[宏函数]可靠,inline 定义的内联函数是真正的传递参数,C++ 中 inline 可用于常规函数也可用于类方法
- 宏函数的一个优点是无类型,可用于任意类型,运算都是有意义的,在 C++ 中可创建内联函数模板实现这个功能
1.2、使用<iostream>而不是<stdio.h>
- stdio.h是C语言的输入输出流,使用的是
printf(...);scanf(...); - iostream是C++的标准的输入输出流,为了避免命名定义的冲突,引入了 命名空间定义“namespace”; 在使用
cout<<...;cin>>...; 是需要先申明using namespace std;
点击查看代码
#include <iostream>
#include <string>
using namespace std;
int mian()
{
string user_name;
cout << "Please enter your name: ";
cin >> user_name ;
cout << "Hello, " + user_name +"; Start Effective C++! \n";
return 0;
}
1.3、使用new和delete而不用malloc和free
- 在C++中,使用new/delete和malloc/free进行动态内存的分配与释放;
- new/delete
- 类型安全性: new/delete可以提供更好的类型安全性。使用
new创造对象时,会自动调用 构造函数 进行初始化,在释放内存时, 会自动调用 析构函数,确保资源正确释放,避免内存泄露和资源泄露的风险。 - 异常处理:
new在分配内存失败时,会抛出异常std::bad_alloc异常,便于处理。 - 自动资源管理:new/delete提供了自动资源管理功能,在对象的生命周期结束后能正确释放内存,不需要手动管理。
点击查看代码
#include <iostream>
class MyClass {
public:
MyClass() {
std::cout << " MyClass()" << std::endl;
}
~MyClass() {
std::cout << "~MyClass()" << std::endl;
}
void show() {
std::cout << "Hello!" << std::endl;
}
};
int main() {
// 使用new分配内存并创建对象
MyClass* obj = new MyClass();
obj->show(); // 输出: Hello!
// 使用delete释放内存并调用析构函数
delete obj; // 输出: ~MyClass()
//数组的用法
int* pa=new int[6];
delete[] pa;
return 0;
}
- malloc/free
- 内存分配:
malloc函数根据请求的大小分配一块连续的内存区域,并返回指向该内存的指针。它不会自动初始化内存区域。 - 内存释放:
free函数用于释放之前通过malloc分配的内存。它不会调用析构函数或执行任何清理操作。 - 错误处理:如果
malloc无法分配所需的内存,它会返回NULL
点击查看代码
#include <iostream>
#include <stdlib.h> // 为了使用malloc和free
int main() {
// 使用malloc分配内存(但不调用构造函数)
void* memory = malloc(sizeof(MyClass));
if (memory == nullptr) {
std::cerr << "Memory allocation failed." << std::endl;
return 1;
}
// 使用"placement new"在已分配的内存上构造对象
MyClass* obj = new(memory) MyClass();
obj->show(); // 输出:Hello!
// 手动调用析构函数来销毁对象(但不释放内存)
obj->~MyClass(); // 输出: ~MyClass()
// 使用free释放之前通过malloc分配的内存
free(memory);
return 0;
}
二、内存管理
- C++内存模型
- 在C++中。类是创建对象的模板,不占用内存。不存在编译后的可执行文件内。对象是实际的数据,需要内存存储。
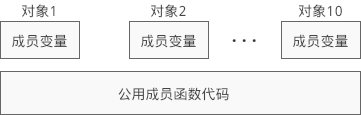
不同对象的成员变量可能不同需要单独分配内存,但不同对象成员函数的代码是一样的,可以共享。存储结构类似上图。 成员变量在堆区或栈区分配内存,成员函数在代码区分配内存。 - 在C++使用new/delete进行动态内存的分配与释放时,需要采用相同的形式;
点击查看代码
//example1, 使用new/delete分配内存更简单,new会依据数据类型来推断需要的内存大小
int *p = new int; //分配1个int型的内存空间
delete p; //释放内存
//example2, 如果希望分配一组连续的数据,使用new[]; 需要使用delete[]释放,两者要对应
int *p = new int[10]; //分配10个int型的内存空间
delete[] p;
三、构造函数,析构函数和赋值操作
- 几乎所有的类都有一个或多个构造函数,一个析构函数和一个赋值操作符。它们提供的都是一些最基本的功能。构造函数控制对象生成时的基本操作,并保证对象被初始化;析构函数摧毁一个对象并保证它被彻底清除;赋值操作符则给对象一个新的值。
- 3.1、构造函数(Constructor):在C++中,有一种特殊的成员函数,它的名字和类名相同,没有返回值,不需要用户显式调用(用户也不能调用),而是在创建对象时自动执行。有了构造函数的存在,可以在创建对象的同时,完成为对象变量赋值;
- 示例如下:
点击查看代码
#include <iostream>
using namespace std;
class Student{
private:
char *m_name;
int m_age;
float m_score;
public:
//声明构造函数
Student(char *name, int age, float score);
//声明普通成员函数
void show();
};
//定义构造函数
Student::Student(char *name, int age, float score){
m_name = name;
m_age = age;
m_score = score;
}
//定义普通成员函数
void Student::show(){
cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
}
int main(){
//创建对象时向构造函数传参
Student stu("小明", 15, 92.5f);
stu.show();
//创建对象时向构造函数传参
Student *pstu = new Student("李华", 16, 96);
pstu -> show();
return 0;
}
- 3.1.1、构造函数必须是public属性,否则创建对象时无法访问;且构造函数没有返回值,不能有return语句。
id:: 66e29a91-e576-42ba-afe2-64262435832e - 3.1.2、构造函数初始化列表
- 构造函数的一项重要功能是对成员变量进行初始化,为了达到这个目的,可以在构造函数的函数体中对成员变量一 一赋值,还可以采用初始化列表。
- 示例如下:
- 初始化列表可以用于全部成员变量,也可以只用于部分成员变量。下面的示例只对 m_name 使用初始化列表,其他成员变量还是一一赋值;成员变量的初始化顺序与初始化列表中列出的变量的顺序无关,它只与成员变量在类中声明的顺序有关。
点击查看代码
#include <iostream>
using namespace std;
class Student{
private:
char *m_name;
int m_age;
float m_score;
public:
Student(char *name, int age, float score);
void show();
};
//采用初始化列表
Student::Student(char *name, int age, float score): m_name(name){
m_age = age;
m_score = score;
}
void Student::show(){
cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
}
int main(){
Student stu("小明", 15, 92.5f);
stu.show();
Student *pstu = new Student("李华", 16, 96);
pstu -> show();
return 0;
}
- 3.1.3、初始化const成员变量
- 初始化 const 成员变量的唯一方法就是使用初始化列表。
点击查看代码
class VLA{
private:
const int m_len; //使用了const修饰,只能使用初始化列表赋值
int *m_arr;
public:
VLA(int len);
};
//必须使用初始化列表来初始化 m_len
VLA::VLA(int len): m_len(len){
m_arr = new int[len];
}
- 3.2、析构函数(Destructor): 也是一种特殊的成员函数,没有返回值,不需要程序员显式调用(程序员也没法显式调用),而是在销毁对象时自动执行。构造函数的名字和类名相同,而析构函数的名字是在类名前面加一个
~符号。一般用来释放已分配的内存。 - 3.3、this指针
- this是C++的一个关键字,也是一个const指针;this 作为隐式形参,本质上是成员函数的局部变量,所以只能用在成员函数的内部,并且只有在通过对象调用成员函数时才给 this 赋值。示例如下:
点击查看代码
#include <iostream>
using namespace std;
class Student{
public:
void setname(char *name);
void setage(int age);
void setscore(float score);
void show();
private:
char *name;
int age;
float score;
};
void Student::setname(char *name){
this->name = name;
}
void Student::setage(int age){
this->age = age;
}
void Student::setscore(float score){
this->score = score;
}
void Student::show(){
cout<<this->name<<"的年龄是"<<this->age<<",成绩是"<<this->score<<endl;
}
int main(){
Student *pstu = new Student;
pstu -> setname("李华");
pstu -> setage(16);
pstu -> setscore(96.5);
pstu -> show();
return 0;
}
四、类与函数
- 4.1、类(class):是创建对象的模板,一个类可以创建多个对象;类只是一种复杂数据类型的声明,不占用内存空间。而对象是类这种数据类型的一个变量,或者说是通过类这种数据类型创建出来的一份实实在在的数据,所以占用内存空间。
- 尽量使类的接口完整且最小;
- 避免public接口出现数据成员; public接口声明函数; private定义数据成员;来实现功能分离。
- 4.2、成员函数,非成员函数,友元函数
- 类可以看做一个包含成员变量和成员函数的集合;类的成员函数也和普通函数一样,都有返回值和参数列表,区别是:成员函数是一个类的成员,出现在类体中,它的作用范围由类来决定;而普通函数是独立的,作用范围是全局的,或位于某个命名空间内。
点击查看代码
class Student{
public:
//成员变量
char *name;
int age;
float score;
//成员函数
void say(); //函数声明
};
//函数定义
void Student::say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
- 对于类(class)的Private成员,只能通过当前类的成员函数才能访问,但当前类以外定义的,不属于当前类的函数,也可以在类中声明,加上 friend关键字,就构成了 友元函数,可访问当前类的所有成员,包括public、protected、private 属性的。
点击查看代码
#include <iostream>
using namespace std;
class Student{
public:
Student(char *name, int age, float score);
public:
friend void show(Student *pstu); //将show()声明为友元函数
private:
char *m_name;
int m_age;
float m_score;
};
Student::Student(char *name, int age, float score): m_name(name), m_age(age)m_score(score){ }
//非成员函数
void show(Student *pstu){
cout<<pstu->m_name<<"的年龄是 "<<pstu->m_age<<",成绩是 "<<pstu->m_score<<endl;
}
int main(){
Student stu("小明", 15, 90.6);
show(&stu); //调用友元函数
Student *pstu = new Student("李磊", 16, 80.5);
show(pstu); //调用友元函数
return 0;
}
点击查看代码
//name是命名空间的名字, 里面可以包含变量,函数,类,typedef,#define等
namespace name{
//variables, functions, classes
}
- 为对象分配的内存,其存活时间称为储存期或范围;
对象在程序内的存活区域称为该对象的scope(作用域);分为local scope和file scope。
local scope:一般为函数内部。
file scope:对象在函数意外声明,从其声明点至文件末尾都是可见的。
五、继承与面向对象设计
-
继承(Inheritance)可以理解为一个类从另一个类获取成员变量和成员函数的过程。例如类 B 继承于类 A,那么 B 就拥有 A 的成员变量和成员函数。
-
以下是两种典型的使用继承的场景:
- 当你创建的新类与现有的类相似,只是多出若干成员变量或成员函数时,可以使用继承,这样不但会减少代码量,而且新类会拥有基类的所有功能。
- 当你需要创建多个类,它们拥有很多相似的成员变量或成员函数时,也可以使用继承。可以将这些类的共同成员提取出来,定义为基类,然后从基类继承,既可以节省代码,也方便后续修改成员。
- class 派生类名:[继承方式] 基类名{派生类新增加的成员};
继承方式包括 public(公有的)、private(私有的)和 protected(受保护的),
此项是可选的,如果不写,那么默认为 private。
-
不同的继承方式会影响基类成员在派生类中的访问权限,建议使用公有继承
继承方式/基类成员 public成员 protected成员 private成员 public继承 public protected 不可见 protected继承 protected protected 不可见 private继承 private private 不可见 - 私有继承: 假定 Class D私有继承于 Class B, 即D对象在实现中用到了B对象, 不继承接口,只继承实现。
- 函数模板:实际上是建立一个通用函数,它所用到的数据的类型(包括返回值类型、形参类型、局部变量类型)可以不具体指定,而是用一个虚拟的类型来代替(实际上是用一个标识符来占位),等发生函数调用时再根据传入的实参来逆推出真正的类型。这个通用函数就称为函数模板(Function Template)。
-
点击查看代码
template<typename T> void Swap(T *a, T *b){
T temp = *a;
*a = *b;
*b = temp;
}
六 异常处理
- 程序的错误大致可以分为三种,分别是语法错误、逻辑错误和运行时错误:
1) 语法错误在编译和链接阶段就能发现,只有符合语法规则的代码才能生成可执行程序。语法错误是最容易发现、最容易定位、最容易排除的错误。
2) 逻辑错误是说我们编写的代码思路有问题,不能够达到最终的目标,这种错误可以通过调试来解决。
3) 运行时错误是指程序在运行期间发生的错误,例如除数为 0、内存分配失败、数组越界、文件不存在等。C++异常(Exception)机制就是为解决运行时错误而引入的。 - C++的异常处理流程为:
抛出(throw)-->检测(Try)-->捕获(catch)- 抛出异常(throw)
- 使用throw关键字显示的抛出异常,用法是 throw exceptionData;
exceptionData可以包含任何数据,可以是基本类型int,float,bool等,也可以是指针,数组,字符串等。 - 捕获异常
- 借助异常机制来捕获异常,避免程序的崩溃,使用语法:
-
try{ // 可能抛出异常的语句 }catch(exceptionType variable){ // 处理异常的语句 } exceptionType是异常类型,表面当前的 catch 可以处理什么类型的异常;variable是一个量,用来接收异常信息。当程序抛出异常时,会创建一份数据,这份数据包含了错误信息,根据这些信来判断到底出了什么问题,接下来怎么处理。只有跟 exceptionType 类型匹配的异常数据才会被传给 variable,否则 catch 不会接收这份异常数据,也不会执行 catch 块中的语句。-
try{ //可能抛出异常的语句 }catch (exception_type_1 e){ //处理异常的语句 }catch (exception_type_2 e){ //处理异常的语句 } //其他的catch catch (exception_type_n e){ //处理异常的语句 } - 当异常发生时,程序会按照从上到下的顺序,将异常类型和 catch 所能接收的类型逐个匹配。一旦找到类型匹配的 catch 就停止检索,并将异常交给当前的 catch 处理。如果最终也没有找到匹配的 catch,就只能交给系统处理,终止程序的运行。
- 标准异常
- 标准库定义了一套异常类体系(exception class hierarchy),其根部名为exception的抽象基类。可以通过以下语句捕获所有的标准异常:
-
try{ //可能抛出异常的语句 }catch(exception &e){ //处理异常的语句 }
-
- 标准库定义了一套异常类体系(exception class hierarchy),其根部名为exception的抽象基类。可以通过以下语句捕获所有的标准异常:
参考链接:https://c.biancheng.net/view/2333.html
标签:name,int,成员,笔记,学习,C++,Student,函数 From: https://www.cnblogs.com/huqinglong/p/18523199