c++指针和引用的区别
指针和引用在 C++ 中都用于间接访问变量,但它们有一些区别:
- 指针是一个变量,它保存了另一个变量的内存地址;引用是另一个变量的别名,与原变量共享内存地址。
- 指针(除指针常量)可以被重新赋值,指向不同的变量;引用在初始化后不能更改,始终指向同一个变量。
- 指针可以为 nullptr,表示不指向任何变量;引用必须绑定到一个变量,不能为 nullptr。
- 使用指针需要对其进行解引用以获取或修改其指向的变量的值;引用可以直接使用,无需解引用。
#include <iostream>
int main() {
int a = 10;
int b = 20;
// 指针
int *p = &a;
std::cout << "Pointer value: " << *p << std::endl; // 输出:Pointer value: 10
p = &b;
std::cout << "Pointer value: " << *p << std::endl; // 输出:Pointer value: 20
// 引用
int &r = a;
std::cout << "Reference value: " << r << std::endl; // 输出:Reference value: 10
// r = &b; // 错误:引用不能被重新绑定
int &r2 = b;
r = r2; // 将 b 的值赋给 a,r 仍然引用 a
std::cout << "Reference value: " << r << std::endl; // 输出:Reference value: 20
return 0;
}
从汇编看引用和指针
引用会被c++编译器当做const指针来进行操作。
先分别用指针和引用来写个非常熟悉的函数swap
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 引用版
void swap(int &a, int &b) {
int temp = a;
a = b;
b = temp;
}
直接gcc -S 输出汇编
# 引用版汇编
__Z4swapRiS_: ## @_Z4swapRiS_
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movq %rdi, -8(%rbp) # 传入的第一个参数存放到%rbp-8 (应该是采用的寄存器传参,而不是常见的压栈)
movq %rsi, -16(%rbp) # 第二个参数 存放到 %rbp-16
movq -8(%rbp), %rsi # 第一个参数赋给 rsi
movl (%rsi), %eax # 以第一个参数为地址取出值赋给eax,取出*a暂存寄存器
movl %eax, -20(%rbp) # temp = a
movq -16(%rbp), %rsi # 将第二个参数重复上面的
movl (%rsi), %eax
movq -8(%rbp), %rsi
movl %eax, (%rsi) # a = b
movl -20(%rbp), %eax # eax = temp
movq -16(%rbp), %rsi
movl %eax, (%rsi) # b = temp
popq %rbp
retq
.cfi_endproc
## -- End function
在来一个函数调用引用版本swap
void call() {
int a = 10;
int b = 3;
int &ra = a;
int &rb = b;
swap(ra, rb);
}
__Z4callv: ## @_Z4callv
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
subq $32, %rsp
leaq -8(%rbp), %rax # rax中是b的地址
leaq -4(%rbp), %rcx # rcx中是a的地址
movl $10, -4(%rbp)
movl $3, -8(%rbp) # 分别初始化a、b
movq %rcx, -16(%rbp) # 赋给ra引用
movq %rax, -24(%rbp) # 赋给rc引用
movq -16(%rbp), %rdi # 寄存器传参, -16(%rbp)就是rcx中的值也就是a的地址
movq -24(%rbp), %rsi # 略
callq __Z4swapRiS_
addq $32, %rsp
popq %rbp
retq
清楚了! 我们可以看到给引用赋初值也就是把所绑定对象的地址赋给引用所在内存,和指针是一样的。
__Z4swapPiS_: ## @_Z4swapPiS_
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movq %rdi, -8(%rbp)
movq %rsi, -16(%rbp)
movq -8(%rbp), %rsi
movl (%rsi), %eax
movl %eax, -20(%rbp)
movq -16(%rbp), %rsi
movl (%rsi), %eax
movq -8(%rbp), %rsi
movl %eax, (%rsi)
movl -20(%rbp), %eax
movq -16(%rbp), %rsi
movl %eax, (%rsi)
popq %rbp
retq
.cfi_endproc
## -- End function
简单总结
-
引用只是C++语法糖,可以看作编译器自动完成取地址、解引用的指针常量
-
引用区别于指针的特性都是编译器约束完成的,一旦编译成汇编就和指针一样
-
由于引用只是指针包装了下,所以也存在风险,比如如下代码:
int *a = new int; int &b = *a; delete a; b = 12; // 对已经释放的内存解引用 -
引用由编译器保证初始化,使用起来较为方便(如不用检查空指针等)
-
尽量用引用代替指针
-
引用没有顶层const即int & const,因为引用本身就不可变,所以在加顶层const也没有意义; 但是可以有底层const即 const int&,这表示引用所引用的对象本身是常量
-
指针既有顶层const(int * const--指针本身不可变),也有底层const(int * const--指针所指向的对象不可变)
-
有指针引用--是引用,绑定到指针, 但是没有引用指针--这很显然,因为很多时候指针存在的意义就是间接改变对象的值,但是引用本身的值我们上面说过了是所引用对象的地址,但是引用不能更改所引用的对象,也就当然不能有引用指针了。
-
指针和引用的自增(++)和自减含义不同,指针是指针运算, 而引用是代表所指向的对象对象执行++或--
指针传递、值传递、引用传递
值传递(value passing)
值传递是将实参的值传递给形参。在这种情况下,函数内对形参的修改不会影响到实参。
#include <iostream>
void swap_value(int a, int b) {
int temp = a;
a = b;
b = temp;
}
int main() {
int x = 10;
int y = 20;
swap_value(x, y);
std::cout << "x: " << x << ", y: " << y << std::endl; // 输出:x: 10, y: 20
return 0;
}
引用传递
引用传递是将实参的引用传递给形参。在这种情况下,函数内对形参的修改会影响到实参。
#include <iostream>
void swap_reference(int &a, int &b) {
int temp = a;
a = b;
b = temp;
}
int main() {
int x = 10;
int y = 20;
swap_reference(x, y);
std::cout << "x: " << x << ", y: " << y << std::endl; // 输出:x: 20, y: 10
return 0;
}
指针传递
指针传递是将实参的地址传递给形参。在这种情况下,函数内对形参的修改会影响到实参。
#include <iostream>
void swap_pointer(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
int main() {
int x = 10;
int y = 20;
swap_pointer(&x, &y);
std::cout << "x: " << x << ", y: " << y << std::endl; // 输出:x: 20, y: 10
return 0;
}
其实,关于值传递、指针传递等有很多争论,比如指针传递这个,本质上也是值传递,只不过传递的值是一个指针而已,所以就看你从什么角度去看待这个问题。
值传递与引用传递,传的是什么?
在网上看到过很多讨论 Java、C++、Python 是值传递还是引用传递这类文章。
参数传递无外乎就是传值(pass by value),传引用(pass by reference)或者说是传指针。
传值还是传引用可能在 Java、Python 这种语言中常常会困扰一些初学者,但是如果你有 C/C++背景的话,那这个理解起来就是 so easy。
今天我就从 C 语言出发,一次性把 Java、Python 这些都给大家讲明白
堆、栈
要注意,这“堆”和“栈”并不是数据结构意义上的堆(Heap,一个可看成完全二叉树的数组对象)和 栈(Stack,先进后出的线性结构)。这里说的堆栈是指内存的两种组织形式,堆是指动态分配内存的一块区域,一般由程序员手动分配,比如 Java 中的 new、C/C++ 中的 malloc 等,都是将创建的对象或者内存块放置在堆区。
而栈是则是由编译器自动分配释放(大概就是你申明一个变量就分配一块相应大小的内存),用于存放函数的参数值,局部变量等。
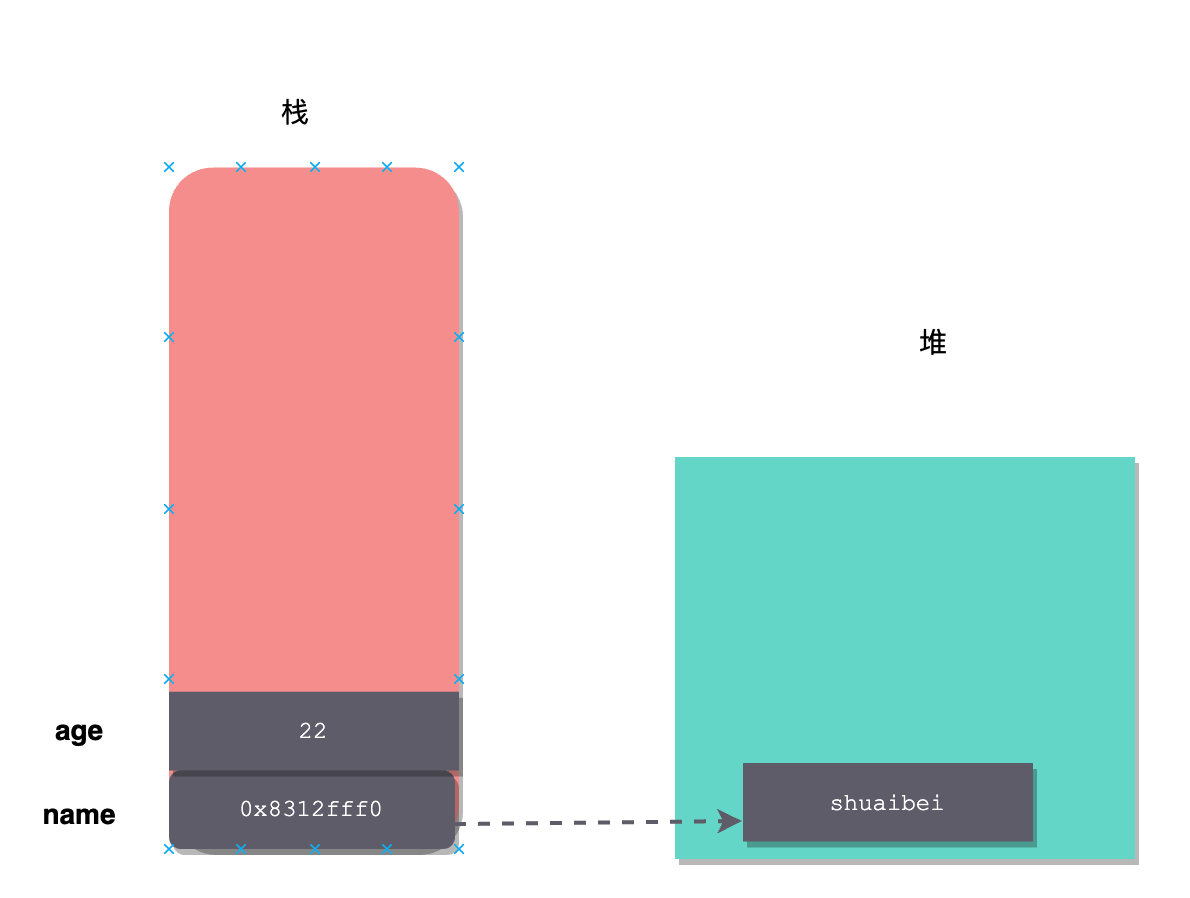
就拿 Java 来说吧,基本类型(int、double、long这种)是直接将存储在栈上的,而引用类型(类)则是值存储在堆上,栈上只存储一个对对象的引用。
举个栗子:
int age = 22;
String name = new String("shuaibei");
这两个变量存储图如下:
如果,我们分别对age、name变量赋值,会发生什么呢?
age = 18;
name = new String("xiaobei");
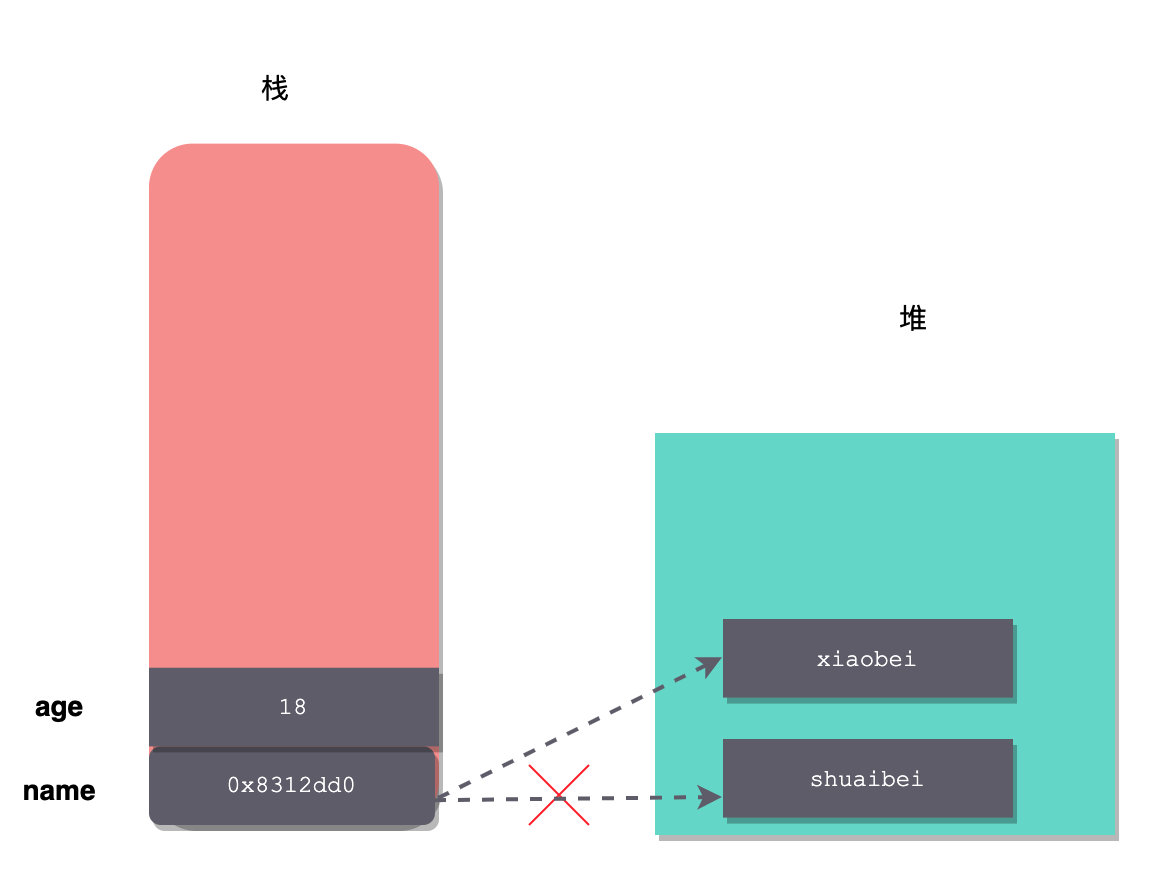
age 仅仅是将栈上的值修改为 18,而 name 由于是 String 引用类型,所以会重新创建一个 String 对象,并且修改 name,让其指向新的堆对象。(细心的话,你会发现,图中 name 执行的地址我做了修改)
然后,之前那个对象如果没有其它变量引用的话,就会被垃圾回收器回收掉。这里也要注意一点,我创建 String 的时候,使用的是 new,如果直接采用字符串赋值,比如:
String name = "shuaibei"
那么是会放到 JVM 的常量池去,不会被回收掉,这是字符串两种创建对象的区别,不过这里我们不关注。Java 中引用这东西,和 C/C++ 的指针就是一模一样的嘛,只不过 Java 做了语义层包装和一些限制,让你觉得这是一个引用,实际上就是指针。
函数调用栈
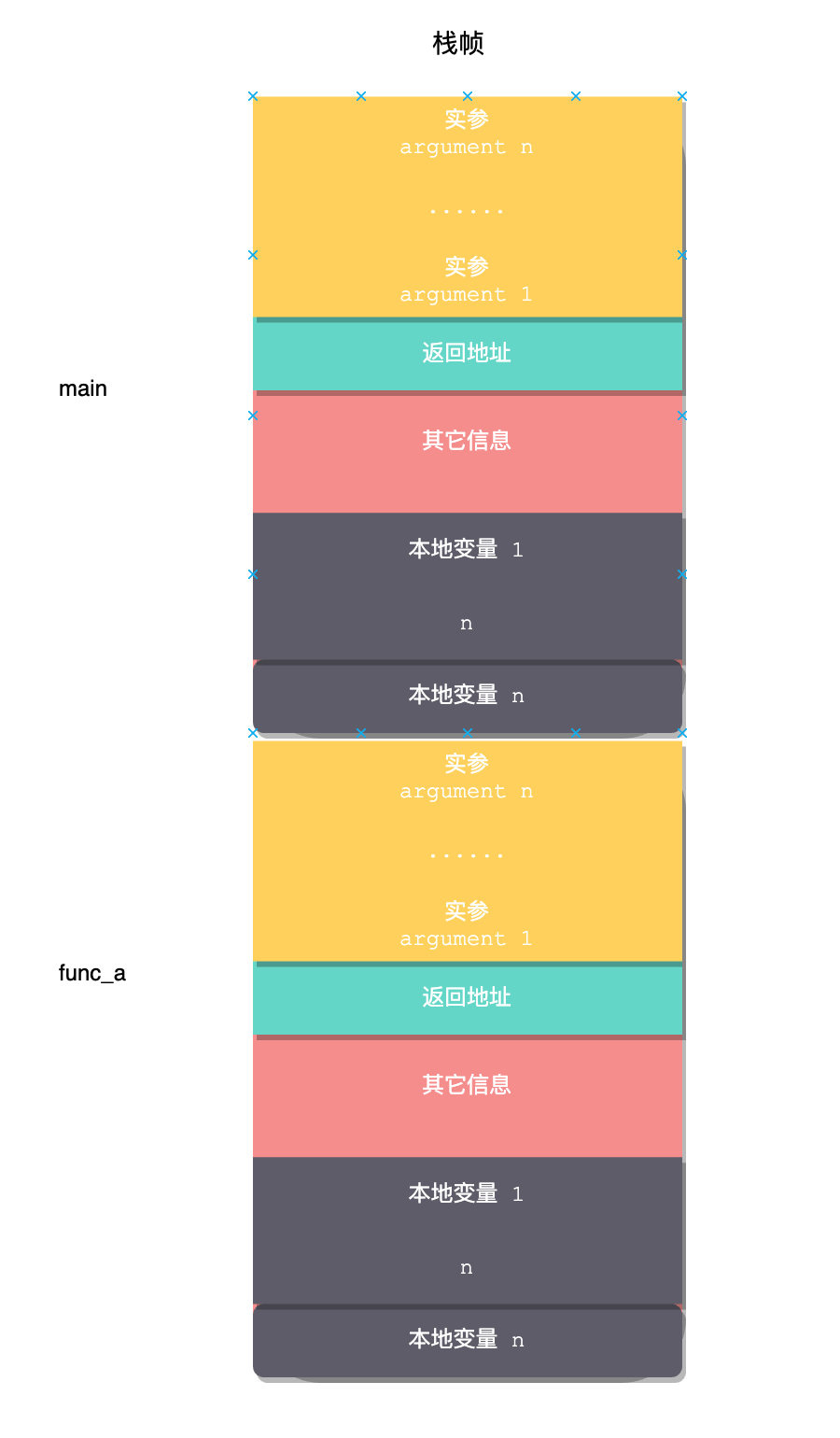
一个函数需要在内存上存储哪些信息呢?参数、局部变量,理论上这两个就够了,但是当多个函数相互调用的时候,就还需要机制来保证它们顺利的返回和恢复主调函数的栈结构信息。
那这部分就包括返回地址、ebp寄存器(基址指针寄存器,指向当前堆栈底部) 以及其它需要保存的寄存器。所以一个完整的函数调用栈大概长得像下面这个样子:

那,多个函数调用的时候呢?
简单来说就是叠罗汉,这是两个函数栈:
面这段代码在main函数内调用了func_a函数
int func_a(int a, int *b) {
a = 5;
*b = 5;
};
int main(void) {
int a = 10;
int b = 10;
func_a(a, &b);
printf("a=%d, b=%d\n", a, b);
return 0;
}
// 输出
a=10, b=5
那么func_a(a, &b) 这个过程,在函数调用栈上究竟是怎么样的呢?
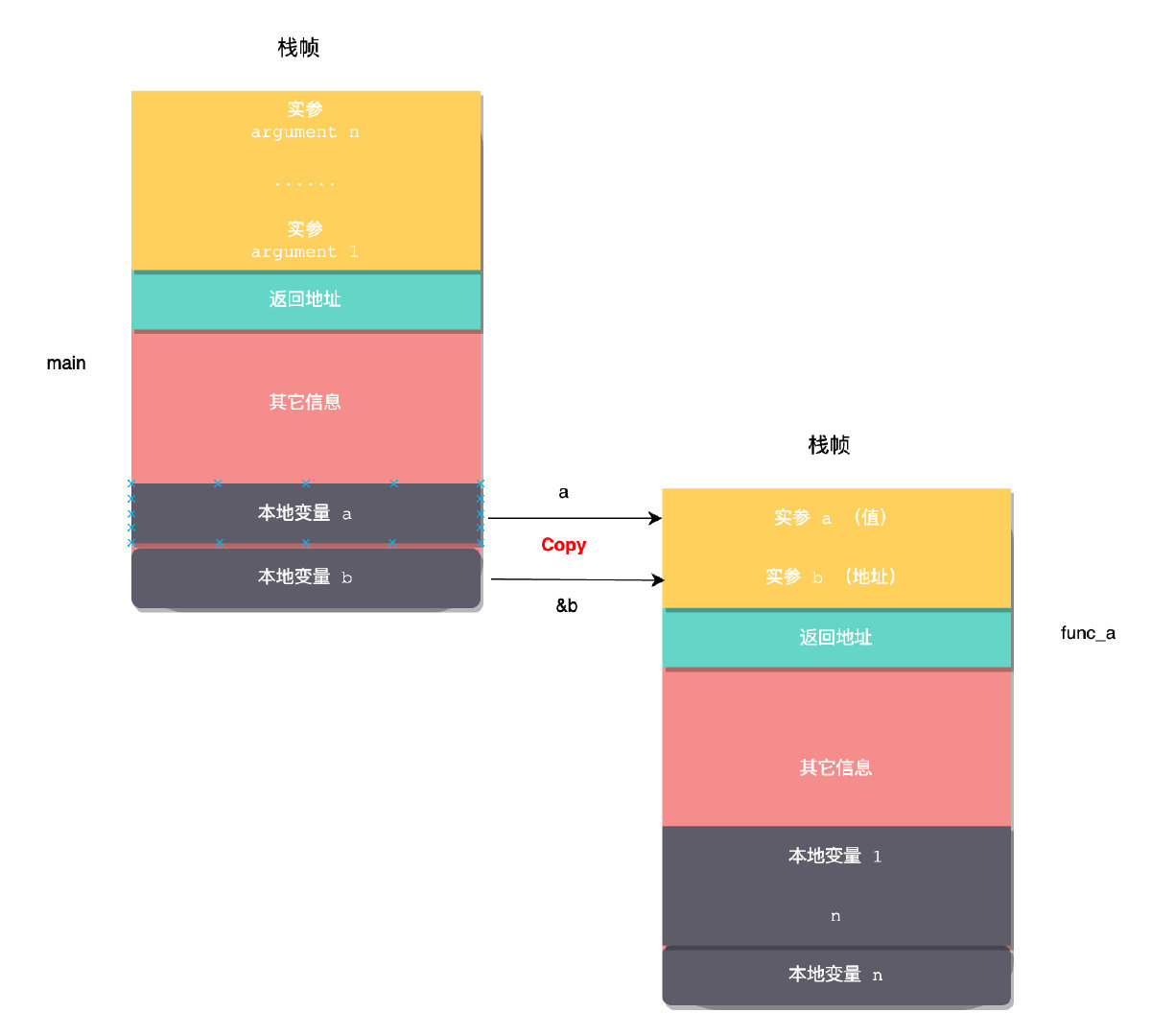
就像上图所示,编译器会生成一段函数调用代码。将 main 函数内变量 a 的值拷贝到 func_a 函数参数 a 位置。将变量 b的地址,拷贝到 func_a 函数参数 b 的位置。记住这张图,这是函数参数传递的本质,没有其它方式,just copy!copy 意味着是副本,也就是在子函数的参数永远是主调函数内的副本。决定是值传递还是所谓的引用传递,在于你 copy 的到底是一个值,还是一个引用(的值。
标签:rsi,int,c++,rbp,引用,movq,指针 From: https://www.cnblogs.com/sfbslover/p/18407357