在光照条件不佳下捕获的图像可能同时包含过曝和欠曝。目前的方法主要集中在调整图像亮度上,这可能会加剧欠曝区域的色调失真,并且无法恢复过曝区域的准确颜色。论文提出通过学习估计和校正这种色调偏移,来增强既有过曝又有欠曝的图像。先通过基于
UNet的网络推导输入图像的增亮和变暗版本的色彩特征图,然后使用伪正常特征生成器生成伪正常色彩特征图。接着,通过论文提出的COlor Shift Estimation(COSE) 模块来估计推导的增亮(或变暗)色彩特征图与伪正常色彩特征图之间的色调偏移,分别校正过曝和欠曝区域的估计色调偏移。最后,使用提出的COlor MOdulation(COMO) 模块来调制过曝和欠曝区域中分别校正后的颜色,以生成增强图像。来源:晓飞的算法工程笔记 公众号
论文: Color Shift Estimation-and-Correction for Image Enhancement

Introduction
现实世界的场景通常涉及广泛的照明条件,这对摄影构成了重大挑战。尽管相机具有自动曝光模式来根据场景亮度确定“理想”的曝光设置,但是在整个图像范围内均匀调整曝光仍可能导致区域过度明亮和过度昏暗,这种欠曝和过曝的区域可能表现出明显的色调失真。欠曝区域相对较高的噪音水平会改变数据分布,导致色调偏移,而过曝区域则会失去原始的色彩。因此,增强这类图像通常涉及到亮度调整和色调偏移校正。
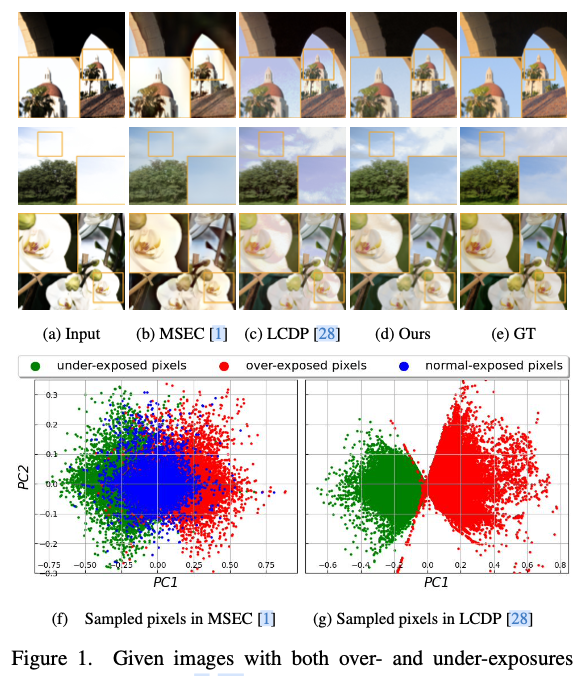
近年来,已经进行了许多努力来增强不正确曝光的图像。这些方法可以大致分为两类。
- 第一类专注于增强过曝或欠曝的图像。一些方法提出学习曝光不变的表示空间,其中不同的曝光水平可以映射到一个标准化和不变的表示中。其他方法则提出将频率信息与空间信息整合,这有助于模拟图像固有的结构特征,从而增强图像的亮度和结构失真。然而,上述方法通常假设过度或欠曝发生在整个图像上,对于同时存在过度曝光和欠曝光的图像(例如,图
1(b)),它们效果不佳。 - 第二类工作旨在增强同时存在过度曝光和欠曝光的图像,利用局部颜色分布作为先验来引导增强过程。然而,尽管设计了金字塔式的局部颜色分布先验,仍然倾向于产生在大面积均质区域中出现显著色彩偏移的结果(例如,图
1(c))。
本文旨在校正同时存在过度曝光和欠曝光的图像的亮度和色彩失真问题。为了解决这个问题,首先在图1(f)和1(g)中展示了从两个相关数据集(MSEC和LCDP)中随机抽样的像素的PCA结果。MSEC数据集中每个场景包含五张不同曝光值(EV)的输入图像,而LCDP数据集中每个场景只有一张同时包含过度曝光和欠曝光的输入图像。从这个初步研究中,可以得出了两个观察结果。
- 在这两个数据集中,欠曝光像素(绿点)倾向于与过度曝光像素(红点)有相反的分布偏移。
- 与
MSEC数据集包含了0 EV输入图像作为曝光标准化过程的参考图像不同,LCDP的图像没有这样的“正常曝光”像素。
第一个观察结果启发我们考虑估计和校正这样的色彩偏移,而第二个观察结果则启发我们创建伪正常曝光特征图,作为色彩偏移估计和矫正的参考。
为此,论文提出了一种新方法,联合调整图像亮度并校正色调失真。首先使用基于UNet的网络,从输入图像的增亮和变暗版本中提取过度曝光和欠曝光区域的色彩特征图。接着,伪正常特征生成器基于这些派生的色彩特征图创建伪正常色彩特征图。随后,论文提出了一种新的颜色偏移估计(COSE)模块,分别估计和校正派生的增亮(或变暗)色彩特征图与创建的伪正常色彩特征图之间的色彩偏移,通过在颜色特征域中扩展可变形卷积来实现COSE模块。进一步,论文提出了一种新的颜色调制(COMO)模块,通过定制的交叉注意力机制,在过度曝光和欠曝光区域的分别校正的色彩上进行调制,以生成增强图像。通过在输入图像和估计的变暗/增亮色彩偏移上执行定制的交叉注意力机制来实现COMO模块,图1(d)显示了我们的方法能够生成视觉上令人愉悦的图像。
论文的主要贡献可以总结如下:
-
提出了一种新颖的神经网络方法,通过建模色彩分布的变化来增强同时存在过度曝光和欠曝光的图像。
-
提出了一种新颖的神经网络,包括两个新模块:一是用于分别估计和校正过度曝光和欠曝光区域中色彩的新颖颜色偏移估计(
COSE)模块,二是用于调制校正后的颜色以生成增强图像的新颖颜色调制(COMO)模块。 -
广泛的实验证明,论文的网络具有轻量化的特点,并且在流行的基准测试中表现优于现有的图像增强方法。
Proposed Method
论文的方法受到两点观察的启发。首先,与欠曝光像素相比,过曝光像素倾向于具有反向分布偏移,这表明有必要分别捕捉和修正这样的色彩偏移。其次,由于绝大多数(如果不是全部)像素都受到过曝光或欠曝光的影响,因此有必要创建伪正常曝光信息,以指导过曝光或欠曝光像素色彩偏移的估计。基于这两点观察,我们提出了一种新的网络,其中包括两个新模块:新的色彩偏移估计(COSE)模块和新的色彩调制(COMO)模块,用于增强具有过曝光或欠曝光的图像。
Network Overview
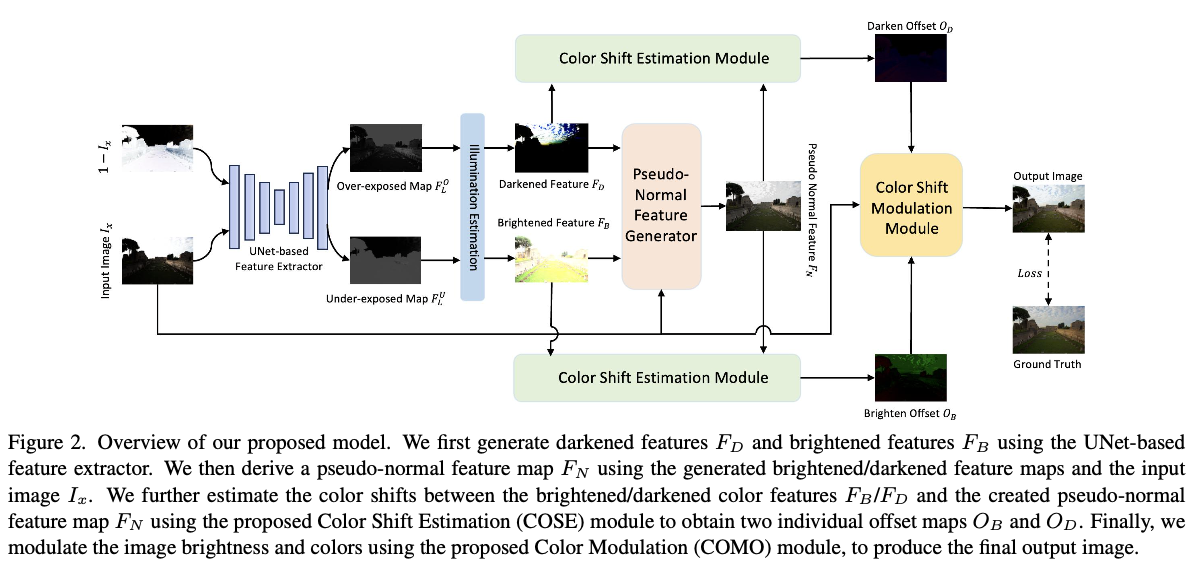
给定一个具有过曝光和欠曝光的输入图像 \(I_x\in \mathcal{R}^{3\times H\times W}\),旨在生成一个增强后的图像 \(I_y\in \mathcal{R}^{3\times H\times W}\),具有校正的图像亮度以及恢复的图像细节和颜色,模型结构如图2所示。给定输入图像 \(I_x\),首先通过计算其反向版本 \(\hat{I}_x=1-I_x\),然后将两者输入基于UNet的网络,以提取两个光照图 \(F_L^U\in \mathcal{R}^{1\times H\times W}\) 和 \(F_L^O\in \mathcal{R}^{1\times H\times W}\),这两个光照图(即 \(F_L^U\) 和 \(F_L^O\))分别表示受欠曝光和过曝光影响的区域。接下来,计算暗化特征图 \(F_D\)和增亮特征图 \(F_B\),具体如下:
其中, \(f(\cdot)\) 表示基于UNet的特征提取器。根据增亮和暗化的特征图 \(F_B, F_D \in \mathbb{R}^{3 \times H \times W}\) 来建模色彩偏移。
给定 \(F_B\) 和 \(F_D\) ,首先使用伪正常特征生成器将它们与输入图像 \(I_x\) 融合,生成伪正常特征图 \(F_N\) ,具体如下:
\[\begin{align} F_N = g(F_B, F_D, I_x), \end{align} \] 其中, \(g(\cdot)\) 表示伪正常曝光生成器。然后,将 \(F_N\) 可以作为参考,分别通过两个COSE模块引导估计 \(F_B\) 和 \(F_N\) 以及 \(F_D\) 和 \(F_N\) 之间的色彩偏移。这两个COSE模块产生的暗化偏移 \(O_D\) 和增亮偏移 \(O_B\) ,针对输入图像 \(I_x\) 模拟了亮度和色彩的变化。因此, \(O_D\) 、 \(O_B\) 和 \(I_x\) 被送入提出的COMO模块中,用于调整图像的亮度并纠正色彩偏移,生成最终的图像 \(I_y\) 。
Color Shift Estimation (COSE) Module
与亮度调整不同,色彩偏移校正更具挑战性,因为它本质上要求网络在RGB色彩空间中建模像素方向,而不是像素强度的幅度。尽管有一些工作使用余弦相似性正则化来帮助在训练过程中保持图像的颜色,但这样的策略通常在大面积低曝光或过曝区域失败,因为这些区域中的小值或高值像素预期具有不同的颜色。
论文提出基于可变形卷积技术的COSE模块来解决这一问题。可变形卷积(DConv)通过引入空间偏移 \(\Delta p_n\) 扩展了普通卷积,能够自适应地在任何 \(N\times N\) 像素的任意位置执行卷积,其中 \(N\times N\) 表示卷积核的大小。调制项 \(\Delta m_n\) 被提出来为不同的卷积核位置分配不同的权重,使卷积运算符聚焦于重要的像素。虽然可变形卷积可以预测相对于基础的偏移量,从而捕捉颜色分布的变化,但由于之前的方法只在像素空间域应用了可变形卷积,论文提出将可变形卷积扩展到空间域和色彩空间中,以联合建模亮度变化和色彩偏移。
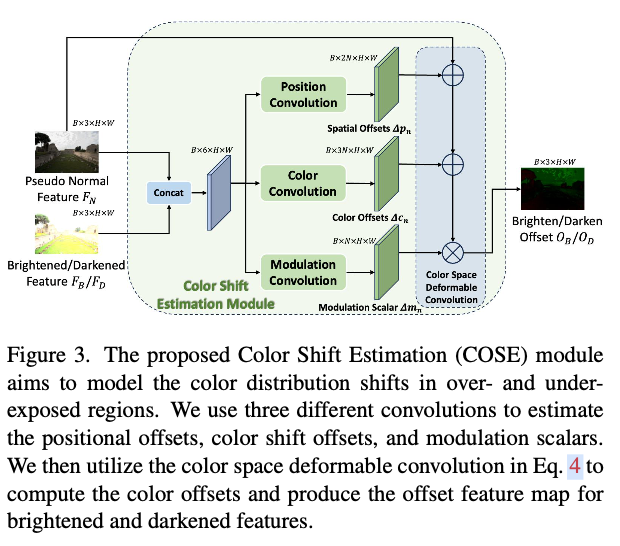
如图3所示,COSE模块首先沿通道维度连接伪正常特征图 \(F_N\) 和增亮/暗化特征图 \(F_B\) / \(F_D\),然后使用三个独立的 \(3\times 3\) 卷积来提取位置偏移 \(\Delta p_n\in \mathcal{R}^{B\times 2N\times H\times W}\) ,颜色偏移 \(\Delta c_n\in \mathcal{R}^{B\times 3N\times H\times W}\) 和调制项 \(\Delta m_n\in \mathcal{R}^{B\times N\times H\times W}\) 。位置偏移 \(\Delta p_n\) 和调制项 \(\Delta m_n\) 在空间域内执行,以聚合卷积操作中变形不规则感受野的空间上下文信息。此外,引入了颜色偏移 \(\Delta c_n\) ,用于表示每个通道在每个卷积核位置上的颜色偏移。学习到的颜色偏移 \(\Delta c_n\) 被设计为具有 \(3N\) 个通道,用于模拟具有3个通道的输入sRGB图像的颜色偏移。
可变形卷积在空间域和色彩空间中的计算可以写成:
\[\begin{align} y = \sum_{p_n\in \mathcal{R}} (w_n\cdot x(p_0 + p_n + \Delta p_n) + \Delta c_n) \cdot \Delta m_n,\label{eq:cdc} \end{align} \]其中,\(x\) 表示卷积操作的输入特征,而 \(p_0\) , \(p_n\) 和 \(\Delta p_n\) 是表示空间位置的二维变量。\(y\) (或 \(y(p_0)\) )表示输入图像中每个像素 \(p_0\) 的色彩空间可变形卷积的输出。集合 \(\mathcal{R} = \{(-1, -1), (-1, 0), \dots, (1, 1)\}\) 表示常规 \(3\times 3\) 卷积核的网格。 \(n\) 是 \(\mathcal{R}\) 中元素的枚举器,指示第 \(n\) 个位置, \(N\) 是 \(\mathcal{R}\) 的长度(对于常规 \(3\times 3\) 卷积核, \(N=9\) )。由于位移 \(\Delta p_n\) 在实践中可能具有小数,采用双线性插值进行计算,这与空间可变形卷积相一致。
Color Modulation (COMO) Module
COMO模块用于调节输入图像的亮度和颜色,生成最终的输出图像 \(I_y\) ,基于学习到的亮化特征 \(F_B\) 和变暗特征 \(F_D\) 之间的偏移量 \(O_B\) / \(O_D\) ,以及伪正常特征 \(F_N\) 。由于在生成具有和谐颜色的校正图像时聚合全局信息至关重要,论文从非局部上下文建模中汲取灵感,并通过将self-affinity计算扩展为cross-affinity计算来制定COMO模块,以便COMO能够通过查询 \(O_B\) 和 \(O_D\) 来增强输入图像。
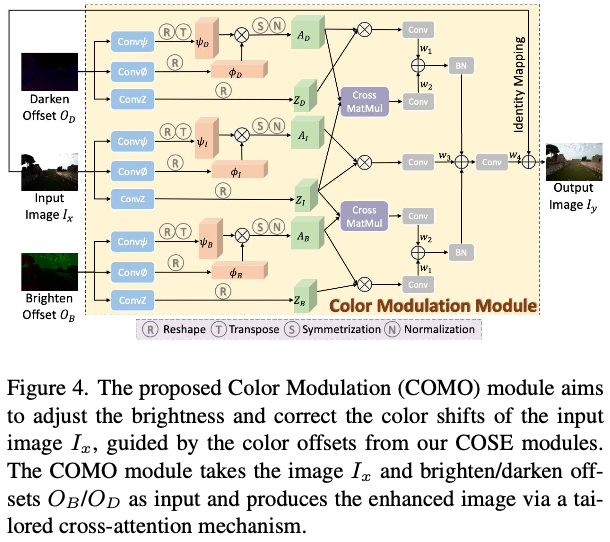
如图4所示,为处理输入图像 \(I_x\) 、变暗偏移量 \(O_D\) 和亮化偏移量 \(O_B\) 分别分配了三个分支,每个分支包含三个 \(1\times 1\) 卷积层(分别表示为 \(Conv\psi\) 、 \(Conv\phi\) 和 \(ConvZ\) )。然后,在每个分支中计算self-affinity矩阵 \(A_i\) ,如下所示:
其中, \(\otimes\) 表示矩阵乘法, \(\psi_i\) 和 \(\phi_i\) 分别是由 \(Conv\psi\) 和 \(Conv\phi\) 得到的特征图。然后, \(A_i\) 被对称化并归一化,以确保存在实特征值并稳定反向传播。 \(A_i\) 的每一行用作空间注意力图,而 \(Z_i\) (通过 \(ConvZ\) 获得)用作注意力图的权重。接下来,通过矩阵乘法建模 \(I_x\) 与 \(O_B\) / \(O_D\) 之间的相关性,并将它们与self-affinity特征相加,如下所示:
其中, \(j \in \{B, D\}\) 是亮化或变暗分支中的亲和矩阵 \(A_j\) 和特征图 \(Z_j\) 的索引。 \(w_1\) 和 \(w_2\) 是由 \(1\times 1\) 卷积生成的权重矩阵。在公式6中,第一项是为了发现由COSE学习到的 \(O_B\) 和 \(O_D\) 中显著的颜色偏移区域,而第二项旨在利用输入 \(Z_I\) 的学习权重来关注 \(O_B\) 和 \(O_D\) 的注意力图,以了解输入的显著区域中的偏移情况。
最后,将 \(f_B\) 、 \(f_D\) 和输入图像 \(I_x\) 结合起来,作为指导输入图像的探索的颜色偏移,生成最终的结果 \(I_y\) ,如下所示:
\[\begin{align} I_y = w_4(BN(f_B) + BN(f_D) + w_3A_I\otimes Z_I) + I_x, \end{align} \]其中, \(BN(\cdot)\) 表示批量归一化, \(w_3\) 、 \(w_4\) 是由 \(1\times 1\) 卷积生成的权重矩阵。
Loss Function
使用两个损失函数 \(\mathcal{L}_{pesudo}\) 和 \(\mathcal{L}_{output}\) 来训练。由于需要生成一个伪正常的特征图来帮助识别颜色偏移,使用 \(\mathcal{L}_{pesudo}\) 来为生成过程提供中间监督。
\[\begin{align} \mathcal{L}_{pesudo} = ||F_N - GT||_1. \end{align} \] \(\mathcal{L}_{output}\) 包含四个项,用于监督网络生成增强图像,即 \(L1\) 损失,余弦相似度 \(\mathcal{L}_{cos}\) ,结构相似性(SSIM)损失 \(\mathcal{L}_{ssim}\) 和VGG损失 \(\mathcal{L}_{vgg}\) 。 \(\mathcal{L}_{output}\) 可以表达为:
其中, \(\lambda_1\) 、 \(\lambda_2\) 、 \(\lambda_3\) 和 \(\lambda_4\) 是四个平衡超参数。整体损失函数为:
\[\begin{align} \mathcal{L} = \lambda_p \mathcal{L}_{pesudo} + \lambda_o \mathcal{L}_{output}, \end{align} \]其中, \(\lambda_p\) 和 \(\lambda_o\) 是两个平衡超参数。
Experiments
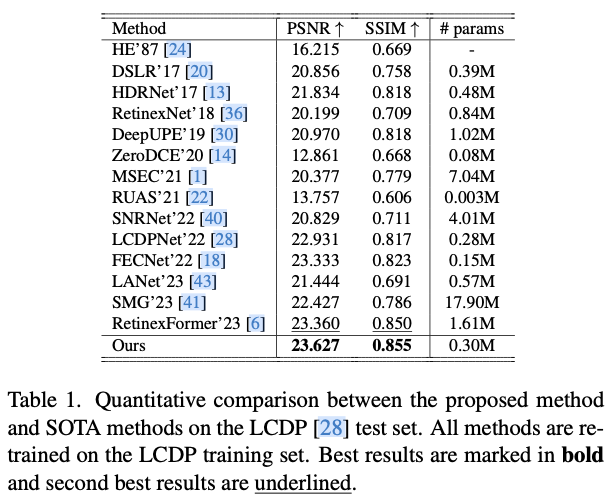
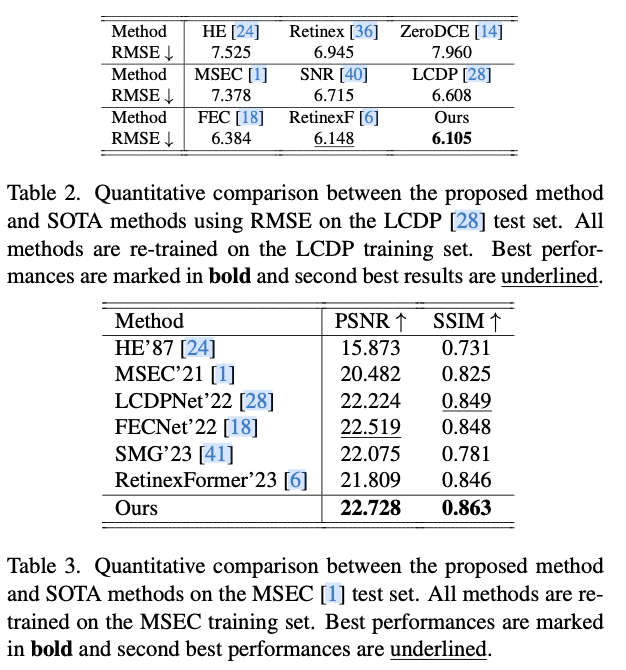

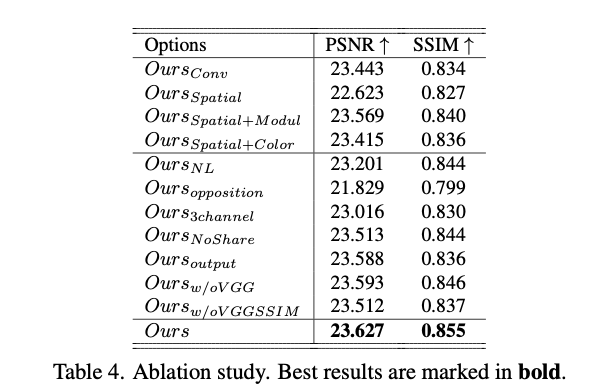


如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
