提取PPG特征之——whisper库的使用(2.1)
1 安装对应的包
-
方法一(自用):
直接pip即可:
pip install openai-whisper成功后如下图所示
-
方法二:
当时用了他这个方法环境直接崩了,已老实
conda install -c conda-forge ffmpeg conda install -c conda-forge poetry poetry init poetry add openai-whisper
2 运行官方demo测试:
1 import whisper
2
3 model = whisper.load_model("base")
4
5 # load audio and pad/trim it to fit 30 seconds
6 audio = whisper.load_audio("audio.mp3")
7 audio = whisper.pad_or_trim(audio)
8
9 # make log-Mel spectrogram and move to the same device as the model
10 mel = whisper.log_mel_spectrogram(audio).to(model.device)
11
12 # detect the spoken language
13 _, probs = model.detect_language(mel)
14 print(f"Detected language: {max(probs, key=probs.get)}")
15
16 # decode the audio
17 options = whisper.DecodingOptions()
18 result = whisper.decode(model, mel, options)
19
20 # print the recognized text
21 print(result.text)
3 歌词信息提取部分learning
-
可以从官方的官方的调用思路中学习,我们调用的时候也可以参照这个demo来稍作修改
-
如何通过whisper来提取PPG特征【Phoneme Posteriorgram 即音素后验概率图】,这里的后验概率特征指的就是歌词的信息特征,我们这里2.1先把歌词信息提取出来
步骤:
-
导入对应依赖库
-
主要是导入
whisper(主要库)和torch(用来使用gpu加速的)
-
-
导入所选模型
模型可选信息如下图所示:

-
size里面既是大小,也是对应可以加载的模型名 -
各位可以根据自己的
VRAM显存大小和对应的速度【他这里多少倍应该的对照最大的那个模型来衡量速度的】来选择 -
第一次因为本地没有模型,会自动下载,下载不了了都是网络问题,自行解决,救不了:

-
-
输入音频路径及其余可选信息
可选信息:
-
language:部分常见语言代码如下表所示:
语言 代码 英语 en 中文 zh 德语 de 西班牙语 es 法语 fr 日语 ja 韩语 ko 意大利语 it 葡萄牙语 pt 荷兰语 nl 俄语 ru 土耳其语 tr 波兰语 pl 越南语 vi 瑞典语 sv 印地语 hi 泰语 th 乌克兰语 uk 希腊语 el 匈牙利语 hu 阿拉伯语 ar
-
-
根据不同情况进行输出
代码实现:
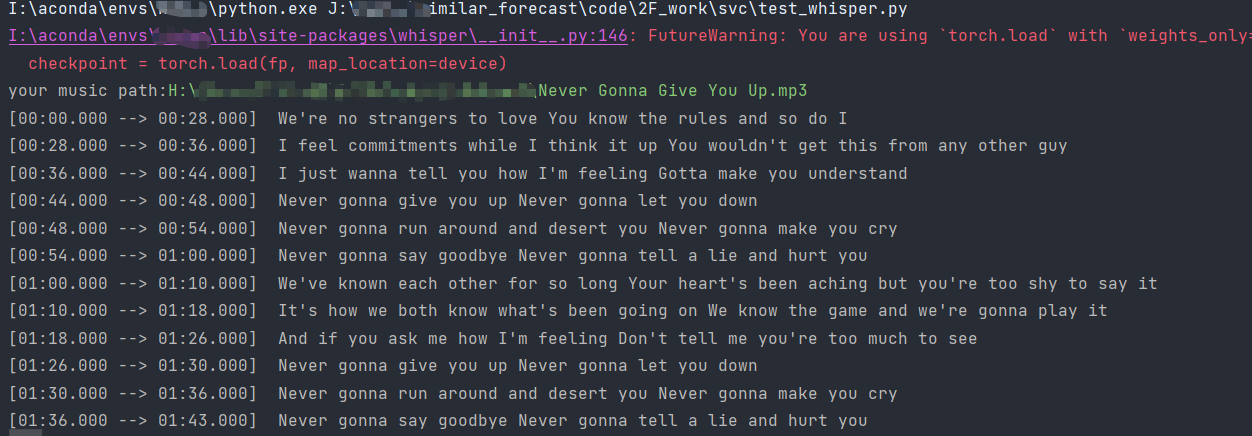
1 import whisper#导入依赖包 2 3 model = whisper.load_model('small')#选择模型 4 result = model.transcribe(audio=input("your music path:"), language='en', verbose=True) 5 print(result)#输出结果 6 -
结果【我这里的歌是Never Gonna Give You Up.mp3】:
-
解释:
其实蛮简单的,如果只需要获取歌词信息的话,4行就能完成了
-
load_model(name: str, device: Union[str, device, None] = None, download_root: Optional[str] = None, in_memory: bool = False) -> Whisper函数:参数解释:
-
name:对应的是上文中所选模型的名字,你选择哪一种大小的模型就在这个导入中体现,tiny、small之类的,这里也能通过路径来确定你的模型,但一般用不上-
probe the "name" element(进阶深入理解):
在官方构造这个函数中,写到了:
one of the official model names listed by
whisper.available_models(),or path to a model checkpoint containing the model dimensions and the model state_dict.从中我们可以使用
whisper.available_models()来查看支持的模型名称print(whisper.available_models()),且这个name还可以是本地的模型尺度(如上面的small)的路径['tiny.en', 'tiny', 'base.en', 'base', 'small.en', 'small', 'medium.en', 'medium', 'large-v1', 'large-v2', 'large-v3', 'large']
-
-
(可选)
device:模型运行时的设备,这里默认不选即可,系统会自动选择-
probe the "devic" element:
the PyTorch device to put the model into
为什么说可以默认不选择,看一下函数。因为官方已经帮我们选好了,自动帮我们执行了我们平常调用
torch进行GPU处理时的设备选择:if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
-
-
其他元素:
download_root:模型下载的路径,不填就是默认位置。我的建议是不懂这个的话最好默认就好了,不然可能后续调用有问题,了解一下即可
-
-
def transcribe(model: Whisper, audio: Union[str, ndarray, Tensor],*)这个函数的参数太多了,我挑选几个平时可能会用到的讲解:-
model:模型的调用示例,传入的是一个Whisper类,就是上文我们load_model完的modle变量 -
audio:音频的路径或者是音频的波形图(即音频的数组化形式)The path to the audio file to open, or the audio waveform
-
(可选)
language:虽然没在函数中列出来,但也是重要的参数,选择对应的语言,默认为"en"--英语,可以根据需要自行选择 -
其他参数:
-
(可选)
verbose:是否在控制台显示正在解码的文本。如果为 True,则显示所有详细信息;如果为 False,则显示最少的详细信息;如果为 None,则不显示任何信息。【建议显示】Whether to display the text being decoded to the console. If True, displays all the details, If False, displays minimal details. If None, does not display anything
-
(可选)
initial_prompt:对第一个窗口的提示词,方便模型区分一些专有名词什么的Optional text to provide as a prompt for the first window. This can be used to provide, or "prompt-engineer" a context for transcription, e.g. custom vocabularies or proper nouns to make it more likely to predict those word correctly.
-
其他的更深入就是某个指标达不到预定值的操作,较少用,不深入了,我也不懂
-
-
-
封装一下,更规范一点:
1 import whisper 2 from whisper.utils import get_writer 3 4 model = whisper.load_model('small')#可以放在里面,这里方便调用 5 6 def get_transcribe(audio: str, language: str = 'en'): 7 return model.transcribe(audio=audio, language=language, verbose=True) 8 9 def save_file(results, format='tsv'): 10 writer = get_writer(format, 'output/') 11 writer(results, f'transcribe.{format}') 12 13 def get_language(): 14 """ 15 构造了个语言选择输入,如果是默认就回车就好了,会设置为英文 16 :return: 17 """ 18 language_input = input("input the song language[default->enter]\n" 19 "(英语->en、中文->zh、德语->de、西班牙语->es、法语->fr、日语->ja、.....):") 20 default = 'en' if not language_input else language_input #如果language_input为空 则语言为英文,否则是输入的语言 21 print(f"model language is {default}") 22 return default 23 24 25 if __name__ == "__main__": 26 result = get_transcribe(audio=input("please input your music path:"), language= get_language()) 27 print(result.get('text', '')) -
4 保存歌词信息
-
调用方法:
-
def get_writer(output_format: str, output_dir: str) -> Callable[[dict, TextIO, dict], None]:-
explain:
output_format:输出的格式,str类型,可选形式如下:writers = {
"txt": WriteTXT,
"vtt": WriteVTT,
"srt": WriteSRT,
"tsv": WriteTSV,
"json": WriteJSON,
}-
probe in
output_format:if output_format == "all": all_writers = [writer(output_dir) for writer in writers.values()]
这个选项还可以是all,直接全部格式都生成一遍
output_dir:输出文件夹 -
-
调用方式:
1 def save_file(results, format='tsv'): 2 writer = get_writer(format, 'output/') 3 writer(results, f'transcribe.{format}') #直接调用就好,第一个参数是前面我们获取的歌词信息result,后面跟的是保存的文件名字
-
5 all code:
import whisper
from whisper.utils import get_writer
model = whisper.load_model('small')
def get_transcribe(audio: str, language: str = 'en'):
return model.transcribe(audio=audio, language=language, verbose=True)
def save_file(results, format='tsv'):
writer = get_writer(format, 'output/')
writer(results, f'transcribe.{format}')
def get_language():
"""
构造了个语言选择输入,如果是默认就回车就好了,会设置为英文
:return:
"""
language_input = input("input the song language[default->enter]\n"
"(英语->en、中文->zh、德语->de、西班牙语->es、法语->fr、日语->ja、.....):")
default = 'en' if not language_input else language_input #如果language_input为空 则语言为英文,否则是输入的语言
print(f"model language is {default}")
return default
if __name__ == "__main__":
result = get_transcribe(audio=input("please input your music path:"), language= get_language())
print('-'*50)
print(result.get('text', ''))
save_file(result)
save_file(result, 'txt')
save_file(result, 'srt')