雪花算法
1.1 概述
雪花算法是twitter开源的一个分布式id的生成算法。雪花id,是分布式计算中使用的唯一标识符的一种形式。该格式由twitter创建。人们普遍认为,每片雪花都有唯一的结构,因此他们取了“雪花ID”这个名字。
1.2 什么是雪花id
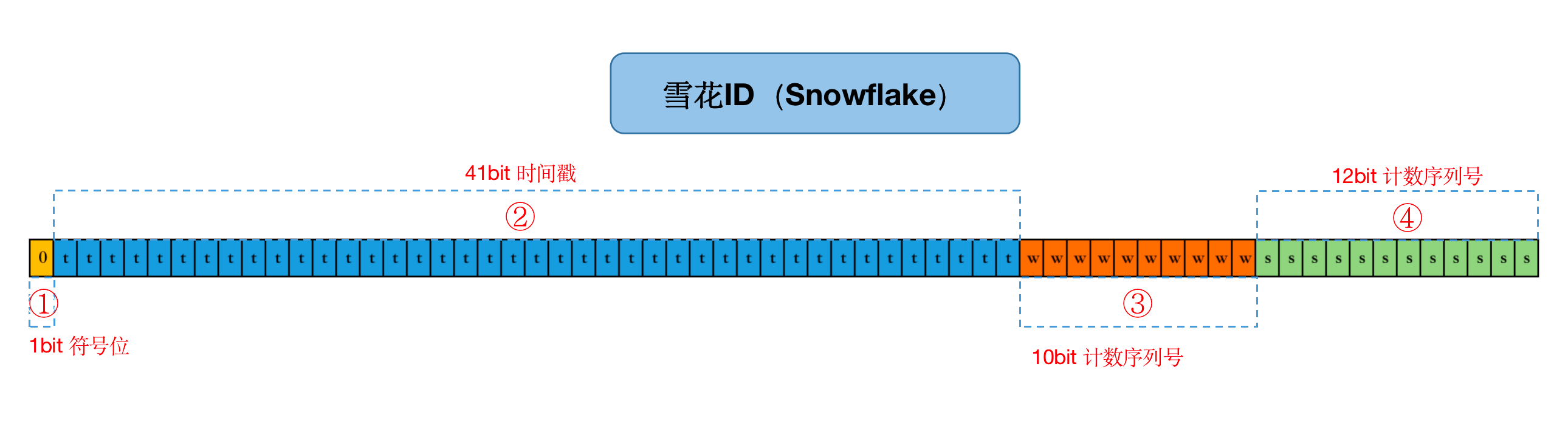
雪花id是有一种分布式id算法生成的,他的设计目标是在分布式系统中生成唯一id,具有趋势递增,高性能,可拓展的特点,它可以分为四个部分。
- 1 符号位:符号位,也就是最高位,始终是0,没有任何意义,因为要是唯一计算机二进制补码中就是负数,0才是正数。
- 2 时间戳:占用41位,记录生成ID的时间戳,精确到毫秒级。
- 3 机器标识:占用10位,用于标识不同的机器。
- 4 计数序列号:占用12位,用于解决同一毫秒内生成多个ID的冲突。
1.3 python实现
import time
class Snowflake:
def __init__(self, machine_id):
# 当前的唯一机器码
self.machine_id = machine_id
# 用于初始和重置序列号
self.sequence = 0
# 不存在的时间戳,用于第一次生成id
self.last_timestamp = -1
def _get_timestamp(self):
# 获取当前时间戳(毫秒)
return int(time.time() * 1000)
# 等带下一毫秒
def _til_next_millis(self, last_timestamp):
timestamp = self._get_timestamp()
while timestamp <= last_timestamp:
timestamp = self._get_timestamp()
return timestamp
def generate_id(self):
timestamp = self._get_timestamp()
# 检测时钟是否回拨
if timestamp < self.last_timestamp:
raise Exception("Clock moved backwards. Refusing to generate ID.")
if timestamp == self.last_timestamp:
# 如果时间戳相同,序列号递增
self.sequence = (self.sequence + 1) & 4095
if self.sequence == 0:
timestamp = self._til_next_millis(self.last_timestamp)
else:
# 如果不相同,则重置序列号
self.sequence = 0
self.last_timestamp = timestamp
snowflake_id = ((timestamp - 1288834974657) << 22) | (self.machine_id << 12) | self.sequence
return snowflake_id
if __name__ == "__main__":
snowflake = Snowflake(machine_id=1)
for _ in range(10):
print(snowflake.generate_id())