文章目录
概要
本实例只针对简单的账密登录场景做处理,涉及登录方式切换、人机检测部分未作处理,后续会跟进处理。
整体架构流程
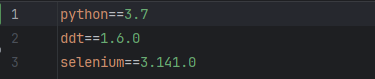
- 依赖环境
Python3.7
selenium 3.141.0
ddt 1.6.0
- 目录结构

目录说明
1. base: 公共基础方法,定位元素 2. business: 业务层,处理具体一件事情,如登录 3. case: 用例 4. config: 全局配置文件,主要配置项目 url 及页面元素定位信息 5. handle: 处理具体一件事情的某个步骤,比如输入用户名,输入验证码等 6. log: 日志文件夹 7. page: 定位具体页面的元素 8. report: 报告路径 9. screenCapture: 屏幕截图 10. util: 工具类方法,比如读取配置,获取验证码等
- 调用关系
case->business->handle->page
- 代码构建
1、创建projectConfig.ini项目配置文件
test/config/projectConfig.ini
[Project]
loginUrl = https://mail.163.com
timeout=5
username = username
password = password2、创建globalElConfig.ini全局元素配置文件
test/config/globalElConfig.ini
[Login]
Tips=xpath:/html/body/header/div[1]/ul[1]/li[1]/div/span[1]
search_iframe=xpath://iframe[starts-with(@id,"x-URS")]
search_iframe2=xpath://iframe[starts-with(@id,"getMarkedContacts")]
option=xpath:lbApp
username=xpath://input[@name="email"]
password=xpath://input[@name="password"]
login_btn=xpath://*[@id="dologin"]3、创建配置读取公共类
test/config/read_ini.py
# coding=utf-8
import configparser
class ReadIni(object):
def __init__(self, node, file_name, encoding='utf-8'):
self.node = node
self.encoding = encoding
self.cf = self.load_ini(file_name)
def load_ini(self, file_name):
cf = configparser.ConfigParser()
cf.read(file_name, encoding=self.encoding)
return cf
def get_value(self, key):
return self.cf.get(self.node, key)
4、创建Log日志类,记录执行日志、错误日志
test/log/user_log.py
import logging
import os
import datetime
class UserLog():
def __init__(self):
self.logger = logging.getLogger()
self.logger.setLevel(logging.INFO)
self.fileStream = logging.FileHandler(self.__get_log_name(),encoding='utf-8')
self.__init_logger_handle()
def __get_log_name(self):
log_path = os.path.join(os.path.dirname(
os.path.abspath(__file__)), "logs")
log_file = datetime.datetime.now().strftime("%Y-%m-%d")+".log"
return log_path+"/"+log_file
def __init_logger_handle(self):
formatter = logging.Formatter(
'%(asctime)s %(filename)s %(funcName)s %(lineno)s %(levelname)s --->%(message)s')
self.fileStream.setFormatter(formatter)
self.logger.addHandler(self.fileStream)
def close(self):
self.fileStream.close()
self.logger.removeHandler(self.fileStream)
def get_logger(self):
return self.logger
if __name__ == "__main__":
log = UserLog()
logger = log.get_logger()
logger.info("打一年工搬一年砖")
log.close()
5、创建元素查找公共类
test/base/find_element.py
# encoding=utf-8
from config.read_ini import ReadIni
import os
from selenium.webdriver.common.by import By
import selenium.webdriver.support.expected_conditions as EC
import selenium.webdriver.support.ui as ui
class FindElement(object):
def __init__(self, driver, node,
config=os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'config',
'globalElConfig.ini')):
self.driver = driver
self.read_ini = ReadIni(node, config)
self.read_project = ReadIni('Project',
os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'config',
'projectConfig.ini'))
self.config = config
def get_element(self, key):
timeout = self.read_project.get_value('timeout')
webDriverWait = ui.WebDriverWait(self.driver, int(timeout))
try:
by, value = self.get_locator(key)
if not by or not value:
print(f"Failed to get locator for key {key}")
return None
print(f"Finding element by {by} with value {value}")
if by == 'id':
return webDriverWait.until(EC.presence_of_element_located((By.ID, value)))
elif by == 'name':
return webDriverWait.until(EC.presence_of_element_located((By.NAME, value)))
elif by == 'classname':
return webDriverWait.until(EC.presence_of_element_located((By.CLASS_NAME, value)))
elif by == 'cssSelector':
return webDriverWait.until(EC.presence_of_element_located((By.CSS_SELECTOR, value)))
else:
return webDriverWait.until(EC.presence_of_element_located((By.XPATH, value)))
except Exception as e:
print(f"Exception occurred while finding element: {e}")
return None
def get_elements(self, key):
timeout = self.read_project.get_value('timeout')
webDriverWait = ui.WebDriverWait(self.driver, int(timeout))
try:
by, value = self.get_locator(key)
if not by or not value:
print(f"Failed to get locator for key {key}")
return None
print(f"Finding elements by {by} with value {value}")
if by == 'id':
return webDriverWait.until(EC.visibility_of_all_elements_located((By.ID, value)))
elif by == 'name':
return webDriverWait.until(EC.visibility_of_all_elements_located((By.NAME, value)))
elif by == 'classname':
return webDriverWait.until(EC.visibility_of_all_elements_located((By.CLASS_NAME, value)))
elif by == 'cssSelector':
return webDriverWait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, value)))
else:
return webDriverWait.until(EC.visibility_of_all_elements_located((By.XPATH, value)))
except Exception as e:
print(f"Exception occurred while finding elements: {e}")
return None
6、创建webdriver工具类
test/util/webdriver.py
import json
import sys
from selenium import webdriver
from selenium.webdriver import DesiredCapabilities
class myWebdriver(object):
@staticmethod
def get_driver():
chrome_options = webdriver.ChromeOptions() # 创建 Chrome 浏览器选项
chrome_options.add_experimental_option('w3c', False) # 设置 w3c 实验性选项为 False,确保浏览器兼容
caps = DesiredCapabilities.CHROME # 设置浏览器能力 (caps):
caps['loggingPrefs'] = {'performance': 'ALL'} # 设置了 loggingPrefs,以便收集所有性能相关的日志
chrome_options.add_argument('--disable-gpu') # 添加禁用 GPU 的选项
if 'linux' in sys.platform: # 根据操作系统设置无头模式
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(desired_capabilities=caps, options=chrome_options) # 创建 Chrome 浏览器驱动
driver.implicitly_wait(10) # 设置隐式等待时间:10s
driver.set_window_size(1936,
1056) if 'linux' in sys.platform else driver.maximize_window() # 最大化窗口在--headless模式下无效,导致linux截图太小,所以手动设置
return driver
@staticmethod
def save_performance_log(driver, filename):
logs = [json.loads(log['message'])['message'] for log in driver.get_log("performance")]
with open(filename, 'a') as f:
json.dump(logs, f, indent=4, ensure_ascii=False)7、创建页面page元素获取类,处理具体一件事情的某个步骤
test/page/login_page.py
# coding=utf-8
from base.find_element import FindElement
import os
class LoginPage(object):
# 获取globalElConfig.ini配置Login节点下配置
def __init__(self, driver):
self.fd = FindElement(driver, 'Login')
# 初始化iframe框架,默认嵌套一层
def get_iframe_element(self):
return self.fd.get_element("search_iframe")
# 多个iframe框架切换
def get_iframe2_element(self):
return self.fd.get_element("search_iframe2")
# 获取断言结果元素
def get_err_tips_elements(self):
return self.fd.get_elements("errTips")
# 获取账密登录按钮
def get_option_element(self):
return self.fd.get_element("option")
# 获取用户名元素
def get_username_element(self):
return self.fd.get_element("username")
# 获取密码元素
def get_password_element(self):
return self.fd.get_element("password")
# 获取登录按钮元素
def get_login_btn_element(self):
return self.fd.get_element("login_btn")
9、创建handle应用类,处理
test/handle/login_handle.py
from handle.handle import Handle
from page.login_page import LoginPage
class LoginHandle(Handle):
def __init__(self, driver):
super().__init__(driver)
self.login_p = LoginPage(driver)
# iframe框架调用
def into_iframe_work(self):
frame = self.login_p.get_iframe_element()
self.driver.switch_to.frame(frame)
def quit_iframe_work(self):
self.driver.switch_to.default_content()
# 输入用户名
def send_user_name(self, username):
username_element = self.login_p.get_username_element()
username_element.send_keys(username)
# 输入密码
def send_user_password(self, password):
password_element = self.login_p.get_password_element()
password_element.send_keys(password)
# 点击登录按钮
def click_login_btn(self):
self.login_p.get_login_btn_element().click()
# 截取断言文本
def get_tips(self):
tips = self.login_p.get_err_tips_elements()
if tips is None:
print('元素未找到!')
return None
if len(tips) > 1:
print('出现多条提示!')
tip = tips[-1].text
print(tip)
return tip
10、创建business业务类,处理具体一件事情
test/business/login_business.py
# coding=utf-8
from handle.login_handle import LoginHandle
class LoginBusiness(object):
def __init__(self, driver):
self.login_h = LoginHandle(driver)
def click_option_success(self, username, password):
self.login_h.into_iframe_work() # 进入iframe框架
self.login_h.send_user_name(username) # 输入用户名
self.login_h.send_user_password(password) # 输入密码
self.login_h.click_login_btn() # 点击登录按钮
self.login_h.quit_iframe_work() # 退出iframe框架,因为断言元素不在框架内
return self.login_h.get_tips() # 获取断言结果返回
11、创建TestCase类,初始化浏览器,利用ddt构建测试数据集,Unittest框架执行单元测试用例
test/case/login_case.py
# coding=utf-8
import os
import unittest
import datetime
import ddt
from log.user_log import UserLog
from business.login_business import LoginBusiness
from config.read_ini import ReadIni
from util.webdriver import myWebdriver
@ddt.ddt
class LoginCass(unittest.TestCase):
@classmethod
def setUpClass(cls): # 读取配置节点
cls.driver = myWebdriver.get_driver()
cls.log = UserLog()
cls.logger = cls.log.get_logger()
cls.readIni = ReadIni('Project',
os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'config',
'projectConfig.ini'))
cls.loginUrl = cls.readIni.get_value('loginUrl')
def setUp(self):
self.driver.get(self.loginUrl)
self.login_b = LoginBusiness(self.driver)
def tearDown(self):
for method_name, error in self._outcome.errors:
if error:
# case_name=self._testMethodName
self.logger.info(error)
case_name = str(method_name)[:str(method_name).find("(")]
file_path = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'screenCapture',
case_name + '.png')
self.driver.save_screenshot(file_path)
log_file = 'login_case_' + datetime.datetime.now().strftime("%Y-%m-%d") + ".log"
myWebdriver.save_performance_log(self.driver,
os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))),
'log', 'performancelog', log_file))
@classmethod
def tearDownClass(cls):
cls.driver.close()
cls.log.close()
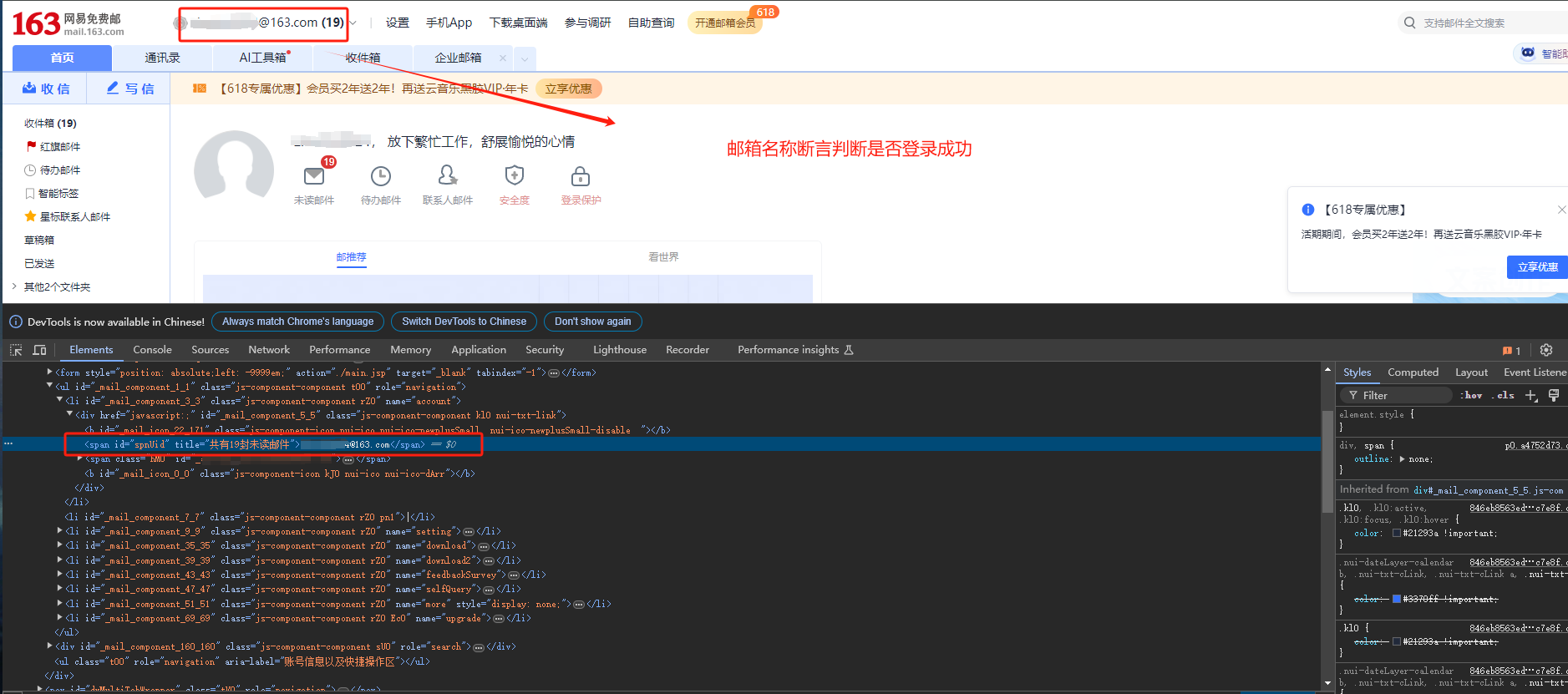
# 通过[email protected]用户名断言判断是否登录成功
@ddt.data(['username', 'password', '[email protected]'])
@ddt.unpack
def test_1_login_case(self, username, password, tips):
actual_tips = self.login_b.click_option_success(username, password)
self.assertEqual(actual_tips, tips)
12、创建HTMLTestRunner测试报告类,记录测试过程,保存测试结果test/util/HTMLTestRunner.py
HTMLTestRunner最新内容见:
http://tungwaiyip.info/software/HTMLTestRunner.html
13、创建Test_main测试套件,用于批量执行测试用例,生成测试报告
test/case/test_main.py
import os
import unittest
from util.HTMLTestRunner import HTMLTestRunner
if __name__ == "__main__":
# unittest.main()
report_path = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'report', 'result.html')
with open(report_path, 'wb') as f:
discover = unittest.defaultTestLoader.discover('./', pattern="*_case.py") # 批量执行case用例
#suite = unittest.TestLoader().loadTestsFromTestCase(LoginCass)
runner = HTMLTestRunner(
stream=f, title="web自动化测试报告", description=u"网易邮箱", verbosity=2)
runner.run(discover)执行Test_main查看Result结果:

技术细节
-
driver.switch_to.frame() #iframe框架切换
driver.switch_to.frame()方法是 Selenium 中用于切换到特定 iframe 或 frame 的方法。在网页自动化测试中,很多网页可能包含 iframe(内嵌框架),这些框架是嵌套在主页面中的独立 HTML 文档。要在这些 iframe 中进行操作,需要先切换到对应的 iframe。
语法:
//进入iframe框架 driver.switch_to.frame(reference)
//退出iframe框架 driver.switch_to.default_content()
参数:
reference可以是以下三种之一:
- 索引(index):从 0 开始的整数,表示要切换到的 iframe 在页面上的顺序。
- 名字或 ID(name or id):iframe 的
name或id属性的值。- WebElement 对象:已经找到的 iframe 元素对象。
- 分割定位器字符串,并提取定位器类型和值
# 分割定位器字符串
arr = value.split(':', 1) # 只分割一次
if len(arr) != 2:
print(f"Invalid locator format for key {key}: {value}")
return None, None
- 将读取到的值按照冒号
:分割成两个部分,split(':', 1)表示只分割一次。- 如果分割后的结果不是两个部分,则说明格式不正确,打印提示信息并返回
None, None。
# 提取定位器类型和值
by, locator_value = arr[0], arr[1]
return by, locator_value
- 将分割后的第一个部分赋值给
by,表示定位器类型(如id,name,xpath等)。- 将分割后的第二个部分赋值给
locator_value,表示定位器值。- 返回定位器类型和定位器值。
小结
标签:__,get,Python,driver,unittest,selenium,path,self,def From: https://blog.csdn.net/backtwo/article/details/139830954
UnitTest是 Python 中的一个单元测试框架,用于编写和运行测试用例。它提供了一个结构化的方法来组织测试代码,并能够自动化执行测试并生成结果报告。主要特点和用法:
测试用例(Test Case):
- 测试用例是
unittest的核心概念,通常继承自unittest.TestCase类。- 每个测试用例是一个独立的测试单元,用于验证被测试代码的某个方面或功能是否正确。
断言方法(Assertions):
unittest提供了多种断言方法,用于检查预期结果与实际结果是否一致,例如assertEqual(),assertTrue(),assertIn()等。- 当断言失败时,会抛出
AssertionError异常,标记测试失败。测试装置(Test Fixture):
unittest支持设置测试装置,包括setUp()和tearDown()方法。setUp()方法在每个测试方法运行前执行,用于准备测试环境。tearDown()方法在每个测试方法运行后执行,用于清理测试环境。测试套件(Test Suite):
- 测试套件是一组相关的测试用例的集合,可以用来组织和运行多个测试。
- 可以使用
unittest.TestSuite()创建测试套件,并将测试用例添加到套件中。运行器(Test Runner):
unittest提供了命令行接口和 GUI 工具来运行测试用例。- 常用的运行器包括
unittest.TextTestRunner()(文本输出)、unittest.TextTestResult(详细文本输出)、unittest.XMLTestRunner(XML 格式输出)等。跳过测试和预期异常:
- 可以使用装饰器
@unittest.skip(reason)跳过某个测试用例。- 使用
@unittest.expectedFailure装饰器标记预期会失败的测试用例。