C++容器
bitset
构造函数
//1.默认构造函数 :0
bitset<10> a; //a:0000000000
//2.用一个数值初始化
//(1)当用一个数值去构造的时候,其实就是将数值在内存中的存储方式显示出来。(数值在内存中是以补码形式存储的)
//(2)若bitset的位数n小于数值的位数,只取数值(小端的)前n位初始化给bitset
bitset<4> a(-16); //-16的补码为11111111.....10000,a有4位,因此a:0000
bitset<5> a(17); //17的补码为00000000.....10001,a有5位,因此a:10001
bitset<6> a(-8); //-8的补码为 11111111.....11000,a有6位,因此a:111000
bitset<7> a(8); //8的补码为 00000000.....01000,a有7位,因此a:0001000
//3.用字符串string 或者 char[]初始化
//以string为例,char[]与其用法相同
string b = "100101111"; //这里特别注意,bitset的size和字符串长度不匹配的时候如何构造
bitset<3> a(b); //a:100 //当bitset的size小于等于字符串长度,取字符串的前size位
bitset<6> a(b); //a:100101
bitset<9> a(b); //a:100101111
bitset<12> a(b); //a:000100101111 //当bitset的size大于字符串长度,进行补零
运算符重载[],支持下标从0开始访问,与数组类似
注意 :下标小的是小端
bitset<4> a; //a:0000(默认构造函数)
a[0] = 1;
a[2] = 1;
//a:0101
bitset<7> b("1001101");
for (int i = 0; i < 7; i++)
cout << b[i] << ' ';//输出:1011001
成员函数
- count()
count 返回bitset中 1 的个数
//成员函数声明
size_t count() const;
//用例
bitset<6> a("011101");
cout << a.count() // 4
- size()
size 返回size大小
//成员函数声明
size_t size() const;
//用例:
bitset<6> a("011101");
cout << a.size(); // 6
- test()
test 返回某一位(下标)是否为1
//成员函数声明
bool test (size_t pos) const;
//用例:
bitset<6> a("011101");
cout << a.test(0) << endl; //1 (true)
cout << a.test(1) << endl; //0 (false)
cout << a.test(5) << endl; //0 (false)
- any()
any 只要有一位是1,就返回true,否则返回false
//成员函数声明
bool any() const;
//用例:
cout << bitset<4>("0001").any() << endl; //1 (true)
cout << bitset<4>("0000").any() << endl; //0
- none()
none 若全为0,返回true,否则返回false
//成员函数声明
bool none() const;
//用例:
cout << bitset<4>("0000").none() << endl; //1 (true)
cout << bitset<4>("0001").none() << endl; //0
- all()
all 若全为1,返回true,否则返回false
//成员函数声明
bool all() const noexcept;
//用例:
cout << bitset<4>("1111").all() << endl; //1 (true)
cout << bitset<4>("1101").all() << endl; //0
- set()
set 全部置1,或者某一位置1或0
//成员函数声明
bitset& set() noexcept;
//用例:
//1.
bitset<6> a("011101");
a.set();
cout << a << endl; //输出:111111
//2.set也可以指定参数,第一个参数是索引,第二个true表示置1,false表示置0
bitset& set (size_t pos, bool val = true);
//
bitset<6> a("011101");
a.set(0,0);
a.set(5,1);
cout << a << endl; //输出:111100
- reset()
reset 全部置0,或者某一位置0
//成员函数声明
bitset& reset();
bitset& reset (size_t pos);
//用例:
bitset<6> a("011101");
a.reset();
cout << a << endl; //输出:000000
//也可以指定参数,单独将某一位置0
bitset<6> a("011101");
a.reset(0);
cout << a << endl; //输出:011100
- flip
flip 全部取反,或者某一位取反
//成员函数声明
bitset& flip();
bitset& flip (size_t pos);
//用例:
bitset<6> a("011101");
a.flip();
cout << a << endl; //输出:100010
//也可以指定参数,单独将某一位取反
bitset<6> a("011101");
a.flip(0);
a.flip(1);
cout << a << endl; //输出:011110
- to_string()
to_string( ) 转换为字符串
bitset<6> a("011101");
auto x = a.to_string();
cout << x ; // 011101
- to_ulong()
to_ulong( ) 转换为无符号long类型
bitset<6> a("011101");
auto x = a.to_ulong();
cout << x ; // 输出:29 1 + 4 + 8 + 16 = 29
- to_ullong()
to_ullong( ) 转换为无符号long long类型
bitset<6> a("011101");
auto x = a.to_ullong(); //同上
cout << x ; //29
C++用数组实现bitset
class Bitset {
private:
vector<int> arr; // 存储每一位的数组
int cnt = 0; // 1 的个数
int reversed = 0; // 反转操作的次数奇偶性
public:
Bitset(int size) {
arr.resize(size);
cnt = 0;
reversed = 0;
}
void fix(int idx) {
if ((arr[idx] ^ reversed) == 0) {
arr[idx] ^= 1;
++cnt;
}
}
void unfix(int idx) {
if ((arr[idx] ^ reversed) == 1) {
arr[idx] ^= 1;
--cnt;
}
}
void flip() {
reversed ^= 1;
cnt = arr.size() - cnt;
}
bool all() {
return cnt == arr.size();
}
bool one() {
return cnt > 0;
}
int count() {
return cnt;
}
string toString() {
string res;
for (int bit: arr) {
res.push_back('0' + (bit ^ reversed));
}
return res;
}
};
vector
参考文章:[详解-vector] C++必知必会 vector常用各种操作解析 - 知乎 (zhihu.com)
1.包含头文件:
#include <vector>
2.创建 vector 对象:
直接使用 vector 模板类来创建一个 vector 对象。可以创建存储特定类型元素的 vector,格式为: vector<数据类型> 名字。例如:
vector<int> myVector; // 创建一个存储整数的 vector,名字为myVector
vector<char> myVector; // 创建一个存储字符的 vector,名字为myVector
vector<string> myVector; // 创建一个存储字符串的 vector,名字为myVector
……
3.初始化一维 vector 对象:
3.1 vector < int > myVector;
此时myVector中没有任何元素,直接进行访问会报错。
可以使用 myVector.resize(num),或者myVector.resize(n, num) 来初始化。
①前者是使用num个0来初始化;
vector <int> myVector;
myVector.resize(5);
//输出内容是:0 0 0 0 0
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
②后者是使用n个num来初始化。
vector <int> myVector;
myVector.resize(5,10);
//输出内容是:10 10 10 10 10
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
vector < int > myVector = { 1,2,3,4,5 };
myVector.resize(3);
//输出内容是:1 2 3
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
vector < int > myVector = { 1,2,3,4,5 };
myVector.resize(7);
//输出内容是:1 2 3 4 5 0 0
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
3.2 vector < int > myVector(testVector); 或者 vector < int > myVector = testVector;
这种方法是使用另外一个数组来初始化myVector,注意,这里的testVector也必须是vector类型
①vector < int > myVector(testVector);
vector < int > testVector = { 1,2,3,4,5 };
vector < int > myVector(testVector);
//输出内容是:1 2 3 4 5
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
②vector < int > myVector = testVector;
vector < int > testVector = { 1,2,3,4,5 };
vector < int > myVector = testVector;
//输出内容是:1 2 3 4 5
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
3.3 使用指针初始化一维vector;
vector < int > myVector (*p, *q); 使用另外一个数组的指针来初始化v,这里既可以使用vector的指针,也可以使用普通数组的指针。
int arr[5] = { 1,2,3,4,5 };
vector<int> myVector = { 1,2,3,4 };
//输出内容是:1 2 3
vector<int> vector1(arr, arr + 3);
for (int i = 0; i < vector1.size(); i++)
cout << vector1[i] << " ";
cout << endl;
//输出内容是:2 3
vector<int> vector2(myVector.begin() + 1, myVector.end() - 1);
for (int i = 0; i < vector2.size(); i++)
cout << vector2[i] << " ";
cout << endl;
4.初始化二维 vector 对象:
4.1 vector < vector < int > > myVector;
和一维数组一样,这里的myVector中没有任何元素,myVector.size() == 0,直接访问会报错。
①可以先使用myVector.resize(n)来初始化这个二维数组的第一维,然后使用一个for循环再初始化第二维。此时myVector中的元素都是0,不是空格。
vector < vector < int > > myVector;
myVector.resize(5);
for (int i = 0; i < 5; i++) {
myVector[i].resize(5);
}
// 输出的是一片空格
for (int i = 0; i < myVector.size(); i++) {
for (int j = 0; j < myVector[i].size(); j++) {
cout << myVector[i][j] << " ";
}
cout << endl;
}
cout << endl;
4.2 vector < vector < int > > myVector(n, testVector);
可以直接使用n和testVector来初始化myVector,但是testVector需要是vector类型
vector <int> testVector(4,1);
vector < vector < int > > myVector(4, testVector);
//输出内容是: 4行4列共16个1
for (int i = 0; i < myVector.size(); i++) {
for (int j = 0; j < myVector[i].size(); j++) {
cout << myVector[i][j] << " ";
}
cout << endl;
}
cout << endl;
4.3 使用指针初始化二维vector
既可以使用vector的指针,也可以使用普通数组的指针。
①使用vector的指针
vector<int> vector1 = { 1,2,3,4 };
vector<vector<int>> vector2(4, vector1);
vector<vector<int>> myVector(vector2.begin(), vector2.end());
for (int i = 0; i < myVector.size(); i++) {
for (int j = 0; j < myVector[i].size(); j++)
cout << myVector[i][j] << " ";
cout << endl;
}
//输出内容是:
/*1 2 3 4
1 2 3 4
1 2 3 4
1 2 3 4*/
②使用普通数组的指针
int arr[4][4] = { {1,2,3,4},{5,6,7,8},{9,10,11,12},{13,14,15,16} };
vector<vector<int>> myVector;
for (int i = 0; i < 4; i++) {
// 使用指针 arr[i] 初始化每一行
vector<int> row(arr[i], arr[i] + 4);
myVector.push_back(row);
}
for (int i = 0; i < myVector.size(); i++) {
for (int j = 0; j < myVector[i].size(); j++)
cout << myVector[i][j] << " ";
cout << endl;
}
//输出内容是:
/*1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16*/
5. 访问 vector 中的元素:
直接使用下标操作符 [] 来访问 vector 中特定索引的元素。
vector<int> myVector = { 100,200,300,400 };
cout << myVector[0] << endl; // 100
cout << myVector[1] << endl; // 200
cout << myVector[2] << endl; // 300
cout << myVector[3] << endl; // 400
6.获取 vector 的大小
C++ STL之 vector的capacity和size属性区别_vector size和capacity-CSDN博客
vector<int> myVector = { 100,200,300,400, 500 };
cout << myVector.size() << endl; // 5
cout << myVector.capacity() << endl; // 5

7.向 vector 中添加元素:
使用 push_back() 函数将元素添加到 vector 的末尾,默认且只能添加到末尾。
vector<int> myVector = { 1,2,3,4 };
myVector.push_back(100);
myVector.push_back(200);
myVector.push_back(300);
//输出内容是:1 2 3 4 100 200 300
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
8.向 vector 中插入元素:
使用 insert() 函数来在指定位置插入元素。需要提供插入位置的迭代器和要插入的元素值。
vector<int> myVector = { 100,200,300,400,500,600 };
vector<int>::iterator it;
it = myVector.begin(); //索引为0的位置
myVector.insert(it, 111); //向索引为0的位置插入元素111
//输出内容为:111 100 200 300 400 500 600
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
it = myVector.begin() + 2; //索引为2的位置
myVector.insert(it, 222); //向索引为2的位置插入元素222
//输出内容为:111 100 222 200 300 400 500 600
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
it = myVector.end(); //myVector的末尾
myVector.insert(it, 999); //向myVector的末尾插入元素999
//输出内容为:111 100 222 200 300 400 500 600 999
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
9.删除 vector 中的元素:
使用 pop_back() 函数删除 vector 末尾的元素,默认且只能删除末尾的元素 。
vector<int> myVector = { 100,200,300,400,500 };
myVector.pop_back();
myVector.pop_back();
cout << myVector.size() << endl; // 3
//输出内容是:100 200 300
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
10.删除 vector 中指定位置的元素:
使用 erase() 函数来删除指定位置的元素,需要提供删除位置的迭代器。
vector<int> myVector = { 100,200,300,400,500,600 };
vector<int>::iterator it;
it = myVector.begin(); //索引为0的位置
myVector.erase(it); //删除索引为0的位置的元素
//输出内容为:200 300 400 500 600
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
it = myVector.begin() + 2; //索引为2的位置
myVector.erase(it); //删除索引为2的位置的元素
//输出内容为:200 300 500 600
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
11.删除 vector 中指定数值的元素:
使用 remove() 函数来删除指定值的元素。
①如果能在目标vector中找到该数值的元素,直接删除
vector<int> myVector = { 100,200,300,400,500,600 };
myVector.erase(remove(myVector.begin(), myVector.end(), 500), myVector.end()); //删除数值为500的元素
myVector.erase(remove(myVector.begin(), myVector.end(), 300), myVector.end()); //删除数值为300的元素
//输出内容为:100 200 400 600
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
②如果目标vector中找不到该数值的元素,不做任何操作,不会报错
vector<int> myVector = { 100,200,300,400,500,600 };
myVector.erase(remove(myVector.begin(), myVector.end(), 555), myVector.end()); //删除数值为555的元素
myVector.erase(remove(myVector.begin(), myVector.end(), 333), myVector.end()); //删除数值为333的元素
//输出内容为:100 200 300 400 500 600
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
12.查找 vector 中的元素:
直接使用下标操作符 [] 来修改 vector 中特定索引的元素。
vector<int> myVector = { 100,200,300,400,500 };
myVector[0] = 111; // 修改索引为0的元素
myVector[1] = 222; // 修改索引为0的元素
//输出内容是:111 222 300 400 500
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
13.查找 vector 中的元素:
使用 find() 函数来查找指定值的元素,或者使用迭代器来遍历查找。
①使用 find() 函数查找:
vector<int> myVector = { 100,200,300,400,500,600 };
vector<int>::iterator it = find(myVector.begin(), myVector.end(), 500);
//输出内容为:目标元素的索引为: 4
if (it != myVector.end()) {
cout << "目标元素的索引为: " << distance(myVector.begin(), it) <<endl;
}
else {
cout << "没有找到" <<endl;
}
②使用迭代器遍历查找:
vector<int> myVector = { 100,200,300,400,500,600 };
bool found = false;
int valueToFind = 300;
//输出内容为:目标元素的索引为: 2
for (vector<int>::iterator it = myVector.begin(); it != myVector.end(); ++it) {
if (*it == valueToFind) {
cout << "目标元素的索引为: " << distance(myVector.begin(), it) << endl;
found = true;
break;
}
}
if (!found) {
cout << "没有找到" << endl;
}
14.清空 vector 中的元素:
使用clear() 函数可以清空 vector 中的所有元素。
vector<int> myVector = { 100,200,300,400,500,600 };
cout << myVector.size() << endl; // 6
myVector.clear();
cout << myVector.size() << endl; // 0
15.使用索引遍历 vector 中的元素:
使用for循环和索引来遍历 vector 中的元素。
vector<int> myVector = { 100,200,300,400,500,600 };
//输出内容是:100 200 300 400 500 600
for (int i = 0; i < myVector.size(); i++) {
cout << myVector[i] << " ";
}
cout << endl;
unordered_map
c++中unordered_map的用法的详述(包含unordered_map和map的区别)_c++ unordered_map-CSDN博客
unordered_map和map的区别
1、内部实现机理不同:
map :map内部实现了一个红黑树(红黑树是非严格平衡二叉搜索树,而AVL是严格平衡二叉搜索树),红黑树具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素。因此,对于map进行的查找、删除,添加等一系列的操作都相当于是对红黑树进行的操作。map中的元素是按照二叉搜索树 (又名儿茶查找树、二叉排序树–特点就是左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根结点的键值)存储的,使用中序遍历可将键值按照从小到大遍历出来。
unordered_map :unordered_map内部实现了一个哈希表 (也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序都是无序的。
各自的优缺点
- map
1、优点:
(1)有序性,这是map结构最大的有点,其元素的有序性在很多应用中都会简化很多的操作。
(2)红黑树,内部实现一个红黑树使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高。
2、缺点:空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间。
3、适用处:对于那些有顺序要求的问题,用map会更高效一些。
- unordered_map
1、优点:因为内部实现了哈希表,因此其查找速度非常的快。
2、缺点:哈希表的建立比较耗费时间
3、适用处:对于查找问题,unordered_map 会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
总结
1、内存占有率的问题就转化成红黑树 VS Hash表,还是unorder_map占用的内存要高。
2、但是unorder_map执行效率要比map高很多
3、对于unordered_map 或unordered_set 容器,其遍历顺序与创建该容器时输入的顺序不一定相同,因为遍历是按照哈希表从前往后依次遍历的。
创建C++ unordered_map容器的方法
(1) 通过调用 unordered_map 模板类的默认构造函数,可以创建空的 unordered_map 容器。比如:
std::unordered_map<std::string, std::string> umap;
由此,就创建好了一个可存储 <string,string> 类型键值对的 unordered_map 容器。
(2) 当然,在创建 unordered_map 容器的同时,可以完成初始化操作。比如:
std::unordered_map<std::string, std::string> umap{
{"淘宝","https://www.taobao.com/"},
{"京东","https://www.jd.com/"},
{"天猫商城","https://jx.tmall.com/"} };
(3) 另外,还可以调用 unordered_map 模板中提供的复制(拷贝)构造函数,将现有 unordered_map 容器中存储的键值对,复制给新建 unordered_map 容器。
例如,在第二种方式创建好 umap 容器的基础上,再创建并初始化一个 umap2 容器:
std::unordered_map<std::string, std::string> umap2(umap);
由此,umap2 容器中就包含有 umap 容器中所有的键值对。
除此之外,C++ 11 标准中还向 unordered_map 模板类增加了移动构造函数,即以右值引用的方式将临时 unordered_map 容器中存储的所有键值对,全部复制给新建容器。例如:
//返回临时 unordered_map 容器的函数
std::unordered_map <std::string, std::string > retUmap(){
std::unordered_map<std::string, std::string>tempUmap{
{"淘宝","https://www.taobao.com/"},
{"京东","https://www.jd.com/"},
{"天猫商城","https://jx.tmall.com/"} };
return tempUmap;
}
//调用移动构造函数,创建 umap2 容器
std::unordered_map<std::string, std::string> umap2(retUmap());
注意,无论是调用复制构造函数还是拷贝构造函数,必须保证 2 个容器的类型完全相同。
(4) 当然,如果不想全部拷贝,可以使用 unordered_map 类模板提供的迭代器,在现有 unordered_map 容器中选择部分区域内的键值对,为新建 unordered_map 容器初始化。例如:
//传入 2 个迭代器,
std::unordered_map<std::string, std::string> umap2(++umap.begin(),umap.end());
通过此方式创建的 umap2 容器,其内部就包含 umap 容器中除第 1 个键值对外的所有其它键值对。
c++ unordered_map容器的成员方法
总览
=================迭代器=========================
begin 返回指向容器起始位置的迭代器(iterator)
end 返回指向容器末尾位置的迭代器
cbegin 返回指向容器起始位置的常迭代器(const_iterator)
cend 返回指向容器末尾位置的常迭代器
=================Capacity================
size 返回有效元素个数
max_size 返回 unordered_map 支持的最大元素个数
empty 判断是否为空
=================元素访问=================
operator[] 访问元素
at 访问元素
=================元素修改=================
insert 插入元素
erase 删除元素
swap 交换内容
clear 清空内容
emplace 构造及插入一个元素
emplace_hint 按提示构造及插入一个元素
================操作=========================
find 通过给定主键查找元素,没找到:返回unordered_map::end
count 返回匹配给定主键的元素的个数
equal_range 返回值匹配给定搜索值的元素组成的范围
================Buckets======================
bucket_count 返回槽(Bucket)数
max_bucket_count 返回最大槽数
bucket_size 返回槽大小
bucket 返回元素所在槽的序号
load_factor 返回载入因子,即一个元素槽(Bucket)的最大元素数
max_load_factor 返回或设置最大载入因子
rehash 设置槽数
reserve 请求改变容器容量
插入元素示例
// unordered_map::insert
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
void display(unordered_map<string,double> myrecipe,string str)
{
cout << str << endl;
for (auto& x: myrecipe)
cout << x.first << ": " << x.second << endl;
cout << endl;
}
int main ()
{
unordered_map<string,double>
myrecipe,
mypantry = {{"milk",2.0},{"flour",1.5}};
/****************插入*****************/
pair<string,double> myshopping ("baking powder",0.3);
myrecipe.insert (myshopping); // 复制插入
myrecipe.insert (make_pair<string,double>("eggs",6.0)); // 移动插入
myrecipe.insert (mypantry.begin(), mypantry.end()); // 范围插入
myrecipe.insert ({{"sugar",0.8},{"salt",0.1}}); // 初始化数组插入(可以用二维一次插入多个元素,也可以用一维插入一个元素)
myrecipe["coffee"] = 10.0; //数组形式插入
display(myrecipe,"myrecipe contains:");
/****************查找*****************/
unordered_map<string,double>::const_iterator got = myrecipe.find ("coffee");
if ( got == myrecipe.end() )
cout << "not found";
else
cout << "found "<<got->first << " is " << got->second<<"\n\n";
/****************修改*****************/
myrecipe.at("coffee") = 9.0;
myrecipe["milk"] = 3.0;
display(myrecipe,"After modify myrecipe contains:");
/****************擦除*****************/
myrecipe.erase(myrecipe.begin()); //通过位置
myrecipe.erase("milk"); //通过key
display(myrecipe,"After erase myrecipe contains:");
/****************交换*****************/
myrecipe.swap(mypantry);
display(myrecipe,"After swap with mypantry, myrecipe contains:");
/****************清空*****************/
myrecipe.clear();
display(myrecipe,"After clear, myrecipe contains:");
return 0;
}
/*
myrecipe contains:
salt: 0.1
milk: 2
flour: 1.5
coffee: 10
eggs: 6
sugar: 0.8
baking powder: 0.3
found coffee is 10
After modify myrecipe contains:
salt: 0.1
milk: 3
flour: 1.5
coffee: 9
eggs: 6
sugar: 0.8
baking powder: 0.3
After erase myrecipe contains:
flour: 1.5
coffee: 9
eggs: 6
sugar: 0.8
baking powder: 0.3
After swap with mypantry, myrecipe contains:
flour: 1.5
milk: 2
After clear, myrecipe contains:
*/
遍历示例
// unordered_map::bucket_count
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main ()
{
unordered_map<string,string> mymap =
{
{"house","maison"},
{"apple","pomme"},
{"tree","arbre"},
{"book","livre"},
{"door","porte"},
{"grapefruit","pamplemousse"}
};
/************begin和end迭代器***************/
cout << "mymap contains:";
for ( auto it = mymap.begin(); it != mymap.end(); ++it )
cout << " " << it->first << ":" << it->second;
cout << endl;
/************bucket操作***************/
unsigned n = mymap.bucket_count();
cout << "mymap has " << n << " buckets.\n";
for (unsigned i=0; i<n; ++i)
{
cout << "bucket #" << i << "'s size:"<<mymap.bucket_size(i)<<" contains: ";
for (auto it = mymap.begin(i); it!=mymap.end(i); ++it)
cout << "[" << it->first << ":" << it->second << "] ";
cout << "\n";
}
cout <<"\nkey:'apple' is in bucket #" << mymap.bucket("apple") <<endl;
cout <<"\nkey:'computer' is in bucket #" << mymap.bucket("computer") <<endl;
return 0;
}
/*
mymap contains: door:porte grapefruit:pamplemousse tree:arbre apple:pomme book:livre house:maison
mymap has 7 buckets.
bucket #0's size:2 contains: [book:livre] [house:maison]
bucket #1's size:0 contains:
bucket #2's size:0 contains:
bucket #3's size:2 contains: [grapefruit:pamplemousse] [tree:arbre]
bucket #4's size:0 contains:
bucket #5's size:1 contains: [apple:pomme]
bucket #6's size:1 contains: [door:porte]
key:'apple' is in bucket #5
key:'computer' is in bucket #6
*/
stack
C++ Stack(栈) - 菜鸟教程 (cainiaojc.com)
| 函数 | 描述 |
|---|---|
| (constructor) | 该函数用于构造堆栈容器。 |
| empty | 该函数用于测试堆栈是否为空。如果堆栈为空,则该函数返回true,否则返回false。 |
| size | 该函数返回堆栈容器的大小,该大小是堆栈中存储的元素数量的度量。 |
| top | 该函数用于访问堆栈的顶部元素。该元素起着非常重要的作用,因为所有插入和删除操作都是在顶部元素上执行的。 |
| push | 该函数用于在堆栈顶部插入新元素。 |
| pop | 该函数用于删除元素,堆栈中的元素从顶部删除。 |
| emplace | 该函数用于在当前顶部元素上方的堆栈中插入新元素。 |
| swap | 该函数用于交换引用的两个容器的内容。 |
| relational operators | 非成员函数指定堆栈所需的关系运算符。 |
| uses allocator |
顾名思义,非成员函数将分配器用于堆栈。 |
示例
#include <iostream>
#include <stack>
using namespace std;
void newstack(stack <int> ss)
{
stack <int> sg = ss;
while (!sg.empty())
{
cout << '\t' << sg.top();
sg.pop();
}
cout << '\n';
}
int main ()
{
stack <int> newst;
newst.push(55);
newst.push(44);
newst.push(33);
newst.push(22);
newst.push(11);
cout << "最新的堆栈是 : ";
newstack(newst);
cout << "\n newst.size() : " << newst.size();
cout << "\n newst.top() : " << newst.top();
cout << "\n newst.pop() : ";
newst.pop();
newstack(newst);
return 0;
}
/*
最新的堆栈是 : 11 22 33 44 55
newst.size() : 5
newst.top() : 11
newst.pop() : 22 33 44 55
*/
pair
pair创建和初始化
pair包含两个数值,与容器一样,pair也是一种模板类型。但是又与之前介绍的容器不同,在创建pair对象时,必须提供两个类型名,两个对应的类型名的类型不必相同
pair<string,string>anon;
pair<string,int>word_count;
pair<string, vector<int> >line;
当然也可以在定义时为每个成员提供初始化式:
pair<string,string>author("James","Joy");
pair类型的使用相当的繁琐,如果定义多个相同的pair类型对象,可以使用typedef简化声明:
typedef pair<string,string> Author;
Author proust("March","Proust");
Author Joy("James","Joy");
pair对象操作
对于pair类,可以直接访问其数据成员:其成员都是公有的,分别命名为first和second,只需要使用普通的点操作符
string firstBook;
if(author.first=="James" && author.second=="Joy")
firstBook="Stephen Hero";
生成新的pair对象
除了构造函数,标准库还定义了一个make_pair函数,由传递给它的两个实参生成一个新的pair对象
pair<string, string> next_auth;
string first,last;
while(cin>>first>>last) {
next_auth=make_pair(first,last);
//...
}
还可以用下列等价的更复杂的操作:
next_auth=pair<string,string>(first,last);
由于pair的数据成员是公有的,因而可如下直接地读取输入:
pair<string, string> next_auth;
while(cin>>next_auth.first>>next_auth.last) {
//...
}
queue
| 函数 | 描述 |
|---|---|
| (constructor) | 该函数用于构造队列容器。 |
| empty | 该函数用于测试队列是否为空。如果队列为空,则该函数返回true,否则返回false。 |
| size | 该函数返回队列中元素的个数。 |
| front | 该函数返回第一个元素。元素起着非常重要的作用,因为所有的删除操作都是在front元素上执行的。 |
| back | 该函数返回最后一个元素。该元素起着非常重要的作用,因为所有插入操作都在后面元素上执行。 |
| push | 该函数用于在末尾插入一个新元素。 |
| pop | 该函数用于删除第一个元素。 |
| emplace | 该函数用于在当前后元素上方的队列中插入新元素。 |
使用示例
#include <iostream>
#include <queue>
using namespace std;
void showsg(queue <int> sg)
{
queue <int> ss = sg;
while (!ss.empty())
{
cout << '\t' << ss.front();
ss.pop();
}
cout << '\n';
}
int main()
{
queue <int> fquiz;
fquiz.push(10);
fquiz.push(20);
fquiz.push(30);
cout << "队列fquiz是 : ";
showsg(fquiz);
cout << "\nfquiz.size() : " << fquiz.size();
cout << "\nfquiz.front() : " << fquiz.front();
cout << "\nfquiz.back() : " << fquiz.back();
cout << "\nfquiz.pop() : ";
fquiz.pop();
showsg(fquiz);
return 0;
}
输出:
队列fquiz是 : 10 20 30
fquiz.size() : 3
fquiz.front() : 10
fquiz.back() : 30
fquiz.pop() : 20 30
priority_queue
C ++中的优先队列是STL中的派生容器,它仅考虑最高优先级元素。队列遵循FIFO策略,而优先队列根据优先级弹出元素,即,优先级最高的元素首先弹出。
它在某些方面类似于普通队列,但在以下方面有所不同:
- 在优先队列中,队列中的每个元素都与某个优先级相关联,但是优先级在队列数据结构中不存在。
- 优先队列中具有最高优先级的元素将被首先删除,而队列遵循FIFO(先进先出)策略,这意味着先插入的元素将被首先删除。
- 如果存在多个具有相同优先级的元素,则将考虑该元素在队列中的顺序。
注意:优先队列是普通队列的扩展版本,但优先级最高的元素将首先从优先队列中删除。
| 函数 | 描述 |
|---|---|
| push() | 它将新元素插入优先队列。 |
| pop() | 它将优先级最高的元素从队列中删除。 |
| top() | 此函数用于寻址优先队列的最顶层元素。 |
| size() | 返回优先队列的大小。 |
| empty() | 它验证队列是否为空。基于验证,它返回队列的状态。 |
| swap() | 它将优先队列的元素与具有相同类型和大小的另一个队列交换。 |
| emplace() | 它在优先队列的顶部插入一个新元素。 |
示例
#include <iostream>
#include<queue>
using namespace std;
int main()
{
priority_queue<int> p; // 变量声明.
p.push(10); // 插入 10 到队列, top=10
p.push(30); // 插入 30 到队列, top=30
p.push(20); // 插入 20 到队列, top=20
cout<<"可用元素的数量 到 'p' :"<<p.size()<<endl;
while(!p.empty())
{
std::cout << p.top() << std::endl;
p.pop();
}
return 0;
}
输出结果:
可用元素的数量 到 'p' :3
30
20
10
大根堆和小根堆
priority_queue<int, vector<int>, less<int>>s;//less表示按照递减(从大到小)的顺序插入元素
priority_queue<int, vector<int>, greater<int>>s;//greater表示按照递增(从小到大)的顺序插入元素
// 不写第三个参数或者写成less都是大根堆, greater是小根堆
自定义排序方式
#if 0
#define rows 3
#define cols 5
//int num[rows][cols] = { {29,17,14,2,1},{19,17,16,15,6},{30,25,20,14,5} };
int num[rows][cols] = { {1,2,14,17,29},{6,15,16,17,19},{5,14,20,25,30} };
struct Node {
int * p;//指向数组的指针,便于取下一个数字
bool operator<(const struct Node& node)const {
return *p > *node.p;
}
};
void gettop(int k){
struct Node arr[rows];
int* res = new int[k];
for (int i = 0; i < rows; ++i)
arr[i].p = num[i];//初始化指针指向各行的首位
//优先队列默认是大堆,这块是自己去设置的大堆。
priority_queue<Node>myq(arr, arr + rows);
for (int j = 0; j < k && j < cols; ++j) {
Node tmp = myq.top();
myq.pop();
res[j] = *tmp.p;
tmp.p++;
myq.push(tmp);
}
for (int i = 0; i < k; ++i) {
cout << res[i]<<" ";
}
cout << endl;
}
int main() {
int k = 5;
gettop(5);
return 0;
}
#endif
容器常见方法
max_element()
max_element是用来来查询最大值所在的第一个位置
#include <algorithm>
#include <iostream>
using namespace std;
struct structs
{
bool operator() (int i, int j) {
return i<j;
}
} structs;
//此处也可以直接用bool bools(int i, int j) { return i<j; }
void main()
{
int ints[] = { 3,5,7,2,7,6,4 };
//方法一
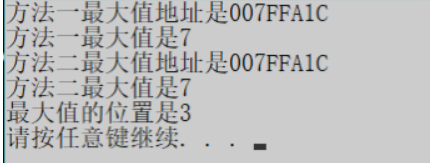
cout << "方法一最大值地址是" << max_element(ints, ints + 7, structs) << endl;
cout << "方法一最大值是" << *max_element(ints, ints + 7, structs ) << endl;
//方法二
cout << "方法二最大值地址是" << max_element(ints, ints + 7) << endl;
cout << "方法二最大值是" << *max_element(ints, ints + 7) << endl;
//如果不加*获取的是他的地址
int pos = *max_element(ints, ints + 7);
int i;
for (i = 0; i < 10; i++)
{
if (ints[i] == pos)
{
break;
}
}
cout << "最大值的位置是" << i + 1 << endl;
}
accumulate()
C++中accumulate的用法_result_value = accumulate(vec_value.begin(), vec_v-CSDN博客
accumulate定义在#include
中,作用有两个,一个是累加求和,另一个是自定义类型数据的处理
累加求和
int sum = accumulate(vec.begin() , vec.end() , 42);
accumulate带有三个形参:头两个形参指定要累加的元素范围,第三个形参则是累加的初值。
accumulate函数将它的一个内部变量设置为指定的初始值,然后在此初值上累加输入范围内所有元素的值。accumulate算法返回累加的结果,其返回类型就是其第三个实参的类型。
可以使用accumulate把string型的vector容器中的元素连接起来:
string sum = accumulate(v.begin() , v.end() , string(""));
这个函数调用的效果是:从空字符串开始,把vec里的每个元素连接成一个字符串。
标签:容器,myVector,cout,map,int,元素,C++,vector From: https://www.cnblogs.com/hnu-hua/p/18179451