一、Target数据采集scrape模块解读
1、scrape target业务流程框架
- 1、由scrape.Manager管理所有的抓取对象;
- 2、所有的抓取对象按group分组,每个group是一个job_name;
- 3、每个group下含多个scrapeTarget,即具体的抓取目标endpoint;
- 4、对每个目标endpoint,启动一个抓取goroutine,按照interval间隔循环的抓取对象的指标;
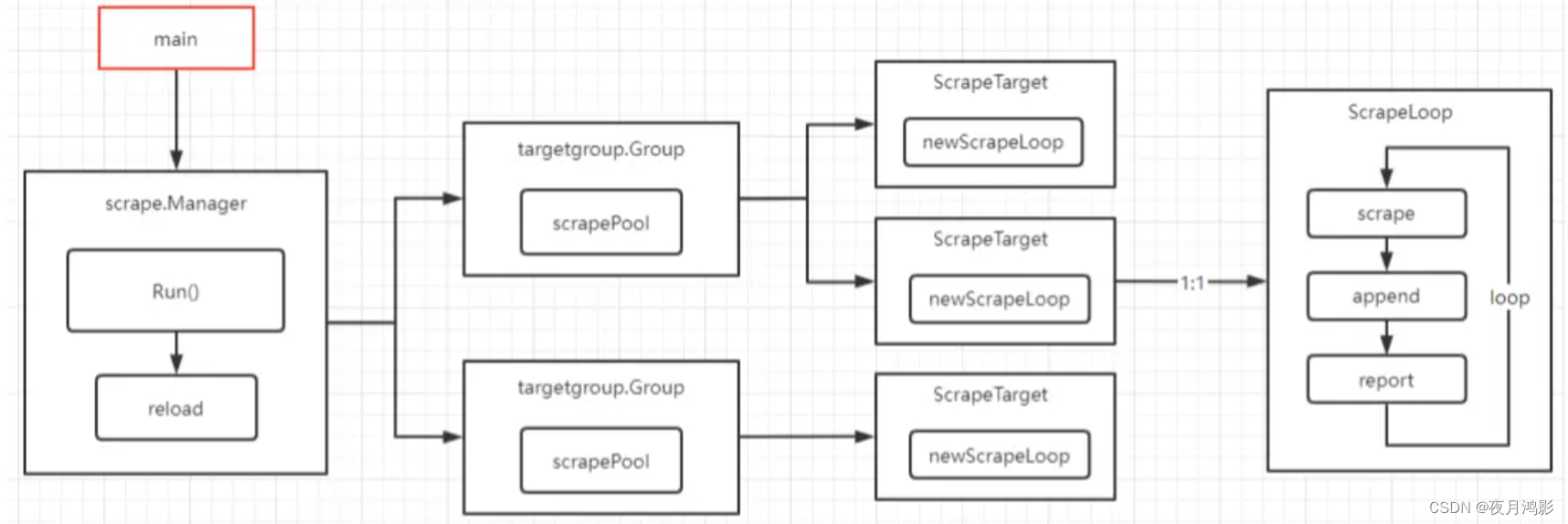
- 举例说明:
假如prometheus.yaml中的抓取配置为:
scrape_configs:
- job_name: "monitor"
static_configs:
- targets: ['192.168.101.9:11504']
- job_name: 'node-exporter'
static_configs:
- targets: ['10.21.1.74:9100', '192.168.101.9:9100']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
那么,抓取对象将按如下结构分组:
{
"monitor": [
{
"Targets": [
{
"__address__": "192.168.101.9:11504"
}
],
"Labels": null,
"Source": "0"
}
],
"node-exporter": [
{
"Targets": [
{
"__address__": "10.21.1.74:9100"
},
{
"__address__": "192.168.101.9:9100"
}
],
"Labels": null,
"Source": "0"
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2、scrape.Manager的代码逻辑
代码入口,prometheus/cmd/main.go
{
// Scrape manager.
g.Add(
func() error {
// When the scrape manager receives a new targets list
// it needs to read a valid config for each job.
// It depends on the config being in sync with the discovery manager so
// we wait until the config is fully loaded.
<-reloadReady.C
**err := scrapeManager.Run(discoveryManagerScrape.SyncCh())**
level.Info(logger).Log("msg", "Scrape manager stopped")
return err
},
func(err error) {
// Scrape manager needs to be stopped before closing the local TSDB
// so that it doesn't try to write samples to a closed storage.
level.Info(logger).Log("msg", "Stopping scrape manager...")
scrapeManager.Stop()
},
)
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
其中函数参数中的map[string][]*targetgroup.Group由discover组件传入:
// scrape.manager.go
func (m *Manager) Run(tsets <-chan map[string][]*targetgroup.Group) error {
go m.reloader()
for {
select {
case ts := <-tsets:
m.updateTsets(ts)
select {
case m.triggerReload <- struct{}{}: //发送数据到channel: m.triggerReload
default:
}
case <-m.graceShut:
return nil
}
}
}
// 等待channel:m.triggerReload上的数据,然后进行reload
// 热加载
func (m *Manager) reloader() {
ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()
for {
select {
case <-m.graceShut:
return
case <-ticker.C:
select {
case <-m.triggerReload:
m.reload()
case <-m.graceShut:
return
}
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 具体的初始化动作在reload()中,对每个targetGroup:
创建scrapePool;
对scrapePool进行Sync:同步信息进行抓取;
// scrape.manager.go
//遍历每个targetGroup:创建scrapePool,然后对scrapePool进行Sync
func (m *Manager) reload() {
m.mtxScrape.Lock()
var wg sync.WaitGroup
for setName, groups := range m.targetSets {
if _, ok := m.scrapePools[setName]; !ok {
scrapeConfig, ok := m.scrapeConfigs[setName]
...
//创建scrapePool
sp, err := newScrapePool(scrapeConfig, m.append, m.jitterSeed, log.With(m.logger, "scrape_pool", setName))
m.scrapePools[setName] = sp
}
wg.Add(1)
// Run the sync in parallel as these take a while and at high load can't catch up.
go func(sp *scrapePool, groups []*targetgroup.Group) {
sp.Sync(groups) //scrapePool内的Sync,这里是groups是数组,但是一般只有1个元素
wg.Done()
}(m.scrapePools[setName], groups)
}
m.mtxScrape.Unlock()
wg.Wait()
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 对于一个targetGroup下的所有target对象,它们共享httpclient和bufferPool:
// scrape/scrape.go
// 创建scrapePool
func newScrapePool(cfg *config.ScrapeConfig, app storage.Appendable, jitterSeed uint64, logger log.Logger) (*scrapePool, error) {
client, err := config_util.NewClientFromConfig(cfg.HTTPClientConfig, cfg.JobName, false)
// bufferPool
buffers := pool.New(1e3, 100e6, 3, func(sz int) interface{} { return make([]byte, 0, sz) })
ctx, cancel := context.WithCancel(context.Background())
sp := &scrapePool{
cancel: cancel,
appendable: app,
config: cfg,
client: client,
activeTargets: map[uint64]*Target{},
loops: map[uint64]loop{},
logger: logger,
}
sp.newLoop = func(opts scrapeLoopOptions) loop {
......
return newScrapeLoop(
ctx,
opts.scraper,
log.With(logger, "target", opts.target),
buffers,
func(l labels.Labels) labels.Labels {
return mutateSampleLabels(l, opts.target, opts.honorLabels, opts.mrc)
},
func(l labels.Labels) labels.Labels { return mutateReportSampleLabels(l, opts.target) },
func() storage.Appender { return appender(app.Appender(), opts.limit) },
cache,
jitterSeed,
opts.honorTimestamps,
)
}
return sp, nil
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
3、scrape.scrapePool的代码逻辑
scrapePool为targetGroup下的每个targets,创建1个scrapeLoop,然后让scrapeLoop干活
// scrape/scrape.go
func (sp *scrapePool) Sync(tgs []*targetgroup.Group) {
//所有的targets
var all []*Target
sp.mtx.Lock()
sp.droppedTargets = []*Target{}
for _, tg := range tgs {
targets, err := targetsFromGroup(tg, sp.config)
......
for _, t := range targets {
if t.Labels().Len() > 0 {
all = append(all, t)
}
......
}
}
sp.mtx.Unlock()
//指挥target干活
sp.sync(all)
......
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 对每个target,使用newLoop()创建targetLoop,然后启动1个goroutine,让targetLoop.run()循环拉取:
// scrape/scrape.go
//遍历Group下的每个target,对每个target: 创建targetScraper,创建scrapeLoop,然后scrapeLoop进行干活
func (sp *scrapePool) sync(targets []*Target) {
for _, t := range targets {
t := t
hash := t.hash()
uniqueTargets[hash] = struct{}{}
if _, ok := sp.activeTargets[hash]; !ok {
s := &targetScraper{Target: t, client: sp.client, timeout: timeout} //创建targetScraper
l := sp.newLoop(scrapeLoopOptions{ //创建scrapeLoop
target: t,
scraper: s,
limit: limit,
honorLabels: honorLabels,
honorTimestamps: honorTimestamps,
mrc: mrc,
})
sp.activeTargets[hash] = t
sp.loops[hash] = l
go l.run(interval, timeout, nil) //scrapeLoop循环拉取
}
......
}
...
wg.Wait()
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
4、scrapeLoop的代码逻辑
每个scrapeLoop按抓取周期循环执行
- scrape抓取指标数据;
- append写入底层存储;
- 最后更新scrapeLoop的状态(主要是指标值);
// scrape/scrape.go
func (sl *scrapeLoop) run(interval, timeout time.Duration, errc chan<- error) {
......
ticker := time.NewTicker(interval) //定时器,定时执行
defer ticker.Stop()
for {
......
var (
start = time.Now()
scrapeCtx, cancel = context.WithTimeout(sl.ctx, timeout)
)
......
contentType, scrapeErr := sl.scraper.scrape(scrapeCtx, buf) //scrape进行抓取
......
//写scrape的数据写入底层存储
total, added, seriesAdded, appErr := sl.append(b, contentType, start)
......
sl.buffers.Put(b) //写入buffer
//更新scrapeLoop的状态
if err := sl.report(start, time.Since(start), total, added, seriesAdded, scrapeErr); err != nil {
level.Warn(sl.l).Log("msg", "Appending scrape report failed", "err", err)
}
select {
......
case <-ticker.C: //循环执行
}
}
......
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
5、targetScrape的抓取逻辑
最终达到HTTP抓取的逻辑:
- 首先,向target的url发送HTTP Get;
- 然后,将写入io.writer(即上文中的buffers)中,待后面解析出指标:
//抓取逻辑
func (s *targetScraper) scrape(ctx context.Context, w io.Writer) (string, error) {
if s.req == nil {
req, err := http.NewRequest("GET", s.URL().String(), nil) //Get /metrics接口
if err != nil {
return "", err
}
req.Header.Add("Accept", acceptHeader)
req.Header.Add("Accept-Encoding", "gzip")
req.Header.Set("User-Agent", userAgentHeader)
req.Header.Set("X-Prometheus-Scrape-Timeout-Seconds", fmt.Sprintf("%f", s.timeout.Seconds()))
s.req = req
}
resp, err := s.client.Do(s.req.WithContext(ctx)) //发送http GET请求
if err != nil {
return "", err
}
.......
if resp.Header.Get("Content-Encoding") != "gzip" {
_, err = io.Copy(w, resp.Body) //将response body写入参数w
if err != nil {
return "", err
}
return resp.Header.Get("Content-Type"), nil
}
if s.gzipr == nil {
s.buf = bufio.NewReader(resp.Body)
s.gzipr, err = gzip.NewReader(s.buf)
if err != nil {
return "", err
}
}
// 写入io.writer
_, err = io.Copy(w, s.gzipr)
s.gzipr.Close()
return resp.Header.Get("Content-Type"), nil
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40