第九章:类
JavaScript 对象在第六章中有所涉及。该章将每个对象视为一组独特的属性,与其他对象不同。然而,通常有必要定义一种共享某些属性的对象类。类的成员或实例具有自己的属性来保存或定义它们的状态,但它们还具有定义其行为的方法。这些方法由类定义,并由所有实例共享。例如,想象一个名为 Complex 的类,表示并对复数执行算术运算。Complex 实例将具有保存复数的实部和虚部(状态)的属性。Complex 类将定义执行这些数字的加法和乘法(行为)的方法。
在 JavaScript 中,类使用基于原型的继承:如果两个对象从同一原型继承属性(通常是函数值属性或方法),那么我们说这些对象是同一类的实例。简而言之,这就是 JavaScript 类的工作原理。JavaScript 原型和继承在§6.2.3 和§6.3.2 中有所涉及,您需要熟悉这些部分的内容才能理解本章。本章在§9.1 中涵盖了原型。
如果两个对象从同一原型继承,这通常(但不一定)意味着它们是由同一构造函数或工厂函数创建和初始化的。构造函数在§4.6、§6.2.2 和§8.2.3 中有所涉及,本章在§9.2 中有更多内容。
JavaScript 一直允许定义类。ES6 引入了全新的语法(包括class关键字),使得创建类变得更加容易。这些新的 JavaScript 类与旧式类的工作方式相同,本章首先解释了创建类的旧方法,因为这更清楚地展示了在幕后使类起作用的原理。一旦我们解释了这些基础知识,我们将转而开始使用新的简化类定义语法。
如果您熟悉像 Java 或 C++这样的强类型面向对象编程语言,您会注意到 JavaScript 类与这些语言中的类有很大不同。虽然有一些语法上的相似之处,并且您可以在 JavaScript 中模拟许多“经典”类的特性,但最好事先了解 JavaScript 的类和基于原型的继承机制与 Java 和类似语言的类和基于类的继承机制有很大不同。
9.1 类和原型
在 JavaScript 中,类是一组从同一原型对象继承属性的对象。因此,原型对象是类的核心特征。第六章介绍了Object.create()函数,该函数返回一个从指定类型对象继承的新创建对象。如果我们定义一个原型对象,然后使用Object.create()创建从中继承的对象,我们就定义了一个 JavaScript 类。通常,类的实例需要进一步初始化,通常定义一个函数来创建和初始化新对象。示例 9-1 演示了这一点:它定义了一个代表值范围的类的原型对象,并定义了一个工厂函数,用于创建和初始化类的新实例。
示例 9-1 一个简单的 JavaScript 类
// This is a factory function that returns a new range object.
function range(from, to) {
// Use Object.create() to create an object that inherits from the
// prototype object defined below. The prototype object is stored as
// a property of this function, and defines the shared methods (behavior)
// for all range objects.
let r = Object.create(range.methods);
// Store the start and end points (state) of this new range object.
// These are noninherited properties that are unique to this object.
r.from = from;
r.to = to;
// Finally return the new object
return r;
}
// This prototype object defines methods inherited by all range objects.
range.methods = {
// Return true if x is in the range, false otherwise
// This method works for textual and Date ranges as well as numeric.
includes(x) { return this.from <= x && x <= this.to; },
// A generator function that makes instances of the class iterable.
// Note that it only works for numeric ranges.
*[Symbol.iterator]() {
for(let x = Math.ceil(this.from); x <= this.to; x++) yield x;
},
// Return a string representation of the range
toString() { return "(" + this.from + "..." + this.to + ")"; }
};
// Here are example uses of a range object.
let r = range(1,3); // Create a range object
r.includes(2) // => true: 2 is in the range
r.toString() // => "(1...3)"
[...r] // => [1, 2, 3]; convert to an array via iterator
在示例 9-1 的代码中有一些值得注意的事项:
-
此代码定义了一个用于创建新 Range 对象的工厂函数
range()。 -
它使用了
range()函数的methods属性作为一个方便的存储原型对象的地方,该原型对象定义了类。将原型对象放在这里并没有什么特殊或成语化的地方。 -
range()函数在每个 Range 对象上定义了from和to属性。这些是定义每个独立 Range 对象的唯一状态的非共享、非继承属性。 -
range.methods对象使用了 ES6 的简写语法来定义方法,这就是为什么你在任何地方都看不到function关键字的原因。(查看§6.10.5 来回顾对象字面量简写方法语法。) -
原型中的一个方法具有计算名称(§6.10.2),即
Symbol.iterator,这意味着它正在为 Range 对象定义一个迭代器。这个方法的名称前缀为*,表示它是一个生成器函数而不是常规函数。迭代器和生成器在第十二章中有详细介绍。目前,要点是这个 Range 类的实例可以与for/of循环和...扩展运算符一起使用。 -
在
range.methods中定义的共享的继承方法都使用了在range()工厂函数中初始化的from和to属性。为了引用它们,它们使用this关键字来引用通过其调用的对象。这种对this的使用是任何类的方法的基本特征。
9.2 类和构造函数
示例 9-1 演示了定义 JavaScript 类的一种简单方法。然而,这并不是惯用的做法,因为它没有定义构造函数。构造函数是为新创建的对象初始化而设计的函数。构造函数使用new关键字调用,如§8.2.3 所述。使用new调用构造函数会自动创建新对象,因此构造函数本身只需要初始化该新对象的状态。构造函数调用的关键特征是构造函数的prototype属性被用作新对象的原型。§6.2.3 介绍了原型并强调,几乎所有对象都有一个原型,但只有少数对象有一个prototype属性。最后,我们可以澄清这一点:函数对象具有prototype属性。这意味着使用相同构造函数创建的所有对象都继承自同一个对象,因此它们是同一类的成员。示例 9-2 展示了如何修改示例 9-1 的 Range 类以使用构造函数而不是工厂函数。示例 9-2 展示了在不支持 ES6 class关键字的 JavaScript 版本中创建类的惯用方法。即使现在class得到了很好的支持,仍然有很多旧的 JavaScript 代码定义类的方式就像这样,你应该熟悉这种习惯用法,这样你就可以阅读旧代码,并且当你使用class关键字时,你能理解发生了什么“底层”操作。
示例 9-2。使用构造函数的 Range 类
// This is a constructor function that initializes new Range objects.
// Note that it does not create or return the object. It just initializes this.
function Range(from, to) {
// Store the start and end points (state) of this new range object.
// These are noninherited properties that are unique to this object.
this.from = from;
this.to = to;
}
// All Range objects inherit from this object.
// Note that the property name must be "prototype" for this to work.
Range.prototype = {
// Return true if x is in the range, false otherwise
// This method works for textual and Date ranges as well as numeric.
includes: function(x) { return this.from <= x && x <= this.to; },
// A generator function that makes instances of the class iterable.
// Note that it only works for numeric ranges.
[Symbol.iterator]: function*() {
for(let x = Math.ceil(this.from); x <= this.to; x++) yield x;
},
// Return a string representation of the range
toString: function() { return "(" + this.from + "..." + this.to + ")"; }
};
// Here are example uses of this new Range class
let r = new Range(1,3); // Create a Range object; note the use of new
r.includes(2) // => true: 2 is in the range
r.toString() // => "(1...3)"
[...r] // => [1, 2, 3]; convert to an array via iterator
值得仔细比较示例 9-1 和 9-2,并注意这两种定义类的技术之间的区别。首先,注意到我们将range()工厂函数重命名为Range()当我们将其转换为构造函数时。这是一个非常常见的编码约定:构造函数在某种意义上定义了类,而类的名称(按照约定)以大写字母开头。常规函数和方法的名称以小写字母开头。
接下来,请注意在示例末尾使用new关键字调用Range()构造函数,而range()工厂函数在没有使用new的情况下调用。示例 9-1 使用常规函数调用(§8.2.1)创建新对象,而示例 9-2 使用构造函数调用(§8.2.3)。因为使用new调用Range()构造函数,所以不需要调用Object.create()或采取任何操作来创建新对象。新对象在构造函数调用之前自动创建,并且可以作为this值访问。Range()构造函数只需初始化this。构造函数甚至不必返回新创建的对象。构造函数调用会自动创建一个新对象,将构造函数作为该对象的方法调用,并返回新对象。构造函数调用与常规函数调用如此不同的事实是我们给构造函数名称以大写字母开头的另一个原因。构造函数被编写为以构造函数方式调用,并且如果以常规函数方式调用,它们通常不会正常工作。将构造函数函数与常规函数区分开的命名约定有助于程序员知道何时使用new。
示例 9-1 和 9-2 之间的另一个关键区别是原型对象的命名方式。在第一个示例中,原型是range.methods。这是一个方便且描述性强的名称,但是任意的。在第二个示例中,原型是Range.prototype,这个名称是强制的。对Range()构造函数的调用会自动使用Range.prototype作为新 Range 对象的原型。
最后,还要注意示例 9-1 和 9-2 之间没有变化的地方:两个类的范围方法的定义和调用方式是相同的。因为示例 9-2 演示了在 ES6 之前 JavaScript 版本中创建类的惯用方式,它没有在原型对象中使用 ES6 的简写方法语法,并且明确用function关键字拼写出方法。但你可以看到两个示例中方法的实现是相同的。
重要的是,要注意两个范围示例在定义构造函数或方法时都没有使用箭头函数。回想一下§8.1.3 中提到的,以这种方式定义的函数没有prototype属性,因此不能用作构造函数。此外,箭头函数从定义它们的上下文中继承this关键字,而不是根据调用它们的对象设置它,这使它们对于方法是无用的,因为方法的定义特征是它们使用this来引用被调用的实例。
幸运的是,新的 ES6 类语法不允许使用箭头函数定义方法,因此在使用该语法时不会出现这种错误。我们很快将介绍 ES6 的class关键字,但首先,还有更多关于构造函数的细节需要讨论。
9.2.1 构造函数、类标识和 instanceof
正如我们所见,原型对象对于类的标识是至关重要的:两个对象只有在它们继承自相同的原型对象时才是同一类的实例。初始化新对象状态的构造函数并不是基本的:两个构造函数可能具有指向相同原型对象的prototype属性。然后,这两个构造函数都可以用于创建同一类的实例。
尽管构造函数不像原型那样基础,但构造函数作为类的公共面孔。最明显的是,构造函数的名称通常被采用为类的名称。例如,我们说 Range() 构造函数创建 Range 对象。然而,更根本的是,构造函数在测试对象是否属于类时作为 instanceof 运算符的右操作数。如果我们有一个对象 r 并想知道它是否是 Range 对象,我们可以写:
r instanceof Range // => true: r inherits from Range.prototype
instanceof 运算符在 §4.9.4 中有描述。左操作数应该是正在测试的对象,右操作数应该是命名类的构造函数。表达式 o instanceof C 在 o 继承自 C.prototype 时求值为 true。继承不必是直接的:如果 o 继承自继承自继承自 C.prototype 的对象,表达式仍将求值为 true。
从技术上讲,在前面的代码示例中,instanceof 运算符并不是在检查 r 是否实际由 Range 构造函数初始化。相反,它是在检查 r 是否继承自 Range.prototype。如果我们定义一个函数 Strange() 并将其原型设置为与 Range.prototype 相同,那么使用 new Strange() 创建的对象在 instanceof 方面将被视为 Range 对象(但实际上它们不会像 Range 对象一样工作,因为它们的 from 和 to 属性尚未初始化):
function Strange() {}
Strange.prototype = Range.prototype;
new Strange() instanceof Range // => true
即使 instanceof 无法实际验证构造函数的使用,但它仍将构造函数作为其右操作数,因为构造函数是类的公共标识。
如果您想要测试对象的原型链以查找特定原型而不想使用构造函数作为中介,可以使用 isPrototypeOf() 方法。例如,在 示例 9-1 中,我们定义了一个没有构造函数的类,因此无法使用该类的 instanceof。然而,我们可以使用以下代码测试对象 r 是否是该无构造函数类的成员:
range.methods.isPrototypeOf(r); // range.methods is the prototype object.
9.2.2 构造函数属性
在 示例 9-2 中,我们将 Range.prototype 设置为一个包含我们类方法的新对象。虽然将这些方法表达为单个对象字面量的属性很方便,但实际上并不需要创建一个新对象。任何常规的 JavaScript 函数(不包括箭头函数、生成器函数和异步函数)都可以用作构造函数,并且构造函数调用需要一个 prototype 属性。因此,每个常规的 JavaScript 函数¹ 自动具有一个 prototype 属性。该属性的值是一个具有单个、不可枚举的 constructor 属性的对象。constructor 属性的值是函数对象:
let F = function() {}; // This is a function object.
let p = F.prototype; // This is the prototype object associated with F.
let c = p.constructor; // This is the function associated with the prototype.
c === F // => true: F.prototype.constructor === F for any F
具有预定义原型对象及其 constructor 属性的存在意味着对象通常继承一个指向其构造函数的 constructor 属性。由于构造函数作为类的公共标识,这个构造函数属性给出了对象的类:
let o = new F(); // Create an object o of class F
o.constructor === F // => true: the constructor property specifies the class
图 9-1 展示了构造函数、其原型对象、原型指向构造函数的反向引用以及使用构造函数创建的实例之间的关系。
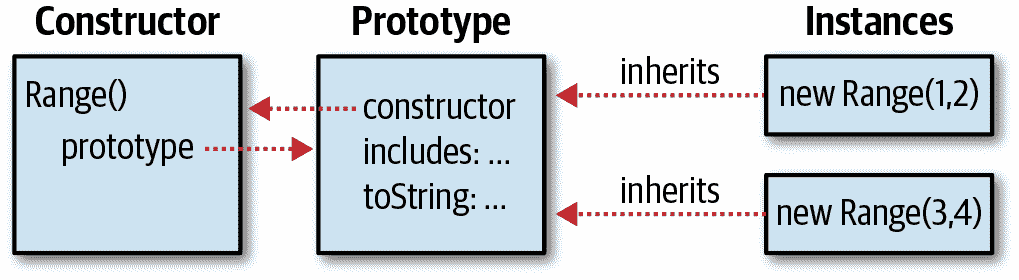
图 9-1. 一个构造函数、其原型和实例
注意图 9-1 使用我们的Range()构造函数作为示例。实际上,然而,在示例 9-2 中定义的 Range 类覆盖了预定义的Range.prototype对象为自己的对象。并且它定义的新原型对象没有constructor属性。因此,如定义的 Range 类的实例没有constructor属性。我们可以通过显式向原型添加构造函数来解决这个问题:
Range.prototype = {
constructor: Range, // Explicitly set the constructor back-reference
/* method definitions go here */
};
另一种在旧版 JavaScript 代码中常见的技术是使用预定义的原型对象及其具有constructor属性,并使用以下代码逐个添加方法:
// Extend the predefined Range.prototype object so we don't overwrite
// the automatically created Range.prototype.constructor property.
Range.prototype.includes = function(x) {
return this.from <= x && x <= this.to;
};
Range.prototype.toString = function() {
return "(" + this.from + "..." + this.to + ")";
};
9.3 使用class关键字的类
类自从语言的第一个版本以来就一直是 JavaScript 的一部分,但在 ES6 中,它们终于得到了自己的语法,引入了class关键字。示例 9-3 展示了使用这种新语法编写的 Range 类的样子。
示例 9-3. 使用class重写的 Range 类
class Range {
constructor(from, to) {
// Store the start and end points (state) of this new range object.
// These are noninherited properties that are unique to this object.
this.from = from;
this.to = to;
}
// Return true if x is in the range, false otherwise
// This method works for textual and Date ranges as well as numeric.
includes(x) { return this.from <= x && x <= this.to; }
// A generator function that makes instances of the class iterable.
// Note that it only works for numeric ranges.
*[Symbol.iterator]() {
for(let x = Math.ceil(this.from); x <= this.to; x++) yield x;
}
// Return a string representation of the range
toString() { return `(${this.from}...${this.to})`; }
}
// Here are example uses of this new Range class
let r = new Range(1,3); // Create a Range object
r.includes(2) // => true: 2 is in the range
r.toString() // => "(1...3)"
[...r] // => [1, 2, 3]; convert to an array via iterator
重要的是要理解,在示例 9-2 和 9-3 中定义的类的工作方式完全相同。引入class关键字到语言中并不改变 JavaScript 基于原型的类的基本性质。尽管示例 9-3 使用了class关键字,但生成的 Range 对象是一个构造函数,就像在示例 9-2 中定义的版本一样。新的class语法干净方便,但最好将其视为对在示例 9-2 中显示的更基本的类定义机制的“语法糖”。
注意示例 9-3 中类语法的以下几点:
-
使用
class关键字声明类,后面跟着类名和用大括号括起来的类体。 -
类体包括使用对象字面量方法简写的方法定义(我们在示例 9-1 中也使用了),其中省略了
function关键字。然而,与对象字面量不同,没有逗号用于将方法彼此分隔开。 (尽管类体在表面上与对象字面量相似,但它们并不是同一回事。特别是,它们不支持使用名称/值对定义属性。) -
关键字
constructor用于为类定义构造函数。但实际上定义的函数并不真正命名为constructor。class声明语句定义了一个新变量Range,并将这个特殊的constructor函数的值赋给该变量。 -
如果你的类不需要进行任何初始化,你可以省略
constructor关键字及其主体,将为你隐式创建一个空的构造函数。
如果你想定义一个继承自另一个类的类,你可以使用extends关键字和class关键字:
// A Span is like a Range, but instead of initializing it with
// a start and an end, we initialize it with a start and a length
class Span extends Range {
constructor(start, length) {
if (length >= 0) {
super(start, start + length);
} else {
super(start + length, start);
}
}
}
创建子类是一个独立的主题。我们将在§9.5 中返回并解释这里显示的extends和super关键字。
类声明与函数声明一样,既有语句形式又有表达式形式。就像我们可以写:
let square = function(x) { return x * x; };
square(3) // => 9
我们也可以写:
let Square = class { constructor(x) { this.area = x * x; } };
new Square(3).area // => 9
与函数定义表达式一样,类定义表达式可以包括一个可选的类名。如果提供了这样的名称,那个名称仅在类体内部定义。
尽管函数表达式非常常见(特别是使用箭头函数简写),在 JavaScript 编程中,类定义表达式不是你经常使用的东西,除非你发现自己正在编写一个以类作为参数并返回子类的函数。
我们将通过提及一些重要的事项来结束对class关键字的介绍,这些事项从class语法中并不明显:
-
class声明体内的所有代码都隐式地处于严格模式中(§5.6.3),即使没有出现"use strict"指令。这意味着,例如,你不能在类体内使用八进制整数字面量或with语句,并且如果你忘记在使用之前声明一个变量,你更有可能得到语法错误。 -
与函数声明不同,类声明不会“被提升”。回想一下§8.1.1 中提到的函数定义行为,就好像它们已经被移动到了包含文件或包含函数的顶部,这意味着你可以在实际函数定义之前的代码中调用函数。尽管类声明在某些方面类似于函数声明,但它们不共享这种提升行为:你不能在声明类之前实例化它。
9.3.1 静态方法
你可以通过在class体中的方法声明前加上static关键字来定义一个静态方法。静态方法被定义为构造函数的属性,而不是原型对象的属性。
例如,假设我们在示例 9-3 中添加了以下代码:
static parse(s) {
let matches = s.match(/^\((\d+)\.\.\.(\d+)\)$/);
if (!matches) {
throw new TypeError(`Cannot parse Range from "${s}".`)
}
return new Range(parseInt(matches[1]), parseInt(matches[2]));
}
这段代码定义的方法是Range.parse(),而不是Range.prototype.parse(),你必须通过构造函数调用它,而不是通过实例调用:
let r = Range.parse('(1...10)'); // Returns a new Range object
r.parse('(1...10)'); // TypeError: r.parse is not a function
有时你会看到静态方法被称为类方法,因为它们是使用类/构造函数的名称调用的。当使用这个术语时,是为了将类方法与在类的实例上调用的常规实例方法进行对比。因为静态方法是在构造函数上调用而不是在任何特定实例上调用,所以在静态方法中几乎不可能使用this关键字。
我们将在示例 9-4 中看到静态方法的示例。
9.3.2 获取器、设置器和其他方法形式
在class体内,你可以像在对象字面量中一样定义获取器和设置器方法(§6.10.6),唯一的区别是在类体中,你不在获取器或设置器后面加逗号。示例 9-4 包括了一个类中获取器方法的实际示例。
一般来说,在对象字面量中允许的所有简写方法定义语法在类体中也是允许的。这包括生成器方法(用*标记)和方法的名称是方括号中表达式的值的方法。事实上,你已经在示例 9-3 中看到了一个具有计算名称的生成器方法,使得 Range 类可迭代:
*[Symbol.iterator]() {
for(let x = Math.ceil(this.from); x <= this.to; x++) yield x;
}
9.3.3 公共、私有和静态字段
在这里讨论使用class关键字定义的类时,我们只描述了类体内的方法定义。ES6 标准只允许创建方法(包括获取器、设置器和生成器)和静态方法;它不包括定义字段的语法。如果你想在类实例上定义一个字段(这只是面向对象的“属性”同义词),你必须在构造函数中或在其中一个方法中进行定义。如果你想为一个类定义一个静态字段,你必须在类体之外,在类定义之后进行定义。示例 9-4 包括了这两种字段的示例。
然而,标准化正在进行中,允许扩展类语法来定义实例和静态字段,包括公共和私有形式。截至 2020 年初,本节其余部分展示的代码尚不是标准 JavaScript,但已经在 Chrome 中得到支持,并在 Firefox 中部分支持(仅支持公共实例字段)。公共实例字段的语法已经被使用 React 框架和 Babel 转译器的 JavaScript 程序员广泛使用。
假设你正在编写一个像这样的类,其中包含一个初始化三个字段的构造函数:
class Buffer {
constructor() {
this.size = 0;
this.capacity = 4096;
this.buffer = new Uint8Array(this.capacity);
}
}
使用可能会被标准化的新实例字段语法,你可以这样写:
class Buffer {
size = 0;
capacity = 4096;
buffer = new Uint8Array(this.capacity);
}
字段初始化代码已经从构造函数中移出,现在直接出现在类体中。(当然,该代码仍然作为构造函数的一部分运行。如果你没有定义构造函数,那么字段将作为隐式创建的构造函数的一部分进行初始化。)出现在赋值左侧的this.前缀已经消失,但请注意,即使在初始化赋值的右侧,你仍然必须使用this.来引用这些字段。以这种方式初始化实例字段的优势在于,这种语法允许(但不要求)你将初始化器放在类定义的顶部,清楚地告诉读者每个实例的状态将由哪些字段保存。你可以通过只写字段名称后跟一个分号来声明没有初始化器的字段。如果这样做,字段的初始值将为undefined。对于所有类字段,始终明确指定初始值是更好的风格。
在添加此字段语法之前,类体看起来很像使用快捷方法语法的对象文字,只是逗号已被移除。这种带有等号和分号而不是冒号和逗号的字段语法清楚地表明类体与对象文字完全不同。
与寻求标准化这些实例字段的提案相同,还定义了私有实例字段。如果你使用前面示例中显示的实例字段初始化语法来定义一个以#开头的字段(这在 JavaScript 标识符中通常不是合法字符),那么该字段将可以在类体内(带有#前缀)使用,但对于类体外的任何代码来说是不可见和不可访问的(因此是不可变的)。如果对于前面的假设的 Buffer 类,你希望确保类的用户不能无意中修改实例的size字段,那么你可以使用一个私有的#size字段,然后定义一个获取器函数来提供只读访问权限:
class Buffer {
#size = 0;
get size() { return this.#size; }
}
请注意,私有字段必须在使用之前使用这种新字段语法进行声明。除非在类体中直接包含字段的“声明”,否则不能在类的构造函数中只写this.#size = 0;。
最后,一个相关的提案旨在标准化static关键字用于字段。如果在公共或私有字段声明之前添加static,那么这些字段将作为构造函数的属性而不是实例的属性创建。考虑我们定义的静态Range.parse()方法。它包含一个可能很好地分解为自己的静态字段的相当复杂的正则表达式。使用提议的新静态字段语法,我们可以这样做:
static integerRangePattern = /^\((\d+)\.\.\.(\d+)\)$/;
static parse(s) {
let matches = s.match(Range.integerRangePattern);
if (!matches) {
throw new TypeError(`Cannot parse Range from "${s}".`)
}
return new Range(parseInt(matches[1]), matches[2]);
}
如果我们希望这个静态字段只能在类内部访问,我们可以使用类似#pattern的私有名称。
9.3.4 示例:复数类
示例 9-4 定义了一个表示复数的类。这个类相对简单,但包括实例方法(包括获取器)、静态方法、实例字段和静态字段。它包含了一些被注释掉的代码,演示了我们如何使用尚未标准化的语法来在类体内定义实例字段和静态字段。
示例 9-4. Complex.js:一个复数类
/**
* Instances of this Complex class represent complex numbers.
* Recall that a complex number is the sum of a real number and an
* imaginary number and that the imaginary number i is the square root of -1.
*/
class Complex {
// Once class field declarations are standardized, we could declare
// private fields to hold the real and imaginary parts of a complex number
// here, with code like this:
//
// #r = 0;
// #i = 0;
// This constructor function defines the instance fields r and i on every
// instance it creates. These fields hold the real and imaginary parts of
// the complex number: they are the state of the object.
constructor(real, imaginary) {
this.r = real; // This field holds the real part of the number.
this.i = imaginary; // This field holds the imaginary part.
}
// Here are two instance methods for addition and multiplication
// of complex numbers. If c and d are instances of this class, we
// might write c.plus(d) or d.times(c)
plus(that) {
return new Complex(this.r + that.r, this.i + that.i);
}
times(that) {
return new Complex(this.r * that.r - this.i * that.i,
this.r * that.i + this.i * that.r);
}
// And here are static variants of the complex arithmetic methods.
// We could write Complex.sum(c,d) and Complex.product(c,d)
static sum(c, d) { return c.plus(d); }
static product(c, d) { return c.times(d); }
// These are some instance methods that are defined as getters
// so they're used like fields. The real and imaginary getters would
// be useful if we were using private fields this.#r and this.#i
get real() { return this.r; }
get imaginary() { return this.i; }
get magnitude() { return Math.hypot(this.r, this.i); }
// Classes should almost always have a toString() method
toString() { return `{${this.r},${this.i}}`; }
// It is often useful to define a method for testing whether
// two instances of your class represent the same value
equals(that) {
return that instanceof Complex &&
this.r === that.r &&
this.i === that.i;
}
// Once static fields are supported inside class bodies, we could
// define a useful Complex.ZERO constant like this:
// static ZERO = new Complex(0,0);
}
// Here are some class fields that hold useful predefined complex numbers.
Complex.ZERO = new Complex(0,0);
Complex.ONE = new Complex(1,0);
Complex.I = new Complex(0,1);
使用示例 9-4 中定义的 Complex 类,我们可以使用构造函数、实例字段、实例方法、类字段和类方法的代码如下:
let c = new Complex(2, 3); // Create a new object with the constructor
let d = new Complex(c.i, c.r); // Use instance fields of c
c.plus(d).toString() // => "{5,5}"; use instance methods
c.magnitude // => Math.hypot(2,3); use a getter function
Complex.product(c, d) // => new Complex(0, 13); a static method
Complex.ZERO.toString() // => "{0,0}"; a static property
9.4 为现有类添加方法
JavaScript 的基于原型的继承机制是动态的:一个对象从其原型继承属性,即使原型的属性在对象创建后发生变化。这意味着我们可以通过简单地向其原型对象添加新方法来增强 JavaScript 类。
例如,这里是为计算复共轭添加一个方法到示例 9-4 的 Complex 类的代码:
// Return a complex number that is the complex conjugate of this one.
Complex.prototype.conj = function() { return new Complex(this.r, -this.i); };
JavaScript 内置类的原型对象也是开放的,这意味着我们可以向数字、字符串、数组、函数等添加方法。这对于在语言的旧版本中实现新的语言特性很有用:
// If the new String method startsWith() is not already defined...
if (!String.prototype.startsWith) {
// ...then define it like this using the older indexOf() method.
String.prototype.startsWith = function(s) {
return this.indexOf(s) === 0;
};
}
这里是另一个例子:
// Invoke the function f this many times, passing the iteration number
// For example, to print "hello" 3 times:
// let n = 3;
// n.times(i => { console.log(`hello ${i}`); });
Number.prototype.times = function(f, context) {
let n = this.valueOf();
for(let i = 0; i < n; i++) f.call(context, i);
};
像这样向内置类型的原型添加方法通常被认为是一个坏主意,因为如果 JavaScript 的新版本定义了同名方法,将会导致混乱和兼容性问题。甚至可以向Object.prototype添加方法,使其对所有对象可用。但这绝不是一个好主意,因为添加到Object.prototype的属性对for/in循环可见(尽管您可以通过使用Object.defineProperty()[§14.1]使新属性不可枚举来避免这种情况)。
9.5 子类
在面向对象编程中,一个类 B 可以扩展或子类化另一个类 A。我们说 A 是超类,B 是子类。B 的实例继承 A 的方法。类 B 可以定义自己的方法,其中一些可能会覆盖类 A 定义的同名方法。如果 B 的方法覆盖了 A 的方法,那么 B 中的覆盖方法通常需要调用 A 中被覆盖的方法。同样,子类构造函数B()通常必须调用超类构造函数A(),以确保实例完全初始化。
本节首先展示了如何以旧的、ES6 之前的方式定义子类,然后迅速转向演示使用class和extends关键字以及使用super关键字调用超类构造方法的子类化。接下来是一个关于避免子类化,依靠对象组合而不是继承的子节。本节以一个定义了一系列 Set 类的扩展示例结束,并演示了如何使用抽象类来将接口与实现分离。
9.5.1 子类和原型
假设我们想要定义一个 Span 子类,继承自示例 9-2 的 Range 类。这个子类将像 Range 一样工作,但不是用起始和结束来初始化,而是指定一个起始和一个距离,或者跨度。Span 类的一个实例也是 Range 超类的一个实例。跨度实例从Span.prototype继承了一个定制的toString()方法,但为了成为 Range 的子类,它还必须从Range.prototype继承方法(如includes())。
示例 9-5. Span.js:Range 的一个简单子类
// This is the constructor function for our subclass
function Span(start, span) {
if (span >= 0) {
this.from = start;
this.to = start + span;
} else {
this.to = start;
this.from = start + span;
}
}
// Ensure that the Span prototype inherits from the Range prototype
Span.prototype = Object.create(Range.prototype);
// We don't want to inherit Range.prototype.constructor, so we
// define our own constructor property.
Span.prototype.constructor = Span;
// By defining its own toString() method, Span overrides the
// toString() method that it would otherwise inherit from Range.
Span.prototype.toString = function() {
return `(${this.from}... +${this.to - this.from})`;
};
为了使 Span 成为 Range 的一个子类,我们需要让Span.prototype从Range.prototype继承。在前面示例中的关键代码行是这一行,如果这对你有意义,你就理解了 JavaScript 中子类是如何工作的:
Span.prototype = Object.create(Range.prototype);
使用Span()构造函数创建的对象将从Span.prototype对象继承。但我们创建该对象是为了从Range.prototype继承,因此 Span 对象将同时从Span.prototype和Range.prototype继承。
你可能注意到我们的Span()构造函数设置了与Range()构造函数相同的from和to属性,因此不需要调用Range()构造函数来初始化新对象。类似地,Span 的toString()方法完全重新实现了字符串转换,而不需要调用 Range 的toString()版本。这使 Span 成为一个特殊情况,我们只能在了解超类的实现细节时才能这样做。一个健壮的子类化机制需要允许类调用其超类的方法和构造函数,但在 ES6 之前,JavaScript 没有简单的方法来做这些事情。
幸运的是,ES6 通过super关键字作为class语法的一部分解决了这些问题。下一节将演示它是如何工作的。
9.5.2 使用 extends 和 super 创建子类
在 ES6 及更高版本中,你可以通过在类声明中添加extends子句来简单地创建一个超类,甚至可以对内置类这样做:
// A trivial Array subclass that adds getters for the first and last elements.
class EZArray extends Array {
get first() { return this[0]; }
get last() { return this[this.length-1]; }
}
let a = new EZArray();
a instanceof EZArray // => true: a is subclass instance
a instanceof Array // => true: a is also a superclass instance.
a.push(1,2,3,4); // a.length == 4; we can use inherited methods
a.pop() // => 4: another inherited method
a.first // => 1: first getter defined by subclass
a.last // => 3: last getter defined by subclass
a[1] // => 2: regular array access syntax still works.
Array.isArray(a) // => true: subclass instance really is an array
EZArray.isArray(a) // => true: subclass inherits static methods, too!
这个 EZArray 子类定义了两个简单的 getter 方法。EZArray 的实例表现得像普通数组,我们可以使用继承的方法和属性,比如push()、pop()和length。但我们也可以使用子类中定义的first和last getter。不仅实例方法像pop()被继承了,静态方法像Array.isArray也被继承了。这是 ES6 类语法启用的一个新特性:EZArray()是一个函数,但它继承自Array():
// EZArray inherits instance methods because EZArray.prototype
// inherits from Array.prototype
Array.prototype.isPrototypeOf(EZArray.prototype) // => true
// And EZArray inherits static methods and properties because
// EZArray inherits from Array. This is a special feature of the
// extends keyword and is not possible before ES6.
Array.isPrototypeOf(EZArray) // => true
我们的 EZArray 子类过于简单,无法提供很多指导性。示例 9-6 是一个更加完整的示例。它定义了一个 TypedMap 的子类,继承自内置的 Map 类,并添加了类型检查以确保地图的键和值是指定类型(根据typeof)。重要的是,这个示例演示了使用super关键字来调用超类的构造函数和方法。
示例 9-6. TypedMap.js:检查键和值类型的 Map 子类
class TypedMap extends Map {
constructor(keyType, valueType, entries) {
// If entries are specified, check their types
if (entries) {
for(let [k, v] of entries) {
if (typeof k !== keyType || typeof v !== valueType) {
throw new TypeError(`Wrong type for entry [${k}, ${v}]`);
}
}
}
// Initialize the superclass with the (type-checked) initial entries
super(entries);
// And then initialize this subclass by storing the types
this.keyType = keyType;
this.valueType = valueType;
}
// Now redefine the set() method to add type checking for any
// new entries added to the map.
set(key, value) {
// Throw an error if the key or value are of the wrong type
if (this.keyType && typeof key !== this.keyType) {
throw new TypeError(`${key} is not of type ${this.keyType}`);
}
if (this.valueType && typeof value !== this.valueType) {
throw new TypeError(`${value} is not of type ${this.valueType}`);
}
// If the types are correct, we invoke the superclass's version of
// the set() method, to actually add the entry to the map. And we
// return whatever the superclass method returns.
return super.set(key, value);
}
}
TypedMap()构造函数的前两个参数是期望的键和值类型。这些应该是字符串,比如“number”和“boolean”,这是typeof运算符返回的。你还可以指定第三个参数:一个包含[key,value]数组的数组(或任何可迭代对象),指定地图中的初始条目。如果指定了任何初始条目,构造函数首先验证它们的类型是否正确。接下来,构造函数使用super关键字调用超类构造函数,就像它是一个函数名一样。Map()构造函数接受一个可选参数:一个包含[key,value]数组的可迭代对象。因此,TypedMap()构造函数的可选第三个参数是Map()构造函数的可选第一个参数,我们使用super(entries)将其传递给超类构造函数。
在调用超类构造函数初始化超类状态后,TypedMap()构造函数接下来通过设置this.keyType和this.valueType来初始化自己的子类状态。它需要设置这些属性以便在set()方法中再次使用它们。
在构造函数中使用super()时,有一些重要的规则你需要知道:
-
如果你用
extends关键字定义一个类,那么你的类的构造函数必须使用super()来调用超类构造函数。 -
如果你在子类中没有定义构造函数,系统会自动为你定义一个。这个隐式定义的构造函数简单地接受传递给它的任何值,并将这些值传递给
super()。 -
在调用
super()之前,你不能在构造函数中使用this关键字。这强制了一个规则,即超类在子类之前初始化。 -
特殊表达式
new.target在没有使用new关键字调用的函数中是未定义的。然而,在构造函数中,new.target是对被调用的构造函数的引用。当子类构造函数被调用并使用super()来调用超类构造函数时,那个超类构造函数将会把子类构造函数视为new.target的值。一个设计良好的超类不应该知道自己是否被子类化,但在日志消息中使用new.target.name可能会很有用。
在构造函数之后,示例 9-6 的下一部分是一个名为set()的方法。Map 超类定义了一个名为set()的方法来向地图添加新条目。我们说这个 TypedMap 中的set()方法覆盖了其超类的set()方法。这个简单的 TypedMap 子类对于向地图添加新条目一无所知,但它知道如何检查类型,所以首先进行类型检查,验证要添加到地图中的键和值是否具有正确的类型,如果不是则抛出错误。这个set()方法没有任何方法将键和值添加到地图本身,但这就是超类set()方法的作用。因此,我们再次使用super关键字来调用超类的方法版本。在这个上下文中,super的工作方式很像this关键字:它引用当前对象但允许访问在超类中定义的重写方法。
在构造函数中,你必须在访问this并自己初始化新对象之前调用超类构造函数。当你重写一个方法时,没有这样的规则。重写超类方法的方法不需要调用超类方法。如果它确实使用super来调用被重写的方法(或超类中的任何方法),它可以在重写方法的开始、中间或结尾进行调用。
最后,在我们离开 TypedMap 示例之前,值得注意的是,这个类是使用私有字段的理想候选。目前这个类的写法,用户可以更改keyType或valueType属性以规避类型检查。一旦支持私有字段,我们可以将这些属性更改为#keyType和#valueType,这样它们就无法从外部更改。
9.5.3 代理而非继承
extends关键字使创建子类变得容易。但这并不意味着你应该创建大量子类。如果你想编写一个共享某个其他类行为的类,你可以尝试通过创建子类来继承该行为。但通常更容易和更灵活的方法是通过让你的类创建另一个类的实例并根据需要简单地委托给该实例来获得所需的行为。你创建一个新类不是通过子类化,而是通过包装或“组合”其他类。这种委托方法通常被称为“组合”,并且面向对象编程的一个经常引用的格言是应该“优先选择组合而非继承”。²
例如,假设我们想要一个直方图类,其行为类似于 JavaScript 的 Set 类,但不仅仅是跟踪值是否已添加到集合中,而是维护值已添加的次数。因为这个直方图类的 API 类似于 Set,我们可以考虑继承 Set 并添加一个count()方法。另一方面,一旦我们开始考虑如何实现这个count()方法,我们可能会意识到直方图类更像是一个 Map 而不是一个 Set,因为它需要维护值和它们被添加的次数之间的映射关系。因此,我们可以创建一个定义了类似 Set API 的类,但通过委托给内部 Map 对象来实现这些方法。示例 9-7 展示了我们如何做到这一点。
示例 9-7. Histogram.js:使用委托实现的类似 Set 的类
/**
* A Set-like class that keeps track of how many times a value has
* been added. Call add() and remove() like you would for a Set, and
* call count() to find out how many times a given value has been added.
* The default iterator yields the values that have been added at least
* once. Use entries() if you want to iterate [value, count] pairs.
*/
class Histogram {
// To initialize, we just create a Map object to delegate to
constructor() { this.map = new Map(); }
// For any given key, the count is the value in the Map, or zero
// if the key does not appear in the Map.
count(key) { return this.map.get(key) || 0; }
// The Set-like method has() returns true if the count is non-zero
has(key) { return this.count(key) > 0; }
// The size of the histogram is just the number of entries in the Map.
get size() { return this.map.size; }
// To add a key, just increment its count in the Map.
add(key) { this.map.set(key, this.count(key) + 1); }
// Deleting a key is a little trickier because we have to delete
// the key from the Map if the count goes back down to zero.
delete(key) {
let count = this.count(key);
if (count === 1) {
this.map.delete(key);
} else if (count > 1) {
this.map.set(key, count - 1);
}
}
// Iterating a Histogram just returns the keys stored in it
[Symbol.iterator]() { return this.map.keys(); }
// These other iterator methods just delegate to the Map object
keys() { return this.map.keys(); }
values() { return this.map.values(); }
entries() { return this.map.entries(); }
}
示例 9-7 中的Histogram()构造函数只是创建了一个 Map 对象。大多数方法都只是简单地委托给地图的一个方法,使得实现非常简单。因为我们使用了委托而不是继承,一个 Histogram 对象不是 Set 或 Map 的实例。但 Histogram 实现了许多常用的 Set 方法,在像 JavaScript 这样的无类型语言中,这通常已经足够了:正式的继承关系有时很好,但通常是可选的。
9.5.4 类层次结构和抽象类
示例 9-6 演示了我们如何继承 Map。示例 9-7 演示了我们如何委托给一个 Map 对象而不实际继承任何东西。使用 JavaScript 类来封装数据和模块化代码通常是一个很好的技术,你可能会经常使用class关键字。但你可能会发现你更喜欢组合而不是继承,并且很少需要使用extends(除非你使用要求你扩展其基类的库或框架)。
然而,在某些情况下,多级子类化是合适的,我们将以一个扩展示例结束本章,该示例演示了代表不同类型集合的类的层次结构。(示例 9-8 中定义的集合类与 JavaScript 内置的 Set 类类似,但不完全兼容。)
示例 9-8 定义了许多子类,但它还演示了如何定义抽象类——不包括完整实现的类——作为一组相关子类的共同超类。抽象超类可以定义所有子类继承和共享的部分实现。然后,子类只需要通过实现超类定义但未实现的抽象方法来定义自己的独特行为。请注意,JavaScript 没有任何正式定义抽象方法或抽象类的规定;我在这里仅仅是使用这个名称来表示未实现的方法和未完全实现的类。
示例 9-8 有很好的注释,可以独立运行。我鼓励你将其作为本章关于类的顶尖示例来阅读。在示例 9-8 中的最终类使用了&、|和~运算符进行大量的位操作,你可以在§4.8.3 中复习。
示例 9-8. Sets.js:抽象和具体集合类的层次结构
/**
* The AbstractSet class defines a single abstract method, has().
*/
class AbstractSet {
// Throw an error here so that subclasses are forced
// to define their own working version of this method.
has(x) { throw new Error("Abstract method"); }
}
/**
* NotSet is a concrete subclass of AbstractSet.
* The members of this set are all values that are not members of some
* other set. Because it is defined in terms of another set it is not
* writable, and because it has infinite members, it is not enumerable.
* All we can do with it is test for membership and convert it to a
* string using mathematical notation.
*/
class NotSet extends AbstractSet {
constructor(set) {
super();
this.set = set;
}
// Our implementation of the abstract method we inherited
has(x) { return !this.set.has(x); }
// And we also override this Object method
toString() { return `{ x| x ∉ ${this.set.toString()} }`; }
}
/**
* Range set is a concrete subclass of AbstractSet. Its members are
* all values that are between the from and to bounds, inclusive.
* Since its members can be floating point numbers, it is not
* enumerable and does not have a meaningful size.
*/
class RangeSet extends AbstractSet {
constructor(from, to) {
super();
this.from = from;
this.to = to;
}
has(x) { return x >= this.from && x <= this.to; }
toString() { return `{ x| ${this.from} ≤ x ≤ ${this.to} }`; }
}
/*
* AbstractEnumerableSet is an abstract subclass of AbstractSet. It defines
* an abstract getter that returns the size of the set and also defines an
* abstract iterator. And it then implements concrete isEmpty(), toString(),
* and equals() methods on top of those. Subclasses that implement the
* iterator, the size getter, and the has() method get these concrete
* methods for free.
*/
class AbstractEnumerableSet extends AbstractSet {
get size() { throw new Error("Abstract method"); }
[Symbol.iterator]() { throw new Error("Abstract method"); }
isEmpty() { return this.size === 0; }
toString() { return `{${Array.from(this).join(", ")}}`; }
equals(set) {
// If the other set is not also Enumerable, it isn't equal to this one
if (!(set instanceof AbstractEnumerableSet)) return false;
// If they don't have the same size, they're not equal
if (this.size !== set.size) return false;
// Loop through the elements of this set
for(let element of this) {
// If an element isn't in the other set, they aren't equal
if (!set.has(element)) return false;
}
// The elements matched, so the sets are equal
return true;
}
}
/*
* SingletonSet is a concrete subclass of AbstractEnumerableSet.
* A singleton set is a read-only set with a single member.
*/
class SingletonSet extends AbstractEnumerableSet {
constructor(member) {
super();
this.member = member;
}
// We implement these three methods, and inherit isEmpty, equals()
// and toString() implementations based on these methods.
has(x) { return x === this.member; }
get size() { return 1; }
*[Symbol.iterator]() { yield this.member; }
}
/*
* AbstractWritableSet is an abstract subclass of AbstractEnumerableSet.
* It defines the abstract methods insert() and remove() that insert and
* remove individual elements from the set, and then implements concrete
* add(), subtract(), and intersect() methods on top of those. Note that
* our API diverges here from the standard JavaScript Set class.
*/
class AbstractWritableSet extends AbstractEnumerableSet {
insert(x) { throw new Error("Abstract method"); }
remove(x) { throw new Error("Abstract method"); }
add(set) {
for(let element of set) {
this.insert(element);
}
}
subtract(set) {
for(let element of set) {
this.remove(element);
}
}
intersect(set) {
for(let element of this) {
if (!set.has(element)) {
this.remove(element);
}
}
}
}
/**
* A BitSet is a concrete subclass of AbstractWritableSet with a
* very efficient fixed-size set implementation for sets whose
* elements are non-negative integers less than some maximum size.
*/
class BitSet extends AbstractWritableSet {
constructor(max) {
super();
this.max = max; // The maximum integer we can store.
this.n = 0; // How many integers are in the set
this.numBytes = Math.floor(max / 8) + 1; // How many bytes we need
this.data = new Uint8Array(this.numBytes); // The bytes
}
// Internal method to check if a value is a legal member of this set
_valid(x) { return Number.isInteger(x) && x >= 0 && x <= this.max; }
// Tests whether the specified bit of the specified byte of our
// data array is set or not. Returns true or false.
_has(byte, bit) { return (this.data[byte] & BitSet.bits[bit]) !== 0; }
// Is the value x in this BitSet?
has(x) {
if (this._valid(x)) {
let byte = Math.floor(x / 8);
let bit = x % 8;
return this._has(byte, bit);
} else {
return false;
}
}
// Insert the value x into the BitSet
insert(x) {
if (this._valid(x)) { // If the value is valid
let byte = Math.floor(x / 8); // convert to byte and bit
let bit = x % 8;
if (!this._has(byte, bit)) { // If that bit is not set yet
this.data[byte] |= BitSet.bits[bit]; // then set it
this.n++; // and increment set size
}
} else {
throw new TypeError("Invalid set element: " + x );
}
}
remove(x) {
if (this._valid(x)) { // If the value is valid
let byte = Math.floor(x / 8); // compute the byte and bit
let bit = x % 8;
if (this._has(byte, bit)) { // If that bit is already set
this.data[byte] &= BitSet.masks[bit]; // then unset it
this.n--; // and decrement size
}
} else {
throw new TypeError("Invalid set element: " + x );
}
}
// A getter to return the size of the set
get size() { return this.n; }
// Iterate the set by just checking each bit in turn.
// (We could be a lot more clever and optimize this substantially)
*[Symbol.iterator]() {
for(let i = 0; i <= this.max; i++) {
if (this.has(i)) {
yield i;
}
}
}
}
// Some pre-computed values used by the has(), insert() and remove() methods
BitSet.bits = new Uint8Array([1, 2, 4, 8, 16, 32, 64, 128]);
BitSet.masks = new Uint8Array([~1, ~2, ~4, ~8, ~16, ~32, ~64, ~128]);
9.6 总结
本章已经解释了 JavaScript 类的关键特性:
-
同一类的对象从相同的原型对象继承属性。原型对象是 JavaScript 类的关键特性,可以仅使用
Object.create()方法定义类。 -
在 ES6 之前,类通常是通过首先定义构造函数来定义的。使用
function关键字创建的函数具有一个prototype属性,该属性的值是一个对象,当使用new作为构造函数调用函数时,该对象被用作所有创建的对象的原型。通过初始化这个原型对象,您可以定义类的共享方法。虽然原型对象是类的关键特征,但构造函数是类的公共标识。 -
ES6 引入了
class关键字,使得定义类更容易,但在底层,构造函数和原型机制仍然保持不变。 -
子类是在类声明中使用
extends关键字定义的。 -
子类可以使用
super关键字调用其父类的构造函数或重写的方法。
¹ 除了 ES5 的Function.bind()方法返回的函数。绑定函数没有自己的原型属性,但如果作为构造函数调用它们,则它们使用基础函数的原型。
² 例如,参见 Erich Gamma 等人的设计模式(Addison-Wesley Professional)或 Joshua Bloch 的Effective Java(Addison-Wesley Professional)。
第十章:模块
模块化编程的目标是允许从不同作者和来源的代码模块组装大型程序,并且所有这些代码在各个模块作者未预料到的代码存在的情况下仍能正确运行。 从实际角度来看,模块化主要是关于封装或隐藏私有实现细节,并保持全局命名空间整洁,以便模块不会意外修改其他模块定义的变量、函数和类。
直到最近,JavaScript 没有内置模块支持,而在大型代码库上工作的程序员尽力利用类、对象和闭包提供的弱模块化。基于闭包的模块化,结合代码捆绑工具的支持,形成了一种基于require()函数的实用模块化形式,这被 Node 所采用。 基于require()的模块是 Node 编程环境的基本组成部分,但从未被正式纳入 JavaScript 语言的一部分。 相反,ES6 使用import和export关键字定义模块。 尽管import和export多年来一直是语言的一部分,但它们最近才被 Web 浏览器和 Node 实现。 作为一个实际问题,JavaScript 模块化仍然依赖于代码捆绑工具。
接下来的章节涵盖:
-
使用类、对象和闭包自行创建模块
-
使用
require()的 Node 模块 -
使用
export、import和import()的 ES6 模块
10.1 使用类、对象和闭包的模块
尽管这可能是显而易见的,但值得指出的是,类的一个重要特性是它们作为其方法的模块。 回想一下示例 9-8。 该示例定义了许多不同的类,所有这些类都有一个名为has()的方法。 但是,您可以毫无问题地编写一个使用该示例中多个集合类的程序:例如,SingletonSet 的has()方法不会覆盖 BitSet 的has()方法。
一个类的方法独立于其他不相关类的方法的原因是,每个类的方法被定义为独立原型对象的属性。 类是模块化的原因是对象是模块化的:在 JavaScript 对象中定义属性很像声明变量,但向对象添加属性不会影响程序的全局命名空间,也不会影响其他对象的属性。 JavaScript 定义了相当多的数学函数和常量,但是不是将它们全部定义为全局的,而是将它们作为单个全局 Math 对象的属性分组。 这种技术可以在示例 9-8 中使用。 该示例可以被编写为仅定义一个名为 Sets 的全局对象,其属性引用各种类。 使用此 Sets 库的用户可以使用类似Sets.Singleton和Sets.Bit的名称引用类。
在 JavaScript 编程中,使用类和对象进行模块化是一种常见且有用的技术,但这还不够。 特别是,它没有提供任何隐藏模块内部实现细节的方法。 再次考虑示例 9-8。 如果我们将该示例编写为一个模块,也许我们希望将各种抽象类保留在模块内部,只将具体子类提供给模块的用户。 同样,在 BitSet 类中,_valid()和_has()方法是内部实用程序,不应该真正暴露给类的用户。 BitSet.bits和BitSet.masks是最好隐藏的实现细节。
正如我们在 §8.6 中看到的,函数内声明的局部变量和嵌套函数对该函数是私有的。这意味着我们可以使用立即调用的函数表达式通过将实现细节和实用函数隐藏在封闭函数中,使模块的公共 API 成为函数的返回值来实现一种模块化。对于 BitSet 类,我们可以将模块结构化如下:
const BitSet = (function() { // Set BitSet to the return value of this function
// Private implementation details here
function isValid(set, n) { ... }
function has(set, byte, bit) { ... }
const BITS = new Uint8Array([1, 2, 4, 8, 16, 32, 64, 128]);
const MASKS = new Uint8Array([~1, ~2, ~4, ~8, ~16, ~32, ~64, ~128]);
// The public API of the module is just the BitSet class, which we define
// and return here. The class can use the private functions and constants
// defined above, but they will be hidden from users of the class
return class BitSet extends AbstractWritableSet {
// ... implementation omitted ...
};
}());
当模块中有多个项时,这种模块化方法变得更加有趣。例如,以下代码定义了一个迷你统计模块,导出 mean() 和 stddev() 函数,同时隐藏了实现细节:
// This is how we could define a stats module
const stats = (function() {
// Utility functions private to the module
const sum = (x, y) => x + y;
const square = x => x * x;
// A public function that will be exported
function mean(data) {
return data.reduce(sum)/data.length;
}
// A public function that we will export
function stddev(data) {
let m = mean(data);
return Math.sqrt(
data.map(x => x - m).map(square).reduce(sum)/(data.length-1)
);
}
// We export the public function as properties of an object
return { mean, stddev };
}());
// And here is how we might use the module
stats.mean([1, 3, 5, 7, 9]) // => 5
stats.stddev([1, 3, 5, 7, 9]) // => Math.sqrt(10)
10.1.1 自动化基于闭包的模块化
请注意,将 JavaScript 代码文件转换为这种模块的过程是一个相当机械化的过程,只需在文件开头和结尾插入一些文本即可。所需的只是一些约定,用于指示哪些值要导出,哪些不要导出。
想象一个工具,它接受一组文件,将每个文件的内容包装在立即调用的函数表达式中,跟踪每个函数的返回值,并将所有内容连接成一个大文件。结果可能看起来像这样:
const modules = {};
function require(moduleName) { return modules[moduleName]; }
modules["sets.js"] = (function() {
const exports = {};
// The contents of the sets.js file go here:
exports.BitSet = class BitSet { ... };
return exports;
}());
modules["stats.js"] = (function() {
const exports = {};
// The contents of the stats.js file go here:
const sum = (x, y) => x + y;
const square = x = > x * x;
exports.mean = function(data) { ... };
exports.stddev = function(data) { ... };
return exports;
}());
将模块捆绑成一个单一文件,就像前面示例中所示的那样,你可以想象编写以下代码来利用这些模块:
// Get references to the modules (or the module content) that we need
const stats = require("stats.js");
const BitSet = require("sets.js").BitSet;
// Now write code using those modules
let s = new BitSet(100);
s.insert(10);
s.insert(20);
s.insert(30);
let average = stats.mean([...s]); // average is 20
这段代码是对代码捆绑工具(如 webpack 和 Parcel)在 web 浏览器中的工作原理的粗略草图,也是对类似于 Node 程序中使用的 require() 函数的简单介绍。
10.2 Node 模块
在 Node 编程中,将程序分割为尽可能多的文件是很正常的。这些 JavaScript 代码文件都假定存在于一个快速的文件系统上。与 web 浏览器不同,后者必须通过相对较慢的网络连接读取 JavaScript 文件,将 Node 程序捆绑成一个单一的 JavaScript 文件既没有必要也没有好处。
在 Node 中,每个文件都是具有私有命名空间的独立模块。在一个文件中定义的常量、变量、函数和类对该文件是私有的,除非文件导出它们。一个模块导出的值只有在另一个模块明确导入它们时才能看到。
Node 模块通过 require() 函数导入其他模块,并通过设置 Exports 对象的属性或完全替换 module.exports 对象来导出它们的公共 API。
10.2.1 Node 导出
Node 定义了一个全局的 exports 对象,它总是被定义。如果你正在编写一个导出多个值的 Node 模块,你可以简单地将它们分配给这个对象的属性:
const sum = (x, y) => x + y;
const square = x => x * x;
exports.mean = data => data.reduce(sum)/data.length;
exports.stddev = function(d) {
let m = exports.mean(d);
return Math.sqrt(d.map(x => x - m).map(square).reduce(sum)/(d.length-1));
};
然而,通常情况下,你可能只想定义一个仅导出单个函数或类的模块,而不是一个充满函数或类的对象。为此,你只需将要导出的单个值分配给 module.exports:
module.exports = class BitSet extends AbstractWritableSet {
// implementation omitted
};
module.exports 的默认值是 exports 所指向的相同对象。在之前的 stats 模块中,我们可以将 mean 函数分配给 module.exports.mean 而不是 exports.mean。像 stats 模块这样的模块的另一种方法是在模块末尾导出一个单一对象,而不是在导出函数时逐个导出:
// Define all the functions, public and private
const sum = (x, y) => x + y;
const square = x => x * x;
const mean = data => data.reduce(sum)/data.length;
const stddev = d => {
let m = mean(d);
return Math.sqrt(d.map(x => x - m).map(square).reduce(sum)/(d.length-1));
};
// Now export only the public ones
module.exports = { mean, stddev };
10.2.2 Node 导入
一个 Node 模块通过调用 require() 函数来导入另一个模块。这个函数的参数是要导入的模块的名称,返回值是该模块导出的任何值(通常是一个函数、类或对象)。
如果你想导入 Node 内置的系统模块或通过包管理器在系统上安装的模块,那么你只需使用模块的未限定名称,不需要任何将其转换为文件系统路径的“/”字符:
// These modules are built in to Node
const fs = require("fs"); // The built-in filesystem module
const http = require("http"); // The built-in HTTP module
// The Express HTTP server framework is a third-party module.
// It is not part of Node but has been installed locally
const express = require("express");
当您想要导入自己代码的模块时,模块名称应该是包含该代码的文件的路径,相对于当前模块文件。使用以/字符开头的绝对路径是合法的,但通常,当导入属于您自己程序的模块时,模块名称将以*./ 或有时是../ *开头,以指示它们相对于当前目录或父目录。例如:
const stats = require('./stats.js');
const BitSet = require('./utils/bitset.js');
(您也可以省略导入文件的.js后缀,Node 仍然可以找到这些文件,但通常会看到这些文件扩展名明确包含在内。)
当一个模块只导出一个函数或类时,您只需导入它。当一个模块导出一个具有多个属性的对象时,您可以选择:您可以导入整个对象,或者只导入您打算使用的对象的特定属性(使用解构赋值)。比较这两种方法:
// Import the entire stats object, with all of its functions
const stats = require('./stats.js');
// We've got more functions than we need, but they're neatly
// organized into a convenient "stats" namespace.
let average = stats.mean(data);
// Alternatively, we can use idiomatic destructuring assignment to import
// exactly the functions we want directly into the local namespace:
const { stddev } = require('./stats.js');
// This is nice and succinct, though we lose a bit of context
// without the 'stats' prefix as a namspace for the stddev() function.
let sd = stddev(data);
10.2.3 Web 上的 Node 风格模块
具有 Exports 对象和require()函数的模块内置于 Node 中。但是,如果您愿意使用像 webpack 这样的捆绑工具处理您的代码,那么也可以将这种模块样式用于旨在在 Web 浏览器中运行的代码。直到最近,这是一种非常常见的做法,您可能会看到许多仍在这样做的基于 Web 的代码。
现在 JavaScript 有了自己的标准模块语法,然而,使用捆绑工具的开发人员更有可能使用带有import和export语句的官方 JavaScript 模块。
10.3 ES6 中的模块
ES6 为 JavaScript 添加了import和export关键字,最终将真正的模块化支持作为核心语言特性。ES6 的模块化在概念上与 Node 的模块化相同:每个文件都是自己的模块,文件中定义的常量、变量、函数和类除非明确导出,否则都是私有于该模块。从一个模块导出的值可以在明确导入它们的模块中使用。ES6 模块在导出和导入的语法以及在 Web 浏览器中定义模块的方式上与 Node 模块不同。接下来的部分将详细解释这些内容。
首先,请注意,ES6 模块在某些重要方面也与常规 JavaScript“脚本”不同。最明显的区别是模块化本身:在常规脚本中,变量、函数和类的顶级声明进入由所有脚本共享的单个全局上下文中。使用模块后,每个文件都有自己的私有上下文,并且可以使用import和export语句,这毕竟是整个重点。但模块和脚本之间还有其他区别。ES6 模块中的代码(就像 ES6 class定义内的代码一样)自动处于严格模式(参见§5.6.3)。这意味着,当您开始使用 ES6 模块时,您将永远不必再编写"use strict"。这意味着模块中的代码不能使用with语句或arguments对象或未声明的变量。ES6 模块甚至比严格模式稍微严格:在严格模式中,作为函数调用的函数中,this是undefined。在模块中,即使在顶级代码中,this也是undefined。(相比之下,Web 浏览器和 Node 中的脚本将this设置为全局对象。)
Web 上和 Node 中的 ES6 模块
多年来,借助像 webpack 这样的代码捆绑工具,ES6 模块已经在 Web 上得到了应用,这些工具将独立的 JavaScript 代码模块组合成大型、非模块化的捆绑包,适合包含在网页中。然而,在撰写本文时,除了 Internet Explorer 之外,所有 Web 浏览器终于原生支持 ES6 模块。在原生支持时,ES6 模块通过特殊的<script type="module">标签添加到 HTML 页面中,本章后面将对此进行描述。
与此同时,作为 JavaScript 模块化的先驱,Node 发现自己处于一个尴尬的位置,必须支持两种不完全兼容的模块系统。Node 13 支持 ES6 模块,但目前,绝大多数 Node 程序仍然使用 Node 模块。
10.3.1 ES6 导出
要从 ES6 模块中导出常量、变量、函数或类,只需在声明之前添加关键字export:
export const PI = Math.PI;
export function degreesToRadians(d) { return d * PI / 180; }
export class Circle {
constructor(r) { this.r = r; }
area() { return PI * this.r * this.r; }
}
作为在模块中散布export关键字的替代方案,你可以像通常一样定义常量、变量、函数和类,不写任何export语句,然后(通常在模块的末尾)写一个单独的export语句,声明在一个地方精确地导出了什么。因此,与在前面的代码中写三个单独的导出相反,我们可以在末尾写一行等效的代码:
export { Circle, degreesToRadians, PI };
这个语法看起来像是export关键字后跟一个对象字面量(使用简写表示法)。但在这种情况下,花括号实际上并没有定义一个对象字面量。这种导出语法只需要在花括号内写一个逗号分隔的标识符列表。
编写只导出一个值(通常是函数或类)的模块很常见,在这种情况下,我们通常使用export default而不是export:
export default class BitSet {
// implementation omitted
}
默认导出比非默认导出稍微容易导入,因此当只有一个导出值时,使用export default会使使用你导出值的模块更容易。
使用export进行常规导出只能用于具有名称的声明。使用export default进行默认导出可以导出任何表达式,包括匿名函数表达式和匿名类表达式。这意味着如果你使用export default,你可以导出对象字面量。因此,与export语法不同,如果你在export default后看到花括号,那么实际上导出的是一个对象字面量。
模块既有一组常规导出又有默认导出是合法的,但有些不太常见。如果一个模块有默认导出,它只能有一个。
最后,请注意export关键字只能出现在你的 JavaScript 代码的顶层。你不能从类、函数、循环或条件语句中导出值。(这是 ES6 模块系统的一个重要特性,它实现了静态分析:模块的导出在每次运行时都是相同的,并且可以在模块实际运行之前确定导出的符号。)
10.3.2 ES6 导入
你可以使用import关键字导入其他模块导出的值。最简单的导入形式用于定义默认导出的模块:
import BitSet from './bitset.js';
这是import关键字,后面跟着一个标识符,然后是from关键字,后面是一个字符串字面量,命名了我们要导入默认导出的模块。指定模块的默认导出值成为当前模块中指定标识符的值。
导入值分配给的标识符是一个常量,就好像它已经用const关键字声明过一样。与导出一样,导入只能出现在模块的顶层,不允许在类、函数、循环或条件语句中。根据普遍惯例,模块所需的导入应放在模块的开头。然而有趣的是,这并非必须:像函数声明一样,导入被“提升”到顶部,所有导入的值在模块的任何代码运行时都可用。
导入值的模块被指定为一个常量字符串文字,用单引号或双引号括起来。(您不能使用值为字符串的变量或其他表达式,也不能在反引号内使用字符串,因为模板文字可以插入变量并且不总是具有常量值。)在 Web 浏览器中,此字符串被解释为相对于执行导入操作的模块的位置的 URL。(在 Node 中,或者使用捆绑工具时,该字符串被解释为相对于当前模块的文件名,但在实践中这几乎没有区别。)模块规范符字符串必须是以“/”开头的绝对路径,或以“./”或“../”开头的相对路径,或具有协议和主机名的完整 URL。ES6 规范不允许未经限定的模块规范符字符串,如“util.js”,因为不清楚这是否意味着要命名与当前目录中的模块或某种安装在某个特殊位置的系统模块。 (这个对“裸模块规范符”的限制不被像 webpack 这样的代码捆绑工具所遵守,它可以很容易地配置为在您指定的库目录中找到裸模块。)语言的未来版本可能允许“裸模块规范符”,但目前不允许。如果要从与当前目录相同的目录导入模块,只需在模块名称前加上“./”,并从“./util.js”而不是“util.js”导入。
到目前为止,我们只考虑了从使用export default的模块导入单个值的情况。要从导出多个值的模块导入值,我们使用稍微不同的语法:
import { mean, stddev } from "./stats.js";
请记住,默认导出在定义它们的模块中不需要名称。相反,当我们导入这些值时,我们提供一个本地名称。但是,模块的非默认导出在导出模块中有名称,当我们导入这些值时,我们通过这些名称引用它们。导出模块可以导出任意数量的命名值。引用该模块的import语句可以通过在花括号内列出它们的名称来导入这些值的任意子集。花括号使这种import语句看起来有点像解构赋值,实际上,解构赋值是这种导入样式在做的事情的一个很好的类比。花括号内的标识符都被提升到导入模块的顶部,并且行为像常量。
样式指南有时建议您明确导入模块将使用的每个符号。但是,当从定义许多导出的模块导入时,您可以轻松地使用像这样的import语句导入所有内容:
import * as stats from "./stats.js";
像这样的import语句会创建一个对象,并将其赋值给名为stats的常量。被导入模块的每个非默认导出都成为这个stats对象的属性。非默认导出始终有名称,并且这些名称在对象内部用作属性名称。这些属性实际上是常量:它们不能被覆盖或删除。在前面示例中显示的通配符导入中,导入模块将通过stats对象使用导入的mean()和stddev()函数,调用它们为stats.mean()和stats.stddev()。
模块通常定义一个默认导出或多个命名导出。一个模块同时使用export和export default是合法的,但有点不常见。但是当一个模块这样做时,您可以使用像这样的import语句同时导入默认值和命名值:
import Histogram, { mean, stddev } from "./histogram-stats.js";
到目前为止,我们已经看到了如何从具有默认导出的模块和具有非默认或命名导出的模块导入。但是还有一种import语句的形式,用于没有任何导出的模块。要将没有任何导出的模块包含到您的程序中,只需使用import关键字与模块规范符:
import "./analytics.js";
这样的模块在第一次导入时运行。(随后的导入不会执行任何操作。)一个仅定义函数的模块只有在导出其中至少一个函数时才有用。但是,如果一个模块运行一些代码,那么即使没有符号,导入它也是有用的。一个用于 Web 应用程序的分析模块可能会运行代码来注册各种事件处理程序,然后在适当的时候使用这些事件处理程序将遥测数据发送回服务器。该模块是自包含的,不需要导出任何内容,但我们仍然需要import它,以便它实际上作为我们程序的一部分运行。
请注意,即使有导出的模块,您也可以使用这种导入空内容的import语法。如果一个模块定义了独立于其导出值的有用行为,并且您的程序不需要任何这些导出值,您仍然可以导入该模块。只是为了那个默认行为。
10.3.3 导入和重命名导出
如果两个模块使用相同名称导出两个不同的值,并且您想要导入这两个值,那么在导入时您将需要重命名其中一个或两个值。同样,如果您想要导入一个名称已在您的模块中使用的值,那么您将需要重命名导入的值。您可以使用带有命名导入的as关键字来重命名它们:
import { render as renderImage } from "./imageutils.js";
import { render as renderUI } from "./ui.js";
这些行将两个函数导入当前模块。这两个函数在定义它们的模块中都被命名为render(),但在导入时使用更具描述性和消除歧义的名称renderImage()和renderUI()。
请记住,默认导出没有名称。导入模块在导入默认导出时总是选择名称。因此,在这种情况下不需要特殊的重命名语法。
话虽如此,但在导入时重命名的可能性提供了另一种从定义默认导出和命名导出的模块中导入的方式。回想一下前一节中的“./histogram-stats.js”模块。以下是导入该模块的默认导出和命名导出的另一种方式:
import { default as Histogram, mean, stddev } from "./histogram-stats.js";
在这种情况下,JavaScript 关键字default充当占位符,并允许我们指示我们要导入并为模块的默认导出提供名称。
也可以在导出时重命名值,但只能在使用花括号变体的export语句时。通常不需要这样做,但如果您在模块内选择了简短、简洁的名称,您可能更喜欢使用更具描述性的名称导出值,这样就不太可能与其他模块发生冲突。与导入一样,您可以使用as关键字来执行此操作:
export {
layout as calculateLayout,
render as renderLayout
};
请记住,尽管花括号看起来有点像对象文字,但它们并不是,export关键字在as之前期望一个标识符,而不是一个表达式。这意味着不幸的是,您不能像这样使用导出重命名:
export { Math.sin as sin, Math.cos as cos }; // SyntaxError
10.3.4 重新导出
在本章中,我们讨论了一个假设的“./stats.js”模块,该模块导出mean()和stddev()函数。如果我们正在编写这样一个模块,并且我们认为该模块的许多用户只想要其中一个函数,那么我们可能希望在“./stats/mean.js”模块中定义mean(),在“./stats/stddev.js”中定义stddev()。这样,程序只需要导入它们需要的函数,而不会因导入不需要的代码而臃肿。
即使我们将这些统计函数定义在单独的模块中,我们可能仍然希望有很多程序需要这两个函数,并且希望有一个方便的“./stats.js”模块,可以在一行中导入这两个函数。
鉴于现在实现在单独的文件中,定义这个“./stat.js”模块很简单:
import { mean } from "./stats/mean.js";
import { stddev } from "./stats/stddev.js";
export { mean, stdev };
ES6 模块预期这种用法并为其提供了特殊的语法。不再简单地导入一个符号再导出它,你可以将导入和导出步骤合并为一个单独的“重新导出”语句,使用export关键字和from关键字:
export { mean } from "./stats/mean.js";
export { stddev } from "./stats/stddev.js";
请注意,此代码中实际上没有使用mean和stddev这两个名称。如果我们不选择性地重新导出并且只想从另一个模块导出所有命名值,我们可以使用通配符:
export * from "./stats/mean.js";
export * from "./stats/stddev.js";
重新导出语法允许使用as进行重命名,就像常规的import和export语句一样。假设我们想要重新导出mean()函数,但同时为该函数定义average()作为另一个名称。我们可以这样做:
export { mean, mean as average } from "./stats/mean.js";
export { stddev } from "./stats/stddev.js";
该示例中的所有重新导出都假定“./stats/mean.js”和“./stats/stddev.js”模块使用export而不是export default导出它们的函数。实际上,由于这些是只有一个导出的模块,定义为export default是有意义的。如果我们这样做了,那么重新导出语法会稍微复杂一些,因为它需要为未命名的默认导出定义一个名称。我们可以这样做:
export { default as mean } from "./stats/mean.js";
export { default as stddev } from "./stats/stddev.js";
如果你想要将另一个模块的命名符号重新导出为你的模块的默认导出,你可以进行import,然后进行export default,或者你可以将这两个语句结合起来,像这样:
// Import the mean() function from ./stats.js and make it the
// default export of this module
export { mean as default } from "./stats.js"
最后,要将另一个模块的默认导出重新导出为你的模块的默认导出(尽管不清楚为什么要这样做,因为用户可以直接导入另一个模块),你可以这样写:
// The average.js module simply re-exports the stats/mean.js default export
export { default } from "./stats/mean.js"
10.3.5 Web 上的 JavaScript 模块
前面的章节以一种相对抽象的方式描述了 ES6 模块及其import和export声明。在本节和下一节中,我们将讨论它们在 Web 浏览器中的实际工作方式,如果你还不是一名经验丰富的 Web 开发人员,你可能会发现在阅读第十五章之后更容易理解本章的其余内容。
截至 2020 年初,使用 ES6 模块的生产代码仍然通常与类似 webpack 的工具捆绑在一起。这样做存在一些权衡之处,¹但总体上,代码捆绑往往能提供更好的性能。随着网络速度的增长和浏览器厂商继续优化他们的 ES6 模块实现,这种情况可能会发生变化。
尽管捆绑工具在生产中仍然可取,但在开发中不再需要,因为所有当前的浏览器都提供了对 JavaScript 模块的原生支持。请记住,模块默认使用严格模式,this不指向全局对象,并且顶级声明默认情况下不会在全局范围内共享。由于模块必须以与传统非模块代码不同的方式执行,它们的引入需要对 HTML 和 JavaScript 进行更改。如果你想在 Web 浏览器中原生使用import指令,你必须通过使用<script type="module">标签告诉 Web 浏览器你的代码是一个模块。
ES6 模块的一个很好的特性是每个模块都有一个静态的导入集合。因此,给定一个起始模块,Web 浏览器可以加载所有导入的模块,然后加载第一批模块导入的所有模块,依此类推,直到完整的程序被加载。我们已经看到import语句中的模块指示符可以被视为相对 URL。<script type="module">标签标记了模块化程序的起点。然而,它导入的模块都不应该在<script>标签中,而是按需作为常规 JavaScript 文件加载,并像常规 ES6 模块一样以严格模式执行。使用<script type="module">标签来定义模块化 JavaScript 程序的主入口点可以像这样简单:
<script type="module">import "./main.js";</script>
内联<script type="module">标签中的代码是 ES6 模块,因此可以使用export语句。然而,这样做没有任何意义,因为 HTML <script>标签语法没有提供任何定义内联模块名称的方式,因此,即使这样的模块导出一个值,也没有办法让另一个模块导入它。
带有type="module"属性的脚本会像带有defer属性的脚本一样加载和执行。代码加载会在 HTML 解析器遇到<script>标签时开始(在模块的情况下,这个代码加载步骤可能是一个递归过程,加载多个 JavaScript 文件)。但是代码执行直到 HTML 解析完成才开始。一旦 HTML 解析完成,脚本(模块和非模块)将按照它们在 HTML 文档中出现的顺序执行。
您可以使用async属性修改模块的执行时间,这对于模块和常规脚本的工作方式是相同的。async模块将在代码加载后立即执行,即使 HTML 解析尚未完成,即使这会改变脚本的相对顺序。
支持<script type="module">的 Web 浏览器也必须支持<script nomodule>。了解模块的浏览器会忽略带有nomodule属性的任何脚本并且不会执行它。不支持模块的浏览器将不识别nomodule属性,因此它们会忽略它并运行脚本。这为处理浏览器兼容性问题提供了一个强大的技术。支持 ES6 模块的浏览器还支持其他现代 JavaScript 特性,如类、箭头函数和for/of循环。如果您编写现代 JavaScript 并使用<script type="module">加载它,您知道它只会被支持的浏览器加载。作为 IE11 的备用方案(在 2020 年,实际上是唯一一个不支持 ES6 的浏览器),您可以使用类似 Babel 和 webpack 的工具将您的代码转换为非模块化的 ES5 代码,然后通过<script nomodule>加载这些效率较低的转换代码。
常规脚本和模块脚本之间的另一个重要区别与跨域加载有关。常规的<script>标签将从互联网上的任何服务器加载 JavaScript 代码文件,互联网的广告、分析和跟踪代码基础设施依赖于这一事实。但是<script type="module">提供了一种加强这一点的机会,模块只能从包含 HTML 文档的同一源加载,或者在适当的 CORS 标头放置以安全地允许跨源加载时才能加载。这种新的安全限制的一个不幸副作用是,它使得使用file: URL 在开发模式下测试 ES6 模块变得困难。使用 ES6 模块时,您可能需要设置一个静态 Web 服务器进行测试。
一些程序员喜欢使用文件扩展名.mjs来区分他们的模块化 JavaScript 文件和传统.js扩展名的常规非模块化 JavaScript 文件。对于 Web 浏览器和<script>标签来说,文件扩展名实际上是无关紧要的。(但 MIME 类型是相关的,因此如果您使用.mjs文件,您可能需要配置您的 Web 服务器以相同的 MIME 类型提供它们,如.js文件。)Node 对 ES6 的支持确实使用文件扩展名作为提示来区分它加载的每个文件使用的模块系统。因此,如果您编写 ES6 模块并希望它们能够在 Node 中使用,采用.mjs命名约定可能会有所帮助。
10.3.6 使用 import()进行动态导入
我们已经看到 ES6 的 import 和 export 指令是完全静态的,并且使 JavaScript 解释器和其他 JavaScript 工具能够在加载模块时通过简单的文本分析确定模块之间的关系,而无需实际执行模块中的任何代码。使用静态导入的模块,你可以确保导入到模块中的值在你的模块中的任何代码开始运行之前就已经准备好供使用。
在 Web 上,代码必须通过网络传输,而不是从文件系统中读取。一旦传输,该代码通常在相对较慢的移动设备上执行。这不是静态模块导入(需要在任何代码运行之前加载整个程序)有很多意义的环境。
Web 应用程序通常只加载足够的代码来渲染用户看到的第一页。然后,一旦用户有一些初步内容可以交互,它们就可以开始加载通常需要更多的代码来完成网页应用程序的其余部分。Web 浏览器通过使用 DOM API 将新的 <script> 标签注入到当前 HTML 文档中,使动态加载代码变得容易,而 Web 应用程序多年来一直在这样做。
尽管动态加载已经很久了,但它并不是语言本身的一部分。这在 ES2020 中发生了变化(截至 2020 年初,支持 ES6 模块的所有浏览器都支持动态导入)。你将一个模块规范传递给 import(),它将返回一个代表加载和运行指定模块的异步过程的 Promise 对象。当动态导入完成时,Promise 将“完成”(请参阅 第十三章 了解有关异步编程和 Promise 的完整细节),并产生一个对象,就像你使用静态导入语句的 import * as 形式一样。
因此,我们可以像这样静态导入“./stats.js”模块:
import * as stats from "./stats.js";
我们可以像这样动态导入并使用它:
import("./stats.js").then(stats => {
let average = stats.mean(data);
})
或者,在一个 async 函数中(再次,你可能需要在理解这段代码之前阅读 第十三章),我们可以用 await 简化代码:
async analyzeData(data) {
let stats = await import("./stats.js");
return {
average: stats.mean(data),
stddev: stats.stddev(data)
};
}
import() 的参数应该是一个模块规范,就像你会在静态 import 指令中使用的那样。但是使用 import(),你不受限于使用常量字符串文字:任何表达式只要以正确形式评估为字符串即可。
动态 import() 看起来像一个函数调用,但实际上不是。相反,import() 是一个操作符,括号是操作符语法的必需部分。这种不寻常的语法之所以存在是因为 import() 需要能够将模块规范解析为相对于当前运行模块的 URL,这需要一些实现魔法,这是不合法的放在 JavaScript 函数中的。在实践中,函数与操作符的区别很少有影响,但如果尝试编写像 console.log(import); 或 let require = import; 这样的代码,你会注意到这一点。
最后,请注意动态 import() 不仅适用于 Web 浏览器。代码打包工具如 webpack 也可以很好地利用它。使用代码捆绑器的最简单方法是告诉它程序的主入口点,让它找到所有静态 import 指令并将所有内容组装成一个大文件。然而,通过策略性地使用动态 import() 调用,你可以将这个单一的庞大捆绑拆分成一组可以按需加载的较小捆绑。
10.3.7 import.meta.url
ES6 模块系统的最后一个特性需要讨论。在 ES6 模块中(但不在常规的 <script> 或使用 require() 加载的 Node 模块中),特殊语法 import.meta 指的是一个包含有关当前执行模块的元数据的对象。该对象的 url 属性是加载模块的 URL。(在 Node 中,这将是一个 file:// URL。)
import.meta.url 的主要用例是能够引用存储在与模块相同目录中(或相对于模块)的图像、数据文件或其他资源。URL() 构造函数使得相对 URL 相对于绝对 URL(如 import.meta.url)容易解析。例如,假设你编写了一个模块,其中包含需要本地化的字符串,并且本地化文件存储在与模块本身相同目录中的 l10n/ 目录中。你的模块可以使用类似这样的函数创建的 URL 加载其字符串:
function localStringsURL(locale) {
return new URL(`l10n/${locale}.json`, import.meta.url);
}
10.4 总结
模块化的目标是允许程序员隐藏其代码的实现细节,以便来自各种来源的代码块可以组装成大型程序,而不必担心一个代码块会覆盖另一个的函数或变量。本章已经解释了三种不同的 JavaScript 模块系统:
-
在 JavaScript 的早期,模块化只能通过巧妙地使用立即调用的函数表达式来实现。
-
Node 在 JavaScript 语言之上添加了自己的模块系统。Node 模块通过
require()导入,并通过设置 Exports 对象的属性或设置module.exports属性来定义它们的导出。 -
在 ES6 中,JavaScript 终于拥有了自己的模块系统,使用
import和export关键字,而 ES2020 正在添加对使用import()进行动态导入的支持。
¹ 例如:经常进行增量更新并且用户频繁返回访问的 Web 应用程序可能会发现,使用小模块而不是大捆绑包可以更好地利用用户浏览器缓存,从而导致更好的平均加载时间。
第十一章:JavaScript 标准库
一些数据类型,如数字和字符串(第三章)、对象(第六章)和数组(第七章)对于 JavaScript 来说是如此基础,以至于我们可以将它们视为语言本身的一部分。本章涵盖了其他重要但不太基础的 API,可以被视为 JavaScript 的“标准库”:这些是内置于 JavaScript 中的有用类和函数,可供所有 Web 浏览器和 Node 中的 JavaScript 程序使用。¹
本章的各节相互独立,您可以按任意顺序阅读它们。它们涵盖了:
-
Set 和 Map 类,用于表示值的集合和从一个值集合到另一个值集合的映射。
-
类型化数组(TypedArrays)等类似数组的对象,表示二进制数据的数组,以及用于从非数组二进制数据中提取值的相关类。
-
正则表达式和 RegExp 类,定义文本模式,对文本处理很有用。本节还详细介绍了正则表达式语法。
-
Date 类用于表示和操作日期和时间。
-
Error 类及其各种子类的实例,当 JavaScript 程序发生错误时抛出。
-
JSON 对象,其方法支持对由对象、数组、字符串、数字和布尔值组成的 JavaScript 数据结构进行序列化和反序列化。
-
Intl 对象及其定义的类,可帮助您本地化 JavaScript 程序。
-
Console 对象,其方法以特别有用的方式输出字符串,用于调试程序和记录程序的行为。
-
URL 类简化了解析和操作 URL 的任务。本节还涵盖了用于对 URL 及其组件进行编码和解码的全局函数。
-
setTimeout()及相关函数用于指定在经过指定时间间隔后执行的代码。
本章中的一些部分,尤其是关于类型化数组和正则表达式的部分,由于您需要理解的重要背景信息较多,因此相当长。然而,其他许多部分很短:它们只是介绍一个新的 API 并展示其使用示例。
11.1 集合和映射
JavaScript 的 Object 类型是一种多功能的数据结构,可以用来将字符串(对象的属性名称)映射到任意值。当被映射的值是像true这样固定的值时,那么对象实际上就是一组字符串。
在 JavaScript 编程中,对象实际上经常被用作映射和集合,但由于限制为字符串并且对象通常继承具有诸如“toString”之类名称的属性,这使得使用起来有些复杂,通常这些属性并不打算成为映射或集合的一部分。
出于这个原因,ES6 引入了真正的 Set 和 Map 类,我们将在接下来的子章节中介绍。
11.1.1 Set 类
集合是一组值,类似于数组。但与数组不同,集合没有顺序或索引,并且不允许重复:一个值要么是集合的成员,要么不是成员;无法询问一个值在集合中出现多少次。
使用Set()构造函数创建一个 Set 对象:
let s = new Set(); // A new, empty set
let t = new Set([1, s]); // A new set with two members
Set()构造函数的参数不一定是数组:任何可迭代对象(包括其他 Set 对象)都是允许的:
let t = new Set(s); // A new set that copies the elements of s.
let unique = new Set("Mississippi"); // 4 elements: "M", "i", "s", and "p"
集合的size属性类似于数组的length属性:它告诉你集合包含多少个值:
unique.size // => 4
创建集合时无需初始化。您可以随时使用add()、delete()和clear()添加和删除元素。请记住,集合不能包含重复项,因此向集合添加已包含的值不会产生任何效果:
let s = new Set(); // Start empty
s.size // => 0
s.add(1); // Add a number
s.size // => 1; now the set has one member
s.add(1); // Add the same number again
s.size // => 1; the size does not change
s.add(true); // Add another value; note that it is fine to mix types
s.size // => 2
s.add([1,2,3]); // Add an array value
s.size // => 3; the array was added, not its elements
s.delete(1) // => true: successfully deleted element 1
s.size // => 2: the size is back down to 2
s.delete("test") // => false: "test" was not a member, deletion failed
s.delete(true) // => true: delete succeeded
s.delete([1,2,3]) // => false: the array in the set is different
s.size // => 1: there is still that one array in the set
s.clear(); // Remove everything from the set
s.size // => 0
关于这段代码有几个重要的要点需要注意:
-
add()方法接受一个参数;如果传递一个数组,它会将数组本身添加到集合中,而不是单独的数组元素。但是,add()始终返回调用它的集合,因此如果要向集合添加多个值,可以使用链式方法调用,如s.add('a').add('b').add('c');。 -
delete()方法也仅一次删除单个集合元素。但是,与add()不同,delete()返回一个布尔值。如果您指定的值实际上是集合的成员,则delete()会将其删除并返回true。否则,它不执行任何操作并返回false。 -
最后,非常重要的是要理解集合成员是基于严格的相等性检查的,就像
===运算符执行的那样。集合可以包含数字1和字符串"1",因为它认为它们是不同的值。当值为对象(或数组或函数)时,它们也被视为使用===进行比较。这就是为什么我们无法从此代码中的集合中删除数组元素的原因。我们向集合添加了一个数组,然后尝试通过向delete()方法传递一个不同的数组(尽管具有相同元素)来删除该数组。为了使其工作,我们必须传递对完全相同的数组的引用。
注意
Python 程序员请注意:这是 JavaScript 和 Python 集合之间的一个重要区别。Python 集合比较成员的相等性,而不是身份,但这样做的代价是 Python 集合只允许不可变成员,如元组,并且不允许将列表和字典添加到集合中。
在实践中,我们与集合最重要的事情不是向其中添加和删除元素,而是检查指定的值是否是集合的成员。我们使用has()方法来实现这一点:
let oneDigitPrimes = new Set([2,3,5,7]);
oneDigitPrimes.has(2) // => true: 2 is a one-digit prime number
oneDigitPrimes.has(3) // => true: so is 3
oneDigitPrimes.has(4) // => false: 4 is not a prime
oneDigitPrimes.has("5") // => false: "5" is not even a number
关于集合最重要的一点是它们被优化用于成员测试,无论集合有多少成员,has()方法都会非常快。数组的includes()方法也执行成员测试,但所需时间与数组的大小成正比,使用数组作为集合可能比使用真正的 Set 对象慢得多。
Set 类是可迭代的,这意味着您可以使用for/of循环枚举集合的所有元素:
let sum = 0;
for(let p of oneDigitPrimes) { // Loop through the one-digit primes
sum += p; // and add them up
}
sum // => 17: 2 + 3 + 5 + 7
因为 Set 对象是可迭代的,您可以使用...扩展运算符将它们转换为数组和参数列表:
[...oneDigitPrimes] // => [2,3,5,7]: the set converted to an Array
Math.max(...oneDigitPrimes) // => 7: set elements passed as function arguments
集合经常被描述为“无序集合”。然而,对于 JavaScript Set 类来说,这并不完全正确。JavaScript 集合是无索引的:您无法像数组那样请求集合的第一个或第三个元素。但是 JavaScript Set 类始终记住元素插入的顺序,并且在迭代集合时始终使用此顺序:插入的第一个元素将是首个迭代的元素(假设您尚未首先删除它),最近插入的元素将是最后一个迭代的元素。²
除了可迭代外,Set 类还实现了类似于数组同名方法的forEach()方法:
let product = 1;
oneDigitPrimes.forEach(n => { product *= n; });
product // => 210: 2 * 3 * 5 * 7
数组的forEach()将数组索引作为第二个参数传递给您指定的函数。集合没有索引,因此 Set 类的此方法简单地将元素值作为第一个和第二个参数传递。
11.1.2 Map 类
Map 对象表示一组称为键的值,其中每个键都有另一个与之关联(或“映射到”)的值。在某种意义上,映射类似于数组,但是不同于使用一组顺序整数作为键,映射允许我们使用任意值作为“索引”。与数组一样,映射很快:查找与键关联的值将很快(尽管不像索引数组那样快),无论映射有多大。
使用Map()构造函数创建一个新的映射:
let m = new Map(); // Create a new, empty map
let n = new Map([ // A new map initialized with string keys mapped to numbers
["one", 1],
["two", 2]
]);
Map() 构造函数的可选参数应该是一个可迭代对象,产生两个元素 [key, value] 数组。在实践中,这意味着如果你想在创建 map 时初始化它,你通常会将所需的键和关联值写成数组的数组。但你也可以使用 Map() 构造函数复制其他 map,或从现有对象复制属性名和值:
let copy = new Map(n); // A new map with the same keys and values as map n
let o = { x: 1, y: 2}; // An object with two properties
let p = new Map(Object.entries(o)); // Same as new map([["x", 1], ["y", 2]])
一旦你创建了一个 Map 对象,你可以使用 get() 查询与给定键关联的值,并可以使用 set() 添加新的键/值对。但请记住,map 是一组键,每个键都有一个关联的值。这与一组键/值对并不完全相同。如果你使用一个已经存在于 map 中的键调用 set(),你将改变与该键关联的值,而不是添加一个新的键/值映射。除了 get() 和 set(),Map 类还定义了类似 Set 方法的方法:使用 has() 检查 map 是否包含指定的键;使用 delete() 从 map 中删除一个键(及其关联的值);使用 clear() 从 map 中删除所有键/值对;使用 size 属性查找 map 包含多少个键。
let m = new Map(); // Start with an empty map
m.size // => 0: empty maps have no keys
m.set("one", 1); // Map the key "one" to the value 1
m.set("two", 2); // And the key "two" to the value 2.
m.size // => 2: the map now has two keys
m.get("two") // => 2: return the value associated with key "two"
m.get("three") // => undefined: this key is not in the set
m.set("one", true); // Change the value associated with an existing key
m.size // => 2: the size doesn't change
m.has("one") // => true: the map has a key "one"
m.has(true) // => false: the map does not have a key true
m.delete("one") // => true: the key existed and deletion succeeded
m.size // => 1
m.delete("three") // => false: failed to delete a nonexistent key
m.clear(); // Remove all keys and values from the map
像 Set 的 add() 方法一样,Map 的 set() 方法可以链接,这允许初始化 map 而不使用数组的数组:
let m = new Map().set("one", 1).set("two", 2).set("three", 3);
m.size // => 3
m.get("two") // => 2
与 Set 一样,任何 JavaScript 值都可以用作 Map 中的键或值。这包括 null、undefined 和 NaN,以及对象和数组等引用类型。与 Set 类一样,Map 通过标识比较键,而不是通过相等性比较,因此如果你使用对象或数组作为键,它将被认为与每个其他对象和数组都不同,即使它们具有完全相同的属性或元素:
let m = new Map(); // Start with an empty map.
m.set({}, 1); // Map one empty object to the number 1.
m.set({}, 2); // Map a different empty object to the number 2.
m.size // => 2: there are two keys in this map
m.get({}) // => undefined: but this empty object is not a key
m.set(m, undefined); // Map the map itself to the value undefined.
m.has(m) // => true: m is a key in itself
m.get(m) // => undefined: same value we'd get if m wasn't a key
Map 对象是可迭代的,每个迭代的值都是一个包含两个元素的数组,第一个元素是键,第二个元素是与该键关联的值。如果你使用展开运算符与 Map 对象一起使用,你将得到一个类似于我们传递给 Map() 构造函数的数组的数组。在使用 for/of 循环迭代 map 时,惯用的做法是使用解构赋值将键和值分配给单独的变量:
let m = new Map([["x", 1], ["y", 2]]);
[...m] // => [["x", 1], ["y", 2]]
for(let [key, value] of m) {
// On the first iteration, key will be "x" and value will be 1
// On the second iteration, key will be "y" and value will be 2
}
像 Set 类一样,Map 类按插入顺序进行迭代。迭代的第一个键/值对将是最近添加到 map 中的键/值对,而迭代的最后一个键/值对将是最近添加的键/值对。
如果你想仅迭代 map 的键或仅迭代关联的值,请使用 keys() 和 values() 方法:这些方法返回可迭代对象,按插入顺序迭代键和值。(entries() 方法返回一个可迭代对象,按键/值对迭代,但这与直接迭代 map 完全相同。)
[...m.keys()] // => ["x", "y"]: just the keys
[...m.values()] // => [1, 2]: just the values
[...m.entries()] // => [["x", 1], ["y", 2]]: same as [...m]
Map 对象也可以使用首次由 Array 类实现的 forEach() 方法进行迭代。
m.forEach((value, key) => { // note value, key NOT key, value
// On the first invocation, value will be 1 and key will be "x"
// On the second invocation, value will be 2 and key will be "y"
});
可能会觉得上面的代码中值参数在键参数之前有些奇怪,因为在 for/of 迭代中,键首先出现。正如本节开头所述,你可以将 map 视为一个广义的数组,其中整数数组索引被任意键值替换。数组的 forEach() 方法首先传递数组元素,然后传递数组索引,因此,类比地,map 的 forEach() 方法首先传递 map 值,然后传递 map 键。
11.1.3 WeakMap 和 WeakSet
WeakMap 类是 Map 类的变体(但不是实际的子类),不会阻止其键值被垃圾回收。垃圾回收是 JavaScript 解释器回收不再“可达”的对象内存的过程,这些对象不能被程序使用。常规映射保持对其键值的“强”引用,它们通过映射保持可达性,即使所有对它们的其他引用都消失了。相比之下,WeakMap 对其键值保持“弱”引用,因此它们不可通过 WeakMap 访问,它们在映射中的存在不会阻止其内存被回收。
WeakMap()构造函数与Map()构造函数完全相同,但 WeakMap 和 Map 之间存在一些重要的区别:
-
WeakMap 的键必须是对象或数组;原始值不受垃圾回收的影响,不能用作键。
-
WeakMap 只实现了
get()、set()、has()和delete()方法。特别是,WeakMap 不可迭代,并且不定义keys()、values()或forEach()。如果 WeakMap 是可迭代的,那么它的键将是可达的,它就不会是弱引用的。 -
同样,WeakMap 也不实现
size属性,因为 WeakMap 的大小随时可能会随着对象被垃圾回收而改变。
WeakMap 的预期用途是允许您将值与对象关联而不会导致内存泄漏。例如,假设您正在编写一个函数,该函数接受一个对象参数并需要对该对象执行一些耗时的计算。为了效率,您希望缓存计算后的值以供以后重用。如果使用 Map 对象来实现缓存,将阻止任何对象被回收,但使用 WeakMap,您可以避免这个问题。(您通常可以使用私有 Symbol 属性直接在对象上缓存计算后的值来实现类似的结果。参见§6.10.3。)
WeakSet 实现了一组对象,不会阻止这些对象被垃圾回收。WeakSet()构造函数的工作方式类似于Set()构造函数,但 WeakSet 对象与 Set 对象的区别与 WeakMap 对象与 Map 对象的区别相同:
-
WeakSet 不允许原始值作为成员。
-
WeakSet 只实现了
add()、has()和delete()方法,并且不可迭代。 -
WeakSet 没有
size属性。
WeakSet 并不经常使用:它的用例类似于 WeakMap。如果你想标记(或“品牌化”)一个对象具有某些特殊属性或类型,例如,你可以将其添加到 WeakSet 中。然后,在其他地方,当你想检查该属性或类型时,可以测试该 WeakSet 的成员资格。使用常规集合会阻止所有标记对象被垃圾回收,但使用 WeakSet 时不必担心这个问题。
11.2 类型化数组和二进制数据
常规 JavaScript 数组可以具有任何类型的元素,并且可以动态增长或缩小。JavaScript 实现执行许多优化,使得 JavaScript 数组的典型用法非常快速。然而,它们与低级语言(如 C 和 Java)的数组类型仍然有很大不同。类型化数组是 ES6 中的新功能,³它们更接近这些语言的低级数组。类型化数组在技术上不是数组(Array.isArray()对它们返回false),但它们实现了§7.8 中描述的所有数组方法以及一些自己的方法。然而,它们与常规数组在一些非常重要的方面有所不同:
-
类型化数组的元素都是数字。然而,与常规 JavaScript 数字不同,类型化数组允许您指定要存储在数组中的数字的类型(有符号和无符号整数和 IEEE-754 浮点数)和大小(8 位到 64 位)。
-
创建类型化数组时必须指定其长度,并且该长度永远不会改变。
-
类型化数组的元素在创建数组时始终初始化为 0。
11.2.1 类型化数组类型
JavaScript 没有定义 TypedArray 类。相反,有 11 种类型化数组,每种具有不同的元素类型和构造函数:
| 构造函数 | 数值类型 |
|---|---|
Int8Array() |
有符号字节 |
Uint8Array() |
无符号字节 |
Uint8ClampedArray() |
无溢出的无符号字节 |
Int16Array() |
有符号 16 位短整数 |
Uint16Array() |
无符号 16 位短整数 |
Int32Array() |
有符号 32 位整数 |
Uint32Array() |
无符号 32 位整数 |
BigInt64Array() |
有符号 64 位 BigInt 值(ES2020) |
BigUint64Array() |
无符号 64 位 BigInt 值(ES2020) |
Float32Array() |
32 位浮点值 |
Float64Array() |
64 位浮点值:普通的 JavaScript 数字 |
名称以 Int 开头的类型保存有符号整数,占用 1、2 或 4 字节(8、16 或 32 位)。名称以 Uint 开头的类型保存相同长度的无符号整数。名称为 “BigInt” 和 “BigUint” 的类型保存 64 位整数,以 BigInt 值的形式表示在 JavaScript 中(参见 §3.2.5)。以 Float 开头的类型保存浮点数。Float64Array 的元素与普通的 JavaScript 数字相同类型。Float32Array 的元素精度较低,范围较小,但只需一半的内存。 (在 C 和 Java 中,此类型称为 float。)
Uint8ClampedArray 是 Uint8Array 的特殊变体。这两种类型都保存无符号字节,可以表示 0 到 255 之间的数字。对于 Uint8Array,如果将大于 255 或小于零的值存储到数组元素中,它会“环绕”,并且会得到其他值。这是计算机内存在低级别上的工作原理,因此速度非常快。Uint8ClampedArray 进行了一些额外的类型检查,以便如果存储大于 255 或小于 0 的值,则会“夹紧”到 255 或 0,而不会环绕。 (这种夹紧行为是 HTML <canvas> 元素的低级 API 用于操作像素颜色所必需的。)
每个类型化数组构造函数都有一个 BYTES_PER_ELEMENT 属性,其值为 1、2、4 或 8,取决于类型。
11.2.2 创建类型化数组
创建类型化数组的最简单方法是调用适当的构造函数,并提供一个数字参数,指定数组中要包含的元素数量:
let bytes = new Uint8Array(1024); // 1024 bytes
let matrix = new Float64Array(9); // A 3x3 matrix
let point = new Int16Array(3); // A point in 3D space
let rgba = new Uint8ClampedArray(4); // A 4-byte RGBA pixel value
let sudoku = new Int8Array(81); // A 9x9 sudoku board
通过这种方式创建类型化数组时,数组元素都保证初始化为 0、0n 或 0.0。但是,如果您知道要在类型化数组中使用的值,也可以在创建数组时指定这些值。每个类型化数组构造函数都有静态的 from() 和 of() 工厂方法,类似于 Array.from() 和 Array.of():
let white = Uint8ClampedArray.of(255, 255, 255, 0); // RGBA opaque white
请记住,Array.from() 工厂方法的第一个参数应为类似数组或可迭代对象。对于类型化数组变体也是如此,只是可迭代或类似数组的对象还必须具有数值元素。例如,字符串是可迭代的,但将它们传递给类型化数组的 from() 工厂方法是没有意义的。
如果只使用 from() 的单参数版本,可以省略 .from 并直接将可迭代或类似数组对象传递给构造函数,其行为完全相同。请注意,构造函数和 from() 工厂方法都允许您复制现有的类型化数组,同时可能更改类型:
let ints = Uint32Array.from(white); // The same 4 numbers, but as ints
当从现有数组、可迭代对象或类似数组对象创建新的类型化数组时,值可能会被截断以符合数组的类型约束。当发生这种情况时,不会有警告或错误:
// Floats truncated to ints, longer ints truncated to 8 bits
Uint8Array.of(1.23, 2.99, 45000) // => new Uint8Array([1, 2, 200])
最后,还有一种使用 ArrayBuffer 类型创建 typed arrays 的方法。ArrayBuffer 是一个对一块内存的不透明引用。你可以用构造函数创建一个,只需传入你想要分配的内存字节数:
let buffer = new ArrayBuffer(1024*1024);
buffer.byteLength // => 1024*1024; one megabyte of memory
ArrayBuffer 类不允许你读取或写入你分配的任何字节。但你可以创建使用 buffer 内存的 typed arrays,并且允许你读取和写入该内存。为此,调用 typed array 构造函数,第一个参数是一个 ArrayBuffer,第二个参数是数组缓冲区内的字节偏移量,第三个参数是数组长度(以元素而不是字节计算)。第二和第三个参数是可选的。如果两者都省略,则数组将使用数组缓冲区中的所有内存。如果只省略长度参数,则你的数组将使用从起始位置到数组结束的所有可用内存。关于这种形式的 typed array 构造函数还有一件事要记住:数组必须是内存对齐的,所以如果你指定了一个字节偏移量,该值应该是你的类型大小的倍数。例如,Int32Array() 构造函数需要四的倍数,而 Float64Array() 需要八的倍数。
给定之前创建的 ArrayBuffer,你可以创建这样的 typed arrays:
let asbytes = new Uint8Array(buffer); // Viewed as bytes
let asints = new Int32Array(buffer); // Viewed as 32-bit signed ints
let lastK = new Uint8Array(buffer, 1023*1024); // Last kilobyte as bytes
let ints2 = new Int32Array(buffer, 1024, 256); // 2nd kilobyte as 256 integers
这四种 typed arrays 提供了对由 ArrayBuffer 表示的内存的四种不同视图。重要的是要理解,所有 typed arrays 都有一个底层的 ArrayBuffer,即使你没有明确指定一个。如果你调用一个 typed array 构造函数而没有传递一个 buffer 对象,一个适当大小的 buffer 将会被自动创建。正如后面所描述的,任何 typed array 的 buffer 属性都指向它的底层 ArrayBuffer 对象。直接使用 ArrayBuffer 对象的原因是有时你可能想要有一个单一 buffer 的多个 typed array 视图。
11.2.3 使用 Typed Arrays
一旦你创建了一个 typed array,你可以用常规的方括号表示法读取和写入它的元素,就像你对待任何其他类似数组的对象一样:
// Return the largest prime smaller than n, using the sieve of Eratosthenes
function sieve(n) {
let a = new Uint8Array(n+1); // a[x] will be 1 if x is composite
let max = Math.floor(Math.sqrt(n)); // Don't do factors higher than this
let p = 2; // 2 is the first prime
while(p <= max) { // For primes less than max
for(let i = 2*p; i <= n; i += p) // Mark multiples of p as composite
a[i] = 1;
while(a[++p]) /* empty */; // The next unmarked index is prime
}
while(a[n]) n--; // Loop backward to find the last prime
return n; // And return it
}
这里的函数计算比你指定的数字小的最大质数。代码与使用常规 JavaScript 数组完全相同,但在我的测试中使用 Uint8Array() 而不是 Array() 使代码运行速度超过四倍,并且使用的内存少了八倍。
Typed arrays 不是真正的数组,但它们重新实现了大多数数组方法,所以你可以几乎像使用常规数组一样使用它们:
let ints = new Int16Array(10); // 10 short integers
ints.fill(3).map(x=>x*x).join("") // => "9999999999"
记住,typed arrays 有固定的长度,所以 length 属性是只读的,而改变数组长度的方法(如 push()、pop()、unshift()、shift() 和 splice())对 typed arrays 没有实现。改变数组内容而不改变长度的方法(如 sort()、reverse() 和 fill())是实现的。返回新数组的 map() 和 slice() 等方法返回与调用它们的 typed array 相同类型的 typed array。
11.2.4 Typed Array 方法和属性
除了标准数组方法外,typed arrays 也实现了一些自己的方法。set() 方法通过将常规或 typed array 的元素复制到 typed array 中一次设置多个元素:
let bytes = new Uint8Array(1024); // A 1K buffer
let pattern = new Uint8Array([0,1,2,3]); // An array of 4 bytes
bytes.set(pattern); // Copy them to the start of another byte array
bytes.set(pattern, 4); // Copy them again at a different offset
bytes.set([0,1,2,3], 8); // Or just copy values direct from a regular array
bytes.slice(0, 12) // => new Uint8Array([0,1,2,3,0,1,2,3,0,1,2,3])
set() 方法以数组或 typed array 作为第一个参数,以元素偏移量作为可选的第二个参数,如果未指定则默认为 0。如果你从一个 typed array 复制值到另一个,这个操作可能会非常快。
Typed arrays 还有一个 subarray 方法,返回调用它的数组的一部分:
let ints = new Int16Array([0,1,2,3,4,5,6,7,8,9]); // 10 short integers
let last3 = ints.subarray(ints.length-3, ints.length); // Last 3 of them
last3[0] // => 7: this is the same as ints[7]
subarray()接受与slice()方法相同的参数,并且似乎工作方式相同。但有一个重要的区别。slice()返回一个新的、独立的类型化数组,其中包含指定的元素,不与原始数组共享内存。subarray()不复制任何内存;它只返回相同底层值的新视图:
ints[9] = -1; // Change a value in the original array and...
last3[2] // => -1: it also changes in the subarray
subarray()方法返回现有数组的新视图,这让我们回到了 ArrayBuffers 的话题。每个类型化数组都有三个与底层缓冲区相关的属性:
last3.buffer // The ArrayBuffer object for a typed array
last3.buffer === ints.buffer // => true: both are views of the same buffer
last3.byteOffset // => 14: this view starts at byte 14 of the buffer
last3.byteLength // => 6: this view is 6 bytes (3 16-bit ints) long
last3.buffer.byteLength // => 20: but the underlying buffer has 20 bytes
buffer属性是数组的 ArrayBuffer。byteOffset是数组数据在底层缓冲区中的起始位置。byteLength是数组数据的字节长度。对于任何类型化数组a,这个不变式应该始终成立:
a.length * a.BYTES_PER_ELEMENT === a.byteLength // => true
ArrayBuffer 只是不透明的字节块。您可以使用类型化数组访问这些字节,但 ArrayBuffer 本身不是类型化数组。但要小心:您可以像在任何 JavaScript 对象上一样使用数字数组索引访问 ArrayBuffers。这样做并不会让您访问缓冲区中的字节,但可能会导致混乱的错误:
let bytes = new Uint8Array(8);
bytes[0] = 1; // Set the first byte to 1
bytes.buffer[0] // => undefined: buffer doesn't have index 0
bytes.buffer[1] = 255; // Try incorrectly to set a byte in the buffer
bytes.buffer[1] // => 255: this just sets a regular JS property
bytes[1] // => 0: the line above did not set the byte
我们之前看到,您可以使用ArrayBuffer()构造函数创建一个 ArrayBuffer,然后创建使用该缓冲区的类型化数组。另一种方法是创建一个初始类型化数组,然后使用该数组的缓冲区创建其他视图:
let bytes = new Uint8Array(1024); // 1024 bytes
let ints = new Uint32Array(bytes.buffer); // or 256 integers
let floats = new Float64Array(bytes.buffer); // or 128 doubles
11.2.5 DataView 和字节顺序
类型化数组允许您以 8、16、32 或 64 位的块查看相同的字节序列。这暴露了“字节序”:字节被排列成更长字的顺序。为了效率,类型化数组使用底层硬件的本机字节顺序。在小端系统上,数字的字节从最不重要到最重要的顺序排列在 ArrayBuffer 中。在大端平台上,字节从最重要到最不重要的顺序排列。您可以使用以下代码确定底层平台的字节顺序:
// If the integer 0x00000001 is arranged in memory as 01 00 00 00, then
// we're on a little-endian platform. On a big-endian platform, we'd get
// bytes 00 00 00 01 instead.
let littleEndian = new Int8Array(new Int32Array([1]).buffer)[0] === 1;
如今,最常见的 CPU 架构是小端。然而,许多网络协议和一些二进制文件格式要求大端字节顺序。如果您正在使用来自网络或文件的数据的类型化数组,您不能仅仅假设平台的字节顺序与数据的字节顺序相匹配。一般来说,在处理外部数据时,您可以使用 Int8Array 和 Uint8Array 将数据视为单个字节的数组,但不应使用其他具有多字节字长的类型化数组。相反,您可以使用 DataView 类,该类定义了用于从具有明确定义的字节顺序的 ArrayBuffer 中读取和写入值的方法:
// Assume we have a typed array of bytes of binary data to process. First,
// we create a DataView object so we can flexibly read and write
// values from those bytes
let view = new DataView(bytes.buffer,
bytes.byteOffset,
bytes.byteLength);
let int = view.getInt32(0); // Read big-endian signed int from byte 0
int = view.getInt32(4, false); // Next int is also big-endian
int = view.getUint32(8, true); // Next int is little-endian and unsigned
view.setUint32(8, int, false); // Write it back in big-endian format
DataView 为每个 10 个类型化数组类定义了 10 个get方法(不包括 Uint8ClampedArray)。它们的名称类似于getInt16()、getUint32()、getBigInt64()和getFloat64()。第一个参数是 ArrayBuffer 中数值开始的字节偏移量。除了getInt8()和getUint8()之外,所有这些获取方法都接受一个可选的布尔值作为第二个参数。如果省略第二个参数或为false,则使用大端字节顺序。如果第二个参数为true,则使用小端顺序。
DataView 还定义了 10 个相应的 Set 方法,用于将值写入底层 ArrayBuffer。第一个参数是值开始的偏移量。第二个参数是要写入的值。除了setInt8()和setUint8()之外,每个方法都接受一个可选的第三个参数。如果省略参数或为false,则以大端格式写入值,最重要的字节在前。如果参数为true,则以小端格式写入值,最不重要的字节在前。
类型化数组和 DataView 类为您提供了处理二进制数据所需的所有工具,并使您能够编写执行诸如解压缩 ZIP 文件或从 JPEG 文件中提取元数据等操作的 JavaScript 程序。
11.3 使用正则表达式进行模式匹配
正则表达式是描述文本模式的对象。JavaScript RegExp 类表示正则表达式,String 和 RegExp 都定义了使用正则表达式执行强大的模式匹配和搜索替换功能的方法。然而,为了有效地使用 RegExp API,您还必须学习如何使用正则表达式语法描述文本模式,这本质上是一种自己的迷你编程语言。幸运的是,JavaScript 正则表达式语法与许多其他编程语言使用的语法非常相似,因此您可能已经熟悉它。 (如果您不熟悉,学习 JavaScript 正则表达式所投入的努力可能也对您在其他编程环境中有所帮助。)
接下来的小节首先描述了正则表达式语法,然后,在解释如何编写正则表达式之后,它们解释了如何使用它们与 String 和 RegExp 类的方法。
11.3.1 定义正则表达式
在 JavaScript 中,正则表达式由 RegExp 对象表示。当然,RegExp 对象可以使用RegExp()构造函数创建,但更常见的是使用特殊的字面量语法创建。正如字符串字面量是在引号内指定的字符一样,正则表达式字面量是在一对斜杠(/)字符内指定的字符。因此,您的 JavaScript 代码可能包含如下行:
let pattern = /s$/;
此行创建一个新的 RegExp 对象,并将其赋给变量pattern。这个特定的 RegExp 对象匹配任何以字母“s”结尾的字符串。这个正则表达式也可以用RegExp()构造函数定义,就像这样:
let pattern = new RegExp("s$");
正则表达式模式规范由一系列字符组成。大多数字符,包括所有字母数字字符,只是描述要匹配的字符。因此,正则表达式/java/匹配包含子字符串“java”的任何字符串。正则表达式中的其他字符不是字面匹配的,而是具有特殊意义。例如,正则表达式/s$/包含两个字符。第一个“s”是字面匹配的。第二个“$”是一个特殊的元字符,匹配字符串的结尾。因此,这个正则表达式匹配任何以字母“s”作为最后一个字符的字符串。
正如我们将看到的,正则表达式也可以有一个或多个标志字符,影响它们的工作方式。标志是在 RegExp 文本的第二个斜杠字符后指定的,或者作为RegExp()构造函数的第二个字符串参数。例如,如果我们想匹配以“s”或“S”结尾的字符串,我们可以在正则表达式中使用i标志,表示我们要进行不区分大小写的匹配:
let pattern = /s$/i;
以下各节描述了 JavaScript 正则表达式中使用的各种字符和元字符。
字面字符
所有字母字符和数字在正则表达式中都以字面意义匹配自身。JavaScript 正则表达式语法还支持以反斜杠(\)开头的转义序列表示某些非字母字符。例如,序列\n在字符串中匹配一个字面换行符。表 11-1 列出了这些字符。
表 11-1. 正则表达式字面字符
| 字符 | 匹配 |
|---|---|
| 字母数字字符 | 本身 |
\0 |
NUL 字符(\u0000) |
\t |
制表符(\u0009) |
\n |
换行符(\u000A) |
\v |
垂直制表符(\u000B) |
\f |
换页符(\u000C) |
\r |
回车符(\u000D) |
\xnn |
十六进制数字 nn 指定的拉丁字符;例如,\x0A 等同于 \n。 |
\uxxxx |
十六进制数字 xxxx 指定的 Unicode 字符;例如,\u0009 等同于 \t。 |
\u{n} |
由代码点 n 指定的 Unicode 字符,其中 n 是 0 到 10FFFF 之间的一到六个十六进制数字。请注意,此语法仅在使用 u 标志的正则表达式中受支持。 |
\cX |
控制字符 ^X;例如,\cJ 等同于换行符 \n。 |
许多标点符号在正则表达式中具有特殊含义。它们是:
^ $ . * + ? = ! : | \ / ( ) [ ] { }
这些字符的含义将在接下来的章节中讨论。其中一些字符仅在正则表达式的某些上下文中具有特殊含义,在其他上下文中被视为文字。然而,作为一般规则,如果要在正则表达式中字面包含任何这些标点符号,必须在其前面加上 \。其他标点符号,如引号和 @,没有特殊含义,只是在正则表达式中字面匹配自身。
如果你记不清哪些标点符号需要用反斜杠转义,你可以安全地在任何标点符号前面放置一个反斜杠。另一方面,请注意,许多字母和数字在前面加上反斜杠时具有特殊含义,因此任何你想字面匹配的字母或数字不应该用反斜杠转义。要在正则表达式中字面包含反斜杠字符,当然必须用反斜杠转义它。例如,以下正则表达式匹配包含反斜杠的任意字符串:/\\/。(如果你使用 RegExp() 构造函数,请记住你的正则表达式中的任何反斜杠都需要加倍,因为字符串也使用反斜杠作为转义字符。)
字符类
通过将单个文字字符组合到方括号中,可以形成字符类。字符类匹配其中包含的任意一个字符。因此,正则表达式 /[abc]/ 匹配字母 a、b 或 c 中的任意一个。也可以定义否定字符类;这些匹配除方括号中包含的字符之外的任意字符。否定字符类通过在左方括号内的第一个字符处放置插入符号(^)来指定。正则表达式 /[^abc]/ 匹配除 a、b 或 c 之外的任意一个字符。字符类可以使用连字符指示字符范围。要匹配拉丁字母表中的任意一个小写字母,请使用 /[a-z]/,要匹配拉丁字母表中的任意字母或数字,请使用 /[a-zA-Z0-9]/。(如果要在字符类中包含实际连字符,只需将其放在右方括号之前。)
由于某些字符类通常被使用,JavaScript 正则表达式语法包括特殊字符和转义序列来表示这些常见类。例如,\s 匹配空格字符、制表符和任何其他 Unicode 空白字符;\S 匹配任何非 Unicode 空白字符。表 11-2 列出了这些字符并总结了字符类语法。(请注意,其中几个字符类转义序列仅匹配 ASCII 字符,并未扩展为适用于 Unicode 字符。但是,你可以显式定义自己的 Unicode 字符类;例如,/[\u0400-\u04FF]/ 匹配任意一个西里尔字母字符。)
表格 11-2. 正则表达式字符类
| 字符 | 匹配 |
|---|---|
[...] |
方括号内的任意一个字符。 |
[^...] |
方括号内的任意一个字符。 |
. |
除换行符或其他 Unicode 行终止符之外的任何字符。或者,如果 RegExp 使用 s 标志,则句点匹配任何字符,包括行终止符。 |
\w |
任何 ASCII 单词字符。等同于 [a-zA-Z0-9_]。 |
\W |
任何不是 ASCII 单词字符的字符。等同于 [^a-zA-Z0-9_]。 |
\s |
任何 Unicode 空白字符。 |
\S |
任何不是 Unicode 空白字符的字符。 |
\d |
任何 ASCII 数字。等同于 [0-9]。 |
\D |
任何 ASCII 数字之外的字符。等同于 [⁰-9]。 |
[\b] |
一个字面退格(特殊情况)。 |
请注意,特殊字符类转义可以在方括号内使用。\s 匹配任何空白字符,\d 匹配任何数字,因此 /[\s\d]/ 匹配任何一个空白字符或数字。请注意有一个特殊情况。正如稍后将看到的,\b 转义具有特殊含义。但是,在字符类中使用时,它表示退格字符。因此,要在正则表达式中字面表示退格字符,请使用具有一个元素的字符类:/[\b]/。
重复
到目前为止,您学到的正则表达式语法可以将两位数描述为 /\d\d/,将四位数描述为 /\d\d\d\d/。但是,您没有任何方法来描述,例如,可以具有任意数量的数字或三个字母后跟一个可选数字的字符串。这些更复杂的模式使用指定正则表达式元素可以重复多少次的正则表达式语法。
指定重复的字符始终跟随其应用的模式。由于某些类型的重复非常常见,因此有特殊字符来表示这些情况。例如,+ 匹配前一个模式的一个或多个出现。
表 11-3 总结了重复语法。
表 11-3. 正则表达式重复字符
| 字符 | 含义 |
|---|---|
{n,m} |
匹配前一个项目至少 n 次但不超过 m 次。 |
{n,} |
匹配前一个项目 n 次或更多次。 |
{n} |
匹配前一个项目的 n 次出现。 |
? |
匹配前一个项目的零次或一次出现。也就是说,前一个项目是可选的。等同于 {0,1}。 |
+ |
匹配前一个项目的一个或多个出现。等同于 {1,}。 |
* |
匹配前一个项目的零次或多次。等同于 {0,}。 |
以下行显示了一些示例:
let r = /\d{2,4}/; // Match between two and four digits
r = /\w{3}\d?/; // Match exactly three word characters and an optional digit
r = /\s+java\s+/; // Match "java" with one or more spaces before and after
r = /[^(]*/; // Match zero or more characters that are not open parens
请注意,在所有这些示例中,重复说明符应用于它们之前的单个字符或字符类。如果要匹配更复杂表达式的重复,您需要使用括号定义一个组,这将在以下部分中解释。
使用 * 和 ? 重复字符时要小心。由于这些字符可能匹配前面的内容的零次,它们允许匹配空内容。例如,正则表达式 /a*/ 实际上匹配字符串“bbbb”,因为该字符串不包含字母 a 的任何出现!
非贪婪重复
表 11-3 中列出的重复字符尽可能多次匹配,同时仍允许正则表达式的任何后续部分匹配。我们说这种重复是“贪婪的”。还可以指定以非贪婪方式进行重复。只需在重复字符后面跟一个问号:??、+?、*?,甚至 {1,5}?。例如,正则表达式 /a+/ 匹配一个或多个字母 a 的出现。当应用于字符串“aaa”时,它匹配所有三个字母。但是 /a+?/ 匹配一个或多个字母 a 的出现,尽可能少地匹配字符。当应用于相同字符串时,此模式仅匹配第一个字母 a。
使用非贪婪重复可能不总是产生您期望的结果。考虑模式/a+b/,它匹配一个或多个 a,后跟字母 b。当应用于字符串“aaab”时,它匹配整个字符串。现在让我们使用非贪婪版本:/a+?b/。这应该匹配由尽可能少的 a 前导的字母 b。当应用于相同字符串“aaab”时,您可能希望它仅匹配一个 a 和最后一个字母 b。但实际上,此模式与贪婪版本的模式一样匹配整个字符串。这是因为正则表达式模式匹配是通过找到字符串中可能发生匹配的第一个位置来完成的。由于从字符串的第一个字符开始就可能发生匹配,因此从后续字符开始的较短匹配甚至不会被考虑。
备选项、分组和引用
正则表达式语法包括用于指定备选项、分组子表达式和引用先前子表达式的特殊字符。|字符分隔备选项。例如,/ab|cd|ef/匹配字符串“ab”或字符串“cd”或字符串“ef”。而/\d{3}|[a-z]{4}/匹配三个数字或四个小写字母中的任何一个。
请注意,备选项从左到右考虑,直到找到匹配项。如果左侧备选项匹配,则右侧备选项将被忽略,即使它可能产生“更好”的匹配。因此,当将模式/a|ab/应用于字符串“ab”时,它仅匹配第一个字母。
括号在正则表达式中有几个目的。一个目的是将单独的项目分组为单个子表达式,以便可以通过|、*、+、?等将项目视为单个单元。例如,/java(script)?/匹配“java”后跟可选的“script”。而/(ab|cd)+|ef/匹配字符串“ef”或一个或多个重复的字符串“ab”或“cd”中的任何一个。
正则表达式中括号的另一个目的是在完整模式内定义子模式。当正则表达式成功匹配目标字符串时,可以提取匹配任何特定括号子模式的目标字符串部分。(您将在本节后面看到如何获取这些匹配的子字符串。)例如,假设您正在寻找一个或多个小写字母后跟一个或多个数字。您可能会使用模式/[a-z]+\d+/。但是假设您只关心每个匹配末尾的数字。如果将模式的这部分放在括号中(/[a-z]+(\d+)/),您可以提取任何找到的匹配中的数字,如后面所述。
括号子表达式的一个相关用途是允许您在同一正则表达式中稍后引用子表达式。这是通过在\字符后跟一个或多个数字来完成的。这些数字指的是正则表达式中括号子表达式的位置。例如,\1引用第一个子表达式,\3引用第三个。请注意,由于子表达式可以嵌套在其他子表达式中,因此计算的是左括号的位置。例如,在以下正则表达式中,嵌套的子表达式([Ss]cript)被称为\2:
/([Jj]ava([Ss]cript)?)\sis\s(fun\w*)/
对正则表达式的先前子表达式的引用不是指该子表达式的模式,而是指匹配该模式的文本。因此,引用可用于强制要求字符串的不同部分包含完全相同的字符。例如,以下正则表达式匹配单引号或双引号内的零个或多个字符。但是,它不要求开头和结尾引号匹配(即,都是单引号或双引号):
/['"][^'"]*['"]/
要求引号匹配,请使用引用:
/(['"])[^'"]*\1/
\1匹配第一个括号子表达式匹配的内容。在此示例中,它强制约束闭合引号与开放引号匹配。此正则表达式不允许单引号在双引号字符串内部,反之亦然。(在字符类内部使用引用是不合法的,因此不能写成:/(['"])[^\1]*\1/。)
当我们稍后讨论 RegExp API 时,您会看到对括号子表达式的引用是正则表达式搜索和替换操作的一个强大功能。
也可以在正则表达式中分组项目而不创建对这些项目的编号引用。不要简单地在(和)内部分组项目,而是从(?:开始组,以)结束。考虑以下模式:
/([Jj]ava(?:[Ss]cript)?)\sis\s(fun\w*)/
在此示例中,子表达式(?:[Ss]cript)仅用于分组,因此?重复字符可以应用于该组。这些修改后的括号不生成引用,因此在此正则表达式中,\2指的是由(fun\w*)匹配的文本。
表格 11-4 总结了正则表达式的交替、分组和引用操作符。
表格 11-4. 正则表达式的交替、分组和引用字符
| 字符 | 含义 |
|---|---|
| |
交替:匹配左侧子表达式或右侧子表达式。 |
(...) |
分组:将项目分组为一个单元,可以与*、+、?、|等一起使用。还要记住匹配此组的字符,以便后续引用。 |
(?:...) |
仅分组:将项目分组为一个单元,但不记住匹配此组的字符。 |
\n |
匹配在第一次匹配组号 n 时匹配的相同字符。组是括号内的子表达式(可能是嵌套的)。组号是通过从左到右计算左括号来分配的。使用(?:形成的组不编号。 |
指定匹配位置
正如前面所述,正则表达式的许多元素匹配字符串中的单个字符。例如,\s匹配单个空白字符。其他正则表达式元素匹配字符之间的位置而不是实际字符。例如,\b匹配 ASCII 单词边界——\w(ASCII 单词字符)和\W(非单词字符)之间的边界,或者 ASCII 单词字符和字符串的开头或结尾之间的边界。[⁴] 元素如\b不指定要在匹配的字符串中使用的任何字符;但它们指定的是合法的匹配位置。有时这些元素被称为正则表达式锚点,因为它们将模式锚定到搜索字符串中的特定位置。最常用的锚定元素是^,将模式绑定到字符串的开头,以及$,将模式锚定到字符串的结尾。
例如,要匹配单独一行的单词“JavaScript”,可以使用正则表达式/^JavaScript$/。如果要搜索“Java”作为单独的单词(而不是作为“JavaScript”中的前缀),可以尝试模式/\sJava\s/,这需要单词前后有空格。但是这种解决方案有两个问题。首先,它不匹配字符串的开头或结尾的“Java”,而只有在两侧有空格时才匹配。其次,当此模式找到匹配时,返回的匹配字符串具有前导和尾随空格,这不是所需的。因此,与其用\s匹配实际空格字符,不如用\b匹配(或锚定)单词边界。得到的表达式是/\bJava\b/。元素\B将匹配锚定到不是单词边界的位置。因此,模式/\B[Ss]cript/匹配“JavaScript”和“postscript”,但不匹配“script”或“Scripting”。
您还可以使用任意正则表达式作为锚定条件。如果在(?=和)字符之间包含一个表达式,那么这是一个前瞻断言,并且它指定封闭字符必须匹配,而不实际匹配它们。例如,要匹配一个常见编程语言的名称,但只有在后面跟着一个冒号时,您可以使用/[Jj]ava([Ss]cript)?(?=\:)/。这个模式匹配“JavaScript”中的单词“JavaScript: The Definitive Guide”,但不匹配“Java in a Nutshell”中的“Java”,因为它后面没有跟着冒号。
如果您使用(?!引入断言,那么这是一个负向前瞻断言,指定接下来的字符不得匹配。例如,/Java(?!Script)([A-Z]\w*)/匹配“Java”后跟一个大写字母和任意数量的其他 ASCII 单词字符,只要“Java”后面不跟着“Script”。它匹配“JavaBeans”但不匹配“Javanese”,它匹配“JavaScrip”但不匹配“JavaScript”或“JavaScripter”。表 11-5 总结了正则表达式锚点。
表 11-5. 正则表达式锚点字符
| 字符 | 含义 |
|---|---|
^ |
匹配字符串的开头或者在使用m标志时,匹配行的开头。 |
| ` | 字符 |
| --- | --- |
^ |
匹配字符串的开头或者在使用m标志时,匹配行的开头。 |
匹配字符串的结尾,并且在使用m标志时,匹配行的结尾。 |
|
\b |
匹配单词边界。也就是说,匹配\w字符和\W字符之间的位置,或者匹配\w字符和字符串的开头或结尾之间的位置。(但请注意,[\b]匹配退格键。) |
\B |
匹配不是单词边界的位置。 |
(?=p) |
正向前瞻断言。要求接下来的字符匹配模式p,但不包括这些字符在匹配中。 |
(?!p) |
负向前瞻断言。要求接下来的字符不匹配模式p。 |
标志
每个正则表达式都可以有一个或多个与之关联的标志,以改变其匹配行为。JavaScript 定义了六个可能的标志,每个标志由一个字母表示。标志在正则表达式字面量的第二个/字符之后指定,或者作为传递给RegExp()构造函数的第二个参数的字符串。支持的标志及其含义如下:
g
g标志表示正则表达式是“全局”的,也就是说,我们打算在字符串中找到所有匹配项,而不仅仅是找到第一个匹配项。这个标志不会改变匹配模式的方式,但正如我们稍后将看到的,它确实以重要的方式改变了 String match()方法和 RegExp exec()方法的行为。
i
i标志指定匹配模式时应该忽略大小写。
m
m标志指定匹配应该在“多行”模式下进行。它表示正则表达式将与多行字符串一起使用,并且^和$锚点应该匹配字符串的开头和结尾,以及字符串中各行的开头和结尾。
s
与m标志类似,s标志在处理包含换行符的文本时也很有用。通常,正则表达式中的“.”匹配除行终止符之外的任何字符。但是,当使用s标志时,“.”将匹配任何字符,包括行终止符。s标志在 ES2018 中添加到 JavaScript 中,并且截至 2020 年初,在 Node、Chrome、Edge 和 Safari 中支持,但在 Firefox 中不支持。
u
u标志代表 Unicode,它使正则表达式匹配完整的 Unicode 代码点,而不是匹配 16 位值。这个标志是在 ES6 中引入的,你应该养成在所有正则表达式上使用它的习惯,除非你有某种理由不这样做。如果你不使用这个标志,那么你的正则表达式将无法很好地处理包含表情符号和其他需要超过 16 位的字符(包括许多中文字符)的文本。没有u标志,"."字符匹配任何 1 个 UTF-16 16 位值。然而,有了这个标志,"."匹配一个 Unicode 代码点,包括那些超过 16 位的代码点。在正则表达式上设置u标志还允许你使用新的\u{...}转义序列来表示 Unicode 字符,并且还启用了\p{...}表示 Unicode 字符类。
y
y标志表示正则表达式是“粘性”的,应该在字符串的开头或上一个匹配项后的第一个字符处匹配。当与旨在找到单个匹配项的正则表达式一起使用时,它有效地将该正则表达式视为以^开头以将其锚定到字符串开头。这个标志在重复使用用于在字符串中找到所有匹配项的正则表达式时更有用。在这种情况下,它导致 String match()方法和 RegExp exec()方法的特殊行为,以强制每个后续匹配项都锚定到上一个匹配项结束的字符串位置。
这些标志可以以任何组合和任何顺序指定。例如,如果你希望你的正则表达式能够识别 Unicode 以进行不区分大小写的匹配,并且打算在字符串中查找多个匹配项,你可以指定标志uig,gui或这三个字母的任何其他排列。
11.3.2 用于模式匹配的字符串方法
到目前为止,我们一直在描述用于定义正则表达式的语法,但没有解释这些正则表达式如何在 JavaScript 代码中实际使用。我们现在转而介绍使用 RegExp 对象的 API。本节首先解释了使用正则表达式执行模式匹配和搜索替换操作的字符串方法。接下来的部分将继续讨论使用 JavaScript 正则表达式进行模式匹配,讨论 RegExp 对象及其方法和属性。
search()
字符串支持四种使用正则表达式的方法。最简单的是search()。这个方法接受一个正则表达式参数,并返回第一个匹配子字符串的起始字符位置,如果没有匹配则返回-1:
"JavaScript".search(/script/ui) // => 4
"Python".search(/script/ui) // => -1
如果search()的参数不是正则表达式,则首先通过将其传递给RegExp构造函数将其转换为正则表达式。search()不支持全局搜索;它会忽略其正则表达式参数的g标志。
replace()
replace()方法执行搜索替换操作。它将正则表达式作为第一个参数,替换字符串作为第二个参数。它在调用它的字符串中搜索与指定模式匹配的内容。如果正则表达式设置了g标志,replace()方法将在字符串中替换所有匹配项为替换字符串;否则,它只会替换找到的第一个匹配项。如果replace()的第一个参数是一个字符串而不是正则表达式,该方法会直接搜索该字符串而不是像search()那样将其转换为正则表达式。例如,你可以使用replace()如下提供文本字符串中“JavaScript”一词的统一大写格式:
// No matter how it is capitalized, replace it with the correct capitalization
text.replace(/javascript/gi, "JavaScript");
然而,replace()比这更强大。回想一下,正则表达式的括号子表达式从左到右编号,并且正则表达式记住了每个子表达式匹配的文本。如果替换字符串中出现了$后跟一个数字,replace()将用指定子表达式匹配的文本替换这两个字符。这是一个非常有用的功能。例如,你可以使用它将字符串中的引号替换为其他字符:
// A quote is a quotation mark, followed by any number of
// nonquotation mark characters (which we capture), followed
// by another quotation mark.
let quote = /"([^"]*)"/g;
// Replace the straight quotation marks with guillemets
// leaving the quoted text (stored in $1) unchanged.
'He said "stop"'.replace(quote, '«$1»') // => 'He said «stop»'
如果你的正则表达式使用了命名捕获组,那么你可以通过名称而不是数字引用匹配的文本:
let quote = /"(?<quotedText>[^"]*)"/g;
'He said "stop"'.replace(quote, '«$<quotedText>»') // => 'He said «stop»'
不需要将替换字符串作为第二个参数传递给replace(),你也可以传递一个函数作为替换值的计算方法。替换函数会被调用并传入多个参数。首先是整个匹配的文本。接下来,如果正则表达式有捕获组,那么被这些组捕获的子字符串将作为参数传递。下一个参数是匹配被找到的字符串中的位置。之后,调用replace()的整个字符串也会被传递。最后,如果正则表达式包含任何命名捕获组,替换函数的最后一个参数是一个对象,其属性名与捕获组名匹配,值为匹配的文本。例如,这里是使用替换函数将字符串中的十进制整数转换为十六进制的代码:
let s = "15 times 15 is 225";
s.replace(/\d+/gu, n => parseInt(n).toString(16)) // => "f times f is e1"
match()
match()方法是 String 正则表达式方法中最通用的。它将正则表达式作为唯一参数(或通过将其传递给RegExp()构造函数将其参数转换为正则表达式)并返回一个包含匹配结果的数组,如果没有找到匹配则返回null。如果正则表达式设置了g标志,该方法将返回出现在字符串中的所有匹配项的数组。例如:
"7 plus 8 equals 15".match(/\d+/g) // => ["7", "8", "15"]
如果正则表达式没有设置g标志,match()不会进行全局搜索;它只是搜索第一个匹配项。在这种非全局情况下,match()仍然返回一个数组,但数组元素完全不同。没有g标志时,返回数组的第一个元素是匹配的字符串,任何剩余的元素是正则表达式中括号捕获组匹配的子字符串。因此,如果match()返回一个数组a,a[0]包含完整匹配,a[1]包含匹配第一个括号表达式的子字符串,依此类推。与replace()方法类比,a[1]与$1相同,a[2]与$2相同,依此类推。
例如,考虑使用以下代码解析 URL⁵:
// A very simple URL parsing RegExp
let url = /(\w+):\/\/([\w.]+)\/(\S*)/;
let text = "Visit my blog at http://www.example.com/~david";
let match = text.match(url);
let fullurl, protocol, host, path;
if (match !== null) {
fullurl = match[0]; // fullurl == "http://www.example.com/~david"
protocol = match[1]; // protocol == "http"
host = match[2]; // host == "www.example.com"
path = match[3]; // path == "~david"
}
在这种非全局情况下,match()返回的数组除了编号数组元素外还有一些对象属性。input属性指的是调用match()的字符串。index属性是匹配开始的字符串位置。如果正则表达式包含命名捕获组,那么返回的数组还有一个groups属性,其值是一个对象。这个对象的属性与命名组的名称匹配,值为匹配的文本。例如,我们可以像这样重新编写之前的 URL 解析示例:
let url = /(?<protocol>\w+):\/\/(?<host>[\w.]+)\/(?<path>\S*)/;
let text = "Visit my blog at http://www.example.com/~david";
let match = text.match(url);
match[0] // => "http://www.example.com/~david"
match.input // => text
match.index // => 17
match.groups.protocol // => "http"
match.groups.host // => "www.example.com"
match.groups.path // => "~david"
我们已经看到,match() 的行为在正则表达式是否设置了 g 标志时会有很大不同。当设置了 y 标志时,行为也会有重要但不那么显著的差异。请记住,y 标志通过限制匹配开始的位置使正则表达式“粘滞”。如果一个正则表达式同时设置了 g 和 y 标志,那么 match() 返回一个匹配字符串的数组,就像在设置了 g 而没有设置 y 时一样。但第一个匹配必须从字符串的开头开始,每个后续匹配必须从前一个匹配的字符紧随其后开始。
如果设置了 y 标志但没有设置 g,那么 match() 会尝试找到单个匹配,并且默认情况下,此匹配受限于字符串的开头。然而,您可以通过设置 RegExp 对象的 lastIndex 属性来更改此默认匹配开始位置,指定要匹配的索引位置。如果找到匹配,那么 lastIndex 将自动更新为匹配后的第一个字符,因此如果再次调用 match(),它将寻找下一个匹配。(lastIndex 可能看起来是一个奇怪的属性名称,它指定开始 下一个 匹配的位置。当我们讨论 RegExp exec() 方法时,我们将再次看到它,这个名称在那种情况下可能更有意义。)
let vowel = /[aeiou]/y; // Sticky vowel match
"test".match(vowel) // => null: "test" does not begin with a vowel
vowel.lastIndex = 1; // Specify a different match position
"test".match(vowel)[0] // => "e": we found a vowel at position 1
vowel.lastIndex // => 2: lastIndex was automatically updated
"test".match(vowel) // => null: no vowel at position 2
vowel.lastIndex // => 0: lastIndex gets reset after failed match
值得注意的是,将非全局正则表达式传递给字符串的 match() 方法与将字符串传递给正则表达式的 exec() 方法是相同的:返回的数组及其属性在这两种情况下都是相同的。
matchAll()
matchAll() 方法在 ES2020 中定义,并且在 2020 年初已被现代 Web 浏览器和 Node 实现。matchAll() 期望一个设置了 g 标志的正则表达式。然而,与 match() 返回匹配子字符串的数组不同,它返回一个迭代器,该迭代器产生与使用非全局 RegExp 时 match() 返回的匹配对象相同的对象。这使得 matchAll() 成为遍历字符串中所有匹配的最简单和最通用的方法。
您可以使用 matchAll() 遍历文本字符串中的单词,如下所示:
// One or more Unicode alphabetic characters between word boundaries
const words = /\b\p{Alphabetic}+\b/gu; // \p is not supported in Firefox yet
const text = "This is a naïve test of the matchAll() method.";
for(let word of text.matchAll(words)) {
console.log(`Found '${word[0]}' at index ${word.index}.`);
}
您可以设置 RegExp 对象的 lastIndex 属性,告诉 matchAll() 在字符串中的哪个索引开始匹配。然而,与其他模式匹配方法不同,matchAll() 永远不会修改您调用它的 RegExp 的 lastIndex 属性,这使得它在您的代码中更不容易出错。
split()
String 对象的正则表达式方法中的最后一个是 split()。这个方法将调用它的字符串分割成一个子字符串数组,使用参数作为分隔符。它可以像这样使用一个字符串参数:
"123,456,789".split(",") // => ["123", "456", "789"]
split() 方法也可以接受正则表达式作为参数,这样可以指定更通用的分隔符。在这里,我们使用一个包含任意数量空白的分隔符来调用它:
"1, 2, 3,\n4, 5".split(/\s*,\s*/) // => ["1", "2", "3", "4", "5"]
令人惊讶的是,如果你使用包含捕获组的正则表达式分隔符调用 split(),那么匹配捕获组的文本将包含在返回的数组中。例如:
const htmlTag = /<([^>]+)>/; // < followed by one or more non->, followed by >
"Testing<br/>1,2,3".split(htmlTag) // => ["Testing", "br/", "1,2,3"]
11.3.3 RegExp 类
本节介绍了 RegExp() 构造函数、RegExp 实例的属性以及 RegExp 类定义的两个重要模式匹配方法。
RegExp() 构造函数接受一个或两个字符串参数,并创建一个新的 RegExp 对象。这个构造函数的第一个参数是一个包含正则表达式主体的字符串——在正则表达式字面量中出现在斜杠内的文本。请注意,字符串字面量和正则表达式都使用 \ 字符作为转义序列,因此当您将正则表达式作为字符串字面量传递给 RegExp() 时,必须将每个 \ 字符替换为 \\。RegExp() 的第二个参数是可选的。如果提供,它表示正则表达式的标志。它应该是 g、i、m、s、u、y,或这些字母的任意组合。
例如:
// Find all five-digit numbers in a string. Note the double \\ in this case.
let zipcode = new RegExp("\\d{5}", "g");
RegExp() 构造函数在动态创建正则表达式时非常有用,因此无法使用正则表达式字面量语法表示。例如,要搜索用户输入的字符串,必须在运行时使用 RegExp() 创建正则表达式。
除了将字符串作为 RegExp() 的第一个参数传递之外,您还可以传递一个 RegExp 对象。这允许您复制正则表达式并更改其标志:
let exactMatch = /JavaScript/;
let caseInsensitive = new RegExp(exactMatch, "i");
RegExp 属性
RegExp 对象具有以下属性:
source
这是正则表达式的源文本的只读属性:在 RegExp 字面量中出现在斜杠之间的字符。
flags
这是一个只读属性,指定表示 RegExp 标志的字母集合的字符串。
global
一个只读的布尔属性,如果设置了 g 标志,则为 true。
ignoreCase
一个只读的布尔属性,如果设置了 i 标志,则为 true。
multiline
一个只读的布尔属性,如果设置了 m 标志,则为 true。
dotAll
一个只读的布尔属性,如果设置了 s 标志,则为 true。
unicode
一个只读的布尔属性,如果设置了 u 标志,则为 true。
sticky
一个只读的布尔属性,如果设置了 y 标志,则为 true。
lastIndex
这个属性是一个读/写整数。对于具有 g 或 y 标志的模式,它指定下一次搜索开始的字符位置。它由 exec() 和 test() 方法使用,这两个方法在下面的两个小节中描述。
test()
RegExp 类的 test() 方法是使用正则表达式的最简单的方法。它接受一个字符串参数,并在字符串与模式匹配时返回 true,否则返回 false。
test() 的工作原理是简单地调用(更复杂的)下一节中描述的 exec() 方法,并在 exec() 返回非空值时返回 true。因此,如果您使用带有 g 或 y 标志的 RegExp 来使用 test(),那么它的行为取决于 RegExp 对象的 lastIndex 属性的值,这个值可能会意外更改。有关更多详细信息,请参阅“lastIndex 属性和 RegExp 重用”。
exec()
RegExp exec() 方法是使用正则表达式的最通用和强大的方式。它接受一个字符串参数,并在该字符串中查找匹配项。如果找不到匹配项,则返回 null。但是,如果找到匹配项,则返回一个数组,就像对于非全局搜索的 match() 方法返回的数组一样。数组的第 0 个元素包含与正则表达式匹配的字符串,任何后续的数组元素包含与任何捕获组匹配的子字符串。返回的数组还具有命名属性:index 属性包含匹配发生的字符位置,input 属性指定被搜索的字符串,如果定义了 groups 属性,则指的是一个保存与任何命名捕获组匹配的子字符串的对象。
与 String 的 match() 方法不同,exec() 无论正则表达式是否有全局 g 标志,都返回相同类型的数组。回想一下,当传递一个全局正则表达式时,match() 返回一个匹配数组。相比之下,exec() 总是返回一个单一匹配,并提供关于该匹配的完整信息。当在具有全局 g 标志或粘性 y 标志的正则表达式上调用 exec() 时,它会查看 RegExp 对象的 lastIndex 属性,以确定从哪里开始查找匹配。如果设置了 y 标志,它还会限制匹配从该位置开始。对于新创建的 RegExp 对象,lastIndex 为 0,并且搜索从字符串的开头开始。但每次 exec() 成功找到一个匹配时,它会更新 lastIndex 属性为匹配文本后面的字符的索引。如果 exec() 未找到匹配,它会将 lastIndex 重置为 0。这种特殊行为允许你重复调用 exec() 以循环遍历字符串中的所有正则表达式匹配。例如,以下代码中的循环将运行两次:
let pattern = /Java/g;
let text = "JavaScript > Java";
let match;
while((match = pattern.exec(text)) !== null) {
console.log(`Matched ${match[0]} at ${match.index}`);
console.log(`Next search begins at ${pattern.lastIndex}`);
}
11.4 日期和时间
Date 类是 JavaScript 用于处理日期和时间的 API。使用 Date() 构造函数创建一个 Date 对象。如果没有参数,它会返回一个代表当前日期和时间的 Date 对象:
let now = new Date(); // The current time
如果你传递一个数字参数,Date() 构造函数会将该参数解释为自 1970 年起的毫秒数:
let epoch = new Date(0); // Midnight, January 1st, 1970, GMT
如果你指定两个或更多整数参数,它们会被解释为年、月、日、小时、分钟、秒和毫秒,使用你的本地时区,如下所示:
let century = new Date(2100, // Year 2100
0, // January
1, // 1st
2, 3, 4, 5); // 02:03:04.005, local time
Date API 的一个怪癖是,一年中的第一个月是数字 0,但一个月中的第一天是数字 1。如果省略时间字段,Date() 构造函数会将它们全部默认为 0,将时间设置为午夜。
请注意,当使用多个数字调用 Date() 构造函数时,它会使用本地计算机设置的任何时区进行解释。如果你想在 UTC(协调世界时,又称 GMT)中指定日期和时间,那么你可以使用 Date.UTC()。这个静态方法接受与 Date() 构造函数相同的参数,在 UTC 中解释它们,并返回一个毫秒时间戳,你可以传递给 Date() 构造函数:
// Midnight in England, January 1, 2100
let century = new Date(Date.UTC(2100, 0, 1));
如果你打印一个日期(例如使用 console.log(century)),默认情况下会以你的本地时区打印。如果你想在 UTC 中显示一个日期,你应该明确地将其转换为字符串,使用 toUTCString() 或 toISOString()。
最后,如果你将一个字符串传递给 Date() 构造函数,它将尝试将该字符串解析为日期和时间规范。构造函数可以解析由 toString()、toUTCString() 和 toISOString() 方法生成的格式指定的日期:
let century = new Date("2100-01-01T00:00:00Z"); // An ISO format date
一旦你有了一个 Date 对象,各种获取和设置方法允许你查询和修改 Date 的年、月、日、小时、分钟、秒和毫秒字段。每个方法都有两种形式:一种使用本地时间进行获取或设置,另一种使用 UTC 时间进行获取或设置。例如,要获取或设置 Date 对象的年份,你可以使用 getFullYear()、getUTCFullYear()、setFullYear() 或 setUTCFullYear():
let d = new Date(); // Start with the current date
d.setFullYear(d.getFullYear() + 1); // Increment the year
要获取或设置 Date 的其他字段,将方法名称中的“FullYear”替换为“Month”、“Date”、“Hours”、“Minutes”、“Seconds”或“Milliseconds”。一些日期设置方法允许你一次设置多个字段。setFullYear() 和 setUTCFullYear() 还可选择设置月份和日期。而 setHours() 和 setUTCHours() 还允许你指定分钟、秒和毫秒字段,除了小时字段。
请注意,查询日期的方法是getDate()和getUTCDate()。更自然的函数getDay()和getUTCDay()返回星期几(星期日为 0,星期六为 6)。星期几是只读的,因此没有相应的setDay()方法。
11.4.1 时间戳
JavaScript 将日期内部表示为整数,指定自 1970 年 1 月 1 日午夜(或之前)以来的毫秒数。支持的整数最大为 8,640,000,000,000,000,因此 JavaScript 在 270,000 年后不会用尽毫秒。
对于任何日期对象,getTime()方法返回内部值,而setTime()方法设置它。因此,您可以像这样为日期添加 30 秒:
d.setTime(d.getTime() + 30000);
这些毫秒值有时被称为时间戳,直接使用它们而不是 Date 对象有时很有用。静态的Date.now()方法返回当前时间作为时间戳,当您想要测量代码运行时间时很有帮助:
let startTime = Date.now();
reticulateSplines(); // Do some time-consuming operation
let endTime = Date.now();
console.log(`Spline reticulation took ${endTime - startTime}ms.`);
11.4.2 日期算术
可以使用 JavaScript 的标准<、<=、>和>=比较运算符比较日期对象。您可以从一个日期对象中减去另一个日期对象以确定两个日期之间的毫秒数。(这是因为 Date 类定义了一个返回时间戳的valueOf()方法。)
如果要从日期中添加或减去指定数量的秒、分钟或小时,通常最简单的方法是修改时间戳,就像前面示例中添加 30 秒到日期一样。如果要添加天数,这种技术变得更加繁琐,对于月份和年份则根本不起作用,因为它们的天数不同。要进行涉及天数、月份和年份的日期算术,可以使用setDate()、setMonth()和setYear()。例如,以下是将三个月和两周添加到当前日期的代码:
let d = new Date();
d.setMonth(d.getMonth() + 3, d.getDate() + 14);
即使溢出,日期设置方法也能正常工作。当我们向当前月份添加三个月时,可能得到大于 11 的值(代表 12 月)。setMonth()通过根据需要递增年份来处理这一点。同样,当我们将月份的日期设置为大于该月份天数的值时,月份会适当递增。
11.4.3 格式化和解析日期字符串
如果您使用 Date 类实际跟踪日期和时间(而不仅仅是测量时间间隔),那么您可能需要向代码的用户显示日期和时间。Date 类定义了许多不同的方法来将 Date 对象转换为字符串。以下是一些示例:
let d = new Date(2020, 0, 1, 17, 10, 30); // 5:10:30pm on New Year's Day 2020
d.toString() // => "Wed Jan 01 2020 17:10:30 GMT-0800 (Pacific Standard Time)"
d.toUTCString() // => "Thu, 02 Jan 2020 01:10:30 GMT"
d.toLocaleDateString() // => "1/1/2020": 'en-US' locale
d.toLocaleTimeString() // => "5:10:30 PM": 'en-US' locale
d.toISOString() // => "2020-01-02T01:10:30.000Z"
这是 Date 类的字符串格式化方法的完整列表:
toString()
此方法使用本地时区,但不以区域感知方式格式化日期和时间。
toUTCString()
此方法使用 UTC 时区,但不以区域感知方式格式化日期。
toISOString()
此方法以 ISO-8601 标准的标准年-月-日小时:分钟:秒.ms 格式打印日期和时间。字母“T”将输出的日期部分与时间部分分开。时间以 UTC 表示,并且最后一个字母“Z”表示这一点。
toLocaleString()
此方法使用本地时区和适合用户区域的格式。
toDateString()
此方法仅格式化日期部分并省略时间。它使用本地时区,不进行区域适当的格式化。
toLocaleDateString()
此方法仅格式化日期。它使用本地时区和适合区域的日期格式。
toTimeString()
此方法仅格式化时间并省略日期。它使用本地时区,但不以区域感知方式格式化时间。
toLocaleTimeString()
这种方法以区域感知方式格式化时间,并使用本地时区。
当将日期和时间格式化为向最终用户显示时,这些日期转换为字符串的方法都不是理想的。查看 §11.7.2 以获取更通用且区域感知的日期和时间格式化技术。
最后,除了这些将 Date 对象转换为字符串的方法之外,还有一个静态的 Date.parse() 方法,它以字符串作为参数,尝试将其解析为日期和时间,并返回表示该日期的时间戳。Date.parse() 能够解析 Date() 构造函数可以解析的相同字符串,并且保证能够解析 toISOString()、toUTCString() 和 toString() 的输出。
11.5 错误类
JavaScript 的 throw 和 catch 语句可以抛出和捕获任何 JavaScript 值,包括原始值。没有必须用于信号错误的异常类型。但是,JavaScript 确实定义了一个 Error 类,并且在使用 throw 信号错误时传统上使用 Error 的实例或子类。使用 Error 对象的一个很好的理由是,当您创建一个 Error 时,它会捕获 JavaScript 堆栈的状态,如果异常未被捕获,堆栈跟踪将显示在错误消息中,这将帮助您调试问题。(请注意,堆栈跟踪显示 Error 对象的创建位置,而不是 throw 语句抛出它的位置。如果您总是在使用 throw new Error() 抛出之前创建对象,这将不会引起任何混淆。)
Error 对象有两个属性:message 和 name,以及一个 toString() 方法。message 属性的值是您传递给 Error() 构造函数的值,必要时转换为字符串。对于使用 Error() 创建的错误对象,name 属性始终为“Error”。toString() 方法简单地返回 name 属性的值,后跟一个冒号和空格,以及 message 属性的值。
尽管它不是 ECMAScript 标准的一部分,但 Node 和所有现代浏览器也在 Error 对象上定义了一个 stack 属性。该属性的值是一个多行字符串,其中包含 JavaScript 调用堆栈在创建 Error 对象时的堆栈跟踪。当捕获到意外错误时,这可能是有用的信息进行记录。
除了 Error 类之外,JavaScript 还定义了一些子类,用于信号 ECMAScript 定义的特定类型的错误。这些子类包括 EvalError、RangeError、ReferenceError、SyntaxError、TypeError 和 URIError。如果看起来合适,您可以在自己的代码中使用这些错误类。与基本 Error 类一样,这些子类的每个都有一个接受单个消息参数的构造函数。并且每个这些子类的实例都有一个 name 属性,其值与构造函数名称相同。
您可以随意定义最能封装您自己程序的错误条件的 Error 子类。请注意,您不仅限于 name 和 message 属性。如果创建一个子类,您可以定义新属性以提供错误详细信息。例如,如果您正在编写解析器,可能会发现定义一个具有指定解析失败确切位置的 line 和 column 属性的 ParseError 类很有用。或者,如果您正在处理 HTTP 请求,可能希望定义一个具有保存失败请求的 HTTP 状态码(例如 404 或 500)的 status 属性的 HTTPError 类。
例如:
class HTTPError extends Error {
constructor(status, statusText, url) {
super(`${status} ${statusText}: ${url}`);
this.status = status;
this.statusText = statusText;
this.url = url;
}
get name() { return "HTTPError"; }
}
let error = new HTTPError(404, "Not Found", "http://example.com/");
error.status // => 404
error.message // => "404 Not Found: http://example.com/"
error.name // => "HTTPError"
11.6 JSON 序列化和解析
当程序需要保存数据或需要将数据通过网络连接传输到另一个程序时,它必须将其内存中的数据结构转换为一串字节或字符,这些字节或字符可以被保存或传输,然后稍后被解析以恢复原始的内存中的数据结构。将数据结构转换为字节流或字符流的过程称为序列化(或编组甚至腌制)。
在 JavaScript 中序列化数据的最简单方法使用了一种称为 JSON 的序列化格式。这个首字母缩写代表“JavaScript 对象表示法”,正如名称所示,该格式使用 JavaScript 对象和数组文字语法将由对象和数组组成的数据结构转换为字符串。JSON 支持原始数字和字符串,以及值true、false和null,以及由这些原始值构建的数组和对象。JSON 不支持 Map、Set、RegExp、Date 或类型化数组等其他 JavaScript 类型。尽管如此,它已被证明是一种非常多才多艺的数据格式,即使在非基于 JavaScript 的程序中也被广泛使用。
JavaScript 支持使用两个函数JSON.stringify()和JSON.parse()进行 JSON 序列化和反序列化,这两个函数在§6.8 中简要介绍过。给定一个不包含任何非可序列化值(如 RegExp 对象或类型化数组)的对象或数组(任意深度嵌套),您可以通过将其传递给JSON.stringify()来简单地序列化对象。正如名称所示,此函数的返回值是一个字符串。并且给定JSON.stringify()返回的字符串,您可以通过将字符串传递给JSON.parse()来重新创建原始数据结构:
let o = {s: "", n: 0, a: [true, false, null]};
let s = JSON.stringify(o); // s == '{"s":"","n":0,"a":[true,false,null]}'
let copy = JSON.parse(s); // copy == {s: "", n: 0, a: [true, false, null]}
如果我们忽略序列化数据保存到文件或通过网络发送的部分,我们可以将这对函数用作创建对象的深层副本的一种效率较低的方式:
// Make a deep copy of any serializable object or array
function deepcopy(o) {
return JSON.parse(JSON.stringify(o));
}
JSON 是 JavaScript 的一个子集
当数据序列化为 JSON 格式时,结果是一个有效的 JavaScript 源代码,用于评估为原始数据结构的副本。如果您在 JSON 字符串前面加上var data =并将结果传递给eval(),您将获得将原始数据结构的副本分配给变量data的结果。但是,您绝对不应该这样做,因为这是一个巨大的安全漏洞——如果攻击者可以将任意 JavaScript 代码注入 JSON 文件中,他们可以使您的程序运行他们的代码。只需使用JSON.parse()来解码 JSON 格式化数据,这样更快速和安全。
JSON 有时被用作人类可读的配置文件格式。如果您发现自己手动编辑 JSON 文件,请注意 JSON 格式是 JavaScript 的一个非常严格的子集。不允许注释,属性名称必须用双引号括起来,即使 JavaScript 不需要这样做。
通常,您只向JSON.stringify()和JSON.parse()传递单个参数。这两个函数都接受一个可选的第二个参数,允许我们扩展 JSON 格式,接下来将对此进行描述。JSON.stringify()还接受一个可选的第三个参数,我们将首先讨论这个参数。如果您希望您的 JSON 格式化字符串可读性强(例如用作配置文件),那么应将null作为第二个参数传递,并将数字或字符串作为第三个参数传递。第三个参数告诉JSON.stringify()应该将数据格式化为多个缩进行。如果第三个参数是一个数字,则它将使用该数字作为每个缩进级别的空格数。如果第三个参数是一个空格字符串(例如'\t'),它将使用该字符串作为每个缩进级别。
let o = {s: "test", n: 0};
JSON.stringify(o, null, 2) // => '{\n "s": "test",\n "n": 0\n}'
JSON.parse()会忽略空格,因此向JSON.stringify()传递第三个参数对我们将字符串转换回数据结构的能力没有影响。
11.6.1 JSON 自定义
如果JSON.stringify()被要求序列化一个 JSON 格式不支持的值,它会查看该值是否有一个toJSON()方法,如果有,它会调用该方法,然后将返回值序列化以替换原始值。Date 对象实现了toJSON():它返回与toISOString()方法相同的字符串。这意味着如果序列化包含 Date 的对象,日期将自动转换为字符串。当您解析序列化的字符串时,重新创建的数据结构将不会与您开始的完全相同,因为它将在原始对象有 Date 的地方有一个字符串。
如果需要重新创建 Date 对象(或以任何其他方式修改解析的对象),可以将“恢复器”函数作为第二个参数传递给JSON.parse()。如果指定了,这个“恢复器”函数将被用于从输入字符串解析的每个原始值(但不包含这些原始值的对象或数组)。该函数被调用时带有两个参数。第一个是属性名称—一个对象属性名称或转换为字符串的数组索引。第二个参数是该对象属性或数组元素的原始值。此外,该函数作为包含原始值的对象或数组的方法被调用,因此您可以使用this关键字引用该包含对象。
恢复函数的返回值将成为命名属性的新值。如果它返回其第二个参数,则属性将保持不变。如果返回undefined,则在JSON.parse()返回给用户之前,命名属性将从对象或数组中删除。
作为示例,这里是一个调用JSON.parse()的示例,使用恢复器函数来过滤一些属性并重新创建 Date 对象:
let data = JSON.parse(text, function(key, value) {
// Remove any values whose property name begins with an underscore
if (key[0] === "_") return undefined;
// If the value is a string in ISO 8601 date format convert it to a Date.
if (typeof value === "string" &&
/^\d\d\d\d-\d\d-\d\dT\d\d:\d\d:\d\d.\d\d\dZ$/.test(value)) {
return new Date(value);
}
// Otherwise, return the value unchanged
return value;
});
除了前面描述的toJSON()的使用,JSON.stringify()还允许通过将数组或函数作为可选的第二个参数来自定义其输出。
如果作为第二个参数传递的是字符串数组(或数字—它们会被转换为字符串),那么这些将被用作对象属性(或数组元素)的名称。任何名称不在数组中的属性都将被省略。此外,返回的字符串将按照它们在数组中出现的顺序包括属性(在编写测试时非常有用)。
如果传递一个函数,它是一个替换函数—实际上是您可以传递给JSON.parse()的可选恢复函数的反函数。如果指定了替换函数,那么替换函数将被用于要序列化的每个值。替换函数的第一个参数是该对象中值的对象属性名称或数组索引,第二个参数是值本身。替换函数作为包含要序列化值的对象或数组的方法被调用。替换函数的返回值将被序列化以替换原始值。如果替换函数返回undefined或根本没有返回任何内容,则该值(及其数组元素或对象属性)将被省略在序列化中。
// Specify what fields to serialize, and what order to serialize them in
let text = JSON.stringify(address, ["city","state","country"]);
// Specify a replacer function that omits RegExp-value properties
let json = JSON.stringify(o, (k, v) => v instanceof RegExp ? undefined : v);
这里的两个JSON.stringify()调用以一种良性的方式使用第二个参数,产生的序列化输出可以在不需要特殊恢复函数的情况下反序列化。然而,一般来说,如果为类型定义了toJSON()方法,或者使用一个实际上用可序列化值替换不可序列化值的替换函数,那么通常需要使用自定义恢复函数与JSON.parse()一起来获取原始数据结构。如果这样做,你应该明白你正在定义一种自定义数据格式,并牺牲了与大量 JSON 兼容工具和语言的可移植性和兼容性。
11.7 国际化 API
JavaScript 国际化 API 由三个类 Intl.NumberFormat、Intl.DateTimeFormat 和 Intl.Collator 组成,允许我们以区域设置适当的方式格式化数字(包括货币金额和百分比)、日期和时间,并以区域设置适当的方式比较字符串。这些类不是 ECMAScript 标准的一部分,但作为ECMA402 标准的一部分定义,并得到 Web 浏览器的良好支持。Intl API 也受 Node 支持,但在撰写本文时,预构建的 Node 二进制文件不包含所需的本地化数据,以使它们能够与除美国英语以外的区域设置一起使用。因此,为了在 Node 中使用这些类,您可能需要下载一个单独的数据包或使用自定义构建的 Node。
国际化中最重要的部分之一是显示已翻译为用户语言的文本。有各种方法可以实现这一点,但这些方法都不在此处描述的 Intl API 的范围内。
11.7.1 格式化数字
世界各地的用户期望以不同的方式格式化数字。小数点可以是句点或逗号。千位分隔符可以是逗号或句点,并且并非在所有地方每三位数字都使用。一些货币被分成百分之一,一些被分成千分之一,一些没有细分。最后,尽管所谓的“阿拉伯数字”0 到 9 在许多语言中使用,但这并非普遍,一些国家的用户期望看到使用其自己脚本中的数字编写的数字。
Intl.NumberFormat 类定义了一个format()方法,考虑到所有这些格式化可能性。构造函数接受两个参数。第一个参数指定应为其格式化数字的区域设置,第二个是一个对象,指定有关如何格式化数字的更多详细信息。如果省略或undefined第一个参数,则将使用系统区域设置(我们假设为用户首选区域设置)。如果第一个参数是字符串,则指定所需的区域设置,例如"en-US"(美国使用的英语)、"fr"(法语)或"zh-Hans-CN"(中国使用简体汉字书写系统)。第一个参数也可以是区域设置字符串数组,在这种情况下,Intl.NumberFormat 将选择最具体且受支持的区域设置。
如果指定了Intl.NumberFormat()构造函数的第二个参数,则应该是一个定义一个或多个以下属性的对象:
style
指定所需的数字格式化类型。默认值为"decimal"。指定"percent"将数字格式化为百分比,或指定"currency"将数字格式化为货币金额。
currency
如果样式为"currency",则需要此属性来指定所需货币的三个字母 ISO 货币代码(例如"USD"表示美元或"GBP"表示英镑)。
currencyDisplay
如果样式为"currency",则此属性指定货币的显示方式。默认值"symbol"使用货币符号(如果货币有符号)。值"code"使用三个字母 ISO 代码,值"name"以长形式拼写货币名称。
useGrouping
将此属性设置为false,如果您不希望数字具有千位分隔符(或其相应的区域设置等价物)。
minimumIntegerDigits
用于显示数字整数部分的最小位数。如果数字的位数少于此值,则将在左侧用零填充。默认值为 1,但可以使用高达 21 的值。
minimumFractionDigits,maximumFractionDigits
这两个属性控制数字的小数部分的格式。如果一个数字的小数位数少于最小值,它将在右侧用零填充。如果小数位数超过最大值,那么小数部分将被四舍五入。这两个属性的合法值介于 0 和 20 之间。默认最小值为 0,最大值为 3,除了在格式化货币金额时,小数部分的长度会根据指定的货币而变化。
minimumSignificantDigits,maximumSignificantDigits
这些属性控制在格式化数字时使用的有效数字位数,使其适用于格式化科学数据等情况。如果指定了这些属性,它们将覆盖先前列出的整数和小数位数属性。合法值介于 1 和 21 之间。
一旦您使用所需的区域设置和选项创建了一个 Intl.NumberFormat 对象,您可以通过将数字传递给其format()方法来使用它,该方法将返回一个适当格式化的字符串。例如:
let euros = Intl.NumberFormat("es", {style: "currency", currency: "EUR"});
euros.format(10) // => "10,00 €": ten euros, Spanish formatting
let pounds = Intl.NumberFormat("en", {style: "currency", currency: "GBP"});
pounds.format(1000) // => "£1,000.00": One thousand pounds, English formatting
Intl.NumberFormat(以及其他 Intl 类)的一个有用功能是它的format()方法绑定到它所属的 NumberFormat 对象。因此,您可以将format()方法分配给一个变量,并像独立函数一样使用它,而不是定义一个引用格式化对象的变量,然后在该变量上调用format()方法,就像这个例子中一样:
let data = [0.05, .75, 1];
let formatData = Intl.NumberFormat(undefined, {
style: "percent",
minimumFractionDigits: 1,
maximumFractionDigits: 1
}).format;
data.map(formatData) // => ["5.0%", "75.0%", "100.0%"]: in en-US locale
一些语言,比如阿拉伯语,使用自己的脚本来表示十进制数字:
let arabic = Intl.NumberFormat("ar", {useGrouping: false}).format;
arabic(1234567890) // => "١٢٣٤٥٦٧٨٩٠"
其他语言,比如印地语,使用自己的数字字符集,但默认情况下倾向于使用 ASCII 数字 0-9。如果要覆盖用于数字的默认字符集,请在区域设置中添加-u-nu-,然后跟上简写的字符集名称。例如,您可以这样格式化数字,使用印度风格的分组和天城数字:
let hindi = Intl.NumberFormat("hi-IN-u-nu-deva").format;
hindi(1234567890) // => "१,२३,४५,६७,८९०"
在区域设置中的-u-指定接下来是一个 Unicode 扩展。nu是编号系统的扩展名称,deva是 Devanagari 的缩写。Intl API 标准为许多其他编号系统定义了名称,主要用于南亚和东南亚的印度语言。
11.7.2 格式化日期和时间
Intl.DateTimeFormat 类与 Intl.NumberFormat 类非常相似。Intl.DateTimeFormat()构造函数接受与Intl.NumberFormat()相同的两个参数:区域设置或区域设置数组以及格式选项对象。使用 Intl.DateTimeFormat 实例的方法是调用其format()方法,将 Date 对象转换为字符串。
如§11.4 中所述,Date 类定义了简单的toLocaleDateString()和toLocaleTimeString()方法,为用户的区域设置生成适当的输出。但是这些方法不会让您控制显示的日期和时间字段。也许您想省略年份,但在日期格式中添加一个工作日。您希望月份是以数字形式表示还是以名称拼写出来?Intl.DateTimeFormat 类根据传递给构造函数的第二个参数中的选项对象中的属性提供对输出的细粒度控制。但是,请注意,Intl.DateTimeFormat 不能总是精确显示您要求的内容。如果指定了格式化小时和秒的选项但省略了分钟,您会发现格式化程序仍然会显示分钟。这个想法是您使用选项对象指定要向用户呈现的日期和时间字段以及您希望如何格式化这些字段(例如按名称或按数字),然后格式化程序将查找最接近您要求的内容的适合区域设置的格式。
可用的选项如下。只为您希望出现在格式化输出中的日期和时间字段指定属性。
年
使用"numeric"表示完整的四位数年份,或使用"2-digit"表示两位数缩写。
月
使用"numeric"表示可能的短数字,如“1”,或"2-digit"表示始终有两位数字的数字表示,如“01”。使用"long"表示全名,如“January”,"short"表示缩写,如“Jan”,"narrow"表示高度缩写,如“J”,不保证唯一。
day
使用"numeric"表示一位或两位数字,或"2-digit"表示月份的两位数字。
weekday
使用"long"表示全名,如“Monday”,"short"表示缩写,如“Mon”,"narrow"表示高度缩写,如“M”,不保证唯一。
era
此属性指定日期是否应以时代(如 CE 或 BCE)格式化。如果您正在格式化很久以前的日期或使用日本日历,则可能很有用。合法值为"long"、"short"和"narrow"。
hour、minute、second
这些属性指定您希望如何显示时间。使用"numeric"表示一位或两位数字字段,或"2-digit"强制将单个数字左侧填充为 0。
timeZone
此属性指定应为其格式化日期的所需时区。如果省略,将使用本地时区。实现始终识别“UTC”,并且还可以识别互联网分配的数字管理局(IANA)时区名称,例如“America/Los_Angeles”。
timeZoneName
此属性指定应如何在格式化的日期或时间中显示时区。使用"long"表示完全拼写的时区名称,"short"表示缩写或数字时区。
hour12
这个布尔属性指定是否使用 12 小时制。默认是与地区相关的,但你可以用这个属性来覆盖它。
hourCycle
此属性允许您指定午夜是写作 0 小时、12 小时还是 24 小时。默认是与地区相关的,但您可以用此属性覆盖默认值。请注意,hour12优先于此属性。使用值"h11"指定午夜为 0,午夜前一小时为 11pm。使用"h12"指定午夜为 12。使用"h23"指定午夜为 0,午夜前一小时为 23。使用"h24"指定午夜为 24。
以下是一些示例:
let d = new Date("2020-01-02T13:14:15Z"); // January 2nd, 2020, 13:14:15 UTC
// With no options, we get a basic numeric date format
Intl.DateTimeFormat("en-US").format(d) // => "1/2/2020"
Intl.DateTimeFormat("fr-FR").format(d) // => "02/01/2020"
// Spelled out weekday and month
let opts = { weekday: "long", month: "long", year: "numeric", day: "numeric" };
Intl.DateTimeFormat("en-US", opts).format(d) // => "Thursday, January 2, 2020"
Intl.DateTimeFormat("es-ES", opts).format(d) // => "jueves, 2 de enero de 2020"
// The time in New York, for a French-speaking Canadian
opts = { hour: "numeric", minute: "2-digit", timeZone: "America/New_York" };
Intl.DateTimeFormat("fr-CA", opts).format(d) // => "8 h 14"
Intl.DateTimeFormat 可以使用除基于基督教时代的默认儒略历之外的其他日历显示日期。尽管一些地区可能默认使用非基督教日历,但您始终可以通过在地区后添加-u-ca-并在其后跟日历名称来明确指定要使用的日历。可能的日历名称包括“buddhist”、“chinese”、“coptic”、“ethiopic”、“gregory”、“hebrew”、“indian”、“islamic”、“iso8601”、“japanese”和“persian”。继续前面的示例,我们可以确定各种非基督教历法中的年份:
let opts = { year: "numeric", era: "short" };
Intl.DateTimeFormat("en", opts).format(d) // => "2020 AD"
Intl.DateTimeFormat("en-u-ca-iso8601", opts).format(d) // => "2020 AD"
Intl.DateTimeFormat("en-u-ca-hebrew", opts).format(d) // => "5780 AM"
Intl.DateTimeFormat("en-u-ca-buddhist", opts).format(d) // => "2563 BE"
Intl.DateTimeFormat("en-u-ca-islamic", opts).format(d) // => "1441 AH"
Intl.DateTimeFormat("en-u-ca-persian", opts).format(d) // => "1398 AP"
Intl.DateTimeFormat("en-u-ca-indian", opts).format(d) // => "1941 Saka"
Intl.DateTimeFormat("en-u-ca-chinese", opts).format(d) // => "36 78"
Intl.DateTimeFormat("en-u-ca-japanese", opts).format(d) // => "2 Reiwa"
11.7.3 比较字符串
将字符串按字母顺序排序(或对于非字母脚本的更一般“排序顺序”)的问题比英语使用者通常意识到的更具挑战性。英语使用相对较小的字母表,没有重音字母,并且我们有字符编码(ASCII,已合并到 Unicode 中)的好处,其数值完全匹配我们的标准字符串排序顺序。在其他语言中情况并不那么简单。例如,西班牙语将ñ视为一个独立的字母,位于 n 之后和 o 之前。立陶宛语将 Y 排在 J 之前,威尔士语将 CH 和 DD 等二合字母视为单个字母,CH 排在 C 之后,DD 排在 D 之后。
如果要按用户自然顺序显示字符串,仅使用数组字符串的sort()方法是不够的。但是,如果创建 Intl.Collator 对象,可以将该对象的compare()方法传递给sort()方法,以执行符合区域设置的字符串排序。Intl.Collator 对象可以配置为使compare()方法执行不区分大小写的比较,甚至只考虑基本字母并忽略重音和其他变音符号的比较。
与Intl.NumberFormat()和Intl.DateTimeFormat()一样,Intl.Collator()构造函数接受两个参数。第一个指定区域设置或区域设置数组,第二个是一个可选对象,其属性精确指定要执行的字符串比较类型。支持的属性如下:
usage
此属性指定如何使用排序器对象。默认值为"sort",但也可以指定"search"。想法是,在对字符串进行排序时,通常希望排序器尽可能区分多个字符串以产生可靠的排序。但是,在比较两个字符串时,某些区域设置可能希望进行较不严格的比较,例如忽略重音。
sensitivity
此属性指定比较字符串时,排序器是否对大小写和重音敏感。值为"base"会忽略大小写和重音,只考虑每个字符的基本字母。(但请注意,某些语言认为某些带重音的字符是不同的基本字母。)"accent"考虑重音但忽略大小写。"case"考虑大小写但忽略重音。"variant"执行严格的比较,考虑大小写和重音。当usage为"sort"时,此属性的默认值为"variant"。如果usage为"search",则默认灵敏度取决于区域设置。
ignorePunctuation
将此属性设置为true以在比较字符串时忽略空格和标点符号。将此属性设置为true后,例如,字符串“any one”和“anyone”将被视为相等。
numeric
如果要比较的字符串是整数或包含整数,并且希望它们按数字顺序而不是按字母顺序排序,请将此属性设置为true。设置此选项后,例如,字符串“Version 9”将在“Version 10”之前排序。
caseFirst
此属性指定哪种大小写应该优先。如果指定为"upper",则“A”将在“a”之前排序。如果指定为"lower",则“a”将在“A”之前排序。无论哪种情况,请注意相同字母的大写和小写变体将按顺序排列在一起,这与 Unicode 词典排序(数组sort()方法的默认行为)不同,在该排序中,所有 ASCII 大写字母都排在所有 ASCII 小写字母之前。此属性的默认值取决于区域设置,并且实现可能会忽略此属性并不允许您覆盖大小写排序顺序。
一旦为所需区域设置和选项创建了 Intl.Collator 对象,就可以使用其compare()方法比较两个字符串。此方法返回一个数字。如果返回值小于零,则第一个字符串在第二个字符串之前。如果大于零,则第一个字符串在第二个字符串之后。如果compare()返回零,则这两个字符串在此排序器的意义上相等。
此接受两个字符串并返回小于、等于或大于零的数字的compare()方法正是数组sort()方法期望的可选参数。此外,Intl.Collator 会自动将compare()方法绑定到其实例,因此可以直接将其传递给sort(),而无需编写包装函数并通过排序器对象调用它。以下是一些示例:
// A basic comparator for sorting in the user's locale.
// Never sort human-readable strings without passing something like this:
const collator = new Intl.Collator().compare;
["a", "z", "A", "Z"].sort(collator) // => ["a", "A", "z", "Z"]
// Filenames often include numbers, so we should sort those specially
const filenameOrder = new Intl.Collator(undefined, { numeric: true }).compare;
["page10", "page9"].sort(filenameOrder) // => ["page9", "page10"]
// Find all strings that loosely match a target string
const fuzzyMatcher = new Intl.Collator(undefined, {
sensitivity: "base",
ignorePunctuation: true
}).compare;
let strings = ["food", "fool", "Føø Bar"];
strings.findIndex(s => fuzzyMatcher(s, "foobar") === 0) // => 2
一些地区有多种可能的排序顺序。例如,在德国,电话簿使用的排序顺序比字典稍微更加语音化。在西班牙,在 1994 年之前,“ch” 和 “ll” 被视为单独的字母,因此该国现在有现代排序顺序和传统排序顺序。在中国,排序顺序可以基于字符编码、每个字符的基本部首和笔画,或者基于字符的拼音罗马化。这些排序变体不能通过 Intl.Collator 选项参数进行选择,但可以通过在区域设置字符串中添加 -u-co- 并添加所需变体的名称来选择。例如,在德国使用 "de-DE-u-co-phonebk" 进行电话簿排序,在台湾使用 "zh-TW-u-co-pinyin" 进行拼音排序。
// Before 1994, CH and LL were treated as separate letters in Spain
const modernSpanish = Intl.Collator("es-ES").compare;
const traditionalSpanish = Intl.Collator("es-ES-u-co-trad").compare;
let palabras = ["luz", "llama", "como", "chico"];
palabras.sort(modernSpanish) // => ["chico", "como", "llama", "luz"]
palabras.sort(traditionalSpanish) // => ["como", "chico", "luz", "llama"]
11.8 控制台 API
你在本书中看到了 console.log() 函数的使用:在网页浏览器中,它会在浏览器的开发者工具窗格的“控制台”选项卡中打印一个字符串,这在调试时非常有帮助。在 Node 中,console.log() 是一个通用输出函数,将其参数打印到进程的 stdout 流中,在终端窗口中通常会显示给用户作为程序输出。
控制台 API 除了 console.log() 外还定义了许多有用的函数。该 API 不是任何 ECMAScript 标准的一部分,但受到浏览器和 Node 的支持,并已经正式编写和标准化在 https://console.spec.whatwg.org。
控制台 API 定义了以下函数:
console.log()
这是控制台函数中最为人熟知的。它将其参数转换为字符串并将它们输出到控制台。它在参数之间包含空格,并在输出所有参数后开始新的一行。
console.debug(), console.info(), console.warn(), console.error()
这些函数几乎与 console.log() 完全相同。在 Node 中,console.error() 将其输出发送到 stderr 流而不是 stdout 流,但其他函数是 console.log() 的别名。在浏览器中,每个函数生成的输出消息可能会以指示其级别或严重性的图标为前缀,并且开发者控制台还可以允许开发者按级别过滤控制台消息。
console.assert()
如果第一个参数为真值(即如果断言通过),则此函数不执行任何操作。但如果第一个参数为 false 或其他假值,则剩余的参数将被打印,就像它们已经被传递给带有“Assertion failed”前缀的 console.error() 一样。请注意,与典型的 assert() 函数不同,当断言失败时,console.assert() 不会抛出异常。
console.clear()
此函数在可能的情况下清除控制台。这在浏览器和在 Node 将其输出显示到终端时有效。但是,如果 Node 的输出已被重定向到文件或管道,则调用此函数没有效果。
console.table()
这个函数是一个非常强大但鲜为人知的功能,用于生成表格输出,特别适用于需要总结数据的 Node 程序。console.table()尝试以表格形式显示其参数(尽管如果无法做到这一点,它会使用常规的console.log()格式)。当参数是一个相对较短的对象数组,并且数组中的所有对象具有相同(相对较小)的属性集时,这种方法效果最佳。在这种情况下,数组中的每个对象被格式化为表格的一行,每个属性是表格的一列。您还可以将属性名称数组作为可选的第二个参数传递,以指定所需的列集。如果传递的是对象而不是对象数组,则输出将是一个具有属性名称列和属性值列的表格。或者,如果这些属性值本身是对象,则它们的属性名称将成为表格中的列。
console.trace()
这个函数像console.log()一样记录其参数,并且在输出后跟随一个堆栈跟踪。在 Node 中,输出会发送到 stderr 而不是 stdout。
console.count()
这个函数接受一个字符串参数,并记录该字符串,然后记录调用该字符串的次数。在调试事件处理程序时,这可能很有用,例如,如果需要跟踪事件处理程序被触发的次数。
console.countReset()
这个函数接受一个字符串参数,并重置该字符串的计数器。
console.group()
这个函数将其参数打印到控制台,就像它们已被传递给console.log()一样,然后设置控制台的内部状态,以便所有后续的控制台消息(直到下一个console.groupEnd()调用)将相对于刚刚打印的消息进行缩进。这允许将一组相关消息视觉上分组并缩进。在 Web 浏览器中,开发者控制台通常允许将分组消息折叠和展开为一组。console.group()的参数通常用于为组提供解释性名称。
console.groupCollapsed()
这个函数与console.group()类似,但在 Web 浏览器中,默认情况下,该组将“折叠”,并且它包含的消息将被隐藏,除非用户点击以展开该组。在 Node 中,此函数是console.group()的同义词。
console.groupEnd()
这个函数不接受任何参数。它不产生自己的输出,但结束了由最近调用的console.group()或console.groupCollapsed()引起的缩进和分组。
console.time()
这个函数接受一个字符串参数,记录调用该字符串的时间,并不产生输出。
console.timeLog()
这个函数将一个字符串作为其第一个参数。如果该字符串之前已传递给console.time(),则打印该字符串,然后是自console.time()调用以来经过的时间。如果console.timeLog()有任何额外的参数,它们将被打印,就像它们已被传递给console.log()一样。
console.timeEnd()
这个函数接受一个字符串参数。如果之前已将该参数传递给console.time(),则打印该参数和经过的时间。在调用console.timeEnd()之后,再次调用console.timeLog()而不先调用console.time()是不合法的。
11.8.1 使用控制台进行格式化输出
类似console.log()打印其参数的控制台函数有一个鲜为人知的功能:如果第一个参数是包含%s、%i、%d、%f、%o、%O或%c的字符串,则此第一个参数将被视为格式字符串,⁶,并且后续参数的值将替换两个字符%序列的位置。
序列的含义如下:
%s
参数被转换为字符串。
%i 和 %d
参数被转换为数字,然后截断为整数。
%f
参数被转换为数字
%o 和 %O
参数被视为对象,并显示属性名称和值。(在 Web 浏览器中,此显示通常是交互式的,用户可以展开和折叠属性以探索嵌套的数据结构。)%o 和 %O 都显示对象的详细信息。大写变体使用一个依赖于实现的输出格式,被认为对软件开发人员最有用。
%c
在 Web 浏览器中,参数被解释为一串 CSS 样式,并用于为接下来的任何文本设置样式(直到下一个 %c 序列或字符串结束)。在 Node 中,%c 序列及其对应的参数会被简单地忽略。
请注意,通常不需要在控制台函数中使用格式字符串:通常只需将一个或多个值(包括对象)传递给函数,让实现以有用的方式显示它们即可。例如,请注意,如果将 Error 对象传递给 console.log(),它将自动打印出其堆栈跟踪。
11.9 URL API
由于 JavaScript 在 Web 浏览器和 Web 服务器中被广泛使用,JavaScript 代码通常需要操作 URL。URL 类解析 URL 并允许修改(例如添加搜索参数或更改路径)现有的 URL。它还正确处理了 URL 的各个组件的转义和解码这一复杂主题。
URL 类不是任何 ECMAScript 标准的一部分,但它在 Node 和除了 Internet Explorer 之外的所有互联网浏览器中都可以使用。它在 https://url.spec.whatwg.org 上标准化。
使用 URL() 构造函数创建一个 URL 对象,将绝对 URL 字符串作为参数传递。或者将相对 URL 作为第一个参数传递,将其相对的绝对 URL 作为第二个参数传递。一旦创建了 URL 对象,它的各种属性允许您查询 URL 的各个部分的未转义版本:
let url = new URL("https://example.com:8000/path/name?q=term#fragment");
url.href // => "https://example.com:8000/path/name?q=term#fragment"
url.origin // => "https://example.com:8000"
url.protocol // => "https:"
url.host // => "example.com:8000"
url.hostname // => "example.com"
url.port // => "8000"
url.pathname // => "/path/name"
url.search // => "?q=term"
url.hash // => "#fragment"
尽管不常用,URL 可以包含用户名或用户名和密码,URL 类也可以解析这些 URL 组件:
let url = new URL("ftp://admin:[email protected]/");
url.href // => "ftp://admin:[email protected]/"
url.origin // => "ftp://ftp.example.com"
url.username // => "admin"
url.password // => "1337!"
这里的 origin 属性是 URL 协议和主机(包括指定的端口)的简单组合。因此,它是一个只读属性。但前面示例中演示的每个其他属性都是读/写的:您可以设置这些属性中的任何一个来设置 URL 的相应部分:
let url = new URL("https://example.com"); // Start with our server
url.pathname = "api/search"; // Add a path to an API endpoint
url.search = "q=test"; // Add a query parameter
url.toString() // => "https://example.com/api/search?q=test"
URL 类的一个重要特性是在需要时正确添加标点符号并转义 URL 中的特殊字符:
let url = new URL("https://example.com");
url.pathname = "path with spaces";
url.search = "q=foo#bar";
url.pathname // => "/path%20with%20spaces"
url.search // => "?q=foo%23bar"
url.href // => "https://example.com/path%20with%20spaces?q=foo%23bar"
这些示例中的 href 属性是一个特殊的属性:读取 href 等同于调用 toString():它将 URL 的所有部分重新组合成 URL 的规范字符串形式。将 href 设置为新字符串会重新运行 URL 解析器,就好像再次调用 URL() 构造函数一样。
在前面的示例中,我们一直使用 search 属性来引用 URL 的整个查询部分,该部分由问号到 URL 结尾的第一个井号字符组成。有时,将其视为单个 URL 属性就足够了。然而,HTTP 请求通常使用 application/x-www-form-urlencoded 格式将多个表单字段或多个 API 参数的值编码到 URL 的查询部分中。在此格式中,URL 的查询部分是一个问号,后面跟着一个或多个名称/值对,它们之间用和号分隔。同一个名称可以出现多次,导致具有多个值的命名搜索参数。
如果你想将这些名称/值对编码到 URL 的查询部分中,那么searchParams属性比search属性更有用。search属性是一个可读/写的字符串,允许你获取和设置 URL 的整个查询部分。searchParams属性是一个只读引用,指向一个 URLSearchParams 对象,该对象具有用于获取、设置、添加、删除和排序编码到 URL 查询部分的参数的 API:
let url = new URL("https://example.com/search");
url.search // => "": no query yet
url.searchParams.append("q", "term"); // Add a search parameter
url.search // => "?q=term"
url.searchParams.set("q", "x"); // Change the value of this parameter
url.search // => "?q=x"
url.searchParams.get("q") // => "x": query the parameter value
url.searchParams.has("q") // => true: there is a q parameter
url.searchParams.has("p") // => false: there is no p parameter
url.searchParams.append("opts", "1"); // Add another search parameter
url.search // => "?q=x&opts=1"
url.searchParams.append("opts", "&"); // Add another value for same name
url.search // => "?q=x&opts=1&opts=%26": note escape
url.searchParams.get("opts") // => "1": the first value
url.searchParams.getAll("opts") // => ["1", "&"]: all values
url.searchParams.sort(); // Put params in alphabetical order
url.search // => "?opts=1&opts=%26&q=x"
url.searchParams.set("opts", "y"); // Change the opts param
url.search // => "?opts=y&q=x"
// searchParams is iterable
[...url.searchParams] // => [["opts", "y"], ["q", "x"]]
url.searchParams.delete("opts"); // Delete the opts param
url.search // => "?q=x"
url.href // => "https://example.com/search?q=x"
searchParams属性的值是一个 URLSearchParams 对象。如果你想将 URL 参数编码到查询字符串中,可以创建一个 URLSearchParams 对象,追加参数,然后将其转换为字符串并设置在 URL 的search属性上:
let url = new URL("http://example.com");
let params = new URLSearchParams();
params.append("q", "term");
params.append("opts", "exact");
params.toString() // => "q=term&opts=exact"
url.search = params;
url.href // => "http://example.com/?q=term&opts=exact"
11.9.1 传统 URL 函数
在之前描述的 URL API 定义之前,已经有多次尝试在核心 JavaScript 语言中支持 URL 转义和解码。第一次尝试是全局定义的escape()和unescape()函数,现在已经被弃用,但仍然被广泛实现。不应该使用它们。
当escape()和unescape()被弃用时,ECMAScript 引入了两对替代的全局函数:
encodeURI()和decodeURI()
encodeURI()以字符串作为参数,返回一个新字符串,其中非 ASCII 字符和某些 ASCII 字符(如空格)被转义。decodeURI()则相反。需要转义的字符首先被转换为它们的 UTF-8 编码,然后该编码的每个字节被替换为一个%xx转义序列,其中xx是两个十六进制数字。因为encodeURI()旨在对整个 URL 进行编码,它不会转义 URL 分隔符字符,如/、?和#。但这意味着encodeURI()无法正确处理 URL 中包含这些字符的各个组件的 URL。
encodeURIComponent()和decodeURIComponent()
这一对函数的工作方式与encodeURI()和decodeURI()完全相同,只是它们旨在转义 URI 的各个组件,因此它们还会转义用于分隔这些组件的字符,如/、?和#。这些是传统 URL 函数中最有用的,但请注意,encodeURIComponent()会转义路径名中的/字符,这可能不是你想要的。它还会将查询参数中的空格转换为%20,尽管在 URL 的这部分中应该用+转义空格。
所有这些传统函数的根本问题在于,它们试图对 URL 的所有部分应用单一的编码方案,而事实上 URL 的不同部分使用不同的编码。如果你想要一个格式正确且编码正确的 URL,解决方案就是简单地使用 URL 类来进行所有的 URL 操作。
11.10 定时器
自 JavaScript 诞生以来,Web 浏览器就定义了两个函数——setTimeout()和setInterval()——允许程序要求浏览器在指定的时间过去后调用一个函数,或者在指定的时间间隔内重复调用函数。这些函数从未作为核心语言的一部分标准化,但它们在所有浏览器和 Node 中都有效,并且是 JavaScript 标准库的事实部分。
setTimeout()的第一个参数是一个函数,第二个参数是一个数字,指定在调用函数之前应该经过多少毫秒。在指定的时间过去后(如果系统繁忙可能会稍长一些),函数将被调用,不带任何参数。这里,例如,是三个setTimeout()调用,分别在一秒、两秒和三秒后打印控制台消息:
setTimeout(() => { console.log("Ready..."); }, 1000);
setTimeout(() => { console.log("set..."); }, 2000);
setTimeout(() => { console.log("go!"); }, 3000);
请注意,setTimeout()在返回之前不会等待时间过去。这个示例中的三行代码几乎立即运行,但在经过 1,000 毫秒后才会发生任何事情。
如果省略setTimeout()的第二个参数,则默认为 0。然而,这并不意味着您指定的函数会立即被调用。相反,该函数被注册为“尽快”调用。如果浏览器忙于处理用户输入或其他事件,可能需要 10 毫秒或更长时间才能调用该函数。
setTimeout()注册一个函数,该函数将在一次调用后被调用。有时,该函数本身会调用setTimeout()以安排在将来的某个时间再次调用。然而,如果要重复调用一个函数,通常更简单的方法是使用setInterval()。setInterval()接受与setTimeout()相同的两个参数,但每当指定的毫秒数(大约)过去时,它会重复调用函数。
setTimeout()和setInterval()都会返回一个值。如果将此值保存在变量中,您随后可以使用它通过传递给clearTimeout()或clearInterval()来取消函数的执行。返回的值在 Web 浏览器中通常是一个数字,在 Node 中是一个对象。实际类型并不重要,您应该将其视为不透明值。您可以使用此值的唯一操作是将其传递给clearTimeout()以取消使用setTimeout()注册的函数的执行(假设尚未调用)或停止使用setInterval()注册的函数的重复执行。
这是一个示例,演示了如何使用setTimeout()、setInterval()和clearInterval()来显示一个简单的数字时钟与 Console API:
// Once a second: clear the console and print the current time
let clock = setInterval(() => {
console.clear();
console.log(new Date().toLocaleTimeString());
}, 1000);
// After 10 seconds: stop the repeating code above.
setTimeout(() => { clearInterval(clock); }, 10000);
当我们讨论异步编程时,我们将再次看到setTimeout()和setInterval(),详见第十三章。
11.11 总结
学习一门编程语言不仅仅是掌握语法。同样重要的是研究标准库,以便熟悉语言附带的所有工具。本章记录了 JavaScript 的标准库,其中包括:
-
重要的数据结构,如 Set、Map 和类型化数组。
-
用于处理日期和 URL 的 Date 和 URL 类。
-
JavaScript 的正则表达式语法及其用于文本模式匹配的 RegExp 类。
-
JavaScript 的国际化库,用于格式化日期、时间和数字以及对字符串进行排序。
-
用于序列化和反序列化简单数据结构的
JSON对象和用于记录消息的console对象。
¹ 这里记录的并非 JavaScript 语言规范定义的所有内容:这里记录的一些类和函数首先是在 Web 浏览器中实现的,然后被 Node 采用,使它们成为 JavaScript 标准库的事实成员。
² 这种可预测的迭代顺序是 JavaScript 集合中的另一件事,可能会让 Python 程序员感到惊讶。
³ 当 Web 浏览器添加对 WebGL 图形的支持时,类型化数组首次引入到客户端 JavaScript 中。ES6 中的新功能是它们已被提升为核心语言特性。
⁴ 除了在字符类(方括号)内部,\b匹配退格字符。
⁵ 使用正则表达式解析 URL 并不是一个好主意。请参见§11.9 以获取更健壮的 URL 解析器。
⁶ C 程序员将从printf()函数中认出许多这些字符序列。