第十二章:迭代器和生成器
可迭代对象及其相关的迭代器是 ES6 的一个特性,在本书中我们已经多次见到。数组(包括 TypedArrays)、字符串以及 Set 和 Map 对象都是可迭代的。这意味着这些数据结构的内容可以被迭代——使用for/of循环遍历,就像我们在§5.4.4 中看到的那样:
let sum = 0;
for(let i of [1,2,3]) { // Loop once for each of these values
sum += i;
}
sum // => 6
迭代器也可以与...运算符一起使用,将可迭代对象展开或“扩展”到数组初始化程序或函数调用中,就像我们在§7.1.2 中看到的那样:
let chars = [..."abcd"]; // chars == ["a", "b", "c", "d"]
let data = [1, 2, 3, 4, 5];
Math.max(...data) // => 5
迭代器可以与解构赋值一起使用:
let purpleHaze = Uint8Array.of(255, 0, 255, 128);
let [r, g, b, a] = purpleHaze; // a == 128
当你迭代 Map 对象时,返回的值是[key, value]对,这与for/of循环中的解构赋值很好地配合使用:
let m = new Map([["one", 1], ["two", 2]]);
for(let [k,v] of m) console.log(k, v); // Logs 'one 1' and 'two 2'
如果你只想迭代键或值而不是键值对,可以使用keys()和values()方法:
[...m] // => [["one", 1], ["two", 2]]: default iteration
[...m.entries()] // => [["one", 1], ["two", 2]]: entries() method is the same
[...m.keys()] // => ["one", "two"]: keys() method iterates just map keys
[...m.values()] // => [1, 2]: values() method iterates just map values
最后,一些常用于 Array 对象的内置函数和构造函数实际上(在 ES6 及更高版本中)被编写为接受任意迭代器。Set()构造函数就是这样一个 API:
// Strings are iterable, so the two sets are the same:
new Set("abc") // => new Set(["a", "b", "c"])
本章解释了迭代器的工作原理,并演示了如何创建自己的可迭代数据结构。在解释基本迭代器之后,本章涵盖了生成器,这是 ES6 的一个强大新功能,主要用作一种特别简单的创建迭代器的方法。
12.1 迭代器的工作原理
for/of循环和展开运算符与可迭代对象无缝配合,但值得理解实际上是如何使迭代工作的。在理解 JavaScript 中的迭代过程时,有三种不同的类型需要理解。首先是可迭代对象:这些是可以被迭代的类型,如 Array、Set 和 Map。其次,是执行迭代的迭代器对象本身。第三,是保存迭代每一步结果的迭代结果对象。
可迭代对象是任何具有特殊迭代器方法的对象,该方法返回一个迭代器对象。迭代器是任何具有返回迭代结果对象的next()方法的对象。而迭代结果对象是具有名为value和done的属性的对象。要迭代可迭代对象,首先调用其迭代器方法以获取一个迭代器对象。然后,重复调用迭代器对象的next()方法,直到返回的值的done属性设置为true为止。关于这一点的棘手之处在于,可迭代对象的迭代器方法没有传统的名称,而是使用符号Symbol.iterator作为其名称。因此,对可迭代对象iterable进行简单的for/of循环也可以以较困难的方式编写,如下所示:
let iterable = [99];
let iterator = iterable[Symbol.iterator]();
for(let result = iterator.next(); !result.done; result = iterator.next()) {
console.log(result.value) // result.value == 99
}
内置可迭代数据类型的迭代器对象本身也是可迭代的。(也就是说,它有一个名为Symbol.iterator的方法,该方法返回自身。)这在以下代码中偶尔会有用,当你想要遍历“部分使用过”的迭代器时:
let list = [1,2,3,4,5];
let iter = list[Symbol.iterator]();
let head = iter.next().value; // head == 1
let tail = [...iter]; // tail == [2,3,4,5]
12.2 实现可迭代对象
在 ES6 中,可迭代对象非常有用,因此当它们表示可以被迭代的内容时,你应该考虑使自己的数据类型可迭代。在第 9-2 和第 9-3 示例中展示的 Range 类是可迭代的。这些类使用生成器函数使自己可迭代。我们稍后会介绍生成器,但首先,我们将再次实现 Range 类,使其可迭代而不依赖于生成器。
要使类可迭代,必须实现一个方法,其名称为符号Symbol.iterator。该方法必须返回具有next()方法的迭代器对象。而next()方法必须返回具有value属性和/或布尔done属性的迭代结果对象。示例 12-1 实现了一个可迭代的 Range 类,并演示了如何创建可迭代、迭代器和迭代结果对象。
示例 12-1. 一个可迭代的数字范围类
/*
* A Range object represents a range of numbers {x: from <= x <= to}
* Range defines a has() method for testing whether a given number is a member
* of the range. Range is iterable and iterates all integers within the range.
*/
class Range {
constructor (from, to) {
this.from = from;
this.to = to;
}
// Make a Range act like a Set of numbers
has(x) { return typeof x === "number" && this.from <= x && x <= this.to; }
// Return string representation of the range using set notation
toString() { return `{ x | ${this.from} ≤ x ≤ ${this.to} }`; }
// Make a Range iterable by returning an iterator object.
// Note that the name of this method is a special symbol, not a string.
[Symbol.iterator]() {
// Each iterator instance must iterate the range independently of
// others. So we need a state variable to track our location in the
// iteration. We start at the first integer >= from.
let next = Math.ceil(this.from); // This is the next value we return
let last = this.to; // We won't return anything > this
return { // This is the iterator object
// This next() method is what makes this an iterator object.
// It must return an iterator result object.
next() {
return (next <= last) // If we haven't returned last value yet
? { value: next++ } // return next value and increment it
: { done: true }; // otherwise indicate that we're done.
},
// As a convenience, we make the iterator itself iterable.
[Symbol.iterator]() { return this; }
};
}
}
for(let x of new Range(1,10)) console.log(x); // Logs numbers 1 to 10
[...new Range(-2,2)] // => [-2, -1, 0, 1, 2]
除了使您的类可迭代之外,定义返回可迭代值的函数也非常有用。考虑这些基于迭代的替代方案,用于 JavaScript 数组的map()和filter()方法:
// Return an iterable object that iterates the result of applying f()
// to each value from the source iterable
function map(iterable, f) {
let iterator = iterable[Symbol.iterator]();
return { // This object is both iterator and iterable
[Symbol.iterator]() { return this; },
next() {
let v = iterator.next();
if (v.done) {
return v;
} else {
return { value: f(v.value) };
}
}
};
}
// Map a range of integers to their squares and convert to an array
[...map(new Range(1,4), x => x*x)] // => [1, 4, 9, 16]
// Return an iterable object that filters the specified iterable,
// iterating only those elements for which the predicate returns true
function filter(iterable, predicate) {
let iterator = iterable[Symbol.iterator]();
return { // This object is both iterator and iterable
[Symbol.iterator]() { return this; },
next() {
for(;;) {
let v = iterator.next();
if (v.done || predicate(v.value)) {
return v;
}
}
}
};
}
// Filter a range so we're left with only even numbers
[...filter(new Range(1,10), x => x % 2 === 0)] // => [2,4,6,8,10]
可迭代对象和迭代器的一个关键特性是它们本质上是惰性的:当需要计算下一个值时,该计算可以推迟到实际需要该值时。例如,假设您有一个非常长的文本字符串,您希望将其标记为以空格分隔的单词。您可以简单地使用字符串的split()方法,但如果这样做,那么必须在使用第一个单词之前处理整个字符串。并且您最终会为返回的数组及其中的所有字符串分配大量内存。以下是一个函数,允许您惰性迭代字符串的单词,而无需一次性将它们全部保存在内存中(在 ES2020 中,使用返回迭代器的matchAll()方法更容易实现此函数,该方法在 §11.3.2 中描述):
function words(s) {
var r = /\s+|$/g; // Match one or more spaces or end
r.lastIndex = s.match(/[^ ]/).index; // Start matching at first nonspace
return { // Return an iterable iterator object
[Symbol.iterator]() { // This makes us iterable
return this;
},
next() { // This makes us an iterator
let start = r.lastIndex; // Resume where the last match ended
if (start < s.length) { // If we're not done
let match = r.exec(s); // Match the next word boundary
if (match) { // If we found one, return the word
return { value: s.substring(start, match.index) };
}
}
return { done: true }; // Otherwise, say that we're done
}
};
}
[...words(" abc def ghi! ")] // => ["abc", "def", "ghi!"]
12.2.1 “关闭”迭代器:返回方法
想象一个(服务器端)JavaScript 变体的words()迭代器,它不是以源字符串作为参数,而是以文件流作为参数,打开文件,从中读取行,并迭代这些行中的单词。在大多数操作系统中,打开文件以从中读取的程序在完成读取后需要记住关闭这些文件,因此这个假设的迭代器将确保在next()方法返回其中的最后一个单词后关闭文件。
但迭代器并不总是运行到结束:for/of循环可能会被break、return或异常终止。同样,当迭代器与解构赋值一起使用时,next()方法只会被调用足够次数以获取每个指定变量的值。迭代器可能有更多值可以返回,但它们永远不会被请求。
如果我们假设的文件中的单词迭代器从未完全运行到结束,它仍然需要关闭打开的文件。因此,迭代器对象可能会实现一个return()方法,与next()方法一起使用。如果在next()返回具有done属性设置为true的迭代结果之前迭代停止(通常是因为您通过break语句提前离开了for/of循环),那么解释器将检查迭代器对象是否具有return()方法。如果存在此方法,解释器将以无参数调用它,使迭代器有机会关闭文件,释放内存,并在完成后进行清理。return()方法必须返回一个迭代结果对象。对象的属性将被忽略,但返回非对象值是错误的。
for/of循环和展开运算符是 JavaScript 的非常有用的特性,因此在创建 API 时,尽可能使用它们是一个好主意。但是,必须使用可迭代对象、其迭代器对象和迭代器的结果对象来处理过程有些复杂。幸运的是,生成器可以极大地简化自定义迭代器的创建,我们将在本章的其余部分中看到。
12.3 生成器
生成器是一种使用强大的新 ES6 语法定义的迭代器;当要迭代的值不是数据结构的元素,而是计算结果时,它特别有用。
要创建一个生成器,你必须首先定义一个生成器函数。生成器函数在语法上类似于普通的 JavaScript 函数,但是用关键字function*而不是function来定义。(从技术上讲,这不是一个新关键字,只是在关键字function之后和函数名之前加上一个*。)当你调用一个生成器函数时,它实际上不会执行函数体,而是返回一个生成器对象。这个生成器对象是一个迭代器。调用它的next()方法会导致生成器函数的主体从头开始运行(或者从当前位置开始),直到达到一个yield语句。yield在 ES6 中是新的,类似于return语句。yield语句的值成为迭代器上next()调用返回的值。通过示例可以更清楚地理解这一点:
// A generator function that yields the set of one digit (base-10) primes.
function* oneDigitPrimes() { // Invoking this function does not run the code
yield 2; // but just returns a generator object. Calling
yield 3; // the next() method of that generator runs
yield 5; // the code until a yield statement provides
yield 7; // the return value for the next() method.
}
// When we invoke the generator function, we get a generator
let primes = oneDigitPrimes();
// A generator is an iterator object that iterates the yielded values
primes.next().value // => 2
primes.next().value // => 3
primes.next().value // => 5
primes.next().value // => 7
primes.next().done // => true
// Generators have a Symbol.iterator method to make them iterable
primes[Symbol.iterator]() // => primes
// We can use generators like other iterable types
[...oneDigitPrimes()] // => [2,3,5,7]
let sum = 0;
for(let prime of oneDigitPrimes()) sum += prime;
sum // => 17
在这个例子中,我们使用了function*语句来定义一个生成器。然而,和普通函数一样,我们也可以以表达式形式定义生成器。再次强调,我们只需在function关键字后面加上一个星号:
const seq = function*(from,to) {
for(let i = from; i <= to; i++) yield i;
};
[...seq(3,5)] // => [3, 4, 5]
在类和对象字面量中,我们可以使用简写符号来完全省略定义方法时的function关键字。在这种情况下定义生成器,我们只需在方法名之前使用一个星号,而不是使用function关键字:
let o = {
x: 1, y: 2, z: 3,
// A generator that yields each of the keys of this object
*g() {
for(let key of Object.keys(this)) {
yield key;
}
}
};
[...o.g()] // => ["x", "y", "z", "g"]
请注意,没有办法使用箭头函数语法编写生成器函数。
生成器通常使得定义可迭代类变得特别容易。我们可以用一个更简短的*Symbol.iterator]()生成器函数来替换[示例 12-1 中展示的[Symbol.iterator]()方法,代码如下:
*[Symbol.iterator]() {
for(let x = Math.ceil(this.from); x <= this.to; x++) yield x;
}
查看第九章中的示例 9-3 以查看上下文中基于生成器的迭代器函数。
12.3.1 生成器示例
如果生成器实际上生成它们通过进行某种计算来产生的值,那么生成器就更有趣了。例如,这里是一个产生斐波那契数的生成器函数:
function* fibonacciSequence() {
let x = 0, y = 1;
for(;;) {
yield y;
[x, y] = [y, x+y]; // Note: destructuring assignment
}
}
注意,这里的fibonacciSequence()生成器函数有一个无限循环,并且永远产生值而不返回。如果这个生成器与...扩展运算符一起使用,它将循环直到内存耗尽并且程序崩溃。然而,经过谨慎处理,可以在for/of循环中使用它:
// Return the nth Fibonacci number
function fibonacci(n) {
for(let f of fibonacciSequence()) {
if (n-- <= 0) return f;
}
}
fibonacci(20) // => 10946
这种无限生成器与这样的take()生成器结合使用更有用:
// Yield the first n elements of the specified iterable object
function* take(n, iterable) {
let it = iterable[Symbol.iterator](); // Get iterator for iterable object
while(n-- > 0) { // Loop n times:
let next = it.next(); // Get the next item from the iterator.
if (next.done) return; // If there are no more values, return early
else yield next.value; // otherwise, yield the value
}
}
// An array of the first 5 Fibonacci numbers
[...take(5, fibonacciSequence())] // => [1, 1, 2, 3, 5]
这里是另一个有用的生成器函数,它交错多个可迭代对象的元素:
// Given an array of iterables, yield their elements in interleaved order.
function* zip(...iterables) {
// Get an iterator for each iterable
let iterators = iterables.map(i => i[Symbol.iterator]());
let index = 0;
while(iterators.length > 0) { // While there are still some iterators
if (index >= iterators.length) { // If we reached the last iterator
index = 0; // go back to the first one.
}
let item = iterators[index].next(); // Get next item from next iterator.
if (item.done) { // If that iterator is done
iterators.splice(index, 1); // then remove it from the array.
}
else { // Otherwise,
yield item.value; // yield the iterated value
index++; // and move on to the next iterator.
}
}
}
// Interleave three iterable objects
[...zip(oneDigitPrimes(),"ab",[0])] // => [2,"a",0,3,"b",5,7]
12.3.2 yield* 和递归生成器
除了在前面的示例中定义的zip()生成器之外,可能还有一个类似的生成器函数很有用,它按顺序而不是交错地产生多个可迭代对象的元素。我们可以这样编写这个生成器:
function* sequence(...iterables) {
for(let iterable of iterables) {
for(let item of iterable) {
yield item;
}
}
}
[...sequence("abc",oneDigitPrimes())] // => ["a","b","c",2,3,5,7]
在生成器函数中产生其他可迭代对象的元素的过程在生成器函数中是很常见的,ES6 为此提供了特殊的语法。yield*关键字类似于yield,不同之处在于,它不是产生单个值,而是迭代一个可迭代对象并产生每个结果值。我们使用的sequence()生成器函数可以用yield*简化如下:
function* sequence(...iterables) {
for(let iterable of iterables) {
yield* iterable;
}
}
[...sequence("abc",oneDigitPrimes())] // => ["a","b","c",2,3,5,7]
数组的forEach()方法通常是遍历数组元素的一种优雅方式,因此你可能会尝试像这样编写sequence()函数:
function* sequence(...iterables) {
iterables.forEach(iterable => yield* iterable ); // Error
}
然而,这是行不通的。yield和yield*只能在生成器函数内部使用,但是这段代码中的嵌套箭头函数是一个普通函数,而不是function*生成器函数,因此不允许使用yield。
yield*可以与任何类型的可迭代对象一起使用,包括使用生成器实现的可迭代对象。这意味着yield*允许我们定义递归生成器,你可以使用这个特性来允许对递归定义的树结构进行简单的非递归迭代,例如。
12.4 高级生成器功能
生成器函数最常见的用途是创建迭代器,但生成器的基本特性是允许我们暂停计算,产生中间结果,然后稍后恢复计算。这意味着生成器具有超出迭代器的功能,并且我们将在以下部分探讨这些功能。
12.4.1 生成器函数的返回值
到目前为止,我们看到的生成器函数没有return语句,或者如果有的话,它们被用来导致早期返回,而不是返回一个值。不过,与任何函数一样,生成器函数可以返回一个值。为了理解在这种情况下会发生什么,回想一下迭代的工作原理。next()函数的返回值是一个具有value属性和/或done属性的对象。对于典型的迭代器和生成器,如果value属性被定义,则done属性未定义或为false。如果done为true,则value为未定义。但是对于返回值的生成器,最后一次调用next会返回一个同时定义了value和done的对象。value属性保存生成器函数的返回值,done属性为true,表示没有更多的值可迭代。这个最终值被for/of循环和展开运算符忽略,但对于手动使用显式调用next()的代码是可用的:
function *oneAndDone() {
yield 1;
return "done";
}
// The return value does not appear in normal iteration.
[...oneAndDone()] // => [1]
// But it is available if you explicitly call next()
let generator = oneAndDone();
generator.next() // => { value: 1, done: false}
generator.next() // => { value: "done", done: true }
// If the generator is already done, the return value is not returned again
generator.next() // => { value: undefined, done: true }
12.4.2 yield 表达式的值
在前面的讨论中,我们将yield视为接受值但没有自身值的语句。实际上,yield是一个表达式,它可以有一个值。
当调用生成器的next()方法时,生成器函数运行直到达到yield表达式。yield关键字后面的表达式被评估,该值成为next()调用的返回值。此时,生成器函数在评估yield表达式的过程中停止执行。下次调用生成器的next()方法时,传递给next()的参数成为暂停的yield表达式的值。因此,生成器通过yield向其调用者返回值,调用者通过next()向生成器传递值。生成器和调用者是两个独立的执行流,来回传递值(和控制)。以下代码示例:
function* smallNumbers() {
console.log("next() invoked the first time; argument discarded");
let y1 = yield 1; // y1 == "b"
console.log("next() invoked a second time with argument", y1);
let y2 = yield 2; // y2 == "c"
console.log("next() invoked a third time with argument", y2);
let y3 = yield 3; // y3 == "d"
console.log("next() invoked a fourth time with argument", y3);
return 4;
}
let g = smallNumbers();
console.log("generator created; no code runs yet");
let n1 = g.next("a"); // n1.value == 1
console.log("generator yielded", n1.value);
let n2 = g.next("b"); // n2.value == 2
console.log("generator yielded", n2.value);
let n3 = g.next("c"); // n3.value == 3
console.log("generator yielded", n3.value);
let n4 = g.next("d"); // n4 == { value: 4, done: true }
console.log("generator returned", n4.value);
当运行这段代码时,会产生以下输出,展示了两个代码块之间的来回交互:
generator created; no code runs yet
next() invoked the first time; argument discarded
generator yielded 1
next() invoked a second time with argument b
generator yielded 2
next() invoked a third time with argument c
generator yielded 3
next() invoked a fourth time with argument d
generator returned 4
注意这段代码中的不对称性。第一次调用next()启动了生成器,但传递给该调用的值对生成器不可访问。
12.4.3 生成器的 return()和 throw()方法
我们已经看到可以接收生成器函数产生的值。您可以通过在调用生成器的next()方法时传递这些值来向正在运行的生成器传递值。
除了使用next()向生成器提供输入外,还可以通过调用其return()和throw()方法来更改生成器内部的控制流。如其名称所示,调用这些方法会导致生成器返回一个值或抛出异常,就好像生成器中的下一条语句是return或throw一样。
在本章的前面提到,如果迭代器定义了一个return()方法并且迭代提前停止,那么解释器会自动调用return()方法,以便让迭代器有机会关闭文件或进行其他清理工作。对于生成器来说,你不能定义一个自定义的return()方法来处理清理工作,但你可以结构化生成器代码以使用try/finally语句,在生成器返回时确保必要的清理工作已完成(在finally块中)。通过强制生成器返回,生成器的内置return()方法确保在生成器不再使用时运行清理代码。
就像生成器的next()方法允许我们向正在运行的生成器传递任意值一样,生成器的throw()方法给了我们一种向生成器发送任意信号(以异常的形式)的方法。调用throw()方法总是在生成器内部引发异常。但如果生成器函数编写了适当的异常处理代码,异常不必是致命的,而可以是改变生成器行为的手段。例如,想象一个计数器生成器,产生一个不断增加的整数序列。这可以被编写成使用throw()发送的异常将计数器重置为零。
当生成器使用yield*从其他可迭代对象中产生值时,那么对生成器的next()方法的调用会导致对可迭代对象的next()方法的调用。return()和throw()方法也是如此。如果生成器在可迭代对象上使用yield*,那么在生成器上调用return()或throw()会导致依次调用迭代器的return()或throw()方法。所有迭代器必须有一个next()方法。需要在不完整迭代后进行清理的迭代器应该定义一个return()方法。任何迭代器可以定义一个throw()方法,尽管我不知道任何实际原因这样做。
12.4.4 关于生成器的最后说明
生成器是一种非常强大的通用控制结构。它们使我们能够使用yield暂停计算,并在任意后续时间点以任意输入值重新启动。可以使用生成器在单线程 JavaScript 代码中创建一种协作线程系统。也可以使用生成器掩盖程序中的异步部分,使你的代码看起来是顺序和同步的,尽管你的一些函数调用实际上是异步的并依赖于网络事件。
尝试用生成器做这些事情会导致代码难以理解或解释。然而,已经做到了,唯一真正实用的用例是管理异步代码。然而,JavaScript 现在有async和await关键字(见第十三章)用于这个目的,因此不再有任何滥用生成器的理由。
12.5 总结
在本章中,你学到了:
-
for/of循环和...扩展运算符适用于可迭代对象。 -
如果一个对象有一个名为
[Symbol.iterator]的方法返回一个迭代器对象,那么它就是可迭代的。 -
迭代器对象有一个
next()方法返回一个迭代结果对象。 -
迭代结果对象有一个
value属性,保存下一个迭代的值(如果有的话)。如果迭代已完成,则结果对象必须将done属性设置为true。 -
你可以通过定义一个
[Symbol.iterator]()方法返回一个具有next()方法返回迭代结果对象的对象来实现自己的可迭代对象。你也可以实现接受迭代器参数并返回迭代器值的函数。 -
生成器函数(使用
function*而不是function定义的函数)是定义迭代器的另一种方式。 -
当调用生成器函数时,函数体不会立即运行;相反,返回值是一个可迭代的迭代器对象。每次调用迭代器的
next()方法时,生成器函数的另一个块会运行。 -
生成器函数可以使用
yield运算符指定迭代器返回的值。每次调用next()都会导致生成器函数运行到下一个yield表达式。该yield表达式的值然后成为迭代器返回的值。当没有更多的yield表达式时,生成器函数返回,迭代完成。
第十三章:异步 JavaScript
一些计算机程序,如科学模拟和机器学习模型,是计算密集型的:它们持续运行,不间断,直到计算出结果为止。然而,大多数现实世界的计算机程序都是显著异步的。这意味着它们经常需要在等待数据到达或某个事件发生时停止计算。在 Web 浏览器中,JavaScript 程序通常是事件驱动的,这意味着它们等待用户点击或轻触才会实际执行任何操作。而基于 JavaScript 的服务器通常在等待客户端请求通过网络到达之前不会执行任何操作。
这种异步编程在 JavaScript 中很常见,本章记录了三个重要的语言特性,帮助简化处理异步代码。Promise 是 ES6 中引入的对象,表示尚未可用的异步操作的结果。关键字async和await是在 ES2017 中引入的,通过允许你将基于 Promise 的代码结构化为同步的形式,简化了异步编程的语法。最后,在 ES2018 中引入了异步迭代器和for/await循环,允许你使用看似同步的简单循环处理异步事件流。
具有讽刺意味的是,尽管 JavaScript 提供了这些强大的功能来处理异步代码,但核心语法本身没有异步特性。因此,为了演示 Promise、async、await和for/await,我们将首先进入客户端和服务器端 JavaScript,解释 Web 浏览器和 Node 的一些异步特性。(你可以在第十五章和第十六章了解更多关于客户端和服务器端 JavaScript 的内容。)
13.1 使用回调进行异步编程
在 JavaScript 中,异步编程的最基本层次是通过回调完成的。回调是你编写并传递给其他函数的函数。当满足某些条件或发生某些(异步)事件时,另一个函数会调用(“回调”)你的函数。你提供的回调函数的调用会通知你条件或事件,并有时,调用会包括提供额外细节的函数参数。通过一些具体的例子更容易理解,接下来的小节演示了使用客户端 JavaScript 和 Node 进行基于回调的异步编程的各种形式。
13.1.1 定时器
最简单的异步之一是当你想在一定时间后运行一些代码时。正如我们在§11.10 中看到的,你可以使用setTimeout()函数来实现:
setTimeout(checkForUpdates, 60000);
setTimeout()的第一个参数是一个函数,第二个是以毫秒为单位的时间间隔。在上述代码中,一个假设的checkForUpdates()函数将在setTimeout()调用后的 60,000 毫秒(1 分钟)后被调用。checkForUpdates()是你的程序可能定义的回调函数,setTimeout()是你调用以注册回调函数并指定在何种异步条件下调用它的函数。
setTimeout()调用指定的回调函数一次,不传递任何参数,然后忘记它。如果你正在编写一个真正检查更新的函数,你可能希望它重复运行。你可以使用setInterval()而不是setTimeout()来实现这一点:
// Call checkForUpdates in one minute and then again every minute after that
let updateIntervalId = setInterval(checkForUpdates, 60000);
// setInterval() returns a value that we can use to stop the repeated
// invocations by calling clearInterval(). (Similarly, setTimeout()
// returns a value that you can pass to clearTimeout())
function stopCheckingForUpdates() {
clearInterval(updateIntervalId);
}
13.1.2 事件
客户端 JavaScript 程序几乎普遍是事件驱动的:而不是运行某种预定的计算,它们通常等待用户执行某些操作,然后响应用户的动作。当用户在键盘上按键、移动鼠标、点击鼠标按钮或触摸触摸屏设备时,Web 浏览器会生成一个事件。事件驱动的 JavaScript 程序在指定的上下文中为指定类型的事件注册回调函数,当指定的事件发生时,Web 浏览器会调用这些函数。这些回调函数称为事件处理程序或事件监听器,并使用addEventListener()进行注册:
// Ask the web browser to return an object representing the HTML
// <button> element that matches this CSS selector
let okay = document.querySelector('#confirmUpdateDialog button.okay');
// Now register a callback function to be invoked when the user
// clicks on that button.
okay.addEventListener('click', applyUpdate);
在这个例子中,applyUpdate()是一个我们假设在其他地方实现的虚构回调函数。调用document.querySelector()返回一个表示 Web 页面中单个指定元素的对象。我们在该元素上调用addEventListener()来注册我们的回调。然后addEventListener()的第一个参数是一个字符串,指定我们感兴趣的事件类型——在这种情况下是鼠标点击或触摸屏点击。如果用户点击或触摸 Web 页面的特定元素,那么浏览器将调用我们的applyUpdate()回调函数,传递一个包含有关事件的详细信息(如时间和鼠标指针坐标)的对象。
13.1.3 网络事件
JavaScript 编程中另一个常见的异步来源是网络请求。在浏览器中运行的 JavaScript 可以使用以下代码从 Web 服务器获取数据:
function getCurrentVersionNumber(versionCallback) { // Note callback argument
// Make a scripted HTTP request to a backend version API
let request = new XMLHttpRequest();
request.open("GET", "http://www.example.com/api/version");
request.send();
// Register a callback that will be invoked when the response arrives
request.onload = function() {
if (request.status === 200) {
// If HTTP status is good, get version number and call callback.
let currentVersion = parseFloat(request.responseText);
versionCallback(null, currentVersion);
} else {
// Otherwise report an error to the callback
versionCallback(response.statusText, null);
}
};
// Register another callback that will be invoked for network errors
request.onerror = request.ontimeout = function(e) {
versionCallback(e.type, null);
};
}
客户端 JavaScript 代码可以使用 XMLHttpRequest 类加上回调函数来进行 HTTP 请求,并在服务器响应到达时异步处理。¹ 这里定义的getCurrentVersionNumber()函数(我们可以想象它被假设的checkForUpdates()函数使用,我们在§13.1.1 中讨论过)发出 HTTP 请求,并定义在接收到服务器响应或超时或其他错误导致请求失败时将被调用的事件处理程序。
请注意,上面的代码示例不像我们之前的示例那样调用addEventListener()。对于大多数 Web API(包括此示例),可以通过在生成事件的对象上调用addEventListener()并传递感兴趣的事件名称以及回调函数来定义事件处理程序。通常,您也可以通过将其直接分配给对象的属性来注册单个事件监听器。这就是我们在这个示例代码中所做的,将函数分配给onload、onerror和ontimeout属性。按照惯例,像这样的事件监听器属性总是以on开头的名称。addEventListener()是更灵活的技术,因为它允许注册多个事件处理程序。但在确保没有其他代码需要为相同的对象和事件类型注册监听器的情况下,直接将适当的属性设置为您的回调可能更简单。
在这个示例代码中关于getCurrentVersionNumber()函数的另一点需要注意的是,由于它发出了一个异步请求,它无法同步返回调用者感兴趣的值(当前版本号)。相反,调用者传递一个回调函数,当结果准备就绪或发生错误时调用。在这种情况下,调用者提供了一个期望两个参数的回调函数。如果 XMLHttpRequest 正常工作,那么getCurrentVersionNumber()会用null作为第一个参数,版本号作为第二个参数调用回调。或者,如果发生错误,那么getCurrentVersionNumber()会用错误详细信息作为第一个参数,null作为第二个参数调用回调。
13.1.4 Node 中的回调和事件
Node.js 服务器端 JavaScript 环境是深度异步的,并定义了许多使用回调和事件的 API。例如,读取文件内容的默认 API 是异步的,并在文件内容被读取后调用回调函数:
const fs = require("fs"); // The "fs" module has filesystem-related APIs
let options = { // An object to hold options for our program
// default options would go here
};
// Read a configuration file, then call the callback function
fs.readFile("config.json", "utf-8", (err, text) => {
if (err) {
// If there was an error, display a warning, but continue
console.warn("Could not read config file:", err);
} else {
// Otherwise, parse the file contents and assign to the options object
Object.assign(options, JSON.parse(text));
}
// In either case, we can now start running the program
startProgram(options);
});
Node 的fs.readFile()函数将一个两参数回调作为其最后一个参数。它异步读取指定的文件,然后调用回调。如果文件成功读取,它将文件内容作为第二个回调参数传递。如果出现错误,它将错误作为第一个回调参数传递。在这个例子中,我们将回调表达为箭头函数,这是一种简洁和自然的语法,适用于这种简单操作。
Node 还定义了许多基于事件的 API。以下函数展示了如何在 Node 中请求 URL 的内容。它有两层通过事件监听器处理的异步代码。请注意,Node 使用on()方法来注册事件监听器,而不是addEventListener():
const https = require("https");
// Read the text content of the URL and asynchronously pass it to the callback.
function getText(url, callback) {
// Start an HTTP GET request for the URL
request = https.get(url);
// Register a function to handle the "response" event.
request.on("response", response => {
// The response event means that response headers have been received
let httpStatus = response.statusCode;
// The body of the HTTP response has not been received yet.
// So we register more event handlers to to be called when it arrives.
response.setEncoding("utf-8"); // We're expecting Unicode text
let body = ""; // which we will accumulate here.
// This event handler is called when a chunk of the body is ready
response.on("data", chunk => { body += chunk; });
// This event handler is called when the response is complete
response.on("end", () => {
if (httpStatus === 200) { // If the HTTP response was good
callback(null, body); // Pass response body to the callback
} else { // Otherwise pass an error
callback(httpStatus, null);
}
});
});
// We also register an event handler for lower-level network errors
request.on("error", (err) => {
callback(err, null);
});
}
13.2 承诺
现在我们已经在客户端和服务器端 JavaScript 环境中看到了回调和基于事件的异步编程的示例,我们可以介绍承诺,这是一个旨在简化异步编程的核心语言特性。
承诺是表示异步计算结果的对象。该结果可能已经准备好,也可能尚未准备好,承诺 API 故意对此保持模糊:没有同步获取承诺值的方法;您只能要求承诺在值准备好时调用回调函数。如果您正在定义一个类似前一节中的getText()函数的异步 API,但希望将其基于承诺,省略回调参数,而是返回一个承诺对象。调用者可以在这个承诺对象上注册一个或多个回调,当异步计算完成时,它们将被调用。
因此,在最简单的层面上,承诺只是一种与回调一起工作的不同方式。然而,使用它们有实际的好处。基于回调的异步编程的一个真正问题是,通常会出现回调内嵌在回调内嵌在回调中的情况,代码行缩进如此之深,以至于难以阅读。承诺允许将这种嵌套回调重新表达为更线性的承诺链,这样更容易阅读和推理。
回调函数的另一个问题是,它们可能会使处理错误变得困难。如果异步函数(或异步调用的回调)抛出异常,那么这个异常就无法传播回异步操作的发起者。这是关于异步编程的一个基本事实:它破坏了异常处理。另一种方法是通过回调参数和返回值来细致地跟踪和传播错误,但这样做很繁琐,很难做到正确。承诺在这里有所帮助,通过标准化处理错误的方式,并提供一种让错误正确传播通过一系列承诺的方法。
请注意,承诺代表单个异步计算的未来结果。然而,它们不能用于表示重复的异步计算。在本章的后面,我们将编写一个基于承诺的setTimeout()函数的替代方案。但我们不能使用承诺来替代setInterval(),因为该函数会重复调用回调函数,而这是承诺设计上不支持的。同样地,我们可以使用承诺来替代 XMLHttpRequest 对象的“load”事件处理程序,因为该回调只会被调用一次。但通常情况下,我们不会使用承诺来替代 HTML 按钮对象的“click”事件处理程序,因为我们通常希望允许用户多次点击按钮。
接下来的小节将:
-
解释承诺术语并展示基本承诺用法
-
展示 Promises 如何被链式调用
-
展示如何创建自己的基于 Promise 的 API
重要
起初,Promise 似乎很简单,事实上,Promise 的基本用例确实简单明了。但是,对于超出最简单用例的任何情况,它们可能变得令人惊讶地令人困惑。Promise 是异步编程的强大习语,但你需要深入理解才能正确自信地使用它们。然而,花时间深入了解是值得的,我敦促你仔细研究这一长章节。
13.2.1 使用 Promises
随着 Promises 在核心 JavaScript 语言中的出现,Web 浏览器已经开始实现基于 Promise 的 API。在前一节中,我们实现了一个getText()函数,该函数发起了一个异步的 HTTP 请求,并将 HTTP 响应的主体作为字符串传递给指定的回调函数。想象一个这个函数的变体,getJSON(),它将 HTTP 响应的主体解析为 JSON,并返回一个 Promise,而不是接受一个回调参数。我们将在本章后面实现一个getJSON()函数,但现在,让我们看看如何使用这个返回 Promise 的实用函数:
getJSON(url).then(jsonData => {
// This is a callback function that will be asynchronously
// invoked with the parsed JSON value when it becomes available.
});
getJSON()启动一个异步的 HTTP 请求,请求指定的 URL,然后,在该请求挂起期间,它返回一个 Promise 对象。Promise 对象定义了一个then()实例方法。我们不直接将回调函数传递给getJSON(),而是将其传递给then()方法。当 HTTP 响应到达时,该响应的主体被解析为 JSON,并将解析后的值传递给我们传递给then()的函数。
你可以将then()方法看作是一个回调注册方法,类似于用于在客户端 JavaScript 中注册事件处理程序的addEventListener()方法。如果多次调用 Promise 对象的then()方法,每个指定的函数都将在承诺的计算完成时被调用。
与许多事件侦听器不同,Promise 代表一个单一的计算,每个注册到then()的函数只会被调用一次。值得注意的是,无论何时调用then(),你传递给then()的函数都会异步调用,即使异步计算在调用then()时已经完成。
在简单的语法层面上,then()方法是 Promise 的独特特征,习惯上直接将.then()附加到返回 Promise 的函数调用上,而不是将 Promise 对象分配给变量的中间步骤。
习惯上,将返回 Promises 的函数和使用 Promises 结果的函数命名为动词,这些习惯导致的代码特别易于阅读:
// Suppose you have a function like this to display a user profile
function displayUserProfile(profile) { /* implementation omitted */ }
// Here's how you might use that function with a Promise.
// Notice how this line of code reads almost like an English sentence:
getJSON("/api/user/profile").then(displayUserProfile);
使用 Promises 处理错误
异步操作,特别是涉及网络的操作,通常会以多种方式失败,必须编写健壮的代码来处理不可避免发生的错误。
对于 Promises,我们可以通过将第二个函数传递给then()方法来实现:
getJSON("/api/user/profile").then(displayUserProfile, handleProfileError);
Promise 代表在 Promise 对象创建后发生的异步计算的未来结果。因为计算是在 Promise 对象返回给我们后执行的,所以传统上计算无法返回一个值或抛出我们可以捕获的异常。我们传递给then()的函数提供了替代方案。当同步计算正常完成时,它只是将其结果返回给调用者。当基于 Promise 的异步计算正常完成时,它将其结果传递给作为then()的第一个参数的函数。
当同步计算出现问题时,它会抛出一个异常,该异常会向上传播到调用堆栈,直到有一个catch子句来处理它。当异步计算运行时,其调用者不再在堆栈上,因此如果出现问题,就不可能将异常抛回给调用者。
相反,基于 Promise 的异步计算将异常(通常作为某种类型的 Error 对象,尽管这不是必需的)传递给then()的第二个函数。因此,在上面的代码中,如果getJSON()正常运行,它会将结果传递给displayUserProfile()。如果出现错误(用户未登录、服务器宕机、用户的互联网连接中断、请求超时等),那么getJSON()会将一个 Error 对象传递给handleProfileError()。
在实践中,很少看到两个函数传递给then()。在处理 Promise 时,有一种更好的、更符合习惯的处理错误的方式。要理解这一点,首先考虑一下如果getJSON()正常完成,但displayUserProfile()中出现错误会发生什么。当getJSON()返回时,回调函数会异步调用,因此它也是异步的,不能有意义地抛出异常(因为没有代码在调用堆栈上处理它)。
在这段代码中处理错误的更符合习惯的方式如下:
getJSON("/api/user/profile").then(displayUserProfile).catch(handleProfileError);
使用这段代码,getJSON()的正常结果仍然会传递给displayUserProfile(),但是getJSON()或displayUserProfile()中的任何错误(包括displayUserProfile抛出的任何异常)都会传递给handleProfileError()。catch()方法只是调用then()的一种简写形式,第一个参数为null,第二个参数为指定的错误处理函数。
当我们讨论下一节的 Promise 链时,我们将会更多地谈到catch()和这种错误处理习惯。
13.2.2 链式 Promise
Promise 最重要的好处之一是它们提供了一种自然的方式来将一系列异步操作表达为then()方法调用的线性链,而无需将每个操作嵌套在前一个操作的回调中。例如,这里是一个假设的 Promise 链:
fetch(documentURL) // Make an HTTP request
.then(response => response.json()) // Ask for the JSON body of the response
.then(document => { // When we get the parsed JSON
return render(document); // display the document to the user
})
.then(rendered => { // When we get the rendered document
cacheInDatabase(rendered); // cache it in the local database.
})
.catch(error => handle(error)); // Handle any errors that occur
这段代码说明了一系列 Promise 如何简单地表达一系列异步操作的过程。然而,我们不会讨论这个特定的 Promise 链。不过,我们将继续探讨使用 Promise 链进行 HTTP 请求的想法。
在本章的前面,我们看到了在 JavaScript 中使用 XMLHttpRequest 对象进行 HTTP 请求。这个奇怪命名的对象具有一个古老且笨拙的 API,它已经大部分被新的、基于 Promise 的 Fetch API(§15.11.1)所取代。在其最简单的形式中,这个新的 HTTP API 就是函数fetch()。你传递一个 URL 给它,它会返回一个 Promise。当 HTTP 响应开始到达并且 HTTP 状态和头部可用时,这个 Promise 就会被实现:
fetch("/api/user/profile").then(response => {
// When the promise resolves, we have status and headers
if (response.ok &&
response.headers.get("Content-Type") === "application/json") {
// What can we do here? We don't actually have the response body yet.
}
});
当fetch()返回的 Promise 被实现时,它会将一个 Response 对象传递给您传递给其then()方法的函数。这个响应对象让您可以访问请求状态和头部,并且还定义了像text()和json()这样的方法,分别以文本和 JSON 解析形式访问响应主体。但是尽管初始 Promise 被实现,响应主体可能尚未到达。因此,用于访问响应主体的这些text()和json()方法本身返回 Promise。以下是使用fetch()和response.json()方法获取 HTTP 响应主体的一种天真的方法:
fetch("/api/user/profile").then(response => {
response.json().then(profile => { // Ask for the JSON-parsed body
// When the body of the response arrives, it will be automatically
// parsed as JSON and passed to this function.
displayUserProfile(profile);
});
});
这是一种天真地使用 Promise 的方式,因为我们像回调一样嵌套它们,这违背了初衷。更好的习惯是使用 Promise 在一个顺序链中编写代码,就像这样:
fetch("/api/user/profile")
.then(response => {
return response.json();
})
.then(profile => {
displayUserProfile(profile);
});
让我们看一下这段代码中的方法调用,忽略传递给方法的参数:
fetch().then().then()
当在一个表达式中调用多个方法时,我们称之为方法链。我们知道fetch()函数返回一个 Promise 对象,我们可以看到这个链中的第一个.then()调用在返回的 Promise 对象上调用一个方法。但是链中还有第二个.then(),这意味着then()方法的第一次调用本身必须返回一个 Promise。
有时,当设计 API 以使用这种方法链时,只有一个对象,并且该对象的每个方法都返回对象本身以便于链接。然而,这并不是 Promise 的工作方式。当我们编写一系列.then()调用时,我们并不是在单个 Promise 对象上注册多个回调。相反,then()方法的每次调用都会返回一个新的 Promise 对象。直到传递给then()的函数完成,新的 Promise 对象才会被实现。
让我们回到上面原始fetch()链的简化形式。如果我们在其他地方定义传递给then()调用的函数,我们可以重构代码如下:
fetch(theURL) // task 1; returns promise 1
.then(callback1) // task 2; returns promise 2
.then(callback2); // task 3; returns promise 3
让我们详细讨论一下这段代码:
-
在第一行,使用一个 URL 调用
fetch()。它为该 URL 发起一个 HTTP GET 请求并返回一个 Promise。我们将这个 HTTP 请求称为“任务 1”,将 Promise 称为“promise 1”。 -
在第二行,我们调用 promise 1 的
then()方法,传递我们希望在 promise 1 实现时调用的callback1函数。then()方法将我们的回调存储在某个地方,然后返回一个新的 Promise。我们将在这一步返回的新 Promise 称为“promise 2”,并且我们将说“任务 2”在调用callback1时开始。 -
在第三行,我们调用 promise 2 的
then()方法,传递我们希望在 promise 2 实现时调用的callback2函数。这个then()方法记住我们的回调并返回另一个 Promise。我们将说“任务 3”在调用callback2时开始。我们可以称这个最新的 Promise 为“promise 3”,但实际上我们不需要为它命名,因为我们根本不会使用它。 -
前三个步骤都是在表达式首次执行时同步发生的。现在,在 HTTP 请求在步骤 1 中发出并通过互联网发送时,我们有一个异步暂停。
-
最终,HTTP 响应开始到达。
fetch()调用的异步部分将 HTTP 状态和标头包装在一个 Response 对象中,并使用该 Response 对象作为值来实现 promise 1。 -
当 promise 1 被实现时,它的值(Response 对象)被传递给我们的
callback1()函数,任务 2 开始。这个任务的工作是,给定一个 Response 对象作为输入,获取响应主体作为 JSON 对象。 -
让我们假设任务 2 正常完成,并且能够解析 HTTP 响应的主体以生成一个 JSON 对象。这个 JSON 对象用于实现 promise 2。
-
实现 promise 2 的值成为传递给
callback2()函数时任务 3 的输入。当任务 3 完成(假设它正常完成)时,promise 3 将被实现。但因为我们从未对 promise 3 做任何操作,当该 Promise 完成时什么也不会发生,异步计算链在这一点结束。
13.2.3 解决 Promise
在上一节中解释了与列表中的 URL 获取 Promise 链相关的内容时,我们谈到了 promise 1、2 和 3。但实际上还涉及第四个 Promise 对象,这将引出我们对 Promise“解决”意味着什么的重要讨论。
请记住,fetch()返回一个 Promise 对象,当实现时,将传递一个 Response 对象给我们注册的回调函数。这个 Response 对象有.text()、.json()和其他方法以各种形式请求 HTTP 响应的主体。但是由于主体可能尚未到达,这些方法必须返回 Promise 对象。在我们一直在研究的示例中,“任务 2”调用.json()方法并返回其值。这是第四个 Promise 对象,也是callback1()函数的返回值。
让我们再次以冗长和非成语化的方式重写 URL 获取代码,使回调和 Promises 明确:
function c1(response) { // callback 1
let p4 = response.json();
return p4; // returns promise 4
}
function c2(profile) { // callback 2
displayUserProfile(profile);
}
let p1 = fetch("/api/user/profile"); // promise 1, task 1
let p2 = p1.then(c1); // promise 2, task 2
let p3 = p2.then(c2); // promise 3, task 3
为了使 Promise 链有用地工作,任务 2 的输出必须成为任务 3 的输入。在我们正在考虑的示例中,任务 3 的输入是获取的 URL 主体,解析为 JSON 对象。但是,正如我们刚才讨论的,回调c1的返回值不是 JSON 对象,而是该 JSON 对象的 Promisep4。这似乎是一个矛盾,但实际上不是:当p1被实现时,c1被调用,任务 2 开始。当p2被实现时,c2被调用,任务 3 开始。但是仅仅因为在调用c1时任务 2 开始,并不意味着任务 2 在c1返回时必须结束。毕竟,Promises 是关于管理异步任务的,如果任务 2 是异步的(在这种情况下是),那么在回调返回时该任务将尚未完成。
现在我们准备讨论您需要真正掌握 Promises 的最后一个细节。当您将回调c传递给then()方法时,then()返回一个 Promisep并安排在稍后的某个时间异步调用c。回调执行一些计算并返回一个值v。当回调返回时,p被解析为值v。当一个 Promise 被解析为一个不是 Promise 的值时,它会立即被实现为该值。因此,如果c返回一个非 Promise,那么返回值就成为p的值,p被实现,我们完成了。但是如果返回值v本身是一个 Promise,那么p被解析但尚未实现。在这个阶段,p不能解决,直到 Promisev解决。如果v被实现,那么p将被实现为相同的值。如果v被拒绝,那么p将因同样的原因被拒绝。这就是 Promise“解析”状态的含义:Promise 已经与另一个 Promise 关联或“锁定”。我们还不知道p是否会被实现或被拒绝,但是我们的回调c不再控制这一点。p“解析”意味着它的命运现在完全取决于 Promisev的发生。
让我们回到我们的 URL 获取示例。当c1返回p4时,p2被解析。但被解析并不意味着被实现,所以任务 3 还没有开始。当完整的 HTTP 响应主体可用时,.json()方法可以解析它并使用解析后的值来实现p4。当p4被实现时,p2也会自动被实现,具有相同的解析 JSON 值。此时,解析后的 JSON 对象被传递给c2,任务 3 开始。
这可能是 JavaScript 中最难理解的部分之一,您可能需要阅读本节不止一次。图 13-1 以可视化形式呈现了这个过程,可能有助于为您澄清。
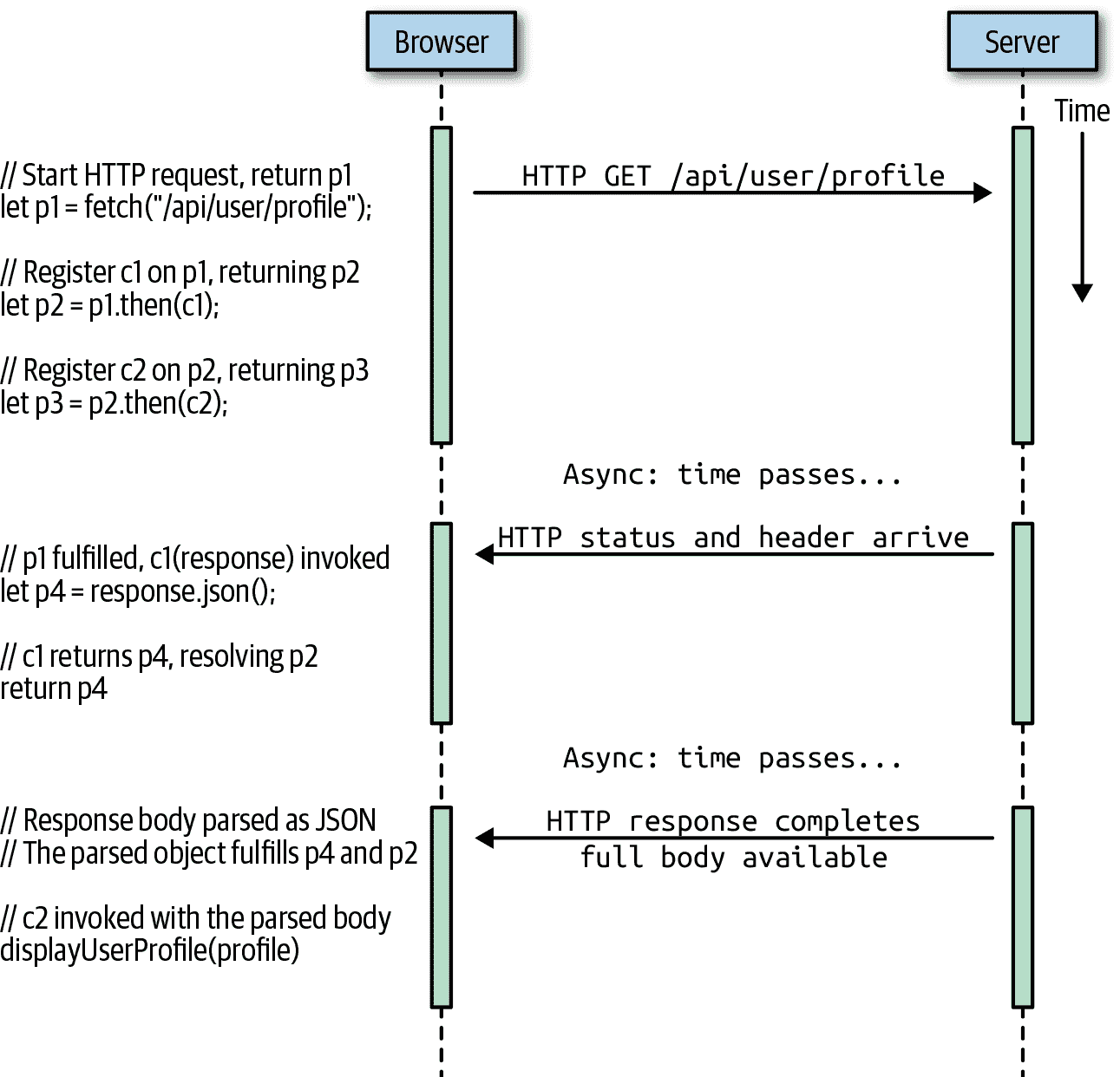
图 13-1. 使用 Promises 获取 URL
13.2.4 更多关于 Promises 和错误
在本章的前面,我们看到您可以将第二个回调函数传递给.then()方法,并且如果 Promise 被拒绝,则将调用此第二个函数。当发生这种情况时,传递给此第二个回调函数的参数是一个值—通常是代表拒绝原因的 Error 对象。我们还了解到,通过向 Promise 链中添加.catch()方法调用来处理 Promise 相关的错误是不常见的(甚至是不成文的)。现在我们已经检查了 Promise 链,我们可以回到错误处理并更详细地讨论它。在讨论之前,我想强调的是,在进行异步编程时,仔细处理错误非常重要。对于同步代码,如果您省略了错误处理代码,您至少会得到一个异常和堆栈跟踪,以便您可以找出出了什么问题。对于异步代码,未处理的异常通常不会被报告,错误可能会悄无声息地发生,使得调试变得更加困难。好消息是,.catch()方法使得在处理 Promise 时处理错误变得容易。
catch 和 finally 方法
Promise 的.catch()方法只是一种使用null作为第一个参数并将错误处理回调作为第二个参数调用.then()的简写方式。给定任何 Promisep和回调c,以下两行是等效的:
p.then(null, c);
p.catch(c);
.catch()简写更受欢迎,因为它更简单,并且名称与try/catch异常处理语句中的catch子句匹配。正如我们讨论过的,普通异常在异步代码中不起作用。Promise 的.catch()方法是一种适用于异步代码的替代方法。当同步代码出现问题时,我们可以说异常“沿着调用堆栈上升”直到找到catch块。对于 Promise 链的异步链,类似的隐喻可能是错误“沿着链路下滑”,直到找到.catch()调用。
在 ES2018 中,Promise 对象还定义了一个.finally()方法,其目的类似于try/catch/finally语句中的finally子句。如果您在 Promise 链中添加一个.finally()调用,那么您传递给.finally()的回调将在您调用它的 Promise 完成时被调用。如果 Promise 完成或拒绝,都会调用您的回调,并且不会传递任何参数,因此您无法找出它是完成还是拒绝。但是,如果您需要在任一情况下运行某种清理代码(例如关闭打开的文件或网络连接),则.finally()回调是执行此操作的理想方式。与.then()和.catch()一样,.finally()返回一个新的 Promise 对象。.finally()回调的返回值通常被忽略,而由.finally()返回的 Promise 通常将使用与调用.finally()的 Promise 解析或拒绝的相同值解析或拒绝。但是,如果.finally()回调引发异常,则由.finally()返回的 Promise 将以该值拒绝。
我们在前几节中学习的 URL 获取代码没有进行任何错误处理。现在让我们通过代码的更实际版本来纠正这一点:
fetch("/api/user/profile") // Start the HTTP request
.then(response => { // Call this when status and headers are ready
if (!response.ok) { // If we got a 404 Not Found or similar error
return null; // Maybe user is logged out; return null profile
}
// Now check the headers to ensure that the server sent us JSON.
// If not, our server is broken, and this is a serious error!
let type = response.headers.get("content-type");
if (type !== "application/json") {
throw new TypeError(`Expected JSON, got ${type}`);
}
// If we get here, then we got a 2xx status and a JSON content-type
// so we can confidently return a Promise for the response
// body as a JSON object.
return response.json();
})
.then(profile => { // Called with the parsed response body or null
if (profile) {
displayUserProfile(profile);
}
else { // If we got a 404 error above and returned null we end up here
displayLoggedOutProfilePage();
}
})
.catch(e => {
if (e instanceof NetworkError) {
// fetch() can fail this way if the internet connection is down
displayErrorMessage("Check your internet connection.");
}
else if (e instanceof TypeError) {
// This happens if we throw TypeError above
displayErrorMessage("Something is wrong with our server!");
}
else {
// This must be some kind of unanticipated error
console.error(e);
}
});
让我们通过分析当事情出错时会发生什么来分析这段代码。我们将使用之前使用的命名方案:p1是fetch()调用返回的 Promise。p2是第一个.then()调用返回的 Promise,c1是我们传递给该.then()调用的回调。p3是第二个.then()调用返回的 Promise,c2是我们传递给该调用的回调。最后,c3是我们传递给.catch()调用的回调。(该调用返回一个 Promise,但我们不需要通过名称引用它。)
可能失败的第一件事是 fetch() 请求本身。如果网络连接断开(或由于某种原因无法进行 HTTP 请求),那么 Promise p1 将被拒绝,并带有一个 NetworkError 对象。我们没有将错误处理回调函数作为第二个参数传递给 .then() 调用,因此 p2 也将以相同的 NetworkError 对象被拒绝。(如果我们向第一个 .then() 调用传递了错误处理程序,错误处理程序将被调用,如果它正常返回,p2 将被解析和/或完成,并带有该处理程序的返回值。)然而,没有处理程序,p2 被拒绝,然后 p3 由于相同原因被拒绝。此时,c3 错误处理回调被调用,并其中的 NetworkError 特定代码运行。
我们的代码可能失败的另一种方式是,如果我们的 HTTP 请求返回 404 Not Found 或其他 HTTP 错误。这些是有效的 HTTP 响应,因此 fetch() 调用不认为它们是错误。fetch() 将 404 Not Found 封装在一个 Response 对象中,并用该对象完成 p1,导致调用 c1。我们在 c1 中的代码检查 Response 对象的 ok 属性,以检测是否收到了正常的 HTTP 响应,并通过简单返回 null 处理这种情况。因为这个返回值不是一个 Promise,它立即完成 p2,并用这个值调用 c2。我们在 c2 中明确检查和处理 falsy 值,通过向用户显示不同的结果来处理这种情况。这是一个我们将异常条件视为非错误并在不使用错误处理程序的情况下处理它的案例。
如果我们得到一个正常的 HTTP 响应代码,但 Content-Type 头部未正确设置,c1 中会发生一个更严重的错误。我们的代码期望一个 JSON 格式的响应,所以如果服务器发送给我们 HTML、XML 或纯文本,我们将会遇到问题。c1 包含了检查 Content-Type 头部的代码。如果头部错误,它将把这视为一个不可恢复的问题并抛出一个 TypeError。当传递给 .then()(或 .catch())的回调抛出一个值时,作为 .then() 调用的返回值的 Promise 将被拒绝,并带有该抛出的值。在这种情况下,引发 TypeError 的 c1 中的代码导致 p2 被拒绝,并带有该 TypeError 对象。由于我们没有为 p2 指定错误处理程序,p3 也将被拒绝。c2 将不会被调用,并且 TypeError 将传递给 c3,它具有明确检查和处理这种类型错误的代码。
关于这段代码有几点值得注意。首先,请注意,使用常规的同步 throw 语句抛出的错误对象最终会在 Promise 链中的 .catch() 方法调用中异步处理。这应该清楚地说明为什么这种简写方法优先于向 .then() 传递第二个参数,并且为什么在 Promise 链末尾使用 .catch() 调用是如此习惯化的。
在我们离开错误处理的话题之前,我想指出,虽然习惯于在每个 Promise 链的末尾使用 .catch() 来清理(或至少记录)链中发生的任何错误,但在 Promise 链的其他地方使用 .catch() 也是完全有效的。如果你的 Promise 链中的某个阶段可能会因错误而失败,并且如果错误是某种可恢复的错误,不应该阻止链的其余部分运行,那么你可以在链中插入一个 .catch() 调用,代码可能看起来像这样:
startAsyncOperation()
.then(doStageTwo)
.catch(recoverFromStageTwoError)
.then(doStageThree)
.then(doStageFour)
.catch(logStageThreeAndFourErrors);
请记住,您传递给 .catch() 的回调只有在前一个阶段的回调抛出错误时才会被调用。如果回调正常返回,那么 .catch() 回调将被跳过,并且前一个回调的返回值将成为下一个 .then() 回调的输入。还要记住,.catch() 回调不仅用于报告错误,还用于处理和恢复错误。一旦错误传递给 .catch() 回调,它就会停止在 Promise 链中传播。.catch() 回调可以抛出新错误,但如果它正常返回,那么返回值将用于解析和/或实现相关的 Promise,并且错误将停止传播。
让我们具体说明一下:在前面的代码示例中,如果 startAsyncOperation() 或 doStageTwo() 抛出错误,则将调用 recoverFromStageTwoError() 函数。如果 recoverFromStageTwoError() 正常返回,则其返回值将传递给 doStageThree(),异步操作将继续正常进行。另一方面,如果 recoverFromStageTwoError() 无法恢复,则它将抛出错误(或重新抛出传递给它的错误)。在这种情况下,doStageThree() 和 doStageFour() 都不会被调用,并且由 recoverFromStageTwoError() 抛出的错误将传递给 logStageThreeAndFourErrors()。
有时,在复杂的网络环境中,错误可能更多或更少地随机发生,通过简单地重试异步请求来处理这些错误可能是合适的。想象一下,您已经编写了一个基于 Promise 的操作来查询数据库:
queryDatabase()
.then(displayTable)
.catch(displayDatabaseError);
现在假设瞬时网络负载问题导致失败率约为 1%。一个简单的解决方案可能是使用 .catch() 调用重试查询:
queryDatabase()
.catch(e => wait(500).then(queryDatabase)) // On failure, wait and retry
.then(displayTable)
.catch(displayDatabaseError);
如果假设的故障确实是随机的,那么添加这一行代码应该将您的错误率从 1% 降低到 0.01%。
13.2.5 并行的 Promises
我们花了很多时间讨论 Promise 链,用于顺序运行更大异步操作的异步步骤。但有时,我们希望并行执行多个异步操作。函数 Promise.all() 可以做到这一点。Promise.all() 接受一个 Promise 对象数组作为输入,并返回一个 Promise。如果任何输入 Promise 被拒绝,则返回的 Promise 将被拒绝。否则,它将以每个输入 Promise 的实现值数组实现。因此,例如,如果您想获取多个 URL 的文本内容,您可以使用以下代码:
// We start with an array of URLs
const urls = [ /* zero or more URLs here */ ];
// And convert it to an array of Promise objects
promises = urls.map(url => fetch(url).then(r => r.text()));
// Now get a Promise to run all those Promises in parallel
Promise.all(promises)
.then(bodies => { /* do something with the array of strings */ })
.catch(e => console.error(e));
Promise.all() 稍微比之前描述的更灵活。输入数组可以包含 Promise 对象和非 Promise 值。如果数组的元素不是 Promise,则会被视为已实现 Promise 的值,并且会被简单地复制到输出数组中。
Promise.all() 返回的 Promise 在任何输入 Promise 被拒绝时也会被拒绝。这会立即发生在第一个拒绝时,而其他输入 Promise 仍在等待的情况下也可能发生。在 ES2020 中,Promise.allSettled() 接受一个输入 Promise 数组并返回一个 Promise,就像 Promise.all() 一样。但是 Promise.allSettled() 永远不会拒绝返回的 Promise,并且在所有输入 Promise 都已完成之前不会实现该 Promise。该 Promise 解析为一个对象数组,每个输入 Promise 都有一个对象。每个返回的对象都有一个 status 属性,设置为“fulfilled”或“rejected”。如果状态是“fulfilled”,那么对象还将有一个 value 属性,给出实现值。如果状态是“rejected”,那么对象还将有一个 reason 属性,给出相应 Promise 的错误或拒绝值:
Promise.allSettled([Promise.resolve(1), Promise.reject(2), 3]).then(results => {
results[0] // => { status: "fulfilled", value: 1 }
results[1] // => { status: "rejected", reason: 2 }
results[2] // => { status: "fulfilled", value: 3 }
});
有时,您可能希望同时运行多个 Promise,但可能只关心第一个实现的值。在这种情况下,您可以使用Promise.race()而不是Promise.all()。它返回一个 Promise,当输入数组中的 Promise 中的第一个实现或拒绝时,该 Promise 将实现或拒绝。(或者,如果输入数组中有任何非 Promise 值,则简单地返回其中的第一个。)
13.2.6 创建 Promises
在许多先前的示例中,我们使用了返回 Promise 的函数fetch(),因为它是内置到 Web 浏览器中的最简单的返回 Promise 的函数之一。我们对 Promises 的讨论还依赖于假设的返回 Promise 的函数getJSON()和wait()。编写返回 Promises 的函数确实非常有用,本节展示了如何创建基于 Promise 的 API。特别是,我们将展示getJSON()和wait()的实现。
基于其他 Promises 的 Promises
如果您有其他返回 Promise 的函数作为起点,编写返回 Promise 的函数就很容易。给定一个 Promise,您可以通过调用.then()来创建(并返回)一个新的 Promise。因此,如果我们使用现有的fetch()函数作为起点,我们可以这样编写getJSON():
function getJSON(url) {
return fetch(url).then(response => response.json());
}
代码很简单,因为fetch()API 的 Response 对象具有预定义的json()方法。json()方法返回一个 Promise,我们从回调中返回该 Promise(回调是一个带有单表达式主体的箭头函数,因此返回是隐式的),因此getJSON()返回的 Promise 解析为response.json()返回的 Promise。当该 Promise 实现时,由getJSON()返回的 Promise 也实现为相同的值。请注意,此getJSON()实现中没有错误处理。我们不检查response.ok和 Content-Type 头,而是允许json()方法拒绝返回的 Promise,如果响应主体无法解析为 JSON,则会引发 SyntaxError。
让我们再写一个返回 Promise 的函数,这次使用getJSON()作为初始 Promise 的来源。
function getHighScore() {
return getJSON("/api/user/profile").then(profile => profile.highScore);
}
我们假设这个函数是某种基于 Web 的游戏的一部分,并且 URL“/api/user/profile”返回一个包含highScore属性的 JSON 格式数据结构。
基于同步值的 Promises
有时,您可能需要实现现有的基于 Promise 的 API,并从函数返回一个 Promise,即使要执行的计算实际上不需要任何异步操作。在这种情况下,静态方法Promise.resolve()和Promise.reject()将实现您想要的效果。Promise.resolve()以其单个参数作为值,并返回一个将立即(但异步地)实现为该值的 Promise。类似地,Promise.reject()接受一个参数,并返回一个将以该值为原因拒绝的 Promise。(要明确:这些静态方法返回的 Promises 在返回时并未已实现或已拒绝,但它们将在当前同步代码块运行完毕后立即实现或拒绝。通常,除非有许多待处理的异步任务等待运行,否则这将在几毫秒内发生。)
请回顾§13.2.3 中的内容,已解决的 Promise 与已实现的 Promise 不是同一回事。当我们调用Promise.resolve()时,通常会传递实现值以创建一个 Promise 对象,该对象将很快实现为该值。但是该方法的名称不是Promise.fulfill()。如果将 Promisep1传递给Promise.resolve(),它将返回一个新的 Promisep2,该 Promise 立即解决,但直到p1实现或拒绝之前,它才会实现或拒绝。
可以编写一个基于 Promise 的函数,其中值是同步计算的,并使用Promise.resolve()异步返回,尽管这种情况可能不太常见。然而,在异步函数中有同步特殊情况是相当常见的,你可以使用Promise.resolve()和Promise.reject()来处理这些特殊情况。特别是,如果在开始异步操作之前检测到错误条件(例如错误的参数值),你可以通过返回使用Promise.reject()创建的 Promise 来报告该错误。(在这种情况下,你也可以同步抛出错误,但这被认为是不好的做法,因为调用者需要同时编写同步的catch子句和使用异步的.catch()方法来处理错误。)最后,Promise.resolve()有时用于在 Promise 链中创建初始 Promise。我们将看到一些以这种方式使用它的示例。
从头开始的 Promises
对于getJSON()和getHighScore(),我们首先调用现有函数以获取初始 Promise,并通过调用该初始 Promise 的.then()方法创建并返回一个新 Promise。但是,当你无法使用另一个返回 Promise 的函数作为起点时,如何编写返回 Promise 的函数呢?在这种情况下,你可以使用Promise()构造函数创建一个全新的 Promise 对象,你可以完全控制它。操作如下:你调用Promise()构造函数并将一个函数作为其唯一参数传递。你传递的函数应该预期两个参数,按照惯例,应该命名为resolve和reject。构造函数会同步调用带有resolve和reject参数的函数。在调用你的函数后,Promise()构造函数会返回新创建的 Promise。返回的 Promise 受你传递给构造函数的函数控制。该函数应执行一些异步操作,然后调用resolve函数以解析或实现返回的 Promise,或调用reject函数以拒绝返回的 Promise。你的函数不必是异步的:如果这样做,即使你同步调用resolve或reject,Promise 仍将异步解析、实现或拒绝。
通过阅读关于将函数传递给构造函数的函数的功能可能很难理解,但希望一些示例能够澄清这一点。以下是如何编写基于 Promise 的wait()函数的方法,我们在本章的早期示例中使用过:
function wait(duration) {
// Create and return a new Promise
return new Promise((resolve, reject) => { // These control the Promise
// If the argument is invalid, reject the Promise
if (duration < 0) {
reject(new Error("Time travel not yet implemented"));
}
// Otherwise, wait asynchronously and then resolve the Promise.
// setTimeout will invoke resolve() with no arguments, which means
// that the Promise will fulfill with the undefined value.
setTimeout(resolve, duration);
});
}
请注意,用于控制使用Promise()构造函数创建的 Promise 的命运的一对函数的名称分别为resolve()和reject(),而不是fulfill()和reject()。如果将一个 Promise 传递给resolve(),则返回的 Promise 将解析为该新 Promise。然而,通常情况下,你会传递一个非 Promise 值,这将用该值实现返回的 Promise。
示例 13-1 是另一个使用Promise()构造函数的示例。这个示例实现了我们的getJSON()函数,用于在 Node 中使用,因为fetch()API 没有内置。请记住,我们在本章一开始讨论了异步回调和事件。这个示例同时使用了回调和事件处理程序,因此很好地演示了我们如何在其他类型的异步编程风格之上实现基于 Promise 的 API。
示例 13-1. 一个异步的 getJSON() 函数
const http = require("http");
function getJSON(url) {
// Create and return a new Promise
return new Promise((resolve, reject) => {
// Start an HTTP GET request for the specified URL
request = http.get(url, response => { // called when response starts
// Reject the Promise if the HTTP status is wrong
if (response.statusCode !== 200) {
reject(new Error(`HTTP status ${response.statusCode}`));
response.resume(); // so we don't leak memory
}
// And reject if the response headers are wrong
else if (response.headers["content-type"] !== "application/json") {
reject(new Error("Invalid content-type"));
response.resume(); // don't leak memory
}
else {
// Otherwise, register events to read the body of the response
let body = "";
response.setEncoding("utf-8");
response.on("data", chunk => { body += chunk; });
response.on("end", () => {
// When the response body is complete, try to parse it
try {
let parsed = JSON.parse(body);
// If it parsed successfully, fulfill the Promise
resolve(parsed);
} catch(e) {
// If parsing failed, reject the Promise
reject(e);
}
});
}
});
// We also reject the Promise if the request fails before we
// even get a response (such as when the network is down)
request.on("error", error => {
reject(error);
});
});
}
13.2.7 顺序执行的 Promises
Promise.all() 让并行运行任意数量的 Promises 变得容易。Promise 链使得表达一系列固定数量的 Promises 变得容易。然而,按顺序运行任意数量的 Promises 就比较棘手了。例如,假设你有一个要获取的 URL 数组,但为了避免过载网络,你希望一次只获取一个。如果数组长度和内容未知,你无法提前编写 Promise 链,因此需要动态构建一个,代码如下:
function fetchSequentially(urls) {
// We'll store the URL bodies here as we fetch them
const bodies = [];
// Here's a Promise-returning function that fetches one body
function fetchOne(url) {
return fetch(url)
.then(response => response.text())
.then(body => {
// We save the body to the array, and we're purposely
// omitting a return value here (returning undefined)
bodies.push(body);
});
}
// Start with a Promise that will fulfill right away (with value undefined)
let p = Promise.resolve(undefined);
// Now loop through the desired URLs, building a Promise chain
// of arbitrary length, fetching one URL at each stage of the chain
for(url of urls) {
p = p.then(() => fetchOne(url));
}
// When the last Promise in that chain is fulfilled, then the
// bodies array is ready. So let's return a Promise for that
// bodies array. Note that we don't include any error handlers:
// we want to allow errors to propagate to the caller.
return p.then(() => bodies);
}
有了定义的 fetchSequentially() 函数,我们可以一次获取一个 URL,代码与我们之前用来演示 Promise.all() 的并行获取代码类似:
fetchSequentially(urls)
.then(bodies => { /* do something with the array of strings */ })
.catch(e => console.error(e));
fetchSequentially() 函数首先创建一个 Promise,在返回后立即实现。然后,它基于该初始 Promise 构建一个长的线性 Promise 链,并返回链中的最后一个 Promise。这就像设置一排多米诺骨牌,然后推倒第一个。
我们可以采取另一种(可能更优雅)的方法。与其提前创建 Promises,我们可以让每个 Promise 的回调创建并返回下一个 Promise。也就是说,我们不是创建和链接一堆 Promises,而是创建解析为其他 Promises 的 Promises。我们不是创建一条多米诺般的 Promise 链,而是创建一个嵌套在另一个内部的 Promise 序列,就像一组套娃一样。采用这种方法,我们的代码可以返回第一个(最外层)Promise,知道它最终会实现(或拒绝!)与序列中最后一个(最内层)Promise 相同的值。接下来的 promiseSequence() 函数编写为通用的,不特定于 URL 获取。它在我们讨论 Promises 的最后,因为它很复杂。然而,如果你仔细阅读了本章,希望你能理解它是如何工作的。特别要注意的是,promiseSequence() 中的嵌套函数似乎递归调用自身,但因为“递归”调用是通过 then() 方法进行的,实际上并没有传统的递归发生:
// This function takes an array of input values and a "promiseMaker" function.
// For any input value x in the array, promiseMaker(x) should return a Promise
// that will fulfill to an output value. This function returns a Promise
// that fulfills to an array of the computed output values.
//
// Rather than creating the Promises all at once and letting them run in
// parallel, however, promiseSequence() only runs one Promise at a time
// and does not call promiseMaker() for a value until the previous Promise
// has fulfilled.
function promiseSequence(inputs, promiseMaker) {
// Make a private copy of the array that we can modify
inputs = [...inputs];
// Here's the function that we'll use as a Promise callback
// This is the pseudorecursive magic that makes this all work.
function handleNextInput(outputs) {
if (inputs.length === 0) {
// If there are no more inputs left, then return the array
// of outputs, finally fulfilling this Promise and all the
// previous resolved-but-not-fulfilled Promises.
return outputs;
} else {
// If there are still input values to process, then we'll
// return a Promise object, resolving the current Promise
// with the future value from a new Promise.
let nextInput = inputs.shift(); // Get the next input value,
return promiseMaker(nextInput) // compute the next output value,
// Then create a new outputs array with the new output value
.then(output => outputs.concat(output))
// Then "recurse", passing the new, longer, outputs array
.then(handleNextInput);
}
}
// Start with a Promise that fulfills to an empty array and use
// the function above as its callback.
return Promise.resolve([]).then(handleNextInput);
}
这个 promiseSequence() 函数是故意通用的。我们可以用它来获取 URL,代码如下:
// Given a URL, return a Promise that fulfills to the URL body text
function fetchBody(url) { return fetch(url).then(r => r.text()); }
// Use it to sequentially fetch a bunch of URL bodies
promiseSequence(urls, fetchBody)
.then(bodies => { /* do something with the array of strings */ })
.catch(console.error);
13.3 async 和 await
ES2017 引入了两个新关键字——async 和 await——代表了 JavaScript 异步编程的范式转变。这些新关键字极大地简化了 Promises 的使用,并允许我们编写基于 Promise 的异步代码,看起来像阻塞的同步代码,等待网络响应或其他异步事件。虽然理解 Promises 如何工作仍然很重要,但当与 async 和 await 一起使用时,它们的复杂性(有时甚至是它们的存在本身!)会消失。
正如我们在本章前面讨论的那样,异步代码无法像常规同步代码那样返回值或抛出异常。这就是 Promises 设计的原因。已实现的 Promise 的值就像同步函数的返回值一样。而拒绝的 Promise 的值就像同步函数抛出的值一样。后者的相似性通过 .catch() 方法的命名得到明确体现。async 和 await 采用高效的基于 Promise 的代码,并隐藏了 Promises,使得你的异步代码可以像低效、阻塞的同步代码一样易于阅读和推理。
13.3.1 await 表达式
await关键字接受一个 Promise 并将其转换为返回值或抛出异常。给定一个 Promise 对象p,表达式await p会等待直到p完成。如果p成功,那么await p的值就是p的成功值。另一方面,如果p被拒绝,那么await p表达式会抛出p的拒绝值。我们通常不会使用一个保存 Promise 的变量来使用await;相反,我们会在返回 Promise 的函数调用之前使用它:
let response = await fetch("/api/user/profile");
let profile = await response.json();
立即理解await关键字不会导致程序阻塞并直到指定的 Promise 完成。代码仍然是异步的,await只是掩饰了这一事实。这意味着任何使用await的代码本身都是异步的。
13.3.2 async 函数
因为任何使用await的代码都是异步的,有一个关键规则:只能在使用async关键字声明的函数内部使用await关键字。以下是本章前面提到的getHighScore()函数的一个使用async和await重写的版本:
async function getHighScore() {
let response = await fetch("/api/user/profile");
let profile = await response.json();
return profile.highScore;
}
声明一个函数为async意味着函数的返回值将是一个 Promise,即使函数体中没有任何与 Promise 相关的代码。如果一个async函数看起来正常返回,那么作为真正返回值的 Promise 对象将解析为该表面返回值。如果一个async函数看起来抛出异常,那么它返回的 Promise 对象将被拒绝并带有该异常。
getHighScore()函数被声明为async,因此它返回一个 Promise。由于它返回一个 Promise,我们可以使用await关键字:
displayHighScore(await getHighScore());
但请记住,那行代码只有在另一个async函数内部才能起作用!你可以无限嵌套await表达式在async函数内部。但如果你在顶层²或者由于某种原因在一个非async函数内部,那么你就不能使用await,而必须以常规方式处理返回的 Promise:
getHighScore().then(displayHighScore).catch(console.error);
你可以在任何类型的函数中使用async关键字。它可以与function关键字一起作为语句或表达式使用。它可以与箭头函数一起使用,也可以与类和对象字面量中的方法快捷形式一起使用。(有关编写函数的各种方式,请参见第八章。)
13.3.3 等待多个 Promises
假设我们使用async编写了我们的getJSON()函数:
async function getJSON(url) {
let response = await fetch(url);
let body = await response.json();
return body;
}
现在假设我们想要使用这个函数获取两个 JSON 值:
let value1 = await getJSON(url1);
let value2 = await getJSON(url2);
这段代码的问题在于它是不必要的顺序执行:第二个 URL 的获取将等到第一个 URL 的获取完成后才开始。如果第二个 URL 不依赖于从第一个 URL 获取的值,那么我们可能应该尝试同时获取这两个值。这是async函数的基于 Promise 的特性的一个案例。为了等待一组并发执行的async函数,我们使用Promise.all(),就像直接使用 Promises 一样:
let [value1, value2] = await Promise.all([getJSON(url1), getJSON(url2)]);
13.3.4 实现细节
最后,为了理解async函数的工作原理,可能有助于思考底层发生了什么。
假设你写了一个这样的async函数:
async function f(x) { /* body */ }
你可以将这看作是一个包装在原始函数体周围的返回 Promise 的函数:
function f(x) {
return new Promise(function(resolve, reject) {
try {
resolve((function(x) { /* body */ })(x));
}
catch(e) {
reject(e);
}
});
}
用这种方式来表达await关键字比较困难。但可以将await关键字看作是一个标记,将函数体分解为单独的同步块。ES2017 解释器可以将函数体分解为一系列单独的子函数,每个子函数都会传递给前面的await标记的 Promise 的then()方法。
13.4 异步迭代
我们从回调和基于事件的异步性讨论开始了本章,当我们介绍 Promise 时,我们注意到它们对于单次异步计算很有用,但不适用于重复异步事件的源,比如setInterval()、Web 浏览器中的“click”事件或 Node 流上的“data”事件。因为单个 Promise 不能用于序列的异步事件,所以我们也不能使用常规的async函数和await语句来处理这些事情。
然而,ES2018 提供了一个解决方案。异步迭代器类似于第十二章中描述的迭代器,但它们是基于 Promise 的,并且旨在与一种新形式的for/of循环一起使用:for/await。
13.4.1 for/await循环
Node 12 使其可读流异步可迭代。这意味着您可以使用像这样的for/await循环从流中读取连续的数据块:
const fs = require("fs");
async function parseFile(filename) {
let stream = fs.createReadStream(filename, { encoding: "utf-8"});
for await (let chunk of stream) {
parseChunk(chunk); // Assume parseChunk() is defined elsewhere
}
}
像常规的await表达式一样,for/await循环是基于 Promise 的。粗略地说,异步迭代器生成一个 Promise,for/await循环等待该 Promise 实现,将实现值分配给循环变量,并运行循环体。然后它重新开始,从迭代器获取另一个 Promise 并等待该新 Promise 实现。
假设您有一个 URL 数组:
const urls = [url1, url2, url3];
您可以对每个 URL 调用fetch()以获取 Promise 数组:
const promises = urls.map(url => fetch(url));
我们在本章的前面看到,现在我们可以使用Promise.all()等待数组中所有 Promise 被实现。但假设我们希望在第一个 fetch 的结果变为可用时获取结果,并且不想等待所有 URL 被获取。 (当然,第一个 fetch 可能比其他任何 fetch 都要花费更长的时间,因此这不一定比使用Promise.all()更快。)数组是可迭代的,因此我们可以使用常规的for/of循环遍历 Promise 数组:
for(const promise of promises) {
response = await promise;
handle(response);
}
这个示例代码使用了一个常规的for/of循环和一个常规的迭代器。但由于这个迭代器返回的是 Promise,我们也可以使用新的for/await来编写稍微更简单的代码:
for await (const response of promises) {
handle(response);
}
在这种情况下,for/await循环只是将await调用嵌入到循环中,使我们的代码稍微更加紧凑,但这两个例子实际上做的事情是完全一样的。重要的是,这两个例子只有在声明为async的函数内部才能工作;for/await循环在这方面与常规的await表达式没有区别。
然而,重要的是要意识到,在这个例子中我们使用for/await与一个常规迭代器。使用完全异步迭代器会更有趣。
13.4.2 异步迭代器
让我们回顾一下第十二章中的一些术语。可迭代对象是可以与for/of循环一起使用的对象。它定义了一个符号名称为Symbol.iterator的方法。该方法返回一个迭代器对象。迭代器对象具有一个next()方法,可以重复调用以获取可迭代对象的值。迭代器对象的next()方法返回迭代结果对象。迭代结果对象具有一个value属性和/或一个done属性。
异步迭代器与常规迭代器非常相似,但有两个重要的区别。首先,异步可迭代对象实现了一个符号名称为Symbol.asyncIterator的方法,而不是Symbol.iterator。 (正如我们之前看到的,for/await与常规可迭代对象兼容,但它更喜欢异步可迭代对象,并在尝试Symbol.iterator方法之前尝试Symbol.asyncIterator方法。)其次,异步迭代器的next()方法返回一个解析为迭代器结果对象的 Promise,而不是直接返回迭代器结果对象。
注意
在前一节中,当我们在常规的同步可迭代的 Promise 数组上使用for/await时,我们正在处理同步迭代器结果对象,其中value属性是一个 Promise 对象,但done属性是同步的。真正的异步迭代器会返回 Promise 以进行迭代结果对象,并且value和done属性都是异步的。区别是微妙的:使用异步迭代器时,关于何时结束迭代的选择可以异步进行。
13.4.3 异步生成器
正如我们在第十二章中看到的,实现迭代器的最简单方法通常是使用生成器。对于异步迭代器也是如此,我们可以使用声明为async的生成器函数来实现。异步生成器具有异步函数和生成器的特性:你可以像在常规异步函数中一样使用await,也可以像在常规生成器中一样使用yield。但你yield的值会自动包装在 Promise 中。甚至异步生成器的语法也是一个组合:async function和function *组合成async function *。下面是一个示例,展示了如何使用异步生成器和for/await循环以循环语法而不是setInterval()回调函数重复在固定间隔运行代码:
// A Promise-based wrapper around setTimeout() that we can use await with.
// Returns a Promise that fulfills in the specified number of milliseconds
function elapsedTime(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
// An async generator function that increments a counter and yields it
// a specified (or infinite) number of times at a specified interval.
async function* clock(interval, max=Infinity) {
for(let count = 1; count <= max; count++) { // regular for loop
await elapsedTime(interval); // wait for time to pass
yield count; // yield the counter
}
}
// A test function that uses the async generator with for/await
async function test() { // Async so we can use for/await
for await (let tick of clock(300, 100)) { // Loop 100 times every 300ms
console.log(tick);
}
}
13.4.4 实现异步迭代器
除了使用异步生成器来实现异步迭代器外,还可以通过定义一个具有返回一个返回解析为迭代器结果对象的 Promise 的next()方法的对象的Symbol.asyncIterator()方法来直接实现它们。在下面的代码中,我们重新实现了前面示例中的clock()函数,使其不是一个生成器,而是只返回一个异步可迭代对象。请注意,在这个示例中,next()方法并没有显式返回一个 Promise;相反,我们只是声明next()为 async:
function clock(interval, max=Infinity) {
// A Promise-ified version of setTimeout that we can use await with.
// Note that this takes an absolute time instead of an interval.
function until(time) {
return new Promise(resolve => setTimeout(resolve, time - Date.now()));
}
// Return an asynchronously iterable object
return {
startTime: Date.now(), // Remember when we started
count: 1, // Remember which iteration we're on
async next() { // The next() method makes this an iterator
if (this.count > max) { // Are we done?
return { done: true }; // Iteration result indicating done
}
// Figure out when the next iteration should begin,
let targetTime = this.startTime + this.count * interval;
// wait until that time,
await until(targetTime);
// and return the count value in an iteration result object.
return { value: this.count++ };
},
// This method means that this iterator object is also an iterable.
[Symbol.asyncIterator]() { return this; }
};
}
这个基于迭代器的clock()函数版本修复了基于生成器的版本中的一个缺陷。请注意,在这个更新的代码中,我们针对每次迭代应该开始的绝对时间,并从中减去当前时间以计算传递给setTimeout()的间隔。如果我们在for/await循环中使用clock(),这个版本将更精确地按照指定的间隔运行循环迭代,因为它考虑了实际运行循环体所需的时间。但这个修复不仅仅是关于时间精度。for/await循环总是在开始下一次迭代之前等待一个迭代返回的 Promise 被实现。但如果你在没有for/await循环的情况下使用异步迭代器,就没有任何阻止你在想要的任何时候调用next()方法。使用基于生成器的clock()版本,如果连续调用next()方法三次,你将得到三个几乎在同一时间实现的 Promise,这可能不是你想要的。我们在这里实现的基于迭代器的版本没有这个问题。
异步迭代器的好处在于它们允许我们表示异步事件或数据流。之前讨论的clock()函数相对简单,因为异步性的源是我们自己进行的setTimeout()调用。但是当我们尝试处理其他异步源时,比如触发事件处理程序,实现异步迭代器就变得相当困难——通常我们有一个响应事件的单个事件处理程序函数,但是迭代器的每次调用next()方法必须返回一个不同的 Promise 对象,并且在第一个 Promise 解析之前可能会多次调用next()。这意味着任何异步迭代器方法必须能够维护一个内部 Promise 队列,以便按顺序解析异步事件。如果我们将这种 Promise 队列行为封装到一个 AsyncQueue 类中,那么基于 AsyncQueue 编写异步迭代器就会变得更容易。³
接下来的 AsyncQueue 类具有enqueue()和dequeue()方法,就像你期望的队列类一样。然而,dequeue()方法返回一个 Promise 而不是实际值,这意味着在调用enqueue()之前调用dequeue()是可以的。AsyncQueue 类也是一个异步迭代器,并且旨在与一个for/await循环一起使用,其主体在每次异步排队新值时运行一次。 (AsyncQueue 有一个close()方法。一旦调用,就不能再排队更多的值。当一个关闭的队列为空时,for/await循环将停止循环。)
请注意,AsyncQueue 的实现不使用async或await,而是直接使用 Promises。这段代码有些复杂,你可以用它来测试你对我们在这一长章节中涵盖的内容的理解。即使你不完全理解 AsyncQueue 的实现,也请看一下后面的简短示例:它在 AsyncQueue 的基础上实现了一个简单但非常有趣的异步迭代器。
/**
* An asynchronously iterable queue class. Add values with enqueue()
* and remove them with dequeue(). dequeue() returns a Promise, which
* means that values can be dequeued before they are enqueued. The
* class implements [Symbol.asyncIterator] and next() so that it can
* be used with the for/await loop (which will not terminate until
* the close() method is called.)
*/
class AsyncQueue {
constructor() {
// Values that have been queued but not dequeued yet are stored here
this.values = [];
// When Promises are dequeued before their corresponding values are
// queued, the resolve methods for those Promises are stored here.
this.resolvers = [];
// Once closed, no more values can be enqueued, and no more unfulfilled
// Promises returned.
this.closed = false;
}
enqueue(value) {
if (this.closed) {
throw new Error("AsyncQueue closed");
}
if (this.resolvers.length > 0) {
// If this value has already been promised, resolve that Promise
const resolve = this.resolvers.shift();
resolve(value);
}
else {
// Otherwise, queue it up
this.values.push(value);
}
}
dequeue() {
if (this.values.length > 0) {
// If there is a queued value, return a resolved Promise for it
const value = this.values.shift();
return Promise.resolve(value);
}
else if (this.closed) {
// If no queued values and we're closed, return a resolved
// Promise for the "end-of-stream" marker
return Promise.resolve(AsyncQueue.EOS);
}
else {
// Otherwise, return an unresolved Promise,
// queuing the resolver function for later use
return new Promise((resolve) => { this.resolvers.push(resolve); });
}
}
close() {
// Once the queue is closed, no more values will be enqueued.
// So resolve any pending Promises with the end-of-stream marker
while(this.resolvers.length > 0) {
this.resolvers.shift()(AsyncQueue.EOS);
}
this.closed = true;
}
// Define the method that makes this class asynchronously iterable
[Symbol.asyncIterator]() { return this; }
// Define the method that makes this an asynchronous iterator. The
// dequeue() Promise resolves to a value or the EOS sentinel if we're
// closed. Here, we need to return a Promise that resolves to an
// iterator result object.
next() {
return this.dequeue().then(value => (value === AsyncQueue.EOS)
? { value: undefined, done: true }
: { value: value, done: false });
}
}
// A sentinel value returned by dequeue() to mark "end of stream" when closed
AsyncQueue.EOS = Symbol("end-of-stream");
因为这个 AsyncQueue 类定义了异步迭代的基础,我们可以通过异步排队值来创建自己的更有趣的异步迭代器。下面是一个示例,它使用 AsyncQueue 生成一个可以用for/await循环处理的 web 浏览器事件流:
// Push events of the specified type on the specified document element
// onto an AsyncQueue object, and return the queue for use as an event stream
function eventStream(elt, type) {
const q = new AsyncQueue(); // Create a queue
elt.addEventListener(type, e=>q.enqueue(e)); // Enqueue events
return q;
}
async function handleKeys() {
// Get a stream of keypress events and loop once for each one
for await (const event of eventStream(document, "keypress")) {
console.log(event.key);
}
}
13.5 总结
在本章中,你已经学到了:
-
大多数真实世界的 JavaScript 编程是异步的。
-
传统上,异步性是通过事件和回调函数来处理的。然而,这可能会变得复杂,因为你可能会得到多层嵌套在其他回调内部的回调,并且很难进行健壮的错误处理。
-
Promises 提供了一种新的组织回调函数的方式。如果使用正确(不幸的是,Promises 很容易被错误使用),它们可以将原本嵌套的异步代码转换为
then()调用的线性链,其中一个计算的异步步骤跟随另一个。此外,Promises 允许你将错误处理代码集中到一条catch()调用中,放在then()调用链的末尾。 -
async和await关键字允许我们编写基于 Promise 的异步代码,但看起来像同步代码。这使得代码更容易理解和推理。如果一个函数声明为async,它将隐式返回一个 Promise。在async函数内部,你可以像同步计算 Promise 值一样await一个 Promise(或返回 Promise 的函数)。 -
可以使用
for/await循环处理异步可迭代对象。你可以通过实现[Symbol.asyncIterator]()方法或调用async function *生成器函数来创建异步可迭代对象。异步迭代器提供了一种替代 Node 中“data”事件的方式,并可用于表示客户端 JavaScript 中用户输入事件的流。
¹ XMLHttpRequest 类与 XML 无关。在现代客户端 JavaScript 中,它大部分被fetch() API 取代,该 API 在§15.11.1 中有介绍。这里展示的代码示例是本书中仅剩的基于 XMLHttpRequest 的示例。
² 通常可以在浏览器的开发者控制台中的顶层使用await。而且有一个未决提案,允许在未来版本的 JavaScript 中使用顶层await。
³ 我从https://2ality.com博客中了解到了这种异步迭代的方法,作者是 Axel Rauschmayer 博士。
第十四章:元编程
本章介绍了一些高级 JavaScript 功能,这些功能在日常编程中并不常用,但对于编写可重用库的程序员可能很有价值,并且对于任何想要深入了解 JavaScript 对象行为细节的人也很有趣。
这里描述的许多功能可以宽泛地描述为“元编程”:如果常规编程是编写代码来操作数据,那么元编程就是编写代码来操作其他代码。在像 JavaScript 这样的动态语言中,编程和元编程之间的界限模糊——甚至简单地使用for/in循环迭代对象的属性的能力对更习惯于更静态语言的程序员来说可能被认为是“元编程”。
本章涵盖的元编程主题包括:
-
§14.1 控制对象属性的可枚举性、可删除性和可配置性
-
§14.2 控制对象的可扩展性,并创建“封闭”和“冻结”对象
-
§14.3 查询和设置对象的原型
-
§14.4 使用众所周知的符号微调类型的行为
-
§14.5 使用模板标签函数创建 DSL(领域特定语言)
-
§14.6 使用
reflect方法探查对象 -
§14.7 使用代理控制对象行为
14.1 属性特性
JavaScript 对象的属性当然有名称和值,但每个属性还有三个关联属性,指定该属性的行为方式以及您可以对其执行的操作:
-
可写 属性指定属性的值是否可以更改。
-
可枚举 属性指定属性是否由
for/in循环和Object.keys()方法枚举。 -
可配置 属性指定属性是否可以被删除,以及属性的属性是否可以更改。
在对象字面量中定义的属性或通过普通赋值给对象的属性是可写的、可枚举的和可配置的。但是,JavaScript 标准库中定义的许多属性并非如此。
本节解释了查询和设置属性特性的 API。这个 API 对于库作者尤为重要,因为:
-
它允许他们向原型对象添加方法并使它们不可枚举,就像内置方法一样。
-
它允许它们“锁定”它们的对象,定义不能被更改或删除的属性。
请回顾§6.10.6,在那里提到,“数据属性”具有值,“访问器属性”则具有 getter 和/或 setter 方法。对于本节的目的,我们将考虑访问器属性的 getter 和 setter 方法为属性特性。按照这种逻辑,我们甚至会说数据属性的值也是一个属性。因此,我们可以说属性有一个名称和四个属性。数据属性的四个属性是值、可写、可枚举和可配置。访问器属性没有值属性或可写属性:它们的可写性取决于是否存在 setter。因此,访问器属性的四个属性是获取、设置、可枚举和可配置。
JavaScript 用于查询和设置属性的方法使用一个称为属性描述符的对象来表示四个属性的集合。属性描述符对象具有与其描述的属性相同名称的属性。因此,数据属性的属性描述符对象具有名为value、writable、enumerable和configurable的属性。访问器属性的描述符具有get和set属性,而不是value和writable。writable、enumerable和configurable属性是布尔值,get和set属性是函数值。
要获取指定对象的命名属性的属性描述符,请调用Object.getOwnPropertyDescriptor():
// Returns {value: 1, writable:true, enumerable:true, configurable:true}
Object.getOwnPropertyDescriptor({x: 1}, "x");
// Here is an object with a read-only accessor property
const random = {
get octet() { return Math.floor(Math.random()*256); },
};
// Returns { get: /*func*/, set:undefined, enumerable:true, configurable:true}
Object.getOwnPropertyDescriptor(random, "octet");
// Returns undefined for inherited properties and properties that don't exist.
Object.getOwnPropertyDescriptor({}, "x") // => undefined; no such prop
Object.getOwnPropertyDescriptor({}, "toString") // => undefined; inherited
如其名称所示,Object.getOwnPropertyDescriptor()仅适用于自有属性。要查询继承属性的属性,必须显式遍历原型链。(参见§14.3 中的Object.getPrototypeOf());另请参阅§14.6 中的类似Reflect.getOwnPropertyDescriptor()函数。
要设置属性的属性或使用指定属性创建新属性,请调用Object.defineProperty(),传递要修改的对象、要创建或更改的属性的名称和属性描述符对象:
let o = {}; // Start with no properties at all
// Add a non-enumerable data property x with value 1.
Object.defineProperty(o, "x", {
value: 1,
writable: true,
enumerable: false,
configurable: true
});
// Check that the property is there but is non-enumerable
o.x // => 1
Object.keys(o) // => []
// Now modify the property x so that it is read-only
Object.defineProperty(o, "x", { writable: false });
// Try to change the value of the property
o.x = 2; // Fails silently or throws TypeError in strict mode
o.x // => 1
// The property is still configurable, so we can change its value like this:
Object.defineProperty(o, "x", { value: 2 });
o.x // => 2
// Now change x from a data property to an accessor property
Object.defineProperty(o, "x", { get: function() { return 0; } });
o.x // => 0
你传递给Object.defineProperty()的属性描述符不必包含所有四个属性。如果你正在创建一个新属性,那么被省略的属性被视为false或undefined。如果你正在修改一个现有属性,那么你省略的属性将保持不变。请注意,此方法会更改现有的自有属性或创建新的自有属性,但不会更改继承的属性。另请参阅§14.6 中的非常相似的Reflect.defineProperty()函数。
如果要一次创建或修改多个属性,请使用Object.defineProperties()。第一个参数是要修改的对象。第二个参数是将要创建或修改的属性的名称映射到这些属性的属性描述符的对象。例如:
let p = Object.defineProperties({}, {
x: { value: 1, writable: true, enumerable: true, configurable: true },
y: { value: 1, writable: true, enumerable: true, configurable: true },
r: {
get() { return Math.sqrt(this.x*this.x + this.y*this.y); },
enumerable: true,
configurable: true
}
});
p.r // => Math.SQRT2
这段代码从一个空对象开始,然后向其添加两个数据属性和一个只读访问器属性。它依赖于Object.defineProperties()返回修改后的对象(Object.defineProperty()也是如此)。
Object.create() 方法是在§6.2 中引入的。我们在那里学到,该方法的第一个参数是新创建对象的原型对象。该方法还接受第二个可选参数,与Object.defineProperties()的第二个参数相同。如果你向Object.create()传递一组属性描述符,那么它们将用于向新创建的对象添加属性。
如果尝试创建或修改属性不被允许,Object.defineProperty()和Object.defineProperties()会抛出 TypeError。如果你尝试向不可扩展的对象添加新属性,就会发生这种情况(参见§14.2)。这些方法可能抛出 TypeError 的其他原因与属性本身有关。可写属性控制对值属性的更改尝试。可配置属性控制对其他属性的更改尝试(并指定属性是否可以被删除)。然而,规则并不完全直观。例如,如果属性是可配置的,那么即使该属性是不可写的,也可以更改该属性的值。此外,即使属性是不可配置的,也可以将属性从可写更改为不可写。以下是完整的规则。调用Object.defineProperty()或Object.defineProperties()尝试违反这些规则会抛出 TypeError:
-
如果一个对象不可扩展,你可以编辑其现有的自有属性,但不能向其添加新属性。
-
如果一个属性不可配置,你就无法改变它的可配置或可枚举属性。
-
如果一个访问器属性不可配置,你就无法更改其 getter 或 setter 方法,也无法将其更改为数据属性。
-
如果一个数据属性不可配置,你就无法将其更改为访问器属性。
-
如果一个数据属性不可配置,你就无法将其可写属性从
false更改为true,但你可以将其从true更改为false。 -
如果一个数据属性不可配置且不可写,你就无法改变它的值。但是,如果一个属性是可配置但不可写的,你可以改变它的值(因为这与使其可写,然后改变值,然后将其转换回不可写是一样的)。
§6.7 描述了Object.assign()函数,它将一个或多个源对象的属性值复制到目标对象中。Object.assign()只复制可枚举属性和属性值,而不是属性属性。这通常是我们想要的,但这意味着,例如,如果一个源对象具有一个访问器属性,那么复制到目标对象的是 getter 函数返回的值,而不是 getter 函数本身。示例 14-1 演示了如何使用Object.getOwnPropertyDescriptor()和Object.defineProperty()创建Object.assign()的变体,该变体复制整个属性描述符而不仅仅是复制属性值。
示例 14-1. 从一个对象复制属性及其属性到另一个对象
/*
* Define a new Object.assignDescriptors() function that works like
* Object.assign() except that it copies property descriptors from
* source objects into the target object instead of just copying
* property values. This function copies all own properties, both
* enumerable and non-enumerable. And because it copies descriptors,
* it copies getter functions from source objects and overwrites setter
* functions in the target object rather than invoking those getters and
* setters.
*
* Object.assignDescriptors() propagates any TypeErrors thrown by
* Object.defineProperty(). This can occur if the target object is sealed
* or frozen or if any of the source properties try to change an existing
* non-configurable property on the target object.
*
* Note that the assignDescriptors property is added to Object with
* Object.defineProperty() so that the new function can be created as
* a non-enumerable property like Object.assign().
*/
Object.defineProperty(Object, "assignDescriptors", {
// Match the attributes of Object.assign()
writable: true,
enumerable: false,
configurable: true,
// The function that is the value of the assignDescriptors property.
value: function(target, ...sources) {
for(let source of sources) {
for(let name of Object.getOwnPropertyNames(source)) {
let desc = Object.getOwnPropertyDescriptor(source, name);
Object.defineProperty(target, name, desc);
}
for(let symbol of Object.getOwnPropertySymbols(source)) {
let desc = Object.getOwnPropertyDescriptor(source, symbol);
Object.defineProperty(target, symbol, desc);
}
}
return target;
}
});
let o = {c: 1, get count() {return this.c++;}}; // Define object with getter
let p = Object.assign({}, o); // Copy the property values
let q = Object.assignDescriptors({}, o); // Copy the property descriptors
p.count // => 1: This is now just a data property so
p.count // => 1: ...the counter does not increment.
q.count // => 2: Incremented once when we copied it the first time,
q.count // => 3: ...but we copied the getter method so it increments.
14.2 对象的可扩展性
对象的可扩展属性指定了是否可以向对象添加新属性。普通的 JavaScript 对象默认是可扩展的,但你可以通过本节描述的函数来改变这一点。
要确定一个对象是否可扩展,请将其传递给Object.isExtensible()。要使对象不可扩展,请将其传递给Object.preventExtensions()。一旦这样做,任何尝试向对象添加新属性的操作在严格模式下都会抛出 TypeError,在非严格模式下会静默失败而不会报错。此外,尝试更改不可扩展对象的原型(参见§14.3)将始终抛出 TypeError。
请注意,一旦将对象设置为不可扩展,就没有办法再使其可扩展。另外,请注意,调用Object.preventExtensions()只影响对象本身的可扩展性。如果向不可扩展对象的原型添加新属性,那么不可扩展对象将继承这些新属性。
有两个类似的函数,Reflect.isExtensible()和Reflect.preventExtensions(),在§14.6 中描述。
可扩展属性的目的是能够将对象“锁定”到已知状态,并防止外部篡改。对象的可扩展属性通常与属性的可配置和可写属性一起使用,JavaScript 定义了使设置这些属性变得容易的函数:
-
Object.seal()的作用类似于Object.preventExtensions(),但除了使对象不可扩展外,它还使该对象的所有自有属性不可配置。这意味着无法向对象添加新属性,也无法删除或配置现有属性。但是,可写的现有属性仍然可以设置。无法取消密封的对象。你可以使用Object.isSealed()来确定对象是否被密封。 -
Object.freeze()更加严格地锁定对象。除了使对象不可扩展和其属性不可配置外,它还使对象的所有自有数据属性变为只读。(如果对象具有具有 setter 方法的访问器属性,则这些属性不受影响,仍然可以通过对属性赋值来调用。)使用Object.isFrozen()来确定对象是否被冻结。
需要理解的是 Object.seal() 和 Object.freeze() 只会影响它们所传递的对象:它们不会影响该对象的原型。如果你想完全锁定一个对象,可能需要同时封闭或冻结原型链中的对象。
Object.preventExtensions(), Object.seal(), 和 Object.freeze() 都会返回它们所传递的对象,这意味着你可以在嵌套函数调用中使用它们:
// Create a sealed object with a frozen prototype and a non-enumerable property
let o = Object.seal(Object.create(Object.freeze({x: 1}),
{y: {value: 2, writable: true}}));
如果你正在编写一个 JavaScript 库,将对象传递给库用户编写的回调函数,你可能会在这些对象上使用 Object.freeze() 来防止用户的代码修改它们。这样做很容易和方便,但也存在一些权衡:冻结的对象可能会干扰常见的 JavaScript 测试策略,例如。
14.3 原型属性
一个对象的 prototype 属性指定了它继承属性的对象。(查看 §6.2.3 和 §6.3.2 了解更多关于原型和属性继承的内容。)这是一个非常重要的属性,我们通常简单地说“o 的原型”而不是“o 的 prototype 属性”。还要记住,当 prototype 出现在代码字体中时,它指的是一个普通对象属性,而不是 prototype 属性:第九章 解释了构造函数的 prototype 属性指定了使用该构造函数创建的对象的 prototype 属性。
prototype 属性在对象创建时设置。通过对象字面量创建的对象使用 Object.prototype 作为它们的原型。通过 new 创建的对象使用它们构造函数的 prototype 属性的值作为它们的原型。通过 Object.create() 创建的对象使用该函数的第一个参数(可能为 null)作为它们的原型。
你可以通过将对象传递给 Object.getPrototypeOf() 来查询任何对象的原型:
Object.getPrototypeOf({}) // => Object.prototype
Object.getPrototypeOf([]) // => Array.prototype
Object.getPrototypeOf(()=>{}) // => Function.prototype
一个非常相似的函数 Reflect.getPrototypeOf() 在 §14.6 中描述。
要确定一个对象是否是另一个对象的原型(或是原型链的一部分),使用 isPrototypeOf() 方法:
let p = {x: 1}; // Define a prototype object.
let o = Object.create(p); // Create an object with that prototype.
p.isPrototypeOf(o) // => true: o inherits from p
Object.prototype.isPrototypeOf(p) // => true: p inherits from Object.prototype
Object.prototype.isPrototypeOf(o) // => true: o does too
注意,isPrototypeOf() 执行类似于 instanceof 运算符的功能(参见 §4.9.4)。
对象的 prototype 属性在对象创建时设置并通常保持不变。但是,你可以使用 Object.setPrototypeOf() 改变对象的原型:
let o = {x: 1};
let p = {y: 2};
Object.setPrototypeOf(o, p); // Set the prototype of o to p
o.y // => 2: o now inherits the property y
let a = [1, 2, 3];
Object.setPrototypeOf(a, p); // Set the prototype of array a to p
a.join // => undefined: a no longer has a join() method
通常不需要使用 Object.setPrototypeOf()。JavaScript 实现可能会基于对象原型是固定且不变的假设进行激进的优化。这意味着如果你调用 Object.setPrototypeOf(),使用修改后的对象的任何代码可能比通常运行得慢得多。
一个类似的函数 Reflect.setPrototypeOf() 在 §14.6 中描述。
一些早期的浏览器实现暴露了对象的prototype属性,通过__proto__属性(以两个下划线开头和结尾)。尽管这种做法早已被弃用,但网络上存在大量依赖__proto__的现有代码,因此 ECMAScript 标准要求所有在 Web 浏览器中运行的 JavaScript 实现都必须支持它(Node 也支持,尽管标准不要求 Node 支持)。在现代 JavaScript 中,__proto__是可读写的,你可以(尽管不应该)将其用作Object.getPrototypeOf()和Object.setPrototypeOf()的替代方法。然而,__proto__的一个有趣用途是定义对象字面量的原型:
let p = {z: 3};
let o = {
x: 1,
y: 2,
__proto__: p
};
o.z // => 3: o inherits from p
14.4 众所周知的符号
Symbol 类型是在 ES6 中添加到 JavaScript 中的,这样做的一个主要原因是可以安全地向语言添加扩展,而不会破坏已部署在 Web 上的代码的兼容性。我们在第十二章中看到了一个例子,我们学到可以通过实现一个方法,其“名称”是符号Symbol.iterator,使一个类可迭代。
Symbol.iterator是“众所周知的符号”中最为人熟知的例子。这些是一组作为Symbol()工厂函数属性存储的符号值,用于允许 JavaScript 代码控制对象和类的某些低级行为。接下来的小节描述了每个这些众所周知的符号,并解释了它们的用途。
14.4.1 Symbol.iterator 和 Symbol.asyncIterator
Symbol.iterator 和 Symbol.asyncIterator 符号允许对象或类使自己可迭代或异步可迭代。它们在第十二章和§13.4.2 中有详细介绍,这里仅为完整性而提及。
14.4.2 Symbol.hasInstance
当描述instanceof运算符时,在§4.9.4 中我们说右侧必须是一个构造函数,并且表达式o instanceof f通过查找o的原型链中的值f.prototype来进行评估。这仍然是正确的,但在 ES6 及更高版本中,Symbol.hasInstance提供了一种替代方法。在 ES6 中,如果instanceof的右侧是具有[Symbol.hasInstance]方法的任何对象,则该方法将以其参数作为左侧值调用,并且方法的返回值,转换为布尔值,成为instanceof运算符的值。当然,如果右侧的值没有[Symbol.hasInstance]方法但是一个函数,则instanceof运算符会按照其普通方式行为。
Symbol.hasInstance意味着我们可以使用instanceof运算符来进行通用类型检查,只需定义适当的伪类型对象即可。例如:
// Define an object as a "type" we can use with instanceof
let uint8 = {
Symbol.hasInstance {
return Number.isInteger(x) && x >= 0 && x <= 255;
}
};
128 instanceof uint8 // => true
256 instanceof uint8 // => false: too big
Math.PI instanceof uint8 // => false: not an integer
请注意,这个例子很巧妙但令人困惑,因为它使用了一个非类对象,而通常期望的是一个类。对于你的代码读者来说,编写一个isUint8()函数而不依赖于Symbol.hasInstance行为会更容易理解。
14.4.3 Symbol.toStringTag
如果调用基本 JavaScript 对象的toString()方法,你会得到字符串“[object Object]”:
{}.toString() // => "[object Object]"
如果将相同的Object.prototype.toString()函数作为内置类型的实例方法调用,你会得到一些有趣的结果:
Object.prototype.toString.call([]) // => "[object Array]"
Object.prototype.toString.call(/./) // => "[object RegExp]"
Object.prototype.toString.call(()=>{}) // => "[object Function]"
Object.prototype.toString.call("") // => "[object String]"
Object.prototype.toString.call(0) // => "[object Number]"
Object.prototype.toString.call(false) // => "[object Boolean]"
使用Object.prototype.toString().call()技术可以获取任何 JavaScript 值的“类属性”,其中包含了否则无法获取的类型信息。下面的classof()函数可能比typeof运算符更有用,因为它可以区分不同类型的对象:
function classof(o) {
return Object.prototype.toString.call(o).slice(8,-1);
}
classof(null) // => "Null"
classof(undefined) // => "Undefined"
classof(1) // => "Number"
classof(10n**100n) // => "BigInt"
classof("") // => "String"
classof(false) // => "Boolean"
classof(Symbol()) // => "Symbol"
classof({}) // => "Object"
classof([]) // => "Array"
classof(/./) // => "RegExp"
classof(()=>{}) // => "Function"
classof(new Map()) // => "Map"
classof(new Set()) // => "Set"
classof(new Date()) // => "Date"
在 ES6 之前,Object.prototype.toString()方法的这种特殊行为仅适用于内置类型的实例,如果你在自己定义的类的实例上调用classof()函数,它将简单地返回“Object”。然而,在 ES6 中,Object.prototype.toString()会在其参数上查找一个名为Symbol.toStringTag的符号名称属性,如果存在这样的属性,它将在输出中使用属性值。这意味着如果你定义了自己的类,你可以轻松地使其与classof()等函数一起工作:
class Range {
get [Symbol.toStringTag]() { return "Range"; }
// the rest of this class is omitted here
}
let r = new Range(1, 10);
Object.prototype.toString.call(r) // => "[object Range]"
classof(r) // => "Range"
14.4.4 Symbol.species
在 ES6 之前,JavaScript 没有提供任何真正的方法来创建 Array 等内置类的强大子类。然而,在 ES6 中,你可以简单地使用class和extends关键字来扩展任何内置类。§9.5.2 演示了这个简单的 Array 子类:
// A trivial Array subclass that adds getters for the first and last elements.
class EZArray extends Array {
get first() { return this[0]; }
get last() { return this[this.length-1]; }
}
let e = new EZArray(1,2,3);
let f = e.map(x => x * x);
e.last // => 3: the last element of EZArray e
f.last // => 9: f is also an EZArray with a last property
Array 定义了concat()、filter()、map()、slice()和splice()等方法,它们返回数组。当我们创建一个像 EZArray 这样继承这些方法的数组子类时,继承的方法应该返回 Array 的实例还是 EZArray 的实例?对于任一选择都有充分的理由,但 ES6 规范表示(默认情况下)这五个返回数组的方法将返回子类的实例。
它是如何工作的:
-
在 ES6 及以后的版本中,
Array()构造函数有一个名为Symbol.species的符号属性。(请注意,此 Symbol 用作构造函数的属性名称。这里描述的大多数其他知名 Symbols 用作原型对象的方法名称。) -
当我们使用
extends创建一个子类时,结果子类构造函数会继承自超类构造函数的属性。(这是正常继承的一种,其中子类的实例继承自超类的方法。)这意味着每个 Array 的子类构造函数也会继承一个名为Symbol.species的继承属性。(或者子类可以定义自己的具有此名称的属性,如果需要的话。) -
在 ES6 及以后的版本中,像
map()和slice()这样创建并返回新数组的方法稍作调整。它们(实际上)调用new this.constructor[Symbol.species]()来创建新数组。
现在这里有趣的部分。假设Array[Symbol.species]只是一个常规的数据属性,像这样定义:
Array[Symbol.species] = Array;
在这种情况下,子类构造函数将以Array()构造函数作为其“species”继承,并在数组子类上调用map()将返回超类的实例而不是子类的实例。然而,ES6 实际上并不是这样行为的。原因是Array[Symbol.species]是一个只读的访问器属性,其 getter 函数简单地返回this。子类构造函数继承了这个 getter 函数,这意味着默认情况下,每个子类构造函数都是其自己的“species”。
然而,有时这种默认行为并不是你想要的。如果你希望 EZArray 的返回数组方法返回常规的 Array 对象,你只需要将EZArray[Symbol.species]设置为Array。但由于继承的属性是只读访问器,你不能简单地使用赋值运算符来设置它。不过,你可以使用defineProperty():
EZArray[Symbol.species] = Array; // Attempt to set a read-only property fails
// Instead we can use defineProperty():
Object.defineProperty(EZArray, Symbol.species, {value: Array});
最简单的选择可能是在创建子类时明确定义自己的Symbol.speciesgetter:
class EZArray extends Array {
static get [Symbol.species]() { return Array; }
get first() { return this[0]; }
get last() { return this[this.length-1]; }
}
let e = new EZArray(1,2,3);
let f = e.map(x => x - 1);
e.last // => 3
f.last // => undefined: f is a regular array with no last getter
创建有用的 Array 子类是引入Symbol.species的主要用例,但这并不是这个众所周知的 Symbol 被使用的唯一场合。Typed array 类使用 Symbol 的方式与 Array 类相同。类似地,ArrayBuffer 的slice()方法查看this.constructor的Symbol.species属性,而不是简单地创建一个新的 ArrayBuffer。而像then()这样返回新 Promise 对象的 Promise 方法也通过这种 species 协议创建这些对象。最后,如果您发现自己正在对 Map(例如)进行子类化并定义返回新 Map 对象的方法,您可能希望为了您的子类的好处自己使用Symbol.species。
14.4.5 Symbol.isConcatSpreadable
Array 方法concat()是前一节描述的使用Symbol.species确定返回的数组要使用的构造函数之一。但concat()还使用Symbol.isConcatSpreadable。回顾§7.8.3,数组的concat()方法将其this值和其数组参数与非数组参数区别对待:非数组参数简单地附加到新数组,但this数组和任何数组参数被展平或“展开”,以便将数组的元素连接起来而不是数组参数本身。
在 ES6 之前,concat()只是使用Array.isArray()来确定是否将一个值视为数组。在 ES6 中,算法略有改变:如果传递给concat()的参数(或this值)是一个对象,并且具有符号名称Symbol.isConcatSpreadable的属性,则该属性的布尔值用于确定是否应“展开”参数。如果不存在这样的属性,则像语言的早期版本一样使用Array.isArray()。
有两种情况下您可能想使用这个 Symbol:
-
如果您创建一个类似数组的对象(参见§7.9),并希望在传递给
concat()时表现得像真正的数组,您可以简单地向您的对象添加这个符号属性:let arraylike = { length: 1, 0: 1, [Symbol.isConcatSpreadable]: true }; [].concat(arraylike) // => [1]: (would be [[1]] if not spread) -
默认情况下,数组子类是可展开的,因此,如果您正在定义一个数组子类,而不希望在使用
concat()时表现得像数组,那么您可以在子类中添加一个类似这样的 getter:class NonSpreadableArray extends Array { get [Symbol.isConcatSpreadable]() { return false; } } let a = new NonSpreadableArray(1,2,3); [].concat(a).length // => 1; (would be 3 elements long if a was spread)
14.4.6 模式匹配符号
§11.3.2 记载了使用 RegExp 参数执行模式匹配操作的 String 方法。在 ES6 及更高版本中,这些方法已被泛化,可以与 RegExp 对象或任何定义了通过具有符号名称的属性进行模式匹配行为的对象一起使用。对于每个字符串方法match()、matchAll()、search()、replace()和split(),都有一个对应的众所周知的 Symbol:Symbol.match、Symbol.search等等。
正则表达式是描述文本模式的一种通用且非常强大的方式,但它们可能会很复杂,不太适合模糊匹配。通过泛化的字符串方法,您可以使用众所周知的 Symbol 方法定义自己的模式类,以提供自定义匹配。例如,您可以使用 Intl.Collator(参见§11.7.3)执行字符串比较,以在匹配时忽略重音。或者您可以基于 Soundex 算法定义一个模式类,根据其近似音调匹配单词或宽松匹配给定的 Levenshtein 距离内的字符串。
通常,当您在模式对象上调用这五个 String 方法之一时:
string.method(pattern, arg)
那个调用会变成在您的模式对象上调用一个以符号命名的方法:
patternsymbol
举个例子,考虑下一个示例中的模式匹配类,它使用简单的*和?通配符实现模式匹配,你可能从文件系统中熟悉这些通配符。这种模式匹配风格可以追溯到 Unix 操作系统的早期,这些模式通常被称为globs:
class Glob {
constructor(glob) {
this.glob = glob;
// We implement glob matching using RegExp internally.
// ? matches any one character except /, and * matches zero or more
// of those characters. We use capturing groups around each.
let regexpText = glob.replace("?", "([^/])").replace("*", "([^/]*)");
// We use the u flag to get Unicode-aware matching.
// Globs are intended to match entire strings, so we use the ^ and $
// anchors and do not implement search() or matchAll() since they
// are not useful with patterns like this.
this.regexp = new RegExp(`^${regexpText}$`, "u");
}
toString() { return this.glob; }
Symbol.search { return s.search(this.regexp); }
Symbol.match { return s.match(this.regexp); }
Symbol.replace {
return s.replace(this.regexp, replacement);
}
}
let pattern = new Glob("docs/*.txt");
"docs/js.txt".search(pattern) // => 0: matches at character 0
"docs/js.htm".search(pattern) // => -1: does not match
let match = "docs/js.txt".match(pattern);
match[0] // => "docs/js.txt"
match[1] // => "js"
match.index // => 0
"docs/js.txt".replace(pattern, "web/$1.htm") // => "web/js.htm"
14.4.7 Symbol.toPrimitive
§3.9.3 解释了 JavaScript 有三种稍有不同的算法来将对象转换为原始值。粗略地说,对于期望或偏好字符串值的转换,JavaScript 首先调用对象的toString()方法,如果未定义或未返回原始值,则回退到valueOf()方法。对于偏好数值的转换,JavaScript 首先尝试valueOf()方法,如果未定义或未返回原始值,则回退到toString()。最后,在没有偏好的情况下,它让类决定如何进行转换。日期对象首先使用toString()进行转换,而所有其他类型首先尝试valueOf()。
在 ES6 中,著名的 Symbol Symbol.toPrimitive 允许你重写默认的对象到原始值的行为,并完全控制你自己类的实例将如何转换为原始值。为此,请定义一个具有这个符号名称的方法。该方法必须返回某种代表对象的原始值。你定义的方法将被调用一个字符串参数,告诉你 JavaScript 正在尝试对你的对象进行什么样的转换:
-
如果参数是
"string",这意味着 JavaScript 在一个期望或偏好(但不是必须)字符串的上下文中进行转换。例如,当你将对象插入模板文字中时会发生这种情况。 -
如果参数是
"number",这意味着 JavaScript 在一个期望或偏好(但不是必须)数字值的上下文中进行转换。当你使用对象与<或>运算符或使用-和*等算术运算符时会发生这种情况。 -
如果参数是
"default",这意味着 JavaScript 在一个数字或字符串值都可以使用的上下文中转换你的对象。这发生在+、==和!=运算符中。
许多类可以忽略参数,并在所有情况下简单地返回相同的原始值。如果你希望你的类的实例可以使用<和>进行比较和排序,那么这是定义[Symbol.toPrimitive]方法的一个很好的理由。
14.4.8 Symbol.unscopables
我们将在这里介绍的最后一个著名 Symbol 是一个晦涩的 Symbol,它是为了解决由于已弃用的with语句引起的兼容性问题而引入的。回想一下,with语句接受一个对象,并执行其语句体,就好像它在对象的属性是变量的作用域中执行一样。当向 Array 类添加新方法时,这导致了兼容性问题,并且破坏了一些现有代码。Symbol.unscopables 就是解决方案。在 ES6 及更高版本中,with语句已经稍作修改。当与对象o一起使用时,with语句计算Object.keys(o[Symbol.unscopables]||{}),并在创建模拟作用域以执行其语句体时忽略其名称在生成的数组中的属性。ES6 使用这个方法向Array.prototype添加新方法,而不会破坏网络上的现有代码。这意味着你可以通过评估来找到最新的 Array 方法列表:
let newArrayMethods = Object.keys(Array.prototype[Symbol.unscopables]);
14.5 模板标签
反引号内的字符串称为“模板字面量”,在 §3.3.4 中有介绍。当一个值为函数的表达式后面跟着一个模板字面量时,它变成了一个函数调用,并且我们称之为“标记模板字面量”。为标记模板字面量定义一个新的标记函数可以被视为元编程,因为标记模板经常用于定义 DSL—领域特定语言—并且定义一个新的标记函数就像向 JavaScript 添加新的语法。标记模板字面量已经被许多前端 JavaScript 包采用。GraphQL 查询语言使用 gql 标签函数来允许查询嵌入到 JS 代码中。以及,Emotion 库使用css标记函数来使 CSS 样式嵌入到 JavaScript 中。本节演示了如何编写自己的类似这样的标记函数。
标记函数没有什么特别之处:它们是普通的 JavaScript 函数,不需要特殊的语法来定义它们。当一个函数表达式后面跟着一个模板字面量时,该函数被调用。第一个参数是一个字符串数组,然后是零个或多个额外参数,这些参数可以是任何类型的值。
参数的数量取决于插入到模板字面量中的值的数量。如果模板字面量只是一个没有插值的常量字符串,那么标记函数将被调用一个包含那个字符串的数组和没有额外参数的数组。如果模板字面量包含一个插入值,那么标记函数将被调用两个参数。第一个是包含两个字符串的数组,第二个是插入的值。初始数组中的字符串是插入值左侧的字符串和右侧的字符串,其中任何一个都可能是空字符串。如果模板字面量包含两个插入值,那么标记函数将被调用三个参数:一个包含三个字符串和两个插入值的数组。这三个字符串(任何一个或全部可能为空)是第一个值左侧的文本、两个值之间的文本和第二个值右侧的文本。在一般情况下,如果模板字面量有 n 个插入值,那么标记函数将被调用 n+1 个参数。第一个参数将是一个包含 n+1 个字符串的数组,其余参数是 n 个插入值,按照它们在模板字面量中出现的顺序。
模板字面量的值始终是一个字符串。但是标记模板字面量的值是标记函数返回的任何值。这可能是一个字符串,但是当标记函数用于实现 DSL 时,返回值通常是一个非字符串数据结构,它是字符串的解析表示。
作为一个返回字符串的模板标签函数的示例,考虑以下 html 模版,当你打算将值安全插入 HTML 字符串时比较实用。在使用它构建最终字符串之前,该标签在每个值上执行 HTML 转义:
function html(strings, ...values) {
// 将每个值转换为字符串并转义特殊的 HTML 字符
let escaped = values.map(v => String(v)
.replace("&", "&")
.replace("<", "<")
.replace(">", ">");
.replace('"', """)
.replace("'", "'"));
// 返回连接的字符串和转义的值
let result = strings[0];
for(let i = 0; i < escaped.length; i++) {
result += escaped[i] + strings[i+1];
}
return result;
}
let operator = "<";
html`<b>x ${operator} y</b>` // => "<b>x < y</b>"
let kind = "game", name = "D&D";
html`<div class="${kind}">${name}</div>` // =>'<div class="game">D&D</div>'
对于不返回字符串而是返回字符串的解析表示的标记函数的示例,回想一下 14.4.6 中定义的 Glob 模式类。由于Glob()构造函数采用单个字符串参数,因此我们可以定义一个标记函数来创建新的 Glob 对象:
function glob(strings, ...values) {
// 将字符串和值组装成一个字符串
let s = strings[0];
for(let i = 0; i < values.length; i++) {
s += values[i] + strings[i+1];
}
// 返回该字符串的解析表示
return new Glob(s);
}
let root = "/tmp";
let filePattern = glob`${root}/*.html`; // 一个 RegExp 替代方案
"/tmp/test.html".match(filePattern)[1] // => "test"
3.3.4 节中提到的特性之一是String.raw标签函数,以其“原始”形式返回一个字符串,而不解释任何反斜杠转义序列。这是使用我们尚未讨论过的标签函数调用的一个特性实现的。当调用标签函数时,我们已经看到它的第一个参数是一个字符串数组。但是这个数组还有一个名为 raw 的属性,该属性的值是另一个具有相同数量元素的字符串数组。参数数组包含已解释转义序列的字符串。原始数组包含未解释转义序列的字符串。如果要定义使用反斜杠的语法的语法的 DSL,这个晦涩的特性是重要的。例如,如果我们想要我们的 glob 标签函数支持 Windows 风格路径上的模式匹配(它使用反斜杠而不是正斜杠),并且我们不希望标签的用户必须双写每个反斜杠,我们可以重写该函数来使用strings.raw[]而不是strings[]。 当然,缺点可能是我们不能再在我们的 glob 字面值中使用转义,例如\u。
14.6 Reflect API
Reflect 对象不是一个类;像 Math 对象一样,其属性只是定义了一组相关函数。这些函数在 ES6 中添加,定义了一个 API,用于“反射”对象及其属性。这里几乎没有新功能:Reflect 对象定义了一组方便的函数,全部在一个命名空间中,模仿核心语言语法的行为并复制各种现有 Object 函数的功能。
尽管 Reflect 函数不提供任何新功能,但它们将功能组合在一个便利的 API 中。而且,重要的是,Reflect 函数集与我们将在§14.7 中学习的 Proxy 处理程序方法一一对应。
Reflect API 包括以下函数:
Reflect.apply(f, o, args)
此函数将函数f作为o的方法调用(如果o为null,则作为没有this值的函数调用),并将args数组中的值作为参数传递。它等效于f.apply(o, args)。
Reflect.construct(c, args, newTarget)
此函数调用构造函数c,就像使用new关键字一样,并将数组args的元素作为参数传递。如果指定了可选的newTarget参数,则它将用作构造函数调用中的new.target值。如果未指定,则new.target值将为c。
Reflect.defineProperty(o, name, descriptor)
此函数在对象o上定义属性,使用name(字符串或符号)作为属性的名称。描述符对象应该定义属性的值(或 getter 和/或 setter)和属性的属性。Reflect.defineProperty()与Object.defineProperty()非常相似,但成功时返回true,失败时返回false。(Object.defineProperty()成功时返回o,失败时抛出 TypeError。)
Reflect.deleteProperty(o, name)
此函数从对象o中删除具有指定字符串或符号名称的属性,如果成功(或不存在此属性),则返回true,如果无法删除属性,则返回false。调用此函数类似于编写delete o[name]。
Reflect.get(o, name, receiver)
此函数返回具有指定名称(字符串或符号)的对象o的属性的值。如果属性是具有 getter 的访问器方法,并且指定了可选的receiver参数,则 getter 函数将作为receiver的方法调用,而不是作为o的方法调用。调用此函数类似于评估o[name]。
Reflect.getOwnPropertyDescriptor(o, name)
此函数返回描述对象,描述对象描述了对象o的名为name的属性的属性,如果不存在此属性,则返回undefined。此函数与Object.getOwnPropertyDescriptor()几乎相同,只是 Reflect API 版本的函数要求第一个参数是对象,如果不是则抛出 TypeError。
Reflect.getPrototypeOf(o)
此函数返回对象o的原型,如果对象没有原型则返回null。如果o是原始值而不是对象,则抛出 TypeError。此函数与Object.getPrototypeOf()几乎相同,只是Object.getPrototypeOf()仅对null和undefined参数抛出 TypeError,并将其他原始值强制转换为其包装对象。
Reflect.has(o, name)
如果对象o具有指定的name属性(必须是字符串或符号),则此函数返回true。调用此函数类似于评估name in o。
Reflect.isExtensible(o)
此函数返回true如果对象o是可扩展的(§14.2),如果不可扩展则返回false。如果o不是对象,则抛出 TypeError。Object.isExtensible()类似,但当传递一个不是对象的参数时,它只返回false。
Reflect.ownKeys(o)
此函数返回对象o的属性名称的数组,如果o不是对象则抛出 TypeError。返回的数组中的名称将是字符串和/或符号。调用此函数类似于调用Object.getOwnPropertyNames()和Object.getOwnPropertySymbols()并组合它们的结果。
Reflect.preventExtensions(o)
此函数将对象o的可扩展属性(§14.2)设置为false,并返回true以指示成功。如果o不是对象,则抛出 TypeError。Object.preventExtensions()具有相同的效果,但返回o而不是true,并且不会为非对象参数抛出 TypeError。
Reflect.set(o, name, value, receiver)
此函数将对象o的指定name属性设置为指定的value。成功时返回true,失败时返回false(如果属性是只读的,则可能失败)。如果o不是对象,则抛出 TypeError。如果指定的属性是具有 setter 函数的访问器属性,并且传递了可选的receiver参数,则将调用 setter 作为receiver的方法,而不是作为o的方法。调用此函数通常与评估o[name] = value相同。
Reflect.setPrototypeOf(o, p)
此函数将对象o的原型设置为p,成功时返回true,失败时返回false(如果o不可扩展或操作会导致循环原型链)。如果o不是对象或p既不是对象也不是null,则抛出 TypeError。Object.setPrototypeOf()类似,但成功时返回o,失败时抛出 TypeError。请记住,调用这些函数之一可能会使您的代码变慢,因为它会破坏 JavaScript 解释器的优化。
14.7 代理对象
ES6 及更高版本中提供的 Proxy 类是 JavaScript 最强大的元编程功能。它允许我们编写改变 JavaScript 对象基本行为的代码。在§14.6 中描述的 Reflect API 是一组函数,它们直接访问 JavaScript 对象上的一组基本操作。Proxy 类的作用是允许我们自己实现这些基本操作并创建行为与普通对象不同的对象。
创建代理对象时,我们指定另外两个对象,目标对象和处理程序对象:
let proxy = new Proxy(target, handlers);
生成的代理对象没有自己的状态或行为。每当对其执行操作(读取属性、写入属性、定义新属性、查找原型、将其作为函数调用),它都将这些操作分派到处理程序对象或目标对象。
代理对象支持的操作与 Reflect API 定义的操作相同。假设p是代理对象,您写delete p.x。Reflect.deleteProperty()函数的行为与delete运算符相同。当使用delete运算符删除代理对象的属性时,它会在处理程序对象上查找deleteProperty()方法。如果存在这样的方法,则调用它。如果处理程序对象上不存在这样的方法,则代理对象将在目标对象上执行属性删除。
对于所有基本操作,代理对象都是这样工作的:如果处理程序对象上存在适当的方法,则调用该方法执行操作。(方法名称和签名与§14.6 中涵盖的 Reflect 函数相同。)如果处理程序对象上不存在该方法,则代理对象将在目标对象上执行基本操作。这意味着代理对象可以从目标对象或处理程序对象获取其行为。如果处理程序对象为空,则代理基本上是目标对象周围的透明包装器:
let t = { x: 1, y: 2 };
let p = new Proxy(t, {});
p.x // => 1
delete p.y // => true: 删除代理的属性 y
t.y // => undefined: 这也会在目标中删除它
p.z = 3; // 在代理上定义一个新属性
t.z // => 3: 在目标上定义属性
这种透明包装代理本质上等同于底层目标对象,这意味着没有理由使用它而不是包装对象。然而,当创建为“可撤销代理”时,透明包装器可以很有用。你可以使用 Proxy.revocable() 工厂函数,而不是使用 Proxy() 构造函数来创建代理。这个函数返回一个对象,其中包括一个代理对象和一个 revoke() 函数。一旦调用 revoke() 函数,代理立即停止工作:
function accessTheDatabase() { /* 实现省略 */ return 42; }
let {proxy, revoke} = Proxy.revocable(accessTheDatabase, {});
proxy() // => 42: 代理提供对基础目标函数的访问
revoke(); // 但是访问可以随时关闭
proxy(); // !TypeError: 我们不能再调用这个函数
注意,除了演示可撤销代理之外,上述代码还演示了代理可以与目标函数以及目标对象一起使用。但这里的主要观点是可撤销代理是一种代码隔离的基础,当你处理不受信任的第三方库时,可能会用到它们。例如,如果你必须将一个函数传递给一个你无法控制的库,你可以传递一个可撤销代理,然后在完成与库的交互后撤销代理。这可以防止库保留对你的函数的引用,并在意想不到的时候调用它。这种防御性编程在 JavaScript 程序中并不典型,但 Proxy 类至少使其成为可能。
如果我们将非空处理程序对象传递给 Proxy() 构造函数,那么我们不再定义一个透明的包装器对象,而是为我们的代理实现自定义行为。通过正确设置处理程序,底层目标对象基本上变得无关紧要。
例如,以下代码展示了如何实现一个看起来具有无限只读属性的对象,其中每个属性的值与属性的名称相同:
// 我们使用代理创建一个对象, 看起来拥有每个
// 可能的属性, 每个属性的值都等于其名称
let identity = new Proxy({}, {
// 每个属性都以其名称作为其值
get(o, name, target) { return name; },
// 每个属性名称都已定义
has(o, name) { return true; },
// 有太多属性要枚举, 所以我们只是抛出
ownKeys(o) { throw new RangeError("属性数量无限"); },
// 所有属性都存在且不可写, 不可配置或可枚举。
getOwnPropertyDescriptor(o, name) {
return {
value: name,
enumerable: false,
writable: false,
configurable: false
};
},
// 所有属性都是只读的, 因此无法设置
set(o, name, value, target) { return false; },
// 所有属性都是不可配置的, 因此它们无法被删除
deleteProperty(o, name) { return false; },
// 所有属性都存在且不可配置, 因此我们无法定义更多
defineProperty(o, name, desc) { return false; },
// 实际上, 这意味着对象不可扩展
isExtensible(o) { return false; },
// 所有属性已在此对象上定义, 因此无法
// 即使它有原型对象, 也不会继承任何东西。
getPrototypeOf(o) { return null; },
// 对象不可扩展, 因此我们无法更改原型
setPrototypeOf(o, proto) { return false; },
});
identity.x // => "x"
identity.toString // => "toString"
identity[0] // => "0"
identity.x = 1; // 设置属性没有效果
identity.x // => "x"
delete identity.x // => false: 也无法删除属性
identity.x // => "x"
Object.keys(identity); // !RangeError: 无法列出所有键
for(let p of identity) ; // !RangeError
代理对象可以从目标对象和处理程序对象派生其行为,到目前为止我们看到的示例都使用了一个对象或另一个对象。但通常更有用的是定义同时使用两个对象的代理。
例如,下面的代码使用 Proxy 创建了一个目标对象的只读包装器。当代码尝试从对象中读取值时,这些读取会正常转发到目标对象。但如果任何代码尝试修改对象或其属性,处理程序对象的方法会抛出 TypeError。这样的代理可能有助于编写测试:假设你编写了一个接受对象参数的函数,并希望确保你的函数不会尝试修改输入参数。如果你的测试传入一个只读包装器对象,那么任何写入操作都会抛出异常,导致测试失败:
function readOnlyProxy(o) {
function readonly() { throw new TypeError("只读"); }
return new Proxy(o, {
set: readonly,
defineProperty: readonly,
deleteProperty: readonly,
setPrototypeOf: readonly,
});
}
let o = { x: 1, y: 2 }; // 普通可写对象
let p = readOnlyProxy(o); // 它的只读版本
p.x // => 1: 读取属性有效
p.x = 2; // !TypeError: 无法更改属性
delete p.y; // !TypeError: 无法删除属性
p.z = 3; // !TypeError: 无法添加属性
p.__proto__ = {}; // !TypeError: 无法更改原型
写代理时的另一种技术是定义处理程序方法,拦截对象上的操作,但仍将操作委托给目标对象。Reflect API(§14.6)的函数具有与处理程序方法完全相同的签名,因此它们使得执行这种委托变得容易。
例如,这是一个代理,它将所有操作委托给目标对象,但使用处理程序方法记录操作:
/*
* 返回一个代理对象, 包装 o, 将所有操作委托给
* 在记录每个操作后, 该对象的名称是一个字符串
* 将出现在日志消息中以标识对象。如果 o 具有自有
* 其值为对象或函数, 则如果您查询
* 这些属性的值是对象或函数, 则返回代理而不是
* 此代理的记录行为是“传染性的”。
*/
function loggingProxy(o, objname) {
// 为我们的记录代理对象定义处理程序。
// 每个处理程序记录一条消息, 然后委托给目标对象。
const handlers = {
// 这个处理程序是一个特例, 因为对于自有属性
// 其值为对象或函数, 则返回代理而不是值本身。
// 返回值本身。
get(target, property, receiver){
// 记录获取操作
console.log(`Handler get(${objname}, ${property.toString()})`);
// 使用 Reflect API 获取属性值
let value = Reflect.get(target, property, receiver);
// 如果属性是目标的自有属性且
// 值是对象或函数, 则返回其代理。
if(Reflect.ownKeys(target).includes(property)&&
(typeof value === "object" || typeof value === "function")){
return loggingProxy(value, `${objname}.${property.toString()}`);
}
// 否则返回未修改的值。
返回值;
},
// 以下三种方法没有特殊之处:
// 它们记录操作并委托给目标对象。
// 它们是一个特例, 只是为了避免记录
// 可能导致无限递归的接收器对象。
set(target, prop, value, receiver){
console.log(`Handler set(${objname}, ${prop.toString()}, ${value})`);
return Reflect.set(target, prop, value, receiver);
},
apply(target, receiver, args){
console.log(`Handler ${objname}(${args})`);
return Reflect.apply(target, receiver, args);
},
构造(target, args, receiver){
console.log(`Handler ${objname}(${args})`);
return Reflect.construct(target, args, receiver);
}
};
// 我们可以自动生成其余的处理程序。
// 元编程 FTW!
Reflect.ownKeys(Reflect).forEach(handlerName => {
if(!(handlerName in handlers)){
handlers[handlerName] = function(target, ...args){
// 记录操作
console.log(`Handler ${handlerName}(${objname}, ${args})`);
// 委托操作
return Reflect[handlerName](target, ...args);
};
}
});
// 返回一个对象的代理, 使用这些记录处理程序
return new Proxy(o, handlers);
}
之前定义的 loggingProxy() 函数创建了记录其使用方式的代理。如果你试图了解一个未记录的函数如何使用你传递给它的对象,使用记录代理可以帮助。
考虑以下示例,这些示例对数组迭代产生了一些真正的见解:
// 定义一个数据数组和一个具有函数属性的对象
let data = [10,20];
let methods = { square: x => x*x };
// 为数组和具有函数属性的对象创建记录代理
let proxyData = loggingProxy(data, "data");
let proxyMethods = loggingProxy(methods, "methods");
// 假设我们想要了解 Array.map()方法的工作原理
data.map(methods.square) // => [100, 400]
// 首先, 让我们尝试使用一个记录代理数组
proxyData.map(methods.square) // => [100, 400]
// 它产生以下输出:
// Handler get(data, map)
// Handler get(data, length)
// Handler get(data, constructor)
// Handler has(data, 0)
// Handler get(data, 0)
// Handler has(data, 1)
// Handler get(data, 1)
// 现在让我们尝试使用一个代理方法对象
data.map(proxyMethods.square) // => [100, 400]
// 记录输出:
// Handler get(methods, square)
// Handler methods.square(10, 0, 10, 20)
// Handler methods.square(20, 1, 10, 20)
// 最后, 让我们使用一个记录代理来了解迭代协议
for(let x of proxyData) console.log("data", x);
// 记录输出:
// Handler get(data, Symbol(Symbol.iterator))
// Handler get(data, length)
// Handler get(data, 0)
// data 10
// Handler get(data, length)
// Handler get(data, 1)
// data 20
// Handler get(data, length)
从第一块日志输出中,我们了解到 Array.map() 方法在实际读取元素值之前明确检查每个数组元素的存在性(导致调用 has() 处理程序),然后读取元素值(触发 get() 处理程序)。这可能是为了区分不存在的数组元素和存在但为 undefined 的元素。
第二块日志输出可能会提醒我们,我们传递给 Array.map() 的函数会使用三个参数调用:元素的值、元素的索引和数组本身。(我们的日志输出中存在问题:Array.toString() 方法在其输出中不包含方括号,并且如果在参数列表中包含它们,日志消息将更清晰 (10,0,[10,20])。)
第三块日志输出向我们展示了 for/of 循环是通过查找具有符号名称 [Symbol.iterator] 的方法来工作的。它还演示了 Array 类对此迭代器方法的实现在每次迭代时都会检查数组长度,并且不假设数组长度在迭代过程中保持不变。
14.7.1 代理不变性
之前定义的 readOnlyProxy() 函数创建了实际上是冻结的代理对象:任何尝试更改属性值、属性属性或添加或删除属性的尝试都会引发异常。但只要目标对象未被冻结,我们会发现如果我们可以使用 Reflect.isExtensible() 和 Reflect.getOwnPropertyDescriptor() 查询代理,它会告诉我们应该能够设置、添加和删除属性。因此,readOnlyProxy() 创建了处于不一致状态的对象。我们可以通过添加 isExtensible() 和 getOwnPropertyDescriptor() 处理程序来解决这个问题,或者我们可以接受这种轻微的不一致性。
代理处理程序 API 允许我们定义具有主要不一致性的对象,但在这种情况下,代理类本身将阻止我们创建不良不一致的代理对象。在本节开始时,我们将代理描述为没有自己行为的对象,因为它们只是将所有操作转发到处理程序对象和目标对象。但这并不完全正确:在转发操作后,代理类会对结果执行一些检查,以确保不违反重要的 JavaScript 不变性。如果检测到违规,代理将抛出 TypeError,而不是让操作继续执行。
例如,如果为不可扩展对象创建代理,则如果 isExtensible() 处理程序返回 true,代理将抛出 TypeError:
let target = Object.preventExtensions({});
let proxy = new Proxy(target, { isExtensible(){ return true; });
Reflect.isExtensible(proxy); // !TypeError:不变违规
相关地,对于不可扩展目标的代理对象可能没有返回除目标的真实原型对象之外的 getPrototypeOf() 处理程序。此外,如果目标对象具有不可写、不可配置的属性,则代理类将在 get() 处理程序返回除实际值之外的任何内容时抛出 TypeError:
let target = Object.freeze({x: 1});
let proxy = new Proxy(target, { get(){ return 99; });
proxy.x; // !TypeError:get()返回的值与目标不匹配
代理强制执行许多附加不变性,几乎所有这些不变性都与不可扩展的目标对象和目标对象上的不可配置属性有关。
14.8 总结
在本章中,您已经学到了:
-
JavaScript 对象具有可扩展属性,对象属性具有可写、可枚举和可配置属性,以及值和 getter 和/或 setter 属性。您可以使用这些属性以各种方式“锁定”您的对象,包括创建“密封”和“冻结”对象。
-
JavaScript 定义了一些函数,允许您遍历对象的原型链,甚至更改对象的原型(尽管这样做可能会使您的代码变慢)。
-
Symbol对象的属性具有“众所周知的符号”值,您可以将其用作您定义的对象和类的属性或方法名称。这样做可以让您控制对象与 JavaScript 语言特性和核心库的交互方式。例如,众所周知的符号允许您使您的类可迭代,并控制将实例传递给Object.prototype.toString()时显示的字符串。在 ES6 之前,这种定制仅适用于内置到实现中的本机类。 -
标记模板字面量是一种函数调用语法,定义一个新的标签函数有点像向语言添加新的文字语法。定义一个解析其模板字符串参数的标签函数允许您在 JavaScript 代码中嵌入 DSL。标签函数还提供对原始、未转义的字符串文字的访问,其中反斜杠没有特殊含义。
-
代理类和相关的 Reflect API 允许对 JavaScript 对象的基本行为进行低级控制。代理对象可以用作可选撤销包装器,以改善代码封装,并且还可以用于实现非标准对象行为(例如早期 Web 浏览器定义的一些特殊情况 API)。
¹ V8 JavaScript 引擎中的一个错误意味着这段代码在 Node 13 中无法正常工作。
标签:异步,函数,迭代,对象,JavaScript,Promise,重译,第七版,属性 From: https://www.cnblogs.com/apachecn/p/18089175