使用Python实现查重
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 初步认识软件开发流程,独立培养开发能力,熟悉PSP记录开发过程 |
你可以在GitHub上找到本项目并下载额外三种算法代码
前言
作为开发人员,不幸的是此前未曾接触熟悉过Python语言,本次开发即第一次实战,在使用C语言进行开发途中遇到许多问题,调试无果,遂改用面向对象语言进行开发
为熟悉软件开发流程,本次开发将按照PSP进行开发记录
如果需要查询设计流程,接口实现,性能优化,异常处理等,代码分析等,请阅读PSP开发记录文档,此处不再大篇幅给出,仅仅给出作业要求部分
相似度计算
本处给出基本信息,详细请查阅文档
余弦相似度
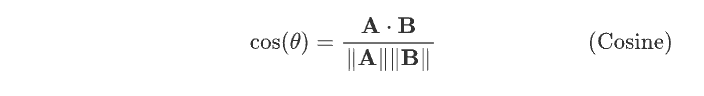
雅可比相似度
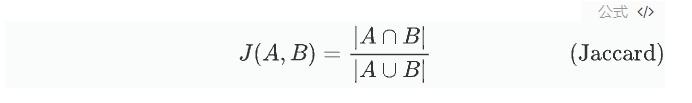
编辑距离
莱文斯坦距离 / 编辑距离(Edit Distance,Levenshtein Distance只是编辑距离的其中一种)
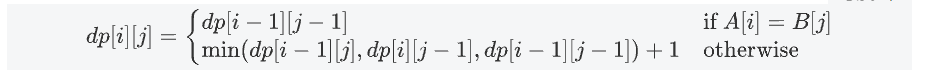
公式理解:通过动态规划来实现,设 dp[i][j] 表示字符串 A 的前 i 个字符和字符串 B 的前 j 个字符的编辑距离,我们有以下的状态转移方程:
- 如果
A[i] == B[j],那么dp[i][j] = dp[i-1][j-1]。 - 否则,
dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + 1。
欧式距离
该方法不太适用本次作业,没有过多实现,但给出了基本代码
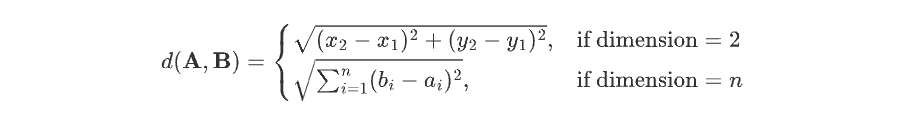
接口设计
使用代码实现预设操作——仅仅考虑传入英文和中文文档的情况
针对中文文档
-
净化文本
re库是Python的正则表达式库,使用它来移除文本中的标点符号,使用正则表达式[^\w\s]来匹配所有的标点符号,然后使用re.sub函数将它们替换为无 -
停用词处理--需求不允许读写其他文件,此处停用词处理仅供参考
STOP_WORDS需要自己指定停用表,初步设想是打开以及做好的停用表文件
-
分词处理
jieba库是一个用于中文分词的Python库,这个函数的作用是对文本进行分词。使用jieba.cut函数来进行分词,然后使用' '.join来将分词后的结果连接成一个字符串
针对英文文档
-
转换小写
-
净化文本
-
移除停用词
函数的作用是移除文本中的英文停用词。我们使用
nltk.corpus.stopwords.words('english')来获取英文的停用词列表,然后移除他们
对两种处理进行区分并相应处理
-
预处理函数的构建
函数会对传入的文档以及其语言不同分别处理,调用上述文档处理文件执行操作
-
相似度的计算
三种方法均已实现此处仅给出main默认使用的余弦算法
-
将结果输出保存到目标文件
-
接受文件参数以及函数调用入口
给出接口设计的调用图,能力有限不能理解所有内容
单元测试
本处给出单元测试,在PSP开发记录文档有集成测试
初次开发对流程不是很了解,本次单元测试是在进行接口优化后才学习完成的,对本版块还是不太熟悉,测试是模仿写出来的
Python的unittest库提供了编写单元测试的框架
首先创建一个测试类
class TestCosine(unittest.TestCase):
编写测试用例
每一个测试用例都是测试类中的一个方法。这个方法会使用
assert语句来验证代码的行为。如果assert语句失败(也就是说,它的条件为False),那么测试就会失败
仅给出一个测试案例,其他案例在代码test部分可以找到
def test_cosine_similarity_sklearn(self):
vec1 = Counter(["你好", "世界"])
vec2 = Counter(["你好", "世界"])
self.assertEqual(cosine_similarity_sklearn(vec1, vec2), 1.0)
代码覆盖率

修改了几次效果不是很好,或许忽略了某些情况
优化处理
本次不再给出代码,详细请在PSP开发记录文档中查看
对于当前代码我们在执行的时候不难发现有许多存在的问题,最主要的问题是无法满足5s完成计算的需求,所以我们来分析程序的运行
通过测试案例:使用命令行来传入
python cosine_similarity.py .\orig.txt .\orig_0.8_add.txt .\output.txt
此处的两个文件有千字
运行函数监测并发图

不难发现这次进程耗时巨大
开始优化处理
考虑多进程执行
创建一个进程池,通过并行处理,对两个出入进行文档处理,zip(texts1, texts2, output_files)创建一个元组的列表,其中每个元组包含一个来自texts1的元素、一个来自texts2的元素和一个来自output_files的元素。然后,starmap函数将这些元组解包,并将元组中的元素作为参数传递给worker函数,最终实现并行处理
优化之后:

不难发现变快了近一秒
再次尝试优化分析
通过Python的cProfile模块生成性能分析报告
本模块提供方便的查询报告结果,也可以通过Pycharm专业版中的优化分析来实现
ncalls tottime percall cumtime percall filename:lineno(function)
2 0.000 0.000 3.900 1.950 pool.py:359(map)
3 0.000 0.000 3.901 1.300 pool.py:761(wait)
3 0.000 0.000 3.901 1.300 pool.py:764(get)
6 0.000 0.000 3.905 0.651 threading.py:288(wait)
表中列出花销比较大的几个函数,查阅资料:multiprocessing.Pool().map函数和multiprocessing.pool.wait/get函数以及threading.wait函数都是用于并行处理和线程同步的,执行时间主要取决于代码的并行部分的运行时间,没有办法从这些代码入手
那么改变思路,来优化并行任务减少并行任务量
通过对比cpu核心数量与文件数量,保证任务量一定小于cpu核心数量,取其中最小值可以大大减少无用进程
执行代码

时间减少1秒左右,两次优化将效率提高一倍左右
异常处理
考虑单元的异常
当输入路径不存在的时候
python main.py .\text1.txt .\text2.txt .\out.txt
程序会自动创建文件,这样不符合要求,我们来修改main_cosine代码
增加一个查询文件是否存在的功能
# 检查文件路径是否存在
for file_path in file_paths1 + file_paths2:
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件 {file_path} 不存在")
异常处理还有无效语言,文件权限等问题,能力有限就不继续探究
在准备结束项目的时候又发现了一个异常,当我尝试传入绝对路径时候,程序总是无法得出结果,于是开始排查异常
首先对绝对路径传入处理,拟使用了 Python 的 os 模块中的 os.path.normpath() 函数,可惜还是不对
再次分析代码,注意到处理文档函数传入的是一个字符串,这就导致了文档路径被当作字符串处理,这是因为之前在做性能优化时,为了减少IO次数而优化的,这个优化现阶段看起来不是那么好,修改它
def preprocess_text(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
...
问题解决
PSP表
| *PSP2.1* | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | 计划 | 30 | 140 |
| · Estimate | · 估计这个任务需要多少时间 | 120 | 160 |
| Development | 开发 | 300 | 420 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 200 |
| · Design Spec | · 生成设计文档 | 10 | 120 |
| · Design Review | · 设计复审 | 5 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 3 | 10 |
| · Design | · 具体设计 | 15 | 60 |
| · Coding | · 具体编码 | 120 | 140 |
| · Code Review | · 代码复审 | 20 | 70 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 30 | 60 |
| · Test Repor | · 测试报告 | 40 | 30 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 848 | 1545 |