1 哈希
1.1 概念
哈希就是构造一个数字使之唯一的代表一个字符串。
我们来考虑一下二进制数的转化:
$(1001)2=1\times 23+0\times22+0\times2^1+1=(9)$
现在,我们令 $'a'=1,'b'=2,'c'=3\cdots,'z'=26$。然后将进制 $p$ 设为 $131$。就能得到:
$(abc)p=1\times p^2+2\times p+3=(2248356)$
这个过程就叫做字符串哈希。
在实际应用中,哈希常常用来判断字符串是否相等。然而,在有些情况下,难免会有两个不同字符串哈希值相等,我们的程序就会爆掉。因此,在正常情况下,通常取 $p=131,13331$ 等素数,而且还需要取模,模数一般取 $2^{64}-1$。
1.2 实现
1.2.1 单哈希
我们设 hash[i] 为字符串前 $i$ 位的哈希值。则有递推公式:
hash[i] = hash[i - 1] * p + s[i] - 47
由于模数取 $2^{64}-1$,因此可以用 unsigned long long 类型的自然溢出来达到取模的效果。
代码:
string s;
ull h[Maxn];//注意 c++14 中 "hash" 是关键字
const ull p = 131;
void Hash() {
for(int i = 1; i <= s.size(); i++) {
h[i] = h[i - 1] * p + (s[i] - 'a' + 1);
}
}
1.2.2 双哈希
由于一个哈希仍仍可能被毒瘤出题人卡掉,我们可以对一个字符串用两个 $q$ 计算,只有两个哈希都相等时才满足。这被称之为双哈希,几乎不可能再有错误概率。
如下:
string s;
ll h1[Maxn], h2[Maxn];
const ll p = 131;
const ll q1 = 998244353;
const ll q2 = 1000000007;
void Hash() {
for(int i = 1; i <= s.size(); i++) {
h1[i] = (h1[i - 1] * p % q1 + (s[i] - 'a' + 1) % q1) % q1;
h2[i] = (h2[i - 1] * p % q2 + (s[i] - 'a' + 1) % q2) % q2;
}
}
1.3 基本应用
1.3.1 获取字串哈希
我们举一个浅显的例子:
设一个字符串为 $s_1s_2s_3s_4$。
则哈希值分别如下:
$hash[1]=s_1$
$hash[2]=s_1\times p + s_2$
$hash[3] = s_1\times p^2 + s_2 \times p + s_3$
$hash[4] = s1 \times p^3 + s_2 \times p^2 + s_3\times p + s_4$
假如我们要知道 $s_3s_4$ 的哈希值,也就是 $s_3\times p + s_4$,应该怎么算呢?
很明显,用 $hash[4]$ 和 $hash[2]$ 得到,但 $hash[2]$ 差了一个 $p^2$,我们就给他乘上,所以结果为:
$hash[4]-hash[2]\times p^2$
这启示我们一个重要的公式:
一个字符串 $|S|$ ,其字串 $s_l\cdots s_r$ 的哈希值的为:
$hash[r] - hash[l-1]\times p^{r-l+1}$
注意实际应用中的取模。
1.3.2 一些应用
首先,有一句不知道谁说的话:
哈希可以当半个 KMP、Manacher 等其他字符串算法使用。
1.3.2.1 字符串匹配
这个其实很好做了,求出文本串中每个与模式串长度相等的串的哈希,比较即可。
1.3.2.2 允许至多 $k$ 次失配的字符串匹配
这道题无法使用 KMP 解决,但是可以通过哈希 + 二分来解决。
枚举所有可能匹配的子串,假设现在枚举的子串为 $s'$ ,通过哈希 + 二分可以快速找到 $s'$ 与 $p$ 第一个不同的位置。之后将 $s'$ 与 $p$ 在这个失配位置及之前的部分删除掉,继续查找下一个失配位置。这样的过程最多发生 $k$ 次。
总的时间复杂度为 $O(m+kb\log_2m)$。
1.3.2.3 最长回文子串
这就体现出半个 Manacher 的好处了。
二分答案,判断可行时枚举回文中心(对称轴),哈希来判断来两侧是否相等。需要正着和倒着都处理一遍哈希,复杂度 $O(n\log n)$。
(其实哈希就可以当 Manacher 使用,有一种 $O(n)$ 的哈希回文,具体看 OI Wiki)
2 KMP
2.1 问题概述
这个算法是一种在文本串 $s$ 中查找模式串 $p$ 的算法。
我们先想一下暴力算法会怎么做:
int i = 0, j = 0;
while (i < s.size())
{
if (s[i] == p[j])
++i, ++j;
else
i = i - j + 1, j = 0;
if (j == p.length()) // 匹配成功
{
cout << i - j << endl;
i = i - j + 1;
j = 0;
}
}
在暴力匹配中,我们定义了两个指针 $i$ 和 $j$,分别在 $s$ 和 $p$ 上。每次 $i$ 与 $j$ 失配时,$i,j$ 都要回溯至起始点重新匹配。复杂度 $O(nm)$。
由于每次失配时,$i,j$ 都要回溯至起始点重新匹配,这样大大浪费了时间。我们考虑将 $i$ 定住,不让 $i$ 回溯。现在的问题是:$j$ 如何转移?
2.2 KMP 算法
2.2.1 PMT 表
$j$ 如何转移,至于模式串 $p$ 有关。每个模式串都有一个 PMT。我们定义 pmt[i] 表示前 $i$ 位中公共真前后缀的长度。通俗来讲就是从 $p_0$ 往后,$p_i$ 往前数,保证相同的情况下最多能数多少位。
例如:
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
p[i] |
a | b | a | b | c | a | b | a | a |
pmt[i] |
0 | 0 | 1 | 2 | 0 | 1 | 2 | 3 | 1 |
接下来,我们先不管 pmt[i] 如何求,我们先来考虑一下 PMT 对于 $j$ 转移的作用。
我们来看下面两个字符串:
| a | b | a | b | a | b | c | a | b |
|---|---|---|---|---|---|---|---|---|
| a | b | a | b | c |
我们来看第 $5$ 格,此时失配,我们保持 $i$ 不变。由于 abab 已经匹配成功,同时有公共前后缀 ab,我们把它利用起来,变成这样:
| a | b | a | b | a | b | c | a | b |
|---|---|---|---|---|---|---|---|---|
| a | b | a | b | c |
我们就充分利用到了之前的结果。这里实际上就是进行 j=pmt[j-1] 操作。
当然,如果一直不匹配,我们要一直让 $j$ 等于 pmt[j-1],pmt[pmt[j-1]-1]……直到等于 $0$。
代码如下:
void KMP(string s, string p) {
for(int i = 0, j = 0; i < s.size(); i++) {
while(j && s[i] != p[j]) j = pmt[j - 1];
if(s[i] == p[j]) j++;
if(j == p.size()) {
//do something...
j = pmt[j - 1];
}
}
}
2.2.2 求 PMT
上面已经讲述了如何求解 KMP,但有一个很小的大问题:
如何求出 PMT?
有一个相当精妙的方法:将 $p$ 错开一位后,自己去匹配自己。这其实相当于用前缀来匹配一个公共的后缀。
先令 pmt[0]=0。然后如下:
| a | b | a | b | c | a | b | a | a | |
|---|---|---|---|---|---|---|---|---|---|
| a | b | a | b | c | a | b | a | a |
第一位匹配失败,pmt[1]=0,$i$ 后移。
| a | b | a | b | c | a | b | a | a | ||
|---|---|---|---|---|---|---|---|---|---|---|
| a | b | a | b | c | a | b | a | a |
匹配成功,则 $j$ 指针右移,于是 pmt[2]=1,两个指针均右移。
而后不断重复。其实这段代码与 KMP 过程相当相似:
void PMT(string p) {
for(int i = 1, j = 0; i < p.size(); i++) {
while(j && p[i] != p[j]) j = pmt[j - 1];
if(p[i] == p[j]) j++;
pmt[i] = j;
}
}
然后就得到了完整的 KMP 代码。
2.3 完整代码
以 POJ3461 乌力波 为例:
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
const int Maxn = 1e6 + 5;
string s, p;
int pmt[Maxn], cnt;
void PMT(string p) {
for(int i = 1, j = 0; i < p.size(); i++) {
while(j && p[i] != p[j]) j = pmt[j - 1];
if(p[i] == p[j]) j++;
pmt[i] = j;
}
}
void KMP(string s, string p) {
for(int i = 0, j = 0; i < s.size(); i++) {
while(j && s[i] != p[j]) j = pmt[j - 1];
if(s[i] == p[j]) j++;
if(j == p.size()) {
cnt++;
j = pmt[j - 1];
}
}
}
int T;
int main() {
ios::sync_with_stdio(0);
cin >> T;
while(T--) {
cin >> p >> s;
cnt = 0;
PMT(p);
KMP(s, p);
cout << cnt << '\n';
}
return 0;
}
2.3.1 补充
大多数文章和教材会使用 next[i] 数组,其实就是将 pmt 整体右移一位(令 next[0]=-1)
而上面的算法也只能叫 MP 算法,因为我们还缺少一个由 Knuth 提出的常数优化。但时间复杂度永远是 $O(n+m)$。具体可以看 这个。
3 Trie
3.1 概念
Trie(字典树)是一个比较好理解的数据结构,用来存储和查询字符串。
如下图,就是一颗由 water,wish,win,tie,tired 组成的字典树。
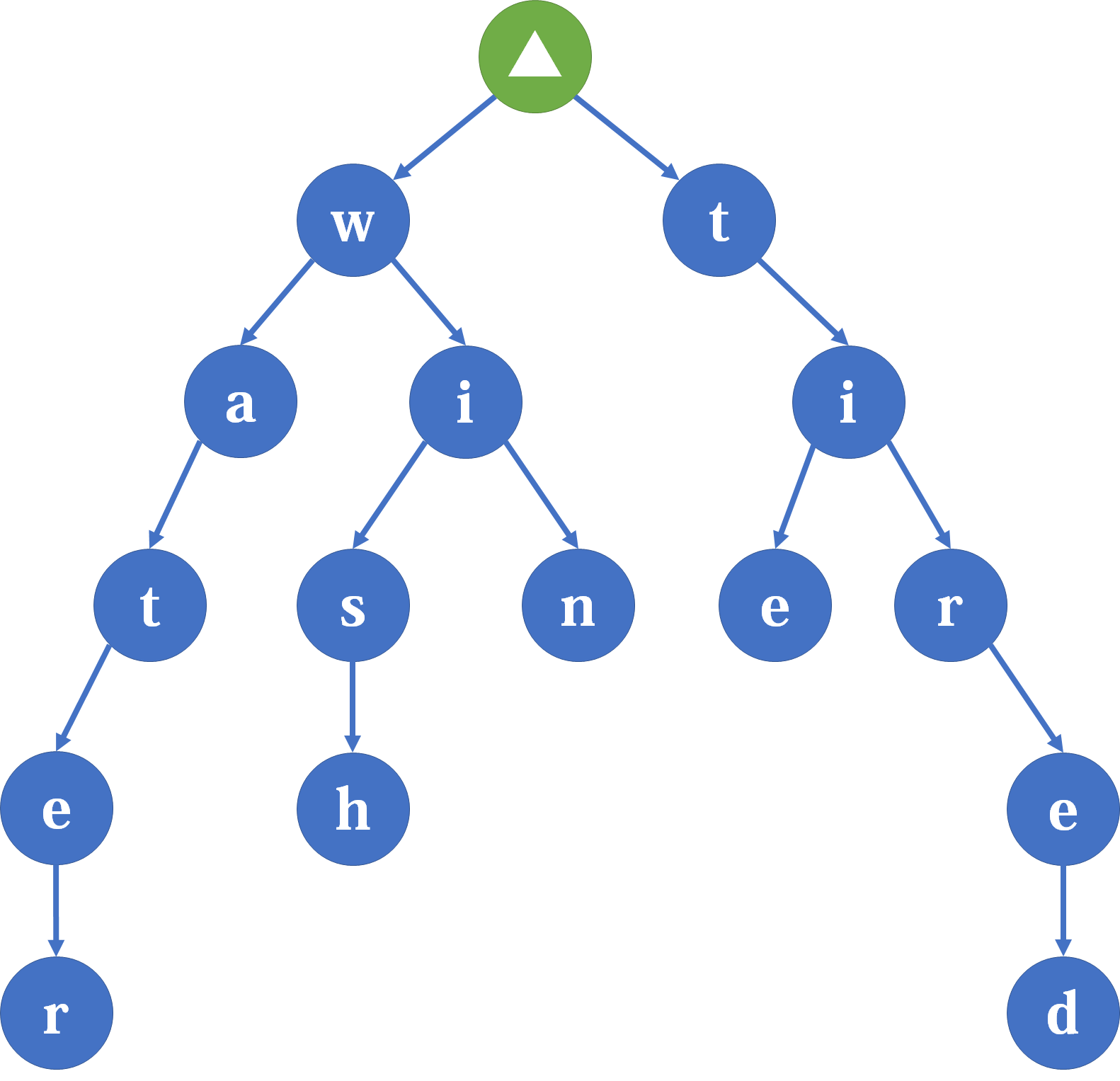
树上的一个节点就是一个字符,树上的一条链就是一个字符串。相同前缀的字符串共用一部分节点。
这样,我们牺牲了一部分空间,实现了 $O(n)$ 的查询。
3.2 实现
3.2.1 建树
考虑建树。用 nxt[i][j] 表示 $i$ 号点的儿子中,存储字符映射值为 $c$ 的节点编号。注意 $1$ 号点一般不放字符,代码如下:
int nxt[Maxn][27], cnt = 1;
void insert(string s) {
int u = 1;
for(int i = 0; i < s.size(); i++) {
int c = s[i] - 'a' + 1;
if(!nxt[u][c]) {//尽可能重复使用前缀,否则建立新节点
nxt[u][c] = ++cnt;
}
u = nxt[u][c];
}
}
3.2.2 查询
3.2.2.1 查询前缀
我们可以用字典树简单的查询到一个前缀是否存在。与建树代码比较相似:
bool find(string s) {
int u = 1;
for(int i = 0; i < s.size(); i++) {
int c = s[i] - 'a' + 1;
if(!nxt[u][c]) {
return 0;
}
u = nxt[u][c];
}
return 1;
}
3.2.2.2 查询字符串
如果要查询某个字符串是否出现,就不能够直接判断,因为可能出现一个字符串是另一个的前缀。
我们用一个 vis 数组。在插入操作完成时,把当前叶子结点的 vis 设为 $1$。查询完成后判断 vis 是否存在即可。
这是一个常见的套路,在 Trie 中用叶子结点代表整个字符串,来保存信息已完成要求。
3.2.3 模板
以 P8306 【模板】字典树 - 洛谷 为例。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int Maxn = 4e6 + 5;
int nxt[Maxn][65], cnt = 1, vis[Maxn];
void insert(string s) {
int u = 1;
for(int i = 0; i < s.size(); i++) {
int c;
if(s[i] >= '0' && s[i] <= '9') c = s[i] - '0' + 1;
if(s[i] >= 'A' && s[i] <= 'Z') c = s[i] - 'A' + 11;
if(s[i] >= 'a' && s[i] <= 'z') c = s[i] - 'a' + 38;
if(!nxt[u][c]) {
nxt[u][c] = ++cnt;
}
u = nxt[u][c];
vis[u] ++;
}
}
int find(string s) {
int u = 1;
for(int i = 0; i < s.size(); i++) {
int c;
if(s[i] >= '0' && s[i] <= '9') c = s[i] - '0' + 1;
if(s[i] >= 'A' && s[i] <= 'Z') c = s[i] - 'A' + 11;
if(s[i] >= 'a' && s[i] <= 'z') c = s[i] - 'a' + 38;
if(!nxt[u][c]) {
return 0;
}
u = nxt[u][c];
}
return vis[u];
}
int T;
int main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> T;
while(T--){
int n, q;
cin >> n >> q;
for(int i = 1; i <= cnt; i++) {//卡 memset 了
memset(nxt[i], 0, sizeof(nxt[i]));
vis[i] = 0;
}
cnt = 1;
for(int i = 1; i <= n; i++) {
string s;
cin >> s;
insert(s);
}
for(int i = 1; i <= q; i++) {
string t;
cin >> t;
cout << find(t) << '\n';
}
}
return 0;
}
3.3 0-1 Trie
3.3.1 概念
01-Trie,是一种用 Trie 来存储数字二进制的数据结构,常常被用来求解数字异或问题。
我们将原本 Trie 的字符集缩减为只有 ${0,1}$,将原先字符串变为一个个二进制数,以此来建树。这样我们得到的 Trie 树就叫做 01-Trie。
3.3.2 建树
建树与普通 Trie 没有什么区别,到位了做题方便,一般还用 num 来记录当前叶子结点所对应的数字(又是上面的小技巧)。
int nxt[Maxn][2], cnt = 1, num[Maxn];
void insert(int x) {
int u = 1;
for(int i = 30; i >= 0; i--) {//枚举可能的位数
int c = x >> i & 1;//取出 x 的第 i 位
if(!nxt[u][c]) {
nxt[u][c] = ++ cnt;
}
u = nxt[u][c];
}
num[u] = x;
}
3.3.3 具体应用及代码
3.3.3.1 最大异或对
以 The XOR Largest Pair 为例。
题目大意:在 $n$ 个数中选出两个数,使他们的异或和最大。
我们先建立 01-Trie,然后使用贪心求解。枚举当前的数 $a_i$,在树上走一条路径。由于要求异或和最大,所以要尽可能让当前位上的数与 $a_i$ 当前位上的数不一样,否则就只能走相同的了。
同时,依次为模板题,给出 01-Trie 代码:
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int Maxn = 2e5 + 5;
int nxt[Maxn][2], cnt = 1, num[Maxn];
void insert(int x) {
int u = 1;
for(int i = 30; i >= 0; i--) {//枚举可能的位数
int c = x >> i & 1;//取出 x 的第 i 位
if(!nxt[u][c]) {
nxt[u][c] = ++ cnt;
}
u = nxt[u][c];
}
num[u] = x;
}
int find(int x) {
int u = 1;
for(int i = 30; i >= 0; i--) {
int c = x >> i & 1;
if(nxt[u][c ^ 1]) {//尽量不同
u = nxt[u][c ^ 1];
}
else {
u = nxt[u][c];
}
}
return x ^ num[u];//返回异或值
}
int n, a[Maxn], ans;
int main() {
ios::sync_with_stdio(0);
cin >> n;
for(int i = 1; i <= n; i++) {
cin >> a[i];
insert(a[i]);
}
for(int i = 1; i <= n; i++) {
ans = max(ans, find(a[i]));//枚举取最大
}
cout << ans;
return 0;
}
3.3.3.2 最大异或路径
以 The XOR-longest Path 为例。
题目大意:给定一棵 $n$ 个点的带权树,求树上最长的异或和路径。
由于异或具有一个特点:$a\operatorname{xor}a=0$,所以,设 $t_i$ 为从根节点到点 $i$ 的异或和,那么对于树上两点 $A,B$,他们的路径异或和就是 $t_A\operatorname{xor}t_B$,因为 $t_{LCA}$ 部分被算了两次,抵消了。
而此时我们再看,在 $n$ 个结点的 $t_i$ 中,选出两个数的最大异或和。这非常熟悉,实际上就是 3.3.3.1 的情况。
代码:
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int Maxn = 2e6 + 5;
int n;
int head[Maxn], edgenum;
struct node{
int nxt, to, w;
}edge[Maxn];
void add_edge(int from, int to, int w) {
edge[++edgenum].nxt = head[from];
edge[edgenum].to = to;
edge[edgenum].w = w;
head[from] = edgenum;
}
int t[Maxn];
void dfs(int x, int fa, int val) {
t[x] = t[fa] ^ val;
for(int i = head[x]; i; i = edge[i].nxt) {
int to = edge[i].to;
if(to == fa) continue;
dfs(to, x, edge[i].w);
}
}
int nxt[Maxn][2], cnt = 1, num[Maxn];
void insert(int x) {
int u = 1;
for(int i = 30; i >= 0; i--) {
int c = x >> i & 1;
if(!nxt[u][c]) {
nxt[u][c] = ++cnt;
}
u = nxt[u][c];
}
num[u] = x;
}
int find(int x) {
int u = 1;
for(int i = 30; i >= 0; i--) {
int c = x >> i & 1;
if(nxt[u][c ^ 1]) {
u = nxt[u][c ^ 1];
}
else {
u = nxt[u][c];
}
}
return x ^ num[u];
}
int ans = 0;
int main() {
ios::sync_with_stdio(0);
cin >> n;
for(int i = 1; i < n; i++) {
int u, v, w;
cin >> u >> v >> w;
add_edge(u, v, w);
add_edge(v, u, w);
}
dfs(1, 0, 0);
for(int i = 1; i <= n; i++) {
insert(t[i]);
}
for(int i = 1; i <= n; i++) {
ans = max(ans, find(t[i]));
}
cout << ans;
return 0;
}
4 AC 自动机
4.1 概念
有一句著名的话:
AC 自动机 = Trie + KMP
详细一点讲, AC 自动机就是以 Trie 的结构为基础,结合 KMP 的思想建立的自动机,主要用于解决多模式匹配等任务。
4.2 结构及过程
4.2.1 Trie 构建
AC 自动机的第一步很简单:构建以所有模式串组成的 Trie,然后在这个 Trie 上构建 AC 自动机。
我们有必要来解释一下 Trie 上节点的含义,Trie 中的一个节点表示一个模式串的前缀,我们在后文也称之为状态。一个节点表示一个状态,字典树上的边表示状态的转移。
我们把这个 Trie 的所有状态的集合记作 $Q$。
4.2.2 失配指针
这里将会体现出 KMP 的思想。AC 自动机利用 fail 指针来辅助多模匹配。
状态 $u$ 的 fail 指针指向另一个状态 $v$,其中 $v\in Q$,并且 $v$ 是 $u$ 的最长后缀。
附:KMP 中 nxt 指针与 AC 自动机 fail 指针的异同:
- 共同点:两者都是失配时用来快速跳转的指针。
- 不同点:nxt 求的是最长公共前后缀,而 fail 指针指向模式串中的最长后缀。
这就是失配指针的含义。
4.2.2.1 求解失配指针
我们考虑一下构建 fail 指针的基础思想。
我们考虑一个 Trie 中一个节点 $u$,它的父节点为 $p$,$p$ 通过字符 c 的边指向 $u$。也就是 $t[p,c]=u$。接下来我们考虑求解 $fail[u]$。
- 如果 $t[fail[p],c]$ 存在,则让 $fail[u]$ 指向 $t[fail[p],c]$。相当于在状态 $p$ 和 $fail[p]$ 后面加上一个字符
c,分别对应 $u$ 和 $fail[u]$。 - 如果 $t[fail[p],c]$ 不存在,那么我们继续找 $t[fail[fail[p]],c]$。然后重复 1 的判断过程,知道根节点为止。
4.2.2.2 例子
直接摘取 OI-wiki 上的例子 (其实这一部分全是抄 OI-wiki 上的)。
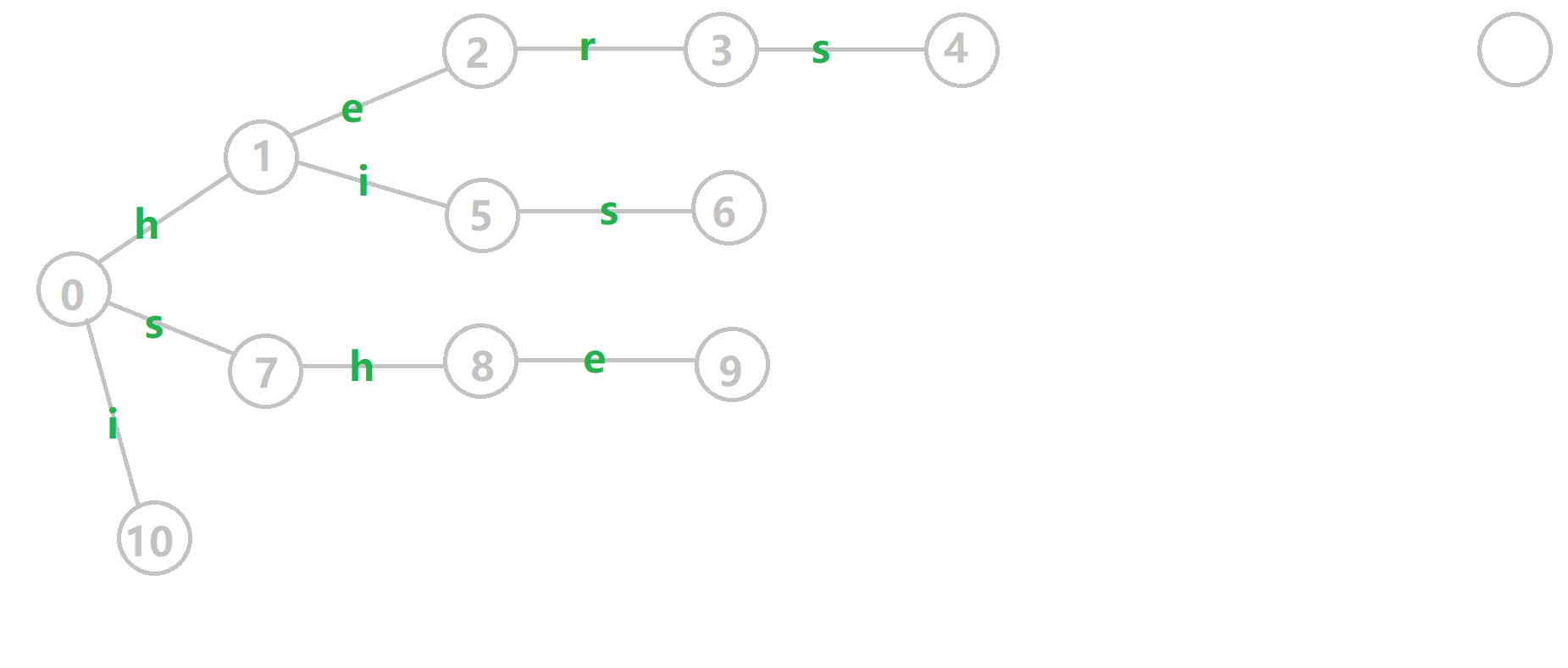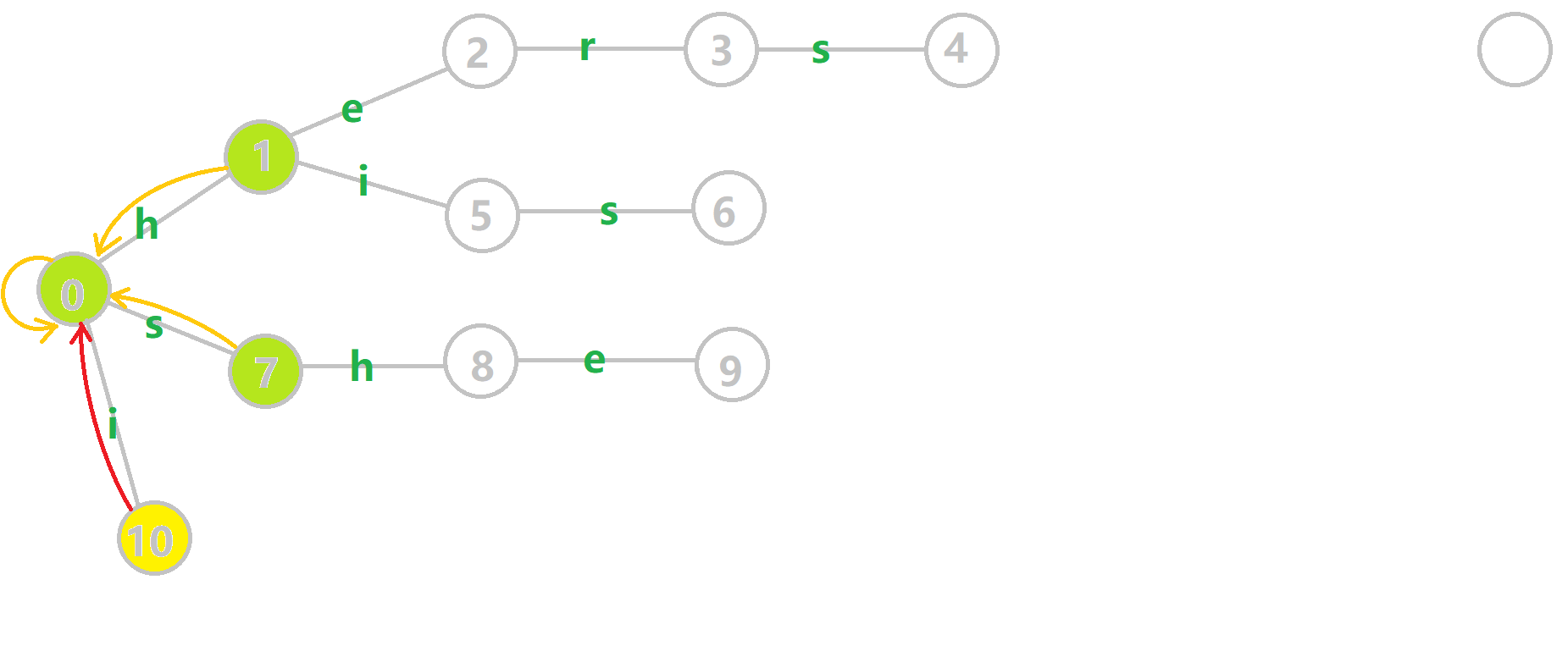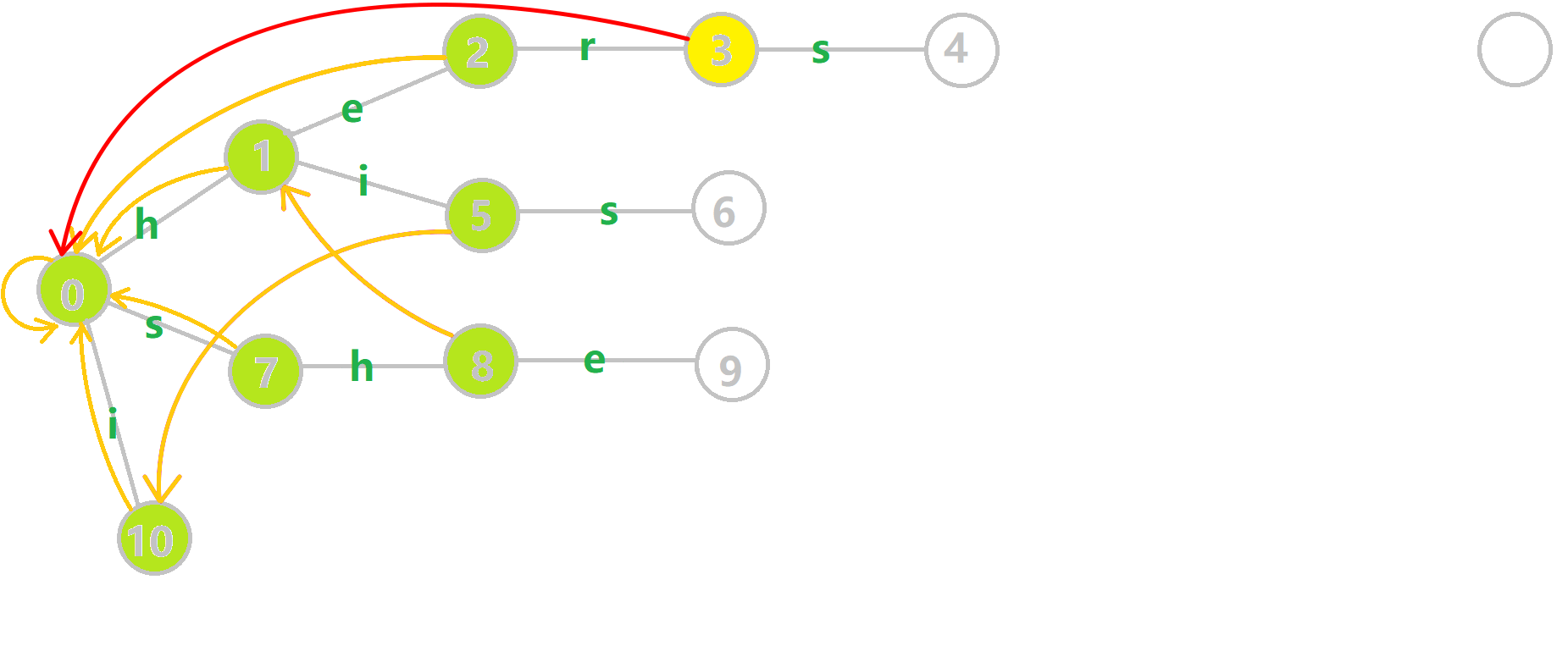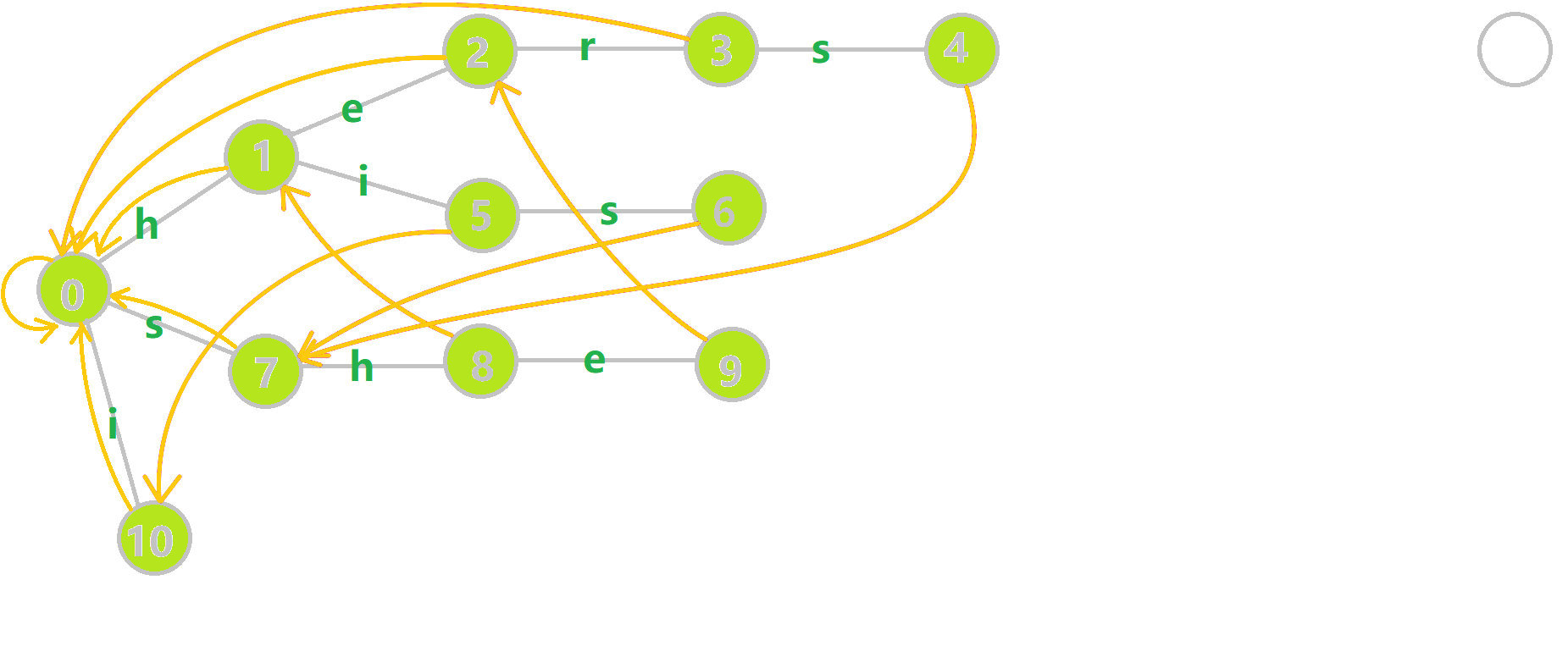
其中橙色的边就是 fail 指针。
我们来看节点 6 的 fail 指针的求解过程:
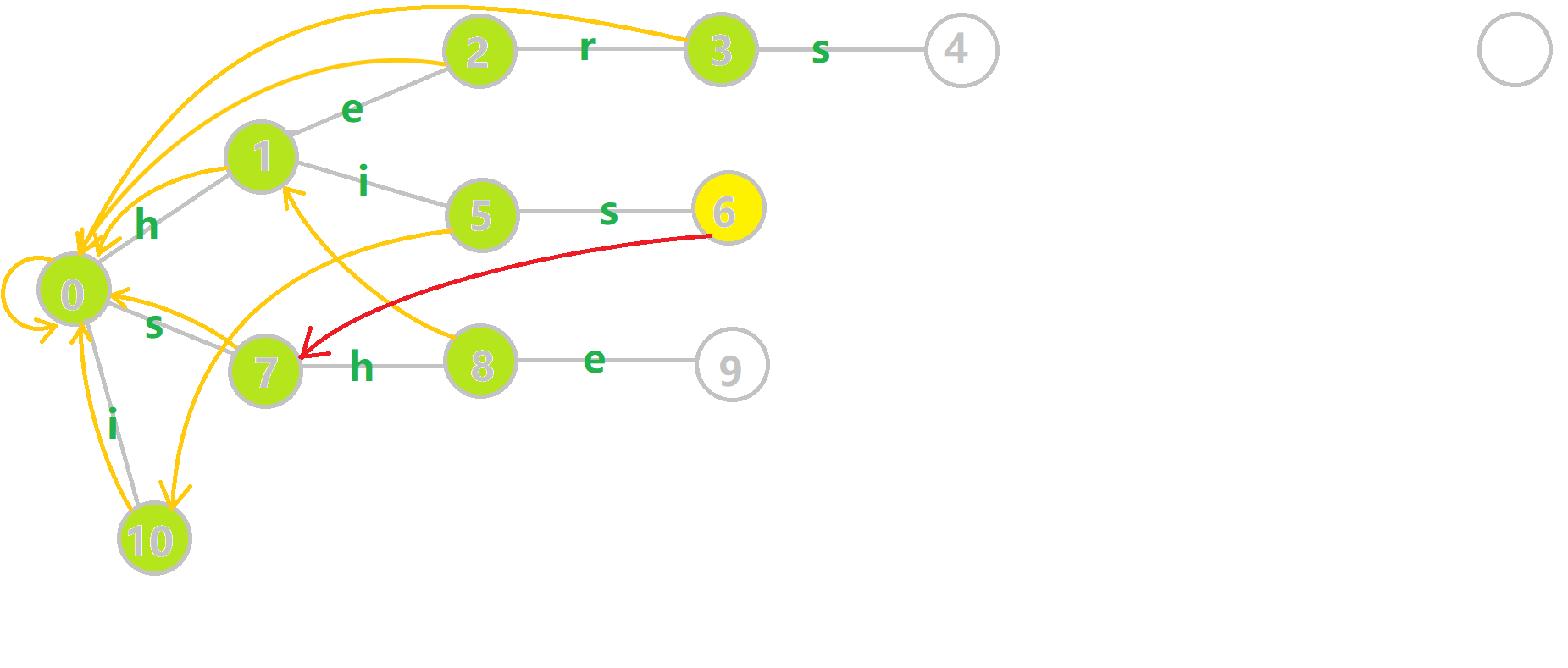
找到 6 的父节点 5,$fail[5]=10$,然而 10 节点没有 s 连出的边;继续跳转到 10 的 fail 指针,$fail[10]=0$。发现 0 节点有 s 连出的边,指向 7。因此最后求出 $fail[6]$ 为 7。
最终的图:
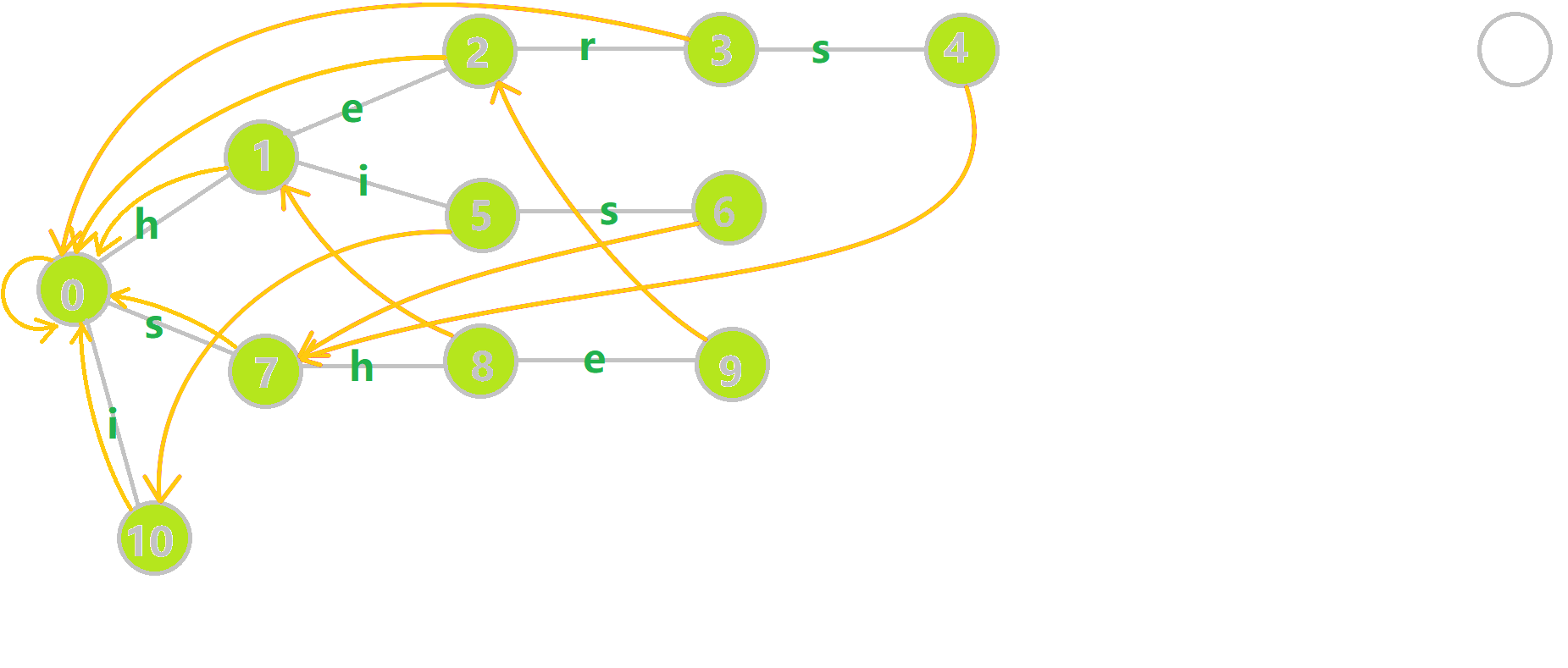
4.2.3 字典树和字典图
我们先来看代码:
void insert() {
//...
}
void build() {
for(int i = 0; i < 26; i++) {
if(tr[0][i]) {
q.push(tr[0][i]);
}
}
while(q.size()) {
int u = q.front();
q.pop();
for(int i = 0; i < 26; i++) {
if(tr[u][i]) {
fail[tr[u][i]] = tr[fail[u]][i];
q.push(tr[u][i]);
}
else {
tr[u][i] = tr[fail[u]][i];
}
}
}
}
我们下面将以这种方式来理解 tr[u,c]:将它看做一种状态转移的函数。
4.2.3.1 代码解释
我们现将根节点的的出边入队,然后 BFS 求解 fail。
我们现将根节点的儿子入队,然后开始 BFS。每次取出队首节点 $u$,然后遍历字符集:
- 如果 $tr[u][i]$ 存在,就将 $tr[u][i]$ 的 fail 指针指向 $tr[fail[u],i]$。这里似乎似乎有一个问题:按照 4.2.2.1 的讲解,我们应该不断跳 fail 指针,然后赋值;只这要牵扯到下面的
else,即字典图的建立。 - 否则,将 $tr[u,i]$ 指向 $tr[fail[u],i]$。
我们发现,按照 Trie 的函数定义,这一步其实就修改了原本 $tr[u,i]$ 函数的应有结果。也就是说,我们通过一行代码,修改了字典树的结构!
我们来仔细剖析一下:$tr[S,c]$ 相当于在 $S$ 后添加字符 $c$ 变成另一个状态 $S'$。如果 $S'$ 存在,说明有一个模式串的前缀为 $S'$。
否则我们让 $tr[S,c]$ 指向 $tr[fail[S],c]$。由于 $fail[S]$ 对应的字符串是 $S$ 的后缀,因此 $fail[S]$ 对应的字符串也是 $S'$ 的后缀。
换言之,我们在 Trie 上跳转时,我们只会从 $S$ 转移到 $S'$,相当于匹配了一个 $S'$;但在 AC 自动机上跳转时,我们会从 $S$ 跳转到 $S'$ 的后缀。
也就是说我们匹配一个字符 c,然后舍弃 $S$ 部分前缀,舍弃掉前缀当然也是能匹配到的。
那么 fail 指针呢?他其实也是在舍弃前缀!试想一下:如果文本串能匹配 $S$,他显然也能匹配 $S$ 的后缀。因此所谓 fail 指针 其实就是 $S$ 的一个后缀集合。
tr 数组还有一个更简单的理解方式:如果在位置 $u$ 失配,我们会跳转到 $fail[u]$。所以我们可能沿着 fail 数组跳转多次才能来到下一个匹配位置。我们就可以用 tr 数组来直接记录下一个能匹配的位置,以节省时间。
(以上是 OI-wiki 上的原汁原味的解释,我觉得有些过于晦涩,有一个相当简单但不太严谨的证明:)
我们来看一张例图:
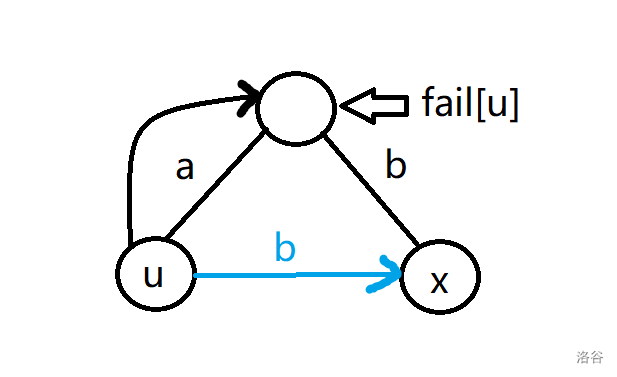
在原来的 fail 跳转中,我们在求 fail 的时候,会先跳到 $fail[u]$,然后看到 $tr[fail[u],b]=x$,并赋值。
然后我们按照新代码的过程,就会有一条蓝色的边,从 $u$ 转移为 $x$。那么在转移的时候,原来的两条黑边被简化为一条蓝边。这或许没有什么意义,但试想:如果中间有相当多的黑边呢?
说了这么多,其实就是一句话:我们通过修改 Trie 的结构,使得它将反复跳 fail 的过程进行了路径压缩,让原本的 while 循环变成了跳一次即可。
所以,字典图的建立完成了两件事:fail 指针构建和字典图的建立。
放上一张最后的字典图:
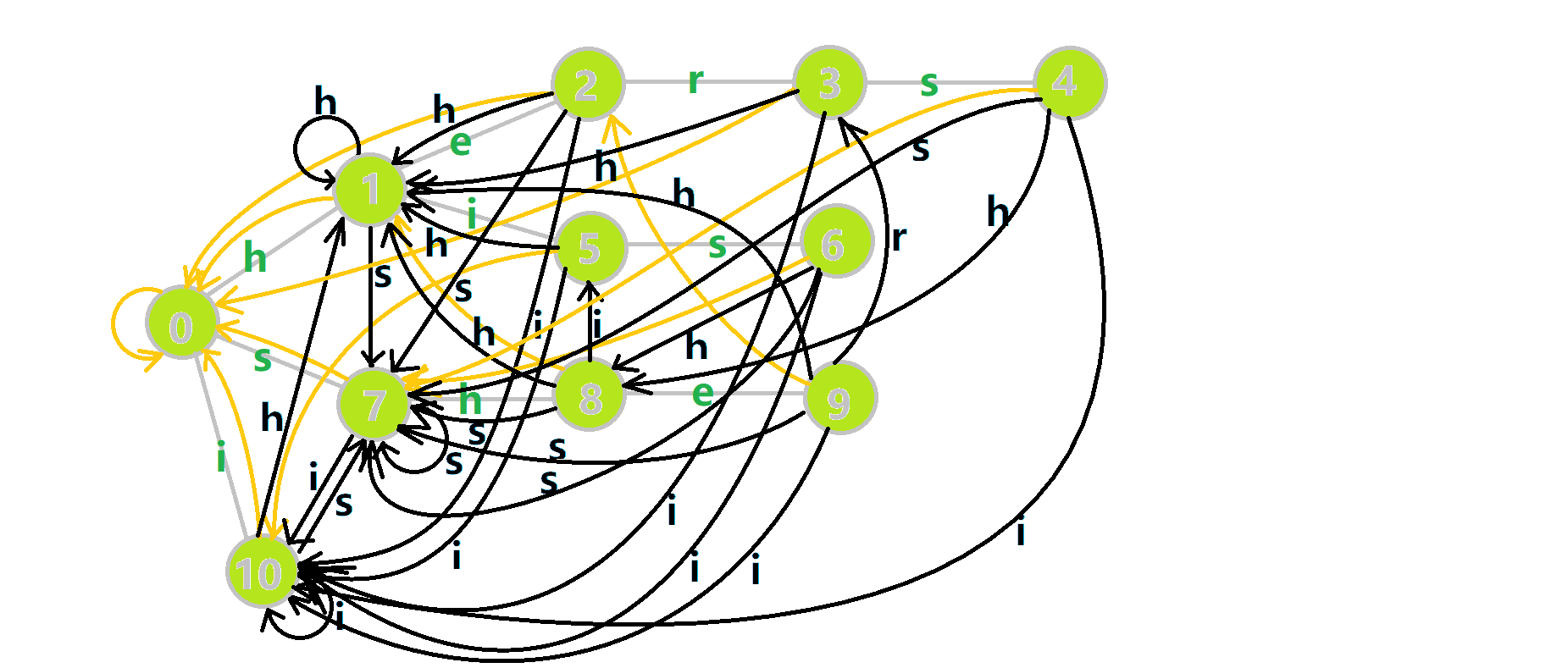
4.2.4 多模匹配
我们还是先看代码:
int query(string t) {
int u = 0, res = 0;
for(int i = 0; i < t.size(); i++) {
u = tr[u][t[i] - 'a'];
for(int j = u; j && e[j] != -1; j = fail[j]) {
res += e[j];
e[j] = -1;
}
}
return res;
}
在代码中,$u$ 作为 Trie 上当前匹配到的节点,res 即为答案。而 e[i] 根据实际情况不同,含义不同。
为了避免重复计算,再算完一遍 $i$ 后就将 $e[i]$ 标记为 $-1$。
我们来分析一下:如果一个模式串匹配成功,那么它的 fail 也一定匹配成功,而 fail 的 fail 也会匹配成功(因为都是后缀),所以我们暴力跳,然后累加答案即可。
以上面的自动机为例,匹配 ushersheishis 的跳转过程:
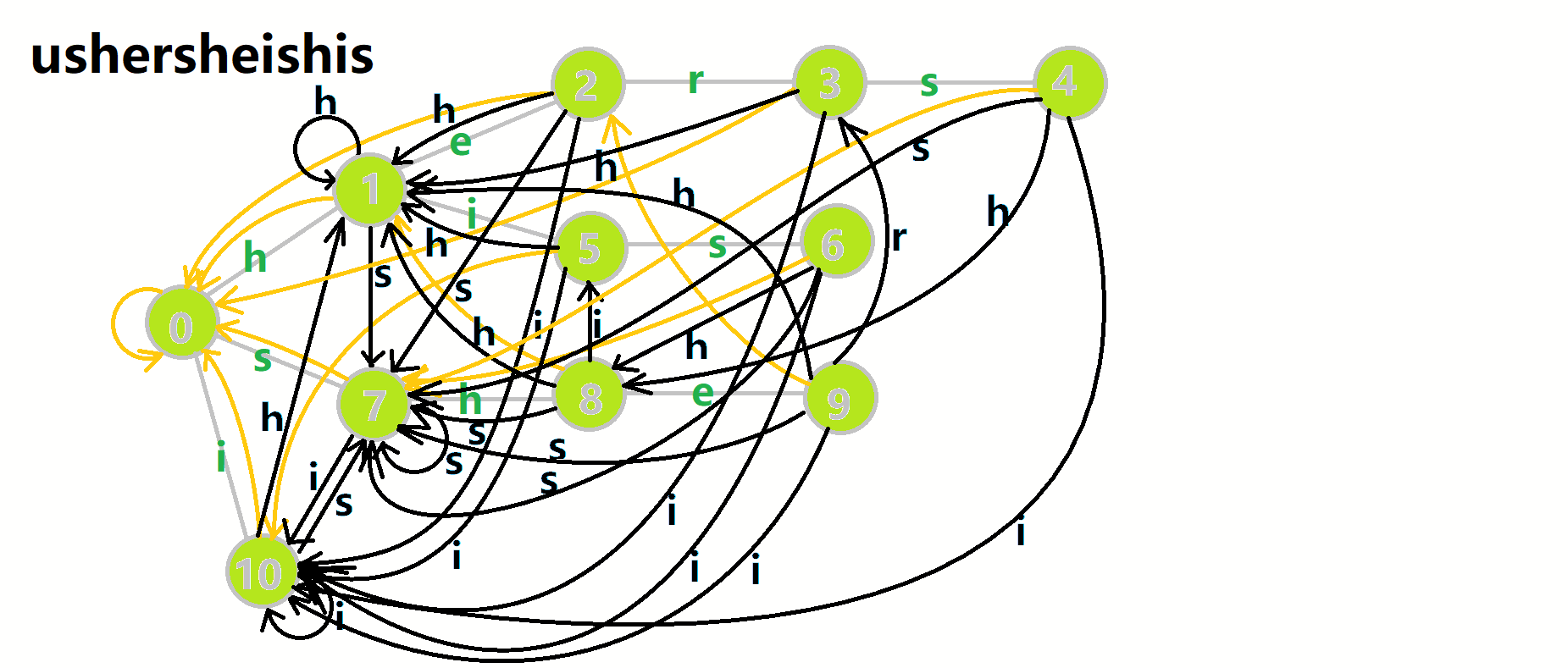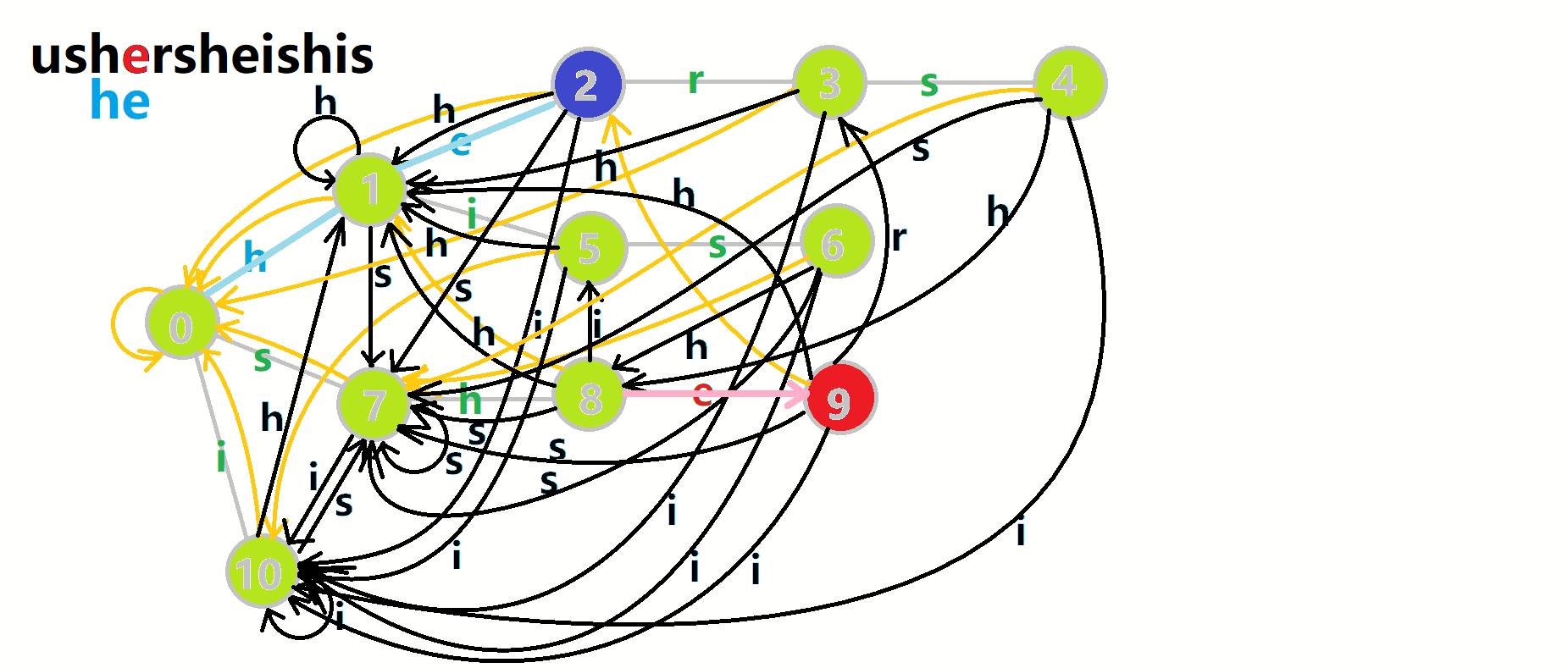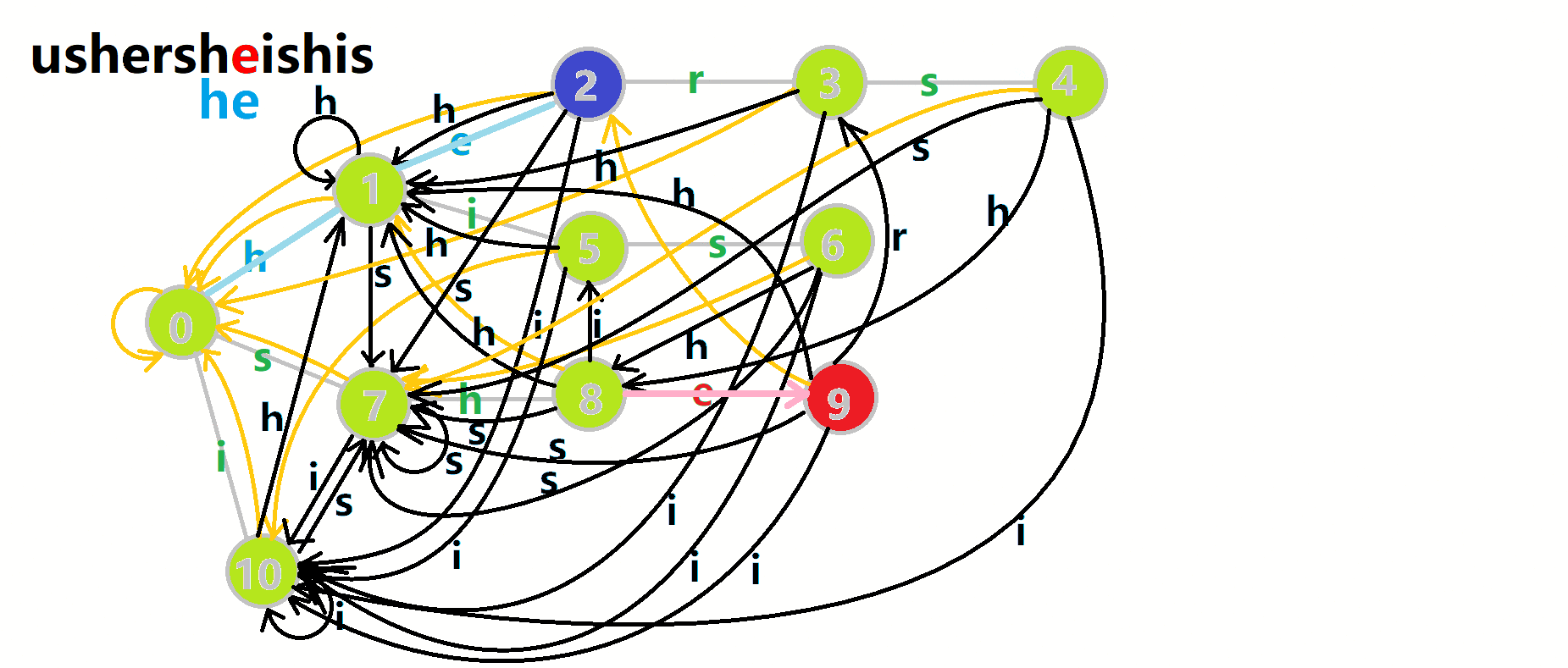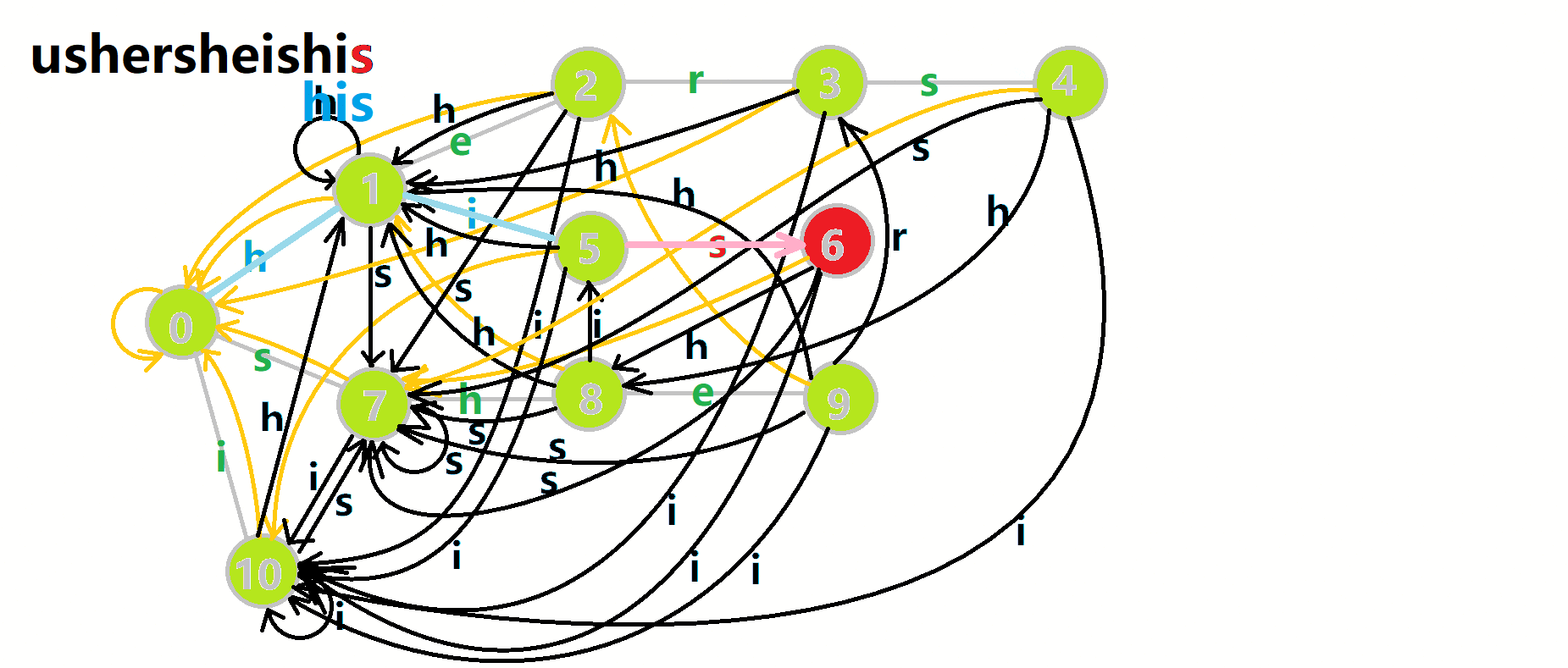
4.2.4.1 效率优化
在上述代码中会有一个问题,使得我们无法通过二次加强的模板题。我们匹配时是不断的跳 fail,fail 的 fail……
这样会使得效率较低,导致 T 掉。
我们先来了解一个性质:所有 fail 指针构成的图是一颗树。
于是,我们匹配的问题就可以转化为在 fail 树上的链求和问题。
有两个方法解决这个问题:拓扑排序优化建图、预处理子树求和。
4.3 代码
以 P3808 【模板】AC 自动机(简单版) 为例,模板代码如下:
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int Maxn = 2e6 + 5;
int n;
string t[Maxn], s;
int tr[Maxn][30], cnt = 1;
int e[Maxn];
void insert(string p) {
int u = 0;
for(int i = 0; i < p.size(); i++) {
int c = p[i] - 'a' + 1;
if(!tr[u][c]) {
tr[u][c] = ++ cnt;
}
u = tr[u][c];
}
e[u]++;//e[i] 表示以 i 节点作为结尾的模式串数量
}
int fail[Maxn];
queue <int> q;
void build() {
for(int i = 1; i <= 26; i++) {
if(tr[0][i]) {
q.push(tr[0][i]);
}
}
while(!q.empty()) {
int u = q.front();
q.pop();
for(int i = 1; i <= 26; i++) {
if(tr[u][i]) {
fail[tr[u][i]] = tr[fail[u]][i];
q.push(tr[u][i]);
}
else {
tr[u][i] = tr[fail[u]][i];
}
}
}
}
int solve(string s) {
int u = 0, res = 0;
for(int i = 0; i < s.size(); i++) {
u = tr[u][s[i] - 'a' + 1];
for(int j = u; j && e[j] != -1; j = fail[j]) {
res += e[j];
e[j] = -1;
}
}
return res;
}
int main() {
ios::sync_with_stdio(0);
cin >> n;
for(int i = 1; i <= n; i++) {
cin >> t[i];
insert(t[i]);
}
build();
cin >> s;
cout << solve(s);
return 0;
}