网上一大堆教程,好多讲的很墨迹,你需要折腾半天才能调试通,up 这里给大家直接上源码干货。
详细教程后面补充,着急使用的可以直接拿走调试
说明
- 到 openai 里面替换你自己的app_key
- https://platform.openai.com/ 登录账号
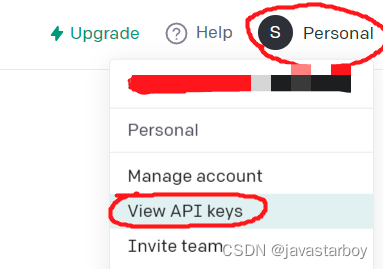
- 登录之后,点击右上角“Personal”,展开菜单,找到“View API keys”
chat_gpt_key = '你的api_key'
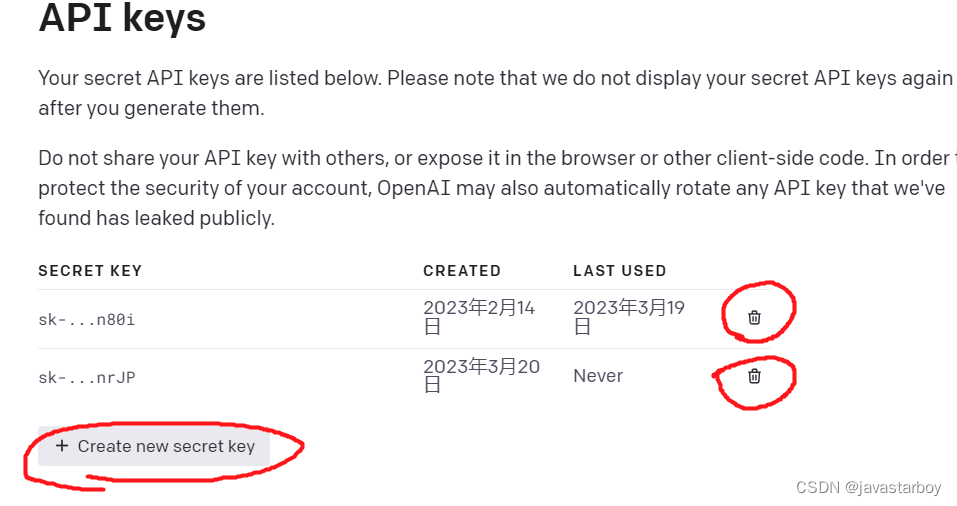
- 然后创建一个 key
- 我目前使用的是免费版的最新模型
MODEL = "gpt-3.5-turbo-0301",不建议使用老模型,因为 gpt4 都出了,其余那些模型即将淘汰 - gpt4 模型后续补充,可以关注一下,第一时间拿到代码
- 网络
源码
直接放入你的 python 工程,引入包,然后运行即可
# 引入 openai 依赖
pip install openai
# 引入 token 计数依赖,如果不想计数,也可以不引用,注释掉num_tokens_from_messages()的代码即可
pip install tiktoken- 1
- 2
- 3
- 4
import openai
import tiktoken
# 你的 api_key
chat_gpt_key = '你的api_key'
# 将 Key 传入 openai
openai.api_key = chat_gpt_key
# 模型
MODEL = "gpt-3.5-turbo-0301"
ROLE_USER = "user"
ROLE_SYSTEM = "system"
ROLE_ASSISTANT = "assistant"
"""
聊天信息(要记录历史信息,因为 AI 需要根据角色【user、system、assistant】上下文理解并做出合理反馈)
对话内容示例
messages = [
{"role": "system", "content": "你是一个翻译家"},
{"role": "user", "content": "将我发你的英文句子翻译成中文,你不需要理解内容的含义作出回答。"},
{"role": "assistant", "content": "Draft an email or other piece of writing."}
]
"""
messages = []
# 调用 chatgpt 接口
def completion(prompt):
"""
API:https://api.openai.com/v1/chat/completions
官方文档:https://platform.openai.com/docs/api-reference/chat
:param prompt: 入参文本框
:return: 助手回答结果
"""
response = openai.ChatCompletion.create(
# 模型,如 gpt-3.5-turbo
model=MODEL,
messages=prompt
)
message = response.choices[0].message.content
# print(response.choices)
dealMsg(ROLE_ASSISTANT, message, '2')
return message
"""
计算文本字符串中有多少个 token.
非常长的对话更有可能收到不完整的回复。
例如,一个长度为 4090 个 token 的 gpt-3.5-turbo 对话将在只回复了 6 个 token 后被截断。
"""
def num_tokens_from_messages(infoMsg, model):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model.startswith("gpt-3.5-turbo"): # 注意: 未来的模型可能会偏离这个规则
num_tokens = 0
for message in infoMsg:
num_tokens += 4
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # 如果有名字,角色将被省略
num_tokens += -1 # Role总是必需的,并且总是1个令牌
num_tokens += 2 # 每个回复都用assistant启动
return num_tokens
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not presently implemented for model {model}.
See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
"""
:param role: 角色【system,user,assistant】
:param msg: 聊天信息
:param type: 统计 token 环节【1-用户信息,2-助手信息】
"""
totalCount = 0
def dealMsg(role, msg, types):
global totalCount
if len(messages) == 0:
if msg == "":
# system 默认角色
msg = "你是一个聊天助手与我聊天,回答我,你是什么角色?"
else:
msg = "假设你是" + msg
messages.append({"role": role, "content": msg})
# message = [{"role": role, "content": msg}]
# message = [{"role": ROLE_SYSTEM, "content": "你是一个陪我聊天的助手"}]
# 转换输入的信息为数组格式并打印 token 数
if types == "1":
typeMsg = "input"
else:
typeMsg = "output"
# 计费:计算耗费的 token 数
count = num_tokens_from_messages(messages, MODEL)
totalCount += count
print(f"{count}{typeMsg} prompt tokens counted. all tokens cost {totalCount}")
# 历史消息
# messageHisList.insert(0, messages)
return messages
# 运行业务代码
print("[AI|:]" + completion(dealMsg(ROLE_SYSTEM, input("请先设定 AI 的角色(如:一名音乐家)|: "), '1')))
print("[AI|:]" + completion(dealMsg(ROLE_USER, input("[You|:]"), "1")))
goOn = True
while goOn:
inputText = input("[You|:]")
if inputText.replace('\n', '').replace('\r', '') == "stop":
goOn = False
print("完整对话记录如下:" + str(messages))
break
else:
print(f"[AI|:]{completion(dealMsg(ROLE_USER, inputText, '1'))}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115