锁
【一】同步原语
- 操作系统—同步原语-CSDN博客
- 实现互斥锁的并发程序设计-皮特森算法【Peterson算法 - 维基百科】
同步原语是一组用于协调多个执行线程或进程之间操作顺序和共享资源访问的基本机制。这些机制的目的是确保多个执行单元能够按照某种协调方式执行,以避免并发操作导致的问题,如竞争条件、死锁和数据不一致性。
常见的同步原语包括:
- 锁(Lock): 锁是一种基本的同步原语,用于控制对共享资源的访问。只有一个线程或进程能够持有锁,其他请求锁的线程或进程需要等待。锁可以防止并发访问导致的数据不一致和竞争条件。
- 条件变量(Condition): 条件变量是一种高级同步原语,用于在多个线程之间进行复杂的协调。它允许线程等待某个条件为真时被通知,从而实现线程之间的协同操作。
- 信号量(Semaphore): 信号量是一种计数同步原语,用于控制同时访问共享资源的数量。信号量维护一个计数器,线程或进程在访问资源前需要获取信号量,每次获取会将计数器减一,释放时会将计数器加一。
- 互斥量(Mutex): 互斥量是一种用于提供互斥访问的同步原语。它类似于锁,但更常用于操作系统层面,用于确保临界区的互斥访问。
- 屏障(Barrier): 屏障是一种同步原语,用于确保多个线程或进程在某个点上汇合,然后同时执行后续操作。屏障可以用于协调多个执行单元的同步点。
这些同步原语为并发编程提供了基础的工具,帮助开发者管理线程或进程之间的协调和竞争条件,确保程序的正确执行。不同的同步原语适用于不同的场景和需求。
【二】锁
锁用于控制对共享资源的访问,以确保在同一时刻只有一个线程或进程能够访问该资源。锁有两种状态:锁定(locked)和未锁定(unlocked)。
在获取锁之前,线程或进程必须先请求锁,并且只有在锁处于未锁定状态时才能成功获取锁。
如果锁已被其他线程或进程持有,请求锁的线程或进程将被阻塞,直到锁被释放。
锁的基本操作包括:
acquire(blocking=True, timeout=None):- 作用:尝试获取锁。如果锁处于未锁定状态,则将其锁定并返回 True;如果锁已被其他线程或进程持有,根据
blocking和timeout参数的设置,决定是阻塞等待锁的释放还是立即返回失败。
- 作用:尝试获取锁。如果锁处于未锁定状态,则将其锁定并返回 True;如果锁已被其他线程或进程持有,根据
release():- 作用:释放锁,将其状态设置为未锁定。如果有其他线程或进程在等待锁,其中一个将被唤醒并成功获取锁。
锁的使用场景主要是在多线程或多进程并发操作时,确保对共享资源的访问是线程安全的,防止出现竞争条件(Race Condition)和数据不一致等问题。
- 锁的目的是保护了数据的安全,但同时一定会带来执行效率降低和消耗时间增加的问题
【1】并发编程中锁的种类
在并发编程中,存在不同种类的锁,每种锁都有其特定的用途和适用场景。以下是一些常见的锁的种类:
- 互斥锁(Mutex): 互斥锁是最基本的锁类型,它确保在任何时刻只有一个线程能够持有锁。互斥锁用于防止多个线程同时访问共享资源,从而避免竞争条件。在 Python 中,
threading.Lock和multiprocessing.Lock都是互斥锁的实现。 - 递归锁(Recursive Lock): 递归锁允许同一线程在多次请求锁时不被阻塞,以避免死锁。如果一个线程已经获得了递归锁,它可以多次调用
acquire而不被阻塞,每次调用都需要相应的release操作。在 Python 中,threading.RLock和multiprocessing.RLock实现了递归锁。 - 条件变量锁(Condition Lock): 条件变量锁结合了锁和条件变量的功能。它用于在多个线程之间进行复杂的协调,允许线程等待某个条件为真时被通知。在 Python 中,
threading.Condition和multiprocessing.Condition提供了条件变量锁的实现。 - 信号量(Semaphore): 信号量是一种计数锁,用于控制同时访问共享资源的数量。信号量维护一个计数器,每次成功获取锁时,计数器减一;释放锁时,计数器加一。在 Python 中,
threading.Semaphore和multiprocessing.Semaphore实现了信号量。 - 事件锁(Event Lock): 事件锁是一种用于线程间通信的同步原语。它允许一个线程发出信号,而其他线程等待这个信号。在 Python 中,
threading.Event和multiprocessing.Event是事件锁的实现。
这些锁的选择取决于并发编程的具体需求,不同的场景可能需要不同类型的锁。例如,互斥锁用于防止多线程或多进程同时访问共享资源,而条件变量锁适用于实现复杂的线程协调。
【2】互斥锁
【2.1】进程锁
- 通过
mutiprocessing.Lock实现
import os
import time
from multiprocessing import Process, Lock
def task(lock):
# 为进程加锁
lock.acquire()
print(f"{os.getpid()} 正在执行任务")
time.sleep(0.1)
print(f"{os.getpid()} 任务执行完毕")
# 释放锁
# 只有释放了锁,下一个进程才可以拿到锁并执行任务
lock.release()
if __name__ == '__main__':
# 声明锁对象
lock = Lock()
# 生成五个进程
p_list = [Process(target=task, args=(lock,)) for i in range(3)]
'''等价于
for i in range(3):
p = Process(target=task,args=(lock,))
p_list.append(p)
'''
[p.start() for p in p_list] # 启动任务
[p.join() for p in p_list] # 等待任务结束
print("主进程结束!")
# 9612 正在执行任务
# 9612 任务执行完毕
# 19452 正在执行任务
# 19452 任务执行完毕
# 19112 正在执行任务
# 19112 任务执行完毕
# 主进程结束!
- 如果不加锁

【2.2】线程锁
- 与进程锁的使用方式完全一致
import os
import time
from threading import Thread, Lock
def task(lock):
# 为进程加锁
lock.acquire()
print(f"{os.getpid()} 正在执行任务")
time.sleep(0.1)
print(f"{os.getpid()} 任务执行完毕")
# 释放锁
# 只有释放了锁,下一个进程才可以拿到锁并执行任务
lock.release()
if __name__ == '__main__':
# 声明锁对象
lock = Lock()
# 生成五个进程
p_list = [Thread(target=task, args=(lock,)) for i in range(3)]
'''等价于
for i in range(3):
p = Thread(target=task,args=(lock,))
p_list.append(p)
'''
[p.start() for p in p_list] # 启动任务
[p.join() for p in p_list] # 等待任务结束
print("主进程结束!")
# 9612 正在执行任务
# 9612 任务执行完毕
# 19452 正在执行任务
# 19452 任务执行完毕
# 19112 正在执行任务
# 19112 任务执行完毕
# 主进程结束!
【2.3】互斥锁解决文件资源抢夺
- 资源被抢夺就无法保证数据能够正常的读写
'''不加锁的情况'''
import json
import os
import time
from multiprocessing import Process
def buy_ticket(path):
# 获取票务信息
print("正在查询票务信息")
time.sleep(0.2) # 模拟延迟
data = read_data(path)
ticket_count = data.get("ticket")
print(f"当前剩余票数{ticket_count}")
if ticket_count <= 0:
print("票已售罄!")
else:
print(f"【{os.getpid()}】购票成功")
data["ticket"] -= 1
save_data(path, data)
def read_data(path):
# 读取文件
with open(path, mode='r', encoding='utf8') as fp:
data = json.load(fp)
return data
def save_data(path, data):
# 写入文件
with open(path, mode='w', encoding='utf8') as fp:
json.dump(data, fp, ensure_ascii=False)
if __name__ == '__main__':
# 读取当前文件夹下的1.json
path = os.path.join(os.path.dirname(__file__), '1.json')
# 初始化2张票
data = {"ticket": 2}
save_data(path, data)
# 假设有五个人买票
t_list = [Process(target=buy_ticket, args=(path,)) for i in range(5)]
[t.start() for t in t_list]
[t.join() for t in t_list]
print("已退出")
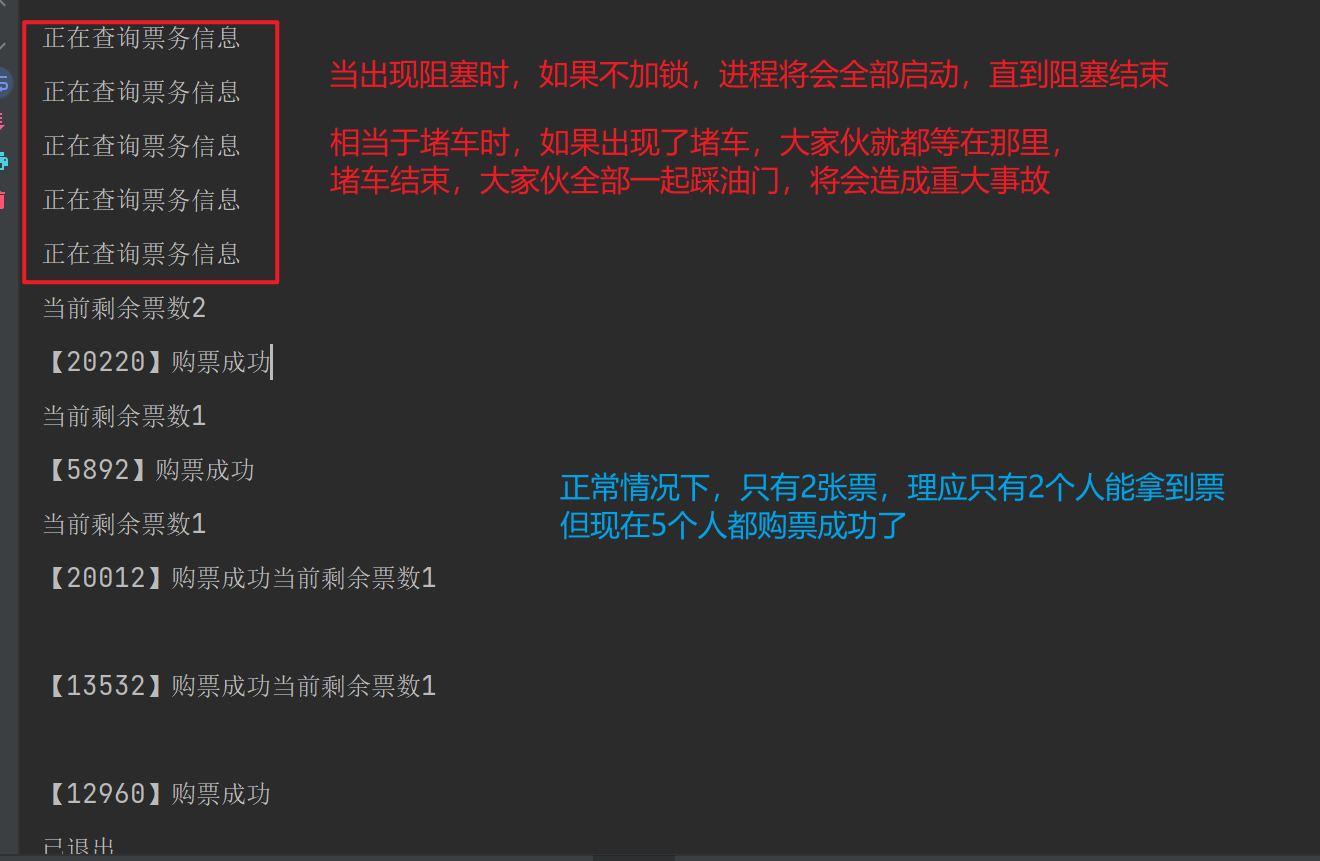
- 这是因为,进程20220跑的最快,它拿到了第一张票,还剩最后一张
- 而其余进程同一时刻启动,它们读取到的文件就是,票数还剩最后一张,所以对于它们自己而已,它们都拿到了最后一张票,这样是不对的
import json
import os
import time
from multiprocessing import Process, Lock
def buy_ticket(path,lock):
lock.acquire()
# 获取票务信息
print("正在查询票务信息")
time.sleep(0.2) # 模拟延迟
data = read_data(path)
ticket_count = data.get("ticket")
print(f"当前剩余票数{ticket_count}")
if ticket_count <= 0:
print("票已售罄!")
else:
print(f"【{os.getpid()}】购票成功")
data["ticket"] -= 1
save_data(path, data)
lock.release()
def read_data(path):
# 读取文件
with open(path, mode='r', encoding='utf8') as fp:
data = json.load(fp)
return data
def save_data(path, data):
# 写入文件
with open(path, mode='w', encoding='utf8') as fp:
json.dump(data, fp, ensure_ascii=False)
if __name__ == '__main__':
# 读取当前文件夹下的1.json
path = os.path.join(os.path.dirname(__file__), '1.json')
# 初始化2张票
data = {"ticket": 2}
save_data(path, data)
# 声明锁对象
lock = Lock()
# 假设有五个人买票
t_list = [Process(target=buy_ticket, args=(path,lock)) for i in range(5)]
[t.start() for t in t_list]
[t.join() for t in t_list]
print("已退出")
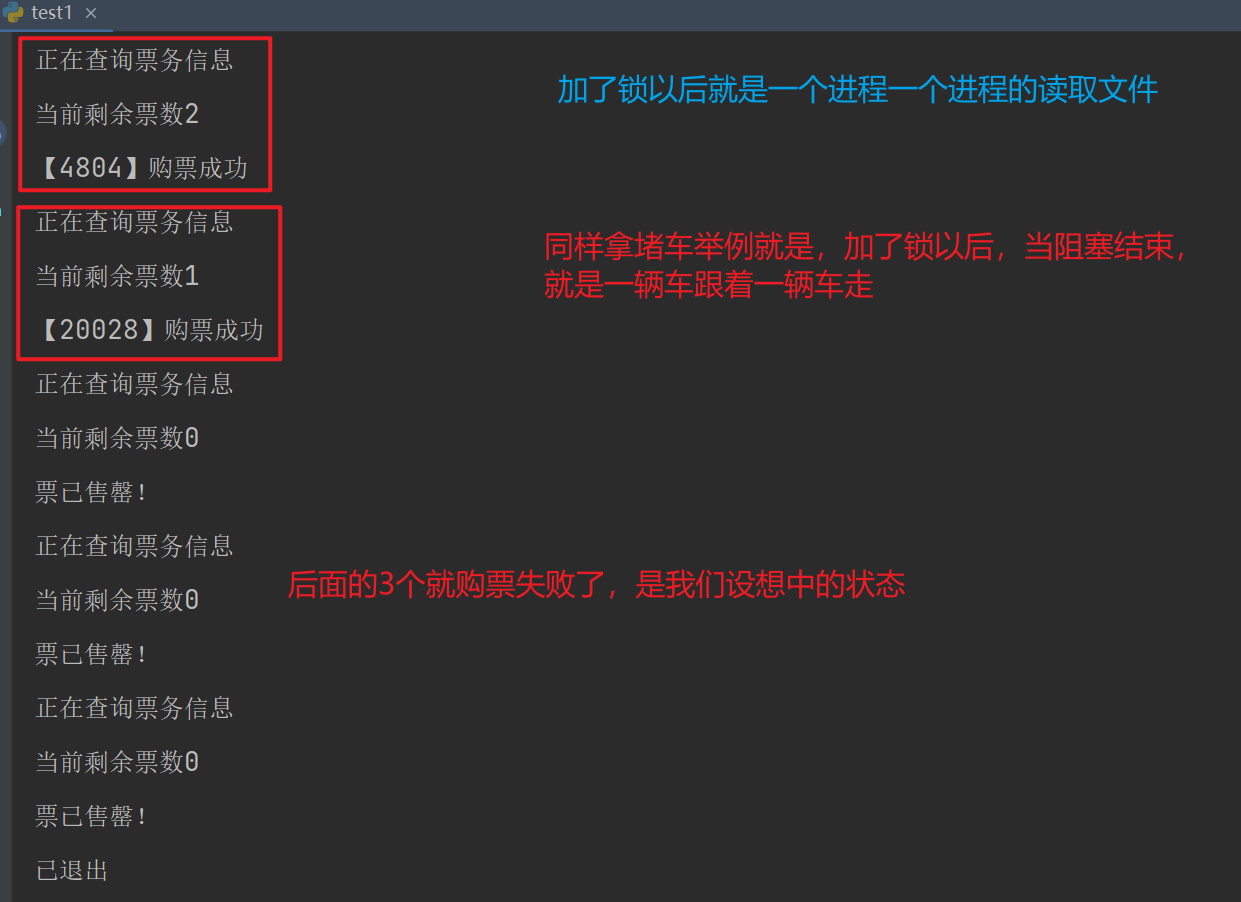
【3】死锁
from threading import Thread, Lock
import time
metexA = Lock()
metexB = Lock()
class MyThread(Thread):
def run(self):
# 每一个线程都走完两个函数
self.func1()
self.func2()
def func1(self):
metexA.acquire()
# self.name:获取当前线程名
print(f'{self.name} 抢到了A锁')
metexB.acquire()
print(f'{self.name} 抢到了B锁')
metexB.release()
metexA.release()
def func2(self):
metexB.acquire()
# self.name:获取当前线程名
print(f'{self.name} 抢到了A锁')
'''阻塞时,将会有下一个线程来拿到锁'''
# 而这时,就会尬住了,第二个线程拿到B锁却没释放,第三个线程就会卡住,后续的线程就都卡住了
time.sleep(2)
metexA.acquire()
print(f'{self.name} 抢到了B锁')
metexA.release()
metexB.release()
def main():
for i in range(10):
t = MyThread()
t.start()
if __name__ == '__main__':
main()
# Thread-1 抢到了A锁
# Thread-1 抢到了B锁
# Thread-1 抢到了A锁
# Thread-2 抢到了A锁
# 线程卡死
# 开启十个线程 第一个线程走完第一圈 回到原地抢 A 结果第二个线程已经拿到了A 导致AB卡死
-
死锁是在多个线程或进程之间发生的一种阻塞状态,其中每个线程或进程都在等待某个资源被释放,而这个资源却被其他线程或进程所持有,从而导致它们互相等待,无法继续执行。
-
死锁通常涉及两个或多个线程(或进程),每个都在等待另一个释放某个资源。这种循环等待的情况会导致程序无法继续执行,进而陷入死锁状态。死锁是并发编程中的一个严重问题,可以导致程序假死,无法正常运行。
【3.1】死锁发生的条件通常包括:
- 互斥条件: 一个资源每次只能被一个线程或进程持有。
- 占有且等待条件: 一个线程或进程在持有某个资源的同时又等待另一个资源。
- 不可抢占条件: 一个线程或进程持有某个资源时,其他线程或进程不能强行抢占该资源。
- 循环等待条件: 一组线程或进程形成一个循环,每个都在等待下一个线程或进程持有的资源。
【3.2】避免死锁的方法包括:
- 按顺序获取锁: 确保所有线程按照相同的顺序获取锁,避免循环等待的发生。
- 使用超时机制: 设置获取锁的超时时间,如果超时仍未获取到锁,可以进行相应的处理,而不是一直等待。
- 资源分配的策略: 考虑使用资源分配的策略,以减少死锁的发生。
- 避免嵌套锁: 尽量避免在持有一个锁的同时去获取其他锁,避免占有且等待的情况。
【4】递归锁
- 递归锁(Recursive Lock),也称为可重入锁,是一种特殊类型的锁,允许同一个线程多次获取该锁而不会发生死锁。当一个线程已经持有递归锁时,它可以多次调用锁的
acquire方法,每次调用都需要相应的release操作,只有当锁的计数器降为零时,其他线程才能获取该锁。 - 递归锁主要用于解决同一线程在多个嵌套层次上需要获取同一个锁的情况。如果使用普通的互斥锁,同一线程在多次获取锁时会发生死锁,因为锁已经被该线程所占有,其他线程无法再获取,导致程序无法继续执行。而递归锁允许同一线程在持有锁的同时多次获取锁,只有在锁的计数器降为零时才能释放锁。
- 在 Python 中,
threading模块提供了递归锁的实现,可以使用threading.RLock来创建递归锁。
from threading import Thread,RLock
import time
# 两个变量同时指向一把锁
metexA = metexB = RLock()
class MyThread(Thread):
def run(self):
# 每一个线程都走完两个函数
self.func1()
self.func2()
def func1(self):
metexA.acquire()
# self.name:获取当前线程名
print(f'{self.name} 抢到了A锁')
metexB.acquire()
print(f'{self.name} 抢到了B锁')
metexB.release()
metexA.release()
# func1将AB两个锁都释放
def func2(self):
metexB.acquire()
# self.name:获取当前线程名
print(f'{self.name} 抢到了A锁')
'''阻塞时,将会有下一个线程来拿到锁'''
time.sleep(2)
metexA.acquire()
print(f'{self.name} 抢到了B锁')
metexA.release()
metexB.release()
# 当锁的类型时递归锁时,只要锁被正常释放了,下一个就可以拿到
def main():
for i in range(10):
t = MyThread()
t.start()
if __name__ == '__main__':
main()
【5】条件变量锁
- 条件变量锁(Condition Lock)是一种复杂的同步原语,它结合了锁和条件变量的功能。条件变量锁允许线程在等待某个条件为真时被通知,从而在多个线程之间进行复杂的协调。
- 在 Python 中,
threading模块提供了条件变量锁的实现,可以使用threading.Condition来创建条件变量锁。
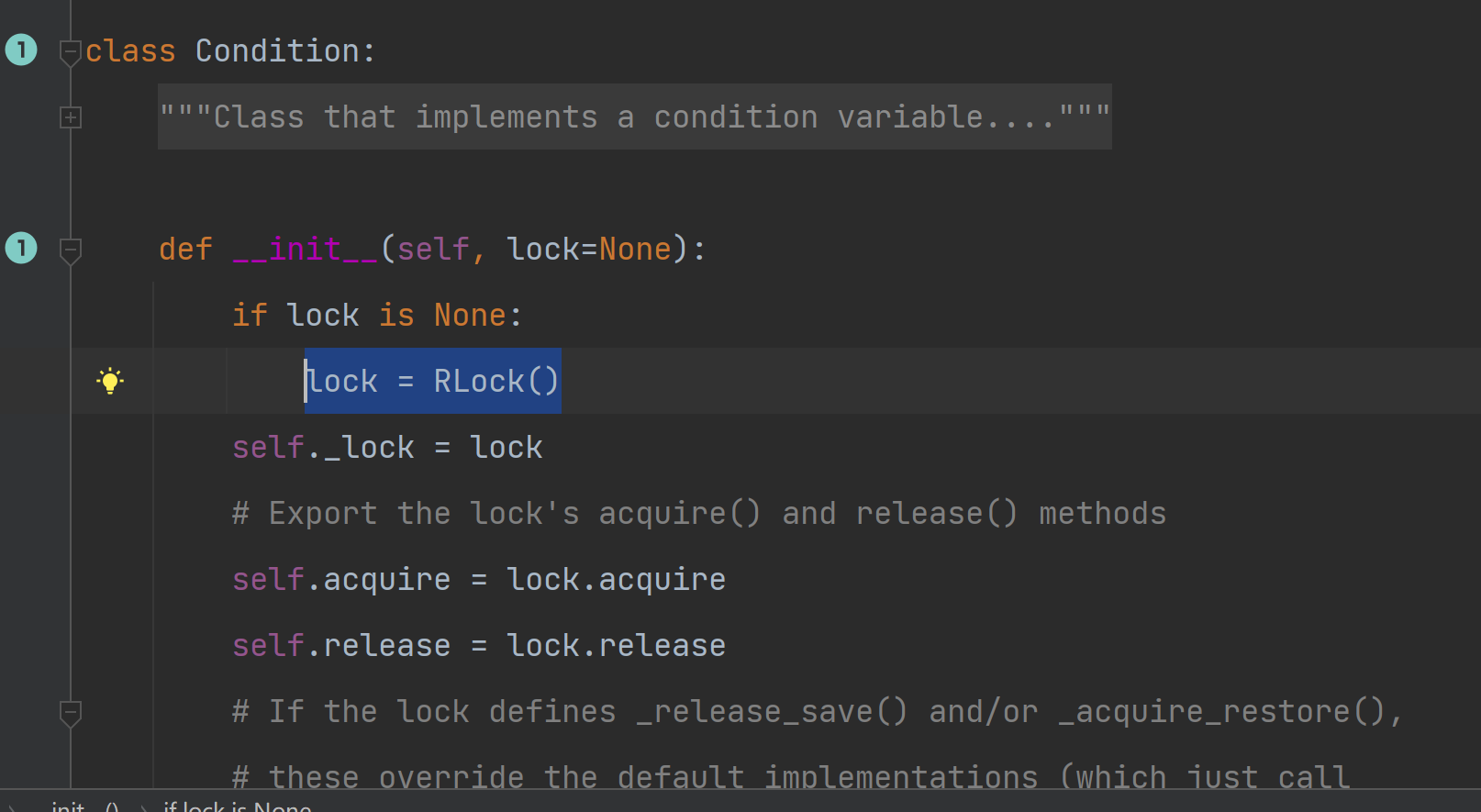
- 查看源码可以发现,可以指定锁的类型,并且也是有acquire和release方法的
# 源码注释
"""Class that implements a condition variable.
A condition variable allows one or more threads to wait until they are
notified by another thread.
If the lock argument is given and not None, it must be a Lock or RLock
object, and it is used as the underlying lock. Otherwise, a new RLock object
is created and used as the underlying lock.
"""
'''
这是一个实现条件变量的类。
条件变量允许一个或多个线程等待,直到它们被另一个线程通知。
如果提供了 lock 参数且不为 None,它必须是一个 Lock 或 RLock 对象,并且将被用作底层锁。否则,将创建一个新的 RLock 对象,并用作底层锁。
'''
【5.1】常用方法
acquire(self, *args): 获取底层锁。这个方法调用底层锁的acquire方法。release(self): 释放底层锁。这个方法调用底层锁的release方法。wait(self, timeout=None): 等待条件变量。释放底层锁,然后等待通知或超时。一旦被通知,重新获取底层锁并继续执行。notify(self, n=1): 发送单个通知。唤醒等待该条件变量的一个线程。notify_all(self): 发送通知给所有等待的线程。唤醒所有等待该条件变量的线程。
【5.2】代码示例
import threading
import time
# 共享资源
shared_resource = 0
# 创建条件变量锁
condition_lock = threading.Condition()
def producer():
global shared_resource
for i in range(5):
with condition_lock:
# 生产者生产资源
shared_resource += 1
print(f"Produced: {shared_resource}")
# 发出通知,通知消费者可以消费资源了
condition_lock.notify()
# 模拟生产过程中的耗时操作
time.sleep(1)
def consumer():
global shared_resource
for i in range(5):
with condition_lock:
# 消费者等待资源可用
while shared_resource == 0:
condition_lock.wait()
# 消费者消费资源
consumed_resource = shared_resource
shared_resource -= 1
print(f"Consumed: {consumed_resource}") # 消费的值
# 模拟消费过程中的耗时操作
time.sleep(1)
if __name__ == "__main__":
# 创建生产者和消费者线程
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)
# 启动线程
producer_thread.start()
consumer_thread.start()
# 等待线程完成
producer_thread.join()
consumer_thread.join()
【6】信号量
【6.1】信号量
信号量(Semaphore)是一种用于控制对共享资源的访问的同步机制。它是由计数器和相应的操作集合组成的数据结构,用于保护对临界区的访问,以防止并发引起的问题。
信号量主要有两个基本操作:
- P(Wait)操作: 当线程进入临界区时,首先执行 P 操作,使信号量的计数器减一。如果计数器为正,线程可以继续执行,否则线程将被阻塞。
- V(Signal)操作: 当线程离开临界区时,执行 V 操作,使信号量的计数器加一。这会释放一个被 P 操作阻塞的线程,使其可以继续执行。
信号量的计数器可以看作是可以同时访问共享资源的线程数目。当计数器为正时,表示还有可用的资源,线程可以进入临界区。当计数器为零时,表示所有资源都被占用,线程需要等待。
# 源码介绍
"""This class implements semaphore objects.
Semaphores manage a counter representing the number of release() calls minus
the number of acquire() calls, plus an initial value. The acquire() method
blocks if necessary until it can return without making the counter
negative. If not given, value defaults to 1."""
"""
这个类实现了信号量对象。
信号量管理一个计数器,该计数器表示 release() 方法调用的次数减去 acquire() 方法调用的次数,再加上一个初始值。acquire() 方法会阻塞,直到它可以在不使计数器为负的情况下返回。如果没有提供初始值,value 默认为 1。
"""
【6.2】常用方法
threading.Semaphore(value=1):- 作用:初始化信号量,设置初始值。默认初始值为 1。
acquire(blocking=True, timeout=None):- 作用:尝试获取信号量。如果信号量的值大于零,将其减一并立即返回;否则,线程将被阻塞,直到信号量的值大于零或超时。如果
blocking参数为False,则尝试获取信号量,如果失败立即返回。
- 作用:尝试获取信号量。如果信号量的值大于零,将其减一并立即返回;否则,线程将被阻塞,直到信号量的值大于零或超时。如果
release():- 作用:释放信号量,将其值加一。如果有等待的线程,其中一个将被唤醒。
import threading
import time
# 创建一个初始值为2的信号量
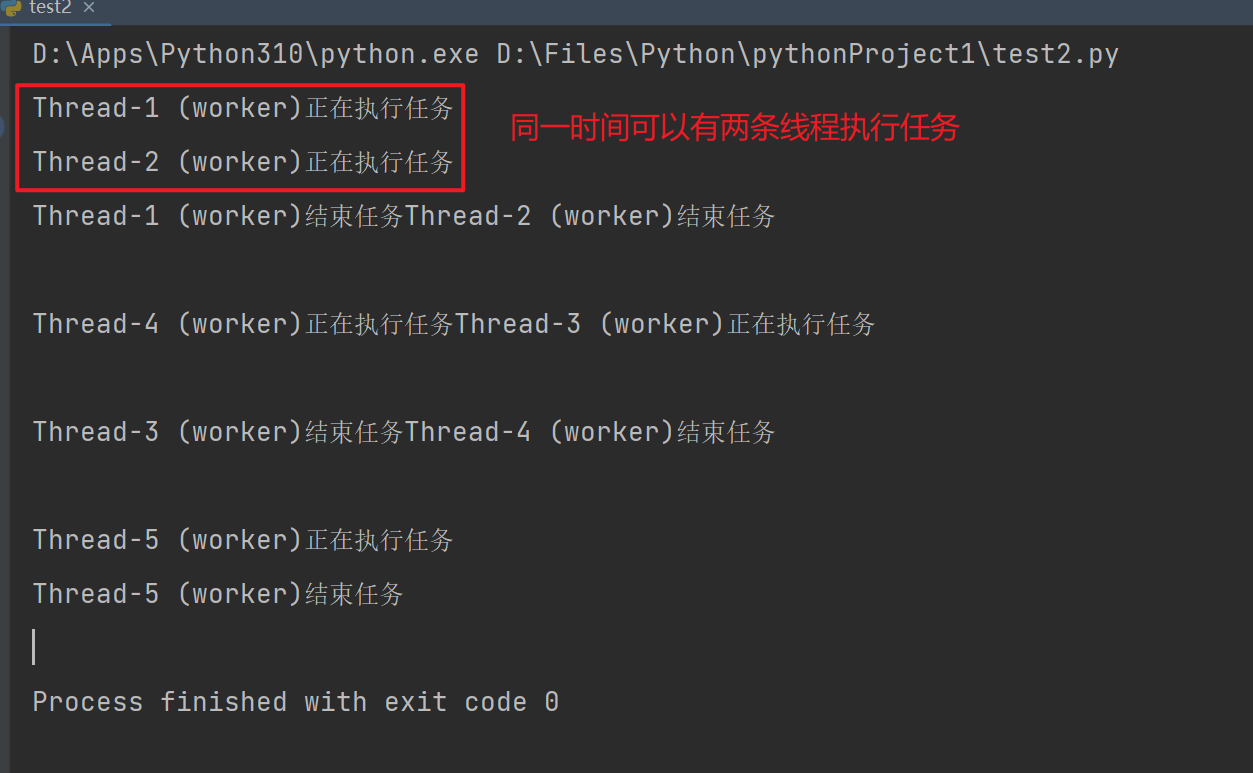
semaphore = threading.Semaphore(2)
def worker(semaphore):
semaphore.acquire()
print(f"{threading.current_thread().name}正在执行任务")
time.sleep(0.1)
print(f"{threading.current_thread().name}结束任务")
semaphore.release()
# 创建多个线程
threads = [threading.Thread(target=worker,args=(semaphore,)) for i in range(5)]
# 启动线程
for thread in threads:
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
- 使用with语句同样可以实现
import threading
import time
# 创建一个初始值为2的信号量
semaphore = threading.Semaphore(2)
def worker():
with semaphore:
print(f"{threading.current_thread().name}正在执行任务")
time.sleep(0.1)
# 临界区代码
print(f"{threading.current_thread().name}结束任务")
# 创建多个线程
threads = [threading.Thread(target=worker) for i in range(5)]
# 启动线程
for thread in threads:
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
【6.3】线程池与信号量结合使用
-
信号量(Semaphore):
- 作用: 信号量是一种同步原语,用于控制对共享资源的访问。它维护一个内部计数器,线程通过
acquire()方法尝试获取信号量,成功则计数器减一,失败则线程被阻塞。通过release()方法释放信号量,计数器加一。 - 使用场景: 适用于需要限制并发访问某一资源的情况,例如共享的数据结构、文件、网络连接等。
- 作用: 信号量是一种同步原语,用于控制对共享资源的访问。它维护一个内部计数器,线程通过
-
线程池(ThreadPool):
- 作用: 线程池是一组预先创建的线程,用于执行异步任务。它可以管理线程的生命周期、复用线程以减少创建和销毁的开销,并提供任务队列,让任务在线程池中异步执行。
- 使用场景: 适用于需要异步执行大量任务的情况,例如并行计算、IO密集型操作等。
-
结合使用:
- 在一些情况下,你可能希望在使用线程池执行任务时,限制对某一共享资源的并发访问。这时,信号量可以用于控制对共享资源的访问。例如,在一个线程池中执行多个任务,但这些任务需要访问同一个文件资源,你可以使用信号量确保同时只有一个任务能够访问该文件。
import threading
import time
from concurrent.futures import ThreadPoolExecutor
def worker(semaphore, resource):
with semaphore:
print(f"{threading.current_thread().name}申请资源")
# 模拟对共享资源的操作
time.sleep(1)
print(f"T{threading.current_thread().name} 使用资源: {resource}")
print(f"{threading.current_thread().name} 释放资源")
return f"{resource}执行完毕"
if __name__ == "__main__":
# 创建信号量,初始值为2
sem = threading.Semaphore(value=2)
# 创建线程池
with ThreadPoolExecutor(max_workers=3) as executor:
# 提交多个任务给线程池
tasks = [executor.submit(worker, sem, f"Thread-{i}") for i in range(5)]
# 等待所有任务完成
for future in tasks:
# print(future) # <Future at 0x1d972d58700 state=finished returned NoneType>
print(future.result())
print("====")
【7】事件锁
【7.1】事件(Event)
事件(Event)是一种线程间通信的同步机制,它提供了一种线程间的触发和等待的机制。在多线程编程中,一个线程通常需要等待另一个线程发生某个事件,或者通知其他线程某个事件已经发生。
事件有两个基本操作:
- 设置(Set): 将事件的状态设置为"已发生",唤醒等待该事件的线程。
- 清除(Clear): 将事件的状态设置为"未发生",使线程等待该事件。
线程可以通过等待事件的发生来进入阻塞状态,直到其他线程将事件设置为"已发生"。一旦事件被设置,所有等待该事件的线程都将被唤醒。
事件的使用场景包括但不限于:
- 线程间的协同工作,其中一个线程需要等待其他线程完成某个任务后再继续执行。
- 用于发信号,通知其他线程某个条件已经满足。
- 控制线程的启动和停止。
需要注意的是,事件是一次性的,即一旦事件被设置,再次等待该事件的线程将无法再次被唤醒。如果需要多次使用的事件,可以考虑使用 threading.Condition。
【7.2】代码演示
import threading
import time
# 创建事件
event = threading.Event()
def worker():
print(f"Thread {threading.current_thread().name} is waiting for the event.")
event.wait() # 阻塞等待事件发生
print(f"Thread {threading.current_thread().name} has received the event.")
# 创建多个线程
threads = [threading.Thread(target=worker) for i in range(3)]
# 启动线程
for thread in threads:
thread.start()
# 主线程等待一段时间后设置事件
time.sleep(2)
print("Setting the event.")
event.set() # 设置事件
# 等待所有线程完成
for thread in threads:
thread.join()
【7.3】捉迷藏小游戏
'''阻塞任务,知道条件符合就继续执行任务'''
import random
import threading
import time
event = threading.Event()
def hider():
# 老鼠
print(f"{threading.current_thread().name}:我正在躲藏!")
time.sleep(0.1)
print(f"{threading.current_thread().name}:我藏好了!")
event.set()
time.sleep(0.3)
event.wait()
time.sleep(0.1)
print("====游戏结束====")
def seeker():
# 猫
print(f"{threading.current_thread().name}:捉迷藏游戏开始喽!")
event.wait()
print(f"{threading.current_thread().name}:我正在抓捕!")
time.sleep(0.3)
res = bool(random.randint(0, 1))
if res:
print(f"{threading.current_thread().name}:抓到你啦!")
else:
print(f"{threading.current_thread().name}:没有找到你!")
event.set()
if __name__ == '__main__':
hider_one = threading.Thread(target=hider)
seeker_one = threading.Thread(target=seeker)
seeker_one.start()
time.sleep(0.1)
hider_one.start()
hider_one.join()
seeker_one.join()
# Thread-2 (seeker):捉迷藏游戏开始喽!
# Thread-1 (hider):我正在躲藏!
# Thread-1 (hider):我藏好了!
# Thread-2 (seeker):我正在抓捕!
# Thread-2 (seeker):没有找到你!
# ====游戏结束====
【8】GIL锁
GIL(全局解释器锁)是在 CPython 解释器中使用的一种机制,用于确保在同一时刻只有一个线程能够执行 Python 字节码。它是为了保护解释器内部数据结构而设计的,以防止多线程并发执行导致的数据竞争和不一致性问题。
要理解 GIL,以下是一些关键点:
- 全局锁: GIL 是一个全局锁,它锁住整个解释器,防止多个线程同时执行 Python 字节码。
- Python 解释器: GIL 是与 CPython 解释器紧密关联的概念。CPython 是 Python 的官方解释器,而 GIL 是它的一个特定特性。
- 影响多线程性能: GIL 的存在限制了多线程并发执行的效果,因为在任何时刻只有一个线程能够在解释器中执行 Python 代码。这使得多线程在 CPU 密集型任务上的性能提升有限。
- 不影响IO密集型任务: GIL 对于 I/O 密集型任务的影响相对较小,因为在执行 I/O 操作时,线程可以释放 GIL,让其他线程执行。
- 多进程并行: 对于 CPU 密集型任务,可以考虑使用多进程并行来绕过 GIL 的限制,因为每个进程都有自己的解释器和 GIL。
- 释放GIL: CPython 在执行一些特定操作(如 I/O 操作、sleep 等)时会释放 GIL,以允许其他线程执行。
- GIL争夺: 在多线程环境中,不同线程会竞争 GIL,这可能导致性能瓶颈,特别是在多核系统上。
虽然 GIL 在某些情况下限制了 Python 的多线程性能,但它也简化了解释器的实现,使得 Python 更容易使用和开发。对于大多数应用而言,GIL 并不是主要的性能瓶颈。如果需要充分利用多核系统,可以考虑使用多进程、使用其他解释器(如 Jython、IronPython)或使用 C 扩展模块。
"""得出结论:GIL锁就是保证在统一时刻只有一个线程执行,所有的线程必须拿到GIL锁才有执行权限"""
"""以下几个问题是需要理解记忆的"""
1. python有GIL锁的原因,同一个进程下多个线程实际上同一时刻,只有一个线程在执行
2. 只有在python上开进程用的多,其他语言一般不开多进程,只开多线程就够了
3. cpython解释器开多线程不能利用多核优势,只有开多进程才能利用多核优势,其他语言不存在这个问题
4. 8核cpu电脑,充分利用起我这个8核,至少起8个线程,8条线程全是计算--->计算机cpu使用率是100%,
5. 如果不存在GIL锁,一个进程下,开启8个线程,它就能够充分利用cpu资源,跑满cpu
6. cpython解释器中好多代码,模块都是基于GIL锁机制写起来的,改不了了---》我们不能有8个核,但我现在只能用1核,----》开启多进程---》每个进程下开启的线程,可以被多个cpu调度执行
7. cpython解释器:io密集型使用多线程,计算密集型使用多进程
# -io密集型,遇到io操作会切换cpu,假设你开了8个线程,8个线程都有io操作---》io操作不消耗cpu---》一段时间内看上去,其实8个线程都执行了, 选多线程好一些
# -计算密集型,消耗cpu,如果开了8个线程,第一个线程会一直占着cpu,而不会调度到其他线程执行,其他7个线程根本没执行,所以我们开8个进程,每个进程有一个线程,8个进程下的线程会被8个cpu执行,从而效率高
'''计算密集型选多进程好一些,在其他语言中,都是选择多线程,而不选择多进程.'''
【8.1】代码展示GIL锁
import os
from threading import Thread
import time
num = 50
def task():
time.sleep(0.1) # 就算加了阻塞,数据依旧不会错乱
global num
num -= 1
print(f"{os.getpid()}|num的值为{num}")
if __name__ == '__main__':
t_list = [Thread(target=task) for i in range(5)]
[t.start() for t in t_list]
[t.join() for t in t_list]
print("====")
'''并没有对数据加锁,但是因为gil的缘故,并没有造成数据错乱'''
# 22460|num的值为49
# 22460|num的值为48
# 22460|num的值为47
# 22460|num的值为46
# 22460|num的值为45
# ====