C#使用WhisperNet实现语音识别功能
1.写在前面
最近想做一下本地音频语音识别工具,在网上找了一些本地音频语音识别方面的资料。
Whisper 是 OpenAI 的一种自动最先进的语音识别系统,它已经接受了 680000 小时从网络收集的多语言和多任务监督数据的训练。这个庞大而多样化的数据集提高了对口音、背景噪音和技术语言的鲁棒性。此外,它还支持多种语言的转录,以及将这些语言翻译成英语。与 DALLE-2 和 GPT-3 不同,Whisper 是一种免费的开源模型。 Whisper的优势是开源免费、支持多语种(包括中文),根据不同的场景需求有不同模型可供选择,最终的效果比市面上很多音频转文字的效果都要好。 Whisper提供了五种型号尺寸,其中四种为纯英文版本,提供速度和准确性的权衡。以下是可用型号的名称及其大致的内存要求和相对速度。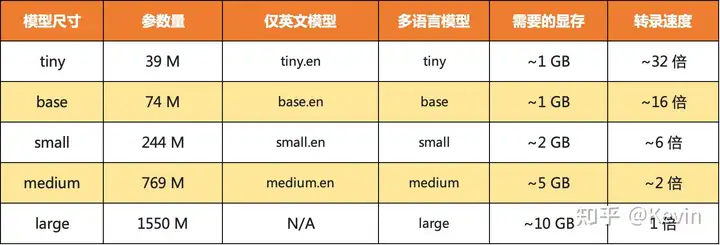
Whisper 的性能因语言而异。下图显示了使用该模型的 Fleurs 数据集按语言的 WER(单词错误率)细分large-v2(数字越小,性能越好)。中文为14.7%

2.下载地址
源码下载地址:https://github.com/Const-me/Whisper
模型下载地址:https://huggingface.co/sandrohanea/whisper.net/tree/main/classic
3.程序实现
下面将贴出实现该程序的关键代码。
private async void buttonAsr_Click(object sender, EventArgs e)
{
string[] list = Library.listGraphicAdapters();
CommandLineArgs cla = new CommandLineArgs();
cla.language = eLanguage.Chinese;
cla.gpu = textGpu.Text;
cla.model = textModel.Text;
cla.fileName = textFile.Text;
cla.prompt = "这是一段播客的内容。";
cla.output_srt = true;
using iModel model = await Library.loadModelAsync(cla.model, new CancellationToken(), eGpuModelFlags.Cloneable, cla.gpu);
int[]? prompt = null;
if (!string.IsNullOrEmpty(cla.prompt))
prompt = model.tokenize(cla.prompt);
//using Context context = model.createContext();
context = model.createContext();
cla.apply(ref context.parameters);
context.parameters.setFlag(eFullParamsFlags.NoContext, true);
using iMediaFoundation mf = Library.initMediaFoundation();
Transcribe transcribe = new Transcribe(cla);
using iAudioReader reader = mf.openAudioFile(cla.fileName, cla.diarize);
await context.runFullAsync(reader, transcribe, UpdateProgress, prompt);
}
4.程序界面

5.功能
本地音频语音识别。
程序中包含WhisperDesktop.exe
下载地址:https://pan.baidu.com/s/1c8r7HO2XvGocEuVIwdddpQ?pwd=6666 提取码:6666