Python 中的 __init__.py 和__all__ 详解
 JOKER
没意思先生
JOKER
没意思先生
之前不论是自己写代码还是用别人的代码,都没有注意过这个东西,今天忽然看了一下,网上的教程感觉讲的都不是很清楚,自己又研究了研究,总结一下,如果有不对的地方,大家帮忙指正一下。
在Python工程里,当python检测到一个目录下存在__init__.py文件时,python就会把它当成一个模块(module)。个人习惯说这是一个包,只有.py的文件我才说是模块,不知道我这个表述规范不规范,不规范的话大家帮忙指正一下。
__init__.py这个东西不是必须有的,如果有的话,在调用包的时候,会运行这个文件。没有的话,也不耽误。
__init__.py存在的意义,是简化代码
看这个示例:
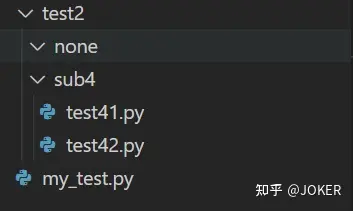
# my_test.py
from test2.sub4.test41 import print_41 # print_41是在test41.py里定义的函数 后面的都可以依次类推 我就不写了
print_41()跑的通,没任何问题
这样也跑的通:
from test2.sub4 import test41
test41.print_41()但这个,是跑不通的,不是把py文件写在了一个文件夹下,这个文件夹就是知道他下面有啥了的!!!!
from test2 import sub4
sub4.test41.print_41()
# 报错:AttributeError: module 'test2.sub4' has no attribute 'test41'下面调整一下,加上__init__.py,但是__init__.py里什么都不写
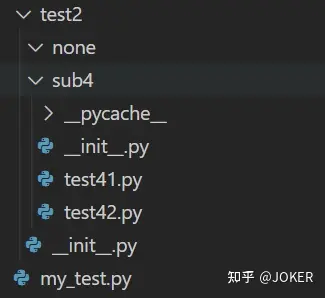
再跑这段代码:
from test2 import sub4
sub4.test41.print_41()不好意思,这样照样也是跑不通,会报同样的错误,回到我前面说的,在调用包的时候,会运行__init__.py这个文件,你__init__里啥也没写,就跟没有一样
那要怎么样这段代码才能跑的通呢?在两个__init__文件里分别写上这些东西:
# test2/__init__.py
from . import sub4
# test2/sub4/__init__.py
from . import test41然后运行那一段代码,就可以跑的通了,原理就是,我在运行 from test2 import sub4 这句代码的时候,就运行了 test2/sub4/__init__.py (其实test2/__init__.py也有运行) 就相当于在sub4这个包里,引入了test41这个模块,sub4知道自己有这个模块了。
这里还有一个,我为什么要写 from . import test41 直接 import 不行吗?不行的,在我们执行 import 时,当前目录是不会变的(就算是执行子目录的文件),还是需要完整的路径的。from . 的意思,就是在当前运行文件的所在目录下面找。
所以 我如果运行下面这个:
from test2 import sub4
sub4.test42.print_42()跑不通的, test2/sub4/__init__.py没有写 import test42,所以sub4是不知道自己下面有test42这个模块的
继续 为什么我说是运行了那两个__init__.py文件呢,我们稍微修改一下__init__.py文件:
# test2/__init__.py
from . import sub4
print("you have imported sub4")
# test2/sub4/__init__.py
from . import test41
print("you have imported test41")再来运行这个代码:
from test2 import sub4
sub4.test41.print_41()
# 输出:
# you have imported test41
# you have imported sub4
# 41 (函数.print_41的输出)看到了吧 from test2 import sub4 照样会运行 test2/__init__.py 这个文件
哎 反正涉及到 test2 就会运行 test2/__init__.py,就可以import sub4,import sub4 不就又运行了 test2/sub4/__init__.py 那我这样写不也可以吗:
import test2
test2.sub4.test41.print_41()当然可以了,完全跑的通,输出也依然是:
# you have imported test41
# you have imported sub4
# 41 (函数.print_41的输出)但这样可不行:
import test2
sub4.test41.print_41()冷不丁的写一个sub4,是不行的,在my_test.py里sub4是没有被定义的。
但是这样写好长啊,有没有办法短一点呢?有办法的,把 test2/__init__.py 改成这个:
# test2/__init__.py
from .sub4.test41 import print_41 as p41
print("you have imported sub4")然后 我就只需要写,就可以了:
import test2
test2.p41()
# 输出
# you have imported test41
# you have imported sub4
# 41 (函数.print_41的输出)其实一般情况下,init文件都是这样写的,不然写了init 我们还要写一大堆东西,那写init干嘛呢。
接下来 还要说一个变量,就是__all__:
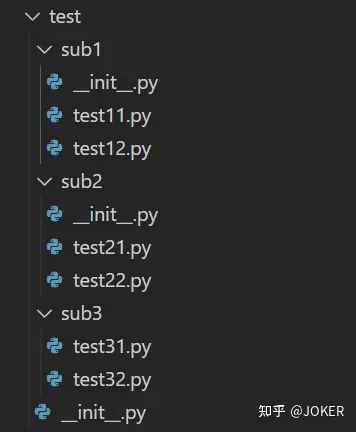
看上边这个东西
# test/__init__.py
from .sub1 import *
from . import sub2
from . import sub3
__all__=['sub1','sub3']
print("You have imported test")
# test/sub1/__init__.py
from . import test11,test12
__all__ = ['test11']
print("you have imported sub1")
# test/sub2/__init__.py
from . import test21
from . import test22
print('you have imported sub2')
# sub3 里没有init文件然后我们分别运行下面的代码 我直接把输出都列出来了:
from test import *
print(dir())
# 输出:
# you have imported sub1
# you have imported sub2
# You have imported test
# ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'sub1', 'sub3']
# 看好了,输出了 you have imported sub2 ,dir()没有sub2,原因就是,sub2 不在__all__这个变量里。那为什么会输出那句话呢,原因就是 运行了test/__init__.py
import test
print(dir())
print(dir(test))
print(dir(test.sub1))
print(dir(test.sub2))
print(dir(test.sub3))
test.test11.print_11()
# 输出:
# you have imported sub1
# you have imported sub2
# You have imported test
# ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'test']
# ['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'sub1', 'sub2', 'sub3', 'test11']
# ['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'sub1', 'sub2', 'test11']
# ['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'test11', 'test12']
# ['__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__']
# 11
# 我们发现,在当前的py文件下,只有test这个包,但在test包中,不仅有 'sub1', 'sub2', 'sub3',还有一个 'test11'模块,并且可以直接test.test11.print_11()调用里面的函数
# 我们还发现,test.sub1包里照样有test11和test12两个,test.sub2里也照样有test21和test22两个,sub3下面啥也没有
# 挨个解释,只有当 from test import * 的时候,__all__才有影响。当直接import test 时,__all__是影响不到test中子包的。dir(test)里,是有sub2的
# 为什么test下会有 test11,因为在init里,写的是 from .sub1 import * ,这就相当于把sub1包里的模块导入了test包里,所以可以直接调用
# 为什么test下没有 test12呢,因为test12 不在 test/sub1/__init__.py 的__all__变量里。
# 为什么test.sub1下会有test11和test12两个,原因还是__all__是影响不到包里面的模块的。
# 为什么sub3下面啥也没有,因为sub3里是没有init的,他是不知道自己下边有啥的加深一下理解,把 test/__init__.py 改一下,改成这样:
# test/__init__.py
from . import sub2
from . import sub3
__all__=['sub1','sub3']
print("You have imported test")运行下面这个:
import test
print(dir())
print(dir(test))
# 输出
# you have imported sub2
# You have imported test
# ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'test']
# ['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'sub2', 'sub3']
# 完全没有sub1什么事了,原因就是在test里没有import sub1,test下是没有那个子包的
from test import *
print(dir())
# 输出
# you have imported sub2
# You have imported test
# you have imported sub1
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'sub1', 'sub3']
# 哎!这下有了sub1了,但注意you have imported sub1这句话跑到最后了。原因是,__all__变量起了作用,并且是在运行完了init之后,才把sub1给弄进来的