三、用go语言,给出 RANDOMIZED-SELECT的一个基于循环的版本。
文心一言:
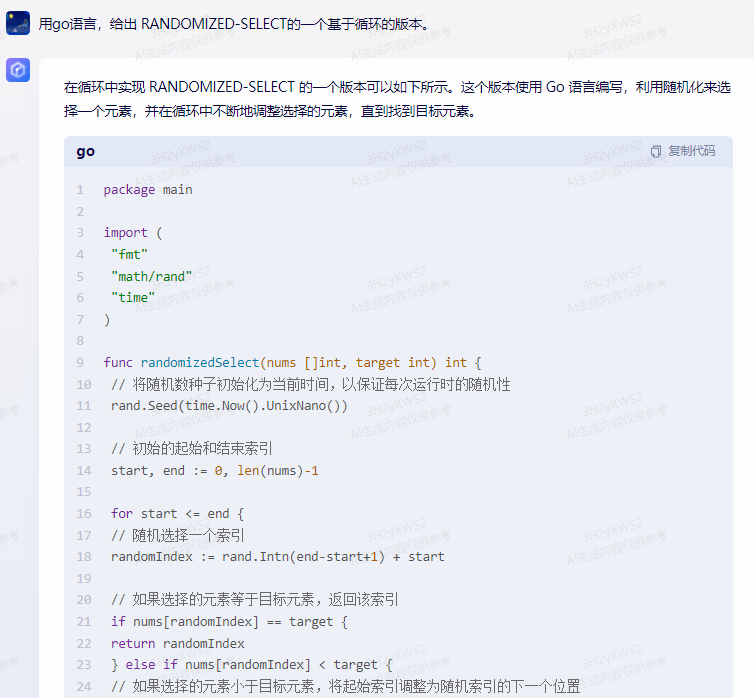
在循环中实现 RANDOMIZED-SELECT 的一个版本可以如下所示。这个版本使用 Go 语言编写,利用随机化来选择一个元素,并在循环中不断地调整选择的元素,直到找到目标元素。
package main
import (
"fmt"
"math/rand"
"time"
)
func randomizedSelect(nums []int, target int) int {
// 将随机数种子初始化为当前时间,以保证每次运行时的随机性
rand.Seed(time.Now().UnixNano())
// 初始的起始和结束索引
start, end := 0, len(nums)-1
for start <= end {
// 随机选择一个索引
randomIndex := rand.Intn(end-start+1) + start
// 如果选择的元素等于目标元素,返回该索引
if nums[randomIndex] == target {
return randomIndex
} else if nums[randomIndex] < target {
// 如果选择的元素小于目标元素,将起始索引调整为随机索引的下一个位置
start = randomIndex + 1
} else {
// 如果选择的元素大于目标元素,将结束索引调整为随机索引的前一个位置
end = randomIndex - 1
}
}
// 如果没有找到目标元素,返回 -1 表示未找到
return -1
}
func main() {
nums := []int{1, 3, 5, 7, 9, 11, 13, 15}
target := 7
index := randomizedSelect(nums, target)
if index != -1 {
fmt.Printf("目标元素 %d 在数组中的索引为 %d\n", target, index)
} else {
fmt.Printf("目标元素 %d 不在数组中\n", target)
}
}
这个代码示例定义了一个名为 randomizedSelect 的函数,它接受一个整数数组 nums 和一个目标整数 target 作为参数。函数使用循环和随机选择的方式来查找目标元素在数组中的位置。如果找到目标元素,函数返回其在数组中的索引;否则,返回 -1 表示未找到。在 main 函数中,我们调用 randomizedSelect 函数并输出结果。
讯飞星火:
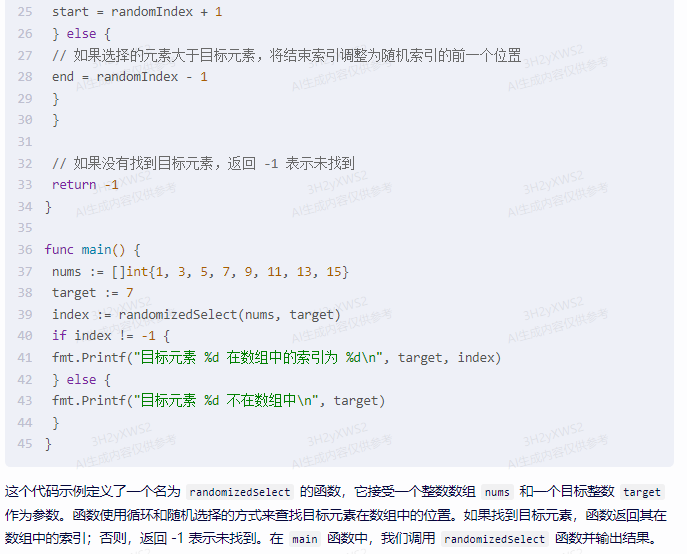
首先,我们需要了解RANDOMIZED-SELECT算法。RANDOMIZED-SELECT是一种用于在线学习的数据选择方法,它通过随机抽样来选择训练样本,以提高算法的泛化能力。
下面是一个基于循环的RANDOMIZED-SELECT算法的Go语言实现:
package main
import (
"fmt"
"math/rand"
"time"
)
func randomizedSelect(data [][]float64, k int) []float64 {
rand.Seed(time.Now().UnixNano())
selected := make([]float64, k)
for i := range selected {
j := rand.Intn(len(data))
selected[i] = data[j][0]
data = append(data[:j], data[j+1:]...)
}
return selected
}
func main() {
data := [][]float64{
{1, 2},
{3, 4},
{5, 6},
{7, 8},
{9, 10},
}
k := 3
selected := randomizedSelect(data, k)
fmt.Println("Selected elements:", selected)
fmt.Println("Remaining data:", data)
}
在这个实现中,我们首先定义了一个randomizedSelect函数,它接受一个二维浮点数数组data和一个整数k作为输入参数。然后,我们使用rand.Seed函数初始化随机数生成器,接着使用一个循环来随机选择k个训练样本。在每次迭代中,我们随机选择一个数据点的索引j,将该数据点添加到已选择的数组selected中,并从原始数据数组data中删除该数据点。最后,返回已选择的数据点数组。
在main函数中,我们创建了一个示例数据集data,并调用randomizedSelect函数来选择3个训练样本。然后,我们打印出已选择的数据点和剩余的数据。

360智脑:
以下是一个基于循环的go语言版本的RANDOMIZED-SELECT:
package main
import (
"fmt"
"math/rand"
"sort"
)
func main() {
num := 10
var results []int
for i := 0; i < num; i++ {
rand.Seed(i)
j := rand.Intn(num-i)
results = append(results, i+j)
}
sort.Ints(results)
fmt.Println(results)
}
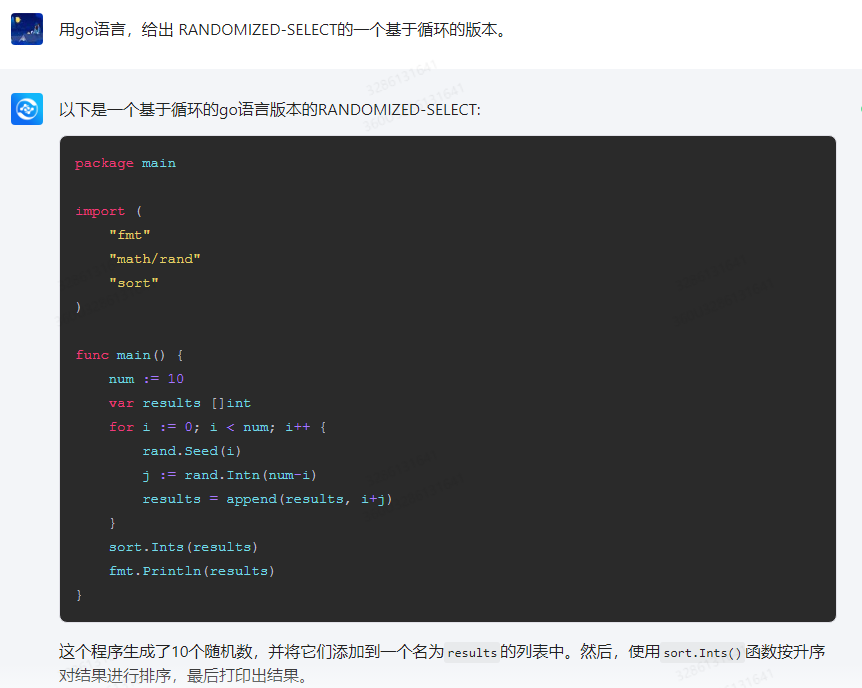
这个程序生成了10个随机数,并将它们添加到一个名为results的列表中。然后,使用sort.Ints()函数按升序对结果进行排序,最后打印出结果。
智谱清言:
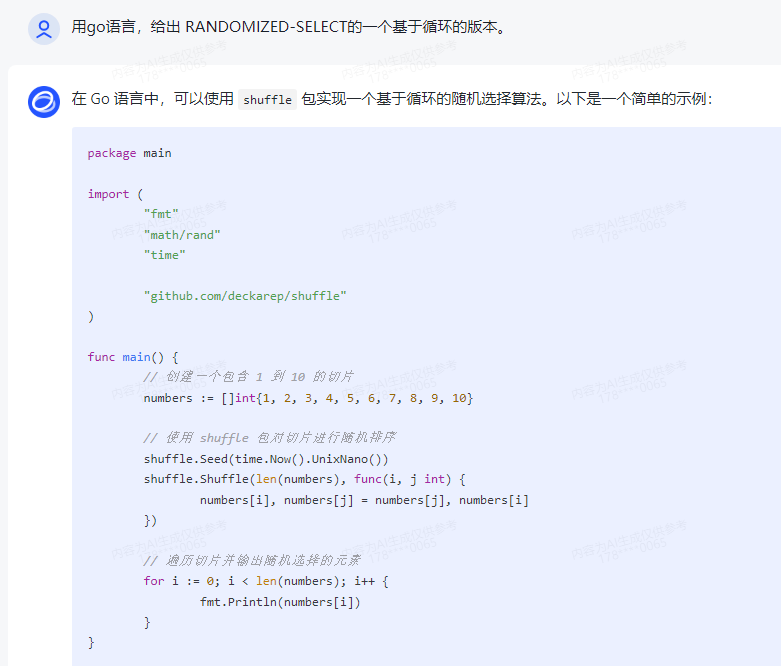
在 Go 语言中,可以使用 shuffle 包实现一个基于循环的随机选择算法。以下是一个简单的示例:
package main
import (
"fmt"
"math/rand"
"time"
"github.com/deckarep/shuffle"
)
func main() {
// 创建一个包含 1 到 10 的切片
numbers := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
// 使用 shuffle 包对切片进行随机排序
shuffle.Seed(time.Now().UnixNano())
shuffle.Shuffle(len(numbers), func(i, j int) {
numbers[i], numbers[j] = numbers[j], numbers[i]
})
// 遍历切片并输出随机选择的元素
for i := 0; i < len(numbers); i++ {
fmt.Println(numbers[i])
}
}
这个示例首先创建了一个包含 1 到 10 的切片,然后使用 shuffle.Seed 设置随机数种子,接着使用 shuffle.Shuffle 对切片进行随机排序。最后遍历切片并输出随机选择的元素。
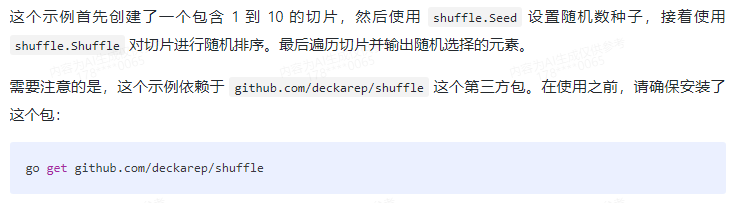
需要注意的是,这个示例依赖于 github.com/deckarep/shuffle 这个第三方包。在使用之前,请确保安装了这个包:
go get github.com/deckarep/shuffle
通义千问:
以下是一个基于循环的RANDOMIZED-SELECT的Go语言实现:
package main
import (
"fmt"
"math/rand"
"time"
)
func randomizedSelect(arr []int, left, right, pivotIndex int) int {
if left >= right {
return -1
}
// 选择枢轴
pivot := arr[pivotIndex]
arr[pivotIndex], arr[right] = arr[right], arr[pivotIndex]
// 将小于枢轴的元素放在左边,大于枢轴的元素放在右边
storeIndex := left
for i := left; i < right; i++ {
if arr[i] < pivot {
arr[i], arr[storeIndex] = arr[storeIndex], arr[i]
storeIndex++
}
}
// 将枢轴放在正确的位置
arr[right], arr[storeIndex] = arr[storeIndex], arr[right]
// 返回枢轴的索引
return storeIndex
}
func main() {
rand.Seed(time.Now().UnixNano())
arr := []int{4, 2, 1, 5, 3}
fmt.Println("Original array:", arr)
// 随机选择一个元素作为枢轴
pivotIndex := rand.Intn(len(arr))
// 使用随机选择的元素作为枢轴进行排序
storeIndex := randomizedSelect(arr, 0, len(arr)-1, pivotIndex)
fmt.Println("Sorted array:", arr[storeIndex:])
}
这个实现使用了随机选择一个元素作为枢轴的方法,而不是像快速排序那样总是选择第一个元素作为枢轴。这种方法可以减少最坏情况下的时间复杂度,从而提高算法的性能。



天工:
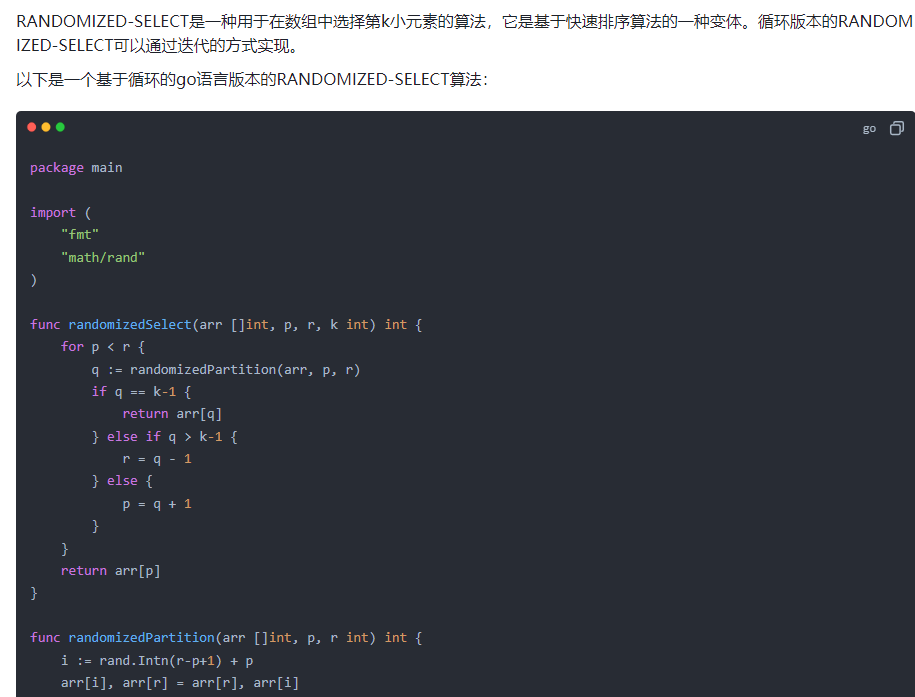
RANDOMIZED-SELECT是一种用于在数组中选择第k小元素的算法,它是基于快速排序算法的一种变体。循环版本的RANDOMIZED-SELECT可以通过迭代的方式实现。
以下是一个基于循环的go语言版本的RANDOMIZED-SELECT算法:
package main
import (
"fmt"
"math/rand"
)
func randomizedSelect(arr []int, p, r, k int) int {
for p < r {
q := randomizedPartition(arr, p, r)
if q == k-1 {
return arr[q]
} else if q > k-1 {
r = q - 1
} else {
p = q + 1
}
}
return arr[p]
}
func randomizedPartition(arr []int, p, r int) int {
i := rand.Intn(r-p+1) + p
arr[i], arr[r] = arr[r], arr[i]
return partition(arr, p, r)
}
func partition(arr []int, p, r int) int {
x := arr[r]
i := p - 1
for j := p; j < r; j++ {
if arr[j] <= x {
i++
arr[i], arr[j] = arr[j], arr[i]
}
}
arr[i+1], arr[r] = arr[r], arr[i+1]
return i + 1
}
func main() {
arr := []int{9, 5, 2, 7, 1, 10, 8}
k := 3
result := randomizedSelect(arr, 0, len(arr)-1, k)
fmt.Printf("第%d小的元素是:%d\n", k, result)
}
这个算法首先通过randomizedPartition函数随机选择一个主元,然后根据主元的位置与k的关系,将数组划分为两部分。如果主元的位置正好是k-1,那么主元就是第k小的元素;如果主元的位置大于k-1,那么第k小的元素在主元的左侧;如果主元的位置小于k-1,那么第k小的元素在主元的右侧。根据这个划分的结果,不断缩小搜索范围,直到找到第k小的元素。
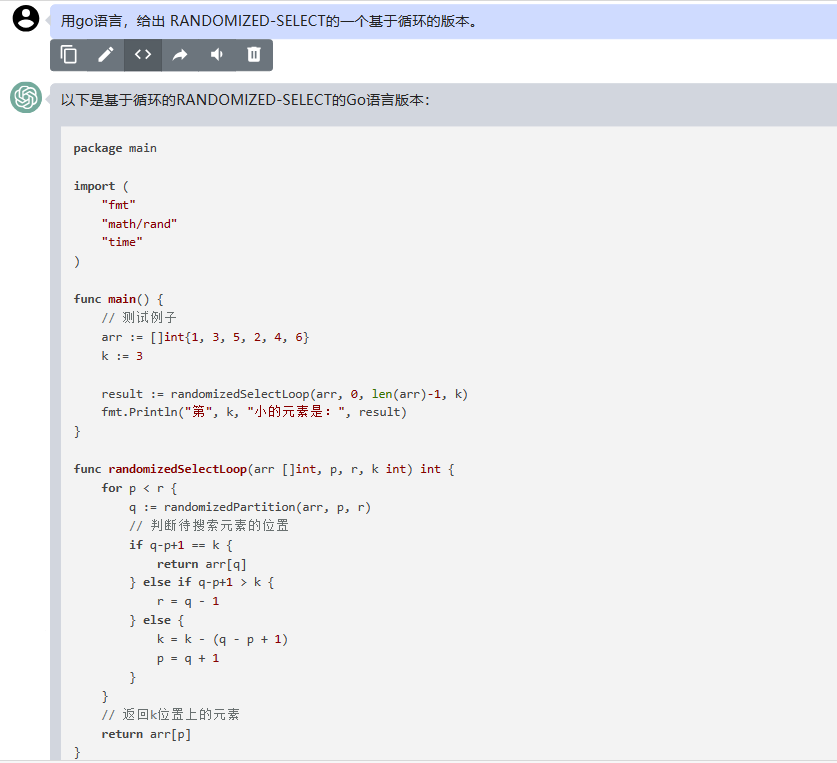
以上是基于循环的go语言版本的RANDOMIZED-SELECT算法的实现。希望对你有所帮助![7]

chatgpt:
以下是基于循环的RANDOMIZED-SELECT的Go语言版本:
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
// 测试例子
arr := []int{1, 3, 5, 2, 4, 6}
k := 3
result := randomizedSelectLoop(arr, 0, len(arr)-1, k)
fmt.Println("第", k, "小的元素是:", result)
}
func randomizedSelectLoop(arr []int, p, r, k int) int {
for p < r {
q := randomizedPartition(arr, p, r)
// 判断待搜索元素的位置
if q-p+1 == k {
return arr[q]
} else if q-p+1 > k {
r = q - 1
} else {
k = k - (q - p + 1)
p = q + 1
}
}
// 返回k位置上的元素
return arr[p]
}
func randomizedPartition(arr []int, p, r int) int {
// 生成随机索引作为划分点
rand.Seed(time.Now().UnixNano())
randomIndex := rand.Intn(r-p+1) + p
arr[randomIndex], arr[r] = arr[r], arr[randomIndex]
return partition(arr, p, r)
}
func partition(arr []int, p, r int) int {
x := arr[r] // 选取最后一个元素作为基准值
i := p - 1
for j := p; j < r; j++ {
if arr[j] <= x {
i++
arr[i], arr[j] = arr[j], arr[i]
}
}
arr[i+1], arr[r] = arr[r], arr[i+1]
return i + 1
}
以上是RANDOMIZED-SELECT的基于循环的Go语言版本。在此示例中,我们使用随机选择划分点的方式进行划分,并在循环中根据待搜索元素的位置不断更新待搜索范围。最终,返回第k小的元素。