本笔记主体框架主要参考自姜罕老师所做的技术分享,本人对其中的一些具体技术细节做了资料搜集与补充。
参考材料:
https://zhuanlan.zhihu.com/p/369635307
1. 概述
本节主要介绍搜索引擎的一些基本概念(如搜索引擎的分类、搜索好坏的衡量指标)以及搜索系统的基本架构
1.1 搜索引擎的分类
搜索引擎按照搜索的广度可以分为:
- 综合搜索(如Google、百度等):内容涵盖了几乎网络上的所有内容,检索处理的数据量量巨大
- 垂直搜索(如影视、商品、音乐等的搜索):只涉及某个局限领域内的内容检索,检索处理的数据量量相对较小大
1.2 搜索结构好坏的评估
从主观上衡量,影响搜索好坏的主要因素是用户的使用感受。在这一方面上,搜索引擎的发展经历了三个发展阶段:
- 从无到有:在互联网发展的早期,用户只能通过记录目标网页的网址才能访问网页、获取相关信息
- 海量信息的快速检索:搜索引擎出现后,用户能够根据搜索关键字找到想要检索的网页或链接
- 有效检索信息的展示:在展示检索结果时,除了展示网页链接外,还展示更加详细、生动的富媒体信息(如搜索电视剧,可展示相应剧集播放链接、网页文档中的搜索词位置等)
总体上来说,在这一维度上,搜索引擎的发展目标就是拉近用户与有效信息的距离。
从定量上衡量,搜索的好坏主要由 专家评估指标 和 统计学指标 的数值来体现。这些定量指标主要依据用户使用搜索引擎的行为,来衡量搜索结果是否符合用户喜好、给用户带来好的体验。
专家评估指标 主要包含以下几个:
- 满意度:由用户反馈的人工打分评价。满意度是一个综合立体的评价指标,包含了用户对搜索引擎使用的总体评价,但由于是人工打分产生,容易受到不同打分标准的影响,相对不稳定。
- 基础相关性:同样是由用户反馈的人工打分评价。基本属性同满意度
- 准确率:由用户判断反馈产生。(在每次展示搜索结果后,由用户反馈搜索结果是否准确,最后统计每条搜索结果的准确率)相比于满意度、相关性更加稳定。
- 召回率:基本属性与准确率相似。
总体上来说,专家评估指标都依赖于使用者的反馈,相对不稳定,因此主要用于指导、验证统计学指标的结果。
统计学指标 主要包含以下几个:
- CTR (Click Through Rate) 点击率:数值上等于 “实际点击次数 / 展示次数”。点击率体现了用户对推荐的 网页/内容条目 的喜好程度。
- 停留时长:记录了用户在推荐内容页面的停留时间。停留时长对于网页搜索上应用不广,但在希望延长用户使用时间的目标下,是一个重要的评估指标。
- 点击位置:点击位置反应了搜索结果满足用户需求的程度。点击位置越靠前,说明搜索结果越符合用户需求。
- 用户留存率:用户在使用完产品后,在一段时间后(天、周、月)仍继续使用产品的数量。
在进行算法迭代的过程中,评估改进模型与现有模型效果时,主要有一下几个评估方式:
- Side by side:现有模型与改进模型使用相同的数据作为输入(如相同的quary),逐条比较每一条数据的结果,评估新旧模型有多少条数据变好/基本不变/坏。
- 交叉验证:比较新旧模型的交叉验证评估结果。
- ABTest:常用的基础线上测试评估方式。分别给新旧模型(控制单变量)输入同一层随机互斥的流量,评估比较两个模型的CTR、停留时长等指标。值得注意的是,ABTest一般都是使用同层互斥流量,这必然会占用宝贵的线上流量。若新模型不好,有可能会对用户体验造成损害。(参考:https://www.woshipm.com/pd/1080730.html)
- Interleaving:这个评估方式由ABTest改进而来,比ABTest占用的线上流量更少、灵敏度更高、基本消除了用户之间的差异。Interleaving中,新旧模型接收同一份流量但输出的 搜索/推荐 结果交替混合,通过用户对单挑结果的点击率、停留时长来判断哪个模型更好。(参考链接:https://www.zhihu.com/tardis/zm/art/68509372?source_id=1003)
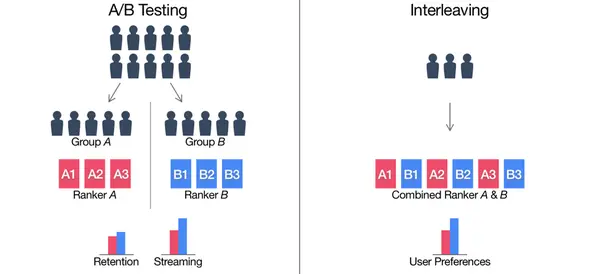
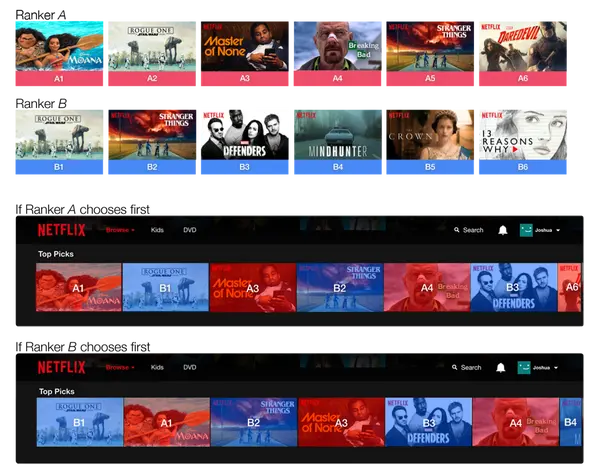 ABTest与Interleaving在推荐页面下的区别
ABTest与Interleaving在推荐页面下的区别
1.3 搜索引擎基础架构图
搜索引擎的架构按照用户搜索行为发生前后,可以分为数据准备与搜索两部分。数据准备阶段主要是为了提取海量数据中的关键信息,为后续的召回搜索阶段做好准备。召回搜索阶段则是依据用户提供的搜索词,从索引库中找到满足用户需求的数据。召回搜索阶段是搜索引擎的核心,其中的排序算法是目前主要的研究改进点。
下面介绍的第2章主要是针对数据准备阶段的,第3、4、5则是召回搜索阶段的。
graph LR A[爬虫/Spider] --> B[DocDB] B --> Doc_Analyse subgraph Doc_Analyse C1[关键词提取] C2[内容分类] C3[内容质量评估] end C1 --> D[(分层倒排索引库)] C2 --> D C3 --> D E[Query Analyse] --> F[召回/召回语法树] D --> F subgraph 排序/LTR G1[粗排] --> G2[精排] G2 --> G3[重排] end F --> 排序/LTR 排序/LTR --> H[展示]2. 内容分析与理解
这一部分的内容对应框架图中的"Doc_Analyse",其核心功能正如其模块的划分可分为:理解内容并提取结构化信息、为内容打上类别标签、评估内容质量。
2.1 关键词/结构化信息提取
第一部分“理解并提取结构化信息”,主要目标是从原始数据中,按照结构提取如文章标题title、正文内容body、外部链接等内容,同时也提取文章的关键词、关键词的词频/紧密度/位置 等信息。
此处涉及的提取算法、应用有:
- 基于规则/简单分类模型的提取算法
- title、Anchor、QAnchor 等关键词的提取
- TF-IDF、词性、词频、位置、互信息、词跨度等的关键词信息提取。
- 基于词图模型的提取算法:TextRank(由PageRank启发而来)
- 基于主题模型的提取算法
- ...
2.2 内容分类
第二部分“为内容打上标签”,主要目标是将内容标记为 小说、视频、音乐、电影/电视、爱情/武侠/悬疑 等类别。此外还可按照内容的组织/结构,分为索引页面、百科页面、问答、bbs(网络论坛)等。
可用作分类的特征有:内容特征、结构特征、URL特征、站点特征、链接特征
此处涉及的分类算法有:
- 朴素贝叶斯、LDA
- SVM、树模型
- 神经网络:TextCNN、BERT
目前效果最好的是神经网络模型,机器学习模型在对处理速度要求较高、算力充足的场景下还在使用。
2.3 内容质量评估
第三部分“评估内容质量”,主要目标是清洗掉Spam(垃圾)并通过利用Doc之间的关系、用户行为信息,计算文档质量的得分(可分为若干档次)。
此处涉及的质量评估算法/指标有:
- PageRank/TrustRank(一般常用于综合搜索)
- HostRank
- AnchorWeight
- 热度、完成度、时长
后三个在垂直搜索场景中比较常用。
3. Query分析
这一章的内容对应框架图中的“Query_Analyse”,这一模块最主要的作用就是从用户输入的搜索信息理解用户的意图。在理解了用户的意图之后,就可以构建查询语法树,为最终的排序准备好query相关特征。
3.1 分词 & 实体分析
由于中文搜索引擎主要面向的是中文用户,所以不同于英文还需要先完成从用户的query中分词。
涉及的分词方法(规则+字典匹配分词):
- 基于字典(知识图谱)、前向匹配、反向匹配、最短路径、双向匹配
- 词义分词法
- 统计分词法
涉及的实例分析(Named-entity recognition)方法:
- 机器学习序列标注模型
- HMM & MEMM & CRF
- 深度学习序列标注模型
- LSTM + CRF
- Attention
- Bert
此外,这一部分还涉及一些其他算法内容:
- TermWeight:
在用户的搜索Query中,有些词在用户的核心语义诉求中占据主导地位,在召回排序时需要着重关注,而有些词语则重要性较低,即使丢掉也不影响核心语义表达。TermWeight是一种自动计算用户查询Query中各term之间相对重要性关系的模块。(参考链接:https://www.jianshu.com/p/37df02e4699b)
- 统计+规则:TF-IDF,词性,信息增益
- 紧密度: 前后词的紧密程度
虽然深度学习模型的效果更好,但由于其对算力要求大、推理速度慢的原因,目前CRF等机器学习模型仍经常使用。
4. 召回/召回语法树
在获得结构化的搜索条目信息、理清用户检索Query关键后,我们需要利用倒排索引对海量搜索条目进行初筛,以介绍后续需处理的条目数量,这个过程称之为召回。一般来说,召回阶段不会进行复杂的计算,主要根据当前的搜索条件对候选条目快速圈定。在此之后,排序阶段的计算复杂度逐渐提高,处理的特征逐渐增多,搜索条目数量逐渐减少,最终获得展示的条目。
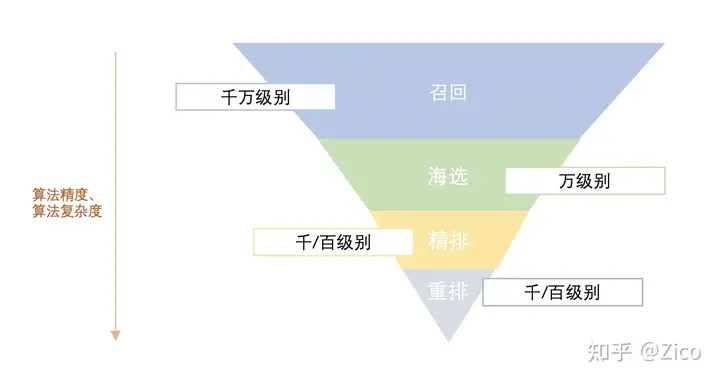
在召回阶段常用的算法为召回语法树,下面主要介绍其涉及的核心语法:(与SQL中的语法很相似)
- AND:“A AND B”要求同时条目同时包含A和B
- OR:“A OR B”要求条目包含A或者B中其一
- RANK: “A RANK B”融合了一些优先级的概念,首先要求条目满足同时包含A和B。若召回数量还没达到,则要求条目包含A的条目也召回回来,直到补足数量为止。
构造语法树所涉及的方法:
- 规则(主要)+ CRF(构建语法树后确定哪些是最优的,哪些是次优的,从而做出选择)
生成语法树过程中,主要使用的特征包含(以此确定树种的每个节点用什么语法,做什么操作):
- 语意切词粒度结果
- term weight
- 词性
- 紧密度
5. 排序算法/LTR (Learn to Rank)
排序算法模块是整个流程里的核心。所谓排序,就是将用户的query、条目特征以及预测目标(如CTR等)交由学习系统学习如何利用query和条目特征预测目标,利用学习好的预测模型在线下/线上测试集中预测相应分数,最后按指标排序确定展示的条目。
5.1 评估排序模型好坏的指标
常见的评估指标有:
- AUC
- MAP:将召回后的文档按照二分类来计算
- DCG、NDCG:认为文档排序的不是简单的二分类,综合了排序中靠后条目计算(更加常用)
参考链接:https://zhuanlan.zhihu.com/p/343424079
5.2 排序模型的分类
正如其名字,排序模型的主要功能是“排序”,即明确条目排列的先后次序。按照这个终极目标,我们在设计模型时有几种不同的设计思路:
- 希望模型学会预测每个条目的绝对分数,最后按照这个绝对分数对条目排序
- 希望模型学会预测2个条目之间的相对分数,最后按照两两之间的先后关系确定所有条目的排列
- 希望模型学会预测 n个/多个 条目之间的先后关系,直接输出排序结果
这几种思路分别对应PointWise、PairWise、ListWise这三大类排序模型。
5.2.1 PointWise
PointWise目前主要在推荐中大量应用
- 基本假设:样本相互独立
- 输入:单个query-doc
- 输出:单个doc的分数
- 损失函数:单doc预测与真实值的差异
常用的基于PointWise的模型:
- 基于回归的算法:线性回归、决策树...
- 基于分类的算法:SVM、LR、GBDT...
- 基于有序回归的算法:Pranking、Margin
PointWise模型存在的问题:
由于Ranking只要求相对得分,因此计算单个样本与query的相关得分,使得模型未考虑样本结构、结果数量、排序位置等因素。
5.2.2 PairWise
PairWise相比PointWise考虑了样本间的相对关系,在搜索中效果相对更好
- 基本假设:样本两两之间的相对好坏决定最终的排序效果
- 输入:query-doc对
- 输出:样本对的相对好坏
- 损失函数:相关度偏好与真实值差异(数值差异的连续值回归 / 相对好坏的离散值分类)
PairWise的常用模型(PointWise --> PairWise)
- SVM --> RankingSVM
- GBDT --> GBRank
- NN --> SoftNet/RankNet
PairWise模型存在的问题:
- 直接标注相对好坏的成本高,若利用现有标注做转化则存在信息损失
- 未考虑样本结构(?)
- 放大样本不平衡性
- 放大噪声影响
- 模型输出的稳定性差(由于输出是相对关系,因此基准不确定)
针对上述问题,LamdaRank模型在损失函数中添加了相对位置的约束,以缓解PairWise模型存在的问题。
5.2.3 ListWise
ListWise最符合用户的使用感受,但从样本标注到各方面所需花费的比PointWise和PairWise大,因此限制了其应用。
- 基本假设:doc整体排列决定排序效果
- 输入:query-doc list
训练样本标签的构造方式:
- 直接标注理想排序
- 利用现有的Point标注/Pair标注构造ListWise序列(精度相比第一种较差)
直接以评价指标作为学习目标建立的模型:
- Loss不可微问题:近似、上界、特殊优化器
- SoftRank,SVM-NDCG,AdaRank
不以评估指标作为学习目标的模型:
- ListNet
ListWise模型存在的问题:
- 复杂度、学习成本高
5.3 决定排序先后的衡量指标
前面介绍了排序模型如何排序的模型算法,但有一个很重要的问题我们还没介绍:所有条目应该使用什么统一的指标进行比较?模型输出的“分数”到底有什么含义?
排序模型常用的学习目标包含:
- 人工标注指标(质量高、适用范围广,但成本高、数量少、样本分布存在偏差)
- 满意度(针对最终排序后用户的反馈,体现最终排序效果)
- 文本相关性
- 质量评分
- 统计类指标
- 点击率 CTR
- 转化率 CVR
- 成交金额 GMV
- 其他
- 主题分类(?)
人工标注类的指标,由于标注成本较大,更适合于数据量较少的场景。统计类指标,可自动统计,所以应用较为广泛。
值得注意的是,这里的“决定排序先后的衡量指标”与前面介绍的“评估排序模型好坏的指标”是不同的。前者是样本条目之间做比较,确定最终展示在用户面前时条目谁先谁后。后者是排序模型之间做比较,确定哪个排序模型更贴合用户所思所想,找到用户最想检索的内容。
5.4 可用于作为排序模型输入的特征
以下特征常作为排序模型的输入:
- Query特征(Query分析阶段提取的特征,略)
- Doc特征(内容分析与理解阶段提取的特征,略)
- QueryDoc特征
- 基础统计类特征
- Click Through Rate, CTR
- Coverage of Title Rate, CTR'
- Coverage of Query Rate, CQR
- BM25
- 其他
- 点击模型预测分数(点击事件未发生)
- 停留时长模型预测分数(点击事件未发生)
- 基础统计类特征
- 内容匹配程度特征
- Query与文档各部分的匹配程度
- Query-title
- Query-anchor
- Query-qanchor
- Query-body
- 传统机器学习模型(如GBDT)预测的匹配分数
- 深度学习模型预测的匹配分数(经历了 DNN -> CNN/CDSSM -> LSTM -> BERT 的变化)
- Query与文档各部分的匹配程度
5.4 从海量数据中 构造/挑选 训练样本
挑选样本的方式主要有两种:
- 点击指引
- 适用场景:排序模型
- 单Session:条目单次展示是否点击/停留时长
- 优点:成本低、样本量大、样本分布与线上吻合
- 缺点:目标偏差、干扰因素多(影响点击的因素很多,如位置bias问题等)、单样本质量差
- 区间统计:一定时间聚合统计 CTR(平均)、中位数时长
- 优点:热门样本质量相对较高
- 缺点:长冷质量差、样本分布偏置、位置偏置
- anchor / qanchor 指引
- 适用场景:文本相关性得分
- 方法:将Anchor/Qanchor与doc有关联的作为正例,Query下CTR低的作为负例
- 优点:质量较高、数据量大、分布与点击互补
- 缺点:长冷doc标注质量差,只适合于PointWise模型
5.5 排序模型的分层及其功能
正如框架图所展示的,排序阶段按照数据流的处理先后依次是:粗排、精排、重排(LTR1、LTR2)。下面简要介绍各个部分的相关细节。
5.5.1 粗排
- 排序对象:召回的每一个doc
- 关键特征
- 主题匹配度
- 紧密度满足程度
- 权威性得分
- 网页质量
- CQR、CTR、QT-BM25等
- 模型:规则 + 人工拟合的简单线性模型
- 输出:每个数据分片Top几百(总量万级别)
5.5.2 精排
- 排序对象:粗排结构doc
- 关键特征
- 粗排特征精细化
- Qanchor / Anchor / 点击 等新特征
- 模型:规则 + 人工拟合的简单线性模型
- 输出:每个数据分片的top几十(总量千级别)
5.5.3 重排
- 重排-LTR1
- 排序对象:精排后Top数千的doc
- 特征:精排特征、文本分特征、Qanchor模型、质量模型
- 模型:LamdaRank
- 输出:Top几百
- 重排-LTR2
- 排序对象:重排top几十
- 特征:添加各种NN模型特征
- 模型:LamdaRank
- 重排-点击模型
- 对象:框计算 + 网页结果的第一页
- 模型:点击模型 + 规则