
背景介绍
当我们做一些推荐系统网站时,通常需要合适的推荐算法,下面给大家介绍推荐系统中经典的推荐算法——协同过滤算法。在本文中通过Python语言,以一个图书推荐系统为案例,最终实现一个基于用户对图书的评分而对指定的用户个性化推荐的网站系统。(ps:本文中介绍的是算法的简单示例,如需项目功能扩展,可在最下方联系我)
协同过滤算法
协同过滤是一种常用于推荐系统中的算法,用于预测用户可能感兴趣的物品或内容。它的核心思想是基于用户行为和相似性来进行预测,而不依赖于物品或用户的内容特征。协同过滤算法根据用户和物品之间的交互历史,发现用户之间的相似性或物品之间的相似性,从而为用户生成个性化的推荐列表。
协同过滤算法可以分为两种主要类型:基于用户的协同过滤和基于物品的协同过滤。
- 基于用户的协同过滤: 这种方法首先计算用户之间的相似性,然后利用与目标用户相似的其他用户的偏好来预测目标用户对物品的评分或喜好。基于用户的协同过滤通常包括以下步骤:
- 相似性计算: 使用一些相似性度量(如余弦相似度、皮尔逊相关系数等)来计算用户之间的相似性。
- 邻居选择: 选取与目标用户最相似的一些用户作为邻居。
- 预测生成: 利用邻居用户对物品的评分来预测目标用户对尚未互动过的物品的评分。
- 基于物品的协同过滤: 这种方法通过计算物品之间的相似性来预测用户对尚未互动过的物品的评分或喜好。基于物品的协同过滤一般包括以下步骤:
- 相似性计算: 计算物品之间的相似性,通常与用户的历史行为相关。
- 邻居选择: 选取与目标物品最相似的一些物品作为邻居。
- 预测生成: 基于目标用户对邻近物品的评分,预测用户对尚未互动过的物品的评分。
协同过滤算法的优点在于它能够捕捉用户和物品之间的复杂关系,从而提供个性化的推荐。然而,它也面临一些挑战,比如“冷启动”问题(新用户或新物品如何进行推荐)、数据稀疏性(用户和物品之间的交互数据可能非常少)、推荐偏差(可能会忽视一些长尾物品)等。
代码示例
在本文中通过使用Django框架作为网站开发的后端框架。其数据表模型结构如下:
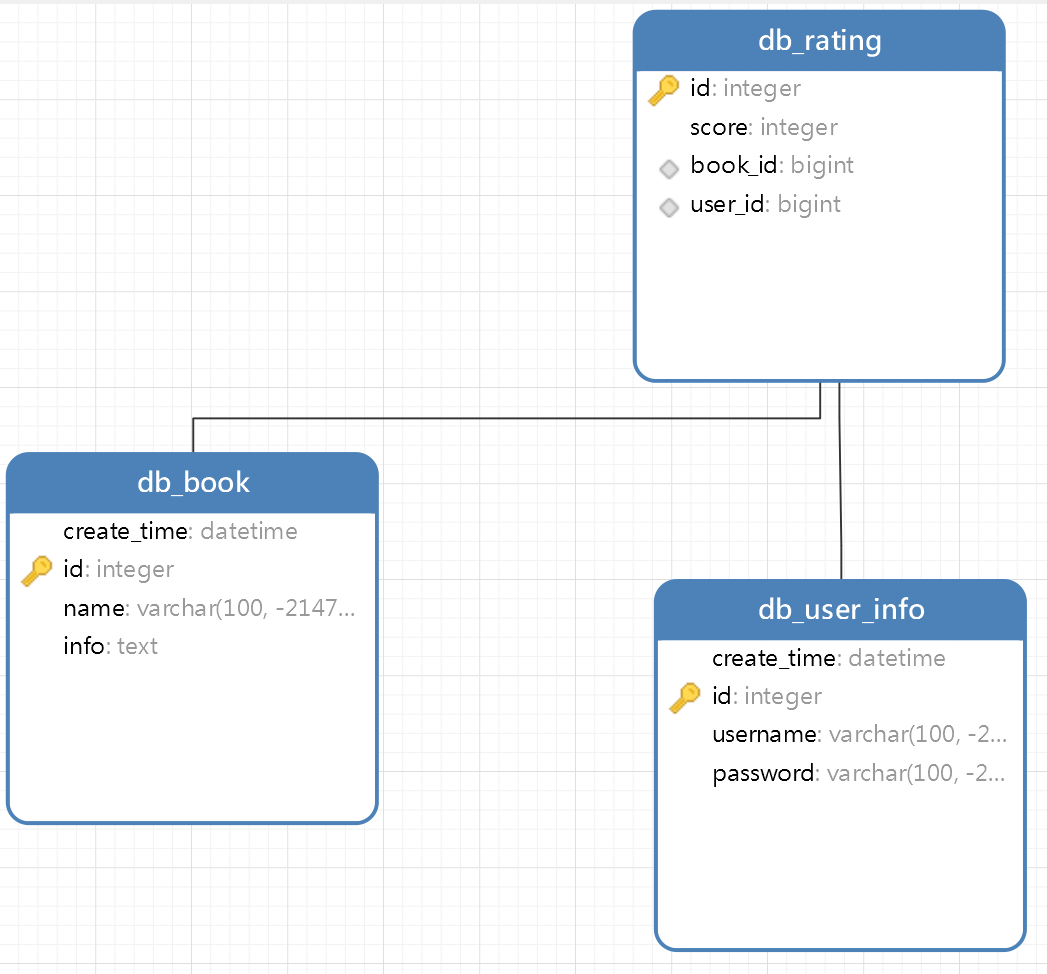
db_user_info:用户信息表db_book:书籍表db_rating:书籍评分表
在本文中通过使用基于用户的协同过滤算法,在计算相似度时选用余弦相似度计算公式。余弦相似度衡量两个向量之间的方向一致程度。在这里,向量是用户对共同评价过的图书的评分。余弦相似度计算公式为:
$$
cosine_similarity = \frac{\sum_{i} user1_scores[i] \times user2_scores[i]}{\sqrt{\sum_{i} user1_scores[i]^2} \times \sqrt{\sum_{i} user2_scores[i]^2}}
$$
代码如下:
def calculate_cosine_similarity(user_ratings1, user_ratings2):
# 将用户1的图书评分存入字典,键为图书ID,值为评分
book_ratings1 = {rating.book_id: rating.score for rating in user_ratings1}
# 将用户2的图书评分存入字典,键为图书ID,值为评分
book_ratings2 = {rating.book_id: rating.score for rating in user_ratings2}
# 找出两个用户共同评价过的图书
common_books = set(book_ratings1.keys()) & set(book_ratings2.keys())
if len(common_books) == 0:
return 0.0 # 无共同评价的图书,相似度为0
# 提取共同评价图书的评分,存入NumPy数组
user1_scores = np.array([book_ratings1[book_id] for book_id in common_books])
user2_scores = np.array([book_ratings2[book_id] for book_id in common_books])
# 计算余弦相似度
cosine_similarity = np.dot(user1_scores, user2_scores) / (
np.linalg.norm(user1_scores) * np.linalg.norm(user2_scores))
return cosine_similarity
其中,user1_scores 和 user2_scores 是两个用户的评分向量,i 是共同评价过的图书的索引。实现步骤如下:
首先遍历所用其他的用户,对于每个其他用户计算与目标用户的余弦相似度。如果相似度大于0,那么遍历其他用户评价的图书,创建推荐记录包括加权评分和相似度。然后按照分数大小降序排列。将对应的图书名称信息等返回给用户。
实验效果
Python网站开发、项目订制、请联系V:sql2201
标签:Python,过滤,用户,评分,算法,book,scores,物品 From: https://www.cnblogs.com/shiqianlong/p/17664548.html