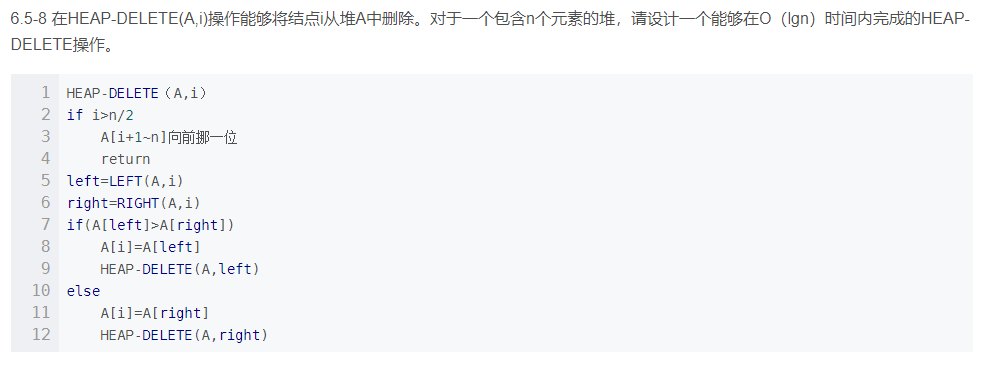
八、HEAP-DELETE(A,i)操作能够将结点 i 从堆 A 中删除。对于一个包含 n个元素的堆,请设计一个能够在 O(lgn)时间内完成的 HEAP-DELETE 操作。
文心一言:
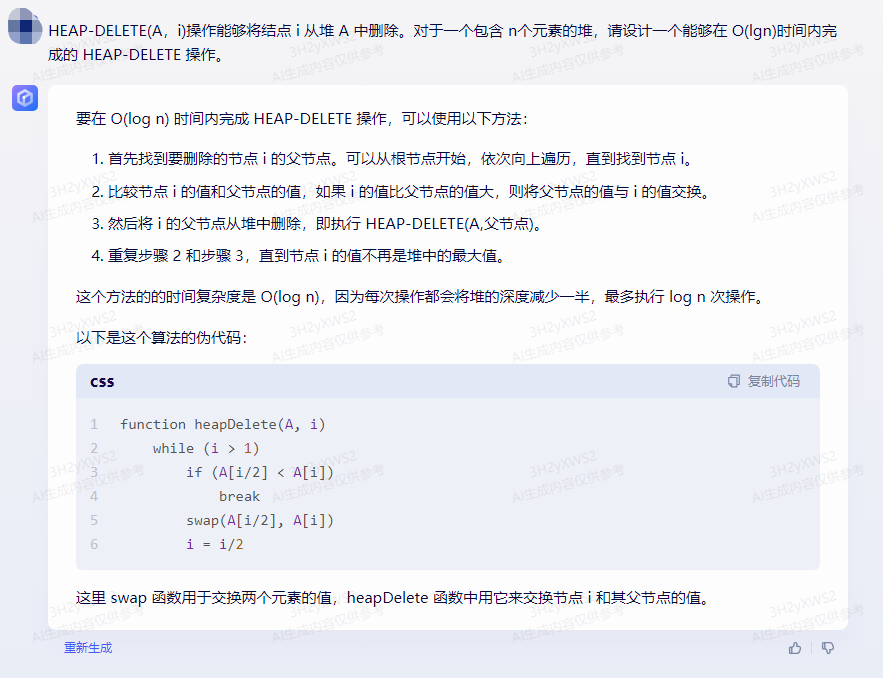
要在 O(log n) 时间内完成 HEAP-DELETE 操作,可以使用以下方法:
1.首先找到要删除的节点 i 的父节点。可以从根节点开始,依次向上遍历,直到找到节点 i。
2.比较节点 i 的值和父节点的值,如果 i 的值比父节点的值大,则将父节点的值与 i 的值交换。
3.然后将 i 的父节点从堆中删除,即执行 HEAP-DELETE(A,父节点)。
4.重复步骤 2 和步骤 3,直到节点 i 的值不再是堆中的最大值。
这个方法的的时间复杂度是 O(log n),因为每次操作都会将堆的深度减少一半,最多执行 log n 次操作。
以下是这个算法的伪代码:
function heapDelete(A, i)
while (i > 1)
if (A[i/2] < A[i])
break
swap(A[i/2], A[i])
i = i/2
这里 swap 函数用于交换两个元素的值,heapDelete 函数中用它来交换节点 i 和其父节点的值。
讯飞星火:
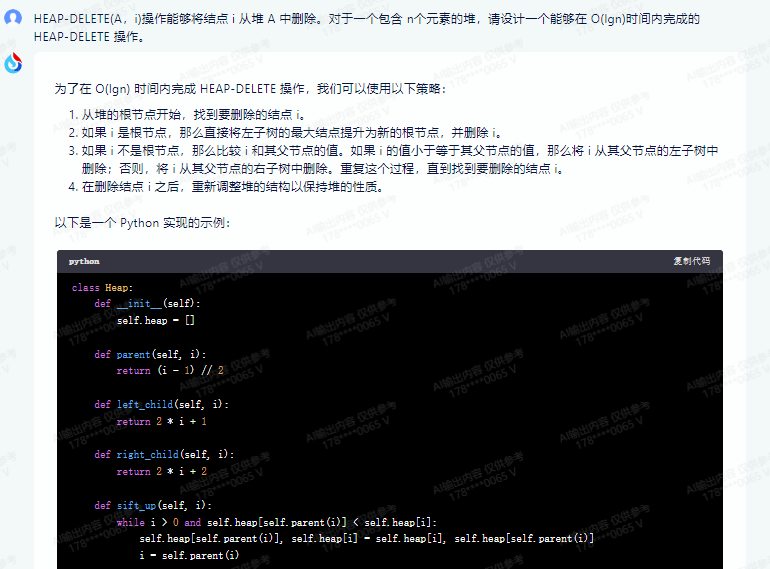
为了在 O(lgn) 时间内完成 HEAP-DELETE 操作,我们可以使用以下策略:
1.从堆的根节点开始,找到要删除的结点 i。
2.如果 i 是根节点,那么直接将左子树的最大结点提升为新的根节点,并删除 i。
3.如果 i 不是根节点,那么比较 i 和其父节点的值。如果 i 的值小于等于其父节点的值,那么将 i 从其父节点的左子树中删除;否则,将 i 从其父节点的右子树中删除。重复这个过程,直到找到要删除的结点 i。
4.在删除结点 i 之后,重新调整堆的结构以保持堆的性质。
以下是一个 Python 实现的示例:
class Heap:
def __init__(self):
self.heap = []
def parent(self, i):
return (i - 1) // 2
def left_child(self, i):
return 2 * i + 1
def right_child(self, i):
return 2 * i + 2
def sift_up(self, i):
while i > 0 and self.heap[self.parent(i)] < self.heap[i]:
self.heap[self.parent(i)], self.heap[i] = self.heap[i], self.heap[self.parent(i)]
i = self.parent(i)
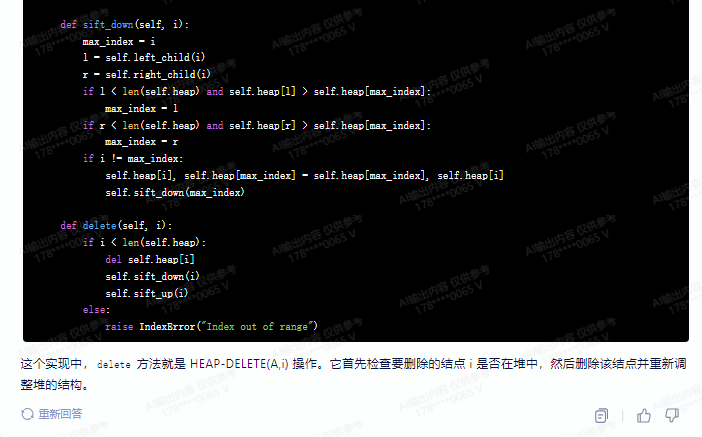
def sift_down(self, i):
max_index = i
l = self.left_child(i)
r = self.right_child(i)
if l < len(self.heap) and self.heap[l] > self.heap[max_index]:
max_index = l
if r < len(self.heap) and self.heap[r] > self.heap[max_index]:
max_index = r
if i != max_index:
self.heap[i], self.heap[max_index] = self.heap[max_index], self.heap[i]
self.sift_down(max_index)
def delete(self, i):
if i < len(self.heap):
del self.heap[i]
self.sift_down(i)
self.sift_up(i)
else:
raise IndexError("Index out of range")
这个实现中,delete 方法就是 HEAP-DELETE(A,i) 操作。它首先检查要删除的结点 i 是否在堆中,然后删除该结点并重新调整堆的结构。
360智脑:
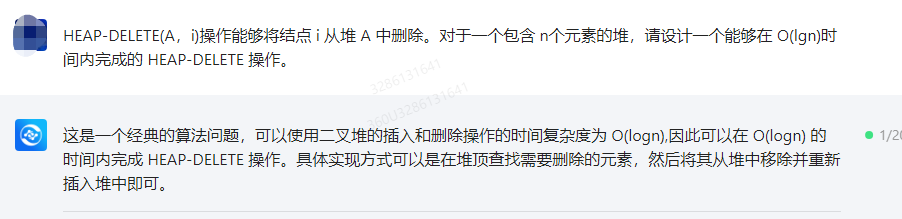
这是一个经典的算法问题,可以使用二叉堆的插入和删除操作的时间复杂度为 O(logn),因此可以在 O(logn) 的时间内完成 HEAP-DELETE 操作。具体实现方式可以是在堆顶查找需要删除的元素,然后将其从堆中移除并重新插入堆中即可。
chatglm:
为了设计一个能够在 O(lgn) 时间内完成的 HEAP-DELETE 操作,我们可以使用二分查找的方法来找到结点 i 在堆中的位置。具体步骤如下:
1.初始化一个指针 p,指向堆 A 中的第一个元素。
2.使用二分查找的方法,找到结点 i 在堆中的位置。具体来说,我们可以先将 p 指向堆的中间位置,然后分别比较 p 左边和右边的元素与 i 的大小关系。如果 p 左边的元素比 i 小,则说明 i 在 p 左边的子树中;否则,如果 p 左边的元素比 i 大,则说明 i 在 p 右边的子树中。我们可以根据这个判断,将 p 指向对应的子树中,并重复上述步骤,直到找到结点 i。
3.将堆顶元素(即 p 指向的元素)与结点 i 交换位置。
4.调整堆,使得交换后的堆仍满足堆的性质。具体来说,我们可以从 p 开始,依次向下调整堆,直到调整到叶子节点为止。
由于使用二分查找的方法,每次查找都可以将查找范围缩小一半,因此,对于一个包含 n 个元素的堆,最多需要进行 logn 次查找。而且,在调整堆的过程中,我们只需要对涉及到的元素进行交换和调整,因此,总的时间复杂度为 O(lgn)。
因此,我们可以设计一个能够在 O(lgn) 时间内完成的 HEAP-DELETE 操作,具体实现如下:
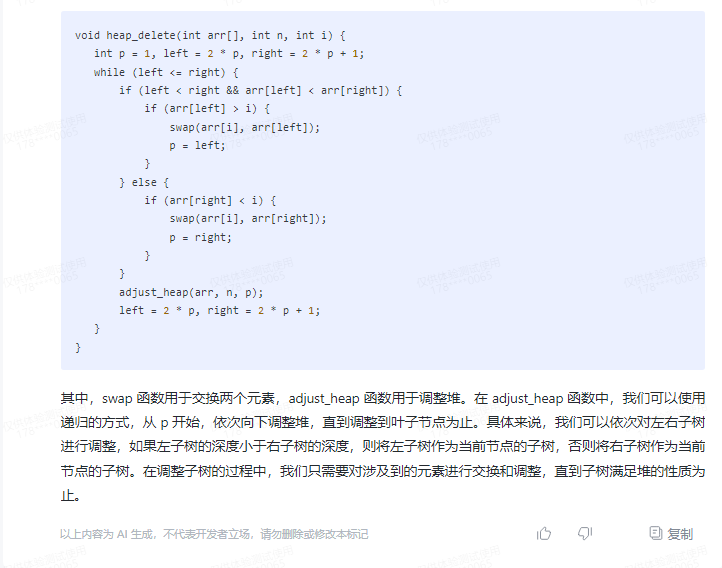
void heap_delete(int arr[], int n, int i) {
int p = 1, left = 2 * p, right = 2 * p + 1;
while (left <= right) {
if (left < right && arr[left] < arr[right]) {
if (arr[left] > i) {
swap(arr[i], arr[left]);
p = left;
}
} else {
if (arr[right] < i) {
swap(arr[i], arr[right]);
p = right;
}
}
adjust_heap(arr, n, p);
left = 2 * p, right = 2 * p + 1;
}
}
其中,swap 函数用于交换两个元素,adjust_heap 函数用于调整堆。在 adjust_heap 函数中,我们可以使用递归的方式,从 p 开始,依次向下调整堆,直到调整到叶子节点为止。具体来说,我们可以依次对左右子树进行调整,如果左子树的深度小于右子树的深度,则将左子树作为当前节点的子树,否则将右子树作为当前节点的子树。在调整子树的过程中,我们只需要对涉及到的元素进行交换和调整,直到子树满足堆的性质为止。

通义千问:
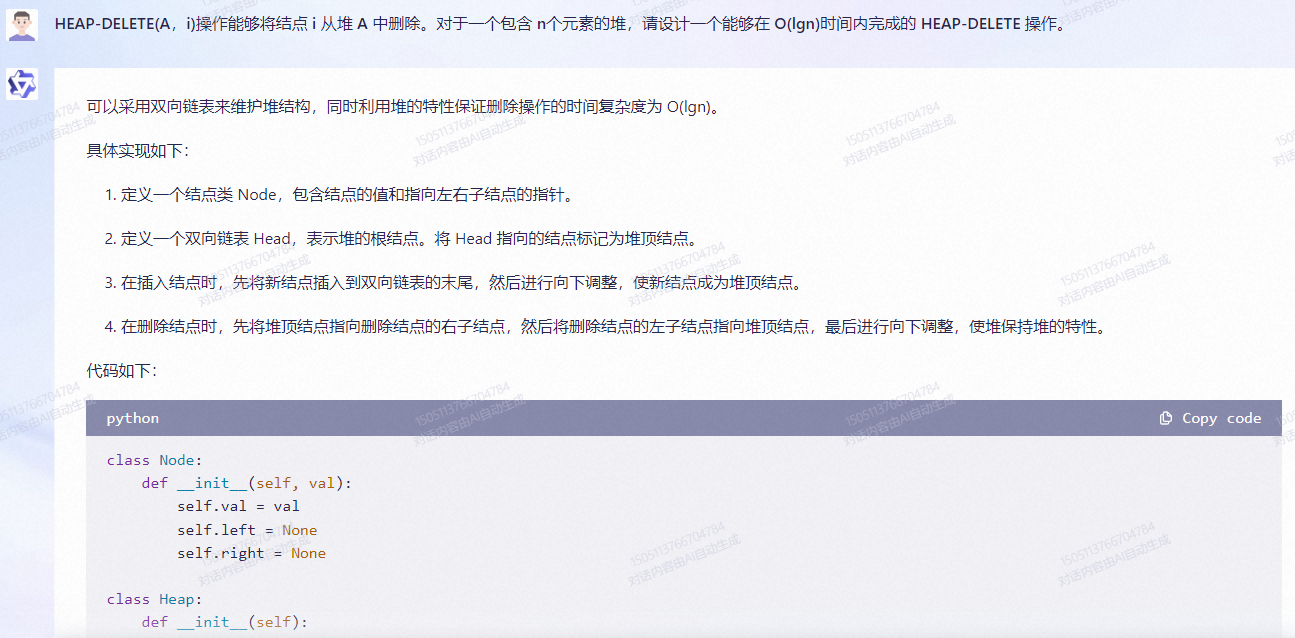
可以采用双向链表来维护堆结构,同时利用堆的特性保证删除操作的时间复杂度为 O(lgn)。
具体实现如下:
1.定义一个结点类 Node,包含结点的值和指向左右子结点的指针。
2.定义一个双向链表 Head,表示堆的根结点。将 Head 指向的结点标记为堆顶结点。
3.在插入结点时,先将新结点插入到双向链表的末尾,然后进行向下调整,使新结点成为堆顶结点。
4.在删除结点时,先将堆顶结点指向删除结点的右子结点,然后将删除结点的左子结点指向堆顶结点,最后进行向下调整,使堆保持堆的特性。
代码如下:
class Node:
def __init__(self, val):
self.val = val
self.left = None
self.right = None
class Heap:
def __init__(self):
self.head = None
def heapify(self, node, i):
largest = node
l = 2 * i + 1
r = 2 * i + 2
# 找到左右子结点,并比较大小
if l < len(self) and self[l].val > largest.val:
largest = self[l]
if r < len(self) and self[r].val > largest.val:
largest = self[r]
# 如果当前结点大于最大结点,则交换位置,并进行向下调整
if largest != node:
self[largest.val, :].left = node
node.left = self[largest, :]
self[largest, :].right = node
node.right = self[largest, :]
# 如果左子结点存在,则进行向下调整
if l < len(self) and self[l].val > node.val:
self.heapify(self[l], l)
# 如果右子结点存在,则进行向下调整
if r < len(self) and self[r].val > node.val:
self.heapify(self[r], r)
def insert(self, val):
new_node = Node(val)
# 如果堆为空,则创建一个新的堆
if not self.head:
self.head = new_node
new_node.left = new_node.right = None
return
# 将新结点插入到双向链表的末尾
new_node.left = self.head
self.head.right = new_node
# 进行向下调整,使新结点成为堆顶结点
self.heapify(new_node, 0)
def delete(self, val):
# 定位删除结点的位置
i = self.search(val)
# 如果删除结点不存在,则返回空
if i == -1:
return
# 将堆顶结点指向删除结点的右子结点
self.head.left = self[i].right
# 将删除结点的左子结点指向堆顶结点
self[i].left = self.head
# 进行向下调整,使堆保持堆的特性
self.heapify(self.head, 0)
def search(self, val):
# 遍历整个堆,查找是否存在该结点
for i in range(len(self) - 1, -1, -1):
if self[i].val == val:
return i
return -1



天工:
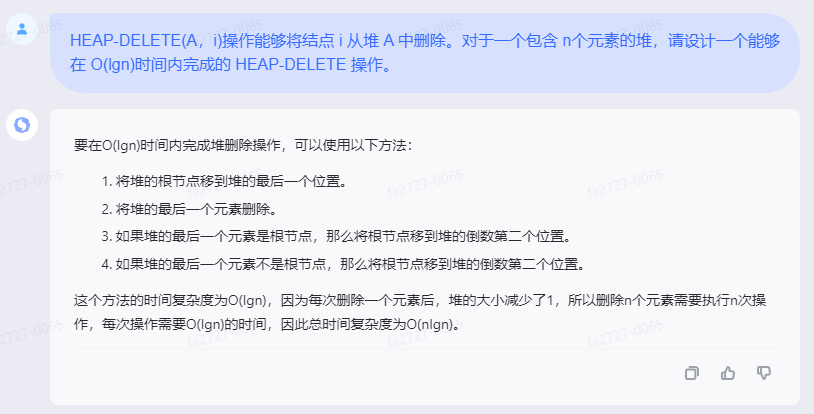
要在O(lgn)时间内完成堆删除操作,可以使用以下方法:
1.将堆的根节点移到堆的最后一个位置。
2.将堆的最后一个元素删除。
3.如果堆的最后一个元素是根节点,那么将根节点移到堆的倒数第二个位置。
4.如果堆的最后一个元素不是根节点,那么将根节点移到堆的倒数第二个位置。
这个方法的时间复杂度为O(lgn),因为每次删除一个元素后,堆的大小减少了1,所以删除n个元素需要执行n次操作,每次操作需要O(lgn)的时间,因此总时间复杂度为O(nlgn)。
chatgpt:
要设计一个能够在 O(lgn) 时间内完成 HEAP-DELETE 操作,可以按照以下步骤进行:
1.首先,将要删除的节点与堆的最后一个节点进行交换。这样做可以保持堆的完全性质。
- 将堆中第 i 个节点与最后一个节点进行交换。
2.接下来,调整交换后的堆,使其仍然满足堆的性质。
-
如果交换后的节点比其父节点更小(对于最小堆)或者更大(对于最大堆),则需要将该节点向上移动。
-
如果交换后的节点比其子节点更大(对于最大堆)或者更小(对于最小堆),则需要将该节点向下移动。
3.重复步骤 2,直到堆的性质被恢复。
下面是一个示例的实现(使用 Python):
def heap_delete(A, i):
n = len(A)
if i < 0 or i >= n:
return A # 如果 i 不在有效范围内,直接返回原堆
A[i], A[n-1] = A[n-1], A[i] # 交换要删除的节点与最后一个节点
# 向上调整
while i > 0 and A[i] < A[(i-1)//2]:
A[i], A[(i-1)//2] = A[(i-1)//2], A[i]
i = (i-1)//2
# 向下调整
while True:
left = 2*i + 1
right = 2*i + 2
smallest = i
if left < n and A[left] < A[smallest]:
smallest = left
if right < n and A[right] < A[smallest]:
smallest = right
if smallest != i:
A[i], A[smallest] = A[smallest], A[i]
i = smallest
else:
break
return A[:-1] # 返回删除节点后的堆(去掉最后一个节点)
该实现通过不断地向上调整和向下调整的过程,保持了堆的性质,并且在最坏情况下的时间复杂度为 O(lgn)。
总结