正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程: 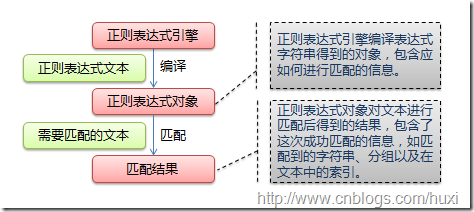
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法: 
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
re模块
re 模块为Python的内置模块,Python程序中通过这个模块来使用正则表达式。
re 模块的使用
re 模块有两种使用方式,示例中以match方法为例。
方式 1:
步骤:
1)直接使用 re.match 方法(传入正则表达式和需要匹配的字符串)对文本进行匹配查找,match方法返回一个 Match 对象
2)使用 Match 对象提供的方法获取匹配结果示例:
import re
m = re.match(r'\d+', '123abc456') # 返回一个 Match 对象
print(m.group()) # 输出匹配结果:123方式 2:
步骤:
1)使用 re.compile 方法(传入正则表达式)得到 Pattern 对象
2)通过 Pattern 对象提供的方法对字符串进行匹配查找,返回一个 Match 对象(包含了匹配结果)
3)使用 Match 对象提供的方法获取匹配结果示例:
import re
pattern = re.compile(r'\d+') # 返回一个 Pattern 对象
m = pattern.match('123abc456') # 返回一个 Match 对象
print(m.group()) # 输出匹配结果:123如上2种方式的区别在于,第二种方式通过 re.compile 方法获取一个 Pattern 对象,使得一个正则表达式被多次用于匹配;而第一种方式,每一次的匹配都需要传入正则表达式。
compile方法
re.compile(pattern[, flag])示例中的 compile 方法用于编译正则表达式,返回一个 Pattern 对象,可利用 Pattern 对象中的一系列方法对字符串进行匹配查找。Pattern 对象中的常用方法包括:match,search,findall,finditer,split,sub,subn。当然这些方法也可以使用 re模块直接调用~
match方法
match 方法用于从字符串的头部开始匹配,仅返回第一个匹配的结果~
pattern.match(string[, pos[, endpos]])
或
re.match(pattern, string[, flags])pattern.match(string[, pos[, endpos]]) 中的 pos,endpos指定字符串匹配的起始和终止位置,这两个均为可选参数,若不指定,默认从字符串的开头开始匹配~
re.match(pattern, string[, flags]) 中的pattern为传入的正则表达式,flags指定匹配模式,如忽略大小写,多行模式,同compile方法中的flag参数~
分组匹配
可以通过在正则表达式中使用小括号'()',来对匹配到的数据进行分组,然后通过group([n]),groups()获取对应的分组数据。
import re
pattern = re.compile('([0-9]*)([a-z]*)([0-9]*)')
m = pattern.match('123abc456')
# 输出匹配的完整字符串
print(m.group()) # 123abc456
# 同上,输出匹配的完整字符串
print(m.group(0)) # 123abc456
# 从匹配的字符串中获取第一个分组
print(m.group(1)) # 123
# 从匹配的字符串中获取第二个分组
print(m.group(2)) # abc
# 从匹配的字符串中获取第三个分组
print(m.group(3)) # 456
# 从匹配的字符串中获取所有分组,返回为元组
print(m.groups()) # ('123', 'abc', '456')
# 获取第二个分组 在字符串中的起始位置(分组第一个字符的索引),start方法的默认参数为0,即字符串的起始索引
print(m.start(2)) # 3
# 获取第二个分组 在字符串中的起始位置(分组最后一个字符的索引+1),通start方法,end方法的默认参数也为0,即字符串结尾的索引+1
print(m.end(2)) # 6
# 第三个分组的起始和结束位置,即 (start(3), end(3))
print(m.span(3)) # (6, 9)
# 同 (start(), end())
print(m.span()) # (0, 9)上述中的 group(),groups(),start(),end(),span() 方法均为 Match类中的方法,这些方法主要用于从匹配的字符串中(或者说是从 Match对象中)获取相关信息~
re 模块下的常用方法
re 模块中较为常用的方法除了 compile() 和 match() 方法,还有下面列出的这些~
search 方法
不同于match方法的从头开始匹配,search方法用于在字符串中的进行查找(从左向右进行查找),只要找到一个匹配结果,就返回 Match 对象,若没有则返回None~
search(string[, pos[, endpos]])
# 可选参数 pos,endpos 用于指定查找的起始位置和结束位置,默认 pos 为0,endpos为字符串长度示例:re.search
import re
pattern = re.compile(r'[a-z]+')
m = pattern.match('123abc456cde')
print(m) # None
m = pattern.search('123abc456cde') # 或者 m = re.search(r'[a-z]+', '123abc456')
print(m.group()) # abc由于match是从头开始匹配,所以这里匹配不到结果~
findall 方法
match方法 和search方法 仅会返回一个结果,findall方法会将字符串中的所有匹配结果以列表的形式返回,注意,返回的是列表,不是 Match 对象~
findall(string[, pos[, endpos]])
# 可选参数 pos,endpos 用于指定查找的起始位置和结束位置,默认 pos 为0,endpos为字符串长度示例:
import re
pattern = re.compile(r'[a-z]+')
res = pattern.findall('123abc456cde')
print(res)
# 执行结果:
['abc', 'cde']findall方法的优先级查询,findall方法会优先把匹配结果组里的内容进行返回,来看如下示例:
import re
pattern = re.compile('\d([a-z]+)\d')
print(pattern.findall('123abc456'))
# 输出结果:
['abc']
其实我们想要的结果是 '3abc4',但是findall方法会优先返回分组中的内容,即 'abc'。若要想要匹配结果,取消权限即可,就是在小括号的起始位置加上 '?:'
import re
pattern = re.compile('\d(?:[a-z]+)\d')
print(pattern.findall('123abc456'))
# 输出结果:
['3abc4']finditer 方法
finditer 方法与 findall方法类似,会查找整个字符串并返回所有匹配的结果,返回的是一个迭代器,且每一个元素为 Match 对象~
import re
pattern = re.compile(r'\d+')
res = pattern.finditer('#123abc456cde')
for i in res:
print(i.group())
# 输出结果:
123
456split 方法
split方法用于将字符串进行切割,切割使用的分隔符就是字符串中被匹配到的子串,将被切割后的子串以列表的形式返回~
split(string[, maxsplit])
# maxsplit 参数用于指定最大分割次数,默认会将这个字符串分割示例:
import re
pattern = re.compile(r'\d+')
m = pattern.split('abc23de3fgh3456ij') # 或者直接 re.split('\d+','abc23de3fgh3ij')
print(m)
# 结果输出:
['abc', 'de', 'fgh', 'ij']正则表达式中添加括号后,则会保留分隔符
import re
ret = re.split("(\d+)", "abc23de3fgh3456ij")
print(ret)
# 结果输出”
['abc', '23', 'de', '3', 'fgh', '3456', 'ij']sub 方法
sub方法用于将字符串中匹配的子串替换为指定的字符串
pattern.sub(repl, string[, count])
或者
re.sub(pattern, repl, string[, count])count为可选参数,指定最大替换次数,repl 可以是一个字符串,也可以是一个 \id 引用匹配到的分组(但不能使用 \0),还可以是一个方法,该方法仅接受一个参数(Match对象),且返回一个字符串~
1)repl 是一个字符串
import re
ret = re.sub(r'\d+', '###', 'abc123cde')
print(ret)
# 输出结果:
abc###cde2)repl 是一个分组引用
将类似于 'hello world' 这样的字符串前后两个单词替换~
import re
ret = re.sub(r'(\w+) (\w+)', r'\2 \1', 'hello world; hello kitty')
print(ret)
# 输出结果:
world hello; kitty hello3)repl是一个方法
import re
def func(m):
return 'hi' + ' ' + m.group(2)
ret = re.sub(r'(\w+) (\w+)', func, 'hello world; hello kitty')
print(ret)
# 输出结果:
hi world; hi kittysubn方法
subn方法和sub方法类似,subn方法会返回一个元组,元组有两个元素,第一个元素与sub方法返回的结果一致,第二个元素为字符串中被替换的子串个数
import re
def func(m):
return 'hi' + ' ' + m.group(2)
ret = re.subn(r'\d+', '###', 'abc123cde')
print(ret)
ret = re.subn(r'(\w+) (\w+)', r'\2 \1', 'hello world; hello kitty')
print(ret)
ret = re.subn(r'(\w+) (\w+)', func, 'hello world; hello kitty')
print(ret)
# 输出结果:
('abc###cde', 1)
('world hello; kitty hello', 2)
('hi world; hi kitty', 2)贪婪匹配 和 非贪婪匹配
正则匹配默认使用的就是贪婪匹配,也就是尽可能的多匹配,如下示例为贪婪匹配:
import re
m = re.match('[a-z]+', 'abc123def')
print(m.group())
# 输出结果:
abc同一示例使用非贪婪匹配,在正则后面加上一个 '?' 即可,注意这个问号不是代表0个或者一个(注意区分):
import re
m = re.match('[a-z]+?', 'abc123def')
print(m.group())
# 输出结果:
a
贪婪匹配(单单使用 ?),?重复0个或者1个,贪婪模式下匹配一个
ret=re.findall('13\d?','1312312312, 134, 34234, 2313')
print(ret)
# 输出结果:
['131', '134', '13']
惰性匹配示例:
ret=re.findall('131\d+?','1312312312')
print(ret)
# 输出结果:
['1312']正则表达式补充
转义符 \
1、反斜杠后边跟元字符去除特殊功能, 比如.
2、反斜杠后边跟普通字符实现特殊功能, 比如\d
\d 匹配任何十进制数; 它相当于类 [0-9]。
\D 匹配任何非数字字符; 它相当于类 [^0-9]。
\s 匹配任何空白字符; 它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符; 它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符; 它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符; 它相当于类 [^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格 ,&,#等
让我们看一下 \b 的应用:
ret=re.findall(r'I\b','I am LIST')
print(ret) # ['I']
Tip:
如上示例中 ret=re.findall(r'I\b','I am LIST') 使用的是 r'I\b' 而不能使用 'I\b' ,解释如下:
Python程序在这里的执行过程分为2步:
第一步:python 解释器读取 'I\b' 字符串进行解析,解析完成后传递给 re 模块
第二步:re 模块 对接收到的字符串进行解析
在第一步中,'\b' 和 '\n' 类似,对于Python解释器而言,有特殊的意义,Python解释器针对 '\b' 和 '\n' 会根据ASCII码表进行翻译,翻译完成之后再传递给 re 模块进行后续的处理;所以 re 模块获取到的不会是 原模原样的 'I\b'。这里若要让 re 模块接收到原模原样的 'I\b',有两种方式:
1)在字符串中使用 \ ,将 \b 转义
re.findall('I\\b','I am LIST')
2)直接在字符串前面加 r,使字符串中的 \b 失效,建议使用这种方式
re.findall(r'I\b','I am LIST')
还有一种情况,要匹配的字符串本身就包含 '\' , 例如匹配 'hello\kitty' 中的 'o\k'
分析:\ 对于re 模块而言,有转义的意思,所以 re 模块希望获取到的字符串规则是 'o\k',也就是说Python解释器解析完字符串后传递给 re 模块的是 'o\k'(如果直接使用 re.findall('o\k','hello\kitty') ,re模块获取到的是 'o\k'),所以这里也有两种实现方式:
1)re.findall(r'o\\k','hello\kitty') ,建议使用这种方式
2)针对2个 \ 分别进行转义
re.findall('o\\\\k','hello\kitty')也许这里会有疑问,re.findall("1\d?", "123,12345235,124234,1,abc,13") ,为何这里的\d 可以直接使用,那是因为 \d 在ASCII码表里面没有对应的字符串(Python解释器对 \d 不会进行翻译),所以可以直接使用。ASCII码表中和 '\' 连用的特殊字符见下图:
元字符之|
|表示 或者,使用 | 时一般需要和 括号配合使用,不然无法区分 | 的左边与右边
import re
ret = re.search('(ab)|\d','#@123abc') # 匹配 ab 或者 数字,search仅会返回第一个匹配到的
print(ret.group()) # 1字符集[]的是使用
import re
# [bc] 表示仅匹配 b 或者 c,如下示例中表示,匹配 abd 或者 acd
ret = re.findall('a[bc]d','acd')
print(ret) #['acd']
# [a-zA-Z] : 所有大小写字母
# [a-zA-Z0-9] : 所有大小写字母及数字
# [a-zA-Z0-9_] : 所有大小写字母及数字,再加上一个下划线
ret = re.findall('[a-z]','acd') # 匹配所有小写字母
print(ret) #['a', 'c', 'd']
# 注意:元字符在 字符集[] 中没有任何效果,这里的 . 和 + 就是普通的符号,有效果的元字符包括:- ^ \
ret = re.findall('[.*+]','a.cd+')
print(ret) #['.', '+']
# - 表示范围符号
ret = re.findall('[1-9]','45dha3') # 匹配数字 1 至 9
print(ret) #['4', '5', '3']
# ^ 表示取反,即匹配 非a,非b的字符
ret = re.findall('[^ab]','45bdha3')
print(ret) #['4', '5', 'd', 'h', '3']
# \ 为转义符
ret = re.findall('[\d]','45bdha3')
print(ret) #['4', '5', '3']