转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/3bbc3146.html
你好,我是测试蔡坨坨。
众所周知,Python语法简洁、功能强大,通过简单的代码就能实现很多实用、有趣的功能,因为它拥有丰富的标准模块和第三方库,因此也成为自动化测试的热门语言,当然除了Python,其他编程语言也能做自动化,至于自动化测试选择什么编程语言,可参考往期文章「做自动化测试选择 Python 还是 Java?」。
要想使用Python语言编写脚本或开发平台进行自动化测试,首先需要学习Python基础语法,通过本篇文章,带你快速入门Python并掌握Python基础语法。
Python简介
背景介绍
Python的格言:Life is short,use python. 即“人生苦短,我用Python。”
由Guido van Rossum于1989年圣诞节为打发无聊的时间,而开发的一个新的脚本解释程序,第一个公开发行版本于1991年。
至于为什么选中Python作为语言名字,是因为他是一个叫Monty Python的喜剧团队爱好者。
特点
优势
- 优雅、明确、简单。
- Python是一个下限特别低(少儿编程),上限特别高的编程语言(人工智能)。
- 上手容易,特别适合没有编程经验的小白作为第一门编程语言,特别容易培养兴趣。
- 语法简洁,表达能力强,通过简单代码就能实现很多实用的功能。
- 代码量小,维护成本低,编程效率高,标准库强大,第三方库非常丰富(比如自动化测试会用到的Selenium、Appium、Requests等),目前已经成为全世界最广泛使用的编程语言之一。
- 同样的问题,用不同的语言解决,代码量差距多,一般情况下Python是Java的1/5,Java需要十行,Python可能只需要两行,所以说人生苦短,我用Python,多留点时间做点自己喜欢的事情吧,不要浪费太多时间在编码上面。
- 解释运行。Python是一种解释型语言(脚本语言)。和
C/C++不同,不是先将源代码文件转化成可执行文件,再执行,而是直接由Python解释器一行一行的读取源代码,每读一行就执行一行。但严格意义上讲,Python算是一种“半编译,半解释”型语言。一方面,Python解释器会按行读取源代码文件,然后会将源代码转为供Python解释器直接执行的“字节码”,然后再执行字节码。 - 跨平台。Python是基于Python的解释器来进行执行。只要某个操作系统/平台上能运行Python解释器,就可以完美的运行Python的源代码。主流的Windows、Linux、Mac等操作系统上都能够很好地支持Python。
- 可扩展性强。Python可以很容易的调用
C/C++语言。如果觉得哪里的逻辑性能不能满足要求,可以使用C/C++重构部分模块,用Python调用。
劣势
执行效率较低,因为Python是一种解释型语言,所以程序执行效率比较低,依赖解释器。
什么是编译型语言和解释型语言?
-
编译型语言:
程序在执行之前需要一个专门的编译过程,把程序编译成为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。
程序执行效率高,依赖编译器,跨平台性差些。如C、C++、Delphi等。
-
解释型语言:
程序不需要编译,程序在运行时才翻译成机器语言,每执行一次都要翻译一次。
程序执行效率比较低,依赖解释器,跨平台性好。如Python、JavaScript、Perl、Shell等。
但是,在摩尔定律的作用下,硬件越来越便宜,反而是开发人员的成本越来越高,一些好的编程实践可以帮助我们写出比较高性能的代码,同时,Python解释器的执行效率也在不断被优化。
Python版本
Python3虽然是Python2的升级版,但是很多语法并不兼容,因此现在不建议学习Python2,直接学习Python3即可。
关于兼容性:
C++能非常好的兼容C语言(C语言写的代码可以直接使用C++编译器进行编译),但是也意味着C++背负着很多C语言的历史包袱。- 但是Python 3 和Python 2 很多地方不兼容(Python 2 写的代码,不能很顺利的在Python 3 的解释器上执行)。
- 这样做是好还是坏,不便评说,还是要看几年之后的最终结果是好是坏,才能盖棺定论。这样意味着很多已经用Python 2 写好的代码不会很顺利的升级到Python 3.。
- 但是这样也意味着Python 3 可以不用背负历史包袱,大刀阔斧的把一些不合理的地方修改掉。
- 官方的说法是,Python 2 最多维护到2020年便停止更新。
Python解释器和PyCharm编辑器
Python解释器的安装
-
在Python官网下载对应机器的安装包:https://www.python.org
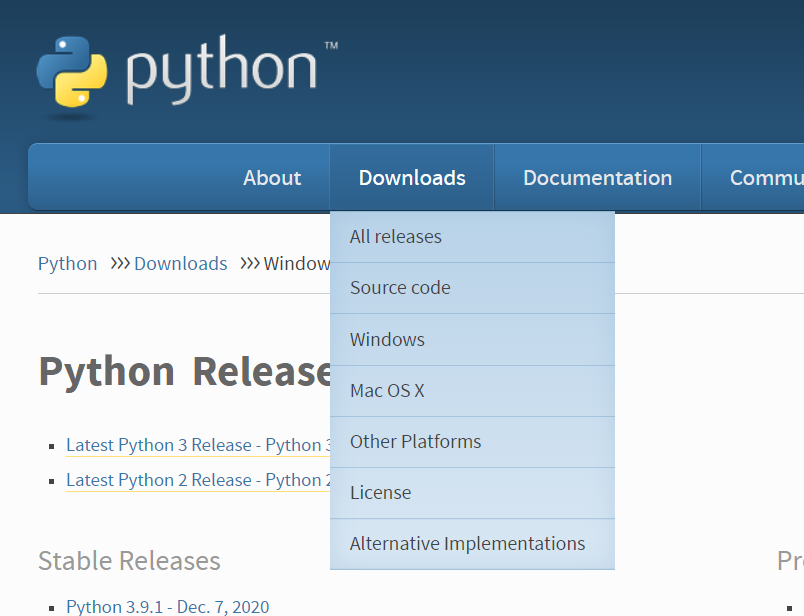
-
双击下载好的Python安装包
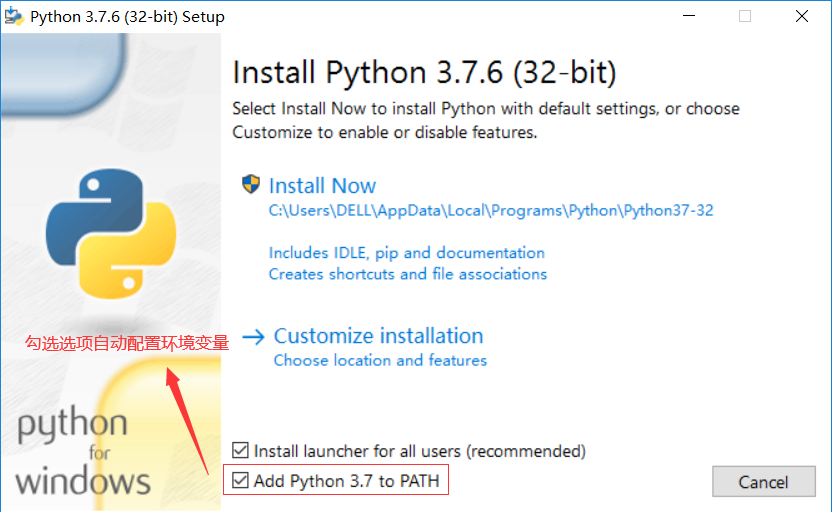
-
如果未勾选Add Python 3.7 to PATH,需要手动配置环境变量(如果已勾选可跳过这一步,直接到第4步)
- 计算机->属性->高级系统设置:
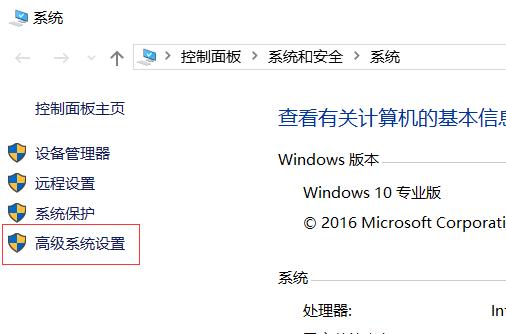
-
环境变量->系统变量->Path:
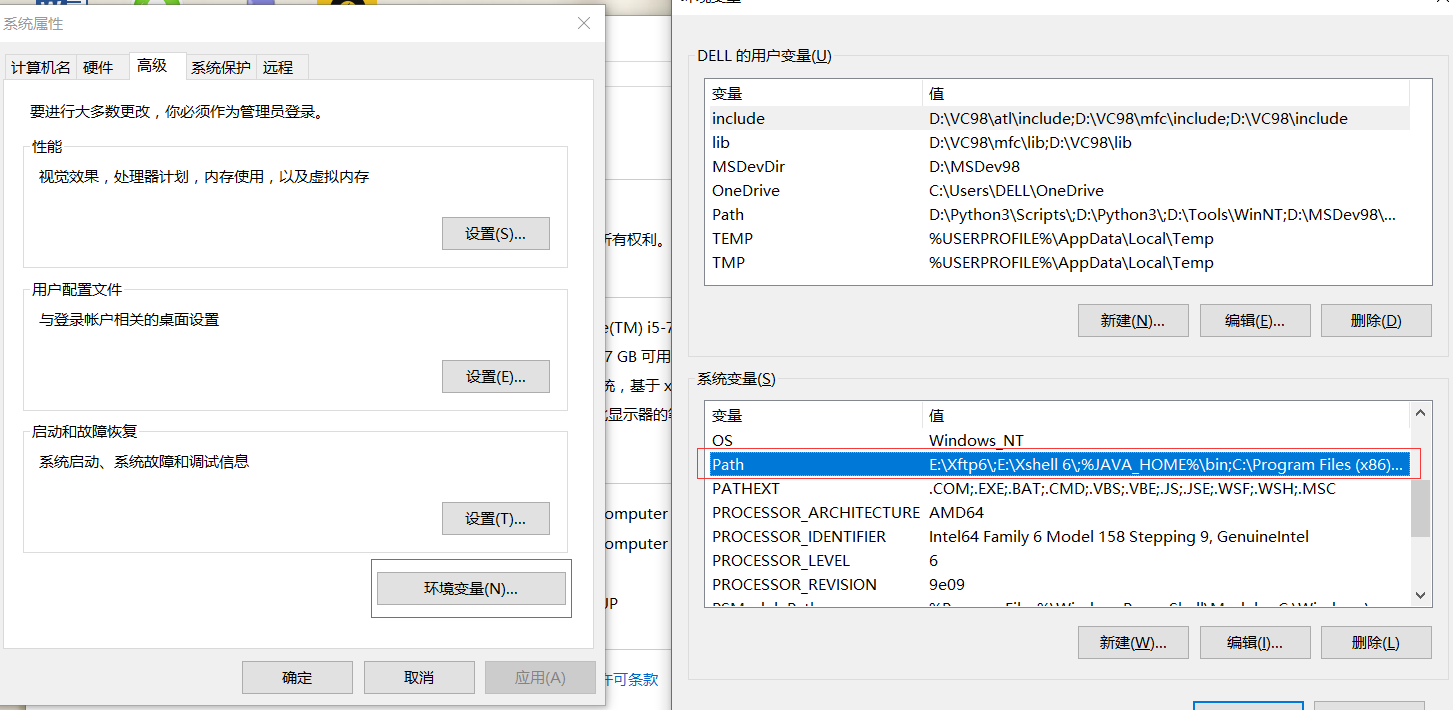
-
将python.exe的路径和pip命令的路径配置到Path中:
例如:D:\Python3
例如:D:\Python3\Scripts
-
在cmd命令下输入python,验证是否配置成功

PyCharm集成开发工具

PyCharm是一种Python IDE(Integrated Development Environment,集成开发环境),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
Python基础语法
变量赋值
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/14 20:24
# 变量和赋值
# 动态类型 type(变量)
# Python中的变量不需要声明,直接定义即可使用。会在初始化的时候决定变量的“类型”
# 使用 = 来进行初始化和赋值操作
counter = 0
miles = 1000.00
name = "poo-poo-cai"
kilometers = 1.666 * miles
print(counter, miles, name, kilometers)
# Python中也支持增量赋值
n = 10
n = n * 10 # 100
n *= 10 # 1000
print(n)
# 但是Python中不支持 ++/-- 这样的自增、自减操作,只能写成:
n += 1 # n = n + 1 == 1001
print(n)
# 运行结果:
# 0 1000.0 poo-poo-cai 1666.0
# 1000
# 1001
标准数据类型
Python3中有六个标准的数据类型:数字、字符串、列表、元组、字典、集合。
Number(数字)
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/6 13:39
# Number(数字)
# Python没有int,float这样的关键字,但是实际上数据的类型是区分int,float这样的类型的;
# Python3支持int(长整型)、float、bool、complex(复数);
# 内置函数type()可以用来查询变量所指的对象类型。
a = 1
print(type(a))
b = 0.1
print(type(b))
c = True
print(type(c))
d = 10 + 5j
print(type(d))
# 此外,还可以用insinstance来判断
num = 222
result = isinstance(num, int)
print(result)
# 布尔值表示真(True)和假(False)
# 布尔类型的变量,也是一种特殊的整数类型,在和整数进行运算时,True被当做1,False被当作0
b1 = True
sum = b1 + 2
print(sum) # 3
String(字符串)
字符串基础应用:
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/6 13:54
# Python中可以使用单引号(')、双引号(")、三引号('''/""")来表示字符串;
str1 = 'caituotuo'
str2 = "caituotuo"
str3 = """caituotuo"""
str4 = '''caituotuo'''
print(str1, str2, str3, str4) # caituotuo caituotuo caituotuo caituotuo
# 字符串中含有引号
str5 = 'I am "caituotuo"'
print(str5) # I am "caituotuo"
# 同时使用反斜杠 \ 转义特殊字符,如:换行符 \n
name = 'My name is \n cai.'
print(name)
# 运行结果:
# My name is
# cai.
# \ 本身需要 \\ 这样的方式来表示
str6 = '\\index\\'
print(str6) # \index
# 使用索引操作符[]或者切片操作符[:]来获取子字符串。(切片操作是一个前闭后开区间)
# 字符串的索引规则:第一个字符索引是0,最后一个字符索引是-1。
str7 = 'hello world!'
print(str7[0]) # h
print(str7[-1]) # !
print(str7[1:3]) # el
print(str7[:3]) # hel
print(str7[3:]) # lo world!
print(str7[:]) # hello world!
print(str7[::2]) # hlowrd
print(str7[::-1]) # !dlrow olleh
# +用于字符串连接运算;* 表示赋值当前字符串,与之结合的数字为复制的次数。
str8 = 'tester'
str9 = 'cai'
print(str8 + str9) # testercai
print(str8 * 1) # tester
print(str8 * 0) # 空
print(str8 * 3) # testertestertester
print(str8 * -1) # 空
# Python没有“字符类型”这样的概念,单个字也是字符串。
str10 = 'tester'
print(type(str10[0])) # <class 'str'>
# 格式化字符串:%s; 格式化整型:%d
name = 'caituotuo'
num = 1
print('尊敬的%s用户,您抽到的码号是%d' % (name, num)) # 尊敬的caituotuo用户,您抽到的码号是1
# 内建函数len获取字符串的长度
str11 = 'hello world!'
print(len(str11)) # 12
# 原始字符串(raw strings)
print(r'/n hello /n world!') # /n hello /n world!
字符串合并和拆分:
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 15:25
# 字符串合并和拆分
# 将列表中的字符串合并成一个字符串
b = "-"
a = ["wel", "come", "to", "beijing"]
print(b.join(a)) # wel-come-to-beijing
# 按空格将字符串拆分成列表
# 应用:接口自动化测时候,批量获取csv文件中的username,password
c = "he ll o wor l d !"
print(c.split(" ")) # ['he', 'll', 'o', 'wor', 'l', 'd', '!']
字符串常用函数:
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 15:33
# 字符串常用函数
# 判定字符串的开头结尾,返回布尔值
a = "hello world. my name is poo poo cai"
print(a.startswith("he"))
print(a.endswith("cai"))
print(a.startswith("cai"))
# 运行结果:
# True
# True
# False
# strip()去除字符串开头结尾的空格/换行符
b = " welcome to my house \n "
print(b)
print(b.strip(), end="---")
# 运行结果:
# welcome to my house
#
# welcome to my house---
# 查找子串
c = "hello world!"
print("\n")
print(c.find("wor")) # 6 返回下标,下标从0开始
print(c[6]) # w
print(c.find("123")) # -1 表示没有找到
# 替换子串(字符串是不可变对象,只能生成新字符串)
d = "welcome to my house!"
print(d.replace("house", "home")) # welcome to my home!
print(d) # welcome to my house!
# 判定字符串是字母还是数字
# str.isalpha()如果字符串至少有一个字符并且所有字符都是字母,则返回True
# str.isdigit()如果字符串只包含数字则返回True,否则返回False
e = "123456"
f = "abc"
g = "123abc"
print(e.isalpha())
print(e.isdigit())
print(f.isdigit(), f.isalpha(), g.isdigit(), g.isalpha())
# 运行结果:
# False
# True
# False True False False
List(列表)/Tuple(元组)
列表和元组基础应用:
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/7 18:13
# 列表和元组类似于C语言中的数组,使用[]来表示列表,用()来表示元组。
# 对象有序排列,通过索引读取,下标从0开始,最后一个下标为-1。
# 能保存任意数量、任意类型的Python对象,可以是数字、字符串、元祖、其他列表、字典。
a_list = [1, 3.666, [1, 2, 3], {"name": 20, 20: 10}, 4, (1, 2, 3, 4), "string", True]
print(a_list, type(a_list))
print(a_list[0], a_list[-1])
a_tuple = (1, 2, 3, 4)
print(a_tuple, type(a_tuple))
# 运行结果:
# [1, 3.666, [1, 2, 3], {'name': 20, 20: 10}, 4, (1, 2, 3, 4), 'string', True] <class 'list'>
# 1 True
# (1, 2, 3, 4) <class 'tuple'>
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 11:26
# 可以使用[:]切片操作得到列表或元组的子集。这个动作和字符串操作是一样的。
a_list = [1, 3.666, [1, 2, 3], {"name": 20, 20: 10}, 4, (1, 2, 3, 4), "string", True]
print(a_list[0:2]) # 从0索引开始,取两个 [1, 3.666]
print(a_list[:]) # [1, 3.666, [1, 2, 3], {'name': 20, 20: 10}, 4, (1, 2, 3, 4), 'string', True]
print(a_list[::-1]) # 反转 [True, 'string', (1, 2, 3, 4), 4, {'name': 20, 20: 10}, [1, 2, 3], 3.666, 1]
a_tuple = (1, 2, 3, 4)
# 列表和元组唯一的区别是:列表中的元素可以修改,但是元组中的元素不能修改。
a_list[0] = 0
print(a_list) # [0, 3.666, ...]
# a_tuple[0] = 0 # TypeError: 'tuple' object does not support item assignment
# 理解元组的不可变
# 元组的不可变指的是元组元素的id不可变。就是说一个元组包含了几个对象,
# 然后不可以给这几个元组再添加或者删除其中的某个对象,
# 也不可以将某个对象改成其他的对象。
# 但是,如果元组中的某个元素是可变对象(比如列表或字典),那么仍然可以修改。
a_tuple02 = (1, 2, [1, 2, 3, 4])
print(a_tuple02) # (1, 2, [1, 2, 3, 4])
a_tuple02[2][0] = 0
print(a_tuple02) # (1, 2, [0, 2, 3, 4])
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 12:32
# 排序
# sorted()排序:这是一个非常有用的函数,返回一个有序的序列(输入参数的副本)
a_list = [1, 5, 2, 3, 80, 55, 66]
a_list02 = sorted(a_list) # 不会破坏原本的列表,而是自己生成一个排序后的新列表
print(a_list) # [1, 5, 2, 3, 80, 55, 66]
print(a_list02) # [1, 2, 3, 5, 55, 66, 80]
# sorted()支持自定义排序规则
# 逆序排序
print(sorted(a_list, reverse=True)) # [80, 66, 55, 5, 3, 2, 1]
# 按字符串的长度排序
a_list03 = ["abc", "name", "u"]
print(sorted(a_list03, key=len)) # ['u', 'abc', 'name']
# sort()排序,会改变列表本身
a_list04 = [1, 5, 2, 6]
print(a_list04) # [1, 5, 2, 6]
a_list04.sort()
print(a_list04) # [1, 2, 5, 6]
列表常用操作:
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 16:12
# append():追加元素
a_list = [1, 2]
a_list.append(3)
print(a_list) # [1, 2, 3]
# 删除指定下标元素
a_list02 = [6, 5, 4, 3, 2, 1]
del a_list02[0]
print(a_list02) # [5, 4, 3, 2, 1]
# remove()按值删除元素
a_list02.remove(3)
print(a_list02) # [5, 4, 2, 1]
# a_list02.remove("1") # ValueError: list.remove(x): x not in list 删除不存在的值会提示not in
# 列表比较操作:==/!= 判定所有元素都相等,则认为列表相等。
# < > <= >= 则是两个列表从第一个元素开始依次比较,直到某一方胜出。
a = ["abc", 1233]
b = ["xyz", 789]
c = ["abc", 823]
print(a < b)
print(b < c)
print(b > c and a == c)
# 运行结果
# True
# False
# False
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 16:58
# 删除列表中指定的值(全部删除)
# 删除列表中所有的2
a_list = [1, 2, 2, 3, 5, 2, 2, 8, 9, 2]
n = len(a_list)
new_list = []
for i in range(0, n):
if a_list[i] == 2:
pass
else:
new_list.append(a_list[i])
print(a_list)
print(new_list)
# 运行结果:
# [1, 2, 2, 3, 5, 2, 2, 8, 9, 2]
# [1, 3, 5, 8, 9]
列表和元组的区别?(面试题)
①列表和元组唯一的区别是:列表中的元素可以修改,但是元组中的元素不能修改。
②理解元组的不可变(子元素不可改,若子元素是一个列表那么列表里面的内容可以改)
# 元组的不可变指的是元组元素的id不可变。就是说一个元组包含了几个对象,
# 然后不可以给这几个元组再添加或者删除其中的某个对象,
# 也不可以将某个对象改成其他的对象。
# 但是,如果元组中的某个元素是可变对象(比如列表或字典),那么仍然可以修改。
Set(集合)
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 12:56
# 集合(set)是一个无序的不重复元素序列。
# 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { }是用来创建一个空字典。
# 创建格式:
a_set = {50, 20, 20}
print(a_set) # {50, 20}
value = {50, 20, 20}
a_set02 = set(value)
print(a_set02) # {50, 20}
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # {'apple', 'orange', 'banana', 'pear'}这里演示的是去重功能
print('orange' in basket) # True 快速判断元素是否在集合内
print('crabgrass' in basket) # False
# 下面展示两个集合间的运算.
a = set('name')
b = set('username')
print(a) # {'n', 'a', 'm', 'e'}
print(b) # {'m', 's', 'r', 'n', 'a', 'u', 'e'}
print(a - b) # set()空集合 集合a中包含而集合b中不包含的元素
print(a | b) # {'m', 'a', 's', 'u', 'r', 'e', 'n'} 集合a或b中包含的所有元素
print(a & b) # {'m', 'a', 'e', 'n'}集合a和b中都包含了的元素
print(a ^ b) # 'r', 's', 'u'} 不同时包含于a和b的元素
Dictionary(字典)
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 14:59
# 字典是Python中的映射数据类型,存储键值对(key:value),无序(3.7有优化,相对有序,按输入的顺序显示)
# 几乎所有类型的Python对象都可以用作键。不过一般是数字和字符串最常用,且key不能重复。
# 使用{}表示字典。
a_dic = {'name': 'poo-poo-cai', 'age': 21} # 创建字典
print(type(a_dic)) # <class 'dict'>
print(a_dic["name"]) # poo-poo-cai 取字典中的元素
a_dic['name'] = "蔡坨坨" # 修改值
print(a_dic["name"]) # 蔡坨坨
a_dic["address"] = "福建" # 插入新的键值对
print(a_dic["address"]) # 福建
# 删除某一个键值对,del
del a_dic['address']
print(a_dic) # {'name': '蔡坨坨', 'age': 21}
# 使用clear()方法,清空整个字典中所有的键值对
a_dic02 = {"username": "007", 7: 8}
print(a_dic02) # {'username': '007', 7: 8}
a_dic02.clear()
print(a_dic02) # {}
# 使用pop()方法,删除键值对同时获取到值
a_dic03 = {"age": 20, "habits": "play computer"}
print(a_dic03) # {'age': 20, 'habits': 'play computer'}
habits = a_dic03.pop("habits")
print(a_dic03) # {'age': 20}
print(habits) # play computer
# 注意:字典也是可变对象,但是键值对的key是不能修改的。
# keys():返回一个列表,包含字典的所有key
# values():返回一个列表,包含字典的所有value
# items():返回一个列表,每一个元素都是一个元组,包含了key和value
a_dic04 = {'name': 'poo-poo-cai', 'age': 21, "address": "成都"}
print(a_dic04.keys())
print(a_dic04.values())
print(a_dic04.items())
# 运行结果:
# dict_keys(['name', 'age', 'address'])
# dict_values(['poo-poo-cai', 21, '成都'])
# dict_items([('name', 'poo-poo-cai'), ('age', 21), ('address', '成都')])
输入输出函数
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/7 17:26
# 输入和输出
# print函数,将结果输出到标准输出(显示屏)上
# input函数,从标准输入中获取用户输入
name = input('请输入你的姓名:')
print('你的姓名是:', name)
# 运行结果:
# 请输入你的姓名:cai
# 你的姓名是: cai
# input返回的结果只是一个字符串,如果需要获取一个数字,需要使用int函数把字符串转换成数字。
num = input('please input a number:')
print('type:', type(num), end="---") # type: <class 'str'>
num2 = int(num)
print('your number is:', num2, 'type:', type(num2)) # your number is: 20 type: <class 'int'>
注释 & 编码
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/7 17:36
# Python中使用 # 作为单行注释,# 后面的内容都是注释的内容。
a = 1.0 # define a
# 查看系统默认编码方式
import sys
print(sys.getdefaultencoding())
# 如果要包含中文,默认不是utf-8的话,需要在代码文件最开头的地方注明。
# -*- coding:utf-8 -*-
运算符
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/7 17:47
# 操作符
# Python中支持 + - * / % (加、减、乘、除、取余)这样的操作符
a = 1
b = 2
print(a + b) # 3
print(a - b) # -1
print(a * b) # 2
print(a / b) # 0.5
print(a % b) # 1
# // 是地板除,无论操作数类型如何,都会对结果进行取地板运算(向下取整)
print(a // b) # 0
# ** 表示乘方运算
c = 3
print(c ** 3) # 27
# 比较运算符,>、<、==、>=、<=、!= ,返回一个布尔值。
print(2 < 3) # True
print(2 > 3) # False
print(2 == 3) # False
print(2 >= 3) # False
print(2 <= 3) # True
print(2 != 3) # True
# 逻辑运算符and、or、not
# 字符串之间可以使用== 或者 != 来判断字符串的内容是否相同。
'test' == 'tester' # False
'test' != 'tester' # True
# 字符串之间也可以比较大小,这个大小的结果取决于字符串的字典序
# 从小到大 0-9 A-Z a-z
'a' < 'bb' # True
对象和变量引用
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/6 14:51
# 理解引用
# Python中可以用id这个内建函数,查看变量的地址
# 对象的三要素;1.type 2.id 3.value
a = 100
print(type(a), id(a), a)
a = 200
print(type(a), id(a), a)
b = a
print(type(b), id(b), b)
b = 300
print(type(b), id(b), b)
# 运行结果:
# <class 'int'> 140708135988976 100
# <class 'int'> 140708135992176 200
# <class 'int'> 140708135992176 200
# <class 'int'> 2225255404560 300
# 给a重新赋值成200,相当于新创建了一个200这样的对象,然后将变量名a重新绑定到200这个对象上。
# 将a赋值给b,相当于又创建了一个变量名为b的对象,并将b这个名字和200这个对象绑定到一起。
# 再次修改b的值,可以看出其实是又创建了一个300的对象,将b绑定到300这个对象上。
# 像创建的a,b这样的变量名,其实只是一个对象的别名。或者叫做变量的“引用”。
条件判断语句
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/6 15:07
# if语句
if 2 > 3:
print('dei') # dei
# if else
if 2 > 3:
print('dei')
else:
print('bu dei') # bu dei
# 非0 || True
if 1:
print('非0') # 非0
if '':
print('非0')
else:
print('空字符串') # 空字符串
if []:
print('非0')
else:
print('空列表') # 空列表
if {}:
print('非0')
else:
print('空字典') # 空字典
x = int(input("please input x's value:"))
y = int(input("please input x's value:"))
if x > 0:
if y > 0:
print('x and y >0')
else:
print('y <= 0')
else:
print('x <= 0')
循环语句
while循环语句:
# while循环
n = 1
while n < 4:
print('这是我循环的第%d次' % n)
n += 1
for循环语句:
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/6 15:31
# for循环
# 循环字符串
name = 'caituotuo'
for n in name:
print(n)
# 循环列表
lists = [1, 1.5, True, 5 + 10j, 'cai', (1, 2, 3)]
for list in lists:
print(list)
dicts = {'id': 666, 'name': 'caituotuo', 'sex': 'boy'}
for dict in dicts:
print(dict)
for k in dicts.keys():
print(k)
for v in dicts.values():
print(v, end=' ') # 666 caituotuo boy
print('\n')
for k, v in dicts.items():
print(k, end=' ')
print(v, end=' ') # id 666 name caituotuo sex boy
print('\n')
for n in range(1, 5): # 左闭右开
print(n)
# 1
# 2
# 3
# 4
常用内置函数/模块(abs、divmod、round、break、continue、pass):
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/6 15:50
# continue、break、pass
# 查找[1,100)第一个3的倍数
for n in range(1, 100):
if n % 3 == 0:
print(n)
break # 跳出当前循环
for n in range(1, 100):
if n % 3 != 0:
continue # 终止一次循环
print(n)
break
if 3 == 3:
pass # 空语句,用来占位
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 17:43
# abs:求一个数的绝对值
a = -20
print(abs(a)) # 20
# divmod:返回一个元组,同时计算商和余数
a, b = divmod(10, 3)
print(a, b) # 3 1
# round:对浮点数进行四舍五入
# round有两个参数,第一个是要进行运算的值,第二个是保留小数点后多少位。
r = round(1.66666, 2)
print(r) # 1.67
使用for生成列表:
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2021/1/15 17:36
# 生成列表
# 使用for循环将生成的值存放到一个列表中
# 生成[0,4)的数字的平方列表
s = [x ** 2 for x in range(4)]
print(s) # [0, 1, 4, 9]
# 还可以搭配使用if语句
# 获取[0,8)区间中的所有奇数
e = [x for x in range(8) if x % 2 == 1]
print(e) # [1, 3, 5, 7]
自定义函数 & 不定长参数
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/6 16:16
# 函数
# 一些可以被重复使用的代码,可以提取出来放到函数中
# Python使用def来定义一个函数,使用return来返回结果
def add(num=3):
num = num + 1
return num
# 调用函数
num = add()
print(num)
num = add(5)
print(num)
# 理解“形参”和“实参”:形参相当于数学中的未知数这样的概念。实参就是给未知数确定具体的数值。
# Python中相同名字的函数,后面的会覆盖前面的。
# Python支持默认参数。函数的参数可以具备默认值。
def fun(x=1):
y = x ** 3
z = y + x
return x, y, z
# Python解包(unpack)语法,函数返回多个值,但是我只关注z,不想关注x、y,可以使用_作为占位符。
_, _, z = fun(2)
print(z)
# 我们实现一个打印日志的函数。这个函数第一个参数是一条日志的前缀,后续可能有n个参数。
# n个参数之间使用\t(tab键)分割。join()方法用于将序列中的元素以指定的字符连接成一个新的字符串。
def log(prefix, *data):
print(prefix + "\t".join(data))
# 调用函数
log('[Notice]', "hello", "world") # [Notice]hello world
# 不定长参数
def bdc(*canshu):
print(canshu)
bdc(1, 1.5, True, 'hello') # (1, 1.5, True, 'hello')
# 通过在参数名前加两个星号,星号后面的部分表示传入的参数是一个字典。
# 这时候调用函数就可以按照键值对的方式传参。
# 成对传参
def chengdu(**kv):
print(kv)
chengdu(name='cai', age=21) # {'name': 'cai', 'age': 21}
作用域 & 文档字符串
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/6 16:31
# 作用域
# Python中,def、class会改变变量的作用域
# if else elif while for try 不会改变变量的作用域
# global
for i in range(3):
print(i)
print(i) # 即使出了for循环语句块,变量i仍然访问到i变量
def fun(**kv):
"""全局变量"""
global new_kv
new_kv = kv
return kv
# 0
# 1
# 2
# 2
kv = fun(name='cai', age=21)
print(kv)
print(new_kv)
# {'name': 'cai', 'age': 21}
# {'name': 'cai', 'age': 21}
# 文档字符串
# 写注释对于提升程序的可读性有很大的帮助,前面我们介绍了 # 来表示单行注释。
# 对于多行注释。我们可以使用三引号('''/""")在函数/类开始位置表示。这个东西也被称为文档字符串。
def fun():
"""文档字符串"""
# 使用对象的doc属性就能看到这个帮助文档
print(fun.__doc__) # 文档字符串
# 或者内建函数help也可以做到相同的效果
help(fun)
# Help on function fun in module __main__:
#
# fun()
# 文档字符串
# 注意:文档字符串一定要放在函数或者类的开始位置,否者上述两个函数无法来访问。
文件操作
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/9 21:25
# 文件操作
# 使用内建函数 open() 打开一个文件
# handle = open('file_name','r')
#
# 第一个参数file_name是文件的名字,可以是一个绝对路径,也可以是一个相对路径。
# 第二个参数是文件的打开方式,选项有:
# 'r':只读
# 'w':覆盖写
# 'a':追加写
# 方式一(使用相对路径):
handle = open('test.txt', 'r', encoding='utf-8') # 指定编码格式encoding,默认是gbk
# 方式二(使用绝对路径):
# handle = open(r'D:\Desktop\Python_Study\Python_Study\bcbx_test\文件操作\test.txt', 'r', encoding='utf-8')
# handle是一个文件句柄,是一个可迭代的对象,可以直接使用for循环按行读取文件内容
for line in handle:
print(line.strip()) # strip()去除空格和换行
# handle使用完毕,需要close掉,否则会引起资源泄露(一个进程能打开的句柄数目是有限的)
handle.close()
print(handle.read(3))
# 读取一行,前面如果读过则不会重复读取,自动从未读取部分往下读
print(handle.readline())
# 读取所有行,将结果存储在result中,第一行的索引为0,以此类推
result = handle.readlines()
print(result[0].strip())
handle.close()
异常
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/9 21:52
# 在我们前面经常提到“程序运行出错”这样的概念。实际上,这是Python解释器抛出了一个异常。
list01 = [1, 2, 3]
try:
print(list01[2]) # IndexError: list index out of range,try except捕获异常,后面程序正常运行
handle = open(r'test02.txt', 'r', encoding='utf-8') # No such file or directory: 'test02.txt'
except Exception as error:
# except IndexError:
print(error)
print(type(error))
if str(error) == 'list index out of range':
print('IndexError')
elif str(error) == "[Errno 2] No such file or directory: 'test02.txt'":
print('FileNotFoundError')
# print(list01[3]) # 没有抛异常,后面的程序无法运行
print('成功捕获异常')
模块
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/9 22:13
# 模块
# 当代码量比较大的时候,我们最好把代码拆分成一些有组织的代码片段。
# 每个代码片段里面包含一组逻辑上有关联的函数或类。
# 每一个片段里放在一个独立的文件中。这样的片段就成为模块(module)
# 使用import可以在一个Python文件中引入其他的模块。
# 既然模块也是一个对象,那么可以给这个对象赋值(相当于定义别名)
# 使用import 模块 as 别名
def bubble_sort(ls):
# 检测列表的数据个数
n = len(ls) # n=6
# i为数据排序的轮次
for i in range(n - 1):
# j为列表数据的下标
for j in range(0, n - i - 1):
# 比较相邻两个数的大小
if ls[j] > ls[j + 1]:
# 相邻两个数交换位置
ls[j], ls[j + 1] = ls[j + 1], ls[j]
# 输出排序后的数据列表
print(ls)
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/9 22:13
from c_bcbx.Python基础.模块.test01 import bubble_sort as b
b([2, 3, 5, 22, 2, 1, 99, 0, 2]) # [0, 1, 2, 2, 2, 3, 5, 22, 99]
注意事项:
- .py文件的命名可以使用数字、字母、下划线。
- 当文件作为主程序运行时,文件名开头可以随意,以数字,字母,下划线开始都可以,如:666_cai.py,cai.py,_cai666.py,cai1.py,_666cai.py;
- 但是,当.py文件作为模块被导入到其他文件中调用时,则作为模块的.py文件不能以数字开头命名,可以用下划线和字母开头,如:cai.py,_cai666.py,cai666.py,_666cai.py,若命名为666cai.py则会出错。
- 同理,若作为模块的.py文件位于某个包下,则这个包的命名也不能以数字开头。
包
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/12 22:23
# 包(Package)
# 当我们代码量进一步变大时,光拆分成多个文件已经不足以满足需求,
# 还需要能按照一定的目录结构层次化的组织这些模块,同时包也可以解决模块之间的名字冲突问题。
# 例如,我们可以以下面的方式组织代码结构:
# test.py
# bao_package/
# add.py
# divide.py
# __init__.py
# 在bao_package目录中增加一个__init__.py文件,bao_package这个目录就成了包。
# 可以在test.py中import bao_package中的模块
from c_bcbx.Python基础.包.bao_package import add, divide
# 调用add.py文件
add
# 调用divide.py文件
divide
# __init__.py 是在包加载的时候会进行执行,负责一些包的初始化操作,一般是空文件即可。
类
# -*- coding:utf-8 -*-
# 作者:测试蔡坨坨
# 时间:2020/12/11 21:11
# 类
# 面向对象:封装
# 面向对象-oop是一种编程思想,万物皆对象,面向对象提高了编程效率,重复利用性高,
# 一个对象包含了数据和操作数据的函数。
# 抽象
# 抽象是指对现实世界问题和实体的本质表现、行为、特征进行建模,抽象的反义词是具体。
# 抽象的本质,是抓住我们重点关注的主体,而忽略一些我们不需要关注的细节。
# 写程序也一样,我们不可能把一个现实事物所有的信息都在程序中表示出来,而是只表示我们需要用到的。
# 类和实例
# 类是施工图纸。里面有房子的重要信息(比如:户型、面积、朝向、层高等)
# 实例是造好的房子,房子造好了,才能住进去。
# 通过同一张图纸可以建造出N个相同格局的房子,那么N个实例就都是属于同一个类。
# 创建一个新的类
class Tester:
# 类的特殊方法,__init__方法里面定义的参数在实例化类的时候必须要传参
def __init__(self, house_type):
self.house_type = house_type
developer = 'SOHO'
def show_price(self, s):
if self.house_type == '洋房':
print('单价30000/每平米')
print('整套的价格是:%d' % (30000 * s))
elif self.house_type == '小高层':
print('单价25000/每平米')
else:
print('单价20000/每平米')
# 实例化类
cai = Tester('洋房')
cai.show_price(100)
cai.house_type == '小高层'