原文网址:https://zhuanlan.zhihu.com/p/518831355
本文讨论的内容来自于仕琪老师的课程:C/C++从基础语法到优化策略
课程地址:[C++](快速学习C和C++,基础语法和优化策略,学了不再怕指针(南科大计算机系原版)_哔哩哔哩_bilibili)
经典案例
首先我们引入一个体现C++11特性的经典案例,hello.cpp:
// C++ example in C++11
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main() {
vector<string> msg {"Hello", "C++", "World", "!"};
for (const string& word: msg) {
cout << word << " ";
}
cout << endl;
return 0;
}
编译与运行代码
我们若要对上面的文件进行编译,编译的指令如下:
g++ hello.cpp这条命令可以把源文件进行编译并生成一个可执行文件,整个过程可以概述为 编译+链接
若我们只需要编译,无需链接,则需要使用参数 -c 指定我们的需求
但是由于 hello.cpp 文件中,对 msg 初始化时采用了新标准:C++11标准,然而g++默认的标准要低于C++11标准的,所以编译可能会报错
所以我们需要指定参数,来告诉编译器应该采用哪个标准,命令修改为:
g++ hello.cpp --std=c++11这样就可以按照特定的C++标准来编译源代码了
我们编译后,会生成一个可执行文件,默认的可执行文件的文件名是a.out,若想更换为自己指定的文件名,则需要使用 -o 参数
使用-o来自定义输出文件的文件名:
g++ hello.cpp --std=c++11 -o hello我们完成编译后,就可以执行这个代码了,执行指令为:
./hello实例:
PS D:\Code> g++ hello.cpp --std=c++11 -o apple
PS D:\Code> ls
目录: D:\Code
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 2022/5/21 21:03 88726 a.exe
-a---- 2022/5/21 21:19 88726 apple.exe
-a---- 2022/5/21 21:02 292 hello.cpp
-a---- 2022/5/21 21:17 88726 hello.exe
PS D:\Code> ./apple
Hello C++ World !有一点需要注意,与其他语言不同,C++在编写一次后,需要在各种不同的平台上去重新编译后才能运行。
C++的优点:
- 优化已经比较完善的编译器
- 可直接访问内存
- 许多AI框架的底层实现依赖于C++
- 卓越的性能
编译与链接
案例:
#include <iostream>
using namespace std;
int mul(int a, int b) {
return a * b;
}
int main() {
int a, b;
int result;
cout << "Pick two integers:";
cin >> a;
cin >> b;
result = mul(a, b);
cout << "The result is " << result <, endl;
return 0;
}
上面的例子中,有两个函数,分别是 main函数 与 mul函数
其中,main() : 由启动代码调用
mul() :被main函数调用
此处,mul称为被调函数,而main称为调用函数
函数原型(函数声明)
函数原型也就是函数的声明,通常放在头文件(*.h、*.hpp)中
int mul(int a, int b);
函数原型在参数列表后要跟分号
函数定义
函数的具体实现,也就是函数的定义,一般放在源文件(*.c、*.cpp)中
int mul(int a, int b) {
return a * b;
}
参数列表之后不跟分号,而是花括号,花括号内是函数体
建议将所有的源代码放到不同的文件中,分门别类去管理
我们将刚刚的代码改为如下三个文件:
- main.cpp
- mul.hpp
- mul.cpp
main.cpp:
#include <iostream>
#include "mul.hpp"
using namespace std;
int main() {
int a, b;
int result;
cout << "Pick two integers:";
cin >> a;
cin >> b;
result = mul(a, b);
cout << "The result is " << result << endl;
return 0;
}
mul.hpp:
#pragma once
int mul(int a, int b);
mul.cpp:
#include "mul.hpp"
int mul(int a, int b) {
return a * b;
}
在我们的头文件mul.hpp中,只存放函数声明也就是函数原型。
在main.cpp中的include "mul.hpp"的作用就是将 mul.hpp 这个头文件里面的代码嵌入到main.cpp 中。
在我们编译的过程中(注意仅是编译并非链接),当 main.cpp 中的主函数第一次遇到 mul函数时,如果有了这个声明,编译器就会知道其是一个函数,就会检查参数列表中的 a 与 b ,看看其数据类型和参数的个数是否符合这个函数的声明(此时不会去找这个函数的具体实现,因为具体实现存放在另外一个源文件中,只有编译那个源文件时才能检查这个函数的具体实现是否有错误),若符合函数原型就代表这行函数调用没有错误。
此处的 mul 函数在编译时,是不会去探究它的具体实现是否有误的,编译器只是知道其是一个函数,在链接时,会去其他Object文件中寻找对应的具体实现,若发现那个实现也通过了编译(都已经是Object文件了,肯定通过编译了),则会将两者链接到一起。
所以,若要将这个三个文件进行编译,编译的过程如下:
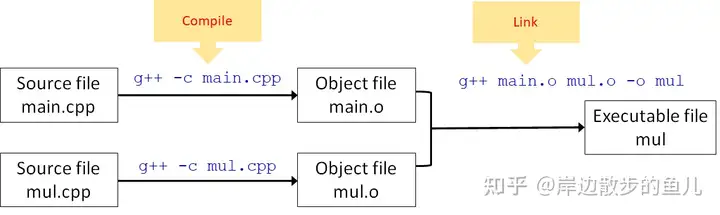 编译多个文件
编译多个文件
之前已经讲述过了,选项 -c 的意思是,表示只编译不链接
g++ -c main.cpp
g++ -c mul.cpp我们 编译+链接 得到的是可执行文件,若只编译,会得到一个 Object文件
main.cpp 通过 g++ 将其编译成 main.o,此文件的扩展名为o,称为 Object文件,是一个二进制文件。
对mul.cpp也是同样的操作,将其也编译成Object文件
将得到的两个object文件进行链接
从Object文件生成可执行程序的步骤叫做链接(Link),也就是将这两个二进制文件合并起来,合并的过程叫做link
g++ main.o mul.o -o mulmul是输出得到的可执行文件名,由参数-o指定
上面的三行语句可以整合为一条执行语句:
g++ main.cpp mul.cpp -o mul这样可以把所有的源文件一次性全部编译并且完成链接。
为什么要分开编译
当源文件特别多的时候,比如有100个源文件时,因为在编程的过程中我们需要经常编译,看看程序的运行是否出错或者未达到我们的理想情况。若每次都将100个源文件全部都编译一遍的话,那会花费较长的时间。若你分别放在不同的源文件中,而且需要编译哪个源文件就单独编译哪个源文件,此时只需要更新一个Object文件,其他 Object文件 无需更新,这样就能节省时间。
虽然这种靠命令的方式去编译链接是一个程序员需要掌握的知识,若若全部手动操作这些命令,会比较花费时间
其实不需要每次都手动输入这些命令,可以使用Makefile
Debug
错误类型:
- 编译错误:一般由语法错误造成
- 链接错误:只要源文件没有任何语法错误,编译一般是不会报错的,但是链接时就不一定了
需要注意的是,若mul.cpp文件中实现的函数名为Mul,而mul.hpp中声明的是mul函数,main.cpp的主函数中调用的是mul函数,此时这三个文件在编译时是不会报错的,因为没有任何的语法错误,但是在链接时会报错,因为在main.o中需要这个mul函数,它会去所有的Object文件中寻找,找不到就会报错:undefined symbols,也就是mul这个符号是未定义的。
简而言之,main函数在编译时,若用到一个函数时,会去头文件中寻找函数声明,看看这个函数的调用是否正确,并且符合语法,这就是这个.hpp文件的作用,然后在链接时,main函数就会去所有的Object文件中寻找,但是链接的时候找不到这个函数的具体实现,所以无法完成链接。
把一个源文件分为三个文件,我目前的理解是:
有三个文件,分别是 main.cpp、mul.hpp、mul.cpp
main.cpp中的主函数是程序的入口,主函数会调用函数mul。
首先在编译main.cpp时,会先去mul.hpp文件中,找调用的函数的函数原型,确认在主函数中调用的mul函数是符合函数原型要求的,比如参数个数、参数数据类型等,这个mul.hpp的作用目前来说就是这样的,用来存放函数原型。
在main.cpp的主函数进行编译时,是不会去关心所调用的mul函数的具体实现有没有编译错误,这个任务是交给另外一个编译命令的。在函数具体实现的mul.cpp文件中,也include了mul.hpp,此处其实如果没有这个include,这个文件编译也是不会出错的,但是如果将一些公共的引用也写在了这个.hpp中,比如#include \<iostream>,则一定要在mul.cpp文件中引用mul.hpp。
之后我们会将这个mul.cpp也进行编译,得到一个对应的Object文件,主函数在检查完这个函数的函数原型是否符合后,我们将两个Object文件进行链接时,它会去对应的Object文件中寻找这个函数的具体实现,因为既然能生成Object文件肯定是通过了编译的,所以这个具体的实现肯定是无编译错误的,若找到了,就可以将两个Object文件链接在一起了,并继续执行。
综上,mul.hpp只是用来存放函数原型,若编译到调用函数语句时,编译可以检查函数的调用是否符合函数原型,只有在链接的时候,才会寻找编译这个函数的具体实现产生的Object文件,链接在一起,才可以具体执行。在编译时是不会管这个函数具体实现是否正确,因为那个步骤是另外一个编译的步骤。在具体实现的源文件中,我们可以没有这条语句:#include "mul.hpp" ,因为里面仅仅是只有函数原型。
链接错误可能的报错:symbol(s) not found for architecture x86_64
或者 clang: error: linker command failed with exit code 1
若报链接错误,需要去看看是哪个symbols,哪个符号没有链接上,去寻找错误的原因
- 运行时错误(runtime error)
若我们成功地编译、链接,并且可执行程序也可以成功运行,但在运行时突然出错,这个时候需要具体看实现的逻辑是否有误了,比如除数是 0
预处理与宏
预处理
整个编译过程可以分为很多子步骤,预处理是在真正的编译之前的一个步骤
预处理器在编译之前进行,预处理器是用来处理预处理指令的
预处理指令通常以 # 开头
每条指令占一行,只能占一行
预处理指令通常有:
define、undef、include、if、ifdef、ifndef、else、elif、endif、line、error、pragma
预处理include的具体过程:
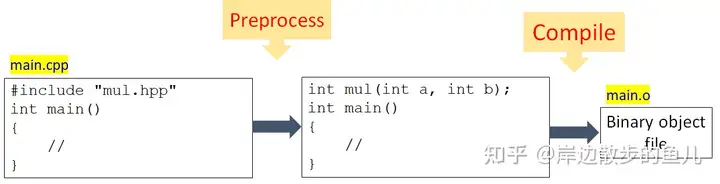
通过预处理后,main.cpp就转化为了中间方框中的表达形式,也就是将.hpp里的内容嵌入到了这个位置,之后我们将嵌入后的代码送到编译器去编译。
所以编译器是不处理include指令的,是由预处理器来处理的,处理完后才会送给编译器
当预处理指令出错时,与编译无关,但是还是会引起编译错误
宏
宏,是由define指令定义的,比如:
#define PI 3.14
此处,PI不是变量,而是一个宏,3.14与PI形成了替换关系,可以像使用变量一样去使用他
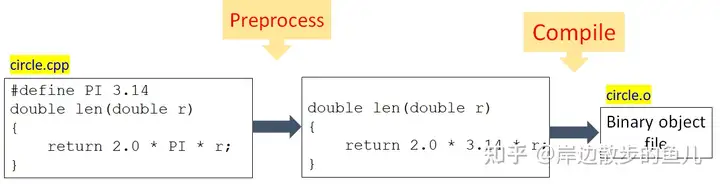
会将PI替换为3.14,再送入编译器进行编译,可以理解为一个全文替换
通过命令行与程序交互
通过命令行参数,把特定的命令发给程序,让程序按照你的指令去做,使用命令行参数的程序调用:
g++ hello.cpp -o hellog++是一个应用程序,与生成的hello没有区别,只是它功能更加丰富、更加庞大
我们使用g++这个程序去编译源文件,要编译的文件的文件名是用户指定的,并且告知将结果存入hello中
用户告诉程序要编译什么,输出成什么
程序通过命令行参数去获取用户的输入
实际上,完整的main函数是由两个参数的
第一个参数叫 argc,arguments count,也就是统计有多少个参数
具体的参数列表会放入一个字符指针数组中,char *argv[],这个数组里面的元素是字符串,每个指针存储的是字符串的首地址,对这个首地址解引用就可获取字符串
写成下面也是等价的:
int main(int argc, char *argv[]) {
...
}
int main(int argc, char **argv) {
...
}
实例argument.cpp:
#include <iostream>
using namespace std;
int main(int argc, char ** argv) {
for (int i = 0; i < argc; i ++) {
cout << i << ": " << argv[i] << endl;
}
}
我们可以通过命令行参数,拿到用户的输入,然后按照用户的指令去做特定的事情
标签:main,函数,int,C++,编译,cpp,mul,随记,浅谈 From: https://www.cnblogs.com/bruce1992/p/17178037.html