一、安装环境
1.1、官网下载包
下载地址:https://golang.google.cn/dl/ (下载对应的版本,mac m1使用arm64)

傻瓜式安装即可,mac安装后默认安装在,/usr/local/go
接着配置GoPath、GoRoot、Go111Module、GoProxy
1.2、配置环境变量
1.2.1、配置GOROOT、GoRoot
open ~/.bash_profiles
#go的安装目录
export GOROOT=/usr/local/go
export PATH=$PATH:$GOROOT/bin
# go工作区,即编写代码存放的目录
export GOPATH=/Users/akka/Desktop/goWorks
gopath工作目录下(goWorks)要新建src、bin、pkg
bin 存放编译后生成的可执行文件
src 存放源码
pkg 则存放编译后的包内容
1.2.2、配置Go111Module、GoProxy
go module是类似于java中的maven,是包的管理工具,在没有这个go module之前,都是配置本地的GOPATH,创建的每个项目也都必须创建在这个GOPATH的src目录下,且项目的go文件不能重名
go module是在go1.1.1版本推出的
配置GO111MODULE
#查看GO111MODULE的当前值
go env
#设置GO111MODULE的值
#开启模块支持,无论什么情况,go命令都会使用module
go env -w GO111MODULE=on
#关闭模块支持,无论什么情况,go命令都不会使用module
go env -w GO111MODULE=off
#默认值,go命令根据当前目录决定是否启用module功能
#即当前目录在GOPATH/src之外且该目录包含go.mod文件时开启module功能;否则继续使用GOPATH
go env -w GO111MODULE=auto
配置代理
# 设置 Go 的国内代理,方便下载第三方包
go env -w GOPROXY=https://goproxy.cn,direct
这样go module就开启好了,执行go mod help看使用

可看到其中是有初始化命令,而go module是用来管理项目的第三方包的
初始化模块

1.3、go 常用命令
go env 查询环境变量
go env -w GOPROXY=https://goproxy.io,direct 设置环境变量
go list 列出当前全部安装的package
go run 编译并运行Go程序
go build 编译
go build -o 路径/a.exe
go clean 命令是用来移除当前源码包里面编译生成的文件
go get 命令主要是用来动态获取远程代码包,目前支持的有BitBucket、GitHub、Google Code和Launchpad。这个命令在内部实际上分成了两步操作:第一步是下载源码包,第二步是执行go install
go install 命令在内部实际上分成了两步操作:第一步是生成结果文件(可执行文件或者.a包),第二步会把编译好的结果移到 GOPATH/pkg 或 者 GOPATH/pkg 或者GOPATH/pkg或者GOPATH/bin
1.4、go多平台打包
GOOS:目标可执行程序运行操作系统,支持 darwin,freebsd,linux,windows
GOARCH:目标可执行程序操作系统构架,包括 386,amd64,arm,arm64
CGO:交叉编译不支持 CGO 所以要禁用它
1.Mac
Mac下编译Linux, Windows、Mac(m1)平台的64位可执行程序:
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build test.go
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build test.go
CGO_ENABLED=0 GOOS=darwin GOARCH=arm64 go build HelloWorld.go
CGO_ENABLED=0 GOOS=darwin GOARCH=arm64 go build -o test HelloWorld.go (指定文件名)
2.Linux
Linux下编译Mac, Windows平台的64位可执行程序:
CGO_ENABLED=0 GOOS=darwin GOARCH=amd64 go build test.go
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build test.go
3.Windows
Windows下编译Mac, Linux平台的64位可执行程序:
SET CGO_ENABLED=0
SET GOOS=darwin
SET GOARCH=amd64
go build main.go
SET CGO_ENABLED=0
SET GOOS=linux
SET GOARCH=amd64
go build main.go
1.5、安装goLand
下载地址:https://www.jetbrains.com/go/download/#section=mac
选择自己需要的版本,本人是mac m1

傻瓜式安装
1.6、HelloWorld程序
新建gofile,然后输入代码执行

package main
import "fmt"
func main() {
fmt.Println("hello,world1111")
}

在这个hello,world程序中发现有个main包,(package)
在Go语言中,main包具有特殊的含义 ,go语言的编译程序会试图把这个包的编译为二进制的可执行文件,所有用go语言编译的可执行程序都必须有一个main的包,一个可执行程序有且仅有一个main包
二、go编程基础
go语言是一种静态的编程语言
2.1、注释
package main
import "fmt"
//单行注释,这是主函数
func main() {
/*多行注释
adasd
asdads
这是主函数
*/
fmt.Println("hello,world1111")
}
2.2、变量
2.2.1 定义单个变量
在go语言中,声明变量使用var
使用格式
var name type
第一个var是声明变量的关键字
第二个是name ,就是变量的名字
第三个type,是变量的类型
例子:
package main
import "fmt"
func main() {
//声明字符串类型和数字型的变量name、age
var name string = "test"
var age int = 18
fmt.Println(name ,age)
}
2.2.2 定义多个变量
package main
import "fmt"
func main() {
var (
name string
age int
addr string
)
//string 类型的默认值是 空
//int 类型默认值是 0
fmt.Println(name, age, addr)
}

2.2.3 定义指针型变量
package main
import "fmt"
func main() {
var name, addr *string
fmt.Println(name, addr)
}
输出

可以看到指针型的默认值是nil
- string型默认值为空
- int型、浮点型默认值为0
- bool型默认为false
- 指针型、切片、函数的变量默认为nil
package main
import "fmt"
func main() {
var addr float32
var name bool
fmt.Println(name, addr)
}
输出

2.2.4 短变量的初始化和赋值
分别进行变量的声明和赋值
package main
import "fmt"
func main() {
//声明变量
var name string
var age int
//赋值变量
name = "张三"
age = 18
fmt.Println(name, age)
}
输出

一起进行
package main
import "fmt"
func main() {
name := "张三"
age := 18
fmt.Println(name, age)
//打印类型,%T表示类型
fmt.Printf("%T,%T", name, age)
}
输出

使用条件
- 只能运用于函数内部
- 定义变量,同时显示初始化
- 不能提供数据类型
注意:由于使用了:=,而不是=,因此左边的变量名必须是未定义过的变量,定义过则会产生报错
package main
import "fmt"
func main() {
var name string
name := "张三"
fmt.Println(name)
}
上述代码会产生编译错误

2.2.5 变量的内存地址输出
格式化输出类型表(fmt.Printf)
--通用部分
%v 按值的本来值输出
%+v 在%v基础上,对结构体字段名和值进行展开
%#v 输出Go语言语法格式的值
%T 输出Go言语法格式的类型和值
%% 输出%本体
--布尔值
%t
--整数
%b 整型以二进制方式显示
%o 整型以八进制方式显示
%d 整型以十进制方式显示
%x 整型以十六进制方式显示
%X 整型以十六进制、字母大写方式显示
%c ASCCI字符
%U Unicode 字符
%f 浮点数
%s 字符串
%p 指针,十六进制方式显示
取地址符号 =》&
package main
import "fmt"
func main() {
var num int
num = 100
fmt.Printf("num:%d,内存地址:%p ", num, &num) //& 取地址符
num = 200
fmt.Printf("num:%d,内存地址:%p ", num, &num) //& 取地址符
}

结论:由此可得变量的指向的内存地址是不变的,内存存储的数据是可以变的。
2.2.6 变量的交换
package main
import "fmt"
func main() {
var a int = 100
var b int = 200
a, b = b, a
fmt.Println(a, b)
}
输出

2.2.7 匿名变量
匿名变量是用下划线声明”-“,本身就是个特殊的标识符,被称为空白标识符,它可用于想其他变量名标识符一样那样用于赋值,但是任何赋值给这个标识符的值都会被抛弃,因此这些值都不能在后续代码中使用、赋值、运算
使用场景如下,在后续不需要使用这个值时,如:只需对象的某一个属性。User对象的名字
package main
import "fmt"
//定义函数test,其中(int,int)表示返回的类型
func test() (int, int) {
return 100, 200
}
func main() {
a, b := test()
fmt.Println(a, b)
//当我们只需要用其中的返回值的一个时,另一个就可以直接采用匿名变量舍弃
c, _ := test()
fmt.Println(c)
}
输出

2.2.8 变量的作用域
局部变量
函数内的变量叫局部变量
全局变量
在源文件中定义的变量,既函数外定义的变量叫全局变量
注意:当全局变量和局部变量名称可以相同,但是函数体内的局部变量会被优先考虑
package main
import "fmt"
var name string = "lisi"
func main() {
var name string = "zhangsan"
fmt.Println(name)
fmt.Println("运行test函数...")
test()
}
func test() {
fmt.Println(name)
}
输出

2.2.9 变量的基本数据类型
布尔型
package main
import "fmt"
func main() {
var isFlag bool
var isFlag1 bool = false
fmt.Printf("%T,%t\n", isFlag, isFlag)
fmt.Printf("%T,%t\n", isFlag1, isFlag1)
}

数字型
整形int、浮点型float32、float64
| 序号 | 类型和描述 |
|---|---|
| 1 | uint8 无符号8位整形(0~255) |
| 2 | uint16 无符号16位整数型(0~65535) |
| 3 | uint32无符号32位整数型(0~4294967295) |
| 4 | uint无符号64位整数型(0~18446744973709551615) |
| 5 | int8 有符号8位整形(-255~255) |
| 6 | int16 有符号16位整数型(-65535~65535) |
| 7 | int32有符号32位整数型(-4294967295~4294967295) |
| 8 | int有符号64位整数型(-18446744973709551615~18446744973709551615) |
浮点型
| 序号 | 类型和描述 |
|---|---|
| float32 IEEE-754 32位浮点型数 | |
| 2 | float64 IEEE-754 64位浮点型数 |
| 3 | complex64 32位实数和虚数 |
| 4 | complex128 64位实数和虚数 |
package main
import "fmt"
func main() {
var age int = 18
var money float32 = 123.11
fmt.Printf("%d,%f\n", age, money) //浮点型默认打印6位小数
fmt.Printf("%d,%.2f\n", age, money)
}

字符串型
整数型单引号和双引号
单引号表示字符,双引号表示字符串
字符编码表
ASCII编码表
中国字的编码表:GBK
全世界的编码表:Unicode编码
package main
import "fmt"
func main() {
var str1 string = "字符串1"
var str2 string = "字符串2"
fmt.Printf("%s,%s\n", str1, str2)
//编码表 ASCII字符变
str3 := 'A'//单引号是表示字符
str4 := '中'
fmt.Printf("%T,%d\n", str3, str3)
fmt.Printf("%T,%d\n", str4, str4)
}

2.2.10 字符串操作
| 操作 | 符号 |
|---|---|
| 字符串连接 | + |
| 转义字符 | \ |
| 换行 | \n |
| 制表符(Tab键) | \t |
package main
import "fmt"
func main() {
fmt.Println("你好" + "世界!")
fmt.Println("你好\"" + "世界!") //打印"
fmt.Println("你好\n" + "世界!") //换行
fmt.Println("你好\t" + "世界!") //制表符
}

2.2.11 数据类型的转换
一种类型转换成另一种的类型的值,由于Go语言不存在隐式类型转换,因此所有的类型必须显式的声明
valueOfTypeB = typeB(valueofTypeA)
类型B的值 = 类型B(类型A的值)
package main
import "fmt"
func main() {
a := 0.5
b := int(a)
fmt.Printf("%T,%.1f\n", a, a)
fmt.Printf("%T,%d\n", b, b)
}

2.3、常量
2.3.1 定义
定义:常量是哥简单的标识符,在程序运行时,不会被修改的变量
常量的数据类型只能是布尔型、数字型(整数型、浮点型和复数)和字符串型
const identifier [type] = value
可以省略类型的说明符[type],因为编译过程会推断常量的类型
- 显式定义: const a string ="abc"
- 隐式定义: const b ="abc"
多个相同类型简写:
const a,b = valuea,valueb
package main
import "fmt"
func main() {
const name string = "ZHANGSAN"
const name1 = "lisi"
const a, b, c = 1, "test", 3.14
fmt.Println(name, name1)
fmt.Println(a, b, c)
}
输出

2.3.2 iota
iota 是特殊的常量,可以认为是一个被编译计数器修改的常量,iota是go语言的常量计数器,iota的初始值为0,依次递增,出现常量时就会+1。
iota在遇到const关键字出现的时候时将被重置为0
package main
import "fmt"
func main() {
const (
a = iota
b = iota
c = iota
)
fmt.Println(a, b, c)
}
输出

可以看到iota的值为0,1,2,i
package main
import "fmt"
func main() {
const (
a = iota
b
c = "test"
d
f = 200
g
h = iota
i
)
const (
j = iota
k
)
fmt.Println(a, b, c, d, f, g, h, i, j, k)
}
输出

得出结论,当常量没有定义时就会继承上一个常量的值,iota为依次递增的整数,直到下次遇到const重置为0
变量的数据
2.4、运算符
-
算数运算符
-
关系运算符
-
逻辑运算符
-
位运算符
-
赋值运算符
-
其他运算符
2.4.1 算数运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 相加 | A+B |
| - | 相减 | A-B |
| * | 相乘 | A*B |
| / | 相除 | B/A |
| % | 求余 | B%A |
| ++ | 自加 | A++ |
| -- | 自减 | A-- |
2.4.2 关系运算符
假设A=1,B=2
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 判断两值是否相等 | (A==B)为 False |
| != | 判断两值是否不相等 | (A!=B) 为 True |
| > | 判断左边是够大于右边 | (A>B)为 False |
| < | 判断右边是够大于左边 | (A<B)为 True |
| >= | 判断左边是够大于等于右边 | (A>=B)为 False |
| <= | 判断右边是够大于等于左边 | (A<=B)为 True |
2.4.3、逻辑运算符
假设A为True,B为False
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 逻辑运算符AND,一假为假 | A&&B 为 False |
| || | 逻辑运算符OR ,一真为真 | A||B 为True |
| ! | 逻辑运算符NOT,否定 | !A 为 Flase , !B 为 True |
2.4.4、位运算符
假定A为60(0011 1100),B为13(0000 1101)
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符“&”是双目运算符。都是1 结果为1,否则为0 | (A&B)结果为12,二进制为0000 1100 |
| | | 按位或运算符“|”是双目运算符。都是0结果为0,否则为1 | (A|B)结果为61,二进制为0011 1101 |
| ^ | 按位异或 运算符“^”是双目运算符,不同为1,相同为0 | (A^B)结果为49,二进制0011 0001 |
| &^ | 位清空,a&^b,对于b上的每个数值,如果为0,则取a对应位上的数值,如果为1,则取0 | (A&^B)结果为240,二进制0011 0000 |
| << | 左移运算符“>>”是双目运算符,左移n位就是乘以2的n次方,其功能把“<<”左边的运算数的各二进位全部左移若干位,由“<<”右边的数指定移动的位数,高位丢弃,低位补0 | (A<<B)结果为15,二进制为1111 0000 |
| >> | 右移运算符“>>”是双目运算符,右移n位就是除以2的n次方,其功能把“<<”右边的运算数的各二进位全部左移若干位,由“>>”右边的数指定移动的位数,高位丢弃,低位补0 | (A>>B)结果为15,二进制为0000 1111 |
2.4.5、赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| 赋值运算符,右边的值赋值给左边 | C=A+B | |
| += | 相加后再赋值 | C+=A 等于 C =C+A |
| -= | 相减后再赋值 | C-=A 等于 C =C-A |
| *= | 相乘后再赋值 | C=A 等于 C =CA |
| /= | 相除后再赋值 | C/=A 等于 C =C/A |
| %= | 求余后再赋值 | C%=A 等于 C =C%A |
| <<= | 左移后再赋值 | C<<=A 等于 C = C<<A |
| >>= | 右移后再赋值 | C>>=A 等于 C = C>>A |
| &= | 按位与后赋值 | C&=A 等于 C= C&A |
| ^= | 按位异或后赋值 | C^=A 等于 C= C^A |
| |= | 按位或后赋值 | C|=A 等于 C= C|A |
2.5、键盘的输入和输出
package main
import "fmt"
func main() {
/*fmt.Println()//换行打印
fmt.Printf()//格式化打印
fmt.Print()//打印输出
fmt.Scanln()//换行输入
fmt.Scanf()//格式化输入
fmt.Scan()//输入*/
fmt.Println("请输入整数型x,浮点数y")
var age int
var money float64
fmt.Scan(&age, &money) //从键盘获取输入,程序会在这里阻塞,等待输入
fmt.Println(age, money)
}

2.6、程序的流程控制
2.6.1 if语句
package main
import "fmt"
func main() {
var a int
fmt.Println("请输入整数型数字a:")
fmt.Scan(&a)
if a > 30 {
fmt.Println("a>30")
} else if a > 20 {
fmt.Println("a>20")
} else {
fmt.Println("a<20")
}
}
2.6.2 switch
package main
import "fmt"
func main() {
var a int
fmt.Println("请输入整数型数字a:")
fmt.Scan(&a)
switch a {
case 90:
fmt.Println("a=90")
case 80:
fmt.Println("a=80")
case 50, 60, 70:
fmt.Println("a=50/60/70")
default:
fmt.Println("a=其他")
}
}

fallthrough
fallthrough只能穿透一个case
package main
import "fmt"
func main() {
var a int
fmt.Println("请输入整数型数字a:")
fmt.Scan(&a)
switch a {
case 90:
fmt.Println("a=90")
fallthrough
case 80:
fmt.Println("a=80")
case 50, 60, 70:
fmt.Println("a=50/60/70")
default:
fmt.Println("a=其他")
}
}
2.6.3 for循环
使用分号";"隔离三个条件,第一个为条件为初始值,第二个为循环限制条件,第三个为每次循环的操作(自增或者自减等、)
package main
import "fmt"
func main() {
//写法一
sum := 0
for i := 0; i <= 1000; i++ {
sum = sum + i
}
fmt.Println(sum)
//写法二
j := 0
for j <= 10 {
fmt.Println(j)
j++
}
//写法三(无线循环 )
h := 0
for {
fmt.Println(h)
h++
}
}
题一,求1到1000的和
package main
import "fmt"
func main() {
sum := 0
for i := 0; i <= 1000; i++ {
sum = sum + i
}
fmt.Println(sum)
}
题二,打印5*5方阵
package main
import "fmt"
func main() {
for i := 1; i <= 5; i++ {
for j := 1; j <= 5; j++ {
fmt.Print("* ")
}
fmt.Println()
}
}
题三,打印99乘法表
package main
import "fmt"
func main() {
for i := 1; i <= 9; i++ {
for j := 1; j <= i; j++ {
fmt.Printf("%d*%d=%d ", j, i, j*i)
}
fmt.Println()
}
}
break,结束整改循环
package main
import "fmt"
func main() {
for i := 1; i <= 9; i++ {
if i == 5 {
break
}
fmt.Println(i)
}
}

continue,结束当此循环
package main
import "fmt"
func main() {
for i := 1; i <= 9; i++ {
if i == 5 {
continue
}
fmt.Println(i)
}
}

String
String字符串是一个字节的切片,字符串是字节的集合,Go中的字符串是unico兼容的,并且是UTF-8编码,string内的字符不可以修改
package main
import "fmt"
func main() {
str := "hello,world"
fmt.Println(str)
fmt.Println(len(str))
/*获取指定的字节*/
fmt.Println(str[0])
fmt.Printf("%c\n", str[0])
//打印字符串
for i := 0; i < len(str); i++ {
fmt.Printf("%c\n", str[i])
}
}

for range使用
package main
import "fmt"
func main() {
str := "hello,world"
//for range,遍历循环数组和切片....
//返回下标和对应的值
for i, v := range str {
fmt.Print(i)
fmt.Printf("%c\n", v)
}
}


2.7、函数
go语言至少有一个main函数,作为函数的入口
2.7.1、函数的声明
函数必须有函数名,无、一个或者多个函数的参数以及参数类型,无、一个或者多个返回值的类型
func function_name([parameter list parameter_type])(return_types){
函数体
}
例子:
package main
import "fmt"
func main() {
add(1, "test")
}
func add(a int, b string) int {
fmt.Printf("a:%d\n", a)
fmt.Printf("b:%s\n", b)
return a
}
例子2:加法
package main
import "fmt"
func main() {
fmt.Println(add(1, 2))
}
func add(a, b int) int {
return a + b
}
2.7.2、可变参数
当我们需要传入的参数为不确定的个数时,就可以使用可变参数
注意:
- 当存在多个参数时,可变参数要放到参数的最后面
- 一个函数有且仅有一个参数
func function_name(arg... int){
//arg ...int 表示这个函数接受不定量的参数,且都为int
}
package main
import "fmt"
func main() {
getSum(1, 2, 3, 4, 111)
}
func getSum(nums ...int) {
sums := 0
for i := 0; i < len(nums); i++ {
sums += nums[i]
}
fmt.Printf("sums:%d", sums)
}
2.7.3、参数传递
按照参数的存储类型特点来分:
- 值类型数据:操作的是数据本身、int、string、float32、float64、bool、array...
- 引用类型传递,操作的是数据的地址,slice、map、chan....
值传递
函数值传递,类似于拷贝的动作,只传输值,并不是传输值地址
package main
import "fmt"
func main() {
arr := [4]int{1, 2, 3, 4}
fmt.Println("main函数内:update函数执行前", arr)
//值传递,类似拷贝的动作
update(arr)
fmt.Println("main函数内:update函数执行后", arr)
}
func update(arr2 [4]int) {
fmt.Println("update函数内更新前的arr2:", arr2)
arr2[1] = 100
fmt.Println("update函数内更新后的arr2:", arr2)
}

引用传递
变量在内存中是存放在一个地址上的,修改变量实际是修改变量地址的值
package main
import "fmt"
func main() {
s1 := []int{1, 2, 3, 4}//切片
fmt.Println("main函数内:update函数执行前", s1)
//值传递,类似拷贝的动作
update(s1)
fmt.Println("main函数内:update函数执行后", s1)
}
func update(s2 []int) {
fmt.Println("update函数内更新前的arr2:", s2)
s2[1] = 100
fmt.Println("update函数内更新后的arr2:", s2)
}

2.7.4、递归函数
定义:自己调用自己的函数就是,递归函数
注意;递归函数需要出口,否则就是死循环
package main
import "fmt"
func main() {
fmt.Println(getSum(5))
}
func getSum(num int) int {
if num == 1 {
return 1
}
return getSum(num-1) + num
}
2.7.5、defer函数
延迟函数,用来延迟函数和方法的执行,遇到多个defer语句时回按照逆序执行,既采用后进先出的堆栈模式
当执行到defer语句时,参数已经被传输进去了,只是函数被延迟到最后才执行。
defer常采用的场景是关闭文件操作
package main
import "fmt"
func main() {
fmt.Println(1)
defer myprint(2)
fmt.Println(3)
defer myprint(4)
fmt.Println(5)
defer myprint(6)
fmt.Println(7)
defer myprint(8)
}
func myprint(num int) {
fmt.Println(num)
}

2.7.6、函数的本质
函数如果不加括号,函数就是个变量,加了括号就变成调用了
package main
import "fmt"
func main() {
//f1如果不加括号,函数f1就是个变量,加了括号就变成调用了
fmt.Printf("%T\n", f1) // fmt.Printf("%T", f1)
var f2 func(int, int)
f2 = f1
fmt.Println(f2)
fmt.Println(f1)
f2(1, 2)
}
func f1(a, b int) {
fmt.Println(a, b)
}

从输出结果看到他们指向的是同一个内存地址,所以调用的代码是一样的。
2.7.7、匿名函数
匿名函数就是没有名字的函数
package main
import "fmt"
func main() {
//没有加括号就是变量,就可以直接赋值
f2 := func() {
}
f2 = f1
f2()
//匿名函数,直接加括号调用
func() {
fmt.Println("我是f2函数")
}()
//匿名函数,直接传参数
func(a, b int) {
fmt.Println(a, b)
}(1, 2)
//匿名函数,传参数加返回值
c := func(a, b int) int {
return a + b
}(1, 2)
fmt.Println(c)
}
func f1() {
fmt.Println("我是f1函数")
}
注意:go语言是支持函数编程的:
-
将匿名函数作为另一个函数的参数,叫做回调函数
-
将匿名函数作为另一个函数的返回值,可以形成闭包结构

2.7.8、回调函数
高阶函数:根据go语言的数据类型的特点,可以将一个函数作为另一个函数的参数。
func1(),func2()
将func1函数作为func2这个函数的参数
func2函数:叫做高阶函数,接受一个函数作为参数的函数
func1函数:叫做回调函数,作为另一个函数的参数
使用场景:在想用一个方法产生不同的结果的时候就可以用回调函数
package main
import "fmt"
func main() {
r := add(1, 2)
fmt.Println(r)
//opr叫做高阶函数,接受函数作为参数的函数
//add叫做回调函数,作为另一个函数的参数
d := opr(2, 2, add)
fmt.Println(d)
//利用匿名函数做为回调函数
f := opr(3, 2, func(i int, j int) int {
return i + j
})
fmt.Println(f)
//opr叫做高阶函数,接受函数作为参数的函数
//sub叫做回调函数,作为另一个函数的参数
g := opr(8, 4, sub)
fmt.Println(g)
//利用匿名函数做为回调函数
h := opr(6, 3, func(i int, j int) int {
if j == 0 {
fmt.Println("除数不能为0")
}
return i / j
})
fmt.Println(h)
}
func opr(a, b int, f func(int, int) int) int {
c := f(a, b)
return c
}
func add(a, b int) int {
return a + b
}
func sub(a, b int) int {
if b == 0 {
fmt.Println("除数不能为0")
}
return a / b
}

2.7.9、闭包结构
一个外层函数中,有内层函数,该内层函数中,会操作外层函数的局部变量
并且该外层函数中的返回值就是这个内层函数
这个内层函数和外层函数的局部变量,统称闭包结构
package main
import "fmt"
func main() {
r1 := increament()
fmt.Println("r1内存地址:", r1)
v1 := r1()
fmt.Println("r1调用1次,结果:", v1)
v2 := r1()
fmt.Println("r1调用2次,结果:", v2)
v3 := r1()
fmt.Println("r1调用3次,结果:", v3)
fmt.Println("--------------------------")
r2 := increament()
fmt.Println("r2内存地址:", r2)
v4 := r2()
fmt.Println("r2调用1次,结果:", v4)
v5 := r1()
fmt.Println("r1在r2调用后再次调用", v5)
v6 := r2()
fmt.Println("r2在r1调用后再次调用", v6)
}
//自增函数
func increament() func() int {
//局部变量
i := 0
//定义一个匿名函数,给局部变量自增
fun := func() int {
i++
return i
}
return fun
}
2.8、数组
2.8.1 定义
数组是一种同类型元素的集合,在go语言中,数组从声明时就确定,使用时可以修改数组成员,但是不能改变数组的大小
var a [4] int
2.8.2 初始化
package main
import "fmt"
func main() {
//数组初始化,固定值
var cityArray = [4]string{"北京", "上海", "广州", "深圳"}
fmt.Println(cityArray)
//数组不指定数组长度,由编译器推到
var num = [...]int{1, 2, 3, 4, 5, 6, 7}
fmt.Println(num)
boolArray := [2]bool{true, false}
fmt.Println(boolArray)
//使用索引值方式初始化
var langArray = [...]string{1: "Golang", 3: "python", 7: "Java"}
fmt.Println(langArray)
fmt.Printf("%T\n", langArray)
}
2.8.3、遍历
package main
import "fmt"
func main() {
//1.利用索引遍历
var num = [7]int{1, 2, 3, 4, 5, 6, 7}
for i := 0; i < len(num); i++ {
fmt.Println(num[i])
}
//
var cityArray = [4]string{"北京", "上海", "广州", "深圳"}
for index, value := range cityArray {
fmt.Println(index, value)
}
}
2.8.4、多维数组
package main
import "fmt"
func main() {
//二位数组的初始化,外层可用...来推到数组长度,内层不可以
var cityArray = [...][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"}}
//二维数组的遍历
for _, value1 := range cityArray {
for _, value2 := range value1 {
fmt.Print(value2)
}
fmt.Println()
}
}
2.8.5、数组是值类型
数组在函数中传的是值,既拷贝动作
package main
import "fmt"
func main() {
var cityArray = [3][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"}}
f1(cityArray)
fmt.Println("main函数:", cityArray)
//拷贝动作
citys := cityArray
citys[0][0] = "中国"
fmt.Println("main函数:", cityArray)
}
func f1(a [3][2]string) {
a[0][0] = "中国"
fmt.Println("f1函数内:", a)
}
输出

2.9、切片
切片(Slice)是一个拥有相同类型元素的可变长度的序列,他是基于数组的一层封装
切片是一个引用类型,他内部结构包含地址、长度和容量,切片一般用于快速地操作一块数据集合。
2.9.1 定义
var name[] type
2.9.2、初始化
package main
import "fmt"
func main() {
//切片的初始化
var s = []int{}
fmt.Println(s)
fmt.Printf("%T\n", s)
//从数组得到切片
a := [5]int{1, 3, 5, 7, 8}
b := a[1:4]
fmt.Printf("a类型:%T\n", a)
fmt.Printf("b类型:%T\n", b)
fmt.Println(b)
//从切片中获取切片
c := b[:] //b[:]=b[0:len(b)]
fmt.Println(c)
fmt.Printf("c类型:%T\n", c)
//make()函数获取切片
d := make([]int, 5, 10) //切片的类型、长度、容量
fmt.Println(d)
fmt.Printf("d类型:%T\n", d)
//len()函数获取长度
fmt.Println("切片的长度", len(d))
//cap()函数获取容量
fmt.Println("切片的容量", cap(d))
}


切片是不能够比较的
不能使用”==“来比较两个切片的大小,切片唯一合法的操作是和nil比(nil就是切片的零值,比如int类型的0、string类型的空),一个nil值的切片长度和容量都是0,但是长度和容量为0的切片就是nil
package main
import "fmt"
func main() {
//声明一个切片,并没有去申请内存
var a []int
if a == nil {
fmt.Println("a==nil")
}
fmt.Println(a, len(a), cap(a))
//切片初始化
var b = []int{}
if b == nil {
fmt.Println("b==nil")
}
fmt.Println(b, len(b), cap(b))
//make()获取切片
c := make([]int, 0)
if c == nil {
fmt.Println("c==nil")
}
fmt.Println(c, len(c), cap(c))
}
所以我们通常通过len()函数判断一个切片是否为空
2.9.3、赋值拷贝
切片是引用类型,所以赋值时,调用的底层内存地址是相同的
package main
import "fmt"
func main() {
a := make([]int, 3)
b := a
b[1] = 100
fmt.Println(a)
fmt.Println(b)
}

2.9.4、遍历
切片跟数组一样都是可以采用索引遍历和range遍历
package main
import "fmt"
func main() {
a := []int{1, 2, 3, 4, 5, 6, 7}
for i := 0; i < len(a); i++ {
fmt.Println(a[i])
}
fmt.Println("-------------")
for _, v := range a {
fmt.Println(v)
}
}
2.9.5、操作切片元素
appen可以追加多个函数
package main
import "fmt"
func main() {
//切片的扩容
var a []int
for i := 0; i < 10; i++ {
a = append(a, i)
fmt.Printf("%v len:%d cap:%d ptr:%p\n", a, len(a), cap(a), a)
}
}
输出

可以看到,当切片容量不够时,就会申请新的内存来存储
追加多个元素
package main
import "fmt"
func main() {
//切片的扩容
var a []int
a = append(a, 1, 2, 3, 4, 5)
fmt.Println(a)
b := []int{12, 13, 14, 15}
a = append(a, b...)
fmt.Println(a)
}

使用copy函数复制切片
因为切片是一个引用值,如果直接赋值就会使用同一个内存地址,所以可以使用copy函数获取相同元素、长度和容量,但是不同地址的切片
package main
import "fmt"
func main() {
//切片的复制
var a []int
a = append(a, 1, 2, 3, 4, 5)
b := make([]int, 5, 5)
//拷贝切片,从新申请了一个内存地址
copy(b, a)
//赋值,调用的是同一个内存地址
c := a
c[0] = 100
fmt.Println(a)
fmt.Println(b)
fmt.Println(c)
}

使用append删除切片元素
package main
import "fmt"
func main() {
//切片的删除
a := []string{"北京", "上海", "广州", "深圳"}
a = append(a[0:2], a[3:]...)//append(a[0:index],a[3:]...)
fmt.Println(a)
}
2.10、Map
Go语言中提供的映射关系为map,其内部使用散列表(hash)实现。
map是一种无序的基于key-value的数据结构,map是引用类型,必须初始化才能使用
定义
map[keyType] valueType //keyType键类型,valueType值类型
map变量的默认初始值nil,需要使用make()函数来分配内存。
make(map[KeyType]ValueType,[cap])//cap表示容量,不是必须
2.10.1、初始化
正确用法--make()
package main
import "fmt"
func main() {
m := make(map[string]int, 10)
m["张三"] = 80
m["李四"] = 90
fmt.Println(m)
fmt.Println(m["张三"])
fmt.Printf("type of m:%T\n", m)
fmt.Printf("%#v\n", m) //%#v 输出Go语言语法格式的值
var m1 = map[int]string{1: "北京", 2: "上海"}
fmt.Printf("type:%T map:%#v len:%d", m1, m1, len(m1))
}

错误用法
package main
import "fmt"
func main() {
var m map[int]string //声明变量
//添加键值对,由于未分配内存,编译运行报错
m[1] = "张三"
fmt.Println(m)
}

2.10.2、map是否存在key
package main
import "fmt"
func main() {
//使用make函数创建
m := make(map[string]int, 10)
//添加键值对
m["张三"] = 80
m["李四"] = 90
//判断是否存在key
value, ok := m["张三"] //value表示该键的值,ok存在就为true,否则为false的布尔值
if ok {
fmt.Println("存在该key,值为:", value)
} else {
fmt.Println("查无此键值对")
}
}
输出

2.10.3、遍历
package main
import "fmt"
func main() {
//使用make函数创建
m := make(map[string]int, 10)
//添加键值对
m["张三"] = 80
m["李四"] = 90
//遍历
for k, v := range m {
fmt.Println(k, v)
}
//遍历key
for k, _ := range m {
fmt.Println(k)
}
//遍历value
for _, v := range m {
fmt.Println(v)
}
}

2.10.4、删除键值对--delete
package main
import "fmt"
func main() {
//使用make函数创建
m := make(map[string]int, 10)
//添加键值对
m["张三"] = 80
m["李四"] = 90
fmt.Printf("%#v\n", m)
//删除键值对
delete(m, "张三")
fmt.Printf("%#v\n", m)
}
2.10.5、对map排序
package main
import (
"fmt"
"math/rand"
"sort"
)
func main() {
//使用make函数创建
m := make(map[string]int, 100)
//添加键值对
for i := 0; i < 50; i++ {
key := fmt.Sprintf("stu%02d", i) //Sprintf将一个格式化的字符串输出到一个目的字符串中,printf是将一个格式化的字符串输出到屏幕。
value := rand.Intn(100) //随机取0到99的书
m[key] = value
}
//根据key从小到大排序
//1.取出所有的键,赋值给切片
keys := make([]string, 0, 100)
for k, _ := range m {
keys = append(keys, k)
}
//2.对key排序
sort.Strings(keys)
//3.根据排序后的key,从新排序map
for _, key := range keys {
fmt.Println(key, m[key])
}
}

2.10.6、元素类型为map 的切片
package main
import "fmt"
func main() {
//元素类型为map的切片
mapSlice := make([]map[string]int, 8, 8) //切片的初始化
fmt.Println(mapSlice[0] == nil)
mapSlice[0] = make(map[string]int) //map的初始化
mapSlice[0]["张三"] = 100 //map赋值
fmt.Println(mapSlice[0])
}

2.10.7、值为切片的map
package main
import "fmt"
func main() {
//值为切片的map
sliceMap := make(map[string][]int, 8) //初始化map
v, ok := sliceMap["张三"]
if ok {
fmt.Println(v)
} else {
sliceMap["张三"] = make([]int, 8, 8) //切片的初始化,长度和容量都为8的切片
sliceMap["张三"][0] = 100
sliceMap["张三"][1] = 100
sliceMap["张三"][3] = 100
sliceMap["张三"][4] = 100
}
//遍历
for k, v := range sliceMap {
fmt.Println(k, v)
}
}

2.10.8、练习
package main
import (
"fmt"
"strings"
)
func main() {
//统计一个字符串中每个单词出现的次数
//"how do you do"
var str string = "how do you do"
//1.定义一个map ,key用来存储单词,value表示出现的次数
wordsCount := make(map[string]int, 10)
//2.从大字符串中提取出单词
words := strings.Split(str, " ")
fmt.Printf("type:%T\n", words)
//3.遍历单词出现的次数判断单词出现的次数
for _, word := range words {
v, ok := wordsCount[word]
if ok {
wordsCount[word] = v + 1
} else {
wordsCount[word] = 1
}
}
for s, i := range wordsCount {
fmt.Println(s, i)
}
}

2.11、指针
指针的三个概念:指针地址、指针类型和指针取值
Go语言的函数传参的变量大部分都是值拷贝(引用类型的切片和map除外),当我们想要修改某个变量的时候,我们就可以创建一个指向该变量地址的指针变量传递数据使用指针,而无需拷贝数据。类型指针不能进行偏移或者运算。go语言中的指针操作给长简单只需要记住两个符号:&(取地址符)和*(根据地址取值)
2.11.1、指针地址/指针类型
每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go语言中使用&字符放在变量前对变量进行取地址操作。
go语言中的值类型(int、float、bool、string、array、struct)都有对应的指针类型,如:(*int,*int64,*string)
取变量指针的语法如下
ptr = &v //v的类型为T
- v:代表被取地址的变量,且其类型为T
- ptr:用于接收地址的变量,ptr的类型就为
*T,称为T类型的指针类型,*代表指针
package main
import "fmt"
func main() {
a := 10
b := &a
fmt.Printf("a:%v,a的地址:%p\n", a, &a)//a:10,a的地址:0x1400001e090
fmt.Printf("b:%v,b的类型:%T,b的地址:%p\n", b, b, &b)//b:0x1400001e090,b的类型:*int,b的地址:0x1400000e028
}

2.11.2、指针取值
在对普通的值变量使用&操作符取地址后会获得这个变量的指针,然后可以对指针使用*操作,也就是指针取值,代码如下z
package main
import "fmt"
func main() {
a := 10
b := &a
c := *b
fmt.Printf("b的值:%v,b的类型:%T\n", b, b) //b的值:0x1400001e090,b的类型:*int
fmt.Printf("c的值:%v,c的类型:%T\n", c, c)//c的值:10,c的类型:int
}
总结:取地址符&和取值操作符*是一对互补操作符,使用&取地址,使用*根据地址取出对应的值
- 对变量进行取地址(&)就能获取这个变量的指针变量
- 指针变量的值是指针地址
- 对指针变量进去取值(*)操作,可以获得指针变量指向原变量的值
2.11.3、指针传值
package main
import "fmt"
func main() {
a := 1
modify1(a)
fmt.Println(a)//1
modify2(&a) //使用取地址符获取a的地址
fmt.Println(a)//1000
}
func modify1(x int) {
x = 100
}
//参数为一个int指针类型
func modify2(y *int) {
*y = 1000 //对y进行取值操作
}
2.11.4、make和new
错误案列
package main
import "fmt"
func main() {
var a *int //声明了个指针,并没有实际上在内存中生成地址
*a = 100 //把100赋值给a内存地址的值,所以报错
fmt.Println(*a)
var b map[string]int //声明但是没有初始化
b["张三"] = 100 //调用错误
fmt.Println(b)
}
由于这样会报空指针错误,所以要学习new函数和make函数
new
new函数是一个内置函数,函数签名如下
func new(Type)*Type
其中
- Type表示类型(int),new函数只需要接受一个参数,就是参数类型
- Type表示类型指针(int),new函数返回一个指向该函数类型内存地址的指针
new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。
package main
import "fmt"
func main() {
a := new(int)
b := new(bool)
fmt.Printf("a的类型:%T,a的值:%v\n", a, *a)//a的类型:*int,a的值:0
fmt.Printf("b的类型:%T,b的值:%v\n", b, *b)//b的类型:*bool,b的值:false
}
错误案例中var a *int只是声明了一个变量但是并没有初始化,指针作为引用类型需要初始化后才会有用内存空间,才能给它赋值。所以应该如下操作
package main
import "fmt"
func main() {
var a *int
a = new(int)
*a = 10
fmt.Printf("a的类型:%T,a的值:%d", a, *a) //a的类型:*int,a的值:0
}
make
make也是用于内存分配,区别于new,他只用于slice、map以及chan的内存创造,而且他返回的是三个类型的本身,而不是他们的指针类型,因为这三种类型是引用类型,所以就没必要返回他们指针了,make函数签名如下
func make(t Type,size ...IntegerType) Type
make函数是无可替代的,我们使用slice、map和channel的时候,都需要使用make进行初始化,然后才可以对他们进行操作
错误案例中var b map[string]int,只声明了变量 ,没进行初始化,我们得初始化后才对键值对进行操作
package main
import "fmt"
func main() {
var b map[string]int
b = make(map[string]int, 8)
b["张三"] = 100
fmt.Println(b)
}
new和make区别
- 二者都是用来做内存分配的
- make只用于slice、map和channel的初始化,返回的是类型本身
- new用于类型的内存分配,并且内存对应的值为零值,返回的是类型的指针
2.12、类型的别名和自定义类型
自定义类型
go 语言有基本的数据类型,如:string、int等...,go可以使用type关键字来定义类型
type MyInt int
通过type定义,MyInt就是一种新的类型,它具有int类型的特性
package main
import "fmt"
func main() {
//自定义类型
type Myint int
var test Myint
fmt.Printf("%T,%v", test, test)
}
类型的别名
定义
type TypeAlias = Tyoe
例如
type byte =uint8
type rune =int32
类型的别名与类型定义区别
类型的别名与类型定义表面上只差一个等号的差异
package main
import "fmt"
func main() {
//自定义类型
type newInt int
//类型别名
type myInt = int
var test1 newInt
var test2 myInt
fmt.Printf("%T,%v\n", test1, test1) //main.newInt,0
fmt.Printf("%T,%v\n", test2, test2) //int,0
}
2.13、结构体
Go语言中的基础数据类型可以表示一些事物的基本属性,但是当我们想表达一个事物的全部或部分属性时,这时候再用单一的基本数据类型明显就无法满足需求了,Go语言提供了一种自定义数据类型,可以封装多个基本数据类型,这种数据类型叫结构体,英文名称struct。 也就是我们可以通过struct来定义自己的类型了。
Go语言中通过struct来实现面向对象。
2.13.1、定义
使用type和struct关键字来定义结构体,具体代码格式如下:
type 类型名 struct {
字段名 字段类型
字段名 字段类型
…
}
其中:
- 类型名:标识自定义结构体的名称,在同一个包内不能重复。
- 字段名:表示结构体字段名。结构体中的字段名必须唯一。
- 字段类型:表示结构体字段的具体类型。
如:定义一个人
type person struct {
name, city string
age int
}
2.13.2、实例化
只有当结构体实例化时,才会真正地分配内存。也就是必须实例化后才能使用结构体的字段。
结构体本身也是一种类型,我们可以像声明内置类型一样使用var关键字声明结构体类型。
var 结构体实例 结构体类型
基本实例化
package main
import "fmt"
type person struct {
name, city string
age int
}
func main() {
var person1 person
person1.name = "张三"
person1.age = 18
person1.city = "广州"
fmt.Printf("%#v\n", person1) //main.person{name:"张三", city:"广州", age:18}
fmt.Println(person1.name)
fmt.Println(person1.age)
fmt.Println(person1.city)
}
2.13.3、匿名结构体
package main
import "fmt"
type person struct {
name, city string
age int
}
func main() {
var user struct {
name string
sex string
}
user.name = "李四"
user.sex = "男"
fmt.Printf("%#v", user)
}
2.13.4、指针类型结构体
new函数
我们还可以通过使用new关键字对结构体进行实例化,得到的是结构体的地址。 格式如下:
package main
import "fmt"
type person struct {
name, city string
age int
}
func main() {
p1 := new(person)
//(*p1).name = "张三"
//(*p1).age = 22
//(*p1).city = "广州"
p1.name = "张三"
p1.age = 22
p1.city = "广州"
fmt.Printf("type:%T\nvalue:%#v\n", p1, p1)
}
取地址符
package main
import "fmt"
type person struct {
name, city string
age int
}
func main() {
p1 := &person{}
p1.name = "张三"
p1.age = 22
p1.city = "广州"
fmt.Printf("type:%T\nvalue:%#v\n", p1, p1)
}
注意:p1.name = "张三",实际上就是(*p1).name = "张三",这go底层帮我们实现的
2.13.5、初始化
使用键值对进行初始化
package main
import "fmt"
type person struct {
name, city string
age int
}
func main() {
p1 := person{
name: "李四",
age: 18,
city: "广州",
}
fmt.Printf("%#v\n", p1)//main.person{name:"李四", city:"广州", age:18}
}
取地址符进行初始化
package main
import "fmt"
type person struct {
name, city string
age int
}
func main() {
p1 := &person{
name: "李四",
age: 18,
city: "广州",
}
fmt.Printf("%#v\n", p1)//&main.person{name:"李四", city:"广州", age:18}
}
注意:当某些字段没有赋值时,该字段可以不写。此时没有指定的字段的值就是零值
使用值的列表进行初始化
package main
import "fmt"
type person struct {
name, city string
age int
}
func main() {
p1 := &person{
"李四",
"广州",
18,
}
fmt.Printf("%#v\n", p1) //&main.person{name:"李四", city:"广州", age:18}
}
使用这种格式初始化时,需要注意:
- 必须初始化结构体的所有字段。
- 初始值的填充顺序必须与字段在结构体中的声明顺序一致。
- 该方式不能和键值初始化方式混用。
2.13.6、构造函数
Go语言的结构体没有构造函数,我们可以自己实现。 例如,下方的代码就实现了一个person的构造函数。 因为struct是值类型,如果结构体比较复杂的话,值拷贝性能开销会比较大,所以该构造函数返回的是结构体指针类型。
package main
import "fmt"
type person struct {
name, city string
age int
}
func main() {
p1 := newPerson("张三", "广州", 29)
fmt.Printf("%#v", p1)//&main.person{name:"张三", city:"广州", age:29}
}
func newPerson(name, city string, age int) *person {
return &person{
name: name,
city: city,
age: age,
}
}
2.13.7、方法和接受者
Go语言中的方法(Method)是一种作用于特定类型变量的函数。这种特定类型变量叫做接收者(Receiver)。接收者的概念就类似于其他语言中的this或者 self
方法的定义
func (接受者变量,接受者类型)方法名(参数列表)(返回参数){
函数体
}
其中,
-
接收者变量:接收者中的参数变量名在命名时,官方建议使用接收者类型名称首字母的小写,而不是
self、this之类的命名。例如,Person类型的接收者变量应该命名为p,Connector类型的接收者变量应该命名为c等。 -
接收者类型:接收者类型和参数类似,可以是指针类型和非指针类型。
-
方法名、参数列表、返回参数:具体格式与函数定义相同。
例子:
package main
import "fmt"
//Person 是个结构体,首字母大写是要添加注释,方便外界调用和获取
type Person struct {
name, city string
age int
}
//NewPerson 是 Person的构造函数
func NewPerson(name, city string, age int) *Person {
return &Person{
name: name,
city: city,
age: age,
}
}
//Eat 是为Person类型定义的方法,接收值是值传递
func (p Person) Eat() {
fmt.Printf("%s吃饭了\n", p.name)
}
func main() {
p1 := NewPerson("张三", "广州", 29)
fmt.Printf("类型:%T\n", *p1) //类型:main.Person
fmt.Printf("值为%#v\n", *p1) //值为main.Person{name:"张三", city:"广州", age:29}
(*p1).Eat() //张三吃饭了
}
注意:方法与函数的区别是,函数不属于任何类型,方法属于特定的类型。
2.13.8、指针接受者和值接受者的区别
指针接受者
指针类型的接收者由一个结构体的指针组成,由于指针的特性,调用方法时修改接收者指针的任意成员变量,在方法结束后,修改都是有效的。这种方式就十分接近于其他语言中面向对象中的this或者self。 例如我们为Person添加一个SetAge方法,来修改实例变量的年龄。
package main
import "fmt"
//Person 是个结构体,首字母大写是要添加注释,方便外界调用和获取
type Person struct {
name, city string
age int
}
//NewPerson 是 Person的构造函数
func NewPerson(name, city string, age int) *Person {
return &Person{
name: name,
city: city,
age: age,
}
}
//SetAge 是用来修改Person的年龄的,接受者是引用传递
func (p *Person) SetAge(age int) {
p.age = age
}
func main() {
p1 := NewPerson("张三", "广州", 29)
fmt.Printf("类型:%T\n", p1) //类型:*main.Person
fmt.Printf("值为%#v\n", p1) //值为&main.Person{name:"张三", city:"广州", age:29}
p1.SetAge(20)
fmt.Printf("值为%#v\n", p1) //值为&main.Person{name:"张三", city:"广州", age:20}
}
值接受者
当方法作用于值类型接收者时,Go语言会在代码运行时将接收者的值复制一份。在值类型接收者的方法中可以获取接收者的成员值,但修改操作只是针对副本,无法修改接收者变量本身。
package main
import "fmt"
//Person 是个结构体,首字母大写是要添加注释,方便外界调用和获取
type Person struct {
name, city string
age int
}
//NewPerson 是 Person的构造函数
func NewPerson(name, city string, age int) *Person {
return &Person{
name: name,
city: city,
age: age,
}
}
//Eat 是为Person类型定义的方法
func (p Person) Eat() {
fmt.Printf("%s吃饭了\n", p.name)
}
//SetAge 是用来修改Person的年龄的,接受者是引用类型
func (p *Person) SetAge(age int) {
p.age = age
}
//SetAge2 是用来修改Person的年龄的,接受者是值类型
func (p Person) SetAge2(age int) {
p.age = age
fmt.Printf("SetAge2方法内部:%#v\n", p)//SetAge2方法内部:main.Person{name:"张三", city:"广州", age:10}
}
func main() {
p1 := NewPerson("张三", "广州", 29)
fmt.Printf("类型:%T\n", p1) //类型:*main.Person
fmt.Printf("值为%#v\n", p1) //值为&main.Person{name:"张三", city:"广州", age:29}
p1.SetAge(20)
fmt.Printf("值为%#v\n", p1) //值为&main.Person{name:"张三", city:"广州", age:20}
p1.SetAge2(10)
fmt.Printf("值为%#v\n", p1) //值为&main.Person{name:"张三", city:"广州", age:20}
}
什么时候使用指针接受者
- 需要修改接收者中的值
- 接收者是拷贝代价比较大的大对象
- 保证一致性,如果有某个方法使用了指针接收者,那么其他的方法也应该使用指针接收者。
2.13.9、任意类型都可以添加方法
在Go语言中,接收者的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法。 举个例子,我们基于内置的int类型使用type关键字可以定义新的自定义类型,然后为我们的自定义类型添加方法。
package main
import "fmt"
//为任意类型添加方法
//MyInt 自定义类型
type MyInt int
func (m MyInt) sayHi() {
fmt.Printf("%d say Hi!", m)
}
func main() {
var i MyInt = 10
i.sayHi()//10 say Hi!
}
注意事项: 非本地类型不能定义方法,也就是说我们不能给别的包的类型定义方法,只能给自己定义的方法添加方法。
2.13.10、结构体的匿名、嵌套、继承
结构体的匿名字段
package main
import "fmt"
//结构体的匿名字段
type Person struct {
string
int
}
func main() {
p1 := Person{
"张三",
18,
}
fmt.Println(p1.string, p1.int)
}
嵌套结构体
package main
import "fmt"
//嵌套结构体
//Address 自定义Address结构体类型
type Address struct {
Province string
City string
}
//Person 自定义Person结构
type Person struct {
Name string
Gender string
Age int
Address Address//嵌套结构体
}
func main() {
p1 := Person{
Name: "张三",
Gender: "男",
Age: 18,
Address: Address{
Province: "广东",
City: "河源",
},
}
fmt.Printf("p1:%#v\n", p1)//p1:main.Person{Name:"张三", Gender:"男", Age:18, Address:main.Address{Province:"广东", City:"河源"}}
fmt.Println(p1.Name, p1.Gender, p1.Age, p1.Address)//张三 男 18 {广东 河源}
}
嵌套匿名结构体
package main
import "fmt"
//嵌套结构体
//Address 自定义Address结构体类型
type Address struct {
Province string
City string
}
//Person 自定义Person结构
type Person struct {
Name string
Gender string
Age int
Address //通过字段类型嵌套匿名结构体
}
func main() {
p1 := Person{
Name: "张三",
Gender: "男",
Age: 18,
Address: Address{
Province: "广东",
City: "河源",
},
}
fmt.Printf("p1:%#v\n", p1)
fmt.Println(p1.Name, p1.Gender, p1.Age, p1.Address)
fmt.Println(p1.Address.Province) //通过匿名字段结构体访问内部的字段
fmt.Println(p1.Province) //直接访问匿名结构体中的字段
}
注意:如果多个嵌套结构体有个相同的字段(比如:收货地址和email地址都有更新时间),那么久不能直接访问匿名结构体中相同的字段
结构体的继承
package main
import "fmt"
//结构体的继承
type Animal struct {
name string
}
func (a *Animal) move() {
fmt.Printf("%s会移动\n", a.name)
}
type Dog struct {
Feet int
*Animal //匿名结构体嵌套,类似继承
}
func (d *Dog) wang() {
fmt.Printf("%s会汪汪汪汪叫\n", d.name)
}
func main() {
d1 := &Dog{
Feet: 4,
Animal: &Animal{
name: "小黑",
},
}
d1.wang()
d1.move()
}
2.13.11、结构体字段的可见性和json序列化
结构体字段的可见性
结构体中字段大写开头表示可公开访问,小写表示私有(仅在定义当前结构体的包中可访问)
结构体与json序列化
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写。同时也易于机器解析和生成。JSON键值对是用来保存JS对象的一种方式,键/值对组合中的键名写在前面并用双引号""包裹,使用冒号:分隔,然后紧接着值;多个键值之间使用英文,分隔。
package main
import (
"encoding/json"
"fmt"
)
//结构体字段的可见性、json序列化
//如果Go语言中定义的标识符(函数名、方法名、变量名)是首字符大写的话,那么他就是对外可见的
type Student struct {
ID int
Name string
}
type Class struct {
Title string
Students []Student
}
func NewStudent(id int, name string) Student {
return Student{
ID: id,
Name: name,
}
}
func main() {
//声明一个班级
c1 := Class{
Title: "初二1班",
Students: make([]Student, 0, 20),
}
//往班级添加学生
for i := 0; i < 10; i++ {
//新建学生
tempStu := NewStudent(i, fmt.Sprintf("stu%02d", i))
//添加学生
c1.Students = append(c1.Students, tempStu)
}
fmt.Println(c1)
//JSON的序列化
data, err := json.Marshal(c1)
if err != nil {
fmt.Println("json marshal err,err:", err)
return
}
fmt.Printf("类型=%T\n", data)
fmt.Printf("json=%s\n", data)
//JSON的反序列化
jsonStr := "{\"Title\":\"初二1班\",\"Students\":[{\"ID\":0,\"Name\":\"stu00\"},{\"ID\":1,\"Name\":\"stu01\"},{\"ID\":2,\"Name\":\"stu02\"}]}"
var c2 Class
err = json.Unmarshal([]byte(jsonStr), &c2)
fmt.Println(err)
//如果值不是空值
if err != nil {
fmt.Println("json unmarshal err err:", err)
}
fmt.Println(c2)
}

如果结构体字段不大写,json包就不能识别结构体的字段,在序列化和反序列时,就不能对该字段进行操作
结构体标签Tag
Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来。 Tag在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
`key1:"value1" key2:"value2"`
结构体tag由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。同一个结构体字段可以设置多个键值对tag,不同的键值对之间使用空格分隔。
注意事项: 为结构体编写Tag时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式写错,编译和运行时都不会提示任何错误,通过反射也无法正确取值。例如不要在key和value之间添加空格。
package main
import (
"encoding/json"
"fmt"
)
//Student 学生
type Student struct {
ID int `json:"id" db:"stuId"` //通过指定tag实现json序列化该字段时的key,数据库db的该字段的stuId
Gender string //json序列化是默认使用字段名作为key
name string //私有不能被json包访问
}
func main() {
s1 := Student{
ID: 1,
Gender: "男",
name: "沙河娜扎",
}
data, err := json.Marshal(s1)
if err != nil {
fmt.Println("json marshal failed!")
return
}
fmt.Printf("json str:%s\n", data) //json str:{"id":1,"Gender":"男"}
}
2.14、go语言的包
在工程化的Go语言开发项目中,Go语言的源码复用是建立在包(package)基础之上的。本文介绍了Go语言中如何定义包、如何导出包的内容及如何导入其他包。
2.14.1、包介绍
Go语言中支持模块化的开发理念,在Go语言中使用包(package)来支持代码模块化和代码复用。一个包是由一个或多个Go源码文件(.go结尾的文件)组成,是一种高级的代码复用方案,Go语言为我们提供了很多内置包,如fmt、os、io等。
例如,在之前的章节中我们频繁使用了fmt这个内置包。
package main
import "fmt"
func main(){
fmt.Println("Hello world!")
}
上面短短的几行代码就涉及到了如何定义包以及如何引入其它包两个内容,接下来我们依次介绍一下它们。
2.14.2、定义包
我们可以根据自己的需要创建自定义包。一个包可以简单理解为一个存放.go文件的文件夹。该文件夹下面的所有.go文件都要在非注释的第一行添加如下声明,声明该文件归属的包。
package 包名

注意事项:
- 一个文件夹下面直接包含的文件只能归属一个
package,同样一个package的文件不能在多个文件夹下。 - 包名可以不和文件夹的名字一样,包名不能包含
-符号。 - 包名为
main的包为应用程序的入口包,这种包编译后会得到一个可执行文件,而编译不包含main包的源代码则不会得到可执行文件。
标识符的可见性
在同一个包内部声明的标识符都位于同一个命名空间下,在不同的包内部声明的标识符就属于不同的命名空间。想要在包的外部使用包内部的标识符就需要添加包名前缀,例如fmt.Println("Hello world!"),就是指调用fmt包中的Println函数。
如果想让一个包中的标识符(如变量、常量、类型、函数等)能被外部的包使用,那么标识符必须是对外可见的(public)。在Go语言中是通过标识符的首字母大/小写来控制标识符的对外可见(public)/不可见(private)的。在一个包内部只有首字母大写的标识符才是对外可见的。
例如:calc包中xxx.go 文件中,大写首字母的可以被外界访问,小写的不能被外界访问
package calc
import "fmt"
var Name = "张三"
var age = 18
type Person struct {
Name string
age int
}
type dog struct {
color string
Feet int
}
func Add(x, y int) int {
return x + y
}
func sayHi() {
fmt.Println("你好")
}
2.14.3、包的导入
要在代码中引用其他包的内容,需要使用import关键字导入使用的包。具体语法如下:
import "包的路径"
注意事项:
- import导入语句通常放在文件开头包声明语句的下面。
- 导入的包名需要使用双引号包裹起来。
- 包名是从
$GOPATH/src/后开始计算的,使用/进行路径分隔。 - Go语言中禁止循环导入包。
package main
//路径为在GOPaths/src目录下
import (
"fmt"
"stu01/calc"
)
func main() {
fmt.Println("12344")
res := calc.Add(1, 2)
fmt.Println(res)
}


可以看到标识符的可见性的验证,结构体内的大写字母依然不可以调用。
2.14.4、自定义包名
在导入包名的时候,我们还可以为导入的包设置别名。通常用于导入的包名太长或者导入的包名冲突的情况。具体语法格式如下:
import 别名 "包的路径"
例如:
多行导入(标准格式)
package main
//路径为在GOPaths/src目录下
import (
f "fmt"
c "stu01/calc"
)
func main() {
f.Println("12344")
res := c.Add(1, 2)
f.Println(res)
}
匿名导入
如果只希望导入包,而不使用包内部的数据时,可以使用匿名导入包。具体的格式如下:
import _ "包的路径"
匿名导入的包与其他方式导入的包一样都会被编译到可执行文件中。因为在不使用包的时候,会有格式错误
2.14.5、init()函数介绍
在Go语言程序执行时导入包语句会自动触发包内部init()函数的调用。需要注意的是: init()函数没有参数也没有返回值。 init()函数在程序运行时自动被调用执行,不能在代码中主动调用它。
在上面例子中,calc包加入init函数,并且在main函数中调用
calc/xxx.go
package calc
import "fmt"
var Name = "张三"
var age = 18
......
//init 函数
func init() {
fmt.Println("calc.init被调用")
fmt.Println("calc内部函数的变量age:", age)
}
mymain.go
package main
//路径为在GOPaths/src目录下
import (
f "fmt"
c "stu01/calc"
)
func main() {
f.Println("12344")
res := c.Add(1, 2)
f.Println(res)
}
输出

包的执行顺序

init函数执行顺序
Go语言包会从main包开始检查其导入的所有包,每个包中又可能导入了其他的包。Go编译器由此构建出一个树状的包引用关系,再根据引用顺序决定编译顺序,依次编译这些包的代码。

2.15、go module(解决包依赖)
go module是Go1.11版本之后官方推出的版本管理工具,并且从Go1.13版本开始,go module将是Go语言默认的依赖管理工具。
类似java的maven
2.15.1、GO111MODULE
要启用go module支持首先要设置环境变量GO111MODULE,通过它可以开启或关闭模块支持,它有三个可选值:off、on、auto,默认值是auto。
GO111MODULE=off禁用模块支持,编译时会从GOPATH和vendor文件夹中查找包。GO111MODULE=on启用模块支持,编译时会忽略GOPATH和vendor文件夹,只根据go.mod下载依赖。GO111MODULE=auto,当项目在$GOPATH/src外且项目根目录有go.mod文件时,开启模块支持。
简单来说,设置GO111MODULE=on之后就可以使用go module了,以后就没有必要在GOPATH中创建项目了,并且还能够很好的管理项目依赖的第三方包信息。
使用 go module 管理依赖后会在项目根目录下生成两个文件go.mod和go.sum。
2.15.2、GOPROXY
Go1.11之后设置GOPROXY命令为:
export GOPROXY=https://goproxy.cn
Go1.13之后GOPROXY默认值为https://proxy.golang.org,在国内是无法访问的,所以十分建议大家设置GOPROXY,这里我推荐使用goproxy.cn。
go env -w GOPROXY=https://goproxy.cn,direct
2.15.3、GOPRIVATE
设置了GOPROXY 之后,go 命令就会从配置的代理地址拉取和校验依赖包。当我们在项目中引入了非公开的包(公司内部git仓库或 github 私有仓库等),此时便无法正常从代理拉取到这些非公开的依赖包,这个时候就需要配置 GOPRIVATE 环境变量。GOPRIVATE用来告诉 go 命令哪些仓库属于私有仓库,不必通过代理服务器拉取和校验。
GOPRIVATE 的值也可以设置多个,多个地址之间使用英文逗号 “,” 分隔。我们通常会把自己公司内部的代码仓库设置到 GOPRIVATE 中,例如:
$ go env -w GOPRIVATE="git.mycompany.com"
这样在拉取以git.mycompany.com为路径前缀的依赖包时就能正常拉取了。
此外,如果公司内部自建了 GOPROXY 服务,那么我们可以通过设置 GONOPROXY=none,允许通内部代理拉取私有仓库的包。
2.15.4、Go mod命令
| 命令 | 介绍 |
|---|---|
| go mod init | 初始化项目依赖,生成go.mod文件 |
| go mod download | 根据go.mod文件下载依赖 |
| go mod tidy | 比对项目文件中引入的依赖与go.mod进行比对 |
| go mod graph | 输出依赖关系图 |
| go mod edit | 编辑go.mod文件 |
| go mod vendor | 将项目的所有依赖导出至vendor目录 |
| go mod verify | 检验一个依赖包是否被篡改过 |
| go mod why | 解释为什么需要某个依赖 |
2.15.5、使用go module引入包
接下来我们将通过一个示例来演示如何在开发项目时使用 go module 拉取和管理项目依赖。
初始化项目 我们在本地新建一个名为holiday项目,按如下方式创建一个名为holiday的文件夹并切换到该目录下:
$ mkdir holiday
$ cd holiday
目前我们位于holiday文件夹下,接下来执行下面的命令初始化项目。
$ go mod init holiday
go: creating new go.mod: module holiday
该命令会自动在项目目录下创建一个go.mod文件,其内容如下。
module holiday
go 1.16
其中:
- module holiday:定义当前项目的导入路径
- go 1.16:标识当前项目使用的 Go 版本
go.mod文件会记录项目使用的第三方依赖包信息,包括包名和版本,由于我们的holiday项目目前还没有使用到第三方依赖包,所以go.mod文件暂时还没有记录任何依赖包信息,只有当前项目的一些信息。
接下来,我们在项目目录下新建一个main.go文件,其内容如下:
// holiday/main.go
package main
import "fmt"
func main() {
fmt.Println("现在是假期时间...")
}
然后,我们的holiday项目现在需要引入一个第三方包github.com/q1mi/hello来实现一些必要的功能。类似这样的场景在我们的日常开发中是很常见的。我们需要先将依赖包下载到本地同时在go.mod中记录依赖信息,然后才能在我们的代码中引入并使用这个包
下载依赖包主要有两种方法。
第一种方法-
go get命令
第一种方法是在项目目录下执行go get命令手动下载依赖的包
holiday $ go get -u github.com/q1mi/hello
go get: added github.com/q1mi/hello v0.1.1

这样默认会下载最新的发布版本,你也可以指定想要下载指定的版本号的
holiday $ go get -u github.com/q1mi/hello@v0.1.0
go: downloading github.com/q1mi/hello v0.1.0
go get: downgraded github.com/q1mi/hello v0.1.1 => v0.1.0

如果依赖包没有发布任何版本则会拉取最新的提交,最终go.mod中的依赖信息会变成类似下面这种由默认v0.0.0的版本号和最新一次commit的时间和hash组成的版本格式:
require github.com/q1mi/hello v0.0.0-20210218074646-139b0bcd549d
如果想指定下载某个commit对应的代码,可以直接指定commit hash,不过没有必要写出完整的commit hash,一般前7位即可。例如:
holiday $ go get github.com/q1mi/hello@2ccfadd
go: downloading github.com/q1mi/hello v0.1.2-0.20210219092711-2ccfaddad6a3
go get: added github.com/q1mi/hello v0.1.2-0.20210219092711-2ccfaddad6a3
此时,我们打开go.mod文件就可以看到下载的依赖包及版本信息都已经被记录下来了。
module holiday
go 1.18
require github.com/q1mi/hello v0.1.0 // indirect

行尾的indirect表示该依赖包为间接依赖,说明在当前程序中的所有 import 语句中没有发现引入这个包。
另外在执行go get命令下载一个新的依赖包时一般会额外添加-u参数,强制更新现有依赖。
第二种方法-直接编辑
go.mod文件
第二种方式是我们直接编辑go.mod文件,将依赖包和版本信息写入该文件。例如我们修改holiday/go.mod文件内容如下:
module holiday
go 1.16
require github.com/q1mi/hello latest
表示当前项目需要使用github.com/q1mi/hello库的最新版本,然后在项目目录下执行go mod download下载依赖包。
holiday $ go mod download

如果不输出其它提示信息就说明依赖已经下载成功,此时go.mod文件已经变成如下内容
module holiday
go 1.18
require github.com/q1mi/hello v0.1.1
这种方法同样支持指定想要下载的commit进行下载,例如直接在go.mod文件中按如下方式指定commit hash,这里只写出来了commit hash的前7位。
require github.com/q1mi/hello 2ccfadda
执行go mod download下载完依赖后,go.mod文件中对应的版本信息会自动更新为类似下面的格式。
module holiday
go 1.18
require github.com/q1mi/hello v0.1.2-0.20210219092711-2ccfaddad6a3
下载好要使用的依赖包之后,我们现在就可以在holiday/main.go文件中使用这个包了
package main
import (
"fmt"
"github.com/q1mi/hello"
)
func main() {
fmt.Println("现在是假期时间......")
hello.SayHi("zhangsan")
}

缺少go.sum,使用
go mod tidy
执行无返回,目录生成go.sum,继续go run代码

当我们的项目功能越做越多,代码越来越多的时候,通常会选择在项目内部按功能或业务划分成多个不同包。Go语言支持在一个项目(project)下定义多个包(package)。
例如,我们在holiday项目内部创建一个新的package——summer,此时新的项目目录结构如下:
holidy
├── go.mod
├── go.sum
├── main.go
└── summer
└── summer.go
其中holiday/summer/summer.go文件内容如下:
package summer
import "fmt"
// Diving 潜水...
func Diving() {
fmt.Println("夏天去诗巴丹潜水...")
}
此时想要在当前项目目录下的其他包或者main.go中调用这个Diving函数需要如何引入呢?这里以在main.go中演示详细的调用过程为例,在项目内其他包的引入方式类似
package main
import (
"fmt"
"github.com/q1mi/hello"
"holiday/summer"
)
func main() {
fmt.Println("现在是假期时间......")
hello.SayHi("zhangsan")
summer.Diving()
}
导入本地的一个包
如果你想要导入本地的一个包,并且这个包也没有发布到到其他任何代码仓库,这时候你可以在go.mod文件中使用replace语句将依赖临时替换为本地的代码包。例如在我的电脑上有另外一个名为liwenzhou.com/overtime的项目,它位于holiday项目同级目录下
├── holiday
│ ├── go.mod
│ ├── go.sum
│ ├── main.go
│ └── summer
│ └── summer.go
└── overtime
├── go.mod
└── overtime.go
由于liwenzhou.com/overtime包只存在于我本地,并不能通过网络获取到这个代码包,这个时候应该如何在holidy项目中引入它呢?
我们可以在holidy/go.mod文件中正常引入liwenzhou.com/overtime包,然后像下面的示例那样使用replace语句将这个依赖替换为使用相对路径表示的本地包。
module holiday
go 1.18
require github.com/q1mi/hello v0.1.1
require liwenzhou.com/overtime v0.0.0
replace liwenzhou.com/overtime => ../overtime
这样,我们就可以在holiday/main.go下正常引入并使用overtime包了
package main
import (
"fmt"
"github.com/q1mi/hello"
"holiday/summer"
"liwenzhou.com/overtime"
)
func main() {
fmt.Println("现在是假期时间......")
hello.SayHi("zhangsan")
summer.Diving()
overtime.Do()
}
我们也经常使用replace将项目依赖中的某个包,替换为其他版本的代码包或我们自己修改后的代码包
2.15.6、go.mod
go.mod文件记录了项目所有的依赖信息,其结构大致如下
module github.com/Q1mi/studygo/blogger
go 1.12
require (
github.com/DeanThompson/ginpprof v0.0.0-20190408063150-3be636683586
github.com/gin-gonic/gin v1.4.0
github.com/go-sql-driver/mysql v1.4.1
github.com/jmoiron/sqlx v1.2.0
github.com/satori/go.uuid v1.2.0
google.golang.org/appengine v1.6.1 // indirect
)
其中,
module用来定义包名require用来定义依赖包及版本indirect表示间接引用- v1.2.3:依赖包的版本号。支持以下几种格式:
- latest:最新版本
- v1.0.0:详细版本号
- commit hash:指定某次commit hash
引入某些没有发布过tag版本标识的依赖包时,go.mod中记录的依赖版本信息就会出现类似v0.0.0-20210218074646-139b0bcd549d的格式,由版本号、commit时间和commit的hash值组成

2.15.7、go.sum
使用go module下载了依赖后,项目目录下还会生成一个go.sum文件,这个文件中详细记录了当前项目中引入的依赖包的信息及其hash 值。go.sum文件内容通常是以类似下面的格式出现
<module> <version>/go.mod <hash>
或者
<module> <version> <hash>
<module> <version>/go.mod <hash>
不同于其他语言提供的基于中心的包管理机制,例如 npm 和 pypi等,Go并没有提供一个中央仓库来管理所有依赖包,而是采用分布式的方式来管理包。为了防止依赖包被非法篡改,Go module 引入了go.sum机制来对依赖包进行校验。

2.15.8、依赖保存的位置
Go module 会把下载到本地的依赖包会以类似下面的形式保存在 $GOPATH/pkg/mod目录下,每个依赖包都会带有版本号进行区分,这样就允许在本地存在同一个包的多个不同版本。
mod
├── cache
├── cloud.google.com
├── github.com
└──q1mi
├── hello@v0.0.0-20210218074646-139b0bcd549d
├── hello@v0.1.1
└── hello@v0.1.0
...

如果想清除所有本地已缓存的依赖包数据,可以执行 go clean -modcache 命令。
2.15.9、使用go module发布包
在上面的小节中我们学习了如何在项目中引入别人提供的依赖包,那么当我们想要在社区发布一个自己编写的代码包或者在公司内部编写一个供内部使用的公用组件时,我们该怎么做呢?接下来,我们就一起编写一个代码包并将它发布到github.com仓库,让它能够被全球的Go语言开发者使用。
我们首先在自己的 github 账号下新建一个项目,并把它下载到本地。我这里就以创建和发布一个名为hello的项目为例进行演示。这个hello包将对外提供一个名为SayHi的函数,它的作用非常简单就是向调用者发去问候。
$ git clone https://github.com/q1mi/hello
$ cd hello
我们当前位于hello项目目录下,执行下面的命令初始化项目,创建go.mod文件。需要注意的是这里定义项目的引入路径为github.com/q1mi/hello,读者在自行测试时需要将这部分替换为自己的仓库路径。
hello $ go mod init github.com/q1mi/hello
go: creating new go.mod: module github.com/q1mi/hello
接下来我们在该项目根目录下创建 hello.go 文件,添加下面的内容:
package hello
import "fmt"
func SayHi() {
fmt.Println("你好,我是七米。很高兴认识你。")
}
然后将该项目的代码 push 到仓库的远端分支,这样就对外发布了一个Go包。其他的开发者可以通过github.com/q1mi/hello这个引入路径下载并使用这个包了。
一个设计完善的包应该包含开源许可证及文档等内容,并且我们还应该尽心维护并适时发布适当的版本。github 上发布版本号使用git tag为代码包打上标签即可。
hello $ git tag -a v0.1.0 -m "release version v0.1.0"
hello $ git push origin v0.1.0
经过上面的操作我们就发布了一个版本号为v0.1.0的版本。
Go modules中建议使用语义化版本控制,其建议的版本号格式如下:
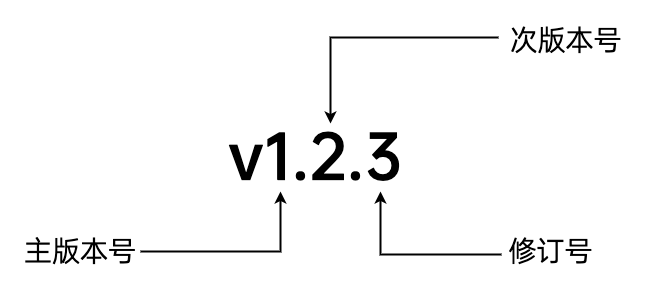
其中:
- 主版本号:发布了不兼容的版本迭代时递增(breaking changes)。
- 次版本号:发布了功能性更新时递增。
- 修订号:发布了bug修复类更新时递增。
2.15.9、在项目中使用 go module
既有项目
如果需要对一个已经存在的项目启用go module,可以按照以下步骤操作:
- 在项目目录下执行
go mod init,生成一个go.mod文件。 - 执行
go get,查找并记录当前项目的依赖,同时生成一个go.sum记录每个依赖库的版本和哈希值。
新项目
对于一个新创建的项目,我们可以在项目文件夹下按照以下步骤操作:
- 执行
go mod init 项目名命令,在当前项目文件夹下创建一个go.mod文件。 - 手动编辑
go.mod中的require依赖项或执行go get自动发现、维护依赖。
2.16、接口
接口(interface)定义了一个对象的行为规范,只定义规范不实现,由具体的对象来实现规范的细节。
在Go语言中接口(interface)是一种类型,一种抽象的类型。相较于之前章节中讲到的那些具体类型(字符串、切片、结构体等)更注重“我是谁”,接口类型更注重“我能做什么”的问题。接口类型就像是一种约定——概括了一种类型应该具备哪些方法,在Go语言中提倡使用面向接口的编程方式实现解耦。
2.16.1、接口类型
接口是一种由程序员来定义的类型,一个接口类型就是一组方法的集合,它规定了需要实现的所有方法。
相较于使用结构体类型,当我们使用接口类型说明相比于它是什么更关心它能做什么。
接口的定义
每个接口类型由任意个方法签名组成,接口的定义格式如下:
type 接口类型名 interface{
方法名1( 参数列表1 ) 返回值列表1
方法名2( 参数列表2 ) 返回值列表2
…
}
- 接口类型名:Go语言的接口在命名时,一般会在单词后面添加
er,如有写操作的接口叫Writer,有关闭操作的接口叫closer等。接口名最好要能突出该接口的类型含义。 - 方法名:当方法名首字母是大写且这个接口类型名首字母也是大写时,这个方法可以被接口所在的包(package)之外的代码访问。
- 参数列表、返回值列表:参数列表和返回值列表中的参数变量名可以省略。
举个例子,定义一个包含Write方法的Writer接口。
type Writer interface{
Write([]byte) error
}
当你看到一个Writer接口类型的值时,你不知道它是什么,唯一知道的就是可以通过调用它的Write方法来做一些事情。
实现接口的条件
接口就是规定了一个需要实现的方法列表,在 Go 语言中一个类型只要实现了接口中规定的所有方法,那么我们就称它实现了这个接口。
我们定义的Singer接口类型,它包含一个Sing方法。
// Singer 接口
type Singer interface {
Sing()
}
我们有一个Bird结构体类型如下。
type Bird struct {}
因为Singer接口只包含一个Sing方法,所以只需要给Bird结构体添加一个Sing方法就可以满足Singer接口的要求。
// Sing Bird类型的Sing方法
func (b Bird) Sing() {
fmt.Println("汪汪汪")
}
这样就称为Bird实现了Singer接口。
面相接口编程
例子:app的支付功能,用户可以选择微信支付、支付宝支付
package main
import "fmt"
type payer interface {
pay(name string, amount float64)
}
//微信结构体
type weixin struct {
name string
}
//微信给钱方法
func (w *weixin) pay(name string, amount float64) {
fmt.Printf("使用%s支付%.2f元\n", name, amount)
}
//支付宝结构体
type alipay struct {
name string
}
//支付宝给钱方法,指针可以方便修改传来的用户的余额--引用类型
func (a *alipay) pay(name string, amount float64) {
fmt.Printf("使用%s支付%.2f元\n", name, amount)
}
//支付操作
func allpay(arg payer, name string, amount float64) {
arg.pay(name, amount)
}
func main() {
w1 := &weixin{
name: "微信",
}
allpay(w1, w1.name, 100)
a1 := &alipay{
name: "支付宝",
}
allpay(a1, a1.name, 120)
}

所以不管你是什么类型,只要实现了接口中方法,就可以称之为实现了该接口,该接口为抽象类型
比如我们需要在某个程序中添加一个将某些指标数据向外输出的功能,根据不同的需求可能要将数据输出到终端、写入到文件或者通过网络连接发送出去。在这个场景下我们可以不关注最终输出的目的地是什么,只需要它能提供一个Write方法让我们把内容写入就可以了。
Go语言中为了解决类似上面的问题引入了接口的概念,接口类型区别于我们之前章节中介绍的那些具体类型,让我们专注于该类型提供的方法,而不是类型本身。使用接口类型通常能够让我们写出更加通用和灵活的代码。
2.16.2、接口类型变量
那实现了接口又有什么用呢?一个接口类型的变量能够存储所有实现了该接口的类型变量。
例如在上面的示例中,Dog和Cat类型均实现了Sayer接口,此时一个Sayer类型的变量就能够接收Cat和Dog类型的变量。
var x Sayer // 声明一个Sayer类型的变量x
a := Cat{} // 声明一个Cat类型变量a
b := Dog{} // 声明一个Dog类型变量b
x = a // 可以把Cat类型变量直接赋值给x
x.Say() // 喵喵喵
x = b // 可以把Dog类型变量直接赋值给x
x.Say() // 汪汪汪
2.16.3、值接受者和指针接受者
在结构体那一章节中,我们介绍了在定义结构体方法时既可以使用值接收者也可以使用指针接收者。那么对于实现接口来说使用值接收者和使用指针接收者有什么区别呢?接下来我们通过一个例子看一下其中的区别。
我们定义一个Mover接口,它包含一个Move方法。
// Mover 定义一个接口类型
type Mover interface {
Move()
}
实现mover接口,接口类型是person
type person struct {
name string
}
func (p person) move() {
fmt.Printf("%s在跑步....\n", p.name)
}
值接受者
package main
import "fmt"
type mover interface {
move()
}
type person struct {
name string
}
//值接受者
func (p person) move() {
fmt.Printf("%s在跑步....\n", p.name)
}
func main() {
p1 := person{
name: "张三",
}
p2 := &person{
name: "张三",
}
var m1 mover
var m2 mover
m1 = p1
m1.move()
fmt.Printf("type:%T,value:%v\n", m1, m1)
m2 = p2
m2.move()
fmt.Printf("type:%T,value:%v\n", m2, m2)
}

从上面的代码中我们可以发现,使用值接收者实现接口之后,不管是结构体类型还是对应的结构体指针类型的变量都可以赋值给该接口变量
指针接受者
我们将person结构体的move方法,改成指针接受者,编译执行看看是否有问题
package main
import "fmt"
type mover interface {
move()
}
type person struct {
name string
}
//指针接受者
func (p *person) move() {
fmt.Printf("%s在跑步....\n", p.name)
}
func main() {
p1 := person{
name: "张三",
}
p2 := &person{
name: "张三",
}
var m1 mover
var m2 mover
m1 = p1//p1变量是person结构体类型,没有实现mover接口类型(修改为指针接受者)
m1.move()
fmt.Printf("type:%T,value:%v\n", m1, m1)
m2 = p2
m2.move()
fmt.Printf("type:%T,value:%v\n", m2, m2)
}

错误显示p1变量是person结构体类型,没有实现mover接口类型(修改为指针接受者)
所以只有类型指针能够赋值到接口变量中
2.16.4、类型与接口的关系
一个类型可以实现多个接口
一个类型可以同时实现多个接口,而接口间彼此独立,不知道对方的实现。例如狗不仅可以叫,还可以动。我们完全可以分别定义Sayer接口和Mover接口,具体代码示例如下。
// Sayer 接口
type Sayer interface {
Say()
}
// Mover 接口
type Mover interface {
Move()
}
person既可以实现move接口,也可以实现say接口
package main
import "fmt"
type mover interface {
move()
}
type sayer interface {
say()
}
type person struct {
name string
}
//指针接受者
func (p *person) move() {
fmt.Printf("%s在跑步....\n", p.name)
}
func (p *person) say() {
fmt.Printf("%s在说话....\n", p.name)
}
func main() {
//同一个person结构体类型可以实现多个接口(sayer、mover)
p1 := &person{
name: "张三",
}
//声明接口类型变量
var m1 mover
m1 = p1
m1.move()
fmt.Printf("type:%T,value:%v\n", m1, m1)
var s1 sayer
s1 = p1
s1.say()
fmt.Printf("type:%T,value:%v\n", m1, m1)
}

多个接口实现一个类型
例子:人、狗两个结构体类型都可以实现mover接口
package main
import "fmt"
type mover interface {
move()
}
type person struct {
name string
}
//指针接受者
func (p *person) move() {
fmt.Printf("%s在跑步....\n", p.name)
}
type dog struct {
name string
}
func (d dog) move() {
fmt.Printf("%s在跳...\n", d.name)
}
func main() {
p1 := &person{
name: "张三",
}
d1 := dog{
name: "小狗",
}
//声明接口类型变量
var m1 mover
m1 = p1
m1.move()
fmt.Printf("type:%T,value:%v\n", m1, m1)
m1 = d1
d1.move()
fmt.Printf("type:%T,value:%v\n", d1, d1)
}

2.16.5、接口的嵌套
接口与接口之间可以通过互相嵌套形成新的接口类型
例子:animal中需要实现mover和sayer接口,
type animal interface {
mover //move()
sayer //say()
}
type mover interface {
move()
}
type sayer interface {
say()
}
person结构体类型实现了animal接口
type person struct {
name string
}
//指针接受者
func (p *person) move() {
fmt.Printf("%s在跑步....\n", p.name)
}
func (p *person) say() {
fmt.Printf("%s在说话....\n", p.name)
}
那么我们就可以直接调用了
package main
import "fmt"
type animal interface {
mover //move()
sayer //say()
}
type mover interface {
move()
}
type sayer interface {
say()
}
type person struct {
name string
}
//指针接受者
func (p *person) move() {
fmt.Printf("%s在跑步....\n", p.name)
}
func (p *person) say() {
fmt.Printf("%s在说话....\n", p.name)
}
func main() {
p1 := &person{
name: "张三",
}
//声明接口类型变量
var m1 mover
m1 = p1
m1.move()
fmt.Printf("type:%T,value:%v\n", m1, m1)
var s1 sayer
s1.say()
fmt.Printf("type:%T,value:%v\n", m1, m1)
}
对于这种由多个接口类型组合形成的新接口类型,同样只需要实现新接口类型中规定的所有方法就算实现了该接口类型.
接口也可以作为结构体的一个字段,我们来看一段Go标准库sort源码中的示例。
// src/sort/sort.go
// Interface 定义通过索引对元素排序的接口类型
type Interface interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}
// reverse 结构体中嵌入了Interface接口
type reverse struct {
Interface
}
通过在结构体中嵌入一个接口类型,从而让该结构体类型实现了该接口类型,并且还可以改写该接口的方法。
// Less 为reverse类型添加Less方法,重写原Interface接口类型的Less方法
func (r reverse) Less(i, j int) bool {
return r.Interface.Less(j, i)
}
Interface类型原本的Less方法签名为Less(i, j int) bool,此处重写为r.Interface.Less(j, i),即通过将索引参数交换位置实现反转。
在这个示例中还有一个需要注意的地方是reverse结构体本身是不可导出的(结构体类型名称首字母小写),sort.go中通过定义一个可导出的Reverse函数来让使用者创建reverse结构体实例。
func Reverse(data Interface) Interface {
return &reverse{data}
}
这样做的目的是保证得到的reverse结构体中的Interface属性一定不为nil,否者r.Interface.Less(j, i)就会出现空指针panic。
此外在Go内置标准库database/sql中也有很多类似的结构体内嵌接口类型的使用示例
2.16.6、空接口
空接口的定义
空接口是指没有定义任何方法的接口类型。因此任何类型都可以视为实现了空接口。也正是因为空接口类型的这个特性,空接口类型的变量可以存储任意类型的值。
package main
import "fmt"
//Any 不包含任何方法的接口,所以该接口可以接受任何类型的变量
type Any interface{}
//狗结构体
type dog struct {
}
func main() {
var x Any
x = "你好" // 字符串型
fmt.Printf("type:%T value:%v\n", x, x)
x = 100 // int型
fmt.Printf("type:%T value:%v\n", x, x)
x = true // 布尔型
fmt.Printf("type:%T value:%v\n", x, x)
x = dog{} // 结构体类型
fmt.Printf("type:%T value:%v\n", x, x)
}
通常我们在使用空接口类型时不必使用type关键字声明,可以像下面的代码一样直接使用interface{}。
var x interface{} // 声明一个空接口类型变量x
空接口的应用
空接口作为函数的参数
使用空接口实现可以接受任意类型的参数
package main
import "fmt"
func show(arg interface{}) {
fmt.Printf("type:%T value:%v\n", arg, arg)
}
func main() {
show("张三")
show(18)
}
空接口作为map的值
package main
import "fmt"
func main() {
m := make(map[string]interface{})
m["name"] = "张三"
m["age"] = 18
m["address"] = "广州"
m["gender"] = true
fmt.Println(m)
}
2.16.7、接口的值
由于接口类型的值可以是任意一个实现了该接口的类型值,所以接口值除了需要记录具体值之外,还需要记录这个值属于的类型。也就是说接口值由“类型”和“值”组成,鉴于这两部分会根据存入值的不同而发生变化,我们称之为接口的动态类型和动态值。

例子:
package main
import "fmt"
func main() {
var x interface{}
x = 100
fmt.Println(x)
}
此时接口的类型就是int,值就是100。
类型断言
接口值可能赋值为任意类型的值,那我们如何从接口值获取其存储的具体数据呢?
我们可以借助标准库fmt包的格式化打印获取到接口值的动态类型
package main
import "fmt"
func main() {
var x interface{}
x = 100
fmt.Printf("%T\n",x)
}
而想要从接口值中获取到对应的实际值需要使用类型断言,其语法格式如下
x.(T)
其中:
- x:表示接口类型的变量
- T:表示断言
x可能是的类型。
该语法返回两个参数,第一个参数是x转化为T类型后的变量,第二个值是一个布尔值,若为true则表示断言成功,为false则表示断言失败。
package main
import "fmt"
func main() {
var x interface{}
x = 100
res, ok := x.(int)
if ok {
fmt.Println("类型断言判断成功")
fmt.Printf("type:%T\n", res)
fmt.Printf("value:%v\n", res)
} else {
fmt.Println("类型断言判断失败")
}
}
如果对一个接口值有多个实际类型需要判断,推荐使用switch语句来实现
package main
import "fmt"
func main() {
var x interface{}
x = 100
justifyType(x)
}
// justifyType 对传入的空接口类型变量x进行类型断言
func justifyType(x interface{}) {
switch v := x.(type) {
case string:
fmt.Printf("x is a string,value is %v\n", v)
case int:
fmt.Printf("x is a int is %v\n", v)
case bool:
fmt.Printf("x is a bool is %v\n", v)
default:
fmt.Println("unsupport type!")
}
}
2.17、Error接口和错误处理
Go 语言中的错误处理与其他语言不太一样,它把错误当成一种值来处理,更强调判断错误、处理错误,而不是一股脑的 catch 捕获异常。
2.17.1、Error接口
Go 语言中使用一个名为 error 接口来表示错误类型
type error interface {
Error() string
}
error 接口只包含一个方法——Error,这个函数需要返回一个描述错误信息的字符串。
当一个函数或方法需要返回错误时,我们通常是把错误作为最后一个返回值
例如下面标准库 os 中打开文件的函数
func Open(name string) (*File, error) {
return OpenFile(name, O_RDONLY, 0)
}
由于 error 是一个接口类型,默认零值为nil,所以我们通常将调用函数返回的错误与nil进行比较,以此来判断函数是否返回错误。例如你会经常看到类似下面的错误判断代码。
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Open("./go.mod")
//因为err的空值为nil,所以的当nil不为空,表示产生错误
if err != nil {
fmt.Println("打开文件失败,err:", err)
} else {
//当err的值为空时,就是等于默认值,表示没有产生错误
fmt.Println(file.Name())
}
}
另一种写法,结果一样
file, err := os.Open("../go.mod")
//因为err的空值为nil,所以的当nil不为空,表示产生错误
if err != nil {
fmt.Println("打开文件失败,err:", err)
return
}
fmt.Println(file.Name())
注意
当我们使用fmt包打印错误时会自动调用 error 类型的 Error 方法,也就是会打印出错误的描述信息。
2.17.2、创建错误
Errors.new
函数签名如下,
func New(text string) error
它接收一个字符串参数返回包含该字符串的错误。我们可以在函数返回时快速创建一个错误。
func queryById(id int64) (*Info, error) {
if id <= 0 {
return nil, errors.New("无效的id")
}
// ...
}
或者用来定义一个错误变量,例如标准库io.EOF错误定义如下。
var EOF = errors.New("EOF")
fmt.Errorf
当我们需要传入格式化的错误描述信息时,使用fmt.Errorf是个更好的选择。
fmt.Errorf("查询数据库失败,err:%v", err)
但是上面的方式会丢失原有的错误类型,只拿到错误描述的文本信息。
为了不丢失函数调用的错误链,使用fmt.Errorf时搭配使用特殊的格式化动词%w,可以实现基于已有的错误再包装得到一个新的错误。
fmt.Errorf("查询数据库失败,err:%w", err)
对于这种二次包装的错误,errors包中提供了以下三个方法。
func Unwrap(err error) error // 获得err包含下一层错误
func Is(err, target error) bool // 判断err是否包含target
func As(err error, target interface{}) bool // 判断err是否为target类型
错误的结构体
此外我们还可以自己定义结构体类型,实现``error`接口。
// OpError 自定义结构体类型
type OpError struct {
Op string
}
// Error OpError 类型实现error接口
func (e *OpError) Error() string {
return fmt.Sprintf("无权执行%s操作", e.Op)
}
2.18、go的time包
Go 语言中使用time.Time类型表示时间。我们可以通过time.Now函数获取当前的时间对象,然后从时间对象中可以获取到年、月、日、时、分、秒等信息
package main
import (
"fmt"
"time"
)
func main() {
now := time.Now()
fmt.Println(now)
year := now.Year()
month := now.Month() // 月
day := now.Day() // 日
hour := now.Hour() // 小时
minute := now.Minute() // 分钟
second := now.Second() // 秒
fmt.Println(year, month, day, hour, minute, second)
}
2.18.1、Location和timezone
Go 语言中使用 location 来映射具体的时区。时区(Time Zone)是根据世界各国家与地区不同的经度而划分的时间定义,全球共分为24个时区。中国差不多跨5个时区,但为了使用方便只用东八时区的标准时即北京时间为准。
2.18.2、Unix Time
Unix Time是自1970年1月1日 00:00:00 UTC 至当前时间经过的总秒数。下面的代码片段演示了如何基于时间对象获取到Unix 时间
package main
import (
"fmt"
"time"
)
func main() {
// timestampDemo 时间戳
now := time.Now() // 获取当前时间
timestamp := now.Unix() // 秒级时间戳
milli := now.UnixMilli() // 毫秒时间戳 Go1.17+
micro := now.UnixMicro() // 微秒时间戳 Go1.17+
nano := now.UnixNano() // 纳秒时间戳
fmt.Println(timestamp, milli, micro, nano)
fmt.Printf("nano:%T", nano) //nano:int64
}
2.18.3、时间间隔
time.Duration是time包定义的一个类型,它代表两个时间点之间经过的时间,以纳秒为单位。time.Duration表示一段时间间隔,可表示的最长时间段大约290年
time 包中定义的时间间隔类型的常量如下:
const (
Nanosecond Duration = 1
Microsecond = 1000 * Nanosecond
Millisecond = 1000 * Microsecond
Second = 1000 * Millisecond
Minute = 60 * Second
Hour = 60 * Minute
)
例如:time.Duration表示1纳秒,time.Second表示1秒。
2.18.4、时间操作
Add
Go语言的时间对象有提供Add方法如下:
func (t Time) Add(d Duration) Time
举个例子,求一个小时之后的时间:
func main() {
now := time.Now()
later := now.Add(time.Hour) // 当前时间加1小时后的时间
fmt.Println(later)
}
Sub
求两个时间之间的差值:
func (t Time) Sub(u Time) Duration
返回一个时间段t-u。如果结果超出了Duration可以表示的最大值/最小值,将返回最大值/最小值。要获取时间点t-d(d为Duration),可以使用t.Add(-d)。
Equal
func (t Time) Equal(u Time) bool
判断两个时间是否相同,会考虑时区的影响,因此不同时区标准的时间也可以正确比较。本方法和用t==u不同,这种方法还会比较地点和时区信息。
Before
func (t Time) Before(u Time) bool
如果t代表的时间点在u之前,返回真;否则返回假。
After
func (t Time) After(u Time) bool
如果t代表的时间点在u之后,返回真;否则返回假。
2.18.5、定时器
使用time.Tick(时间间隔)来设置定时器,定时器的本质上是一个通道(channel)
package main
import (
"fmt"
"time"
)
func main() {
ticker := time.Tick(time.Second)//单位是毫秒
for t := range ticker {
fmt.Println(t)//每秒都会执行任务
}
}
2.18.6、时间格式化
time.Format函数能够将一个时间对象格式化输出为指定布局的文本表示形式,需要注意的是 Go 语言中时间格式化的布局不是常见的Y-m-d H:M:S,而是使用 2006-01-02 15:04:05.000(记忆口诀为2006 1 2 3 4 5)。
其中:
- 2006:年(Y)
- 01:月(m)
- 02:日(d)
- 15:时(H)
- 04:分(M)
- 05:秒(S)
补充
- 如果想格式化为12小时格式,需在格式化布局中添加
PM。 - 小数部分想保留指定位数就写0,如果想省略末尾可能的0就写 9。
package main
import (
"fmt"
"time"
)
func main() {
now := time.Now()
res := now.Format("2006-01-02 15:04:05")
fmt.Println(res)
res1 := now.Format("2006-01-02 15:04:05 PM")
fmt.Println(res1)
res2 := now.Format("2006-01-02 15:04:05 Mon Jan")
fmt.Println(res2)
res3 := now.Format("15:04:05")
fmt.Println(res3)
res4 := now.Format("2006-01-02")
fmt.Println(res4)
}
2.18.7、解析字符串格式时间
对于从文本的时间表示中解析出时间对象,time包中提供了time.Parse和time.ParseInLocation两个函数。
time.Parse
package main
import (
"fmt"
"time"
)
func main() {
// 在没有时区指示符的情况下,time.Parse 返回UTC时间
timeObj, err := time.Parse("2006-01-02 15:04:05", "2022-11-28 12:12:12")
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(timeObj)
}
time.ParseInLocation
package main
import (
"fmt"
"time"
)
func main() {
// 在没有时区指示符的情况下,time.Parse 返回UTC时间
timeObj, err := time.Parse("2006-01-02 15:04:05", "2022-11-28 12:12:12")
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(timeObj)
loc, err := time.LoadLocation("Asia/Shanghai")
timeObj, err = time.ParseInLocation("2006-01-02 15:04:05", "2022-11-28 12:12:12", loc)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(timeObj)
}
2.19、go的os-文件操作
计算机中的文件是存储在外部介质(通常是磁盘)上的数据集合,文件分为文本文件和二进制文件
2.19.1、打开个关闭文件
os.Open()函数能够打开一个文件,返回一个*File和一个err。对得到的文件实例调用close()方法能够关闭文件。
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Open("./go.mod")
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(file.Name())
file.Close()
}
2.19.2、读取文件
Read读取
Read方法定义如下:
func (f *File) Read(b []byte) (n int, err error)
package main
import (
"fmt"
"io"
"os"
)
func main() {
file, err := os.Open("./xx.txt")
if err != nil {
fmt.Println("Error:", err)
return
}
//使用defer在最后关闭文件
defer file.Close()
tmp := make([]byte, 128)
n, err := file.Read(tmp)
if err != nil {
fmt.Println("Error:", err)
return
}
if err == io.EOF {
fmt.Println("文件读取完了")
return
}
fmt.Printf("读取了%d个字节\n", n)
fmt.Printf("type:%T,value:%v\n", tmp, string(tmp))
}
循环读取文件
func readAll() {
file, err := os.Open("./mymain.go")
if err != nil {
fmt.Println("Error:", err)
return
}
//使用defer在最后关闭文件
defer file.Close()
//循环读取
var content []byte
tmp := make([]byte, 128)
for {
n, err := file.Read(tmp)
if err == io.EOF {
fmt.Println("文件读取完了")
break
}
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("读取了%d个字节\n", n)
content = append(content, tmp[:n]...)
}
fmt.Printf("type:%T,value:%v\n", tmp, string(content))
}
bufio读取
func readByBufio() {
file, err := os.Open("./xx.txt")
if err != nil {
fmt.Println("Error:", err)
return
}
//使用defer在最后关闭文件
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err == io.EOF {
if len(line) != 0 {
fmt.Println(line)
}
fmt.Println("文件读取完了")
break
}
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Print(line)
}
}
ioutil读取
文件太大不建议使用
func readByioutil() {
content, err := ioutil.ReadFile("./xx.txt")
if err != nil {
fmt.Println("Error:", err)
}
fmt.Println(string(content))
}
2.19.3、文件写入
os.OpenFile()函数能够以指定模式打开文件,从而实现文件写入相关功能。
func OpenFile(name string, flag int, perm FileMode) (*File, error) {
...
}
其中:
name:要打开的文件名 flag:打开文件的模式。 模式有以下几种:
| 模式 | 含义 |
|---|---|
os.O_WRONLY |
只写 |
os.O_CREATE |
创建文件 |
os.O_RDONLY |
只读 |
os.O_RDWR |
读写 |
os.O_TRUNC |
清空 |
os.O_APPEND |
追加 |
perm:文件权限,一个八进制数。r(读)04,w(写)02,x(执行)01
write
func write() {
file, err := os.OpenFile("writeFile.txt", os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
fmt.Println("Error:", err)
}
defer file.Close()
file.Write([]byte("zhangsan\n"))
file.WriteString("lisi\n")
}
Buffio
func wirteByBuffio() {
file, err := os.OpenFile("writeFile.txt", os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
fmt.Println("Error:", err)
}
defer file.Close()
writer := bufio.NewWriter(file)
writer.WriteString("wirteByBuffio\n") //将数据先写入缓存
writer.Flush() //将缓存中的内容写入文件
}
ioutil
func writeFile() {
str := "hello 沙河"
err := ioutil.WriteFile("writeFile1.txt", []byte(str), 0666)
if err != nil {
fmt.Println("Error:", err)
return
}
}
2.20、反射
Go语言中的变量是分为两部分的:
- 类型信息:预先定义好的元信息。
- 值信息:程序运行过程中可动态变化的。
2.20.1、反射介绍
反射是指在程序运行期间对程序本身进行访问和修改的能力。程序在编译时,变量被转换为内存地址,变量名不会被编译器写入到可执行部分。在运行程序时,程序无法获取自身的信息。
支持反射的语言可以在程序编译期间将变量的反射信息,如字段名称、类型信息、结构体信息等整合到可执行文件中,并给程序提供接口访问反射信息,这样就可以在程序运行期间获取类型的反射信息,并且有能力修改它们。
Go程序在运行期间使用reflect包访问程序的反射信息。
在上一篇博客中我们介绍了空接口。 空接口可以存储任意类型的变量,那我们如何知道这个空接口保存的数据是什么呢? 反射就是在运行时动态的获取一个变量的类型信息和值信息
2.20.2、reflect包
在Go语言的反射机制中,任何接口值都由是一个具体类型和具体类型的值两部分组成的(我们在上一篇接口的博客中有介绍相关概念)。 在Go语言中反射的相关功能由内置的reflect包提供,任意接口值在反射中都可以理解为由reflect.Type和reflect.Value两部分组成,并且reflect包提供了reflect.TypeOf和reflect.ValueOf两个函数来获取任意对象的Value和Type
TypeOf
在Go语言中,使用reflect.TypeOf()函数可以获得任意值的类型对象(reflect.Type),程序通过类型对象可以访问任意值的类型信息。
func reflectType(x interface{}) {
obj := reflect.TypeOf(x)
fmt.Printf("type:%T value:%v\n", obj, obj)
}
type dog struct {
}
type cat struct {
}
func main() {
var a int8 = 1
var b float64 = 3.141592
var c cat
var d dog
reflectType(a) //type:*reflect.rtype value:int8
reflectType(b) //type:*reflect.rtype value:float64
reflectType(c) //type:*reflect.rtype value:main.cat
reflectType(d)//type:*reflect.rtype value:main.dog
}
Type name 、Type kind
在反射中关于类型还划分为两种:类型(Type)和种类(Kind)。因为在Go语言中我们可以使用type关键字构造很多自定义类型,而种类(Kind)就是指底层的类型,但在反射中,当需要区分指针、结构体等大品种的类型时,就会用到种类(Kind)。 举个例子,我们定义了两个指针类型和两个结构体类型,通过反射查看它们的类型和种类
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"os"
"reflect"
)
func readFormFile() {
file, err := os.Open("./xx.txt")
if err != nil {
fmt.Println("Error:", err)
return
}
//使用defer在最后关闭文件
defer file.Close()
//循环读取
tmp := make([]byte, 128)
n, err := file.Read(tmp)
if err != nil {
fmt.Println("Error:", err)
return
}
if err == io.EOF {
fmt.Println("文件读取完了")
return
}
fmt.Printf("读取了%d个字节\n", n)
fmt.Printf("type:%T,value:%v\n", tmp, string(tmp))
}
func readAll() {
file, err := os.Open("./mymain.go")
if err != nil {
fmt.Println("Error:", err)
return
}
//使用defer在最后关闭文件
defer file.Close()
//循环读取
var content []byte
tmp := make([]byte, 128)
for {
n, err := file.Read(tmp)
if err == io.EOF {
fmt.Println("文件读取完了")
break
}
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("读取了%d个字节\n", n)
content = append(content, tmp[:n]...)
}
fmt.Printf("type:%T,value:%v\n", tmp, string(content))
}
func readByBufio() {
file, err := os.Open("./xx.txt")
if err != nil {
fmt.Println("Error:", err)
return
}
//使用defer在最后关闭文件
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err == io.EOF {
if len(line) != 0 {
fmt.Println(line)
}
fmt.Println("文件读取完了")
break
}
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Print(line)
}
}
func readByioutil() {
content, err := ioutil.ReadFile("./xx.txt")
if err != nil {
fmt.Println("Error:", err)
}
fmt.Println(string(content))
}
func write() {
file, err := os.OpenFile("writeFile.txt", os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
fmt.Println("Error:", err)
}
defer file.Close()
file.Write([]byte("zhangsan\n"))
file.WriteString("lisi\n")
}
func wirteByBuffio() {
file, err := os.OpenFile("writeFile.txt", os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
fmt.Println("Error:", err)
}
defer file.Close()
writer := bufio.NewWriter(file)
writer.WriteString("wirteByBuffio\n") //将数据先写入缓存
writer.Flush() //将缓存中的内容写入文件
}
func writeFile() {
str := "hello 沙河"
err := ioutil.WriteFile("writeFile1.txt", []byte(str), 0666)
if err != nil {
fmt.Println("Error:", err)
return
}
}
func reflectType(x interface{}) {
obj := reflect.TypeOf(x)
fmt.Printf("type:%T value:%v valueKind:%v \n", obj, obj.Name(), obj.Kind())
}
type dog struct {
}
type cat struct {
}
func main() {
var a int8 = 1
var b float64 = 3.141592
var c cat
var d dog
var s []string
var i []int
reflectType(a) //type:*reflect.rtype value:int8
reflectType(b) //type:*reflect.rtype value:float64
reflectType(c) //type:*reflect.rtype value:main.cat
reflectType(d) //type:*reflect.rtype value:main.dog
reflectType(s) //type:*reflect.rtype value: valueKind:slice
reflectType(i) //type:*reflect.rtype value: valueKind:slice
}
Go语言的反射中像数组、切片、Map、指针等类型的变量,它们的.Name()都是返回空。
在reflect包中定义的Kind类型如下:
type Kind uint
const (
Invalid Kind = iota // 非法类型
Bool // 布尔型
Int // 有符号整型
Int8 // 有符号8位整型
Int16 // 有符号16位整型
Int32 // 有符号32位整型
Int64 // 有符号64位整型
Uint // 无符号整型
Uint8 // 无符号8位整型
Uint16 // 无符号16位整型
Uint32 // 无符号32位整型
Uint64 // 无符号64位整型
Uintptr // 指针
Float32 // 单精度浮点数
Float64 // 双精度浮点数
Complex64 // 64位复数类型
Complex128 // 128位复数类型
Array // 数组
Chan // 通道
Func // 函数
Interface // 接口
Map // 映射
Ptr // 指针
Slice // 切片
String // 字符串
Struct // 结构体
UnsafePointer // 底层指针
)
valueOf
reflect.ValueOf()返回的是reflect.Value类型,其中包含了原始值的值信息。reflect.Value与原始值之间可以互相转换。
reflect.Value类型提供的获取原始值的方法如下:
| 方法 | 说明 |
|---|---|
| Interface() interface {} | 将值以 interface{} 类型返回,可以通过类型断言转换为指定类型 |
| Int() int64 | 将值以 int 类型返回,所有有符号整型均可以此方式返回 |
| Uint() uint64 | 将值以 uint 类型返回,所有无符号整型均可以此方式返回 |
| Float() float64 | 将值以双精度(float64)类型返回,所有浮点数(float32、float64)均可以此方式返回 |
| Bool() bool | 将值以 bool 类型返回 |
| Bytes() []bytes | 将值以字节数组 []bytes 类型返回 |
| String() string | 将值以字符串类型返回 |
通过反射获取值
func reflectValueOf(x interface{}) {
v := reflect.ValueOf(x)
k := v.Kind()
switch k {
case reflect.Int64:
// v.Int()从反射中获取整型的原始值,然后通过int64()强制类型转换
fmt.Printf("type is int64, value is %d\n", int64(v.Int()))
case reflect.Float32:
// v.Float()从反射中获取浮点型的原始值,然后通过float32()强制类型转换
fmt.Printf("type is float32, value is %f\n", float32(v.Float()))
case reflect.Float64:
// v.Float()从反射中获取浮点型的原始值,然后通过float64()强制类型转换
fmt.Printf("type is float64, value is %f\n", float64(v.Float()))
}
}
func main() {
var a float32 = 3.14
var b int64 = 100
reflectValueOf(a) // type is float32, value is 3.140000
reflectValueOf(b) // type is int64, value is 100
// 将int类型的原始值转换为reflect.Value类型
c := reflect.ValueOf(10)
fmt.Printf("type c :%T\n", c) // type c :reflect.Value
}
通过反射设置变量的值
想要在函数中通过反射修改变量的值,需要注意函数参数传递的是值拷贝,必须传递变量地址才能修改变量值。而反射中使用专有的Elem()方法来获取指针对应的值
func reflectSetvalue(x interface{}) {
v := reflect.ValueOf(x)
//Elem() 是根据指针取值
k := v.Elem().Kind()
switch k {
case reflect.Int64:
v.Elem().SetInt(200)
}
}
func main() {
var a int64 = 100
reflectSetvalue(&a)
fmt.Println(a)
}
isNil()、isValid()
Isnil()
func (v Value) IsNil() bool
IsNil()报告v持有的值是否为nil。v持有的值的分类必须是通道、函数、接口、映射、指针、切片之一;否则IsNil函数会导致panic。
isvalid
func (v Value) IsValid() bool
IsValid()返回v是否持有一个值。如果v是Value零值会返回假,此时v除了IsValid、String、Kind之外的方法都会导致panic。
举例:
IsNil()常被用于判断指针是否为空;IsValid()常被用于判定返回值是否有效。
func main() {
// *int类型空指针
var a *int
fmt.Println("var a *int IsNil:", reflect.ValueOf(a).IsNil())
// nil值
fmt.Println("nil IsValid:", reflect.ValueOf(nil).IsValid())
// 实例化一个匿名结构体
b := struct{}{}
// 尝试从结构体中查找"abc"字段
fmt.Println("不存在的结构体成员:", reflect.ValueOf(b).FieldByName("abc").IsValid())
// 尝试从结构体中查找"abc"方法
fmt.Println("不存在的结构体方法:", reflect.ValueOf(b).MethodByName("abc").IsValid())
// map
c := map[string]int{}
// 尝试从map中查找一个不存在的键
fmt.Println("map中不存在的键:", reflect.ValueOf(c).MapIndex(reflect.ValueOf("娜扎")).IsValid())
}
2.20.3、结构体反射
任意值通过reflect.TypeOf()获得反射对象信息后,如果它的类型是结构体,可以通过反射值对象(reflect.Type)的NumField()和Field()方法获得结构体成员的详细信息。
reflect.Type中与获取结构体成员相关的的方法如下表所示
| 方法 | 说明 |
|---|---|
| Field(i int) StructField | 根据索引,返回索引对应的结构体字段的信息。 |
| NumField() int | 返回结构体成员字段数量。 |
| FieldByName(name string) (StructField, bool) | 根据给定字符串返回字符串对应的结构体字段的信息。 |
| FieldByIndex(index []int) StructField | 多层成员访问时,根据 []int 提供的每个结构体的字段索引,返回字段的信息。 |
| FieldByNameFunc(match func(string) bool) (StructField,bool) | 根据传入的匹配函数匹配需要的字段。 |
| NumMethod() int | 返回该类型的方法集中方法的数目 |
| Method(int) Method | 返回该类型方法集中的第i个方法 |
| MethodByName(string)(Method, bool) | 根据方法名返回该类型方法集中的方法 |
structFiled
StructField类型用来描述结构体中的一个字段的信息。
StructField的定义如下:
type StructField struct {
// Name是字段的名字。PkgPath是非导出字段的包路径,对导出字段该字段为""。
// 参见http://golang.org/ref/spec#Uniqueness_of_identifiers
Name string
PkgPath string
Type Type // 字段的类型
Tag StructTag // 字段的标签
Offset uintptr // 字段在结构体中的字节偏移量
Index []int // 用于Type.FieldByIndex时的索引切片
Anonymous bool // 是否匿名字段
}
结构体反射示例
package main
import (
"fmt"
"reflect"
)
type stu01 struct {
Name string `json:"name" ini:"s_name"`
Score int `json:"score" ini:"s_score"`
}
func main() {
s1 := stu01{
Name: "张三",
Score: 80,
}
t := reflect.TypeOf(s1)
v := reflect.ValueOf(s1)
fmt.Printf("type:%v ,typeKind%v\n", t.Name(), t.Kind())
for i := 0; i < t.NumField(); i++ {
sf := t.Field(i)
fmt.Printf("name:%v value:%v type:%v tag:%v\n", sf.Name, v.Field(i), sf.Type, sf.Tag)
}
fileobj, ok := t.FieldByName("Score")
value := v.FieldByName("Score")
if ok {
fmt.Printf("name:%v value:%v type:%v tag:%v\n", fileobj.Name, value, fileobj.Type, fileobj.Tag)
} else {
fmt.Println("结构体字段不存在")
}
}
反射调用方法和获取方法名
package main
import (
"fmt"
"reflect"
)
type stu01 struct {
Name string `json:"name" ini:"s_name"`
Score int `json:"score" ini:"s_score"`
}
// 给student添加两个方法 Study和Sleep(注意首字母大写)
func (s stu01) Study() string {
msg := "好好学习,天天向上。"
fmt.Println(msg)
return msg
}
func (s stu01) Sleep() string {
msg := "好好睡觉,快快长大。"
fmt.Println(msg)
return msg
}
func printMethod(x interface{}) {
t := reflect.TypeOf(x)
v := reflect.ValueOf(x)
for i := 0; i < t.NumMethod(); i++ {
fmt.Printf("method:%v\n", v.Method(i).Type())
fmt.Printf("name:%v type:%v\n", t.Method(i).Name, t.Method(i).Type)
// 通过反射调用方法传递的参数必须是 []reflect.Value 类型
args := []reflect.Value{}
v.Method(i).Call(args)
}
}
func main() {
s1 := stu01{
Name: "张三",
Score: 80,
}
printMethod(s1)
}
注意:通过反射调用方法传递的参数必须是 []reflect.Value 类型
通过通过方法名调用
package main
import (
"fmt"
"reflect"
)
type stu01 struct {
Name string `json:"name" ini:"s_name"`
Score int `json:"score" ini:"s_score"`
}
// 给student添加两个方法 Study和Sleep(注意首字母大写)
func (s stu01) Study() string {
msg := "好好学习,天天向上。"
fmt.Println(msg)
return msg
}
func (s stu01) Sleep() string {
msg := "好好睡觉,快快长大。"
fmt.Println(msg)
return msg
}
func main() {
s1 := stu01{
Name: "张三",
Score: 80,
}
v := reflect.ValueOf(s1)
args := []reflect.Value{}
v.MethodByName("Study").Call(args)
}
通过valueof的method的call方法调用
2.21、并发
并发编程在当前软件领域是一个非常重要的概念,随着CPU等硬件的发展,我们无一例外的想让我们的程序运行的快一点、再快一点。Go语言在语言层面天生支持并发,充分利用现代CPU的多核优势,这也是Go语言能够大范围流行的一个很重要的原因
2.21.1、基本概念
首先我们先来了解几个与并发编程相关的基本概念。
串行、并发和并行
串行:我们都是先读小学,小学毕业后再读初中,读完初中再读高中。
并发:同一时间段内执行多个任务(你在用微信和两个女朋友聊天)。
并行:同一时刻执行多个任务(你和你朋友都在用微信和女朋友聊天)。
进程、线程和协程
进程(process):程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。
线程(thread):操作系统基于进程开启的轻量级进程,是操作系统调度执行的最小单位。
协程(coroutine):非操作系统提供而是由用户自行创建和控制的用户态‘线程’,比线程更轻量级。
并发模型
业界将如何实现并发编程总结归纳为各式各样的并发模型,常见的并发模型有以下几种:
- 线程&锁模型
- Actor模型
- CSP模型
- Fork&Join模型
Go语言中的并发程序主要是通过基于CSP(communicating sequential processes)的goroutine和channel来实现,当然也支持使用传统的多线程共享内存的并发方式。
2.21.2、goroutine
Goroutine 是 Go 语言支持并发的核心,在一个Go程序中同时创建成百上千个goroutine是非常普遍的,一个goroutine会以一个很小的栈开始其生命周期,一般只需要2KB。区别于操作系统线程由系统内核进行调度, goroutine 是由Go运行时(runtime)负责调度。例如Go运行时会智能地将 m个goroutine 合理地分配给n个操作系统线程,实现类似m:n的调度机制,不再需要Go开发者自行在代码层面维护一个线程池。
Goroutine 是 Go 程序中最基本的并发执行单元。每一个 Go 程序都至少包含一个 goroutine——main goroutine,当 Go 程序启动时它会自动创建。
在Go语言编程中你不需要去自己写进程、线程、协程,你的技能包里只有一个技能——goroutine,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个 goroutine 去执行这个函数就可以了,就是这么简单粗暴。
go关键字
Go语言中使用 goroutine 非常简单,只需要在函数或方法调用前加上go关键字就可以创建一个 goroutine ,从而让该函数或方法在新创建的 goroutine 中执行
go f() // 创建一个新的 goroutine 运行函数f
匿名函数也支持使用go关键字创建 goroutine 去执行。
go func(){
// ...
}()
一个 goroutine 必定对应一个函数/方法,可以创建多个 goroutine 去执行相同的函数/方法
单个goroutine
package main
import "fmt"
func hello() {
fmt.Println("hello 张三")
}
func main() {
go hello()
fmt.Println("hello mail")
}
可能出现多种结果
第一种:main已经执行完了,goroutine还没执行完,只打印main

第二种:第二种都执行完了

那么我们可以采取sync.waitGroup
sync.waitGroup
package main
import (
"fmt"
"sync"
)
//声明全局变量
var wg sync.WaitGroup
func hello() {
fmt.Println("hello 张三")
wg.Done()//表示goroutine执行完
}
func main() {
//登记1个goroutine
wg.Add(1)
go hello()
fmt.Println("hello main")
//等待goroutine执行完
wg.Wait()
}
启用多个goroutine
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func hello(i int) {
fmt.Println("hello", i)
wg.Done()
}
func main() {
wg.Add(10000)
for i := 0; i < 10000; i++ {
go hello(i)
}
fmt.Println("hello main")
wg.Wait()
}
goroutine调用匿名函数
可能存在闭包问题
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func hello(i int) {
fmt.Println("hello", i)
wg.Done()
}
func main() {
wg.Add(10000)
for i := 0; i < 10000; i++ {
go func(i int) { //i要显式传进来,不然会存在闭包问题,主进程for循环已经执行完了(i到10000了),goroutine才开始自行
fmt.Println("hello", i)
wg.Done()
}(i)
}
fmt.Println("hello main")
wg.Wait()
}
GOMAXPROCS
Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个 OS 线程来同时执行 Go 代码。默认值是机器上的 CPU 核心数。例如在一个 8 核心的机器上,GOMAXPROCS 默认为 8。Go语言中可以通过runtime.GOMAXPROCS函数设置当前程序并发时占用的 CPU逻辑核心数。(Go1.5版本之前,默认使用的是单核心执行。Go1.5 版本之后,默认使用全部的CPU 逻辑核心数。)
2.21.3、channel
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的 goroutine 中容易发生竞态问题。为了保证数据交换的正确性,很多并发模型中必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言采用的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说 goroutine 是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个 goroutine 发送特定值到另一个 goroutine 的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
channel的类型
channel是 Go 语言中一种特有的类型。声明通道类型变量的格式如下:
var 变量名称 chan 元素类型
其中:
- chan:是关键字
- 元素类型:是指通道中传递元素的类型
举几个例子:
var ch1 chan int // 声明一个传递整型的通道
var ch2 chan bool // 声明一个传递布尔型的通道
var ch3 chan []int // 声明一个传递int切片的通道
channel的零值
未初始化的通道类型变量其默认零值是nil。
var ch chan int
fmt.Println(ch) // <nil>
channel的初始化
声明的通道类型变量需要使用内置的make函数初始化之后才能使用。具体格式如下:
make(chan 元素类型, [缓冲大小])
其中:
- channel的缓冲大小是可选的。
举几个例子:
ch4 := make(chan int)
ch5 := make(chan bool, 1) // 声明一个缓冲区大小为1的通道
channel的操作
通道共有发送(send)、接收(receive)和关闭(close)三种操作。而发送和接收操作都使用<-符号。
现在我们先使用以下语句定义一个通道:
ch := make(chan int)
发生
将一个值发送到通道中。
ch <- 10 // 把10发送到ch中
接受
从一个通道中接收值。
x := <- ch // 从ch中接收值并赋值给变量x
<-ch // 从ch中接收值,忽略结果
关闭
我们通过调用内置的close函数来关闭通道。
close(ch)
注意:一个通道值是可以被垃圾回收掉的。通道通常由发送方执行关闭操作,并且只有在接收方明确等待通道关闭的信号时才需要执行关闭操作。它和关闭文件不一样,通常在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
关闭后的通道有以下特点:
- 对一个关闭的通道再发送值就会导致 panic。
- 对一个关闭的通道进行接收会一直获取值直到通道为空。
- 对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
- 关闭一个已经关闭的通道会导致 panic。
无缓冲通道
无缓冲的通道又称为阻塞的通道。我们来看一下如下代码片段。
func main() {
ch := make(chan int)
ch <- 10
fmt.Println("发送成功")
}
上面这段代码能够通过编译,但是执行的时候会出现以下错误:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
.../main.go:8 +0x54
deadlock表示我们程序中的 goroutine 都被挂起导致程序死锁了。为什么会出现deadlock错误呢?
因为我们使用ch := make(chan int)创建的是无缓冲的通道,无缓冲的通道只有在有接收方能够接收值的时候才能发送成功,否则会一直处于等待发送的阶段。同理,如果对一个无缓冲通道执行接收操作时,没有任何向通道中发送值的操作那么也会导致接收操作阻塞。就像田径比赛中的4x100接力赛,想要完成交棒必须有一个能够接棒的运动员,否则只能等待。简单来说就是无缓冲的通道必须有至少一个接收方才能发送成功。
上面的代码会阻塞在ch <- 10这一行代码形成死锁,那如何解决这个问题呢?
其中一种可行的方法是创建一个 goroutine 去接收值,例如:
package main
import "fmt"
func recv(ch chan int, i int) {
ch <- i
fmt.Println("发送成功")
}
func main() {
//声明变量
var ch1 chan int
//无缓冲通道,channel是引用类型,需要初始化之后才能使用
ch1 = make(chan int)
//发送
go recv(ch1, 10)
//接受
x := <-ch1
fmt.Println("接受成功")
//关闭
close(ch1)
fmt.Println(x)
}
首先无缓冲通道ch上的发送操作会阻塞,直到另一个 goroutine 在该通道上执行接收操作,这时数字10才能发送成功,两个 goroutine 将继续执行。相反,如果接收操作先执行,接收方所在的 goroutine 将阻塞,直到 main goroutine 中向该通道发送数字10。
使用无缓冲通道进行通信将导致发送和接收的 goroutine 同步化。因此,无缓冲通道也被称为同步通道。
有缓冲通道想
还有另外一种解决上面死锁问题的方法,那就是使用有缓冲区的通道。我们可以在使用 make 函数初始化通道时,可以为其指定通道的容量,例如:
举例子:
package main
import "fmt"
func main() {
//声明变量
var ch1 chan int
//channel是引用类型,需要初始化之后才能使用
//初始化变量为整形的channel,并且设置容量为1
ch1 = make(chan int, 1)
//可以直接一步 ch1 := make(chan int ,1)
//发送
ch1 <- 10
//接受
x := <-ch1
//关闭
close(ch1)
fmt.Println(x)
}
只要通道的容量大于零,那么该通道就属于有缓冲的通道,通道的容量表示通道中最大能存放的元素数量。当通道内已有元素数达到最大容量后,再向通道执行发送操作就会阻塞,除非有从通道执行接收操作。就像你小区的快递柜只有那么个多格子,格子满了就装不下了,就阻塞了,等到别人取走一个快递员就能往里面放一个。
我们可以使用内置的len函数获取通道内元素的数量,使用cap函数获取通道的容量,虽然我们很少会这么做。
多返回值模式
当向通道中发送完数据时,我们可以通过close函数来关闭通道。当一个通道被关闭后,再往该通道发送值会引发panic,从该通道取值的操作会先取完通道中的值。通道内的值被接收完后再对通道执行接收操作得到的值会一直都是对应元素类型的零值。那我们如何判断一个通道是否被关闭了呢?
对一个通道执行接收操作时支持使用如下多返回值模式。
value, ok := <- ch
其中:
- value:从通道中取出的值,如果通道被关闭则返回对应类型的零值。
- ok:通道ch关闭时返回 false,否则返回 true。
package main
import "fmt"
func recv(ch chan int) {
//接受
for {
value, ok := <-ch
if !ok {
fmt.Println("通道关闭")
break
}
fmt.Println(value, ok)
}
}
func main() {
ch1 := make(chan int, 2)
//发送
ch1 <- 10
ch1 <- 20
//关闭
close(ch1)
recv(ch1)
}
for range接受值
通常我们会选择使用for range循环从通道中接收值,当通道被关闭后,会在通道内的所有值被接收完毕后会自动退出循环。上面那个示例我们使用for range改写后会很简洁。
func main() {
ch1 := make(chan int, 2)
//发送
ch1 <- 10
ch1 <- 20
//关闭
close(ch1)
for i := range ch1 {
fmt.Println(i)
}
}
注意:目前Go语言中并没有提供一个不对通道进行读取操作就能判断通道是否被关闭的方法。不能简单的通过len(ch)操作来判断通道是否被关闭。
练习:从ch1通道中取出100个值然后平方存到ch2中
package main
import "fmt"
func f1(c chan int) {
for i := 0; i < 100; i++ {
c <- i
}
close(c)
}
//从c1取出值,平方后存入c2
func f2(c1, c2 chan int) {
for {
value, ok := <-c1
if !ok {
fmt.Println("已经取出所有值")
break
}
c2 <- value * value
}
close(c2)
}
func main() {
ch1 := make(chan int, 100)
ch2 := make(chan int, 100)
//往ch1中存入100个数
f1(ch1)
f2(ch1, ch2)
for i := range ch2 {
fmt.Println(i)
}
}
单向通道
Go语言中提供了单向通道来处理这种需要限制通道只能进行某种操作的情况。
<- chan int // 只接收通道,只能接收不能发送
chan <- int // 只发送通道,只能发送不能接收
其中,箭头<-和关键字chan的相对位置表明了当前通道允许的操作,这种限制将在编译阶段进行检测。另外对一个只接收通道执行close也是不允许的,因为默认通道的关闭操作应该由发送方来完成。
我们将上边的例子也变成,限制只能发送和接收
package main
import "fmt"
func f1(c chan<- int) {
for i := 0; i < 100; i++ {
c <- i
}
close(c)
}
//从c1取出值,平方后存入c2
func f2(c1 <-chan int, c2 chan<- int) {
for {
value, ok := <-c1
if !ok {
fmt.Println("已经取出所有值")
break
}
c2 <- value * value
}
close(c2)
}
func main() {
ch1 := make(chan int, 100)
ch2 := make(chan int, 100)
//往ch1中存入100个数
f1(ch1)
f2(ch1, ch2)
for i := range ch2 {
fmt.Println(i)
}
}
总结
下面的表格中总结了对不同状态下的通道执行相应操作的结果

注意:对已经关闭的通道再执行 close 也会引发 panic。
woker pool(goroutine池)
编码代码实现一个计算机随机数的每个位置之和的程序,要求使用goroutine和channel构建生产者和消费者模式,可以指定启动goroutine数量-wokerpool模式
在工作中我们会经常使用wokerpool模式,控制goroutine的数量,方式goroutine泄露和暴涨
简单的woke pool例子
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func worker(id int, jobs <-chan int, result chan<- int) {
for job := range jobs {
fmt.Printf("woker:%d start job:%d\n", id, job)
result <- job * 2
fmt.Printf("woker:%d stop job:%d\n", id, job)
}
wg.Done()
}
func main() {
jobs := make(chan int, 100)
result := make(chan int, 100)
//开启3个goroutine,三个线程去处理
wg.Add(3)
for j := 0; j < 3; j++ {
go worker(j, jobs, result)
}
for i := 0; i < 5; i++ {
jobs <- i
}
close(jobs)
//输出结果
for i := 0; i < 5; i++ {
ret := <-result
fmt.Println(ret)
}
wg.Wait()
}
select 多路复用
在某些场景下我们可能需要同时从多个通道接收数据。通道在接收数据时,如果没有数据可以被接收那么当前 goroutine 将会发生阻塞。你也许会写出如下代码尝试使用遍历的方式来实现从多个通道中接收值。
for{
// 尝试从ch1接收值
data, ok := <-ch1
// 尝试从ch2接收值
data, ok := <-ch2
…
}
这种方式虽然可以实现从多个通道接收值的需求,但是程序的运行性能会差很多。Go 语言内置了select关键字,使用它可以同时响应多个通道的操作。
Select 的使用方式类似于之前学到的 switch 语句,它也有一系列 case 分支和一个默认的分支。每个 case 分支会对应一个通道的通信(接收或发送)过程。select 会一直等待,直到其中的某个 case 的通信操作完成时,就会执行该 case 分支对应的语句。具体格式如下:
select {
case <-ch1:
//...
case data := <-ch2:
//...
case ch3 <- 10:
//...
default:
//默认操作
}
Select 语句具有以下特点。
- 可处理一个或多个 channel 的发送/接收操作。
- 如果多个 case 同时满足,select 会随机选择一个执行。
- 对于没有 case 的 select 会一直阻塞,可用于阻塞 main 函数,防止退出。
下面的示例代码能够在终端打印出10以内的奇数,我们借助这个代码片段来看一下 select 的具体使用
package main
import "fmt"
func main() {
ch1 := make(chan int, 1)
for i := 1; i <= 10; i++ {
select {
case x := <-ch1: //当x可以从ch1中接受值时,打印出x
fmt.Println(x)
case ch1 <- i: //因为ch1容量为1,所以当ch1没满时能写入
default:
fmt.Println("默认选项")
}
}
}
示例中的代码首先是创建了一个缓冲区大小为1的通道 ch,进入 for 循环后:
- 第一次循环时 i = 1,select 语句中包含两个 case 分支,此时由于通道中没有值可以接收,所以
x := <-ch这个 case 分支不满足,而ch <- i这个分支可以执行,会把1发送到通道中,结束本次 for 循环; - 第二次 for 循环时,i = 2,由于通道缓冲区已满,所以
ch <- i这个分支不满足,而x := <-ch这个分支可以执行,从通道接收值1并赋值给变量 x ,所以会在终端打印出 1; - 后续的 for 循环以此类推会依次打印出3、5、7、9。
2.21.4、并发安全和锁
有时候我们的代码中可能会存在多个 goroutine 同时操作一个资源(临界区)的情况,这种情况下就会发生竞态问题(数据竞态)。这就好比现实生活中十字路口被各个方向的汽车竞争,还有火车上的卫生间被车厢里的人竞争。
我们用下面的代码演示一个数据竞争的示例
package main
import (
"fmt"
"sync"
)
var x int
var wg sync.WaitGroup
func add() {
for i := 0; i < 5000; i++ {
x += 1
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}
在上面的示例代码片中,我们开启了两个 goroutine 分别执行 add 函数,这两个 goroutine 在访问和修改全局的x变量时就会存在数据竞争,某个 goroutine 中对全局变量x的修改可能会覆盖掉另一个 goroutine 中的操作,所以导致最后的结果与预期不符。
互斥锁
斥锁是一种常用的控制共享资源访问的方法,它能够保证同一时间只有一个 goroutine 可以访问共享资源。Go 语言中使用sync包中提供的Mutex类型来实现互斥锁。
sync.Mutex提供了两个方法供我们使用。
| 方法名 | 功能 |
|---|---|
| func (m *Mutex) Lock() | 获取互斥锁 |
| func (m *Mutex) Unlock() | 释放互斥锁 |
我们在下面的示例代码中使用互斥锁限制每次只有一个 goroutine 才能修改全局变量x,从而修复上面代码中的问题
package main
import (
"fmt"
"sync"
)
var x int64
var wg sync.WaitGroup
var m sync.Mutex
func add() {
for i := 0; i < 5000; i++ {
m.Lock()
x = x + 1
m.Unlock()
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}
读写互斥锁
互斥锁是完全互斥的,但是实际上有很多场景是读多写少的,当我们并发的去读取一个资源而不涉及资源修改的时候是没有必要加互斥锁的,这种场景下使用读写锁是更好的一种选择。读写锁在 Go 语言中使用sync包中的RWMutex类型。
sync.RWMutex提供了以下5个方法。
| 方法名 | 功能 |
|---|---|
| func (rw *RWMutex) Lock() | 获取写锁 |
| func (rw *RWMutex) Unlock() | 释放写锁 |
| func (rw *RWMutex) RLock() | 获取读锁 |
| func (rw *RWMutex) RUnlock() | 释放读锁 |
| func (rw *RWMutex) RLocker() Locker | 返回一个实现Locker接口的读写锁 |
读写锁分为两种:读锁和写锁。当一个 goroutine 获取到读锁之后,其他的 goroutine 如果是获取读锁会继续获得锁,如果是获取写锁就会等待;而当一个 goroutine 获取写锁之后,其他的 goroutine 无论是获取读锁还是写锁都会等待。
下面我们使用代码构造一个读多写少的场景,然后分别使用互斥锁和读写锁查看它们的性能差异。
package main
import (
"fmt"
"sync"
"time"
)
var x int64
var wg sync.WaitGroup
var mutex sync.Mutex
var rwmutex sync.RWMutex
//读文件时采用读写锁
func readWithRWLock() {
rwmutex.RLock()
x = x + 1
time.Sleep(time.Millisecond) // 假设读操作耗时1毫秒
rwmutex.RUnlock()
wg.Done()
}
//写文件时采用读写锁
func writeWithRWLock() {
rwmutex.RLock()
x = x + 1
time.Sleep(10 * time.Millisecond) // 假设写操作耗时10毫秒
rwmutex.RUnlock()
wg.Done()
}
//readWithLock 使用互斥锁的读操作
func readWithLock() {
mutex.Lock()
x = x + 1
time.Sleep(time.Millisecond) // 假设读操作耗时1毫秒
mutex.Unlock()
wg.Done()
}
// writeWithLock 使用互斥锁的写操作
func writeWithLock() {
mutex.Lock()
x = x + 1
time.Sleep(10 * time.Millisecond) // 假设写操作耗时10毫秒
mutex.Unlock()
wg.Done()
}
func do(wf, rf func(), wc, rc int) {
start := time.Now()
// wc个并发写操作
for i := 0; i < wc; i++ {
wg.Add(1)
go wf()
}
// rc个并发读操作
for i := 0; i < rc; i++ {
wg.Add(1)
go rf()
}
wg.Wait()
cost := time.Since(start)
fmt.Printf("x:%v cost:%v\n", x, cost)
}
func main() {
//使用互斥锁,10并发写,1000并发读
do(writeWithLock, readWithLock, 10, 1000)
//使用读写锁,10并发写,1000并发读
do(writeWithRWLock, readWithRWLock, 10, 1000)
}
从最终的执行结果可以看出,使用读写互斥锁在读多写少的场景下能够极大地提高程序的性能。不过需要注意的是如果一个程序中的读操作和写操作数量级差别不大,那么读写互斥锁的优势就发挥不出来
Sync.waitGroup
Go语言中可以使用sync.WaitGroup来实现并发任务的同步。 sync.WaitGroup有以下几个方法:
| 方法名 | 功能 |
|---|---|
| func (wg * WaitGroup) Add(delta int) | 计数器+delta |
| (wg *WaitGroup) Done() | 计数器-1 |
| (wg *WaitGroup) Wait() | 阻塞直到计数器变为0 |
sync.WaitGroup内部维护着一个计数器,计数器的值可以增加和减少。例如当我们启动了 N 个并发任务时,就将计数器值增加N。每个任务完成时通过调用 Done 方法将计数器减1。通过调用 Wait 来等待并发任务执行完,当计数器值为 0 时,表示所有并发任务已经完成
需要注意sync.WaitGroup是一个结构体,进行参数传递的时候要传递指针
Sync.Once
某些场景下我们需要确保某些操作即使在高并发的场景下也只会被执行一次,例如只加载一次配置文件等。
Go语言中的sync包中提供了一个针对只执行一次场景的解决方案——sync.Once,sync.Once只有一个Do方法,其签名如下:
func (o *Once) Do(f func())
注意:如果要执行的函数f需要传递参数就需要搭配闭包来使用
加载配置文件实例
延迟一个开销很大的初始化操作到真正用到它的时候再执行是一个很好的实践。因为预先初始化一个变量(比如在init函数中完成初始化)会增加程序的启动耗时,而且有可能实际执行过程中这个变量没有用上,那么这个初始化操作就不是必须要做的。我们来看一个例子:
var icons map[string]image.Image
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon 被多个goroutine调用时不是并发安全的
func Icon(name string) image.Image {
if icons == nil {
loadIcons()
}
return icons[name]
}
多个 goroutine 并发调用Icon函数时不是并发安全的,现代的编译器和CPU可能会在保证每个 goroutine 都满足串行一致的基础上自由地重排访问内存的顺序。loadIcons函数可能会被重排为以下结果:
func loadIcons() {
icons = make(map[string]image.Image)
icons["left"] = loadIcon("left.png")
icons["up"] = loadIcon("up.png")
icons["right"] = loadIcon("right.png")
icons["down"] = loadIcon("down.png")
}
在这种情况下就会出现即使判断了icons不是nil也不意味着变量初始化完成了。考虑到这种情况,我们能想到的办法就是添加互斥锁,保证初始化icons的时候不会被其他的 goroutine 操作,但是这样做又会引发性能问题。
使用sync.Once改造的示例代码如下:
var icons map[string]image.Image
var loadIconsOnce sync.Once
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon 是并发安全的
func Icon(name string) image.Image {
loadIconsOnce.Do(loadIcons)
return icons[name]
}
sync.map
Go 语言中内置的 map 不是并发安全的,请看下面这段示例代码。
package main
import (
"fmt"
"sync"
)
var m = make(map[int]int)
var wg = sync.WaitGroup{}
func get(key int) int {
return m[key]
}
func set(key, value int) {
m[key] = value
}
func main() {
for i := 0; i < 30; i++ {
wg.Add(1)
go func(i int) {
set(i, i+100)
fmt.Printf("key:%v value:%v\n", i, get(i))
wg.Done()
}(i)
}
wg.Wait()
}
运行会报错

可以加锁或者使用sync.map
像这种场景下就需要为 map 加锁来保证并发的安全性了,Go语言的sync包中提供了一个开箱即用的并发安全版 map——sync.Map。开箱即用表示其不用像内置的 map 一样使用 make 函数初始化就能直接使用。同时sync.Map内置了诸如Store、Load、LoadOrStore、Delete、Range等操作方法。
| 方法名 | 功能 |
|---|---|
| func (m *Map) Store(key, value interface{}) | 存储key-value数据 |
| func (m *Map) Load(key interface{}) (value interface{}, ok bool) | 查询key对应的value |
| func (m *Map) LoadOrStore(key, value interface{}) (actual interface{}, loaded bool) | 查询或存储key对应的value |
| func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) | 查询并删除key |
| func (m *Map) Delete(key interface{}) | 删除key |
| func (m *Map) Range(f func(key, value interface{}) bool) | 对map中的每个key-value依次调用f |
下面例子使用了map
package main
import (
"fmt"
"sync"
)
var m2 = sync.Map{}
var wg = sync.WaitGroup{}
func main() {
for i := 0; i < 30; i++ {
wg.Add(1)
go func(i int) {
m2.Store(i, i+100)
v, _ := m2.Load(i)
fmt.Printf("key:%v value:%v\n", i, v)
wg.Done()
}(i)
}
wg.Wait()
}
2.21.5、原子操作
针对整数数据类型(int32、uint32、int64、uint64)我们还可以使用原子操作来保证并发安全,通常直接使用原子操作比使用锁操作效率更高。Go语言中原子操作由内置的标准库sync/atomic提供。
atomic包
| 方法 | 解释 |
|---|---|
| func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64) func LoadUint32(addr *uint32) (val uint32) func LoadUint64(addr *uint64) (val uint64) func LoadUintptr(addr *uintptr) (val uintptr) func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) |
读取操作 |
| func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintptr, val uintptr) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) |
写入操作 |
| func AddInt32(addr *int32, delta int32) (new int32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) |
修改操作 |
| func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) |
交换操作 |
| func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) |
比较并交换操作 |
2.22、Go语言标准库flag基本使用
Go语言内置的flag包实现了命令行参数的解析,flag包使得开发命令行工具更为简单
2.22.1、os.Args
如果你只是简单的想要获取命令行参数,可以像下面的代码示例一样使用os.Args来获取命令行参数
package main
import (
"fmt"
"os"
)
func main() {
if len(os.Args) > 0 {
for index, value := range os.Args {
fmt.Printf("args[%d]=%v\n", index, value)
}
}
}
os.Args是一个存储命令行参数的字符串切片,它的第一个元素是执行文件的名
flag包支持的命令行参数类型有bool、int、int64、uint、uint64、float float64、string、duration。
| flag参数 | 有效值 |
|---|---|
| 字符串flag | 合法字符串 |
| 整数flag | 1234、0664、0x1234等类型,也可以是负数。 |
| 浮点数flag | 合法浮点数 |
| bool类型flag | 1, 0, t, f, T, F, true, false, TRUE, FALSE, True, False。 |
| 时间段flag | 任何合法的时间段字符串。如”300ms”、”-1.5h”、”2h45m”。 合法的单位有”ns”、”us” /“µs”、”ms”、”s”、”m”、”h”。 |
2.22.2、定义命令行参数
有以下两种常用的定义命令行flag参数的方法。
第一种 flag.Type()
基本格式如下:
flag.Type(flag名, 默认值, 帮助信息)*Type 例如我们要定义姓名、年龄、婚否三个命令行参数,我们可以按如下方式定义
name := flag.String("name", "张三", "姓名")
age := flag.Int("age", 18, "年龄")
married := flag.Bool("married", false, "婚否")
delay := flag.Duration("d", 0, "时间间隔")
需要注意的是,此时name、age、married、delay均为对应类型的指针
第二种 flag.TypeVar()
基本格式如下: flag.TypeVar(Type指针, flag名, 默认值, 帮助信息) 例如我们要定义姓名、年龄、婚否三个命令行参数,我们可以按如下方式定义:
var name string
var age int
var married bool
var delay time.Duration
flag.StringVar(&name, "name", "张三", "姓名")
flag.IntVar(&age, "age", 18, "年龄")
flag.BoolVar(&married, "married", false, "婚否")
flag.DurationVar(&delay, "d", 0, "时间间隔")
2.22.3、flag.Parse()
通过以上两种方法定义好命令行flag参数后,需要通过调用flag.Parse()来对命令行参数进行解析。
支持的命令行参数格式有以下几种:
-flag xxx(使用空格,一个-符号)--flag xxx(使用空格,两个-符号)-flag=xxx(使用等号,一个-符号)--flag=xxx(使用等号,两个-符号)
其中,布尔类型的参数必须使用等号的方式指定。
Flag解析在第一个非flag参数(单个”-“不是flag参数)之前停止,或者在终止符”–“之后停止。
2.22.4、flag其他函数
flag.Args() ////返回命令行参数后的其他参数,以[]string类型
flag.NArg() //返回命令行参数后的其他参数个数
flag.NFlag() //返回使用的命令行参数个数
2.22.5、案例
package main
import (
"flag"
"fmt"
)
func main() {
//第一种方式定义参数
host := flag.String("host", "192.168.1.1", "ip地址")
port := flag.Int("port", 80, "端口")
//第二种参数定义参数
var exp string
flag.StringVar(&exp, "exp", "none", "输入利用的exp模块")
//参数解析
flag.Parse()
fmt.Println(*host, *port, exp)
//返回命令行参数后的其他参数
fmt.Println(flag.Args())
//返回命令行参数后的其他参数个数
fmt.Println(flag.NArg())
//返回使用的命令行参数个数
fmt.Println(flag.NFlag())
}
使用
./mymain -h

./mymain -host 172.16.2.2 -port 8080 -exp tongda

./mymain -host 172.16.1.1 a b c

2.23、go语言的net/http库
Go语言内置的net/http包十分的优秀,提供了HTTP客户端和服务端的实现
2.23.1、net\http介绍
Go语言内置的net/http包提供了HTTP客户端和服务端的实现。
Http协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
Get、Head、Post和PostForm函数发出HTTP/HTTPS请求
2.23.2、get函数例子
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
resp, err := http.Get("http://www.baidu.com")
if err != nil {
fmt.Println("Error:", err)
return
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(string(body))
fmt.Println("--------------")
fmt.Println((resp.StatusCode))
fmt.Println(resp.Header)
}
get带参数
关于GET请求的参数需要使用Go语言内置的net/url这个标准库来处理
package main
import (
"fmt"
"io/ioutil"
"net/http"
"net/url"
)
func main() {
apiUrl := "http://192.168.1.1:8080/get"
data := url.Values{}
data.Set("cmd", "ipconfig")
//u, err := url.ParseRequestURI(apiUrl)
u, err := url.Parse(apiUrl)
if err != nil {
fmt.Println("Error:", err)
return
}
u.RawQuery = data.Encode()
fmt.Println(u.String())
resp, err := http.Get(u.String())
if err != nil {
fmt.Println("Error:", err)
return
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(string(body))
}
2.23.3、普通的Post
package main
import (
"fmt"
"io/ioutil"
"net/http"
"strings"
)
func main() {
apiUrl := "http://192.168.1.1:8080/post"
contentType := "application/json"
data := `{"name":"zhangsan","age":"18"}`
resp, err := http.Post(apiUrl, contentType, strings.NewReader(data))
if err != nil {
fmt.Println("Error:", err)
return
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(string(body))
}
2.23.4、自定义client
要管理HTTP客户端的头域、重定向策略和其他设置,创建一个Client:
client := &http.Client{
CheckRedirect: redirectPolicyFunc,
}
resp, err := client.Get("http://example.com")
// ...
req, err := http.NewRequest("GET", "http://example.com", nil)
// ...
req.Header.Add("If-None-Match", `W/"wyzzy"`)
resp, err := client.Do(req)
2.23.5、自定义transport
tr := &http.Transport{
TLSClientConfig: &tls.Config{RootCAs: pool},
DisableCompression: true,
}
client := &http.Client{Transport: tr}
resp, err := client.Get("https://example.com")
Client和Transport类型都可以安全的被多个goroutine同时使用。出于效率考虑,应该一次建立、尽量重用。
2.23.6、client结合transpo例子
package main
import (
"fmt"
"io/ioutil"
"log"
"net/http"
"net/url"
"strings"
"time"
)
func main() {
proxyAddr := "http://127.0.0.1:8080"
httpUrl := "http://baidu.com"
poststr := "name=张三"
proxy, err := url.Parse(proxyAddr)
if err != nil {
log.Fatal(err)
}
netTransport := &http.Transport{
Proxy: http.ProxyURL(proxy),
MaxIdleConnsPerHost: 10,
ResponseHeaderTimeout: time.Second * time.Duration(5),
}
client := &http.Client{
Timeout: time.Second * 10,
Transport: netTransport,
}
req, _ := http.NewRequest("POST", httpUrl, strings.NewReader(poststr))
/*req.AddCookie(&http.Cookie{
Name: "ds",
Value: "req.AddCookie",
Path: "/",
Domain: "localhost",
})*/
req.Header.Add("Cookie", "ds=HeaderCookie")
resp, err := client.Do(req)
defer resp.Body.Close()
if err != nil {
fmt.Println("Error:", err)
return
}
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(string(body))
}

2.23.7、服务端
ListenAndServe使用指定的监听地址和处理器启动一个HTTP服务端。处理器参数通常是nil,这表示采用包变量DefaultServeMux作为处理器。
Handle和HandleFunc函数可以向DefaultServeMux添加处理器。
基本示例
package main
import (
"fmt"
"html"
"net/http"
)
// http server
func sayHello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello 沙河!")
}
func fooHandler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello foo!")
}
func main() {
http.HandleFunc("/", sayHello)
http.HandleFunc("/foo1", fooHandler)
http.HandleFunc("/bar", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, %q", html.EscapeString(r.URL.Path))
})
err := http.ListenAndServe(":9091", nil)
if err != nil {
fmt.Printf("http server failed, err:%v\n", err)
return
}
}
2.24、socket编程
Socket是BSD UNIX的进程通信机制,通常也称作”套接字”,用于描述IP地址和端口,是一个通信链的句柄。Socket可以理解为TCP/IP网络的API,它定义了许多函数或例程,程序员可以用它们来开发TCP/IP网络上的应用程序。电脑上运行的应用程序通常通过”套接字”向网络发出请求或者应答网络请求
2.24.1、go语言实现TCP通信
TCP协议
TCP/IP(Transmission Control Protocol/Internet Protocol) 即传输控制协议/网间协议,是一种面向连接(连接导向)的、可靠的、基于字节流的传输层(Transport layer)通信协议,因为是面向连接的协议,数据像水流一样传输,会存在黏包问题。
TCP服务端
一个TCP服务端可以同时连接很多个客户端,例如世界各地的用户使用自己电脑上的浏览器访问淘宝网。因为Go语言中创建多个goroutine实现并发非常方便和高效,所以我们可以每建立一次链接就创建一个goroutine去处理。
TCP服务端程序的处理流程:
- 监听端口
- 接收客户端请求建立链接
- 创建goroutine处理链接。
我们使用Go语言的net包实现的TCP服务端代码如下:
package main
import (
"bufio"
"fmt"
"net"
)
func process(conn net.Conn) {
defer conn.Close()
//针对当前的链接,循环做发送数据和接受的操作
for {
//声明一个大小128的数组
var buf [128]byte
reader := bufio.NewReader(conn) //这里需要传输的是io.reader接口,该接口只有一个read方法,conn接口实现了read方法
//从输入流读取,然后存放到buf
n, err := reader.Read(buf[:]) //从数组中获取切片
if err != nil {
fmt.Println("read fail,Error:", err)
break //读完后跳出循环,结束当前用户的读操作
}
//打印接受的字符串
recv := string(buf[:n])
fmt.Printf("接受到的数据%v\n", recv)
conn.Write([]byte("ok"))
}
}
func main() {
//1.监听一个端口
listen, err := net.Listen("tcp", "127.0.0.1:20000")
if err != nil {
fmt.Println("listen fail,Error:", err)
return
}
//2.等待客户来连接
for {
conn, err := listen.Accept()
if err != nil {
fmt.Println("conn fail,Error:", err)
continue
}
//3.用一个goroutine去处理这个客户连接
go process(conn)
}
}
TCP客户端
一个TCP客户端进行TCP通信的流程如下:
- 建立与服务端的链接
- 进行数据收发
- 关闭链接
package main
import (
"bufio"
"fmt"
"net"
"os"
"strings"
)
func main() {
//1.和服务器建立连接
conn, err := net.Dial("tcp", "127.0.0.1:20000")
if err != nil {
fmt.Println("conn failed Error:", err)
return
}
defer conn.Close()
//2.循环发送和接受服务端的信息
for {
//从键盘获取输入
fmt.Print("请输入:")
reader := bufio.NewReader(os.Stdin)
//通过回车获取获取输入
inputStr, _ := reader.ReadString('\n')
//去除两边空白字符
input := strings.TrimSpace(inputStr)
if strings.ToUpper(input) == "Q" {
fmt.Println("断开连接")
return
}
//发送数据
_, err := conn.Write([]byte(input))
if err != nil {
fmt.Println("send failed Error:", err)
continue
}
//接受数据
var buf [1024]byte
n, err := conn.Read(buf[:])
if err != nil {
fmt.Println("read failed Error:", err)
}
fmt.Println("accept from server:", string(buf[:n]))
}
}

Tcp黏包
服务端代码如下:
// socket_stick/server/main.go
func process(conn net.Conn) {
defer conn.Close()
reader := bufio.NewReader(conn)
var buf [1024]byte
for {
n, err := reader.Read(buf[:])
if err == io.EOF {
break
}
if err != nil {
fmt.Println("read from client failed, err:", err)
break
}
recvStr := string(buf[:n])
fmt.Println("收到client发来的数据:", recvStr)
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
defer listen.Close()
for {
conn, err := listen.Accept()
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process(conn)
}
}
客户端代码如下:
// socket_stick/client/main.go
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("dial failed, err", err)
return
}
defer conn.Close()
for i := 0; i < 20; i++ {
msg := `Hello, Hello. How are you?`
conn.Write([]byte(msg))
}
}
将上面的代码保存后,分别编译。先启动服务端再启动客户端,可以看到服务端输出结果如下:
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?
客户端分10次发送的数据,在服务端并没有成功的输出10次,而是多条数据“粘”到了一起。
为什么会出现粘包
主要原因就是tcp数据传递模式是流模式,在保持长连接的时候可以进行多次的收和发。
“粘包”可发生在发送端也可发生在接收端:
- 由Nagle算法造成的发送端的粘包:Nagle算法是一种改善网络传输效率的算法。简单来说就是当我们提交一段数据给TCP发送时,TCP并不立刻发送此段数据,而是等待一小段时间看看在等待期间是否还有要发送的数据,若有则会一次把这两段数据发送出去。
- 接收端接收不及时造成的接收端粘包:TCP会把接收到的数据存在自己的缓冲区中,然后通知应用层取数据。当应用层由于某些原因不能及时的把TCP的数据取出来,就会造成TCP缓冲区中存放了几段数据。
解决办法
出现”粘包”的关键在于接收方不确定将要传输的数据包的大小,因此我们可以对数据包进行封包和拆包的操作。
封包:封包就是给一段数据加上包头,这样一来数据包就分为包头和包体两部分内容了(过滤非法包时封包会加入”包尾”内容)。包头部分的长度是固定的,并且它存储了包体的长度,根据包头长度固定以及包头中含有包体长度的变量就能正确的拆分出一个完整的数据包。
我们可以自己定义一个协议,比如数据包的前4个字节为包头,里面存储的是发送的数据的长度。
package proto
import (
"bufio"
"bytes"
"encoding/binary"
)
// Encode 将消息编码
func Encode(message string) ([]byte, error) {
var length = int32(len(message)) // 读取消息的长度,转换成int32类型(占4个字节)
var pkg = new(bytes.Buffer) // 定义一个空的bytes 缓冲区
// 写入消息头
err := binary.Write(pkg, binary.LittleEndian, length) //通过小端序列的方式把length 写到pkg。binary.LittleEndian 为编码格式
if err != nil {
return nil, err
}
// 写入消息实体
err = binary.Write(pkg, binary.LittleEndian, []byte(message)) //在通过小端序列的方式把真实的包内容写入bytes,封装成一个包。
if err != nil {
return nil, err
}
return pkg.Bytes(), nil // 返回封装好的包
}
// Decode 解码消息
func Decode(reader *bufio.Reader) (string, error) {
lengthByte, _ := reader.Peek(4) // 读取前4个字节的数据,及包的内容长度,endoce 里面的length。Peek的方式读取内容,是不会清掉缓存的
lengthBuff := bytes.NewBuffer(lengthByte) //定义一个以lengthByte为内容的bytes缓冲区
var length int32
err := binary.Read(lengthBuff, binary.LittleEndian, &length) // 将lengthBuff 的内容写到length里面。这里要相应解码才能读取到length的内容
if err != nil {
return "", err
}
// Buffered返回缓冲中现有的可读取的字节数。前面用Peek读取,所以这里数据内容应该大于length+4
if int32(reader.Buffered()) < length+4 {
return "", err
}
// 读取真正的消息数据
pack := make([]byte, int(4+length)) // 创建字节切片
_, err = reader.Read(pack)
if err != nil {
return "", err
}
return string(pack[4:]), nil //返回去掉length的字符串
}
接下来在服务端和客户端分别使用上面定义的proto包的Decode和Encode函数处理数据。
服务端代码如下:
// socket_stick/server2/main.go
func process(conn net.Conn) {
defer conn.Close()
reader := bufio.NewReader(conn)
for {
msg, err := proto.Decode(reader)
if err == io.EOF {
return
}
if err != nil {
fmt.Println("decode msg failed, err:", err)
return
}
fmt.Println("收到client发来的数据:", msg)
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
defer listen.Close()
for {
conn, err := listen.Accept()
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process(conn)
}
}
客户端代码如下:
// socket_stick/client2/main.go
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("dial failed, err", err)
return
}
defer conn.Close()
for i := 0; i < 20; i++ {
msg := `Hello, Hello. How are you?`
data, err := proto.Encode(msg)
if err != nil {
fmt.Println("encode msg failed, err:", err)
return
}
conn.Write(data)
}
}
UDP服务端
package main
import (
"fmt"
"net"
)
func main() {
//1.监听端口并且建立链接
conn, err := net.ListenUDP("udp", &net.UDPAddr{
IP: net.IPv4(127, 0, 0, 1),
Port: 30000,
})
if err != nil {
fmt.Println("upd conn failed Error:", err)
return
}
defer conn.Close()
//2.循环发送和接受消息
for true {
//接受消息
var buf [1024]byte
n, addr, err := conn.ReadFromUDP(buf[:])
if err != nil {
fmt.Println("read failed Error:", err)
}
fmt.Printf("server accept from:%v,value:%v\n", addr,string(buf[:n]))
//发送消息
_, err = conn.WriteToUDP([]byte("ok"), addr)
if err != nil {
fmt.Println("write failed Error:", err)
return
}
}
}
UDP客户端
package main
import (
"bufio"
"fmt"
"net"
"os"
"strings"
)
func main() {
//1.建立udp连接
conn, err := net.DialUDP("udp", nil, &net.UDPAddr{
IP: net.IPv4(127, 0, 0, 1),
Port: 30000,
})
if err != nil {
fmt.Println("dail failed Error:", err)
return
}
defer conn.Close()
//2.循环发送消息和接受消息
reader := bufio.NewReader(os.Stdin)
for true {
fmt.Print("请输入:")
inputStr, err := reader.ReadString('\n')
inputStr = strings.TrimSpace(inputStr)
input := strings.TrimSpace(inputStr)
if strings.ToUpper(input) == "Q" {
fmt.Println("断开连接")
return
}
if err != nil {
fmt.Println("read failed Error:", err)
return
}
//发送数据
_, err = conn.Write([]byte(input))
if err != nil {
fmt.Println("write failed Error:", err)
return
}
var buf [1024]byte
//接受数据
n, addr, err := conn.ReadFromUDP(buf[:])
if err != nil {
fmt.Println("read failed Error:", err)
}
fmt.Printf("read from %v ,msg:%v\n", addr, string(buf[:n]))
}
}
参考链接:
https://www.liwenzhou.com/posts/Go/golang-menu/
标签:err,fmt,编程,笔记,Println,func,go,main From: https://www.cnblogs.com/akka1/p/17094195.html