很多兄弟在聊天上没有下太多的功夫,导致自己聊天的时候很容易尬住,然后就不知道聊啥了,这时候合适表情包分分钟就能救场,但是一看自己收藏的表情包,好家伙,两只手都数得过来。
所以今天来给兄弟们分享一下爬取表情包的代码,再也不用尬聊了!
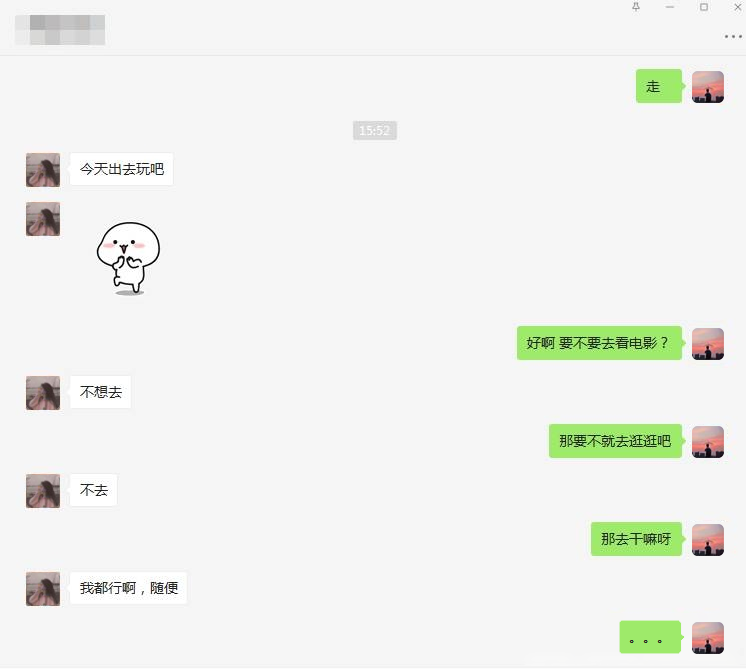
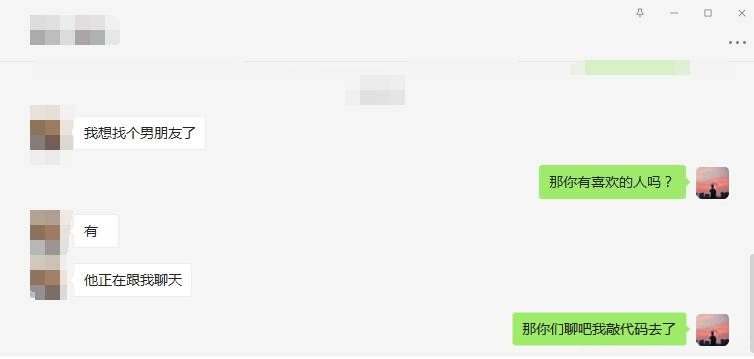
给大家看看我朋友的尬聊场面
本次目标
网站:发表情
网不好 ,没加载出来,表弟又在当老六,看不该看的抢我网速!!!

使用的工具
环境:Python3.8、pycharm
需要安装的第三方模块:lxml 、requests
页面分析
- 静态还是动态 get
- 翻页规律
- 在img标签下 获取属性
src属性 data 下载链接
获取title属性值 图片的名字xpath
代码实战
# 导入模块
import requests # 请求模块
from lxml import etree # 解析模块
import urllib.request # 内置模块
import re # 正则
# 文章不理解,我也录制了相应的视频讲解
# 直接在这个君羊:708525271领取就好了,包括完整代码
num = 0
for i in range(1,11):
url = f'https://**网址屏蔽了,不然过不了/biaoqing/lists/page/{i}.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
} # 模拟用户 爬取数据
response = requests.get(url,headers=headers)
data = response.text
# print(data) # 输出
# 创建对象 html-->xml
html = etree.HTML(data)
# 找到所有img标签 //在任意节点去匹配 不需要考虑位置 //img[@class="ui image lazy"]
img_tag = html.xpath('//img[@class="ui image lazy"]')
# print(len(img_tag)) # 一个页面有45个表情包
for img in img_tag:
# print()
# 下载链接
src = img.xpath('@data-original')[0]
# print(src)
# 名字 当前的img下面找当前节点 title属性'@title'
name = img.xpath('@title')[0]
# print(name)
title = re.sub('[\ / : * ? " < > |]',"", name) # 替换
urllib.request.urlretrieve(src,f'img/{title}{num}.jpg') # 保存
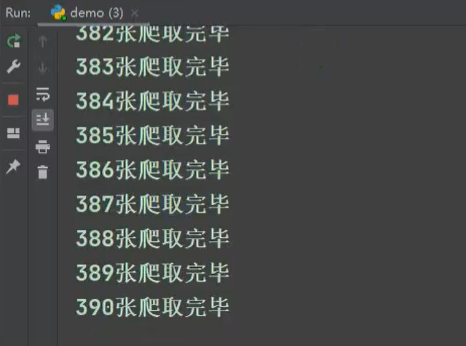
print(f'{num}张爬取完毕')
num+=1 # 等价于num=num+1
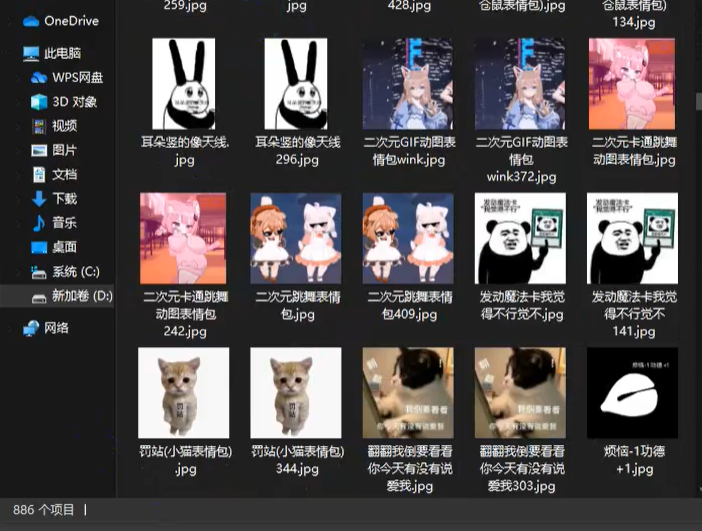
采集结果
最后
表情包在手,你就是斗图之王,没什么事情是一个表情包不能解决的,如果有,那就多发一些!
赶紧去试试吧,记得给小编一个三连吧!么么哒!
标签:img,title,Python,教你用,num,print,斗图,data,表情 From: https://www.cnblogs.com/hahaa/p/17025017.html