——《Java多线程编程实战指南》学习及其他参考博客总结
串行、并行、并发
(1)串行:顺序执行多个任务,一个时刻只有一个任务在执行
(2)并行:多个CPU(核)同一时间多个任务,一个时刻有多个任务在执行
(3)并发:单个CPU(核)同一时间间隔内交替执行多个任务,一个时刻只有一个任务在执行
Java多线程采用线程调度算法,频繁的进行线程切换,使得多个任务交替占用单个或多个CPU(核)时间片来执行——(并行与并发)
进程与线程
进程是资源分配的最小单位,线程是CPU调度的最小单位;
一个线程则相当于进程中的执行流程,一个进程中可以包括多个线程;
Java中任何一段代码都执行在某个确定的线程中,而Java中的所有线程在JVM进程中,启动一个线程的实质是请求JVM运行相应的线程,而这个线程具体何时能够运行是由线程调度器(英文为“Scheduler”,是操作系统的一个部分)决定的,因此,start方法调用结束并不意味着相应线程已经开始运行,这个线程可能稍后才会被运行,甚至也可能永远不被运行,不过,一旦线程的run方法执行结束,相应的线程的运行也就结束了
Java中同一线程不能被重复调用

Java线程属性
线程的属性包括线程的编号(ID)、名称( Name)、线程类别( Daemon)和优先级( Priority )。
线程类别( Daemon)为boolean类型,值为true表示相应的线程为守护线程,值为false则表示线程为用户线程,如果不设置则默认为用户线程。
守护线程是一种特殊线程,在后台默默的完成一些系统性的服务,如垃圾回收线程(GC)、动态编译线程(JIT);用户线程是处理业务的普通线程,完成程序业务逻辑操作,如主线程(main)以及手动创建的线程(默认为用户线程)。当程序中所有的用户线程执行完毕,只剩下守护线程时,JVM进程会自动退出
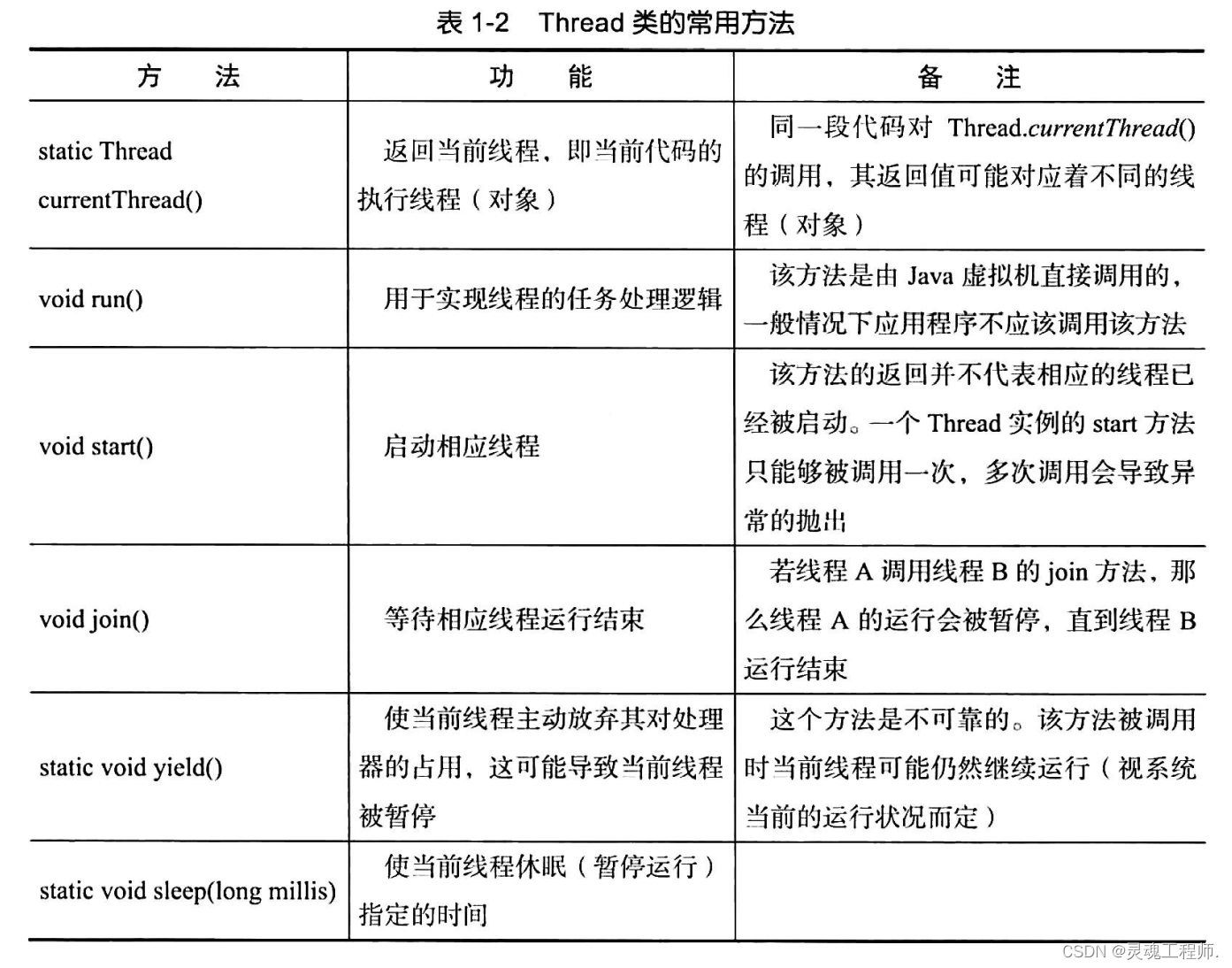
Java线程常用方法
Java中的任何一段代码总是执行在某个确定的线程之中
Java创建线程方式
分别为继承Thread类、实现Runnable接口、实现Callable接口以及使用线程池ThreadPoolExecutor,开发过程中规定使用线程池方式创建线程
1.继承Thread类
package juc;
/**
* @author Arthus
*/
public class TestThread {
public static void main(String[] args) {
MyThread thread1 = new MyThread();
MyThread thread2 = new MyThread();
thread1.setName("Thread1");
thread2.setName("Thread2");
Thread.currentThread().setName("Main Thread");
thread1.start();
thread2.start();
for (int i = 1; i <= 3; i++) {
System.out.println(Thread.currentThread().getName()+"执行第"+i+"次");
}
}
}
class MyThread extends Thread{
@Override
public void run() {
for (int i = 1; i <= 3; i++) {
System.out.println(Thread.currentThread().getName()+"执行第"+i+"次");
}
}
}
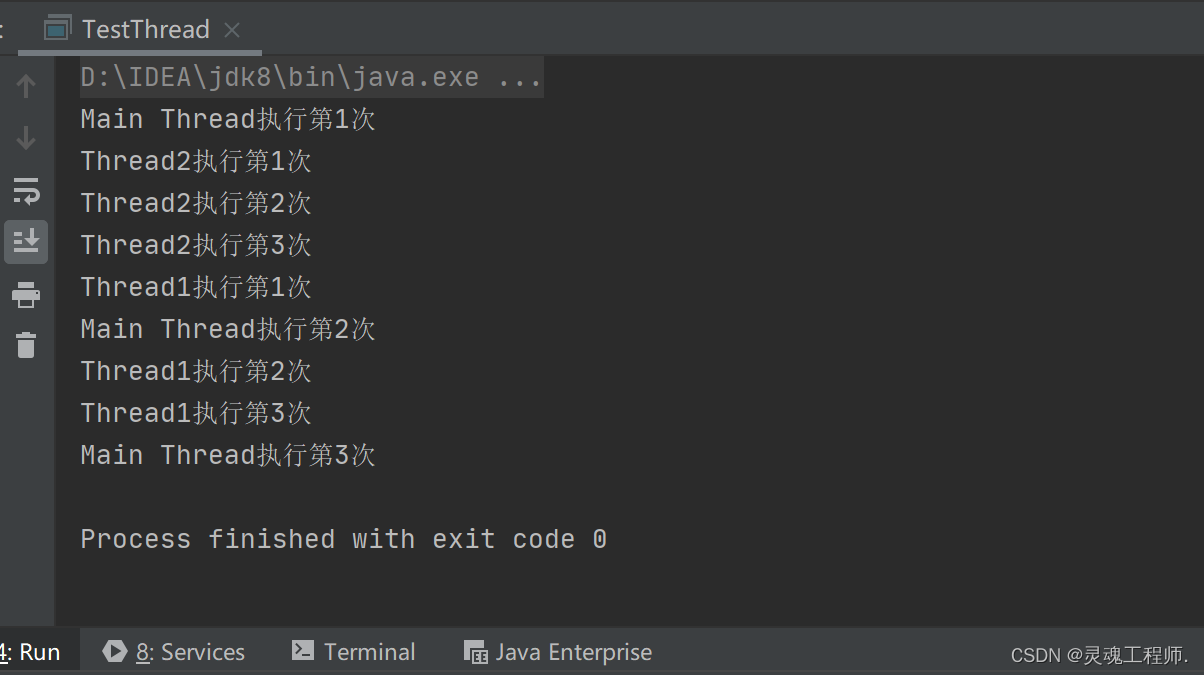
运行结果:
2.实现Runnable接口
package juc;
/**
* @author Arthus
*/
public class TestRunnable {
public static void main(String[] args) {
Thread thread1 = new Thread(new MyRunnable());
thread1.setName("MyRunnable1");
thread1.start();
Thread thread2 = new Thread(new MyRunnable());
thread2.setName("MyRunnable2");
thread2.start();
Thread.currentThread().setName("Main Thread");
for (int i = 1; i <= 3; i++) {
System.out.println(Thread.currentThread().getName()+"执行第"+i+"次");
}
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 1; i <= 3; i++) {
System.out.println(Thread.currentThread().getName()+"执行第"+i+"次");
}
}
}
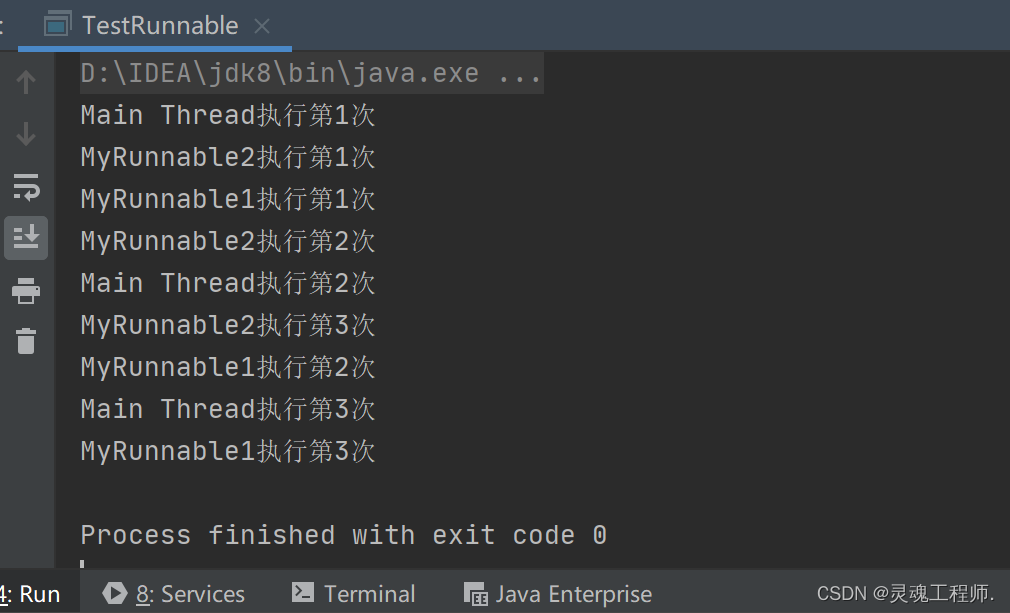
运行结果:
3.实现Callable接口
package juc;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* @author Arthus
*/
public class TestCallable {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> futureTask1 = new FutureTask<>(new MyCallable());
Thread thread1 = new Thread(futureTask1);
thread1.setName("Thread1");
FutureTask<Integer> futureTask2 = new FutureTask<>(new MyCallable());
Thread thread2 = new Thread(futureTask2);
thread2.setName("Thread2");
thread1.start();
thread2.start();
System.out.println("Thread1的返回值:" + futureTask1.get());
System.out.println("Thread2的返回值:" + futureTask2.get());
}
}
class MyCallable implements Callable {
@Override
public Object call() throws Exception {
int i;
for (i = 1; i <= 3; i++) {
System.out.println(Thread.currentThread().getName()+"执行第"+i+"次");
}
return i;
}
}
运算结果:
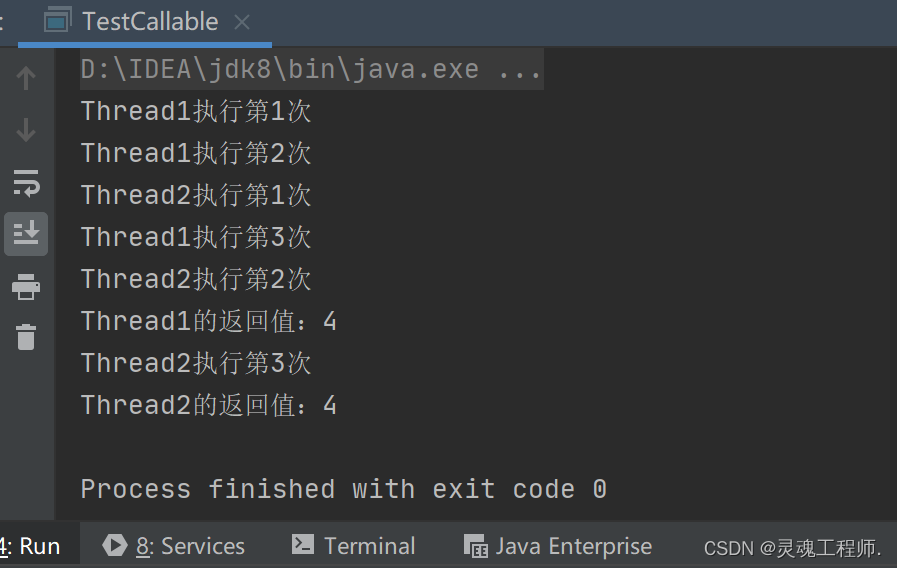
4.线程池创建线程
package juc;
import java.util.concurrent.*;
/**
* @author Arthus
*/
public class TestThreadPool {
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 10, 100, TimeUnit.SECONDS, new LinkedBlockingDeque<>(10));
for (int j = 0; j < 3; j++) {
threadPoolExecutor.execute(new MyPoolRunnable());
}
}
}
class MyPoolRunnable implements Runnable {
@Override
public void run() {
for (int i = 1; i <= 3; i++) {
System.out.println(Thread.currentThread().getName() + "执行第" + i + "次");
}
}
}
运行结果:
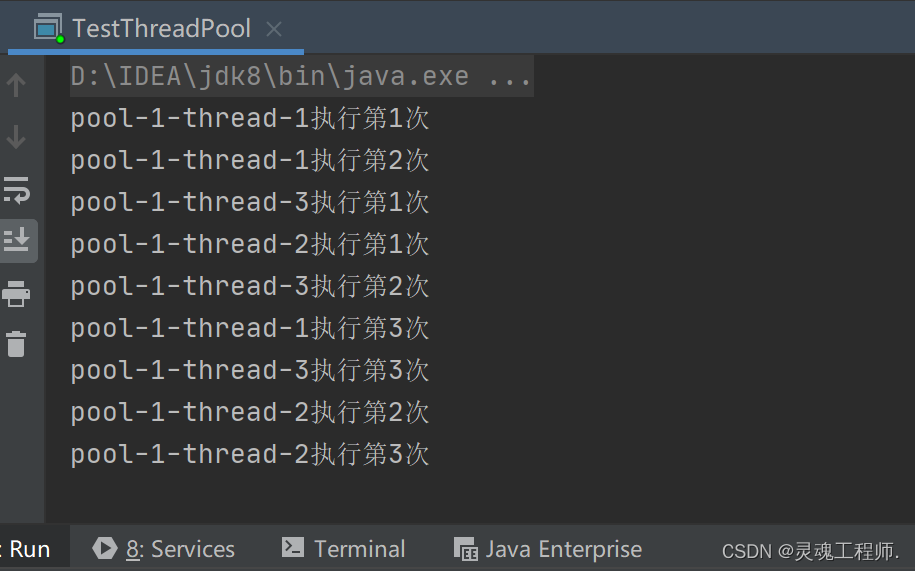
Java线程池
线程池(Thread Pool) 是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL
自行显示创建线程带来的问题不仅开销大,而且对资源无限申请缺少抑制手段,易引发系统资源耗尽的风险,系统无法合理管理内部的资源分布,会降低系统的稳定性,为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想
池化(Pooling)思想:顾名思义,是为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想,应用实例包括:
- 内存池(Memory Pooling):预先申请内存,提升申请内存速度,减少内存碎片。
- 连接池(Connection Pooling):预先申请数据库连接,提升申请连接的速度,降低系统的开销。
- 实例池(Object Pooling):循环使用对象,减少资源在初始化和释放时的昂贵损耗。
- 线程池(Thread Pooling):预先创建线程,重复利用线程资源,减少创建和销毁线程的开销
线程池的优点:
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
ThreadPoolExecutor类
Java中的线程池核心实现类是ThreadPoolExecutor,阿里开发手册规定线程池不允许用Executor来实现,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的人员更加明确线程池的运行规则,规避资源耗尽的风险

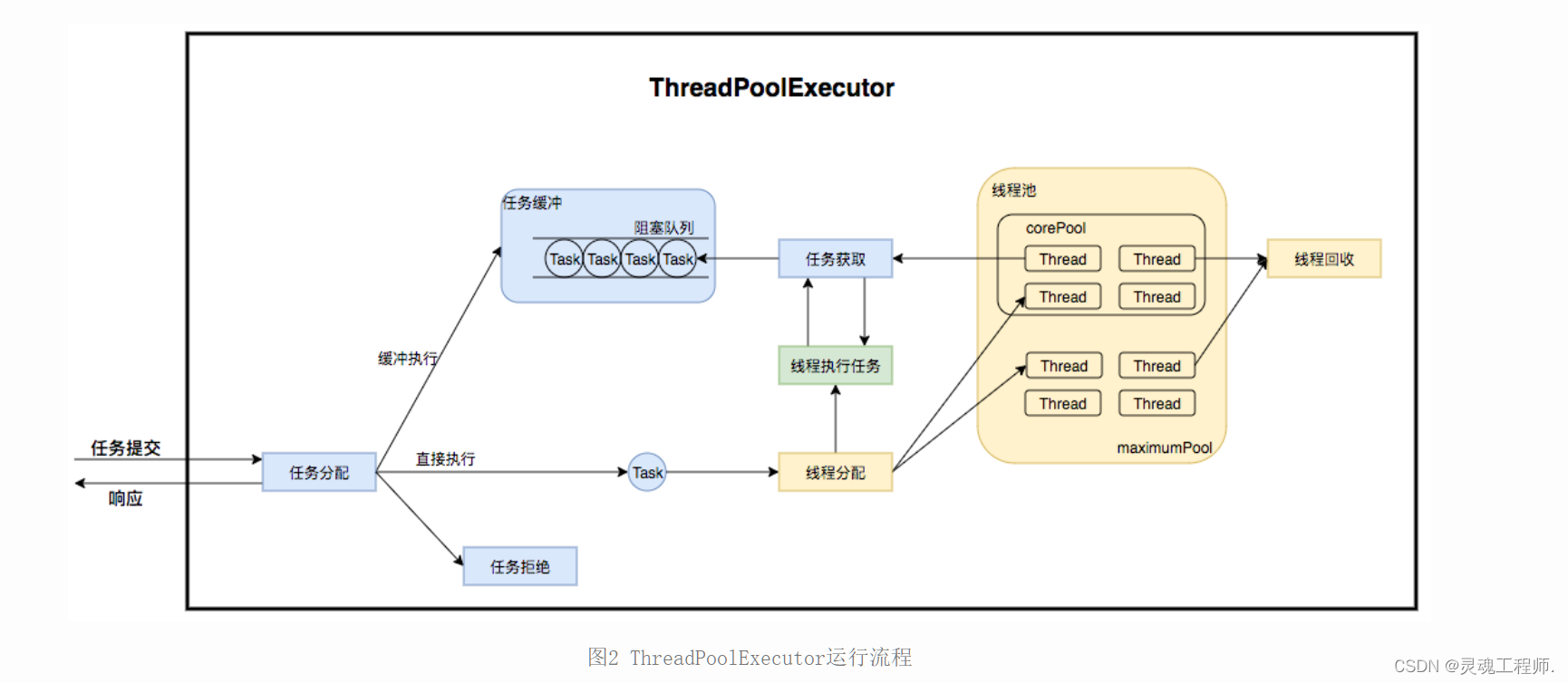
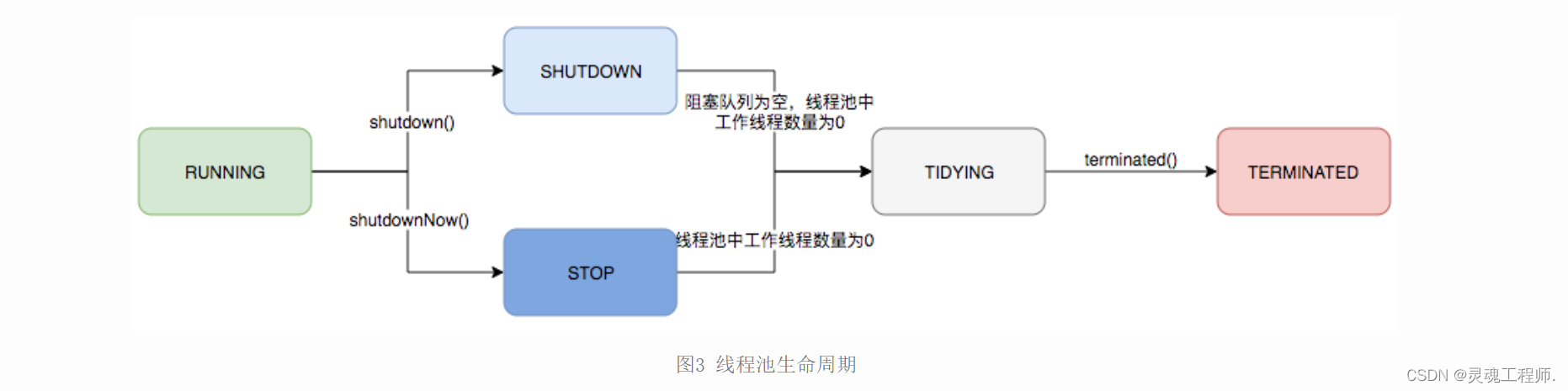
ThreadPoolExecutor运行机制如下图所示:

线程池的生命周期管理
线程池运行的状态,并不是用户显式设置的,而是伴随着线程池的运行,由内部来维护。线程池内部使用一个变量维护两个值:运行状态(runState)和线程数量 (workerCount)。在具体实现中,线程池将运行状态(runState)、线程数量 (workerCount)两个关键参数的维护放在了一起,如下代码所示:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));

关于内部封装的获取生命周期状态、获取线程池线程数量的计算方法如以下代码所示:
private static int runStateOf(int c) { return c & ~CAPACITY; } //计算当前运行状态
private static int workerCountOf(int c) { return c & CAPACITY; } //计算当前线程数量
private static int ctlOf(int rs, int wc) { return rs | wc; } //通过状态和线程数生成ctl
ThreadPoolExecutor的运行状态有5种,分别为:

其生命周期转换如下入所示:
线程池的任务调度
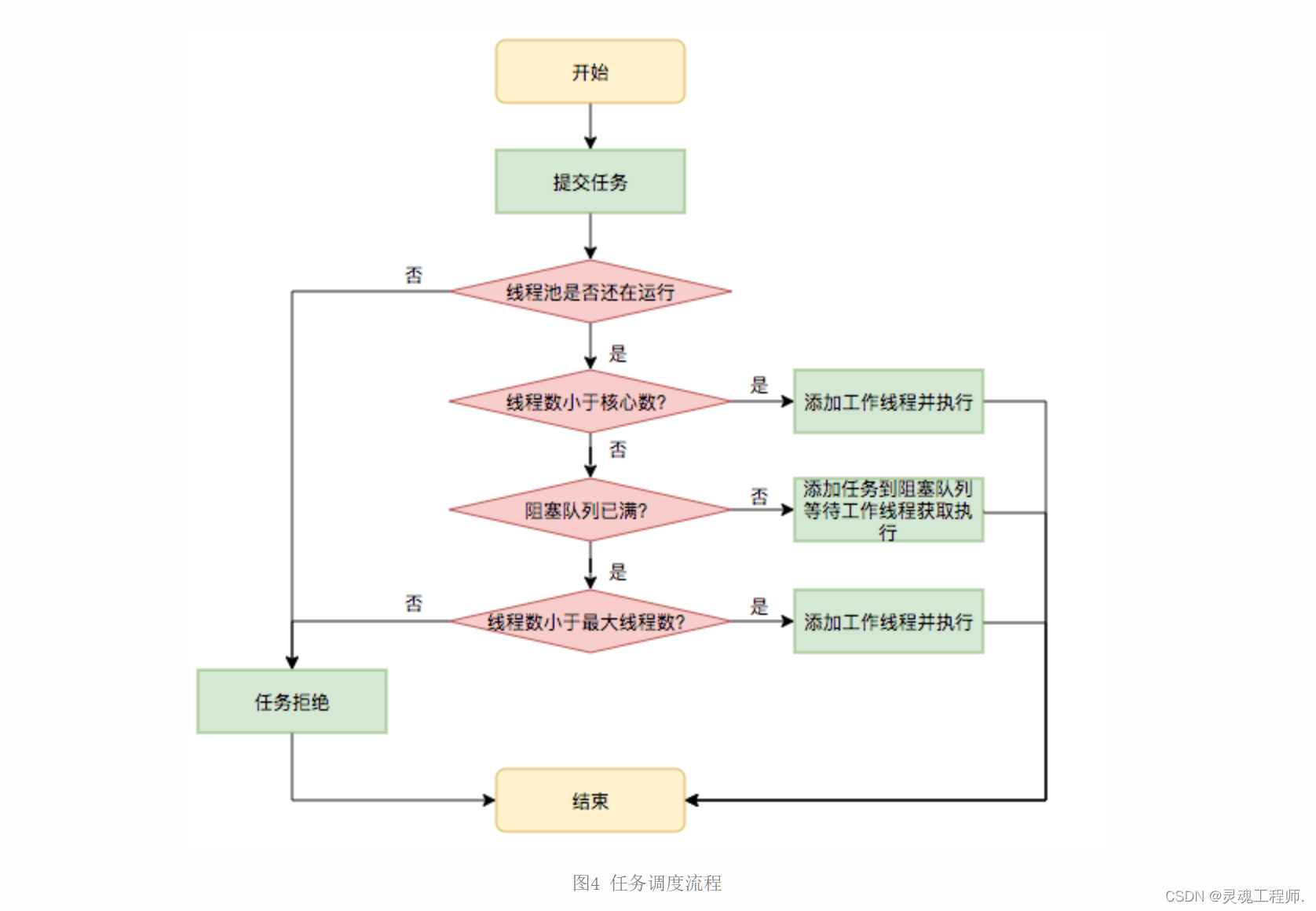
任务调度是线程池的主要入口,当用户提交了一个任务,接下来这个任务将如何执行都是由这个阶段决定的。了解这部分就相当于了解了线程池的核心运行机制。
首先,所有任务的调度都是由execute方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。其执行过程如下:
- 首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
- 如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
- 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
其执行流程如下图所示:
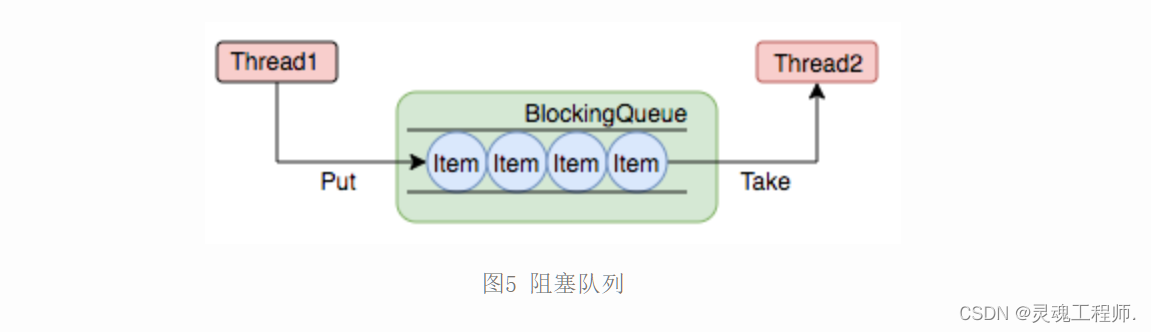
线程池的任务缓冲
任务缓冲模块是线程池能够管理任务的核心部分。线程池的本质是对任务和线程的管理,而做到这一点最关键的思想就是将任务和线程两者解耦,不让两者直接关联,才可以做后续的分配工作。线程池中是以生产者消费者模式,通过一个阻塞队列来实现的。阻塞队列缓存任务,工作线程从阻塞队列中获取任务。
线程池的任务申请
线程需要从任务缓存模块中不断地取任务执行,帮助线程从阻塞队列中获取任务,实现线程管理模块和任务管理模块之间的通信。这部分策略由getTask方法实现,其执行流程如下图所示:
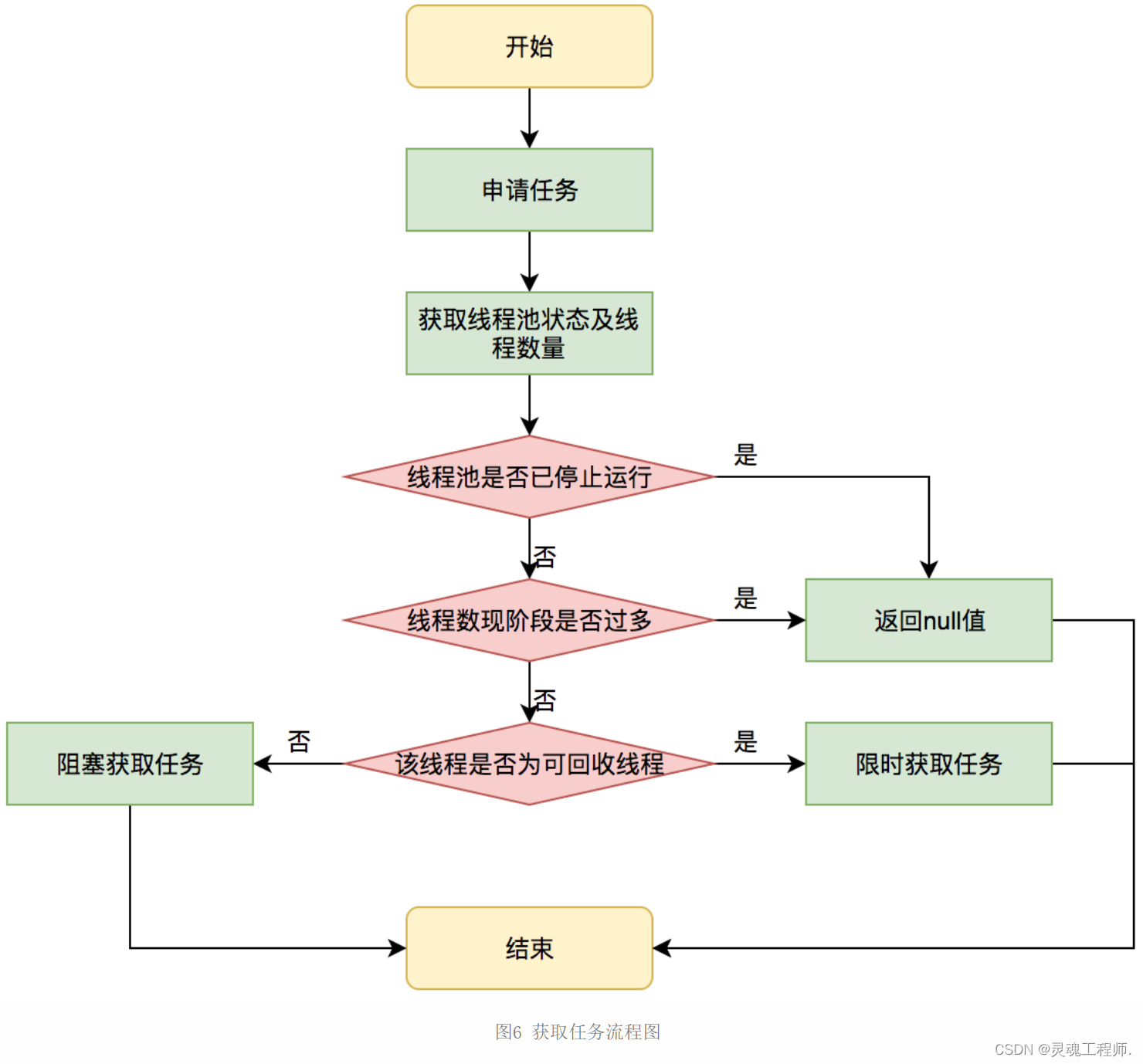
getTask这部分进行了多次判断,为的是控制线程的数量,使其符合线程池的状态。如果线程池现在不应该持有那么多线程,则会返回null值。工作线程Worker会不断接收新任务去执行,而当工作线程Worker接收不到任务的时候,就会开始被回收。
线程池的任务拒绝
任务拒绝模块是线程池的保护部分,线程池有一个最大的容量,当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。
拒绝策略是一个接口,其设计如下:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
用户可以通过实现这个接口去定制拒绝策略,也可以选择JDK提供的四种已有拒绝策略,其特点如下:
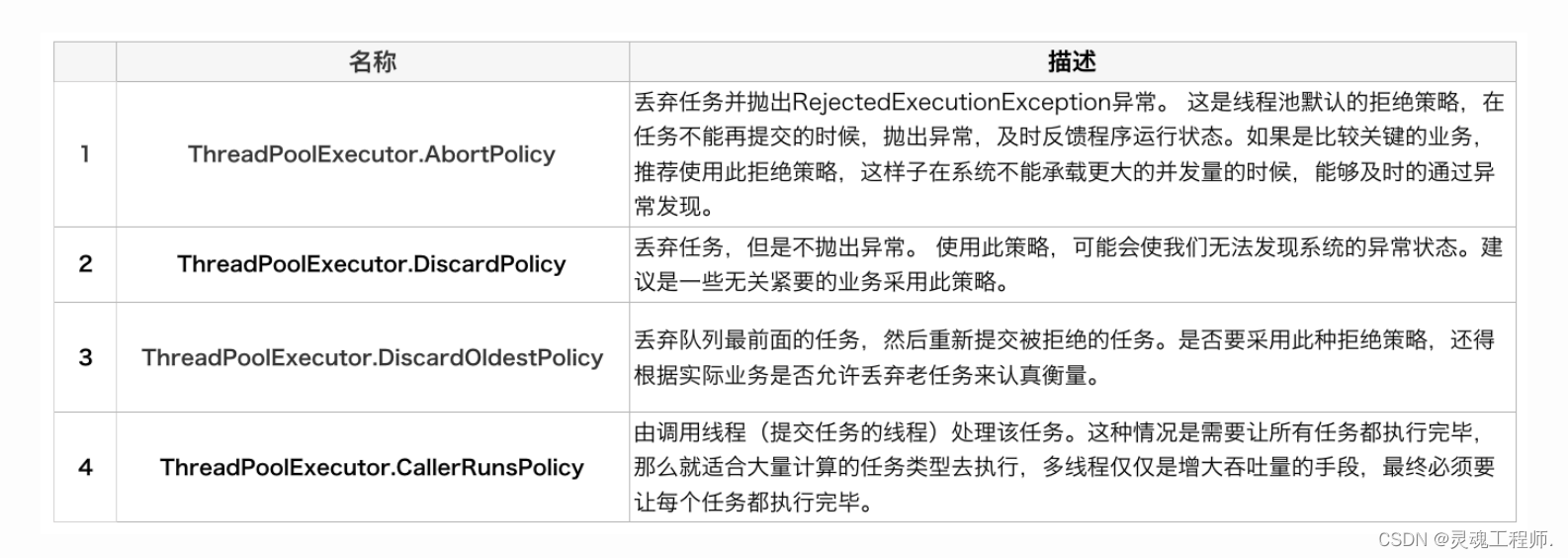
线程池的参数配置
线程池使用面临的核心的问题在于:线程池的参数并不好配置。一方面线程池的运行机制不是很好理解,配置合理需要强依赖开发人员的个人经验和知识;另一方面,线程池执行的情况和任务类型相关性较大,IO密集型和CPU密集型的任务运行起来的情况差异非常大,这导致业界并没有一些成熟的经验策略帮助开发人员参考,业界的一些线程池参数配置方案如下:

由于业务复杂性的原因,我们无法评估出合适的线程池参数配置,于是我们实现动态化线程池,动态化线程池的核心设计包括以下三个方面:
1.简化线程池配置:线程池构造参数有8个,但是最核心的是3个:corePoolSize、maximumPoolSize,workQueue,它们最大程度地决定了线程池的任务分配和线程分配策略。考虑到在实际应用中我们获取并发性的场景主要是两种:(1)并行执行子任务,提高响应速度。这种情况下,应该使用同步队列,没有什么任务应该被缓存下来,而是应该立即执行。(2)并行执行大批次任务,提升吞吐量。这种情况下,应该使用有界队列,使用队列去缓冲大批量的任务,队列容量必须声明,防止任务无限制堆积。所以线程池只需要提供这三个关键参数的配置,并且提供两种队列的选择,就可以满足绝大多数的业务需求,Less is More
2.参数可动态修改:为了解决参数不好配,修改参数成本高等问题。在Java线程池留有高扩展性的基础上,封装线程池,允许线程池监听同步外部的消息,根据消息进行修改配置。将线程池的配置放置在平台侧,允许开发同学简单的查看、修改线程池配置
3.增加线程池监控:对某事物缺乏状态的观测,就对其改进无从下手。在线程池执行任务的生命周期添加监控能力,帮助开发同学了解线程池状态
虽然本质上还是没有逃离使用线程池的范畴,但是在成本和收益之间,算是取得了一个很好的平衡。成本在于实现动态化以及监控成本不高,收益在于:在不颠覆原有线程池使用方式的基础之上,从降低线程池参数修改的成本以及多维度监控这两个方面降低了故障发生的概率
Java中Future接口
Java并发包中提供了一个java.util.concurrent.Future接口用于抽象异步计算结果。JUC中提供了一个Future接口实现---FutureTask类,用于和线程池ThreadPoolExecutor一起搭配使用
//Future接口
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
Future接口提供的get()方法用于阻塞获取异步计算结果,cancel()方法用于取消异步计算任务。所以可以发现:Future对象一方面抽象了异步计算结果;另一方面Future本质上是一种实现线程间同步的组件:协调提交计算的线程和执行计算的线程。具体到FutureTask实现,它的作用就是在提交任务的线程和线程池中执行任务的工作线程之间提供某种同步机制。
Future对象持有的是一个未来的结果,这个未来的结果通过异步方式计算得到
FutureTask类:FutureTask类实现了RunnableFuture接口,而RunnableFuture接口实现了Runnable和Future接口,所以FutureTask本身就是一个Runnable对象,可以作为一个任务被线程池执行
通过博客传送门深入了解源码
线程的层次关系
假设线程A执行的代码创建了线程B,则称线程A为线程B的父线程,线程B为线程A的子线程,父线程与子线程之间的生命周期没有必然的联系。
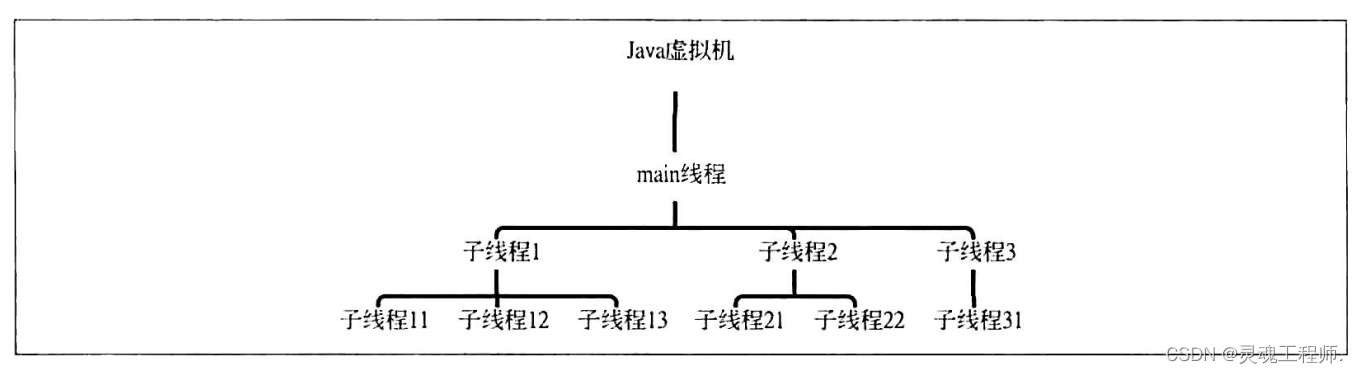
若父线程为守护线程,则其子线程也默认为守护线程
线程的生命周期
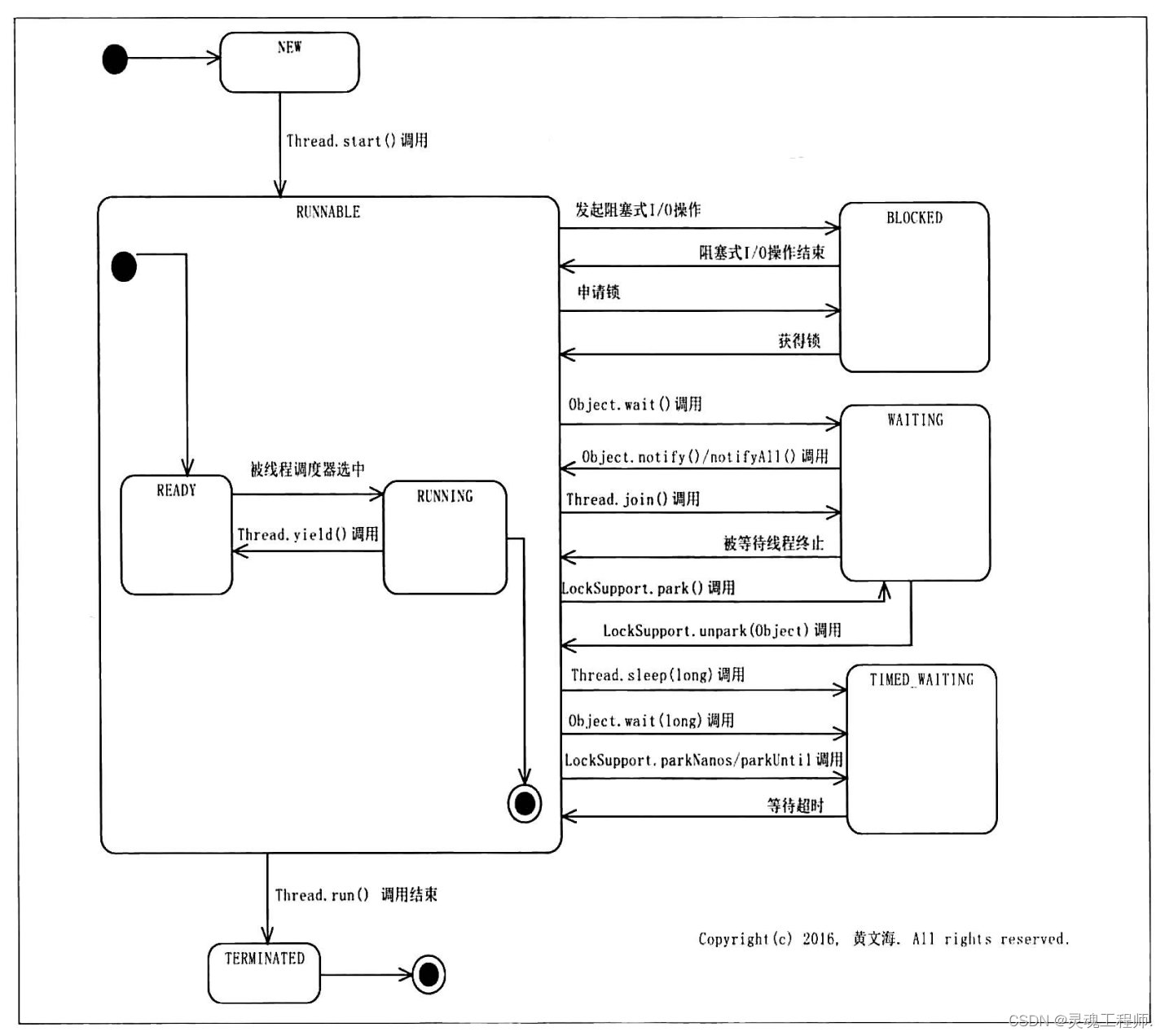
Thread.State定义的线程状态包括6种:
-
NEW(新建):一个已创建而未启动的线程
-
RUNNABLE:该状态可以被看成一个复合状态,包括两个子状态READY(就绪) 和 RUNNING(运行),线程有时会在这两个状态之间进行转换,处于READY子状态的线程也被称为活跃线程
-
BLOCKED(阻塞):当线程发起一个阻塞式I/O操作,或申请一个被其他线程持有的独占资源(比如:锁),线程便会处于BLOCKED阻塞状态,处于BLOCKED状态的线程不会占用CPU,当线程获得了其申请的资源时又可以转化为RUNNABLE状态
-
WAITING(等待):当线程执行了某些特定方法之后就会处于这种等待其他线程执行完另外一些特定操作的状态
能使线程变更为WAITING状态的方法:
Object.wait();Thread.join();LockSupport.park(Object);
能使线程从WAITING状态变更为RUNNABLE状态的方法:Object.notify();Object.notifyAll();LockSupport.unpark(Object); -
TIMED_WAITING(限时等待):有时间限制的等待状态,当其他线程没有在指定时间内执行该线程所期望的特定操作时,该线程自动转换为RUNNABLE状态
-
TERMINATED(终止):run()方法正常执行完毕的线程或run()方法因异常而提前终止的线程会处于该状态
线程安全机制
当多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安全的
多线程的风险
安全性问题:多个线程共享数据时,如果没有采用对应并发访问控制措施,就可能会产生数据一致性问题,如读脏数据、丢失更新等
活跃性问题:如死锁、活锁、饥饿问题
例:线程A在等待线程B释放其持有的资源,而线程B永远都不释放该资源,那么A就会永久地等待下去
性能问题:在多线程中,当线程调度器临时挂起活跃线程并转而运行另一个线程时,就会频繁地出现上下文切换操作(Context Switch),这种操作将带来极大的系统开销;当线程共享数据时,必须使用同步机制,而这些机制往往会抑制某些编译器优化,使内存缓存区中的数据无效,以及增加共享内存总线的同步流量
竞态条件
当某个计算的正确性取决于多个线程的交替执行顺序时,就会发生竞态条件,换句话说,就是结果的正确与否要取决于运气
竞态的两种典型模式:
1.读-改-写(read-modify-write)
如多个线程同时操作i++会出现不可预测的结果,因为一次i++包括三个独立的步骤:
- 将i从内存复制到寄存器
- i在寄存器中进行i++
- 再把i复制到内存
两个线程同时对同一个i执行i++各100次,i最终的结果会是在2~200范围内
2.检测后行动(check-then-act)
如单例模式中的懒汉式含有判断执行条件到导致多个线程获取单例对象时会获取到不同的对象
public class X {
private static X instance;
private X() {
}
public static X getInstance() {
if (instance == null) {
instance = new X();
}
return instance;
}
}
加双检锁和volatile关键字保证懒汉式的线程安全和效率
public class X{
private static volatile X instance;//volatile保证可见性和有序性
private X(){}
private static Object key = new Obejct();
public static X getInstance(){
if(instance == null){//提高效率
synchronized (key) {//线程安全模式
if(instance==null){
instance = new X();
}
}
}
return instance;
}
}
无状态对象:计算过程中的临时状态仅存在于线程栈上的局部变量中,并且只能由正在执行的线程访问,则称为无状态对象;由于线程访问无状态对象的行为并不会影响其他线程中操作的正确性,因此无状态对象是线程安全的,不会出现竞态条件。

原子性
若对于共享变量的操作从其执行线程以外的任意线程来看是不可分割的,那么该操作就是原子操作,相应地我们称该操作具有原子性( Atomicity )。

Java有两种方式实现原子性,一种是使用锁(lock),另一种是使用CAS(Compare-and-Swap) 指令
CAS指令实现原子性的方式与锁实现原子性的方式实质上是相同的,差别在锁通常是在软件这一层次实现的,而CAS是直接在硬件(处理器和内存)这一层次实现的

Java规定对于volatile关键字修饰的变量写操作具有原子性
可见性
可见性就是指一个线程对共享变量的更新结果对于读取该共享变量的线程而言是否可见
可见性问题
例:模拟一个耗时任务,若超时则停止

在主线程中运行以下代码

结果:线程任务可能超时之后也不会停止,出现死循环,可见这里产生了可见性问题,即main线程对共享变量toCancel的更新对子线程thread而言不可见
这种可见性问题是因为代码没有给JIT编译器足够的提示而使得其认为状态变量toCancel只有一个线程对其进行访问,从而导致JIT编译器为了避免重复读取状态变量toCancel以提高代码的运行效率,而将run方法中的while循环优化成与如下代码等效的本地代码(机器码),从而导致可见性问题

另一方面,可见性问题与计算机存储系统有关


在Java中使用volatile关键字保证可见性


线程的启动、停止与可见性:Java语言规范(JLS)保证,父线程在启动子线程之前对共享变量的更新对于子线程来说是可见的,而父线程在子线程启动之后对共享变量的更新对子线程的可见性是没有保证的

Happens-Before原则:定义对于两个操作A和B,这两个操作可以在不同的线程中执行。如果A Happens-Before B(A先于B执行),那么可以保证,当A操作执行完后,A操作的执行结果对B操作是可见的。
有序性
指在某些情况下一个处理器上运行的一个线程所执行的内存访问操作在另一个处理器上运行的其他线程看来是乱序的(乱序指内存访问操作的顺序看起来像是发生了变化)
重排序概念

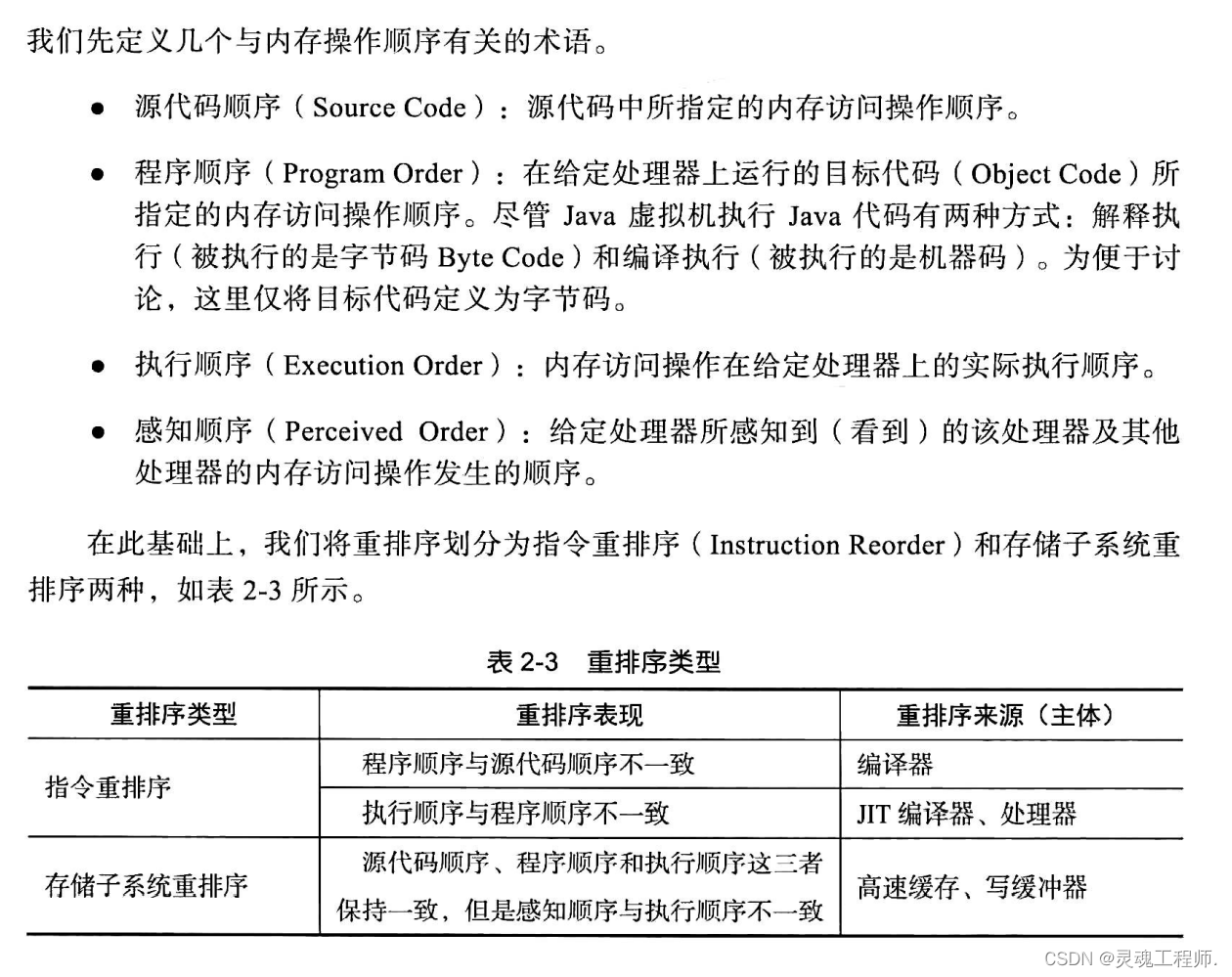
指令重排序
在源代码顺序与程序顺序不一致,或者程序顺序与执行顺序不一致的情况下,我们就说发生了指令重排序,它确确实实地对指令的顺序做出了调整,其重排序的对象是指令

重排序问题代码示例:引用Java攻城狮文章
public class VolatileReOrderSample {
//定义四个静态变量
private static int x=0,y=0;
private static int a=0,b=0;
public static void main(String[] args) throws InterruptedException {
int i=0;
while (true){
i++;
x=0;y=0;a=0;b=0;
//开两个线程,第一个线程执行a=1;x=b;第二个线程执行b=1;y=a
Thread thread1=new Thread(new Runnable() {
@Override
public void run() {
//线程1会比线程2先执行,因此用nanoTime让线程1等待线程2 0.01毫秒
shortWait(10000);
a=1;
x=b;
}
});
Thread thread2=new Thread(new Runnable() {
@Override
public void run() {
b=1;
y=a;
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
//等两个线程都执行完毕后拼接结果
String result="第"+i+"次执行x="+x+"y="+y;
//如果x=0且y=0,则跳出循环
if (x==0&&y==0){
System.out.println(result);
break;
}else{
System.out.println(result);
}
}
}
//等待interval纳秒
private static void shortWait(long interval) {
long start=System.nanoTime();
long end;
do {
end=System.nanoTime();
}while (start+interval>=end);
}
}
运行结果:

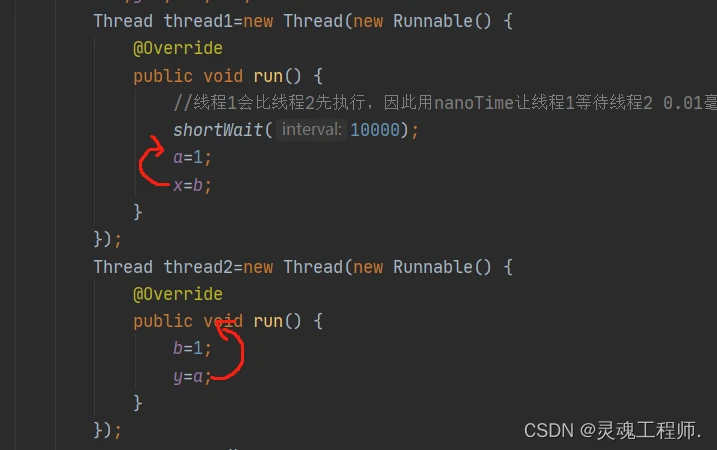
Java平台中 静态编译器(javac) 基本上不会执行指令重排序,而 动态编译器(JIT)则可能执行指令重排序
存储子系统重排序

貌似串行语义(as-if-serial):重排序是遵循一定规则来对指令、内存操作的结果进行顺序调整,编译器和处理器都会遵循这些规则,但重排序会保证在单线程情况下的代码执行结果的正确性,从而给单线程程序造成一种假象——指令是按照源代码顺序执行的,这种假象就称为貌似串行语义

保存内存访问的有序性:使用volatile关键字修饰


可见性和有序性的区别:

活性故障
由资源稀缺性或者程序自身的问题和缺陷导致线程一直处于非Runnable状态,或者线程处于Runnable状态但是其要执行的任务却一直无法进展的现象就被称为线程活性故障,常见的活性故障包括以下几种
死锁(Deadlock)
两个或多个线程各自持有不同的锁,然后各自试图获取对方手里的锁,造成了双方无限等待下去,这就是死锁
public void add(int m) {
synchronized(lockA) { // 获得lockA的锁
this.value += m;
synchronized(lockB) { // 获得lockB的锁
this.another += m;
} // 释放lockB的锁
} // 释放lockA的锁
}
public void dec(int m) {
synchronized(lockB) { // 获得lockB的锁
this.another -= m;
synchronized(lockA) { // 获得lockA的锁
this.value -= m;
} // 释放lockA的锁
} // 释放lockB的锁
}
一个线程可以获取一个锁后,再继续获取另一个锁,在获取多个锁的时候,不同线程获取多个不同对象的锁可能导致死锁;死锁发生后,没有任何机制能解除死锁,只能强制结束JVM进程
锁死(Lockout)
等待线程由于唤醒线程所需要的条件 永远无法成立导致线程一直无法处于RUNNABLE状态,我们就称这个线程被锁死
锁死分为两种:
-
信号丢失锁死:信号丢失锁死是由于没有相应的通知线程来唤醒等待线程而使等待线程一直处于等待状态的一种活性故障。
-
嵌套监视器锁死:嵌套监视器锁死是嵌套锁导致等待线程永远无法被唤醒的一种活性故障
//嵌套监视器锁死实例
public class Lock{
protected MonitorObject monitorObject = new MonitorObject();
protected boolean isLocked = false;
public void lock() throws InterruptedException{
synchronized(this){
while(isLocked){
synchronized(this.monitorObject){
this.monitorObject.wait();
}
}
isLocked = true;
}
}
public void unlock(){
synchronized(this){
this.isLocked = false;
synchronized(this.monitorObject){
this.monitorObject.notify();
}
}
}

虽然死锁与锁死表现出来都是线程等待,无法继续完成任务,但是产生的条件是不同的,即使在不可能产生死锁的情况下也可能出现锁死,所以不能使用对付死锁的办法来解决锁死问题
活锁(Livelock)
活锁是指线程一直争取所需资源未成功而不断重试,此时线程饥饿演变为活锁,活锁可能自动解开
饥饿(Starvation)
线程饥饿( Thread Starvation)是指线程一直无法获得其所需的资源而导致其任务一直无法进展的一种活性故障

比如尽管非公平锁可以支持更高的吞吐率,但它也可能导致某些线程总是无法获取所需的资源(锁),即产生了线程饥饿;把锁看作一种资源,那么我们不难发现死锁和锁死也是一种线程饥饿
上下文切换
上下文切换(Context Switch)在某种程度上可以被看作多个线程共享一个处理器的产物,它是多线程编程中的一个重要概念


按照导致上下文切换的因素划分,我们可以将上下文切换分为自发性上下文切换(Voluntary Context Switch)和非自发性上下文切换(Involuntary Context Switch)
- 自发性上下文切换:指由于其自身因素导致的切出,从Java平台的角度来看,一个线程在其运行过程中执行下列任意一个方法都会引起自发性上下文切换

另外,线程发起了I/O操作(如读取文件)或者等待其他线程持有的锁也会导致自发性上下文切换
- 非自发性上下文切换:指由于线程调度器的原因被迫切出

上下文切换的开销
一方面,上下文切换是必要的。即使是在多核处理器系统中上下文切换也是必要的,这是因为一个系统上需要运行的线程的数量相对于这个系统所拥有的处理器数量总是要大得多(“僧多粥少”)。另一方面,上下文切换又有其不容小觑的开销。
从定性的角度来说,上下文切换的开销包括直接开销和间接开销。
直接开销包括:

间接开销包括

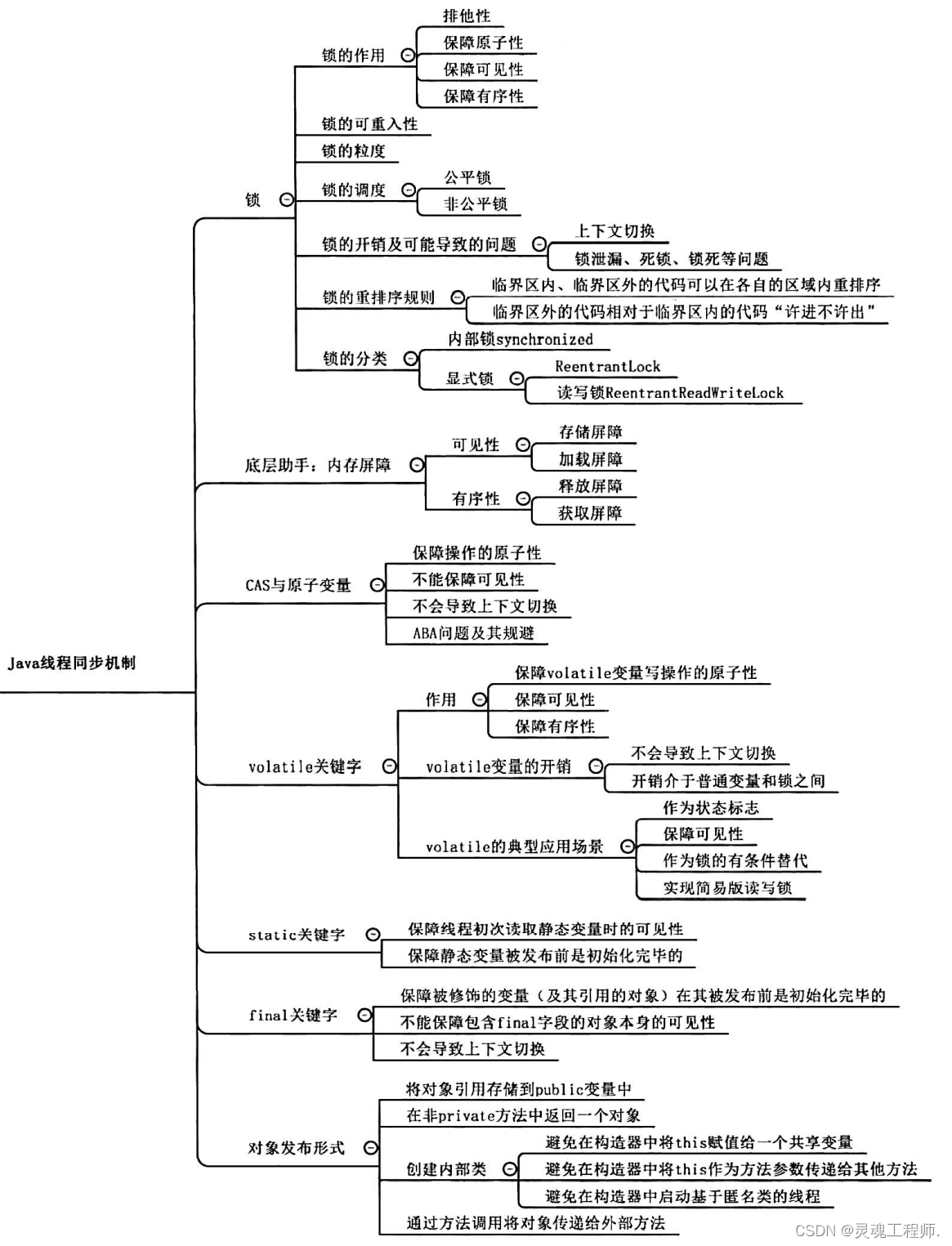
线程同步机制
线程同步机制是一套用于协调线程间的数据访问(Data access)及活动(Activity)的机制,该机制用于保障线程安全以及实现这些线程的共同目标
锁
锁具有排他性(Exclusive),即一个锁一次只能被一个线程持有。因此,这种锁被称为排他锁或互斥锁。另外一种锁---读写锁,可以被看作是排他锁的一种改进
按照JVM对锁的实现方式划分,可分为 内部锁(Intrinsic Lock) 和 显式锁(Explicit Lock)
- 内部锁是由synchronized关键字实现的
- 显示锁是通过java.concurrent.locks.Lock接口中的实现类(如ReentrantLock类和ReetrantReadWriteLock类)实现的
锁能构保护共享数据以实现线程安全,其作用包括保障原子性、可见性和有序性
- 保障原子性

- 保障可见性



- 保障有序性

锁保证原子性、可见性、有序性需要满足一下条件:

可重入性
可重入性(Reetrancy)描述这样一个问题:一个线程在持有一个锁的时候能否再次(或者多次)申请该锁
代码示例:


可重入锁是如何实现的:
锁的争用与调度
Java中锁的调度策略既包括公平策略也包括非公平策略,
相应的锁就被称为公平锁和非公平锁


内部锁属于非公平锁,而显式锁既支持公平锁又支持非公平锁
锁的开销
锁的开销包括锁的申请和释放所产生的开销,以及锁可能导致的上下文切换的开销,这些开销主要是处理器时间
此外,锁的不正确使用也会导致如下一些活性故障

synchronized关键字
Java平台中任何一个对象都有唯一一个与之关联的锁。这种锁被称为监视器(Monitor)或者内部锁(Intrinsic Lock),内部锁是一种排他锁(互斥锁),是通过synchronized关键字实现的
sychronized关键字可以用来修饰方法以及代码块
-
sychronized关键字修饰的方法就被称为同步方法,修饰的静态方法就被称为同步静态方法,修饰的实例方法就被称为同步实例方法。同步方法的整个方法体就是一个临界区。

-
sychronized关键字修饰的代码块就被称为同步块(Sychronized Block),sychronized关键字所引导的代码块就是临界区


同步静态方法相当于以当前对象(Java中的类本身也是一个对象)为引导锁的同步块

线程对内部锁的申请与释放的动作由Java虚拟机负责代为实施,这也是sychronized实现的锁被称为内部锁的原因
内部锁的调度:

Lock接口
显示锁作为一种线程同步机制,其作用与内部锁相同。它提供了一些内部锁所不具备的特性,但并不是内部锁的替代品


一个Lock接口实例就是一个显示锁对象,Lock接口定义的lock方法和unlock方法分别用于申请和释放相应Lock实例表示的锁

显示锁的使用包括以下几个方面:


代码实例:

显示锁的调度:

Read/Write Lock接口
锁的排他性使得多个线程无法以线程安全的方式在同一时刻对共享变量进行读取(只是读取而不更新),这样不利于提高系统的并发性。读写锁(Read/Write Lock) 是一种改进型的排他锁,也被称为共享/排他(Shared/Exclusive)锁,读写锁也属于显式锁的一种

读写锁的功能是通过其扮演两个角色——读锁(Read Lock) 和 写锁(Write Lock) 实现的
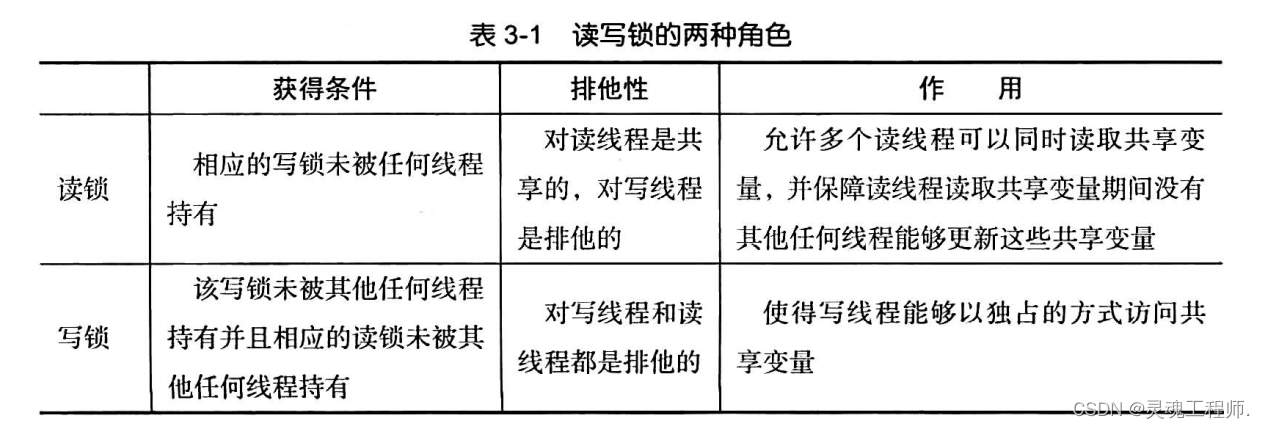


代码示例:

与普通的排他锁(如内部锁和显示锁)相比,读写锁在排他性方面较弱(这是我们期望的),在保障原子性、可见性、有序性方面起到的作用与普通的排他锁是一致的。由于读写锁内部实现比内部锁和其他显示锁复杂得多,因此读写锁适合以下场景:

只有同时满足上面两个条件的时候,读写锁才是适宜的选择;否则,使用读写锁会得不偿失(开销)
ReetrantReadWriteLock所实现的读写锁是个可重入锁,支持锁的降级(Downgrade),即一个线程持有读写锁的写锁情况下可以继续获得相应的读锁:

锁的降级的反面是锁的升级( Upgrade ),即一个线程在持有读写锁的读锁的情况下,申请相应的写锁。ReentrantReadWriteLock 并不支持锁的升级。读线程如果要转而申请写锁,需要先释放读锁,然后申请相应的写锁。
AQS原理
AQS 的全称为(AbstractQueuedSynchronizer),它提供了一个CLH双向队列(FIFO),可以看成是一个用来实现同步锁以及其他涉及到同步功能的核心组件,常见的有:ReentrantLock、SynchronousQueue,FutureTask、CountDownLatch等
AQS是一个抽象类,主要是通过继承的方式来使用,它本身没有实现任何的同步接口,仅仅是定义了同步状态的获取以及释放的方法来提供自定义的同步组件
从使用层面来说,AQS的功能分为两种:独占和共享
- 独占锁,每次只能有一个线程持有锁,比如前面给大家演示的ReentrantLock就是以独占方式实现的互斥锁
- 共享锁,允许多个线程同时获取锁,并发访问共享资源,比如ReentrantReadWriteLock
AQS核心思想是,如果被请求的共享资源空闲,那么就将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程以及等待状态信息构造成一个Node节点,每个Node其实是由线程封装,当线程争抢锁失败后会封装成Node加入到CLH队列中去
//Node节点
static final class Node {
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile int waitStatus;
volatile Node prev; //前驱节点
volatile Node next; //后继节点
volatile Thread thread;//当前线程
Node nextWaiter; //存储在condition队列中的后继节点
//是否为共享锁
final boolean isShared() {
return nextWaiter == SHARED;
}
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
Node() { // Used to establish initial head or SHARED marker
}
//将线程构造成一个Node,添加到等待队列
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
//这个方法会在Condition队列使用,后续单独写一篇文章分析condition
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
CLH队列:Craig、Landin and Hagersten队列,是单向链表,AQS中的队列是CLH变体的虚拟双向队列(FIFO)
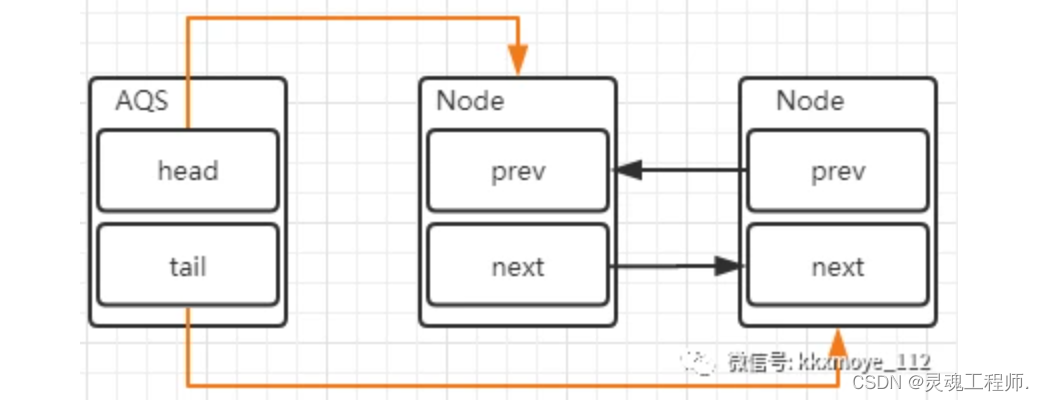
添加节点:当出现锁竞争以及释放锁的时候,AQS同步队列中的节点会发生变化,首先看一下添加节点的场景
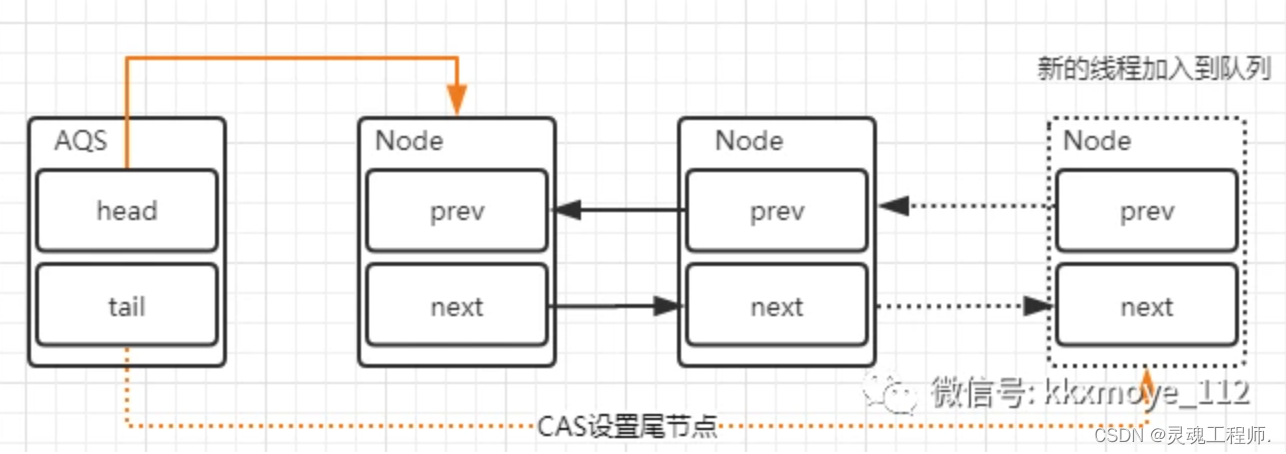
这里会涉及到两个变化:
-
新的线程封装成Node节点追加到同步队列中,设置prev节点以及修改当前节点的前置节点的next节点指向自己
-
通过CAS将tail重新指向新的尾部节点
移除节点:head节点表示获取锁成功的节点,当头结点在释放同步状态时,会唤醒后继节点,如果后继节点获得锁成功,会把自己设置为头结点,节点的变化过程如下
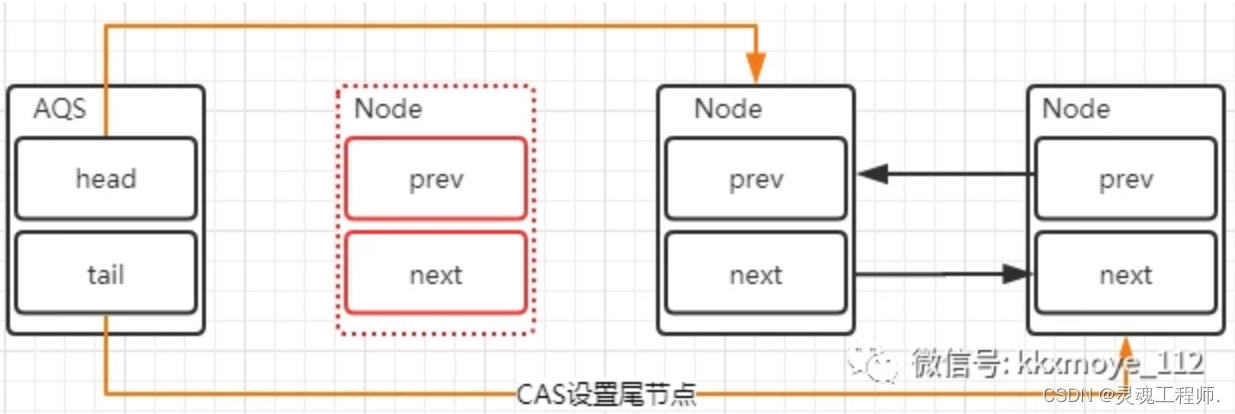
这个过程也是涉及到两个变化:
-
修改head节点指向下一个获得锁的节点
-
新的获得锁的节点,将prev的指针指向null
这里有一个小的变化,就是设置head节点不需要用CAS,原因是设置head节点是由获得锁的线程来完成的,而同步锁只能由一个线程获得,所以不需要CAS原子保证,只需要把head节点设置为原首节点的后继节点,并且断开原head节点的next引用即可
ReentrantLock的时序图:
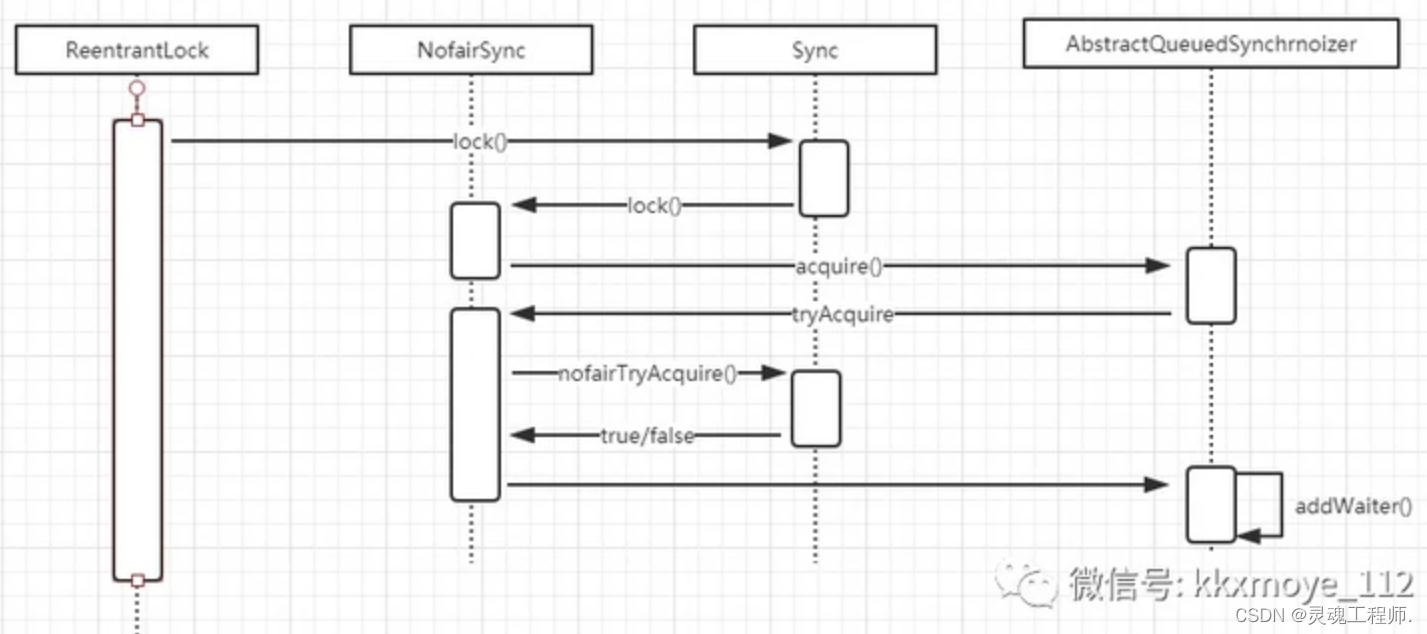
从图上可以看出来,当锁获取失败时,会调用addWaiter()方法将当前线程封装成Node节点加入到AQS队列
通过博客传送门深入了解源码
内部锁和显式锁的比较
内部锁实现为Synchronized关键字,显示锁实现为ReentrantLock类 和 ReentrantReadWrite类

-
内部锁是执行完方法后自动释放锁,而显式锁需要手动启动和释放锁
-
内部锁是基于代码块的锁,灵活性低;显式锁是基于对象的锁,灵活性高

-
内部锁不会发生锁泄露,显示锁容易发生锁泄露

-
显示锁支持了一些内部锁不支持的特性


-
显示锁和内部锁在性能方面的差异

一般情况下,我们可以使用相对保守的策略——默认情况下选用内部锁,仅在需要使用显示锁提供的特性的时候才选用显示锁
锁的使用场景
锁是Java 线程同步机制中功能最强大、适用范围最广泛.同时也是开销最大、可能导致的问题最多的同步机制。多个线程共享同一组数据的时候,如果其中有线程涉及如下操作、那么我们就可以考虑使用锁。
- .读-改-写(check-then-act) 操作:一个线程读取共享数据并在此基础上决定其下一个操作是什么。
- 检测后行动(read-modify-write)操作:一个线程读取共享数据并在此基础上更新该数据。不过,某些像自增操作(“count++”)这种简单的read-modify-write操作,我们可以使用本章后续内容介绍的原子变量类来实现线程安全。
- 多个线程对多个共享数据进行更新:如果这些共享数据之间存在关联关系,那么为了保障操作的原子性我们可以考虑使用锁。例如,关于服务器的配置信息可能包括主机IP地址、端口号等。一个线程如果要对这些数据进行更新,则必须要保障更新操作的原子性,即主机IP地址和端口号总是一起被更新的,否则其他线程可能看到一个并真实存在的主机IP地址和端口号组合所代表的服务器。本章的后续内容也会介绍一种该场景下的替代线程同步机制。
内存屏障
如何保证可见性的时候提到了线程获得和释放锁时所分别执行的两个动作: 刷新处理器缓存 和 冲刷处理器缓存。对于同一个锁所保护的共享数据而言,前一个动作保证了该锁的当前持有线程能够读取到前一个持有线程对这些数据所做的更新,后一个动作保证了该锁的持有线程对这些数据所做的更新对该锁的后续持有线程可见。JVM底层实际上是借助 内存屏障(Memory Barrier,也称Fence) 来实现上述两个动作的

内存屏障是对一类仅针对内存读、写操作指令( Instruction)的跨处理器架构(比如 x86、ARM)的比较底层的抽象(或者称呼)。内存屏障是被插入到两个指令之间进行使用的,其作用是禁止编译器、处理器重排序从而保障有序性。 它在指令序列(如指令1;指令2;指令3)中就像是一堵墙(因此被称为屏障)一样使其两侧(之前和之后)的指令无法“穿越”它(一旦穿越了就是重排序了)。但是,为了实现禁止重排序的功能,这些指令也往往具有一个附带作用——刷新处理器缓存、冲刷处理器缓存,从而保证 可见性 。 不同微架构的处理器所提供的这样的指令是不同的,并且出于不同的目的使用的相应指令也是不同的。


按内存屏障所起的作用来划分内存屏障分为以下几种:
-
按照可见性保障来划分、内存屏障可分为加载屏障(Load Barrier ) 和 存储屏障( Store Barrier )。加载屏障的作用是刷新处理器缓存,存储屏障的作用冲刷处理器缓存。Java 虚拟机会在 MonitorExit(释放锁)对应的机器码指令之后插人一个存储屏障,这就保障了写线程在释放锁之前在临界区中对共享变量所做的更新对读线程的执行处理器来说是可同步的;相应地,Java虚拟机会在. MonitorEnter(申请锁)对应的机器码指令之后临界区开始之前的地方插人一个加载屏障,这使得读线程的执行处理器能够将写线程对相应共享变量所做的更新从其他处理器同步到该处理器的高速缓存中。因此,可见性的保障是通过写线程和读线程成对地使用存储屏障和加载屏障实现的。
-
按照有序性保障来划分,内存屏障可以分为获取屏障(Acquire Barrier) 和 释放屏障( Release Barrier ) 。获取屏障的使用方式是在一个读操作(包括Read-Modify-Write以及普通的读操作)之后插人该内存屏障,其作用是禁止该读操作与其后的任何读写操作之间进行重排序,这相当于在进行后续操作之前先要获得相应共享数据的所有权(这也是该屏障的名称来源)。释放屏障的使用方式是在一个写操作之前插人该内存屏障,其作用是禁止该写操作与其前面的任何读写操作之间进行重排序。这相当于在对相应共享数据操作结束后释放所有权(这也是该屏障的名称来源)。Java 虚拟机会在MonitorEnter (它包含了读操作)对应的机器码指令之后临界区开始之前的地方插入一个获取屏障,并在临界区结束之后MonitorExit(它包含了写操作)对应的机器码指令之前的地方插人一个释放屏障。
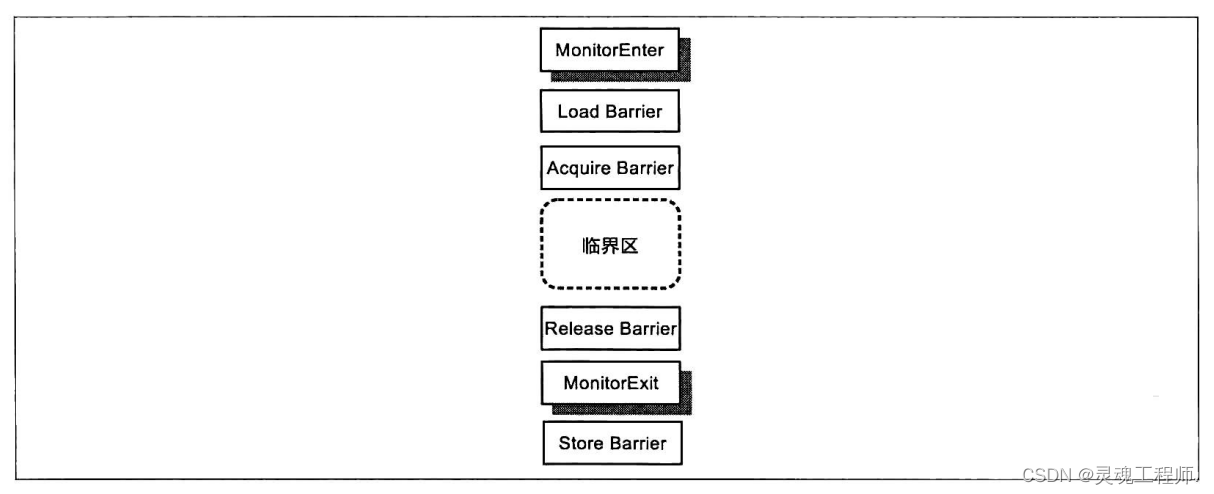
为了保障线程安全,我们需要使用Java线程同步机制,而内存屏障则是Java虚拟机在实现Java线程同步机制时所使用的具体“工具”。因此,Java应用开发人员一般无须(也不能)直接使用内存屏障。
锁与重排序
为了使锁能够起到其预定的作用并且尽量避免对性能造成“伤害”,编译器(基本上指JIT编译器)和处理器必须遵守一些重排序规则,这些重排序规则禁止一部分的重排并且允许另外一部分的重排序(以便不“伤害”性能)。
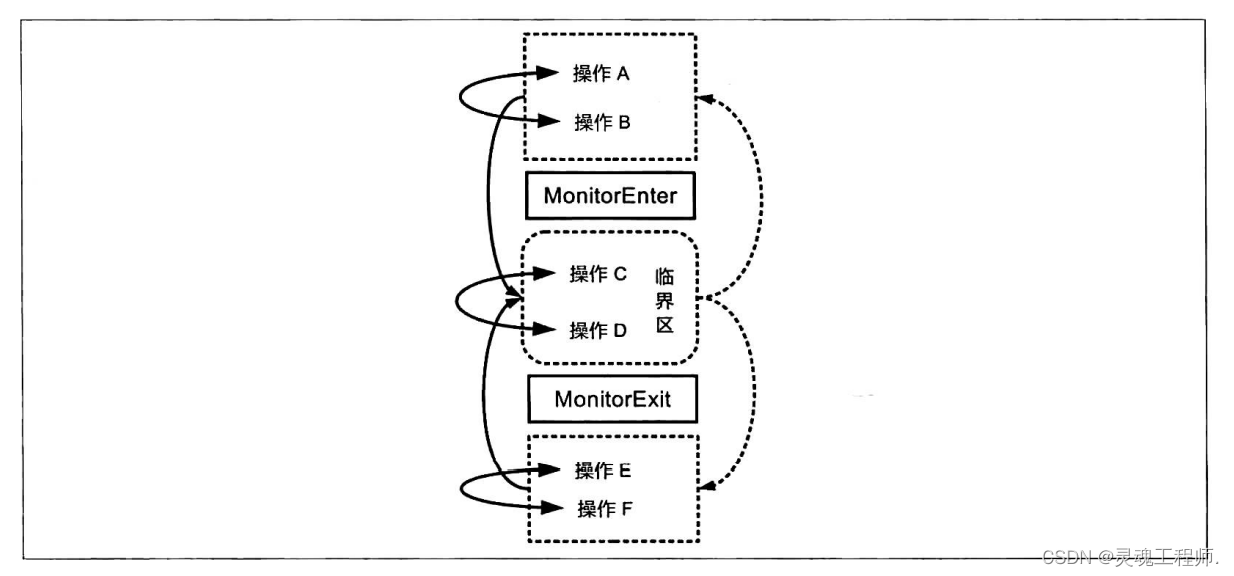
无论是编译器还是处理器,均需要遵守以下重排序规则;
- 规则1——临界区内的操作不允许被重排序到临界区之外(即临界区前或者临界区后)。
- 规则2——临界区内的操作之间允许被重排序。
- 规则3——临界区外(临界区前或者临界区后)的操作之间可以被重排序
- 规则4——锁申请(MonitorEnter)与锁释放(MonitorExit)操作不能被重排序。
- 规则5——两个锁申请操作不能被重排序。
- 规则6——两个锁释放操作不能被重排序。
volatile关键字
volatile关键字常被称为轻量级锁,其作用与锁的作用有相同的地方:保证可见性和有序性。所不同的是,在原子性方面它仅能保障volatile变量写操作的原子性,但没有锁的排他性;其次,volatile关键字的使用不会引起上下文切换(这是volatile被冠以“轻量级”的原因)。因此,volatile更像是一个轻量级简易(功能比锁有限)锁。


对于volatile变量的 写操作 ,Java虚拟机会在该操作之前插人一个释放屏障,并在该操作之后插入一个存储屏障。
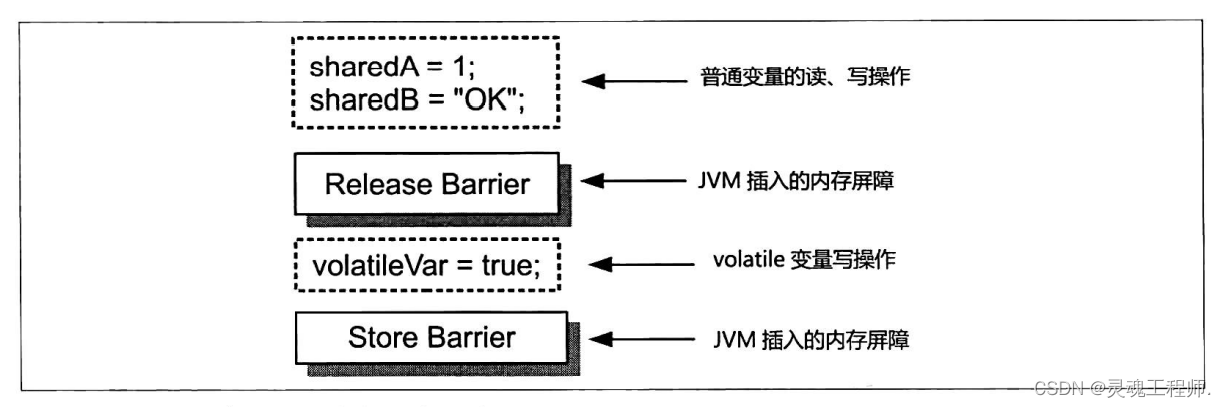

volatile虽然能够保障有序性,但是它不像锁那样具备排他性,所以并不能保障其他操作的原子性,而只能够保障对被修饰变量的写操作的原子性。因此,volatile变量写操作之前的操作如果涉及共享可变变量,那么竞态仍可能产生。这是因为共享变量被赋值给volatile变量的时候其他线程可能已经更新了该共享变量的值。
对于volatile变量 读操作 ,Java虚拟机会在该操作之前插人一个加载屏障(LoadBarrier ),并在该操作之后插人一个获取屏障(Acquire Barrier )
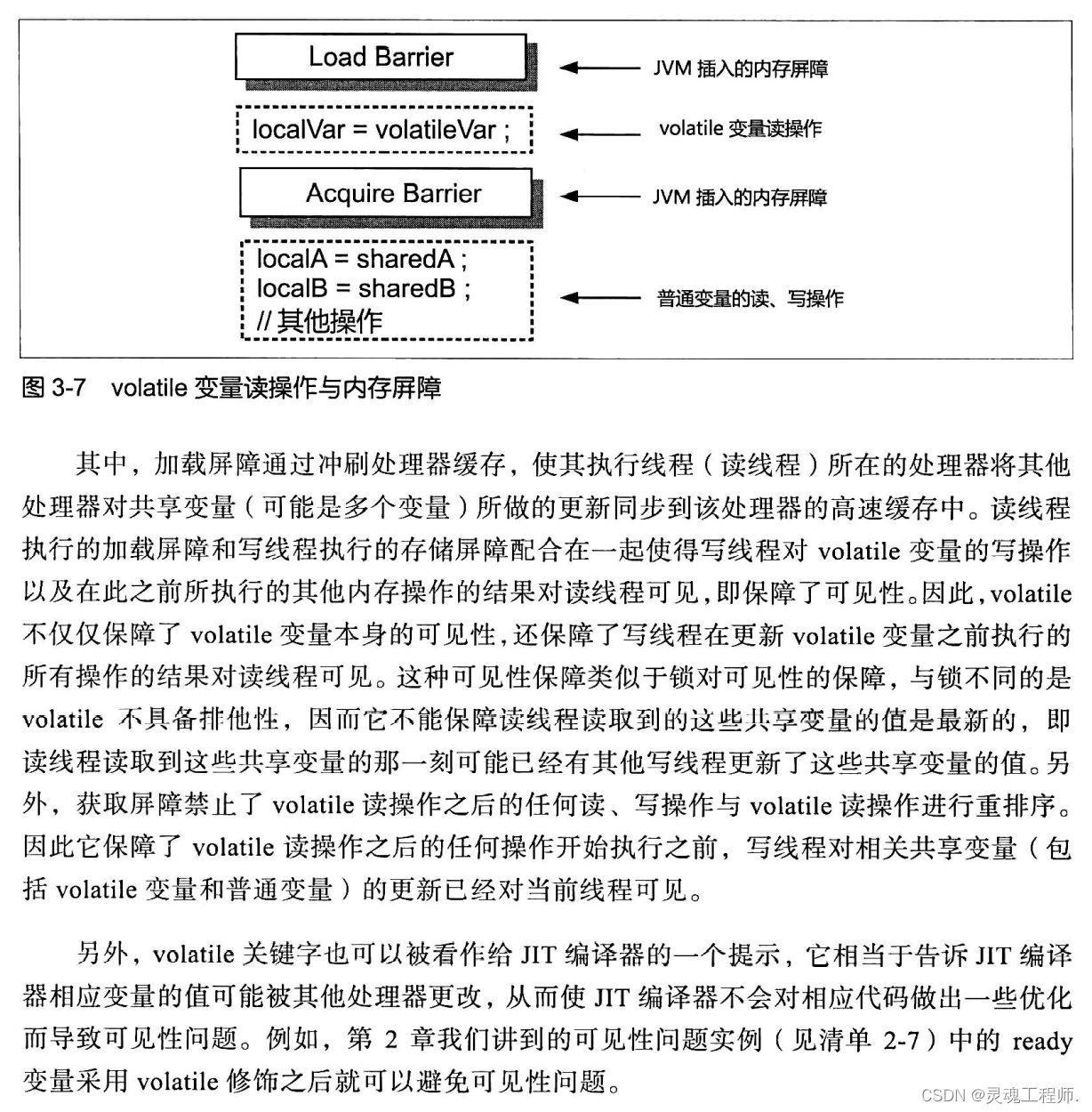
volatile在有序性保障方面也可以从禁止重排序的角度理解,即 volatile禁止了如下重排序:
- 写volatile变量操作与该操作之前的任何读、写操作不会被重排序
- 读volatile变量操作与该操作之后的任何读、写操作不会被重排序
volatile变量的开销
volatile变量的开销包括读变量和写变量两个方面。volatile变量的读、写操作都不会导致上下文切换,因此volatile的开销比锁要小。写一个volatile变量会使该操作以及该操作之前的任何写操作的结果对其他处理器是可同步的、因此 volatile变量写操作的成本介于普通变量的写操作和在临界区内进行的写操作之间。读取 volatile变量的成本也比在临界区中读取变量要低(没有锁的申请与释放以及上下文切换的开销),但是其成本可能比读取普通变量要高一些。这是因为volatile变量的值每次都需要从高速缓存或者主内存中读取,而无法被暂存在寄存器中,从而无法发挥访问的高效性。
volatile应用场景
volatile除了用于保障long/double型变量的读、写操作的原子性,其典型使用场景还包括以下几个方面:
-
场景一:使用volatile变量作为状态标志。在该场景中,应用程序的某个状态由一个线程设置,其他线程会读取该状态并以该状态作为其计算的依据(或者仅仅读取并输出这个状态值)。此时使用volatile变量作为同步机制的好处是一个线程能够“通知”另外一个线程某种事件(例如,网络连接断连之后重新连上)的发生,而这些线程又无须因此而使用锁,从而避免了锁的开销以及相关问题。
-
场景二:使用volatile保障可见性。在该场景中,多个线程共享一个可变状态变量,其中一个线程更新了该变量之后,其他线程在无须加锁的情况下也能够看到该更新。
-
场景三:使用volatile变量替代锁。volatile关键字并非锁的替代品,但是在一定的条件下它比锁更合适(性能开销小、代码简单)。多个线程共享一组可变状态变量的时候,通常我们需要使用锁来保障对这些变量的更新操作的原子性,以避免产生数据不一致问题。利用volatile变量写操作具有的原子性,我们可以把这一组可变状态变量封装成一个对象,那么对这些状态变量的更新操作就可以通过创建一个新的对象并将该对象引用赋值给相应的引用型变量来实现。在这个过程中,volatile保障了原子性和可见性,从而避免了锁的使用。

-
场景四:使用volatile 实现简易版读写锁。在该场景中,读写锁是通过混合使用锁和 volatile变量而实现的,其中锁用于保障共享变量写操作的原子性,volatile变量用于保障共享变量的可见性。因此,与 ReentrantReadWriteLock 所实现的读写锁不同的是,这种简易版读写锁仅涉及一个共享变量并且允许一个线程读取这个共享变量时其他线程可以更新该变量(这是因为读线程并没有加锁)。因此,这种读写锁允许读线程可以读取到共享变量的非最新值。该场景的一个典型例子是实现一个计数器,如清单3-7所示。

CAS无锁机制
CAS是英文单词Compare and Swap的缩写,翻译过来就是比较并替换。CAS机制中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B;CAS机制是乐观锁的典型实现。
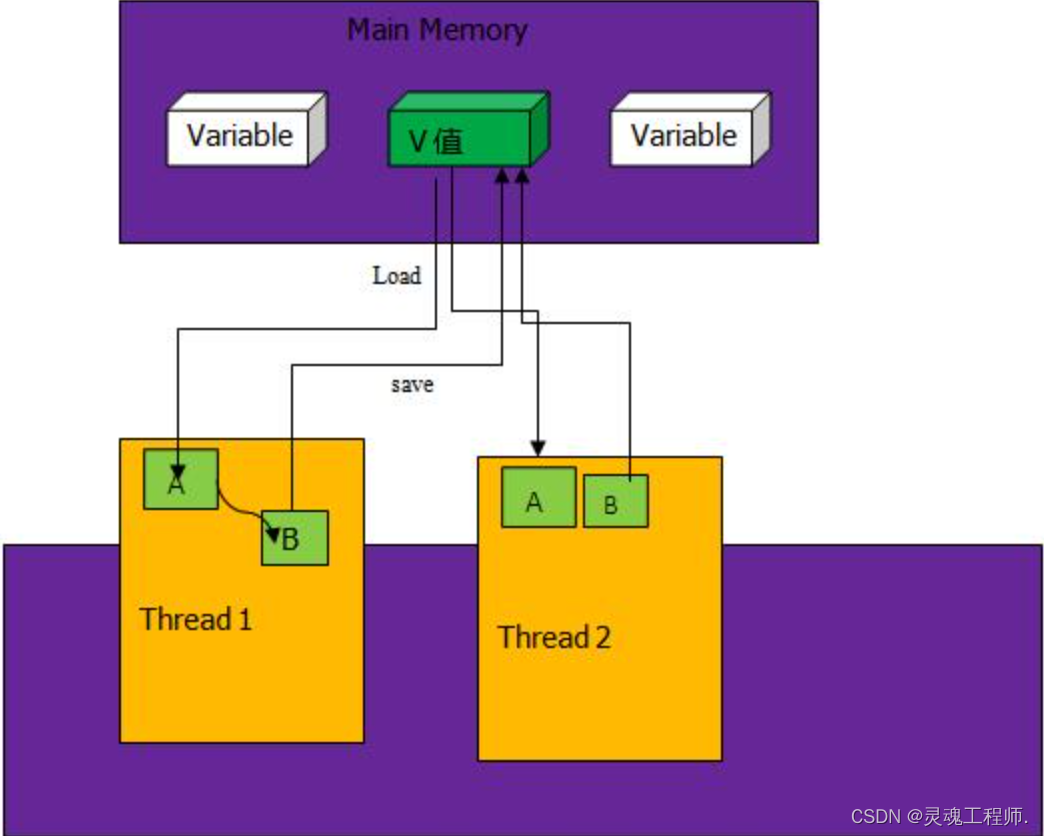
如上图中,主存中保存V值,线程中要使用V值要先从主存中读取V值到线程的工作内存A中,然后计算后变成B值,最后再把B值写回到内存V值中。多个线程共用V值都是如此操作。CAS的核心是在将B值写入到V之前要比较A值和V值是否相同,如果不相同证明此时V值已经被其他线程改变,则进行 自旋 ,重新将V值赋给A,并重新计算得到B,如果相同,则将B值赋给V。
值得注意的是CAS机制中的这步步骤是原子性的(从指令层面提供的原子操作),所以CAS机制可以解决多线程并发编程对共享变量读写的原子性问题。
CAS机制优点:
- 可以保证变量操作的原子性;
- 并发量不是很高的情况下,使用CAS机制比使用锁机制效率更高;
- 在线程对共享资源占用时间较短的情况下,使用CAS机制效率也会较高。
CAS机制缺点:
- ABA问题:CAS在操作的时候会检查变量的值是否被更改过,如果没有则更新值,但是带来一个问题,最开始的值是A,接着变成B,最后又变成了A。经过检查这个值确实没有修改过,因为最后的值还是A,但是实际上这个值确实已经被修改过了。为了解决这个问题,在每次进行操作的时候加上一个版本号,每次操作的就是两个值,一个版本号和某个值,A——>B——>A问题就变成了1A——>2B——>3A。在jdk中提供了AtomicStampedReference类解决ABA问题,用Pair这个内部类实现,包含两个属性,分别代表版本号和引用,在compareAndSet中先对当前引用进行检查,再对版本号标志进行检查,只有全部相等才更新值。
- 可能会消耗较高的CPU:看起来CAS比锁的效率高,从阻塞机制变成了非阻塞机制,减少了线程之间等待的时间。每个方法不能绝对的比另一个好,在线程之间竞争程度大的时候,如果使用CAS,每次都有很多的线程在竞争,也就是说CAS机制不能更新成功。这种情况下CAS机制会一直自旋,这样就会比较耗费CPU。因此可以看出,如果线程之间竞争程度小,使用CAS是一个很好的选择;但是如果竞争很大,使用锁可能是个更好的选择。在并发量非常高的环境中,如果仍然想通过原子类来更新的话,可以使用AtomicLong的替代类:LongAdder。
- 不能保证代码块的原子性:Java中的CAS机制只能保证共享变量操作的原子性,而不能保证代码块的原子性(这是时候就需要synchronied锁了,你会发现synchronied真的是万能的)。
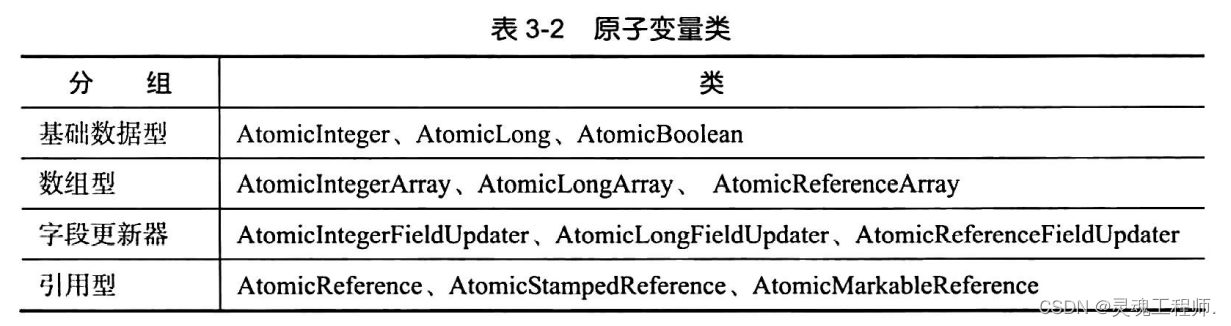
原子变量类
原子变量类( Atomics )是java.util.concurrent.atomic.包下基于CAS实现的能够保障对共享变量进行read-modify-write更新操作的原子性和可见性的一组工具类,原子变量类的内部实现通常借助volatile变量保障共享变量更新操作的原子性,因此它可以被看作增强型的volatile变量

乐观锁和悲观锁的比较
乐观锁和悲观锁是两种思想,用于解决并发场景下的数据竞争问题。
- 乐观锁:乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据:如果别人修改了数据则放弃操作,否则执行操作。
- 悲观锁:悲观锁在操作数据时比较悲观,认为别人会同时修改数据。因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。
乐观锁的实现方式主要有两种:CAS机制和版本号机制
悲观锁的实现方式是加锁,如Java的synchronized关键字(内部锁)、Lock接口的实现类(显式锁)、ReadWrite Lock的实现类(读写锁)
对象的发布与逸出
对象发布是指使对象能够被其作用域之外的线程访问,常见的对象发布形式包括以下几种:

安全发布就是指对象以一种线程安全的方式被发布。当一个对象的发布出现我们不期望的结果或者对象发布本身不是我们所期望的时候,我们就称该对象逸出。逸出应该是我们要尽量避免的,因为它不是一种安全发布。

实现对象的安全发布,通常可以依照以下顺序选择适用且开销最小的线程同步机制
- 使用static关键字修饰引用该对象的变量(static保障静态变量被发布前是初始化完毕的)
- 使用final关键字修饰引用该对象的变量(final保障被修饰的变量及其引用的对象在其被发布前是初始化完毕的)
- 使用volatile关键字修饰引用该对象的变量。
- 使用AtomicReference来引用该对象。对访问该对象的代码进行加锁。
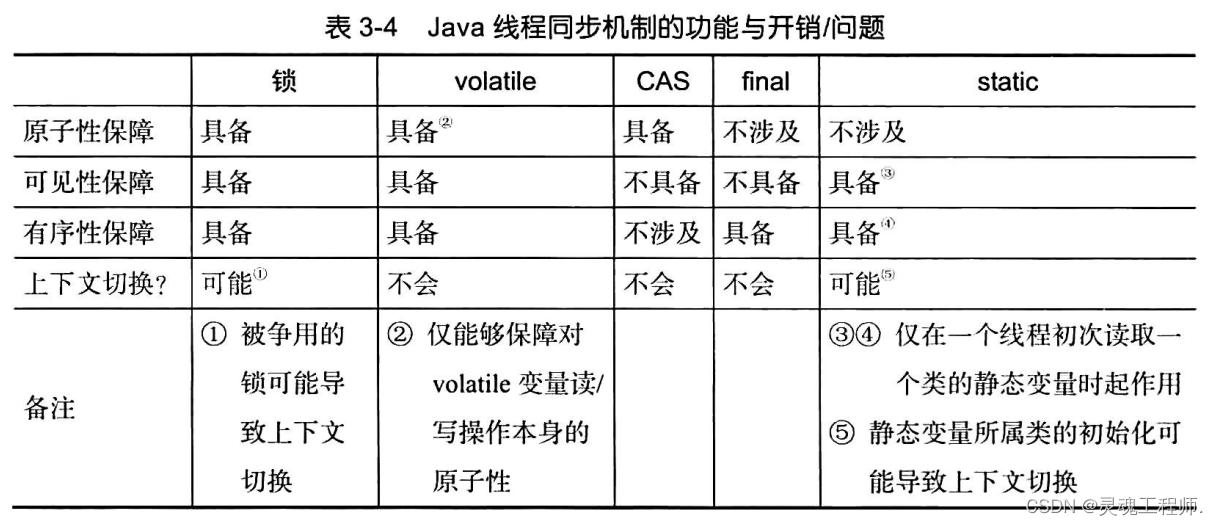
同步机制总结
Java同步机制的功能与开销/问题
Java线程同步机制结构图
线程通信机制
多线程世界中的线程并不是孤立的,一个线程往往需要其他线程的协作才能够完成其待执行的任务
wait和notify
一个线程因其执行目标动作所需的保护条件未满足而被暂停的过程就被称为等待(wait )。一个线程更新了系统的状态,使得其他线程所需的保护条件得以满足的时候唤醒那些被暂停的线程的过程就被称为通知(notify ) 。Object.wait() 的执行线程就被称为等待线程;Object.notify() 的执行线程就被称为通知线程。由于Object类是Java中任何对象的父类,因此使用Java中的任何对象都能够实现等待与通知。
由于一个线程只有在持有一个对象的内部锁(synchronized)的情况下才能够调用该对象的wait方法,因此Object.wait()调用总是放在相应对象所引导的临界区之中

由于一个线程只有在持有一个对象的内部锁(synchronized)的情况下才能够执行该对象的notify方法,因此 Object.notify()调用总是放在相应对象内部锁所引导的临界区之中。也正是由于Object.notify()要求其执行线程必须持有该方法所属对象的内部锁,因此Object.wait()在暂停其执行线程的同时必须释放相应的内部锁;否则通知线程无法获得相应的内部锁,也就无法执行相应对象的notify方法来通知等待线程

如果我们不从同步上下文中调用 wait() 或 notify() 方法, Java 将报错 IllegalMonitorStateException
由于同一个对象的同一个方法(wait()方法)可以被多个线程执行,因此一个对象可能存在多个等待线程。对象上的等待线程可以通过其他线程执行该对象的notify()方法来唤醒。Object.wait()会以原子操作的方式使其执行线程(当前线程)暂停并使该线程释放其持有的内部锁。当前线程被暂停的时候其对wait()方法的调用并未返回。其他线程在该线程所需的保护条件成立的时候执行相应的 notify方法,notify()可以唤醒该对象上的一个(任意的)等待线程,notifyAll()可以唤醒该对象上所有的等待线程。被唤醒的等待线程在其占用处理器继续运行的时候,需要再次申请对应的内部锁。被唤醒的线程在其再次持有对象对应的内部锁的情况下继续执行Object.wait()中剩余的指令,直到 wait方法返回


Object.wait()/notify()的内部实现




wait/notify 的开销及问题
-
过早唤醒:等待线程在其所需的保护条件并未成立的情况下被唤醒的现象就被称为过早唤醒(Wakeup too soon),过早唤醒使得那些本来无需被唤醒的等待线程也被唤醒了,从而造成资源浪费过早唤醒问题可以利用JDK1.5引入的java.util.concurrent.locks.Condition接口来解决
-
信号丢失:等待线程错过了一个本来“发送”给它的信号,因此被称为信号丢失(Missed Signal),信号丢失本质上是一种代码错误,而不是Java API自身的问题
-
欺骗性唤醒: 等待线程也可能在没有其他任何线程执行Object.notify() / notifyAll()的情况下被唤醒,这种现象被称为欺骗性唤醒(Spurious Wakeup )问题。欺骗性唤醒也会导致过早唤醒。欺骗性唤醒虽然在实践中出现的概率非常低,但是由于操作系统是允许这种现象产生的,因此Java平台同样也允许这种现象的存在。欺骗性唤醒是Java平台对操作系统妥协的一种结果。只要我们将对保护条件的判断和Object.wait()调用行放在一个循环语句之中,欺骗性唤醒就不会对我们造成实际的影响。
-
上下文切换:wait/notify的使用可能导致较多的上下文切换。

wait/notify 与 Thread.join()
Thread.join()可以使当前线程等待目标线程结束之后才继续运行。Thread.join()还有另外一个如下声明的版本:
public final void join (long millis) throws InterruptedException
join(long)允许我们指定一个超时时间。如果目标线程没有在指定的时间内终止,那么当前线程也会继续运行。join(long)实际上就是使用了wait/notify来实现的,源码如下:
public final synchronized void join(long millis) throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
join(long)是一个同步方法。它检测到目标线程未结束的时候会调用wait方法来暂停当前线程,直到目标线程已终止。这里,当前线程相当于等待线程,其所需的保护条件是“目标线程已终止”(Thread.isAlive()返回值为false )。Java 虚拟机会在目标线程的run方法运行结束后执行该线程(对象)的 notifyAll方法来通知所有的等待线程。可见这里的目标线程充当了同步对象的角色,而Java 虚拟机中notifyAll方法的执行线程则是通知线程。另外, join(long)正是按照清单所展示的实现等待超时控制的方法来使用wait(long)方法的
Thread.join()调用相当于Thread.join(0)调用
Condition接口
Condition接口可作为wait/notify 的替代品来实现等待/通知,它为解决过早唤醒问题提供了支持,并解决了Object.wait(long)不能区分其返回是否是由等待超时还是被其他线程唤醒而导致的问题。
Condition 接口定义的await方法、signal 方法和signalAll方法分别相当于Object.wait()、Object.notify() 和 Object.notifyAll()。

Condition 接口的使用方法与wait/notify的使用方法相似,如下代码模板所示:
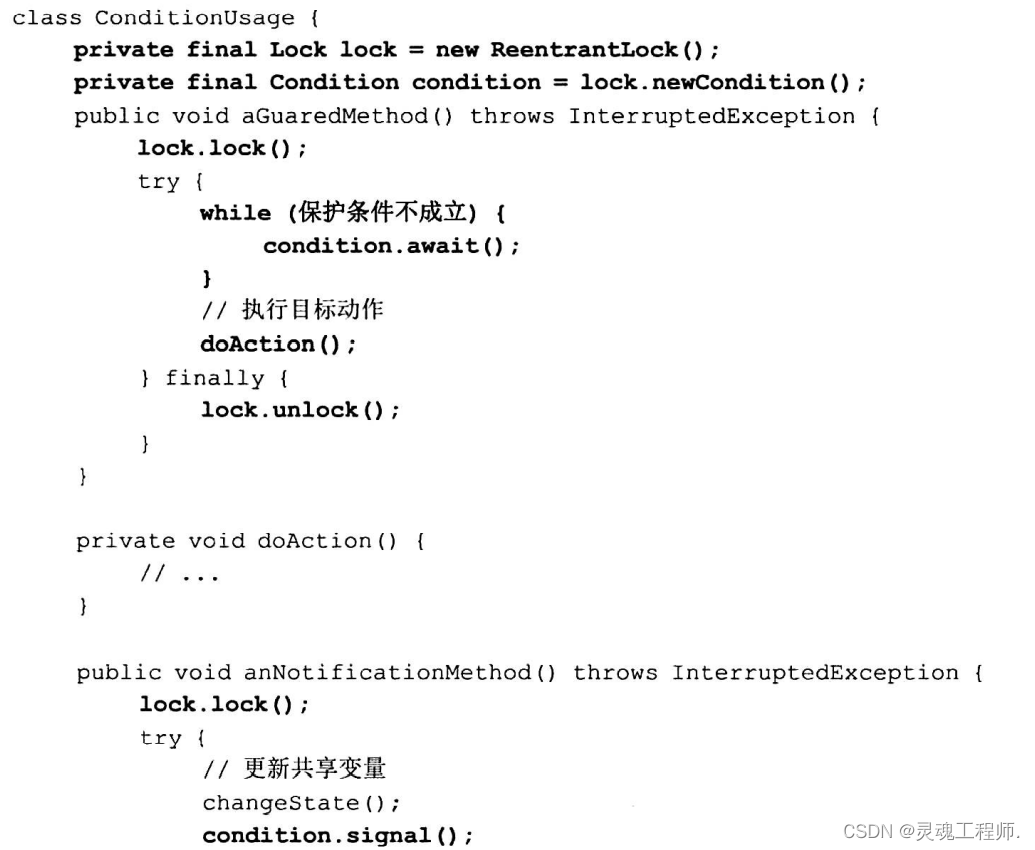

由于条件变量Condition对象实例可以有多个,所以我们可以使用不同的Conditon对象来使多个保护条件不同质的等待线程实现指定的等待和唤醒,从而避免了过早唤醒问题
Condition接口还解决了Object.wait(long)存在的问题——Object.wait(long)无法区分其返回是由于等待超时还是被通知的。Condition.awaitUntil(Date deadline)可以用于实现带超时时间限制的等待,并且该方法的返回值能够区分该方法调用是由于等待超时而返回还是由于其他线程执行了相应条件变量的 signal/signalAll 方法而返回,Condition.awaitUntil(Date)返回值true表示进行的等待尚未达到最后期限,即此时方法的返回是由于其他线程执行了相应条件变量的 signal/signalAll 方法,返回false则表示已超时等待
生产者与消费者示例
synchronized版本
package juc;
/**
* @author Arthus
*/
public class ProducerConsumer1 {
public static void main(String[] args) {
Person1 person = new Person1();
for (int i = 0; i < 6; i++) {
new Thread(() -> {
person.produce();
}, "producer").start();
new Thread(() -> {
person.consume();
}, "consumer").start();
}
}
}
class Person1 {
/**
* 产品数量
*/
int num = 0;
public synchronized void produce() {
while (num != 0) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num++;
this.notifyAll();
System.out.println("生产了商品,目前商品存余:" + num);
}
public synchronized void consume() {
while (num == 0) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num--;
this.notifyAll();
System.out.println("消费了商品,目前商品存余:" + num);
}
}
运行结果:
Lock版本
package juc;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author Arthus
*/
public class ProducerConsumer2 {
public static void main(String[] args) {
Person2 person = new Person2();
for (int i = 0; i < 6; i++) {
new Thread(() -> {
person.produce();
}, "producer").start();
new Thread(() -> {
person.consume();
}, "consumer").start();
}
}
}
class Person2 {
/**
* 产品数量
*/
private int num = 0;
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
public void produce() {
lock.lock();
try {
while (num != 0) {
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num++;
condition.signalAll();
System.out.println("生产了商品,目前商品存余:" + num);
} finally {
lock.unlock();
}
}
public void consume() {
lock.lock();
try {
while (num == 0) {
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num--;
condition.signalAll();
System.out.println("生产了商品,目前商品存余:" + num);
} finally {
lock.unlock();
}
}
}
运行结果:
CountDownLatch倒计时协调器
java.util.concurrent.CountDownLatch工具类可以用来实现一个(或者多个)线程等待其他线程完成一组特定的操作之后才继续运行。这组操作被称为先决操作
CountDownLatch实例化对象时可设置先决操作数,CountDownLatch主要有两个方法,当计数器的值大于0时,一个或多个线程调用await方法时,这些线程会阻塞(BLOCKED),其它线程调用countDown方法会将计数器减1(调用countDown方法的线程不会阻塞),当计数器的值变为0时,因await方法阻塞的线程会被唤醒,继续执行

CountDownLatch 的使用是一次性的:一个CountDownLatch实例只能够实现一次等待和唤醒。可见,CountDownLatch内部封装了对“全部先决操作已执行完毕”(计数器值为0)这个保护条件的等待与通知的逻辑,因此客户端代码在使用CountDownLatch实现等待/通知的时候调用await/countDown方法都无须加锁
CyclicBarrier栅栏
有时候多个线程可能需要相互等待对方执行到代码中的某个地方(集合点),这时这些线程才能够继续执行。这种等待类似于大家相约去爬山的情形:大家事先约定好时间和集合点,先到的人必须在集合点等待其他未到的人,只有所有参与人员到齐之后大家才能够出发去登山。JDK 1.5开始引入了一个类java.util.concurrent.CyclicBarrier,该类可以用来实现这种等待。CyclicBarrier类的类名中虽然包含Barrier 这个里间,但是它和我们前面讲的内存屏障没有直接的关联。类名中 Cyclic表示CyclicBarrier实例是可以重复使用的。

CyclicBarrier 的构造方法第一个参数是目标障碍数,每次执行 CyclicBarrier.wait()方法一次障碍数会加一,这样便可以知道哪个线程是最后的

由于CyclicBarrier内部实现是基于条件变量的,因此CyclicBarrier的开销与条件变量的开销相似,其主要开销在可能产生的上下文切换
CyclicBarrier 的应用场景
CyclicBarrier 的典型应用场景包括以下几个,它们都可以在上述例子中找到影子

CyclicBarrier往往被滥用,其表现是在没有必要使用CyclicBarrier的情况下使用了CyclicBarrier。这种滥用的一个典型例子是利用CyclicBarrier 的构造器参数barrierAction来指定一个任务,以实现一种等待线程结束的效果: barrierAction中的任务只有在目标线程结束后才能够被执行。事实上,这种情形下我们完全可以使用更加对口的Thread.join()或者CountDownLatch来实现。因此,如果代码对CyclicBarrier.await()调用不是放在一个循环之中,并且使用CyclicBarrier 的目的也不是为了模拟高并发操作,那么此时对CyclicBarrier的使用可能是一种滥用。
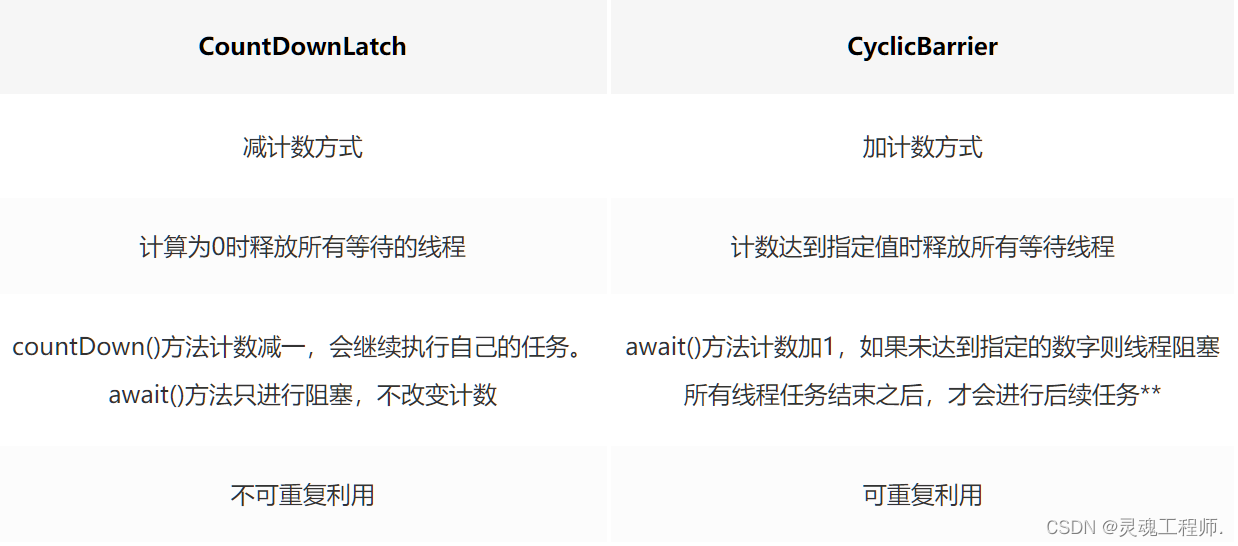
CyclicBarrier 和 CountDownLatch 比较
ThreadLocal线程封闭
数据都被封闭在各自的线程之中,就不需要同步,这种通过将数据封闭在线程中而避免使用同步的技术称为线程封闭,ThreadLocal是线程封闭其中一种体现,它是一个线程级别变量,每个线程都有一个 ThreadLocal 就是每个线程都拥有了自己独立的一个变量,竞态条件被彻底消除了,在并发模式下是绝对安全的变量
可以通过 ThreadLocal<T> value = new ThreadLocal<T>();来使用。
//ThreadLocal代码示例
public class ThreadLocalDemo {
/**
* ThreadLocal变量,每个线程都有一个副本,互不干扰
*/
public static final ThreadLocal<String> THREAD_LOCAL = new ThreadLocal<>();
public static void main(String[] args) throws Exception {
new ThreadLocalDemo().threadLocalTest();
}
public void threadLocalTest() throws Exception {
// 主线程设置值
THREAD_LOCAL.set("wupx");
String v = THREAD_LOCAL.get();
System.out.println("Thread-0线程执行之前," + Thread.currentThread().getName() + "线程取到的值:" + v);
new Thread(new Runnable() {
@Override
public void run() {
String v = THREAD_LOCAL.get();
System.out.println(Thread.currentThread().getName() + "线程取到的值:" + v);
// 设置 threadLocal
THREAD_LOCAL.set("huxy");
v = THREAD_LOCAL.get();
System.out.println("重新设置之后," + Thread.currentThread().getName() + "线程取到的值为:" + v);
System.out.println(Thread.currentThread().getName() + "线程执行结束");
}
}).start();
// 等待所有线程执行结束
Thread.sleep(3000L);
v = THREAD_LOCAL.get();
System.out.println("Thread-0线程执行之后," + Thread.currentThread().getName() + "线程取到的值:" + v);
}
}
运行结果:

结论:多个线程对同一ThreadLocal对象进行 set 操作,但是每个线程get获取的值都还是各个线程对应set 的值
ThreadLocalMap
ThreadLocal还有一个重要的属性 ThreadLocalMap,ThreadLocalMap 是 ThreadLocal 的静态内部类,当一个线程有多个 ThreadLocal 时,需要一个容器来管理多个 ThreadLocal,ThreadLocalMap 的作用就是管理线程中多个 ThreadLocal,源码如下:
static class ThreadLocalMap {
/**
* 键值对实体的存储结构
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
// 当前线程关联的 value,这个 value 并没有用弱引用追踪
Object value;
/**
* 构造键值对
*
* @param k k 作 key,作为 key 的 ThreadLocal 会被包装为一个弱引用
* @param v v 作 value
*/
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// 初始容量,必须为 2 的幂
private static final int INITIAL_CAPACITY = 16;
// 存储 ThreadLocal 的键值对实体数组,长度必须为 2 的幂
private Entry[] table;
// ThreadLocalMap 元素数量
private int size = 0;
// 扩容的阈值,默认是数组大小的三分之二
private int threshold;
}
从源码中看到 ThreadLocalMap 其实就是一个简单的 Map 结构,底层是数组,有初始化大小,也有扩容阈值大小,数组的元素是 Entry,Entry 的 key 就是 ThreadLocal 的引用,value 是 ThreadLocal 的值。ThreadLocalMap 解决 hash 冲突的方式采用的是线性探测法,如果发生冲突会继续寻找下一个空的位置。
ThreadLocal内存泄漏
这样的就有可能会发生内存泄漏的问题,下面让我们进行分析:

那么如何避免内存泄漏呢?
在使用完 ThreadLocal 变量后,需要我们手动 remove 掉,防止 ThreadLocalMap 中 Entry 一直保持对 value 的强引用,导致 value 不能被回收,其中 remove 源码如下所示:
/**
* 清理当前 ThreadLocal 对象关联的键值对
*/
public void remove() {
// 返回当前线程持有的 map
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null) {
// 从 map 中清理当前 ThreadLocal 对象关联的键值对
m.remove(this);
}
}
remove 方法是先获取到当前线程的 ThreadLocalMap,并且调用了它的 remove 方法,从 map 中清理当前 ThreadLocal 对象关联的键值对,这样 value 就可以被 GC 回收了
那么 ThreadLocal 是如何实现线程隔离的呢?
ThreadLocal的set方法
set方法源码如下:
/**
* 为当前 ThreadLocal 对象关联 value 值
*
* @param value 要存储在此线程的线程副本的值
*/
public void set(T value) {
// 返回当前ThreadLocal所在的线程
Thread t = Thread.currentThread();
// 返回当前线程持有的map
ThreadLocalMap map = getMap(t);
if (map != null) {
// 如果 ThreadLocalMap 不为空,则直接存储<ThreadLocal, T>键值对
map.set(this, value);
} else {
// 否则,需要为当前线程初始化 ThreadLocalMap,并存储键值对 <this, firstValue>
createMap(t, value);
}
}

其中 map 就是我们上面讲到的 ThreadLocalMap,可以看到它是通过当前线程对象获取到的 ThreadLocalMap,接下来我们看 getMap方法的源代码:
/**
* 返回当前线程 thread 持有的 ThreadLocalMap
*
* @param t 当前线程
* @return ThreadLocalMap
*/
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
getMap 方法的作用主要是获取当前线程内的 ThreadLocalMap 对象,原来这个 ThreadLocalMap 是线程的一个属性,下面让我们看看 Thread 中的相关代码:
/**
* ThreadLocal 的 ThreadLocalMap 是线程的一个属性,所以在多线程环境下 threadLocals 是线程安全的
*/
ThreadLocal.ThreadLocalMap threadLocals = null;
可以看出每个线程都有 ThreadLocalMap 对象,被命名为 threadLocals,默认为 null,所以每个线程的 ThreadLocals 都是隔离独享的。
调用 ThreadLocalMap.set() 时,会把当前 threadLocal 对象作为 key,想要保存的对象作为 value,存入 map。
其中 ThreadLocalMap.set() 的源码如下:
/**
* 在 map 中存储键值对<key, value>
*
* @param key threadLocal
* @param value 要设置的 value 值
*/
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 计算 key 在数组中的下标
int i = key.threadLocalHashCode & (len - 1);
// 遍历一段连续的元素,以查找匹配的 ThreadLocal 对象
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
// 获取该哈希值处的ThreadLocal对象
ThreadLocal<?> k = e.get();
// 键值ThreadLocal匹配,直接更改map中的value
if (k == key) {
e.value = value;
return;
}
// 若 key 是 null,说明 ThreadLocal 被清理了,直接替换掉
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 直到遇见了空槽也没找到匹配的ThreadLocal对象,那么在此空槽处安排ThreadLocal对象和缓存的value
tab[i] = new Entry(key, value);
int sz = ++size;
// 如果没有元素被清理,那么就要检查当前元素数量是否超过了容量阙值(数组大小的三分之二),以便决定是否扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold) {
// 扩容的过程也是对所有的 key 重新哈希的过程
rehash();
}
}
ThreadLocal 的 get 方法
get方法源码如下:
/**
* 返回当前 ThreadLocal 对象关联的值
*
* @return
*/
public T get() {
// 返回当前 ThreadLocal 所在的线程
Thread t = Thread.currentThread();
// 从线程中拿到 ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
// 从 map 中拿到 entry
ThreadLocalMap.Entry e = map.getEntry(this);
// 如果不为空,读取当前 ThreadLocal 中保存的值
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T) e.value;
return result;
}
}
// 若 map 为空,则对当前线程的 ThreadLocal 进行初始化,最后返回当前的 ThreadLocal 对象关联的初值,即 value
return setInitialValue();
}

其中每个 Thread 的 ThreadLocalMap 以 threadLocal 作为 key,保存自己线程的 value 副本,也就是保存在每个线程中,并没有保存在 ThreadLocal 对象中。
其中 ThreadLocalMap.getEntry() 方法的源码如下:
/**
* 返回 key 关联的键值对实体
*
* @param key threadLocal
* @return
*/
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
// 若 e 不为空,并且 e 的 ThreadLocal 的内存地址和 key 相同,直接返回
if (e != null && e.get() == key) {
return e;
} else {
// 从 i 开始向后遍历找到键值对实体
return getEntryAfterMiss(key, i, e);
}
}
ThreadLocalMap 的 resize 方法
当 ThreadLocalMap 中的 ThreadLocal 的个数超过容量阈值时,ThreadLocalMap 就要开始扩容了,我们一起来看下 resize 的源代码:
/**
* 扩容,重新计算索引,标记垃圾值,方便 GC 回收
*/
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
// 新建一个数组,按照2倍长度扩容
Entry[] newTab = new Entry[newLen];
int count = 0;
// 将旧数组的值拷贝到新数组上
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
// 若有垃圾值,则标记清理该元素的引用,以便GC回收
if (k == null) {
e.value = null;
} else {
// 计算 ThreadLocal 在新数组中的位置
int h = k.threadLocalHashCode & (newLen - 1);
// 如果发生冲突,使用线性探测往后寻找合适的位置
while (newTab[h] != null) {
h = nextIndex(h, newLen);
}
newTab[h] = e;
count++;
}
}
}
// 设置新的扩容阈值,为数组长度的三分之二
setThreshold(newLen);
size = count;
table = newTab;
}
resize 方法主要是进行扩容,同时会将垃圾值标记方便 GC 回收,扩容后数组大小是原来数组的两倍
ThreadLocal应用场景
ThreadLocal 的特性也导致了应用场景比较广泛,主要的应用场景如下:
- 线程间数据隔离,各线程的 ThreadLocal 互不影响
- 方便同一个线程使用某一对象,避免不必要的参数传递
- 全链路追踪中的 traceId 或者流程引擎中上下文的传递一般采用 ThreadLocal
- Spring 事务管理器采用了 ThreadLocal
- Spring MVC 的 RequestContextHolder 的实现使用了 ThreadLocal
阻塞队列
阻塞队列(BlockingQueue) 是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素

阻塞队列提供了四种处理方法:
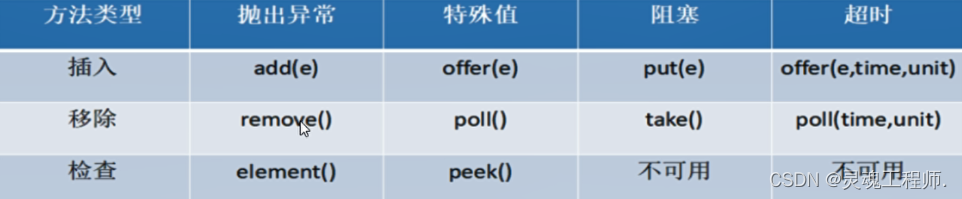
- 抛出异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出IllegalStateException("Queue full")异常。当队列为空时,从队列里获取元素时会抛出NoSuchElementException异常 。
- 返回特殊值:插入方法会返回是否成功,成功则返回true。移除方法,则是从队列里拿出一个元素,如果没有则返回null
- 一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里take元素,队列也会阻塞消费者线程,直到队列可用。
- 超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
七种阻塞队列:
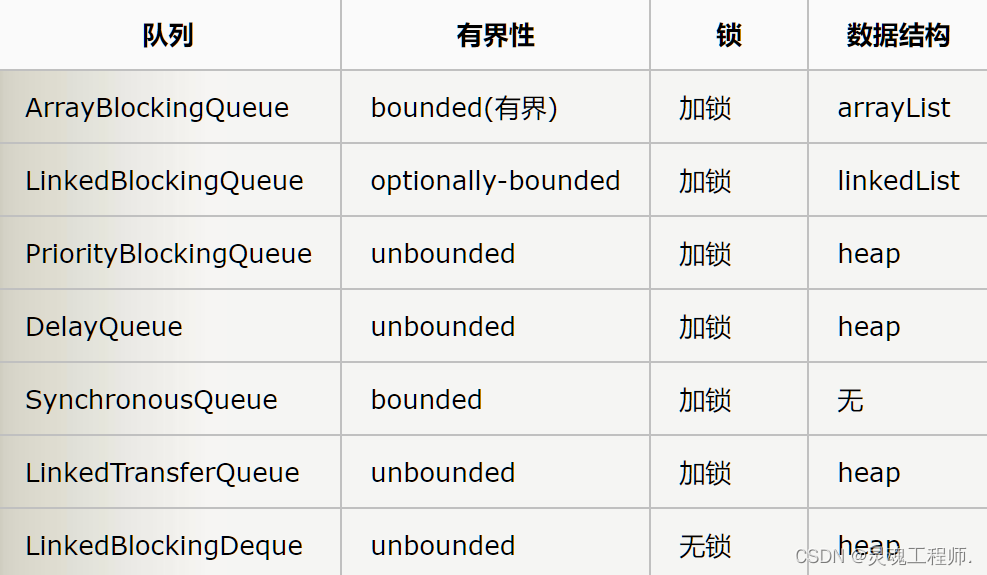

- ArrayBlockingQueue:是一个用数组实现的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。支持公平锁和非公平锁。
- LinkedBlockingQueue:一个由链表结构组成的有界队列,此队列的长度为Integer.MAX_VALUE。此队列按照先进先出的顺序进行排序。
- PriorityBlockingQueue: 一个支持线程优先级排序的无界队列,默认自然序进行排序,也可以自定义实现compareTo()方法来指定元素排序规则,不能保证同优先级元素的顺序。
- DelayQueue: 一个实现PriorityBlockingQueue实现延迟获取的无界队列,在创建元素时,可以指定多久才能从队列中获取当前元素。只有延时期满后才能从队列中获取元素。(DelayQueue可以运用在以下应用场景:1.缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。2.定时任务调度。使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的。)
- SynchronousQueue: 一个不存储元素的阻塞队列,每一个put操作必须等待take操作,否则不能添加元素。支持公平锁和非公平锁。SynchronousQueue的一个使用场景是在线程池里。Executors.newCachedThreadPool()就使用了SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收。
- LinkedTransferQueue: 一个由链表结构组成的无界阻塞队列,相当于其它队列,LinkedTransferQueue队列多了transfer和tryTransfer方法。
- LinkedBlockingDeque: 一个由链表结构组成的双向阻塞队列。队列头部和尾部都可以添加和移除元素,多线程并发时,可以将锁的竞争最多降到一半。




阻塞队列也支持非阻塞式操作(即不会导致执行线程被暂停)。比如,BlockingQueue接口定义的 offer(E)和 poll()分别相当于 put(E)和 take()的非阻塞版。非阻塞式方法通常用特殊的返回值表示操作结果: offer(E)的返回值 false表示入队列失败(队列已满).poll()返回null表示队列为空
管道流
管道流用来实现线程间的直接输入和输出,分为管道输入流(PipeOutputStream) 和 管道输出流(PipeInputStream);这里我们只分析字节管道流,字符管道流原理跟字节管道流一样,只不过底层一个是 byte 数组存储 一个是 char 数组存储的,管道流被号称是难使用的流,被使用的频率比较低

管道输入与输出实际上使用的是一个循环缓冲数来实现的。输入流PipedInputStream从这个循环缓冲数组中读数据,输出流PipedOutputStream往这个循环缓冲数组中写入数据。当这个缓冲数组已满的时候,输出流PipedOutputStream所在的线程将阻塞;当这个缓冲数组为空的时候,输入流PipedInputStream所在的线程将阻塞
在使用管道流之前,需要注意以下要点:
- 管道流仅用于多个线程之间传递信息,若用在同一个线程中可能会造成死锁
- 管道流的输入输出是成对的,一个输出流只能对应一个输入流,使用构造函数或者 connect 函数进行连接
- 一对管道流包含一个缓冲区,其默认值为1024个字节,若要改变缓冲区大小,可 以使用带有参数的构造器
- 管道的读写操作是互相阻塞的,当缓冲区为空时,读操作阻塞。当缓冲区满时,写操作阻塞
- 管道依附于线程,因此若线程结束,则虽然管道流对象还在,仍然会报错“read dead end”
- 管道流的读取方法与普通流不同,只有输出流正确 close 时,输出流才能读到1值。
管道流实现生产者-消费者Demo示例
生产者:
/**
* 我们以数字替代产品 生产者每5秒提供5个产品,放入管道
*/
public class MyProducer extends Thread {
private PipedOutputStream outputStream;
public MyProducer(PipedOutputStream outputStream) {
this.outputStream = outputStream;
}
@Override
public void run() {
while (true) {
try {
for (int i = 0; i < 5; i++) {
outputStream.write(i);
}
} catch (IOException e) {
e.printStackTrace();
}
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
消费者:
/**
* 消费者每0.5秒从管道中取1件产品,并打印剩余产品数量,并打印产品信息(以数字替代)
*/
public class MyConsumer extends Thread {
private PipedInputStream inputStream;
public MyConsumer(PipedInputStream inputStream) {
this.inputStream = inputStream;
}
@Override
public void run() {
while (true) {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
int count = inputStream.available();
if (count > 0) {
System.out.println("rest product count: " + count);
System.out.println("get product: " + inputStream.read());
}
} catch (IOException e1) {
e1.printStackTrace();
}
}
}
}
测试实例:
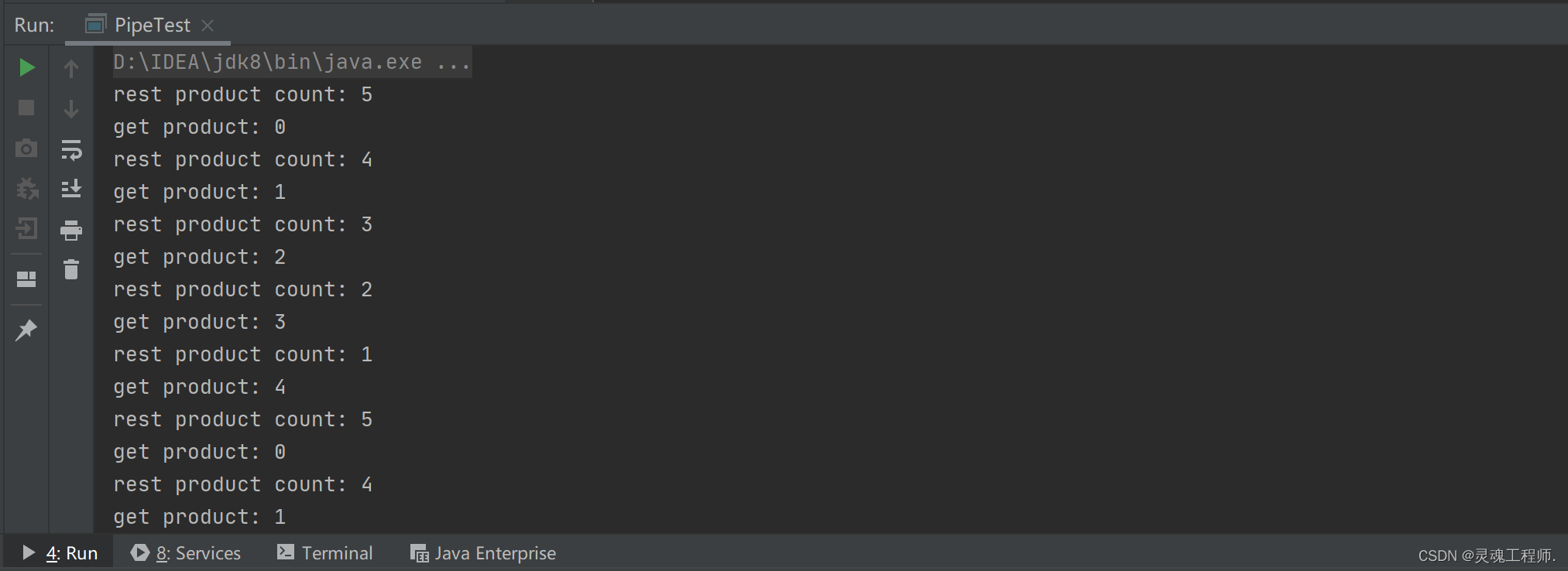
public class PipeTest {
public static void main(String[] args) {
PipedOutputStream pos = new PipedOutputStream();
PipedInputStream pis = new PipedInputStream();
try {
pis.connect(pos);
} catch (IOException e) {
e.printStackTrace();
}
new MyProducer(pos).start();
new MyConsumer(pis).start();
}
}
运行结果:
Java内存模型
编程语言级别的内存模型,这是为了能够使编程语言也能拥有一个一致性的内存视图,于是在硬件内存模型上还存着为编程语言设计的内存模型比如Java内存模型;Java内存模型屏蔽掉了各种硬件和操作系统的内存访问差异,实现了让Java内存模型能够在各种硬件平台下都能够按照预期的方式来运行
计算机硬件内存模型如下:
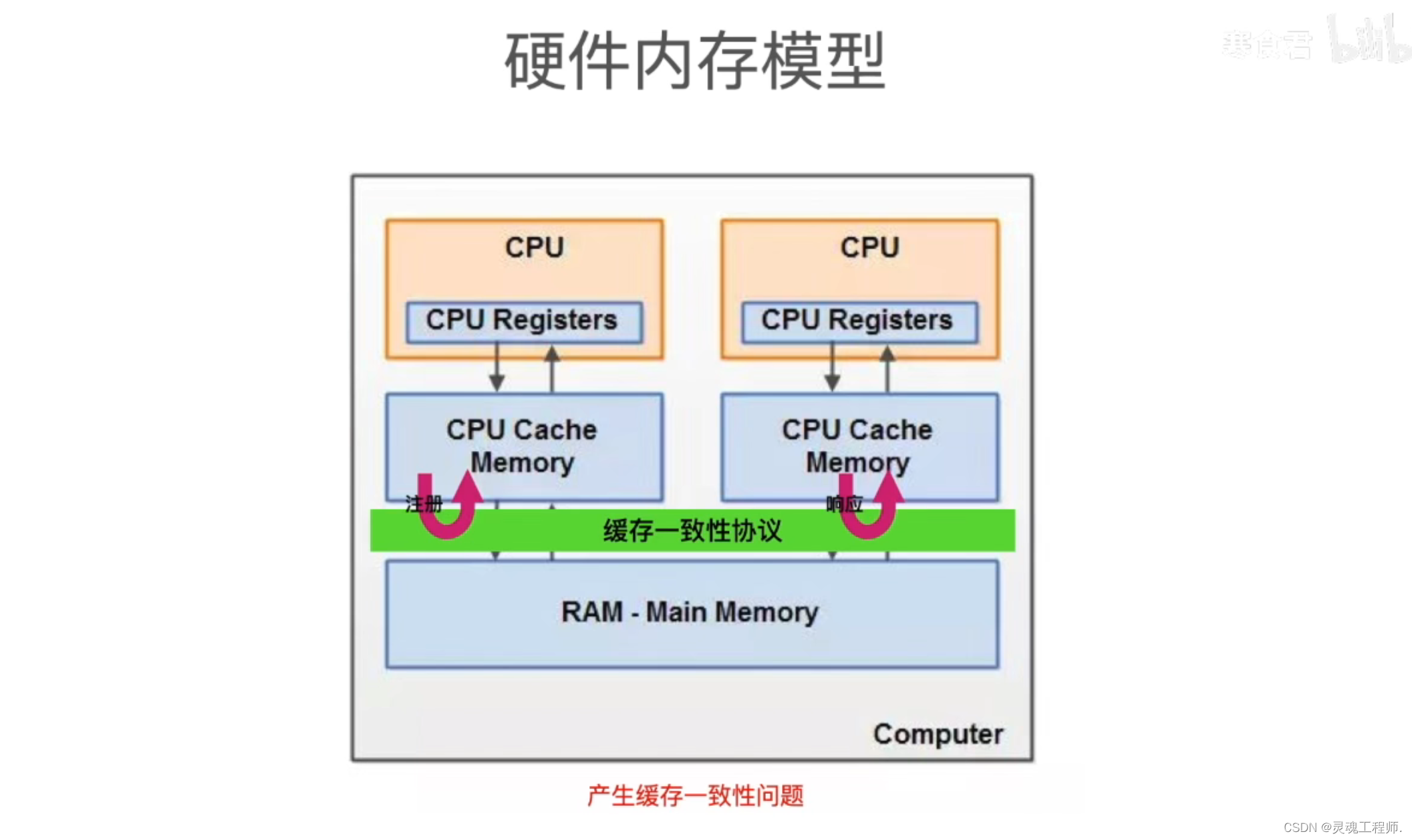
缓存一致性问题:比如两个CPU同时更新同一个共享数据的情况,CPU-1从主存读取数据S到CPU-1的寄存器中进行修改,修改后CPU-1此时还未将数据S写回到主存,而CPU-2并不知道CPU-1已经对数据S进行了修改,此时CPU-2又从主存中读取未被修改过的数据S进行修改,这就出现了数据不同步的问题,所以需要缓存一致性协议来保证数据同步
若采用等待CPU把数据写回主存的方式进行数据同步势必会造成CPU资源极大的浪费,于是便采取异步的方式进行优化,比如CPU-2要读取数据S时,发现数据S正在被CPU-1进行修改,那么CPU-2便通过高速缓存注册一个读取数据S的消息,自己先去做其他事情,CPU-1写回数据S之后通过高速缓存响应了这个注册消息,此时CPU-2发现消息被响应了之后再去读取数据S,这样采用异步的方式进行数据同步能很大程度上提升效率,但这对于CPU-2来说程序看上去就不是顺序执行的了,可能会出现先运行后面的指令再回头去运行前面的指令,这种行为就体现出了一种指令重排序,虽然指令被重排,但CPU依然需要保证程序在单线程中执行结果的正确性,就是说无论指令如何重排,在单线程中最后的执行结果一定要和顺序执行的结果一样,具体如何实现不是本文重点
缓存同步:CPU处理器可以通过缓存一致性协议(Cache Coherence Protocol) 来读取其他处理器的高速缓存中的数据,并将读到的数据更新到该处理器的高速缓存中。这种一个处理器从其自身处理器缓存以外的其他存储部件中读取数据并将其反映(更新)到该处理器的高速缓存的过程,我们称之为缓存同步。相应地,我们称这些存储部件的内容是可同步的,这些存储部件包括处理器的高速缓存、主内存。缓存同步使得一个处理器(上运行的线程)可以读取到另外一个处理器(上运行的线程)对共享变量所做的更新,即保障了可见性。因此,为了保障可见性,我们必须使一个处理器对共享变量所做的更新最终被写入该处理器的高速缓存或者主内存中(而不是始终停留在其写缓冲器中),这个过程被称为冲刷处理器缓存。并且,一个处理器在读取共享变量的时候,如果其他处理器在此之前已经更新了该变量,那么该处理器必须从其他处理器的高速缓存或者主内存中对相应的变量进行缓存同步。这个过程被称为刷新处理器缓存。因此,可见性的保障是通过使更新共享变量的处理器执行冲刷处理器缓存的动作,并使读取共享变量的处理器执行刷新处理器缓存的动作来实现的。
Java内存模型如下: (下面对原子性、可见性、有序性的讲解都是基于Java内存模型展开)
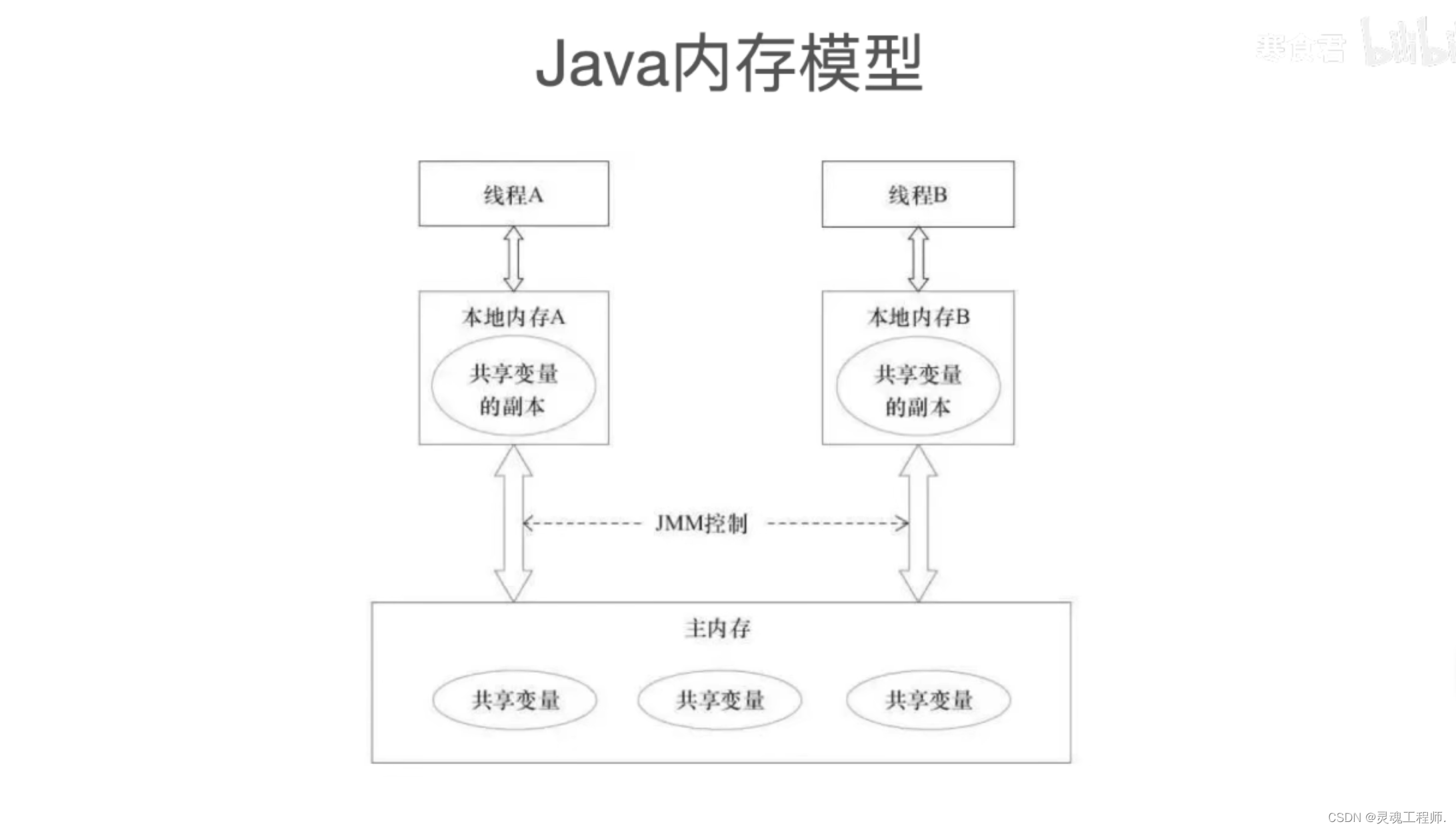
每个工作线程都拥有独占的本地内存,本地内存中存储的是私有变量以及共享变量的副本,并且使用一定机制来控制本地内存和主存之间的读写数据时的同步问题,更加具体点,我们将工作线程和本地内存具象为Thread Stack,将主存具象为Heap,Thread Stack中有两种类型变量,原始类型变量和对象类型变量
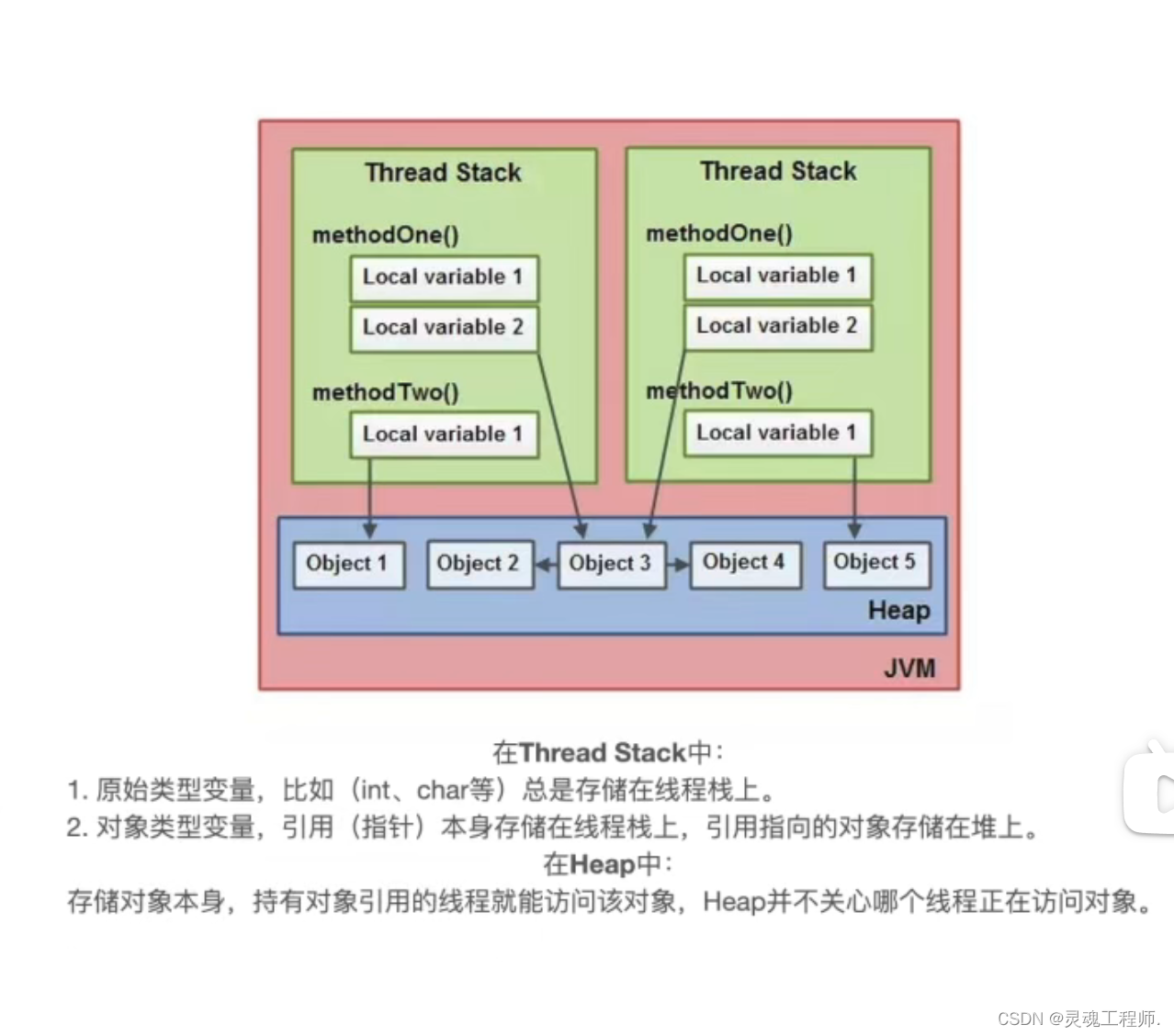
可以这么理解:Java内存模型中的Thread Stack和Heap都是对物理内存的一种抽象,这样开发者只需要关心自己写的程序使用到了Thread Stack/Heap,而不需要关心底层寄存器、CPU缓存、主存,可以猜测,线程在工作的时候大部分情况都在读写本地内存,也就是说本地内存对速度的要求更高,那么它可能大部分都是使用寄存器和CPU缓存来实现的,而Heap中需要存储大量的对象需要更大的容量,那么它可能大部分都是使用主存来实现的,这是Java内存模型和硬件内存模型之间模糊的内容映射关系
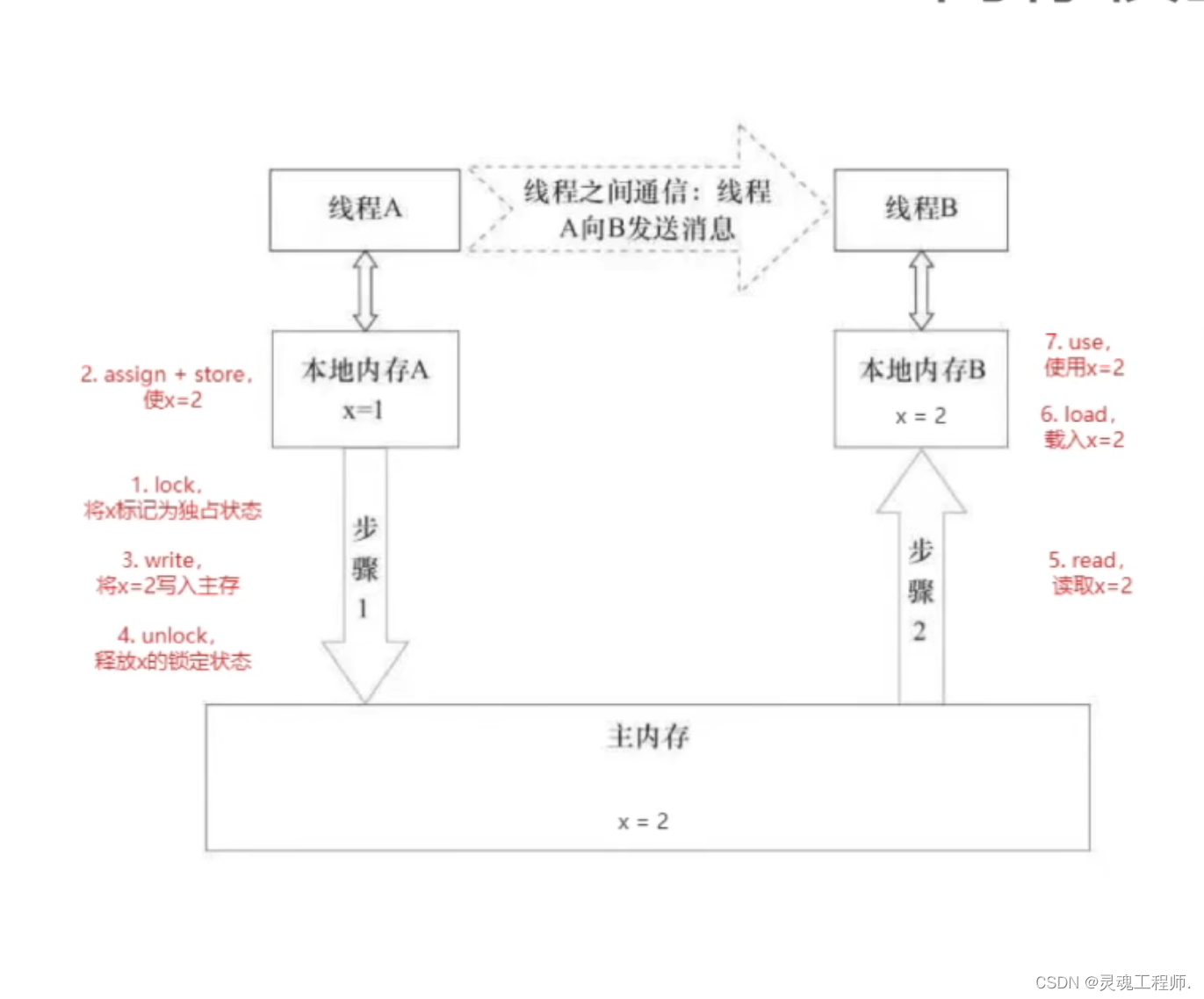
Java内存模型需要设计一些机制来实现主存与工作内存之间的数据传输与同步,这种数据的传递正是线程之间的通信方式,主存和工作内存之间简介通过这八个指令来实现数据的读写与同步,按照作用域分为两类:

例:线程之间通信比较理想的状态
线程通信中可能出现的问题:
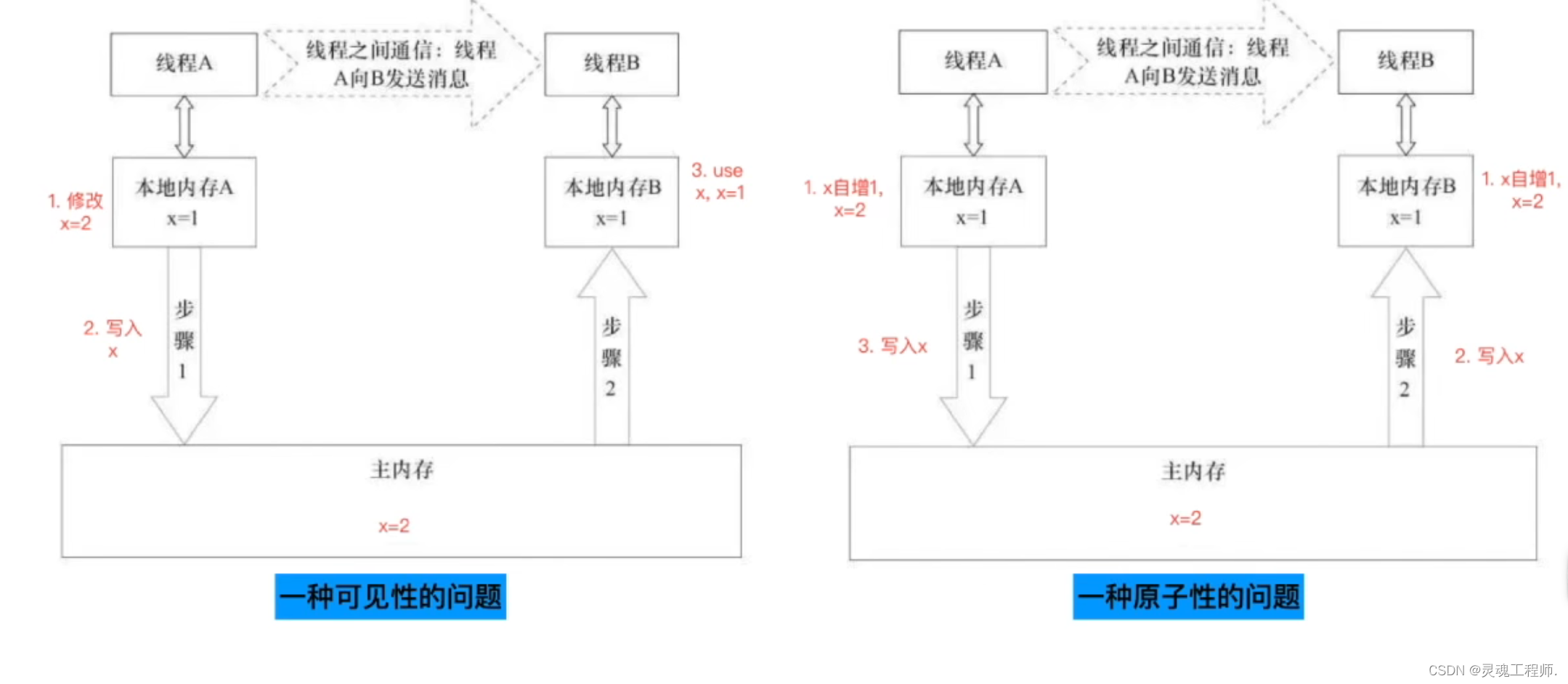

volatile关键字的底层保证了若一个被volatile修饰的变量被修改,那么总是会主动写入主存,若要读取一个volatile变量,那么总是从主存中读取,这样的话相当于操作volatile变量都是直接读写主存,这样可以保证变量操作的可见性
synchronized关键字在同步代码块中monitor的基础上读写变量时将会隐式的执行上文提到的内存lock指令,并清空工作内存中该变量的值,需要使用该变量时必须从主存中读取,同理也会隐式的执行unlock指令,将修改过的变量刷新回主存,这样同样能够保证可见性

volatile关键字禁止当前变量与之前的代码语句进行重排序,可以这么理解,当程序执行到volatile变量的读写时(还未执行),之前的代码语句的执行结果时满足可见性的,当执行volatile变量的读写时,上文讲过变量将会与主存进行同步,所以volatile变量保证了可见性,以可见性为基础,volatile变量禁止与之前的代码语句进行重排序这就保证了变量的有序性
synchronized关键字使得代码块不可分割,这时内部不论指令如何重排序,外部都只能读取到代码块执行完之后最终结果,这样便在保证变量可见性的基础上保证有序性
多线程性能调校
Java虚拟机对内部锁的实现进行了一些优化,主要包括锁消除(Lock Elision)、锁粗化(Lock Coarsening)、偏向锁(Biased Locking)以及适应性锁( Adaptive Locking )。这些优化仅在Java虚拟机 server模式下起作用
-
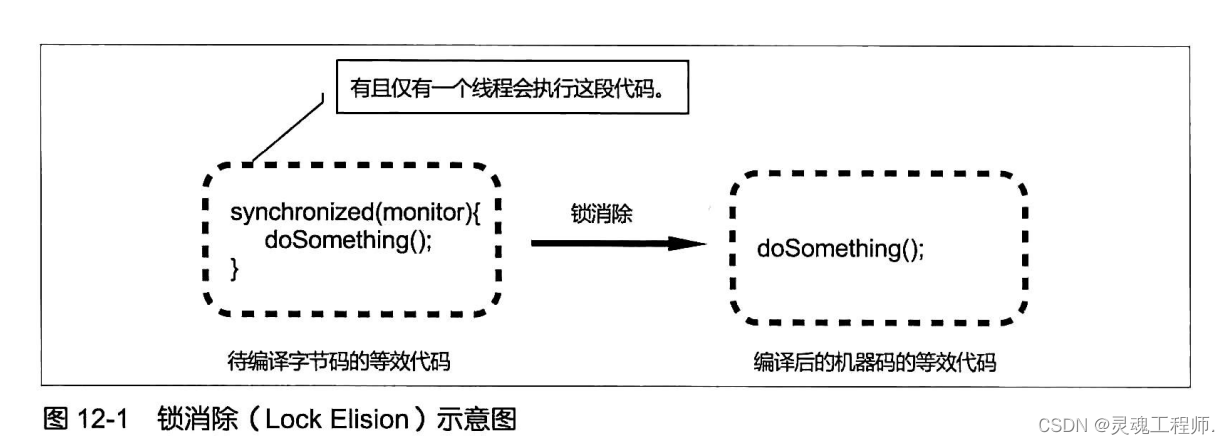
锁消除(Lock Elision):锁消除是JIT编译器对内部锁的具体实现所做的一种优化。在动态编译同步块的时候,JIT编译器可以借助一种被称为逃逸分析(EscapeAnalysis) 的技术来判断同步块所使用的锁对象是否只能够被一个线程访问而没有被发布到其他线程。如果同步块所使用的锁对象通过这种分析被证实只能够被一个线程访问,那么JIT编译器在编译这个同步块的时候并不生成synchronized所表示的锁的申请与释放对应的机器码,而仅生成原临界区代码对应的机器码,这就造成了被动态编译的字节码就像是不包含monitorenter(申请锁) 和monitorexit(释放锁) 这两个字节码指令一样,即消除了锁的使用。这种编译器优化就被称为锁消除(Lock Elision),它使得特定情况下我们可以完全消除锁的开销。

锁消除优化告诉我们在该使用锁的情况下必须使用锁,而不必过多在意锁的开销。开发人员应该在代码的逻辑层面考虑是否需要加锁,而至于代码运行层面上某个锁是否真的有必要使用则由JIT编译器来决定 -
锁粗化(Lock Coarsening):锁粗化是JIT编译器对内部锁的具体实现所做的一种优化。对于相邻的几个同步块,如果这些同步块使用的是同一个锁实例,那么JIT编译器会将这些同步块合并为一个大同步块,从而避免了一个线程反复申请、释放同一个锁所导致的开销。然而,锁粗化可能导致一个线程持续持有一个锁的时间变长,从而使得同步在该锁之上的其他线程在申请锁时的等待时间变长
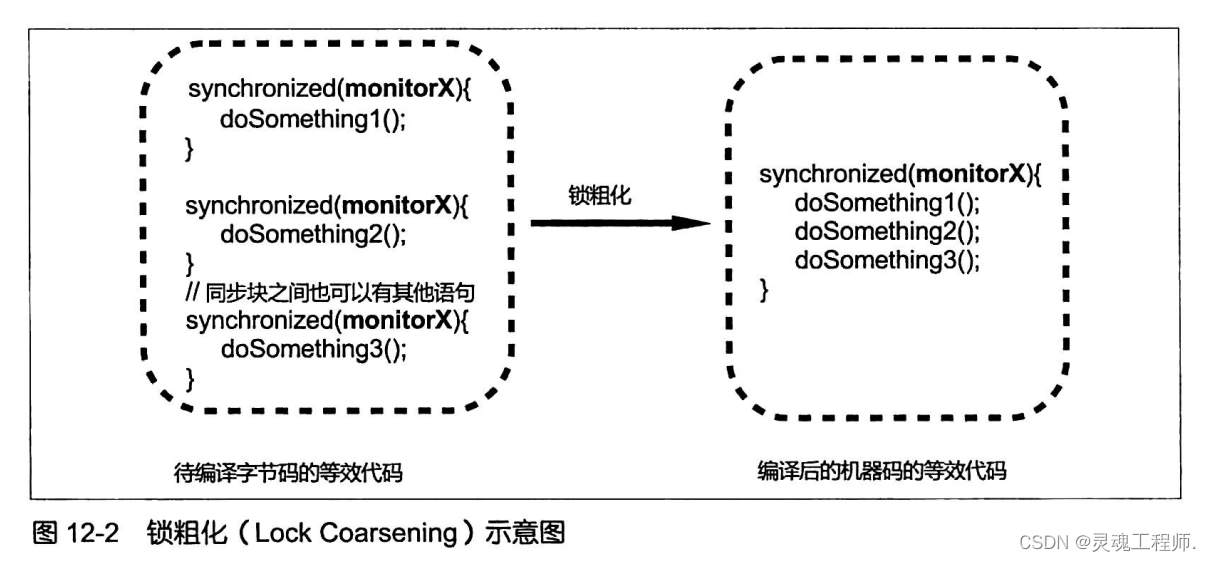

相邻的两个同步块之间如果存在其他语句,也不一定就会阻碍JIT编译器执行锁粗化优化,这是因为JIT编译器可能在执行锁粗化优化前将这些语句挪到(即指令重排序)后一个同步块的临界区之中(当然,JIT编译器并不会将临界区内的代码挪到临界区之外)。 -
偏向锁(Biased Locking):偏向锁是Java 虚拟机对锁的实现所做的一种优化。这种优化基于这样的观测结果( Observation )---大多数锁并没有被争用( Contented ),并且这些锁在其整个生命周期内至多只会被一个线程持有。然而,Java虚拟机在实现 monitorenter字节码(申请锁)和 monitorexit字节码(释放锁)时需要借助一个原子操作(CAS操作)、这个操作代价相对来说比较昂贵。因此,Java虚拟机会为每个对象维护一个偏好( Bias ),即一个对象对应的内部锁第1次被一个线程获得,那么这个线程就会被记录为该对象的偏好线程( Biased Thread )。这个线程后续无论是再次申请该锁还是释放该锁,都无须借助原先(指未实施偏向锁优化前)昂贵的原子操作,从而减少了锁的申请与释放的开销。

然而,一个锁没有被争用并不代表仅仅只有一个线程访问该锁,当一个对象的偏好线程以外的其他线程申请该对象的内部锁时,Java 虚拟机需要收回( Revoke )该对象对原偏好线程的“偏好”并重新设置该对象的偏好线程。这个偏好收回和重新分配过程的代价也是比较昂贵的,因此如果程序运行过程中存在比较多的锁争用的情况,那么这种偏好收回和重新分配的代价便会被放大。有鉴于此,偏向锁优化只适合于存在相当大一部分锁并没有被争用的系统之中。如果系统中存在大量被争用的锁而没有被争用的锁仅占极小的部分,那么我们可以考虑关闭偏向锁优化。 -
适应性锁( Adaptive Locking ):适应性锁是JIT编译器对内部锁实现所做的一种优化。存在锁争用的情况下,一个线程申请一个锁的时候如果这个锁恰好被其他线程持有,那么这个线程就需要等待该锁被其持有线程释放。实现这种等待的一种保守方法我们在前面章节中已经介绍过——将这个线程暂停(线程的生命周期状态变为非 Runnable状态)。由于暂停线程会导致上下文切换,因此对于一个具体锁实例来说,这种实现策略比较适合于系统中绝大多数线程对该锁的持有时间较长的场景,这样才能够抵消上下文切换的开销。另外一种实现方法就是采用忙等( Busy Wait )。所谓忙等相当于如下代码所示的一个循环体为空的循环语句:

事实上, Java虚拟机也不是非要在上述两种实现策略之中择其一,它可以综合使用上述两种策略。对于一个具体的锁实例,Java虚拟机会根据其运行过程中收集到的信息来判断这个锁是属于被线程持有时间“较长”的还是“较短”的。
对于被线程持有时间“较长”的锁,Java虚拟机会选用暂停等待策略;而对于被线程持有时间“较短”的锁,Java虚拟机会选用忙等等待策略。
Java虚拟机也可能先采用忙等等待策略,在忙等失败的情况
下再采用暂停等待策略。Java虚拟机的这种优化就被称为适应性锁(Adaptive Locking ),这种优化同样也需要JIT编译器介入。
从适应性锁优化可以看出,内部锁的使用并不一定会导致上下文切换,这就是前面章节介绍锁与上下文切换时均说锁“可能”导致上下文切换的原因
锁的开销与监视
锁的开销包括以下三个方面:
-
上下文切换与线程调度开销:一个线程申请一个锁的时候,如果这个锁恰好被其他线程持有,那么该线程最终可能会被暂停。Java虚拟机还需要为这些被暂停的线程维护一个等待队列(等待集),以便在这个锁被其持有线程释放的时候将这些线程唤醒。而线程的暂停与唤醒就是一个上下文切换的过程,并且Java 虚拟机维护等待队列也会产生一定的开销。显然,非争用锁并不会导致 上下文切换 和 等待队列 的开销。
-
内存同步、编译器优化受限的开销:锁的内部实现所使用的内存屏障也会产生直接和间接的开销---直接的开销是内存屏障所导致的冲刷写缓冲器、清空无效化队列所导致的开销。另外,内存屏障会阻碍某些编译器优化。无论是争用锁还是非争用锁,都会产生这部分开销。当然,非争用的锁如果最终适用锁消除优化的话那么这个锁的任何开销都会被彻底消除。
-
限制可伸缩性:锁的排他性的本质是局部地将并发计算改为串行计算。这种特性会限制系统的可伸缩性。假设系统的某个操作每次执行的时候都需要申请一个锁,该锁平均被持有的时间为5毫秒,那么1秒之内该系统最多只能完成200个这样的操作,即这个系统的该操作的吞吐率为200 TPS ( Transaction per Second),无论这个系统有多少个处理器。可见,锁的排他性会导致处理器资源(以及其他资源)的浪费,并限制系统的吞吐率。
降低锁的粒度
降低锁的争用程度的另外一种思路是降低锁的申请频率。而减小锁的粒度可以降低锁的申请频率,从而减小锁被争用的概率。减小锁粒度的一种常见方法是将一个粒度较粗的锁拆分成若干粒度更细的锁,其中每个锁仅负责保护(Guard) 原粗粒度锁所保护的所有共享变量中的一部分共享变量,如图所示,这种技术被称为 锁拆分技术( LockSplitting )
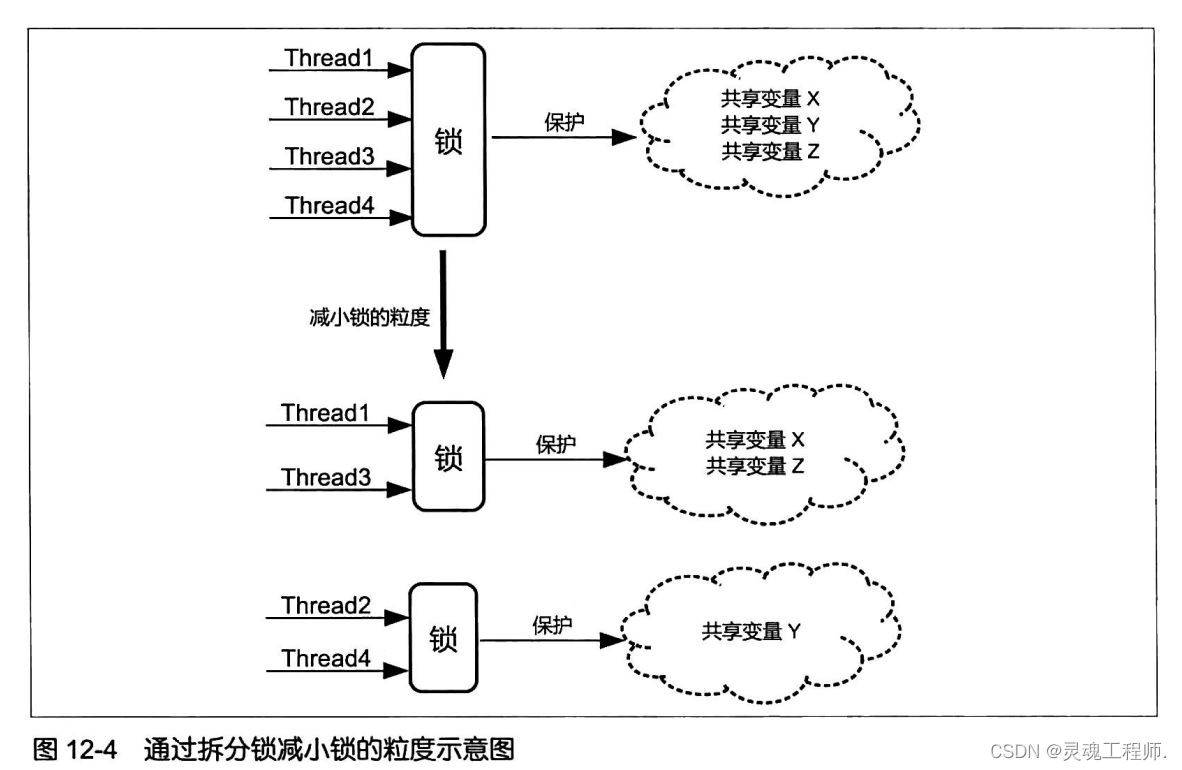
在条件允许的情况下,我们也可以考虑使用锁的替代品来避免锁的开销和问题。这些有条件替代品包括:volatile关键字(参见第3章)、原子变量(参见第3草)、无状念对象(参见第6章)、不可变对象(参见第6章)和线程特有对象(参见第6章)。
—— 送君千里,终须一别 ——
标签:Java,变量,Thread,队列,编程,并发,线程,volatile From: https://www.cnblogs.com/arthus666/p/16637794.html