本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问。
前言
大家好,我是小彭。
在上一篇文章里,我们聊到了计算机的冯·诺依曼架构,以及计算机的五大部件:控制器、运算器、存储器、输入设备和输出设备。在现在计算机体系中,CPU 是整个计算机的核心,主要包含控制器和运算器两大部件。
在后续文章中,我们将从 CPU 的基本认识开始,逐步将 CPU 与执行系统、存储系统 和 I/O 系统串联起来,请关注。
小彭的 Android 交流群 02 群已经建立啦,扫描文末二维码进入~
思维导图:
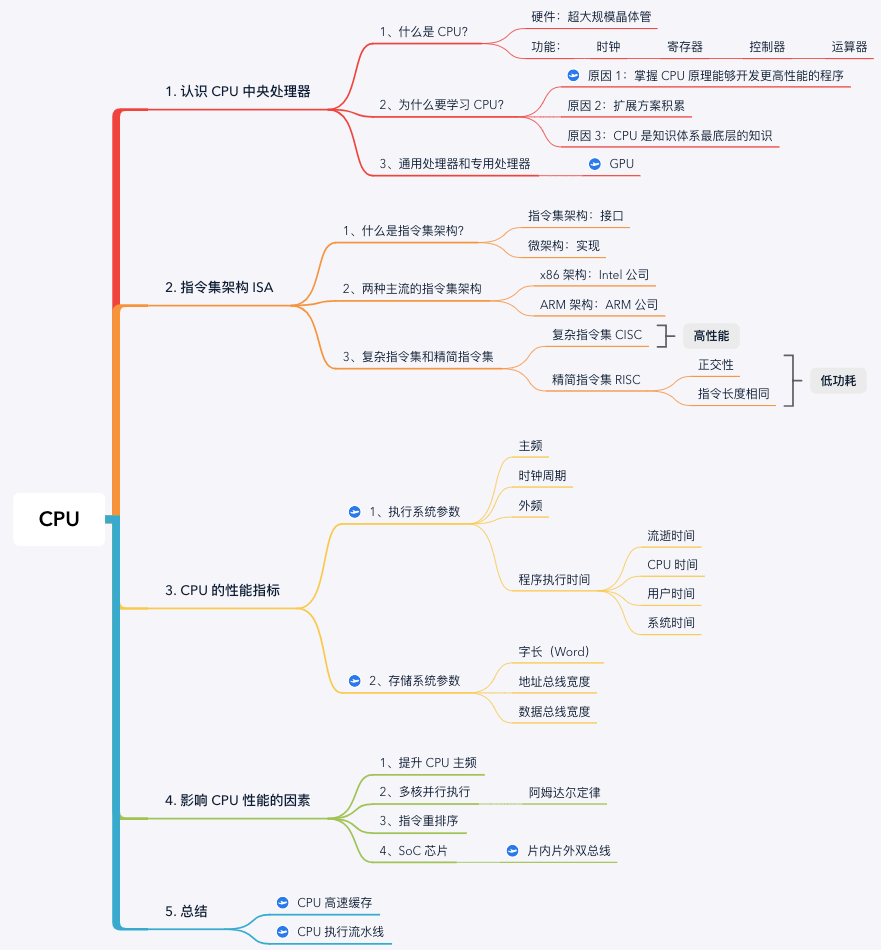
1. 认识 CPU 中央处理器
1.1 什么是 CPU?
中央处理单元(Central Processing Unit,CPU)也叫中央处理器或主处理器,是整个计算机的核心,也是整台计算机中造价最昂贵的部件之一。
从硬件的角度: CPU 由超大规模的晶体管组成;
从功能的角度: CPU 内部由时钟、寄存器、控制器和运算器 4 大部分组成。
- 1、时钟(Clock): 负责发出时钟信号,也可以位于 CPU 外部;
- 2、寄存器(Register): 负责暂存指令或数据,位于存储器系统金字塔的顶端。使用寄存器能够弥补 CPU 和内存的速度差,减少 CPU 的访存次数,提高 CPU 的吞吐量;
- 3、控制器(Control Unit): 负责控制程序指令执行,包括从主内存读取指令和数据发送到寄存器,再将运算器计算后的结果写回主内存;
- 4、运算器(Arithmetic Logic Unit,ALU): 负责执行控制器取出的指令,包括算术运算和逻辑运算。
冯·诺依曼架构
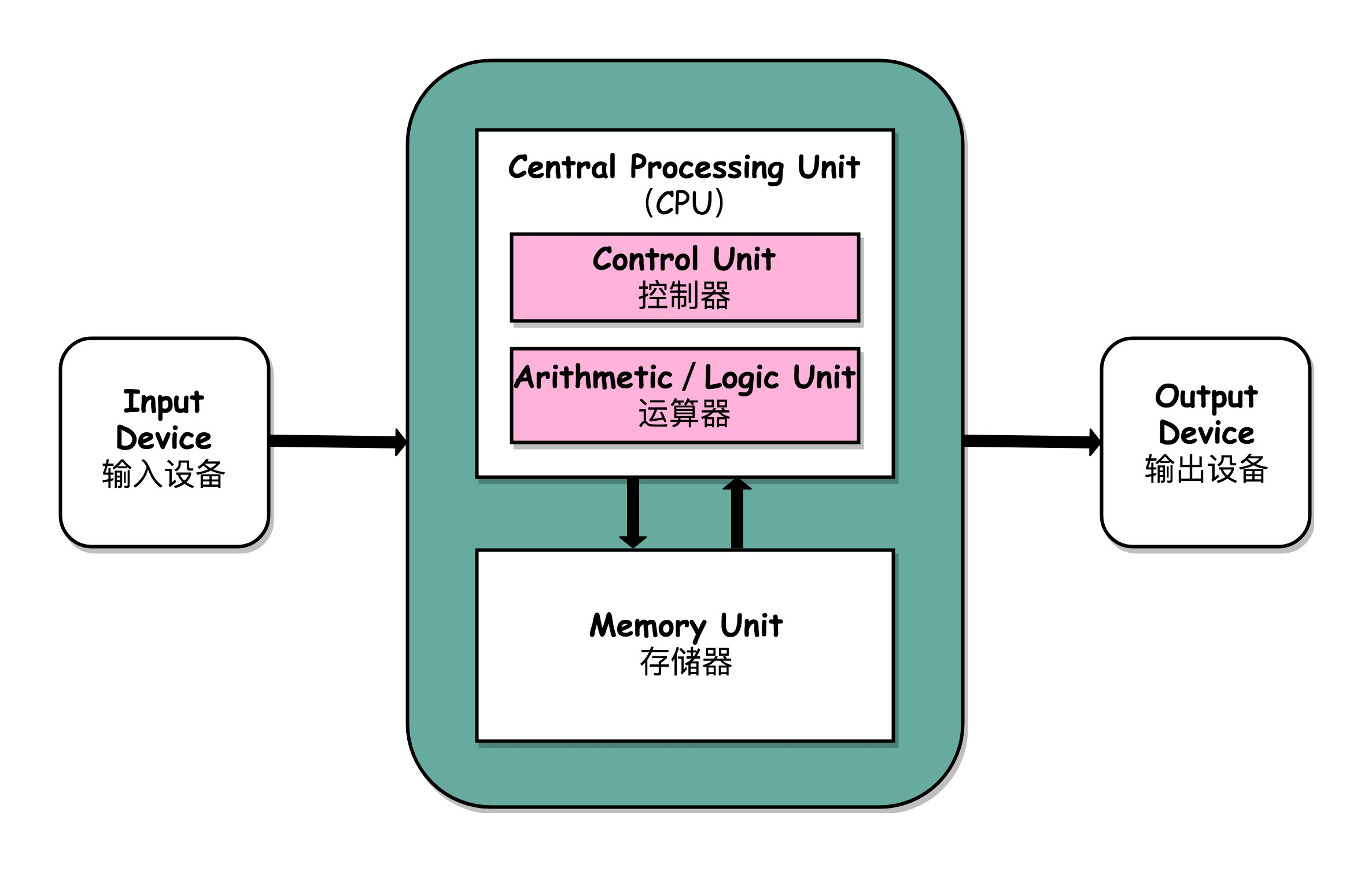
—— 图片引用自 Wikipedia
1.2 为什么要学习 CPU?
对于大部分程序员,日常所处理的工作都是在跟 Java 和 C++ 等高级语言打交道,并不会直接地与 CPU 打交道。那么,为什么我们还要花这么多时间去学习 CPU 呢?我认为有以下原因:
-
原因 1 - 掌握 CPU 原理能够开发更高性能的程序: 理解 CPU 的工作原理有助于设计出更高性能的算法或代码,例如通过避免伪共享、提高缓存命中率等方式提高程序运行效率,就需要对 CPU 的缓存机制有一定的理解;
-
原因 2 - 扩展方案积累: CPU 是整个计算机系统中最复杂的模块,也是当代计算机科学的制高点。积累 CPU 内部的解决方案,能够为将来的遇到类似问题提供思路,达到触类旁通的作用。例如 CPU 缓存淘汰策略与应用内存的缓存淘汰策略有相似之处;
-
原因 3 - CPU 是知识体系最底层的知识: 当我们在思考或解决某一个问题时,就需要利用到更深层次的知识积累来解释,而 CPU 就是位于知识体系中最底层知识。例在内存系统的可见性、执行系统的 IO_WAIT 和线程池设计等问题中,都需要对 CPU 的执行机制有一定理解。
CPU

—— 图片引用自 图片来源
1.3 通用处理器和专用处理器
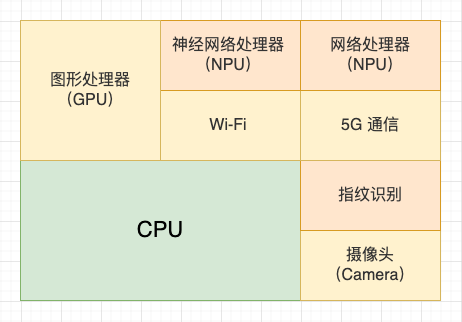
在早期的计算机系统中,只有 1 个通用处理器,使用 1 个处理器就能够完成所有计算任务。后来人们发现可以把一些计算任务分离出来,单独设计专门的芯片微架构,在执行效率上会远远高于通用处理器,最典型的专用处理器就是 GPU 图形处理器。
这种用来专门处理某种计算任务的处理器就是专用处理器,那为什么专用处理器在处理某些特定问题时更快呢,我认为有 3 点解释:
- 1、最优架构: 专用处理器只处理少量类型的工作,可以为特定工作设计最优芯片架构,而通用处理器只能设计全局最优架构,但不一定是执行特定工作的最优机构;
- 2、硬件加速: 可以把多条指令的计算工作直接用硬件实现,相比于 CPU 一条条地执行指令,能够节省大量指令周期;
- 3、成本更低: 专用处理器执行的计算流程是固定的,不需要 CPU 的流水线控制、乱序执行等功能,实现相同计算性能的造价更低。
现代计算机架构都是 1 个通用处理器加上多个专用处理器,这种将不同类型的计算任务采用不同的计算单元完成的设计,也叫 异构计算(Heterogeneous Computing)。
多处理器架构
2. 指令集架构 ISA
2.1 什么是指令集架构?
CPU 所能理解的机器语言就是 指令(Instruction Code), 一个 CPU 所能理解的所有指令就是 指令集(Instruction Set)。
为了保证芯片间的兼容性,芯片厂商并不为每款新芯片设计一个新的指令集,而是将指令集推广为标准规范,这个规范就是 指令集架构(Instruction Set Architecture,ISA) ,
相对于指令集架构,CPU 在实现具体指令集功能的硬件电路设计就是 微架构(Micro Architecture)。 如果用软件的思考方式,ISA 就是 CPU 的功能接口,定义了 CPU 的标准规范,而微架构就是 CPU 的功能实现,定义了 CPU 的具体电路设计,一种指令集可以兼容不同的微架构。
2.2 两种主流的指令集架构
因为 CPU 位于整个计算机系统最底层且最核心的部件,如果 CPU 的兼容性都出问题了,那么以前开发的应用软件甚至操作系统将无法在新的 CPU 上运行,这对芯片厂商的生态破坏是致命的。因此,指令集架构是相对稳定的,芯片厂商在 ISA 中添加或删除指令时会非常谨慎。
目前,能够有效占领市场份额的只有 2 个 ISA ,它们也分别代表了复杂与精简 2 个发展方向:
- x86 架构: Intel 公司在 1970 年代推出的复杂指令集架构;
- ARM 架构: ARM 公司在 1980 年代推出的精简指令集架构,我们熟悉的 Apple M1 芯片、华为麒麟芯片和高通骁龙芯片都是 ARM 架构(其实,ARM 公司并不生产芯片,而是以技术授权的模式运行)。
2.3 复杂指令集和精简指令集
在 CPU 指令集的发展过程中,形成了 2 种指令集类型:
- 复杂指令集(Complex Instruction Set Computer,CISC): 强调单个指令可以同时执行多个基本操作,用少量指令就可以完成大量工作,执行效率更高;
- 精简指令集(Reduced Instruction Set Computer,RISC): 强调单个指令只能执行一个或少数基础操作,指令之间没有重复或冗余的功能,完成相同工作需要使用更多指令。
在早期的计算机系统中,指令集普遍很简单,也没有复杂和精简之分。随着应用软件的功能越来越丰富,应用层也在反向推动芯片架构师推出更强大的指令集,以简化程序编写和提高性能。例如,一些面向音视频的指令可以在一条指令内同时完成多个数据进行编解码。
这在当时的确是不错的选择。 原因是 CPU 和主存的速度差实在太大了,用更少的指令实现程序功能(指令密度更高)可以减少访存次数。 凭借这一点,复杂指令集对精简指令集的优势是几乎全面性的:
- 优势 1: 可以减少程序占用的内存和磁盘空间大小;
- 优势 2: 可以减少从内存或磁盘获取指令所需要的带宽,能够提高总线系统的传输效率;
- 优势 3: CPU L1 Cache 可以容纳更多指令,可以提高缓存命中率。且现代计算机中多个线程会共享 L1 Cache,指令越少对缓存命中率越有利;
- 优势 4: CPU L2 Cache 可以容纳更多数据,对操作大量数据的程序也有利于提高缓存命中率。
然而,这些优势都是有代价的:
- 缺点 1 - 处理器设计复杂化: 指令越复杂,用于解析指令的处理器电路设计肯定会越复杂,执行性能功耗也越大;
- 缺点 2 - 指令功能重叠: 很多新增的指令之间产生了功能重叠,不符合指令集的正交性原则,而且新增的很多复杂指令使用率很低,但处理器却付出了不成正比的设计成本;
- 缺点 3 - 指令长度不统一: 指令长度不统一,虽然有利于使用哈夫曼编码进一步提高指令密度(频率高的指令用短长度,频率高的指令用大长度),但是指令长度不同,执行时间也有长有短,不利于实现流水线式结构。
因此,到 1980 年代,精简指令集 RISC 逐渐浮出水面。目前,大多数低端和移动系统都采用 RISC 架构,例如 Android 系统、Mac 系统和微软 Surface 系列。
相比于复杂指令集,精简指令集更加强调 “正交性” ,单个指令只能执行一个或少数基础操作,指令之间没有重复或冗余的功能。而且精简指令集的每条 指令长度相同 ,非常便于实现流水线式结构。
网上很多资料有一个误区: 精简指令集简化了指令集的大小。 这是不对的,准确的说法是简化了指令集的复杂度。
总结一下: 复杂指令集凭借更高的指令密度,在性能方面整体优于精简指令集(内存 / 磁盘占用、CPU Cache 命中率、TLB 未命中率),而精简指令集牺牲了指令密度换取更简单的处理器架构,以性能换取功耗的平衡。
| 指令集类型 | CISC | RISC |
|---|---|---|
| 指令数量 | 指令数量庞大 | 指令数量相对较少 |
| 指令长度 | 长度不同 | 长度相同 |
| 指令功能 | 有重叠 | 正交 |
| 举例 | x86 | ARM、MIPS |
3. CPU 的性能指标
3.1 执行系统参数
-
1、主频(Frequency/Clock Rate): 在 CPU 内部有一个 晶体振荡器(Oscillator Crystal) ,晶振会以一定的频率向控制器发出信号,这个信号频率就是 CPU 的主频。主频是 CPU 最主要的参数,主频越快,计算机单位时间内能够完成的指令越快。 CPU 的主频并不是固定的,CPU 在运行时可以选择低频、满频甚至超频运行, 但是工作频率越高,意味着功耗也越高;
-
2、时钟周期(Clock Cycle): 主频的另一面,即晶振发出信号的时间间隔, 时钟周期=1/主频;
-
3、外频: 外频是主板为 CPU 提供的时钟频率,早期计算机中 CPU 主频和外频是相同的,但随着 CPU 主频越来越高,而其他设备的速度还跟不上,所以现在主频和外频是不相等的;
-
4、程序执行时间:
-
4.1 流逝时间(Wall Clock Time / Elapsed Time): 程序开始运行到程序结束所流逝的时间;
-
4.2 CPU 时间(CPU Time): CPU 实际执行程序的时间,仅包含程序获得 CPU 时间片的时间(用户时间 + 系统时间)。由于 CPU 会并行执行多个任务,所以程序执行时间会小于流逝时间;
-
4.3 用户时间(User Time): 用户态下,CPU 切换到程序上执行的时间;
-
4.4 系统时间(Sys Time): 内核态下,CPU 切换到程序上执行的时间;
-
3.2 存储系统参数
-
字长(Word): CPU 单位时间内同时处理数据的基本单位,多少位 CPU 就是指 CPU 的字长是多少位,比如 32 位 CPU 的字长就是 32 位,64 位 CPU 的字长就是 64 位;
-
地址总线宽度(Address Bus Width): 地址总线传输的是地址信号,地址总线宽度也决定了一个 CPU 的寻址能力,即最多可以访问多少数据空间。举个例子,32 位地址总线可以寻址 4GB 的数据空间;
-
数据总线宽度(Data Bus Width): 数据总线传输的是数据信号,数据总线宽度也决定了一个 CPU 的信息传输能力。
区分其它几种容量单位:
-
字节(Byte): 字节是计算机数据存储的基本单位,即使存储 1 个位也需要按 1 个字节存储;
-
块(Block): 块是 CPU Cache 管理数据的基本单位,也叫 CPU 缓存行;
-
段(Segmentation)/ 页(Page): 段 / 页是操作系统管理虚拟内存的基本单位。
相关文章: 计算机的存储器金字塔长什么样?
4. 影响 CPU 性能的因素
CPU 作为计算机的核心部件,未来一定是朝着更强大的性能出发。在看待 CPU 的视角上,我们也要具备一定的全局观:
- 1、提升 CPU 性能不止是 CPU 的任务: 计算机系统是多个部件组成的复杂系统,脱离整体谈局部没有意义;
- 2、平衡性能与功耗: 一般来说,CPU 的计算性能越高,功耗也越大。我们需要综合考虑性能和功耗的关系,脱离功耗谈性能没有意义。
4.1 提升 CPU 主频
提升主频对 CPU 性能的影响是最直接的,过去几十年 CPU 的主要发展方向也是在怎么提升 CPU 主频的问题上。
不过,最近几年 CPU 主频的速度似乎遇到瓶颈了。因为想要主频越快,要么让 CPU 满频或超频运行,要么升级芯片制程,在单位体积里塞进去更多晶体管。这两种方式都会提升 CPU 功耗,带来续航和散热问题。如果不解决这两个问题,就无法突破主频瓶颈。
主频的瓶颈
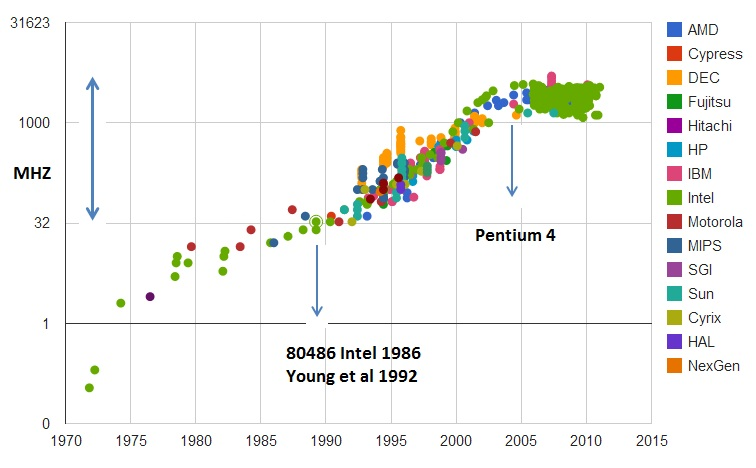
—— 图片引用自 Wikipedia
4.2 多核并行执行
既然单核 CPU 的性能遇到瓶颈,那么在 CPU 芯片里同时塞进去 2 核、4 核甚至更多,那么整个 CPU 芯片的性能不就直接翻倍提升吗?
理想很美好,现实是性能并不总是随着核心数线性增加。在核心数较小时,增加并行度得到的加速效果近似于线性提升,但增加到一定程度后会趋于一个极限, 说明增加并行度的提升效果也是有瓶颈的。
为什么呢?因为不管程序并行度有多高,最终都会有一个结果汇总的任务,而汇总任务无法并行执行,只能串行执行。例如,我们用 Java 的 Fork/Join 框架将一个大任务分解为多个子任务并行执行,最终还是需要串行地合并子任务的结果。
这个结论也有一个经验定律 —— 阿姆达尔定律(Amdahl’s Law) ,它解释了处理器并行计算后效率提升情况。我们把串行的部分称为串行分量 $W_s$ ,把并行的部分称为并行分量 $W_p$ ,正是串行分量限制了性能提升的极限,串行分量越大,极限越低。
- 并行后的执行时间是 $\frac{W_p}{p} + W_s$
- 并行后的加速倍数是 $\frac{W_s+W_p}{W_s+\frac{W_p}{p}}$ ,当并行度 p 趋向于 无穷大时,提升极限就是 $\frac{W_s+W_p}{W_s}$
并行度、并行分量对提升效果的影响
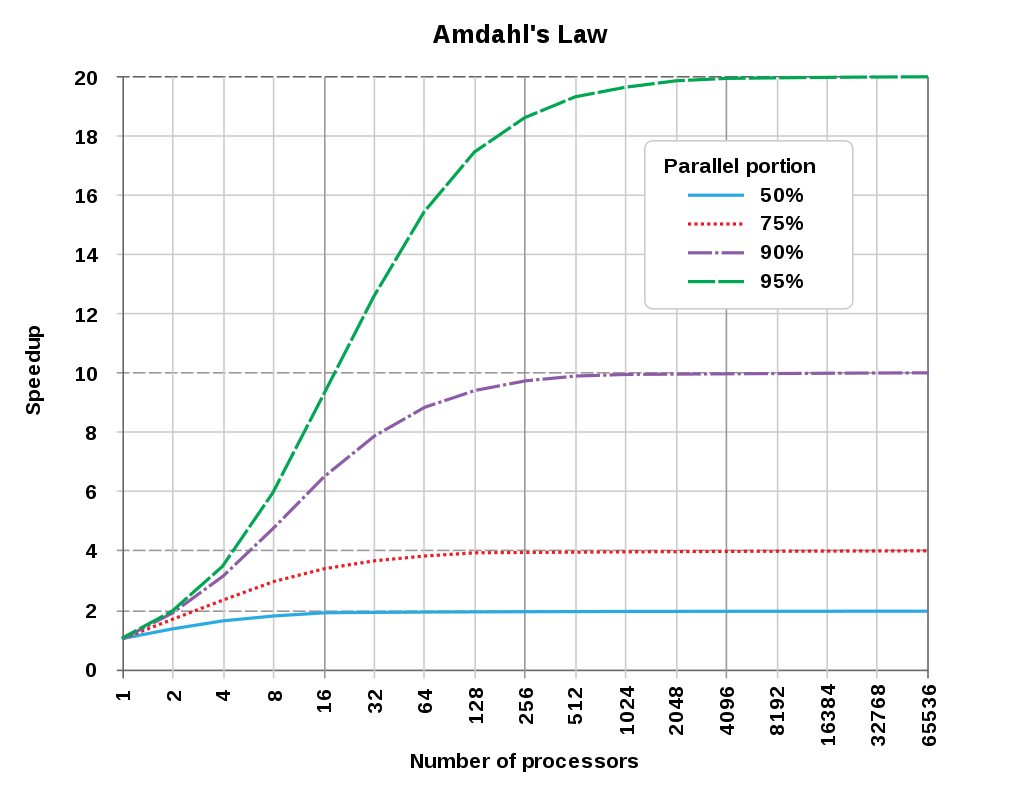
—— 图片引用自 Wiki 百科
说明: 以绿色的曲线为例,程序可以的并行分量是 95%,串行分量是 5%,最终得出的提升极限就会 20 倍。
4.3 指令重排序
增加核心数是提升并行度最直接的方法,但并不是唯一的方法。
现代 CPU 为了提高并行度,会在遵守单线程数据依赖性原则的前提下,对程序指令做一定的重排序。事实上不止是 CPU,从源码到指令执行一共有 3 种级别重排序:
- 1、编译器重排序: 例如将循环内重复调用的操作提前到循环外执行;
- 2、处理器系统重排序: 例如指令并行技术将多条指令重叠执行,或者使用分支预测技术提前执行分支的指令,并把计算结果放到重排列缓冲区(Reorder Buffer)的硬件缓存中,当程序真的进入分支后直接使用缓存中的结算结果;
- 3、存储器系统重排序: 例如写缓冲区和失效队列机制,即是可见性问题,从内存的角度也是指令重排问题。
指令重排序类型

4.4 SoC 芯片 —— 片内片外双总线结构
随着芯片集成电路工艺的进步,在冯·诺依曼架构中的五大部件(运算器、控制器、存储器、输入和输出设备接口)也可以集成在一个芯片上,形成一个近似于完整计算机的系统,这种芯片也叫 片上系统(System on Chip,Soc)。 SoC 芯片将原本分布在主板上的各个部件聚合到同一个芯片上,不同部件之间的总线信息传输效率更高。
相关文章: 图解计算机内部的高速公路 —— 总线系统
5. 总结
今天,我们简单了讨论了 CPU 的基本概念,很多问题只是浅尝辄止。在后续的文章里,我们将从执行系统、存储系统 和 I/O 系统三个角度与 CPU 串联起来。请关注。
参考资料
- CPU 通识课 —— 靳国杰 张戈 著
- 深入浅出计算机组成原理 —— 徐文浩 著,极客时间 出品
- Code Density Concerns for New Architectures —— Vincent M. Weaver 等著
- Central processing unit —— Wikipedia
- Instruction set architecture —— Wikipedia
- Complex instruction set computer —— Wikipedia
- Reduced instruction set computer —— Wikipedia
- Application binary interface —— Wikipedia
- Clock Rate —— Wikipedia
- Amdahl's law —— Wikipedia
小彭的 Android 交流群 02 群
