代码随想录算法训练营Day14|144. 二叉树的前序遍历、94. 二叉树的中序遍历、145. 二叉树的后序遍历
144. 二叉树的前序遍历
递归遍历
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> res;
traversal(root, res);
return res;
}
void traversal(TreeNode* cur, vector<int>& vec) {
// 先设置迭代终止条件
if (cur == NULL) return;
// 前序遍历
vec.push_back(cur->val);
traversal(cur->left, vec);
traversal(cur->right, vec);
}
};
迭代「非递归」遍历
栈与递归之间在某种程度上是可以转换的。递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子节点。这样处理是因为出栈满足先进后出(FILO)原则,所以后加入的左孩子节点会优先出栈,满足前序遍历「中左右」的顺序。代码如下:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> res;
stack<TreeNode*> st;
// 对根节点为空的情况也不能入栈
if (root == NULL) return res;
st.push(root);
while (!st.empty()) {
TreeNode* cur = st.top();
st.pop();
res.push_back(cur->val);
// 由于栈FILO特性,优先压栈右孩子节点
// (注意空节点不入栈)
if (cur->right) st.push(cur->right);
if (cur->left) st.push(cur->left);
}
return res;
}
};
中序遍历
递归法
与「前序遍历」类似,不再赘述。
迭代法「非递归法」
在迭代的过程中,其实我们有两个操作:
- 处理:将元素放进result数组中
- 访问:遍历节点
分析一下刚刚写的前序遍历的代码,不能和中序遍历通用呢?
因为前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,要访问的元素和要处理的元素顺序是一致的,都是中间节点。而中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
动画如下:
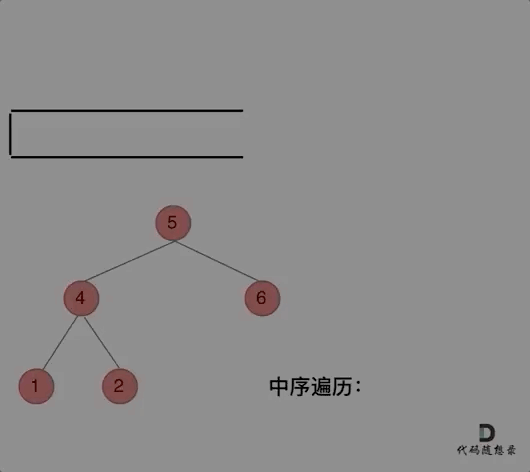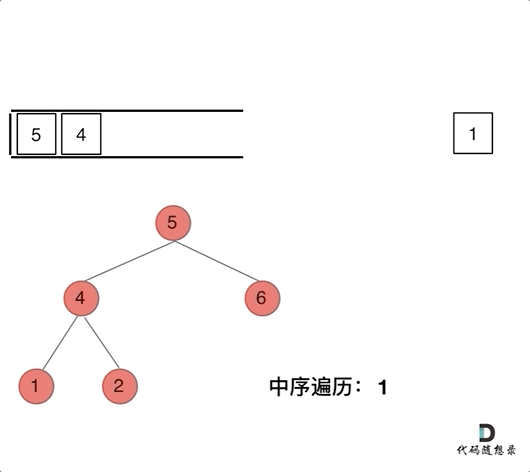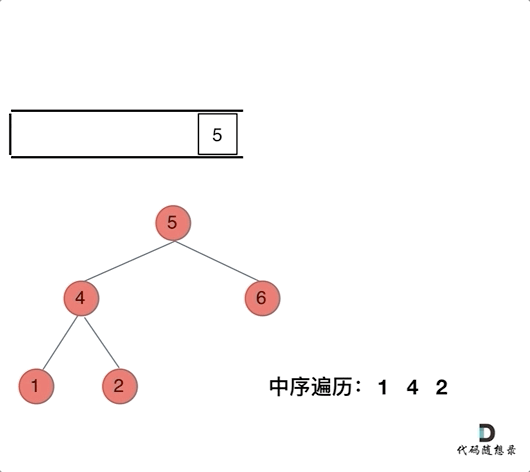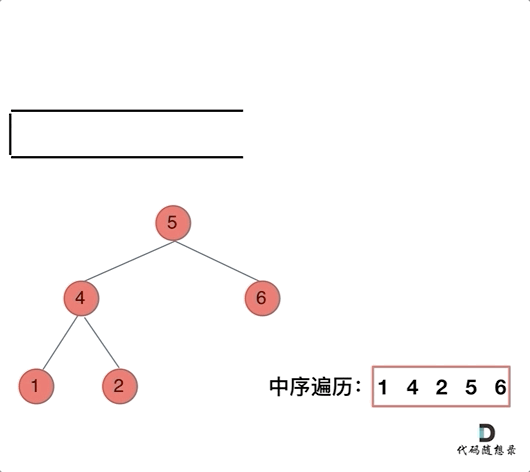
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
stack<TreeNode*> st;
TreeNode* cur = root;
while (cur != NULL || !st.empty()) {
if (cur != NULL) {
// 先遍历到处理节点位置
st.push(cur);
cur = cur->left;
}
else {
cur = st.top();
st.pop();
res.push_back(cur->val);
// 左节点数据处理结束后,再考虑右孩子分支
cur = cur->right;
}
}
return res;
}
};
特别需要注意以下这部分代码:
if (cur != NULL) {
// 先遍历到处理节点位置
st.push(cur);
cur = cur->left;
}
我们使用TreeNode*指针来遍历二叉树,当该游标不为空时便会将对应节点放入栈中,该游标包含两方面作用:
-
一方面可以通过根节点迅速达到二叉树的左孩子叶节点
-
另一方面,当右孩子节点压栈后,也会优先遍历该节点的左孩子节点,输出当前右孩子节点后,还回去考虑右孩子节点的右孩子节点,也能保证中序遍历「左中右」的顺序。
后序遍历
迭代法「非递归法」
再来看后序遍历,先序遍历是中左右,后续遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了,如下图:

/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int> res;
stack<TreeNode*> st;
if (root == NULL) return res;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
res.push_back(node->val);
if (node->left) st.push(node->left);
if (node->right) st.push(node->right);
}
reverse(res.begin(), res.end());
return res;
}
};