目录
一、配置并使用
环境:Windows10 + CLion + VS2019
cuda的安装,并行的话只需要安装cuda,cuDNN就不必了
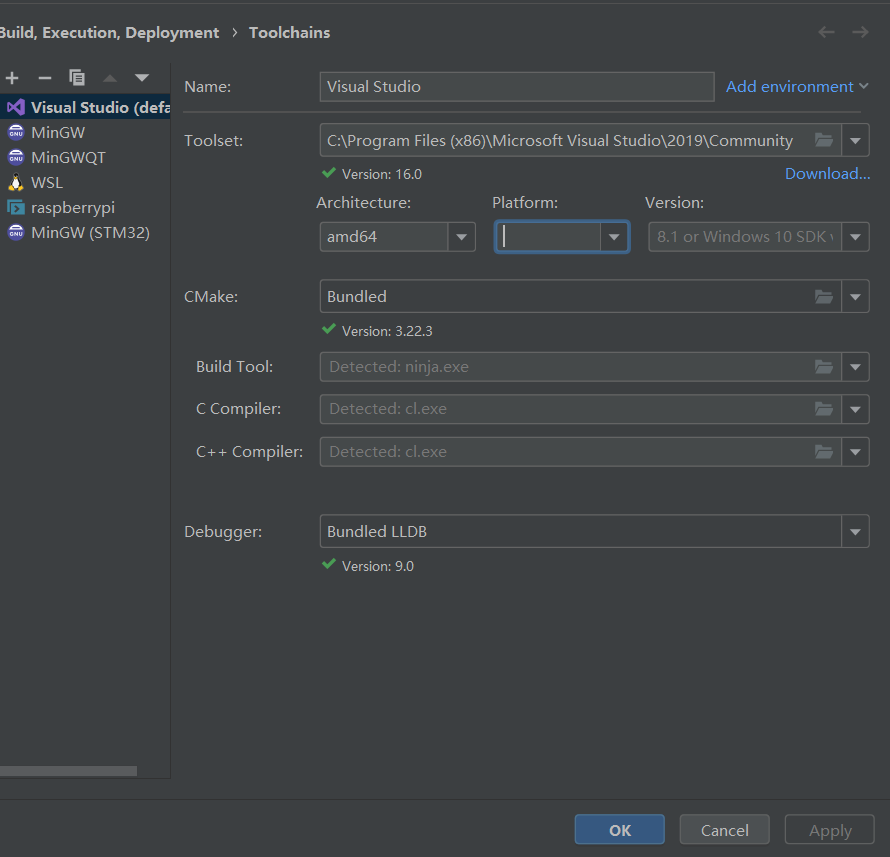
编译器设置,windows下建议使用MSVC,因为是官方支持的,记得架构一定要设置amd64
GPU版本架构查询网址
CmakeList.txt编写
cmake_minimum_required(VERSION 3.22)#跟据自己的cmake版本来设置
project(CUDA_TEST2 LANGUAGES CXX CUDA)
set(CMAKE_CUDA_STANDARD 17)
set(CMAKE_BUILD_TYPE Release)
set(CMAKE_CUDA_ARCHITECTURES 61)
#设置device函数的声名和定义分开,为了性能,不建议这样
set(CMAKE_CUDA_SEPARABLE_COMPILATION ON)
add_executable(CUDA_TEST2 main.cu)
#clion加的,好像可以不要
#set_target_properties(CUDA_TEST2 PROPERTIES
# CUDA_SEPARABLE_COMPILATION ON)
至此,就可以开始写代码了
二、代码
__global__:定义在GPU上的核函数,GPU执行,从CPU调用,可以有参数,不能有返回值,global就是GPU的main函数,device就是其他函数__device__:device修饰的函数定义在GPU上,device是设备函数,GPU执行,只能由GPU调用,调用规则与普通函数一样__host__:host修饰的函数定义在CPU上,只能在CPU上调用,调用规则与普通函数一样- 同时加上host和device修饰符表示同时定义在CPU和GPU上,二者都可调用
__global__ void kernel() {
//sayHi();
printf("Block %d of %d, Thread %d of %d\n", blockIdx.x, gridDim.x, threadIdx.x, blockDim.x);
//printf("Thread Numbers %d\n",blockDim.x);
//线程编号
//printf("Thread %d\n",threadIdx.x);
//sayHello();
}
__device__ void sayHi() {
printf("Hi , GPU\n");
}
__host__ void sayHiCpu() {
printf("Hi , CPU\n");
}
__host__ __device__ void sayHello() {
//从GPU上调用就有这个宏
#ifdef __CUDA_ARCH__
printf("Hello , GPU CUDA_ARCH=%d\n", __CUDA_ARCH__);
#else
printf("Hello , CPU NO CUDA_ARCH\n");
#endif
}
一个kernel就是一个网格
网格内有多个板块,板块内有多个线程组
核函数调用时,parm1:板块 parm2:线程数量
#include <iostream>
#include <cuda_runtime.h>
int main() {
kernel<<<2, 3>>>();
kernel<<<dim3(2, 2, 2), dim3(2, 2, 2)>>>();
cudaDeviceSynchronize();
return 0;
}