目录
{n,m}:匹配前面的字符或子表达式至少n次,但不超过m次。
(?=...):正向先行断言,匹配后面跟着特定模式的字符串。
(?!...):负向先行断言,匹配后面不跟着特定模式的字符串。
(?<=...):正向后行断言,匹配前面有特定模式的字符串。
正则表达式(Regular Expression,简称Regex)是一种用于字符串搜索和操作的强大工具,它使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。它是一套独立的规范,各类编程语言都会提供一些API,支持正则表达式。正则表达式由普通字符(例如,a-z、A-Z、0-9)和特殊字符(称为“元字符”)组成。以下是一些常用的元字符及其含义:
当然,以下是正则表达式元字符和特性的分类,每个都附有一个简单的案例和清晰的输出格式说明:
一. 匹配字符
.:匹配除换行符外的任意单个字符。
示例:
a.t匹配 "act"、"a1t" 或 "a!t"。

二. 位置锚点
^:匹配输入字符串的开始位置。
示例:
^Hello匹配以 "Hello" 开头的句子。

-
$:匹配输入字符串的结束位置。
示例:
World$匹配以 "World" 结尾的句子。

\b:匹配单词边界。
示例:
\bworld这个正则表达式匹配的是 "world" 作为一个完整单词出现的情况


-
\B:匹配非单词边界。
示例:
\Bworld \B匹配 "helloworld" 中的 "world"。

三. 重复限定符
*:匹配前面的字符或子表达式零次或多次(贪婪模式)。
示例:
a*匹配 "a"、"aa" 或 "aaa"。

+:匹配前面的字符或子表达式一次或多次(贪婪模式)。
示例:
a+匹配 "a"、"aa" 或 "aaa",但不匹配空字符串。

?:匹配前面的字符或子表达式零次或一次(懒惰模式)。
示例:
a?匹配 "a" 或空字符串。

{n}:匹配前面的字符或子表达式恰好n次。
示例:
a{3}匹配 "aaa"。

{n,}:匹配前面的字符或子表达式至少n次。
示例:
a{3,}匹配 "aaa"、"aaaa" 或 "aaaaa"。

{n,m}:匹配前面的字符或子表达式至少n次,但不超过m次。
示例:
a{2,3}匹配 "aa" 或 "aaa"。

四. 分支条件
|:逻辑“或”,匹配两个或多个选项中的一个。
示例:
cat|dog匹配 "I have a cat" 或 "I have a dog"。

五. 字符类
[abc]:匹配方括号内的任意一个字符。
示例:
[abc]匹配 "a"、"b" 或 "c"。

[^abc]:匹配不在方括号内的任意一个字符。
示例:
[^abc]匹配 "d"、"e" 或 "f"。

\d:匹配任何数字字符。
示例:
\d匹配 "1"、"2" 或 "3"。

\D:匹配任何非数字字符。
示例:
\D匹配 "a"、"b" 或 "c"。

\s:匹配任何空白字符。
示例:
\s匹配空格、制表符或换行符。

\S:匹配任何非空白字符。
示例:
\S匹配 英文字母。

-
\w:匹配任何字母数字字符及下划线。
示例:
\w匹配 "a"、"1" 或 "_"。

-
\W:匹配任何非字母数字字符及非下划线。
示例:
\W匹配空格或 "!"。

六. 转义字符
\:转义字符,用于匹配元字符本身或特殊序列。
示例:
\.匹配实际的点字符。

七. 特殊序列
\t:匹配制表符(Tab)。
示例:
\t匹配制表符。

\n:匹配换行符。
示例:
\n匹配换行符。

\r:匹配回车符。
示例:
\r匹配回车符。(回车符:将光标移回行首,不换行。换行符:将光标移至下一行开头,换行。)Windows回车换行符都是enter键,单独敲出太麻烦,算了
\f:匹配换页符。
示例:
\f匹配换页符。通常用于打印机或文本处理软件中,以指示开始新的一页。在大多数文本编辑器或命令行界面中,换页符不是通过键盘直接输入的。没法演示。
\v:匹配垂直制表符。
示例:
\v匹配垂直制表符。垂直制表符通常不通过键盘直接输入,因为它主要用于老式的电传打字机和一些特殊的文本处理场景。
八. 分组和引用
():创建捕获组,用于分组和提取匹配的文本。
示例:
(abc)匹配 "abc" 并捕获它。

(?:...):创建非捕获组,用于分组但不捕获匹配的文本。
示例:
(?:abc)匹配 "abc" 但不捕获它。说明:在正则表达式中使用它来对子表达式进行分组,但是不捕获匹配的结果。这意味着匹配到的内容不会像捕获组那样被存储起来,以便后续使用。

\数字:后向引用,引用之前捕获组匹配的文本。配合捕获组使用
示例:
(abc)\1匹配 "abcabc"。匹配文本abc出现两次,并且中间没有任何其他符号。

九. 断言
(?=...):正向先行断言,匹配后面跟着特定模式的字符串。
示例:
abc(?=def)匹配 "abc" 后面跟着 "def"。

(?!...):负向先行断言,匹配后面不跟着特定模式的字符串。
示例:
abc(?!def)匹配 "abc" 后面不跟着 "def"。

-
(?<=...):正向后行断言,匹配前面有特定模式的字符串。
示例:
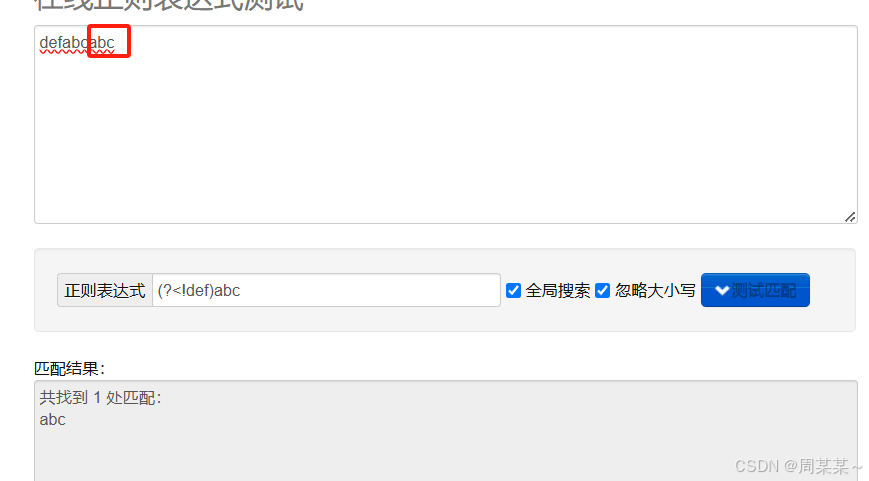
(?<=def)abc匹配 "abc" 前面有 "def"。

(?<!...):负向后行断言,匹配前面没有特定模式的字符串。
示例:
(?<!def)abc匹配 "abc" 前面没有 "def"。
十. Unicode 和其他属性
-
\p{...}:匹配具有特定 Unicode 属性的字符。
示例:
\p{L}匹配任何字母很多正则表达式引擎不支持 Unicode 属性转义或没有启用Unicode模式,暂时没测试。
十一. 递归
-
(?R):递归匹配,正则表达式可以引用自身。
示例:
(?R)可以递归地匹配重复的模式。正则表达式引擎不支持递归模式,暂时没测试。
十二.重复模式
-
贪婪模式:对于重复限定符,默认情况下会匹配尽可能多的字符,这叫做贪婪模式。
-
懒惰模式:在重复限定符之后加上
?,表示匹配尽可能少的字符,这叫做懒惰模式。