大概2周前写了一篇《代码的形状:从外到内的探索与实践》
涵树:代码的形状:从外到内的探索与实践
觉得这个话题还可以继续,它是一个从无形到有形的过程,而这个过程感觉就是王阳明先生说的“心即理”的探寻过程。
我讨论代码的形状,一个初衷是为了降低代码维护的心智负担,而要达到这一目的,其实也是要使代码更加符合于“理”。
使用tree命令来查看代码的目录结构,这个方法颇为有效,他可以让我们很方便的评估这样的结构是否符合我们对项目逻辑的理解。
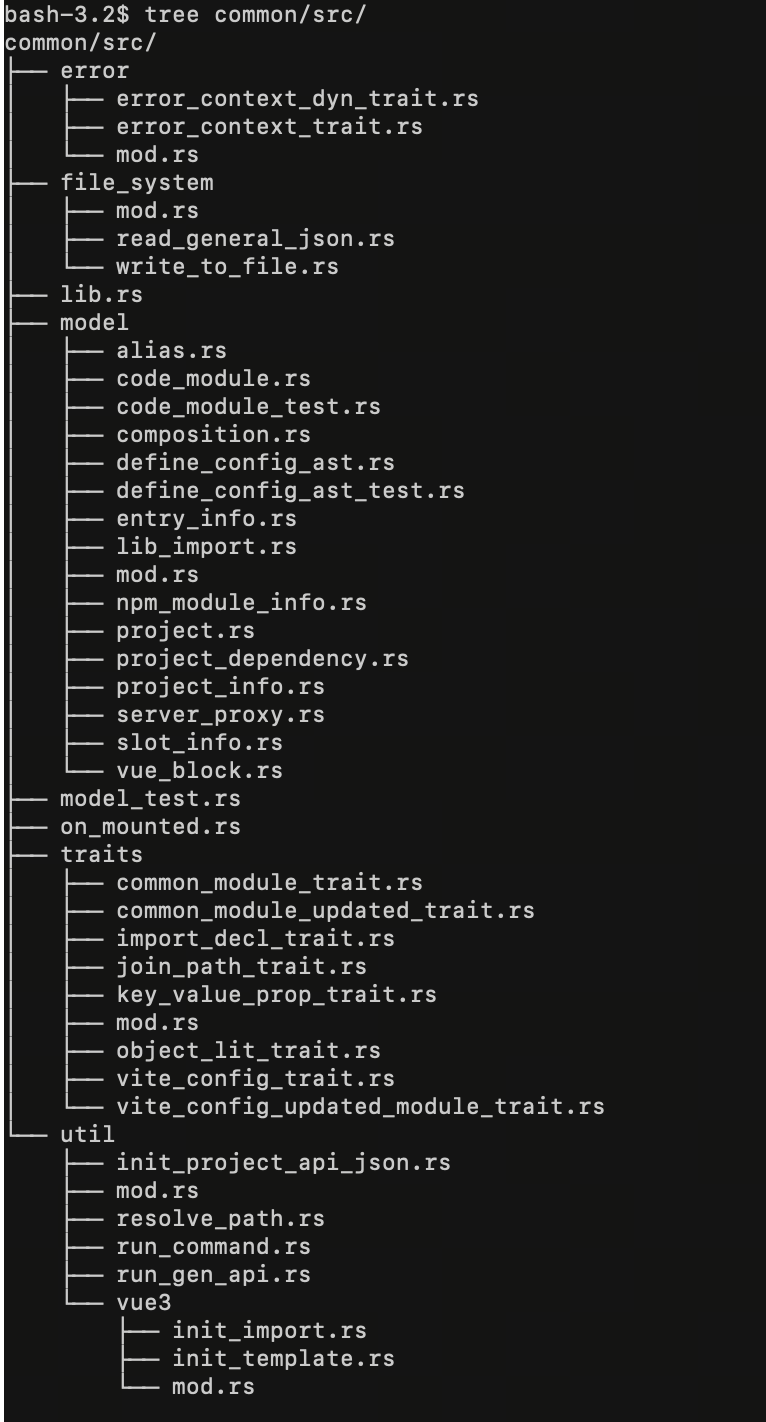 这是一个动态且永不停息的过程,代码在变,而你同时也在变。上面的这个common模块,之前也没有这么多的文件,也是一步一步的重构出来的。其中有一些在重构的过程中修改了名字。
“名字”这个东西,在编程的世界里,往往被一些初学者甚至是部分有经验的开发者视为无足轻重的细节。他们可能觉得,只要代码逻辑正确,功能实现,名字不过是些符号,随便取取就行。然而,我深感这种观念大错特错。“名字”的重要性、价值和可操作性,在我看来,远远胜过了设计模式和架构。
首先,代码中的“名字”是逻辑清晰度的直接体现。当我们为变量、函数、类或模块取名时,如果名字是随意的、模糊的,那么这往往反映出我们对这段代码的逻辑理解还不够清晰。一个好的名字,应该能够准确地传达出代码元素的用途、功能和性质,让阅读者一眼就能明白这段代码的意图。相反,一个随意的名字,获取不够精确的名字,会给代码维护增加心智负担,增加维护的难度。
因此,名字的选择直接影响着代码的可维护性。如果名字不清晰、不准确,那么当日后需要对代码进行修改或扩展时,开发者就会陷入困境。那么如何使名字“清晰”和“准确”呢?呵呵,这里感觉就是一个玄学,或者,我说它不是静态的。即没有一个永远“清晰”和“准确”的名字存在。我们需要不断的review,如果有看不懂的地方,可能就要考虑重构或者修改“名字”了。
这是一个动态且永不停息的过程,代码在变,而你同时也在变。上面的这个common模块,之前也没有这么多的文件,也是一步一步的重构出来的。其中有一些在重构的过程中修改了名字。
“名字”这个东西,在编程的世界里,往往被一些初学者甚至是部分有经验的开发者视为无足轻重的细节。他们可能觉得,只要代码逻辑正确,功能实现,名字不过是些符号,随便取取就行。然而,我深感这种观念大错特错。“名字”的重要性、价值和可操作性,在我看来,远远胜过了设计模式和架构。
首先,代码中的“名字”是逻辑清晰度的直接体现。当我们为变量、函数、类或模块取名时,如果名字是随意的、模糊的,那么这往往反映出我们对这段代码的逻辑理解还不够清晰。一个好的名字,应该能够准确地传达出代码元素的用途、功能和性质,让阅读者一眼就能明白这段代码的意图。相反,一个随意的名字,获取不够精确的名字,会给代码维护增加心智负担,增加维护的难度。
因此,名字的选择直接影响着代码的可维护性。如果名字不清晰、不准确,那么当日后需要对代码进行修改或扩展时,开发者就会陷入困境。那么如何使名字“清晰”和“准确”呢?呵呵,这里感觉就是一个玄学,或者,我说它不是静态的。即没有一个永远“清晰”和“准确”的名字存在。我们需要不断的review,如果有看不懂的地方,可能就要考虑重构或者修改“名字”了。
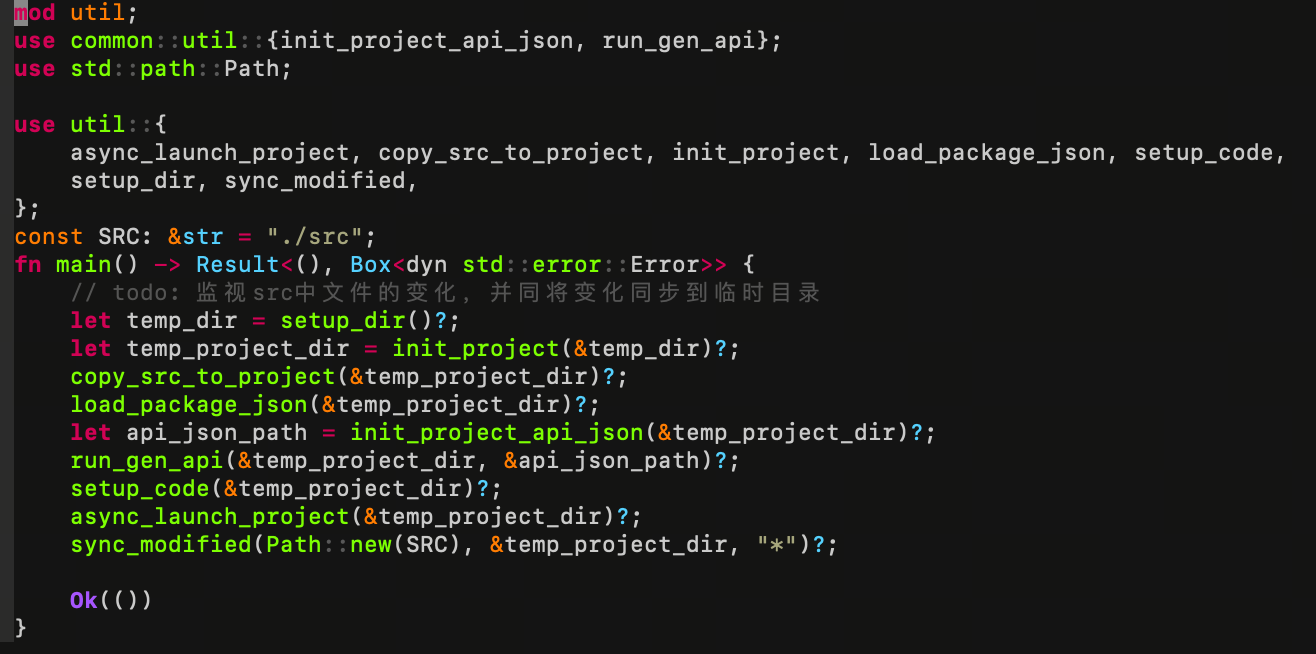 以上面的代码为例,如果我想不起某一个方法的作用,那么我就要考虑修改名字了。
然而,我发现有一个悖论存在于我们的开发实践中。那就是,当我们感觉到代码测试老是有改不完的bug,项目已经变得难以维护时,才想起来要重构。他们希望通过“重构”这剂良药来改变项目的现状,让代码变得更加清晰、可维护。但是,这个时候的“重构”本身也是很危险的。因为在一个已经充满bug、逻辑混乱的代码中进行重构,就像是在一个摇摇欲坠的建筑上进行改造,一不小心就可能引发更大的崩塌。重构带来的改动可能会引入新的bug,大概率会破坏原有的功能,很难起到期望的效果。这也可能是互联网上的流传的“屎山”代码越堆越高的原因吧,没人敢去重构。
这也是我前面说的,“名字”的重要性,价值和可操作性远远胜于重构和系统架构的原因,因为,好的命名是重构和系统架构改进的前提。这是我所相信的,你呢?
以上面的代码为例,如果我想不起某一个方法的作用,那么我就要考虑修改名字了。
然而,我发现有一个悖论存在于我们的开发实践中。那就是,当我们感觉到代码测试老是有改不完的bug,项目已经变得难以维护时,才想起来要重构。他们希望通过“重构”这剂良药来改变项目的现状,让代码变得更加清晰、可维护。但是,这个时候的“重构”本身也是很危险的。因为在一个已经充满bug、逻辑混乱的代码中进行重构,就像是在一个摇摇欲坠的建筑上进行改造,一不小心就可能引发更大的崩塌。重构带来的改动可能会引入新的bug,大概率会破坏原有的功能,很难起到期望的效果。这也可能是互联网上的流传的“屎山”代码越堆越高的原因吧,没人敢去重构。
这也是我前面说的,“名字”的重要性,价值和可操作性远远胜于重构和系统架构的原因,因为,好的命名是重构和系统架构改进的前提。这是我所相信的,你呢?