Transformer模型已经成为大语言模型(LLMs)的标准架构,但研究表明这些模型在准确检索关键信息方面仍面临挑战。今天介绍一篇名叫Differential Transformer的论文,论文的作者观察到一个关键问题:传统Transformer模型倾向于过分关注不相关的上下文信息,这种"注意力噪声"会影响模型的性能。
在这篇论文中,作者注意到transformer模型倾向于关注不相关的上下文。为了放大相关上下文的注意力分数,他们提出了一个新的注意力模型,称为差分注意力模型。在这个模型中,他们将查询和键值向量分成两组,并计算两个子注意力分数。
差分注意力机制
差分注意力机制(Differential Attention)的核心思想是通过计算两个独立的注意力图谱之差来消除注意力噪声。这种设计借鉴了电气工程中差分放大器的原理,通过对比两个信号的差异来消除共模噪声。
让我们看看论文中的第一个方程:
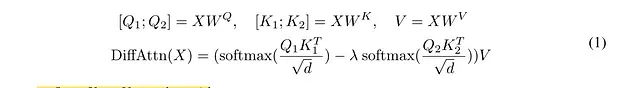
方程(1)
方程(1)显示,我们首先像标准注意力计算一样计算Q、K和V张量。关键点是我们将Q和K张量分成Q1、Q2和K1、K2子张量。
https://avoid.overfit.cn/post/f2e9e7856db24002beb7fc7d2dc33c96
标签:Transformer,模型,Differential,张量,差分,注意力 From: https://www.cnblogs.com/deephub/p/18608208