学习从0到1的json实现(一)
实现自己的json解释器过程中遇到了很多问题,这是一篇日志性质的踩坑记录…或许看起来更像是实验报告(仅用于个人记录)
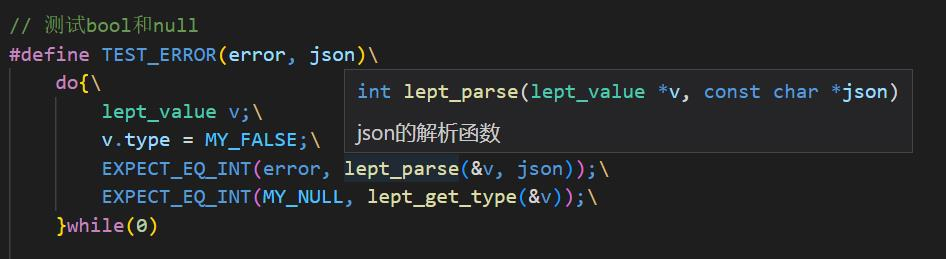
null/true/false
将三个值的解析器合成为一个解析器时,我的初步代码如下:
static int lept_parse_ntf(lept_context* c, lept_value* v, const char* flag, lept_type flag_type){
EXPECT(c, flag[0]);
for(int32_t i=1; i<strlen(flag); ++i){
// 这里如果直接从1开始,万一被恶意传进来了只有一个字符的、那程序就崩了
if (c->json[i-1] != flag[i])
return LEPT_PARSE_INVALID_VALUE;
}
c->json += strlen(flag)-1;
v->type = flag_type;
return LEPT_PARSE_OK;
}
但这里有写不合理,比如我试图把json直接越过整个flag试图比较,但是不知道c的json是否达到那个长度。
number
添加双精度浮点数时、产生疑问:边界是被包含在浮点数范围内的还是范围外?
参考博客:
https://github.com/anjia/blog/issues/87
https://zhuanlan.zhihu.com/p/89320102
个人理解偏移:拉长or缩短数轴(x轴),让每一段中能表达的数字个数相等。回到我们的问题,边界是被包括的,也就是类似于a<=1、1就是a的边界
如何表示这种超大的数?->用宏则仅为替换、不能实现编译时运算;->所以结合cpp中的函数式来搞or内联函数(简单的函数运算);实现lambda的时候发现类型转换有问题、如果返回char*就不能对应上const
lambda
我的代码如下:
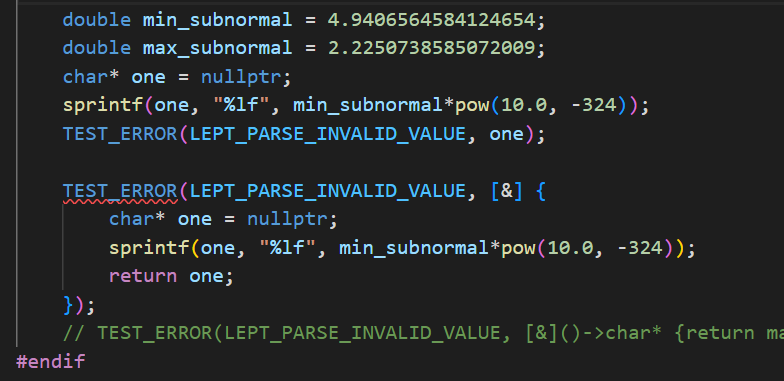
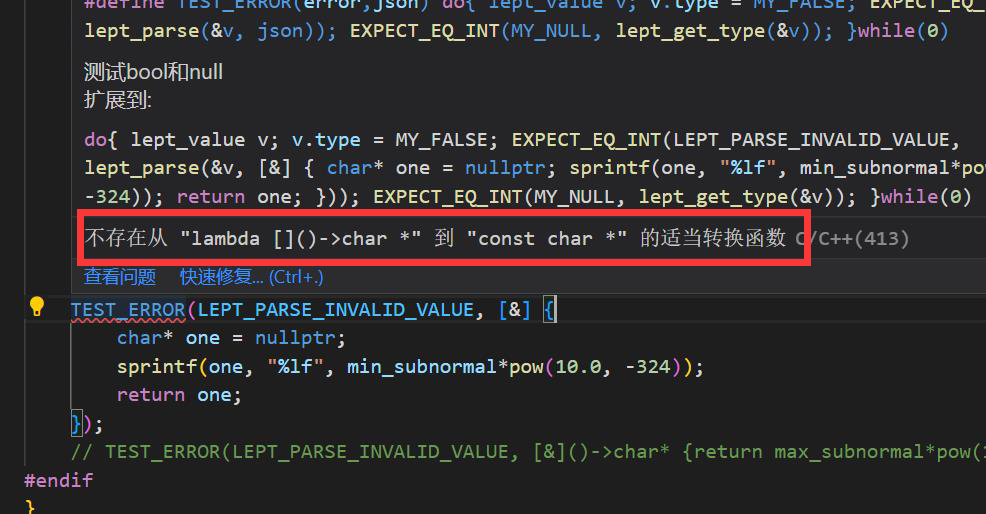
可以看到这里lambda的实现和普通写法一模一样,但是为什么使用lambda会报错呢?这就要看向函数指针和std::function。lambda是一定可以替换掉普通类型的函数实现,而涉及到函数指针的时候,就要使用std::function
但是这里只是为了实现一个测试的例子,最后发现可以用计算机的科学计数法(也就是把3x10^20换成3e+20)来表示、不需要自己再去算……
浮点数符号无法被正确解析->都得到了正的浮点数;不能简单地用条件判断首个字节
if (check_mid_num(c->json)){
v->n = -strtod(c->json, &end);
}else v->n = strtod(c->json, &end);
这反而使其他可以正确解析符号的数字类型也不能通过了(上面的执行增加了条件判断、下面的无)
关于HUGE_VAL
看cppreference的时候完全没想到这个能返回+、-两个符号!还以为统一返回HUGE_VAL的:所以看文档要仔细
string
我感觉这一部分最重要的思想是把申请内存空间和分配值作为两个步骤;也就是说一个内存空间可以重复利用、被不断的分配给其他值;打个比方,就像是旅馆的房间,需要旅馆的时候找到一家旅馆、可以在里面的房间住宿,但当用户离开旅馆时需要归还钥匙、直到下一个游客入住。借用一个栈来实现缓冲区的效果(也可以用vector来搞):
- 解析一个字符串的时候、需要申请动态数组储存;而一个缓冲区就能避免重复开辟内存空间
- 还可以借用template、让它暂存不同类型的数据
其次是理解有效的转义字符的范围(可恶的阅读理解!)。这里要知道16进制应该怎么算,比如%x1F后面跟着%x20……
string = quotation-mark *char quotation-mark
char = unescaped /
escape (
%x22 / ; " quotation mark U+0022
%x5C / ; \ reverse solidus U+005C
%x2F / ; / solidus U+002F
%x62 / ; b backspace U+0008
%x66 / ; f form feed U+000C
%x6E / ; n line feed U+000A
%x72 / ; r carriage return U+000D
%x74 / ; t tab U+0009
%x75 4HEXDIG ) ; uXXXX U+XXXX
escape = %x5C ; \
quotation-mark = %x22 ; "
unescaped = %x20-21 / %x23-5B / %x5D-10FFFF
其中unescaped是转义不有效的范围,中间有俩斜杠、分别挖去了%x22和%x5C(已经处理过的"和\)!
经典链接:undefined reference to……
排错思路:
- 确定调用的函数都存在
- 确定所有被调用的函数、所在的文件都被编译到了
为什么这里要先确定所有被调用的函数都存在呢,因为我遇到的就是这个问题
在c++里可能会出现重载问题:比如当我函数命名为void func(const T* one);,而函数定义时用的void func(T* one){},此时func函数就被重载了。回顾一下有关const的知识。当一个变量加上const就成了静态变量,会被扔到静态变量存储区、直到人为释放or程序结束才生命终止。至于const char*和char*可以进行比较而const T*和T*不行,我们进行一个简单的测试:
#include<iostream>
struct Date
{
int year, month, day;
Date(int x, int y, int z) :year(x), month(y), day(z) {
std::cout << "hello, today is " << year << "-" << month << "-" << day << std::endl;
}
};
bool func(){
const char* one = "a";
char* ano = (char*)"a";
return one==ano;
}
bool test_t(){
const Date one{2022, 10, 9};
Date ano(2022, 10, 9);
return one == ano;
}
int main() {
std::cout << func << std::endl;
std::cout << test_t() << std::endl;
return 0;
}
vscode会在test_t()里return的==处标红,并提示:没有与这些操作数匹配的 "==" 运算符,找到答案了->const修饰普通数据类型(int、char、bool……)可以进行比较,是因为它们的比较符(==)都被重载好了,而当const修饰自定义的结构、类时,我们没有重载==就不能把两者进行比较。
提出疑问:那么隐式类型转换是怎么实现的呢?它其实是编译器的优化、和这里的比较运算符没被重载是两码事
在查找可能的原因时,发现以下代码也不能链接:
#include<iostream>
struct Date
{
int year, month, day;
Date();
Date(int x, int y, int z) :year(x), month(y), day(z) {
std::cout << "hello, today is " << year << "-" << month << "-" << day << std::endl;
}
Date operator= (const Date& d) {
if (&d != this) {
year = d.year;
month = d.month;
day = d.day;
}
return *this;
}
};
int main() {
Date a{ 2022, 10, 9 };
Date b;
Date c;
c = b = a;
std::cout << c.month << std::endl;
system("pause");
return 0;
}
这里涉及到的是构造函数的写法,只需要把Date();改成Date()=default;就可以了。
Unicode
这一部分可以说是我完成的很艰难的地方、完全没有思路(虽然叶大说这里简单,但我实在只能苦笑),以至于看教程解析时仍然迷茫;后来发现其实是我不会实现十六进制的解读,这也导致了我不知道应该怎么使用对应函数中的unsigned u
当我想要调试看看,发现vscode使用gdb时有些问题:vscode连接wsl2,应该使用wsl2的gdb,但我直接用vscode无法击中断点。通过vscode终端使用gdb,调试过程中用l无法显示源码、n和s会转入库文件中
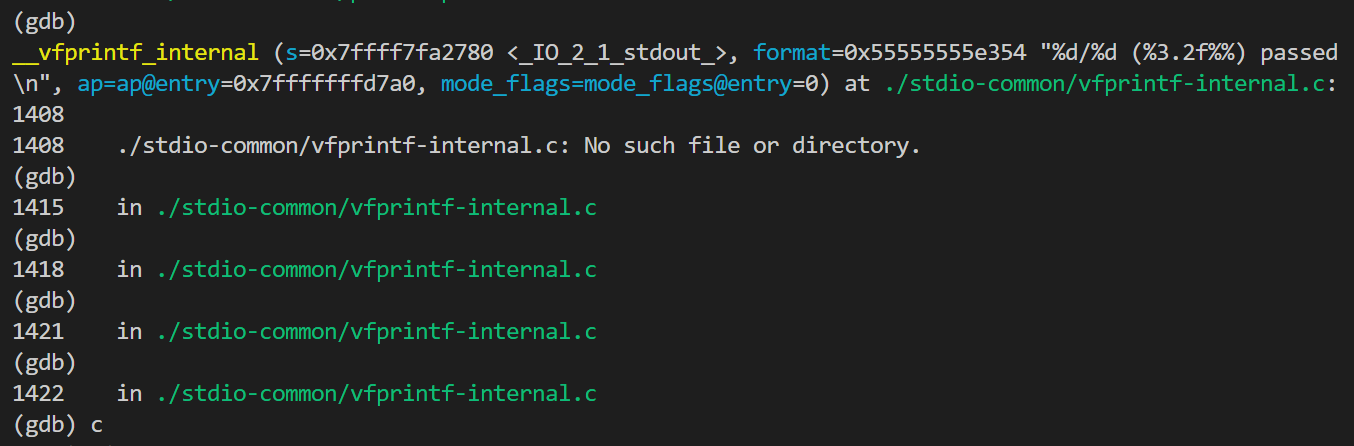
后来突然想起来我直接用的CMakeLists.txt,编出来的可执行文件未添加-g选项。重新编译一个test后,可以通过终端gdb调试test
但是经过这样的调整,我依然只能用vscode的终端进行调试,这涉及到另外一个问题:vscode的设置。我这里若想调试,需要把lept_json.cpp和test.cpp同时编译,把vscode配置中的tasks.json修改
"args": [
"-fdiagnostics-color=always",
"-g",
"${fileDirname}//*.cpp", // 这里加的\\*.cpp可以匹配文件夹下所有cpp进行编译:单用${file}就是单个文件编译
"-o",
"${fileDirname}\\${fileBasenameNoExtension}"
],
接下来就可以使用vscode的调试界面了
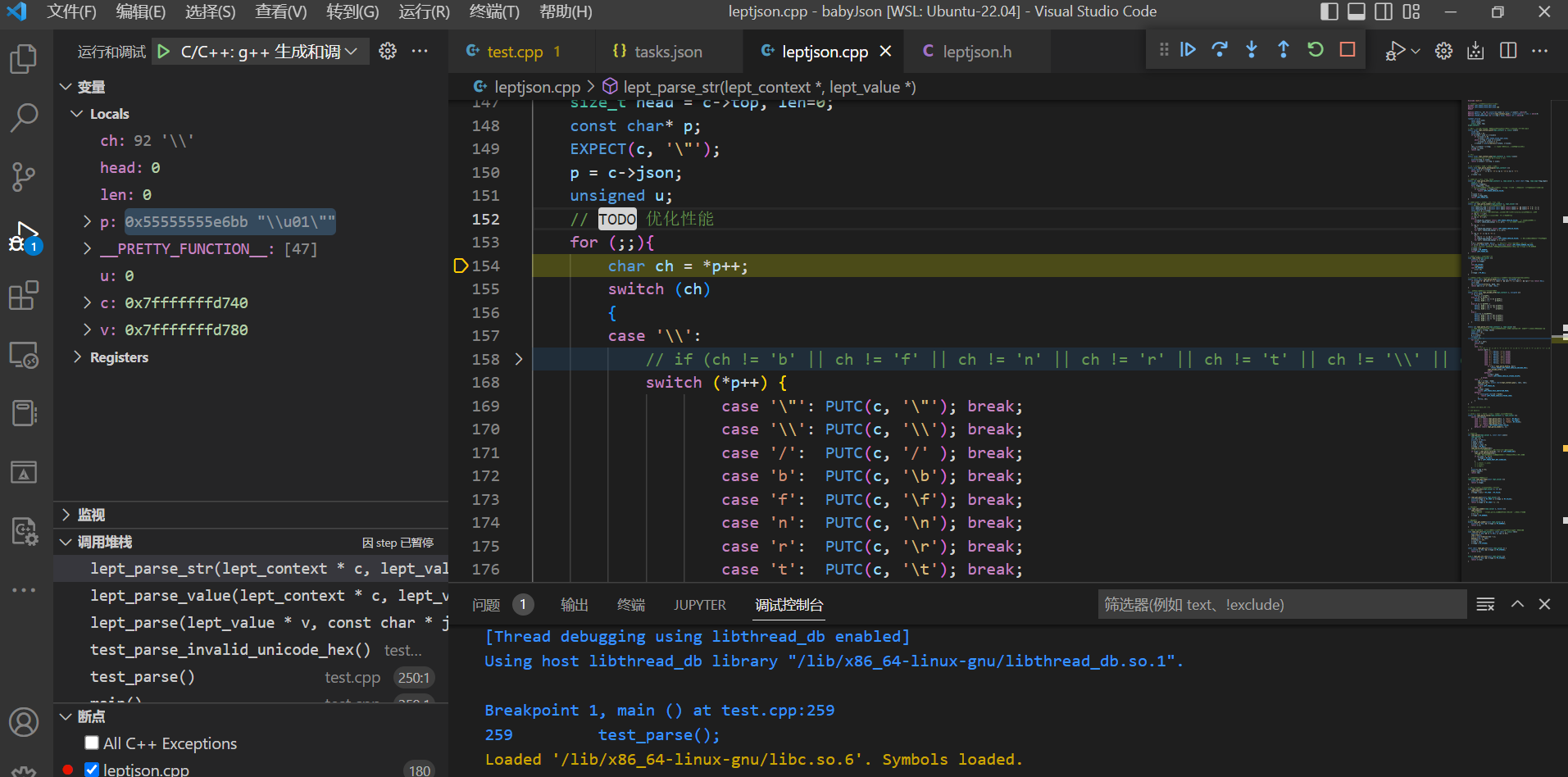
调完后,发现这部分运算是不被加载的,应该是编译器直接优化掉了;也就是实现lept_parse_hex4()和lept_encode_utf8()这两个函数,主要是看懂编码表后使用位运算进行操作。所以还是要学明白位运算……
array
叶大给的解析器实在是精妙,能同时完成解析单个元素、解析整个数组(录入数组一共几个元素+每个元素的“头指针”)两部分。这部分需要重视c、v、e三者:c是传进来的未解析的原字符串,而v是经过解析的最终数组,e是经过解析的数组中单个元素。理清他们在这个解析器中的每个行为,就能理解了。
关于free
free的参数是一个指针,而使用过程中free掉的是指针指向的内存,也就是指针本身仍然存在,但它不指向任何东西了。
Segmentation fault
空悬指针的问题。当我试图这样实现第五章的解决内存泄漏:
// leptjson.cpp
void lept_free(lept_value* v){
assert(v != NULL);
switch (v->type)
{/*...*/
case MY_ARRAY:
for (size_t i=0; i<v->arrSize; ++i) free(&v->e[i]);
}
}
可以看到我试图用简单的迭代free掉每个数组中元素,此时报错Segmentation fault
经过调试,发现此时仍可链接到数组中的字符串元素;也就是说,我仅释放了数组的结构、其中的元素并没有被释放。
回看数组的结构
typedef struct lept_value lept_value;
// json是树形结构,现在搞一个type节点
struct lept_value{
// union比直接随意扔在struct里更省内存->这里要看它的存储结构而不是数据大小
union {
struct { lept_value* e; size_t arrSize;}; // array
struct { char* s; size_t len;}; //string
double n; // number
};
lept_type type;
};
数组本身是一个节点,而数组中的每个元素也是一个节点、具有自己的类型和值等属性;要释放,就先把数组中每个元素的节点释放后再释放数组本身这个节点。按照这个思路,我先写成了下面的形式:
case MY_ARRAY:
for (size_t i=0; i<v->arrSize; ++i){
lept_free(&v->e[i]);
}
free(v->e);
但是它还有点问题;比如,每一个元素被传进来以后,如果不设置终点,将在已经释放的指针上不断循环。于是在数组case的最后和switch分支的最后添加switch的终点:
switch(v->type){
/*...*/
case MY_ARRAY: /*...*/
default:break;
}
数组中每个元素与索引对应
这里回看数组的结构,只有一个lept_value* e和数组元素的个数,那么在清除数组内存的时候是怎么通过&v->e[i]这样的索引找到元素地址的呢?
如果没有整理好这一步,可能会得到报错:
free(): invalid pointer
再回到关于这个数据的结构探讨,v->e才是实际意义上的数组,而v只是一个记录数组信息的指针(包括数组的地址、数组元素个数)。
而索引能对应上要看到每个元素解析时都会被压入栈中:

而栈中的空间申请是连续的,所以数组也可以进行索引
object
相比于前面实现中遇到的阻力,这一part我反而相对快的调出来了,感觉是参透了哈哈哈;基本没遇到问题。感想就是学习的方法很重要,比如需要经过自己的思考,要是实在搞不出来应该及时理解别人的实现、拓展自己思路;然后自行实现。
在拆解解析字符串的函数时,我试图把成功解析并弹栈的值赋给str:
static int lept_parse_str_raw(lept_context* c, char** str, size_t* len){
/*...*/
case '\"':
/*...*/
**str = (const char)lept_context_pop(c, *len);
return LEPT_PARSE_OK;
}
报错:error: cast from ‘void*’ to ‘char’ loses precision
这句话的意思是转变后丢失精度,✔就是把大数变成小数了,再一次思考该函数的使用:给传入的参数进行赋值、起到解析字符串但不自动指定地址的效果。
于是修改为:
*str = (char*)lept_context_pop(c, *len);