前言
平时工作生活非常依赖家里内网设备,搬家后家里电信公网ip还被收回[愤怒],后一直未能寻得一种免费且稳定的中转穿透方案,偶然间发现蒲公英竟然免费开放了自家的路由器OS,心中一动,这不就能白嫖蒲公英的旁路组网了吗(以前可是只能买硬件才能实现),尝试一番后果然在云管理平台可以设置为官方硬件且支持旁路组网,这不掏上了吗,以下是exsi8安装OrayOS的记录。
exsi8安装OrayOS小记
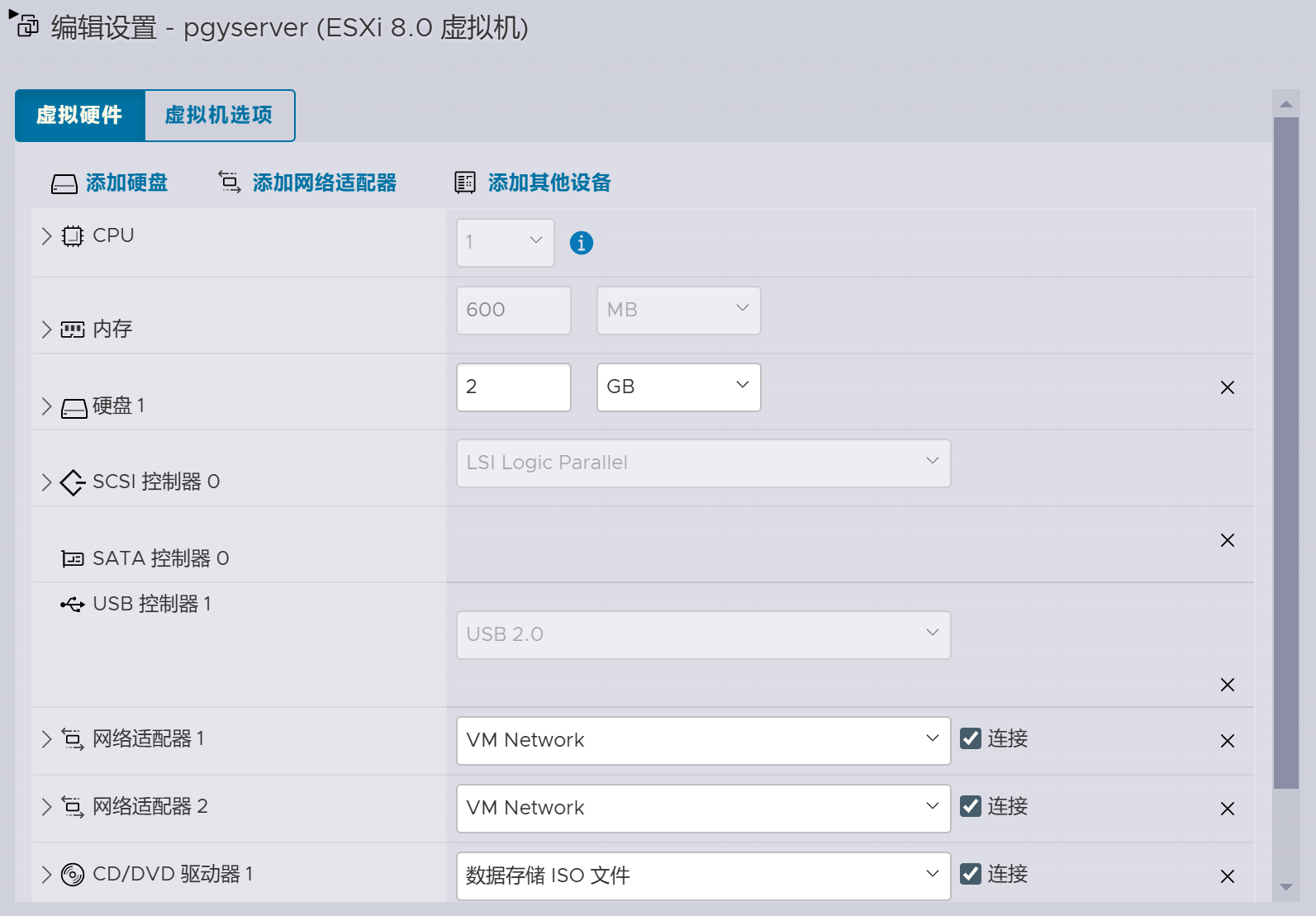
设置虚拟机参数
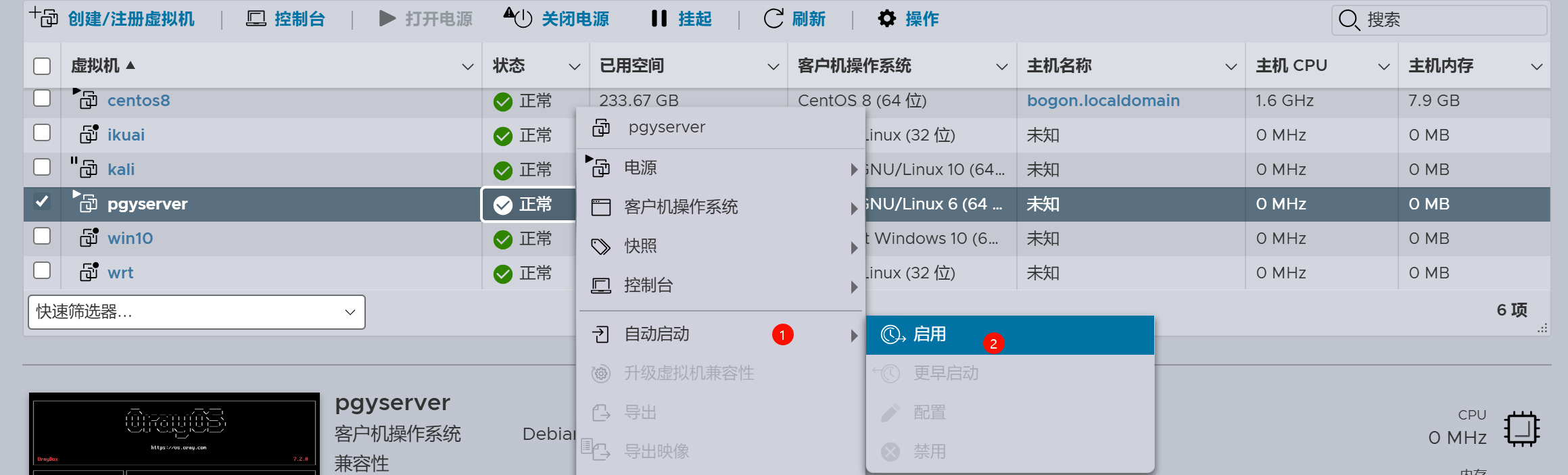
设置自动启动
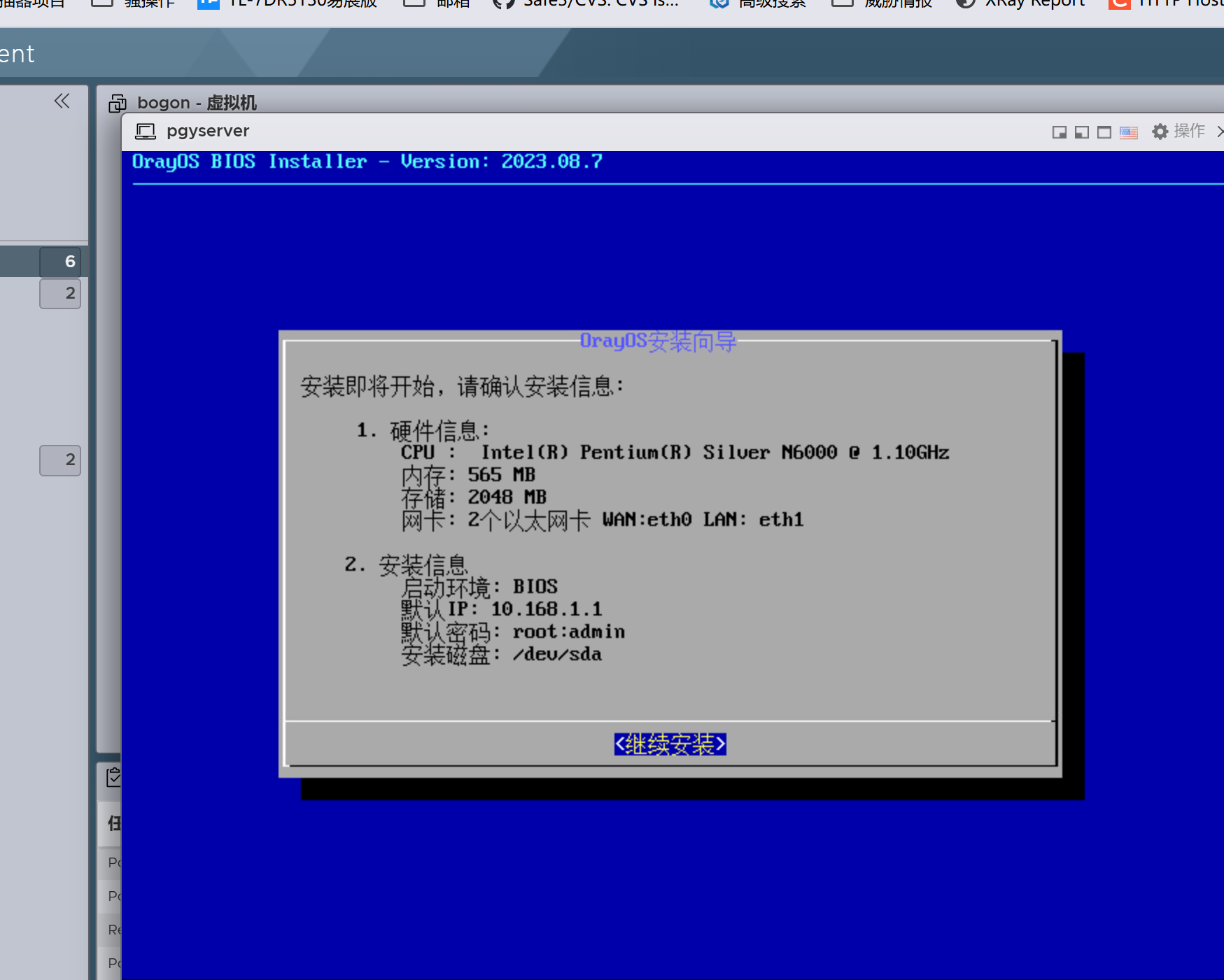
开始启动安装
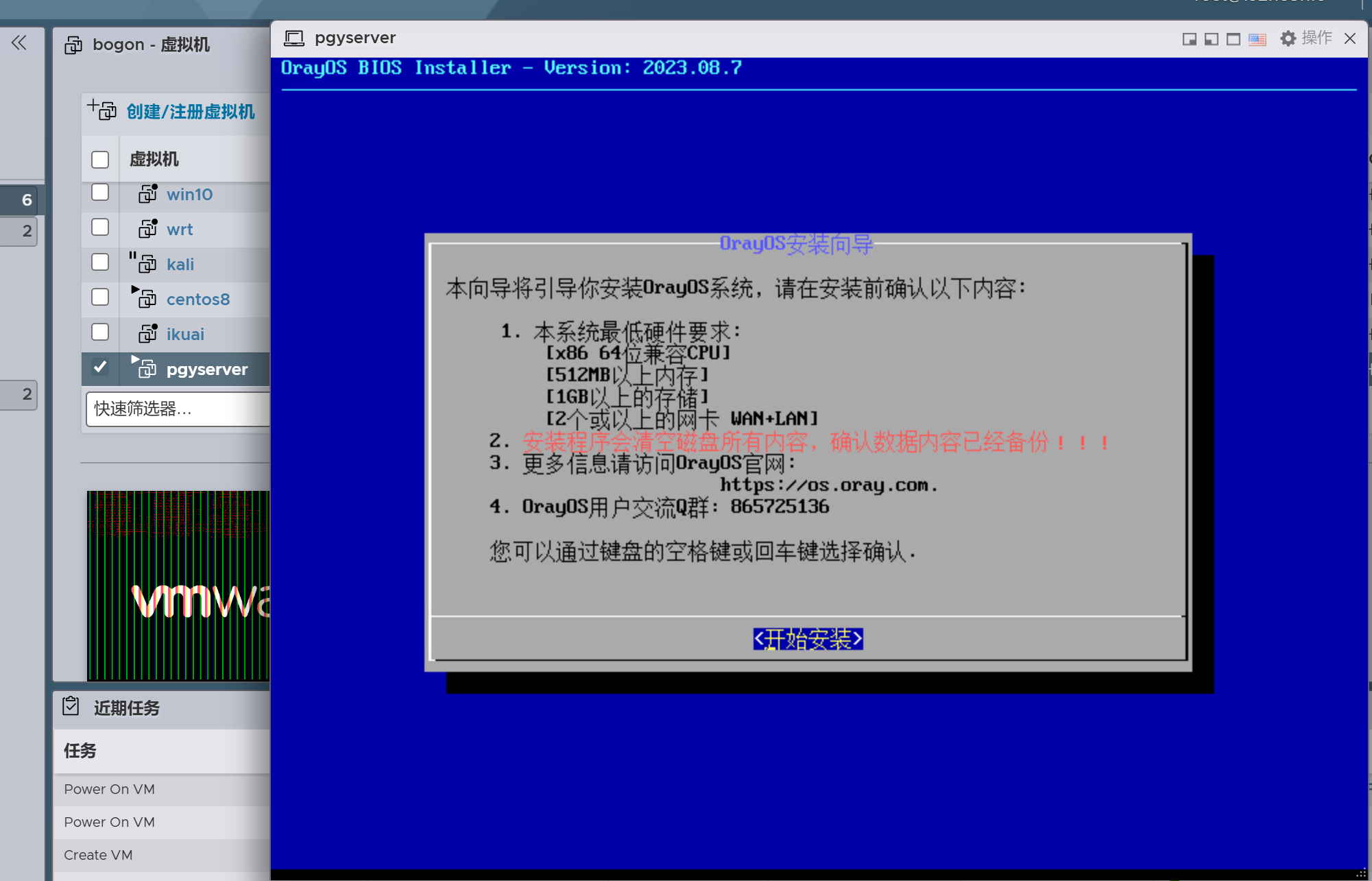
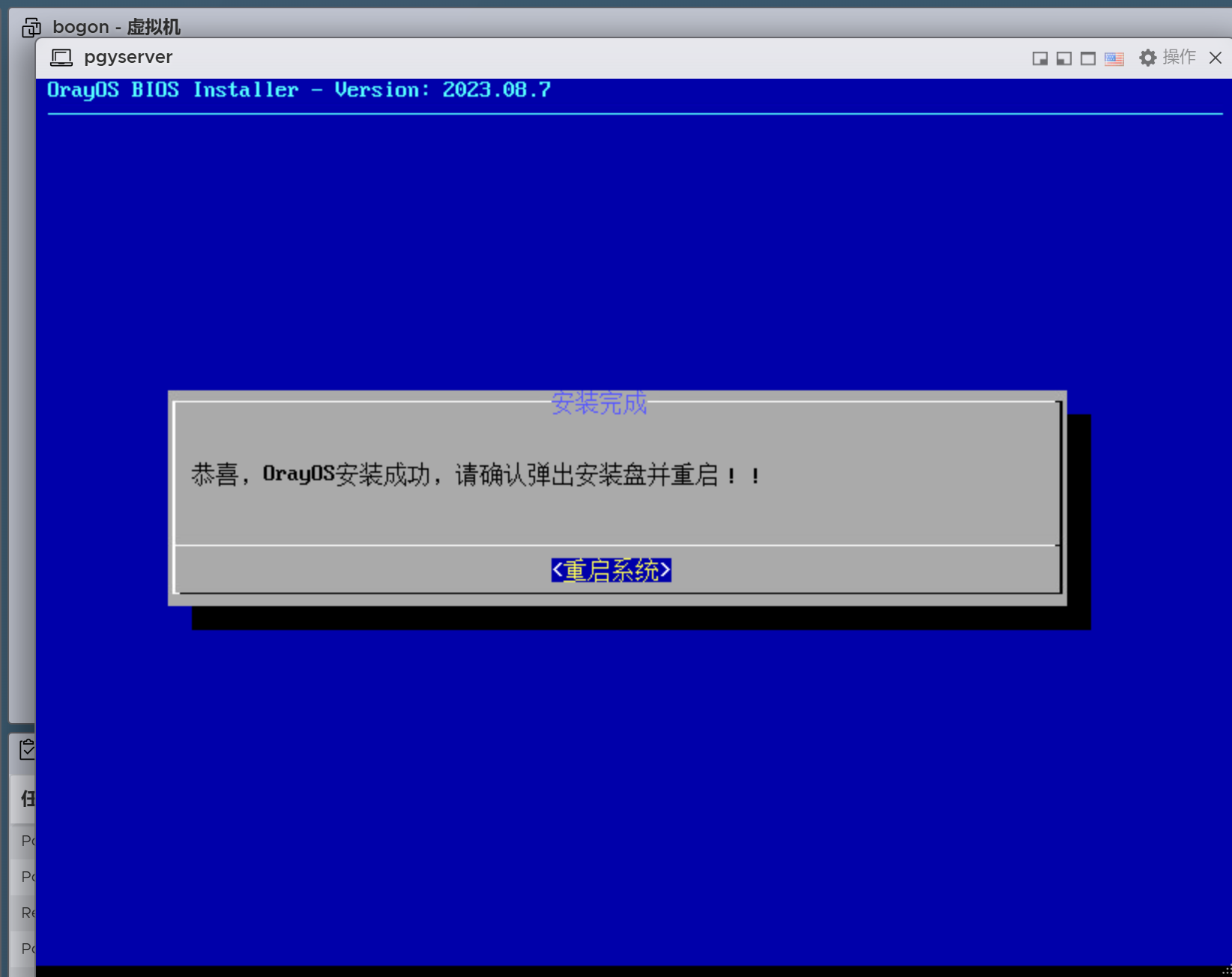
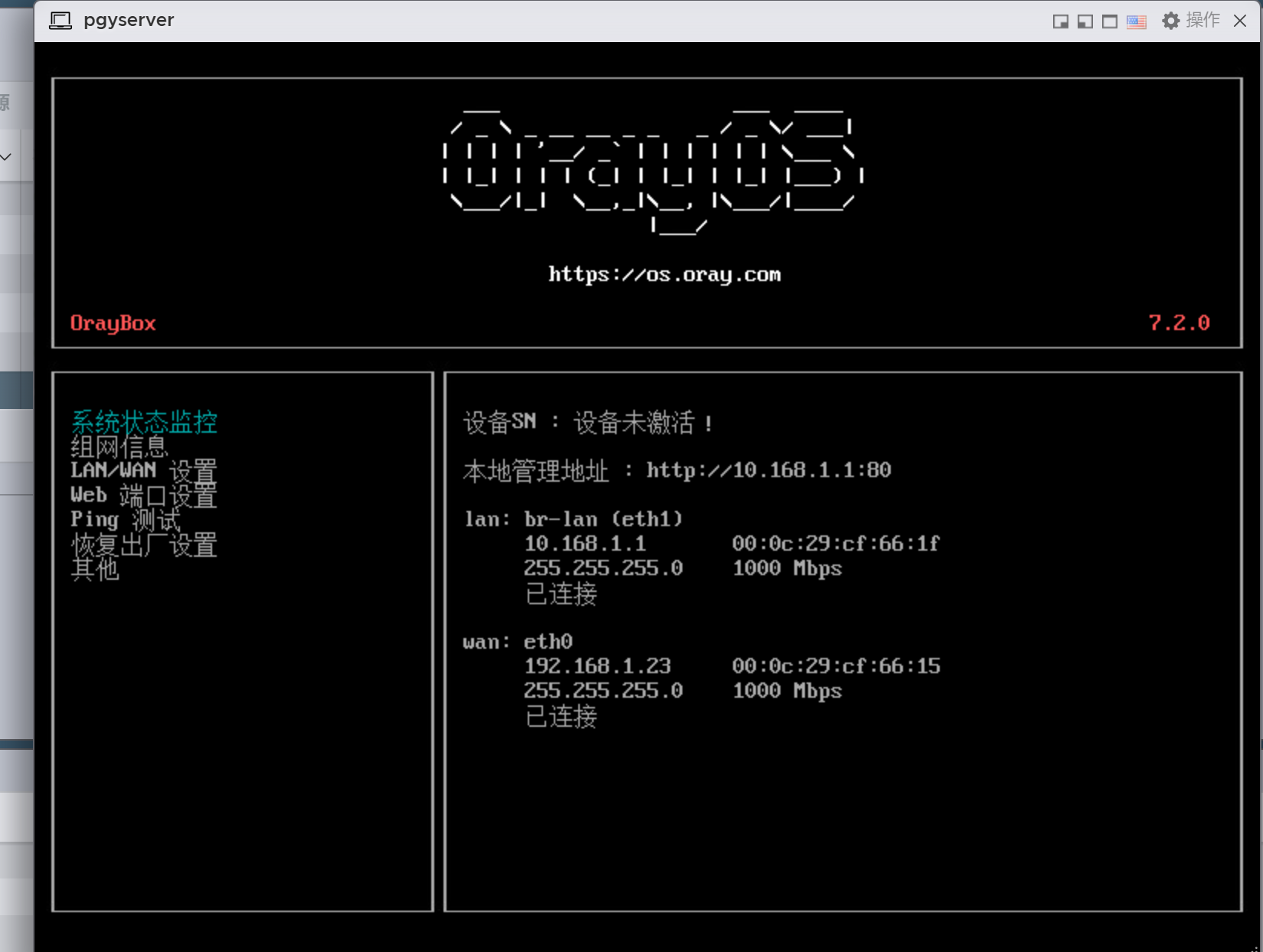
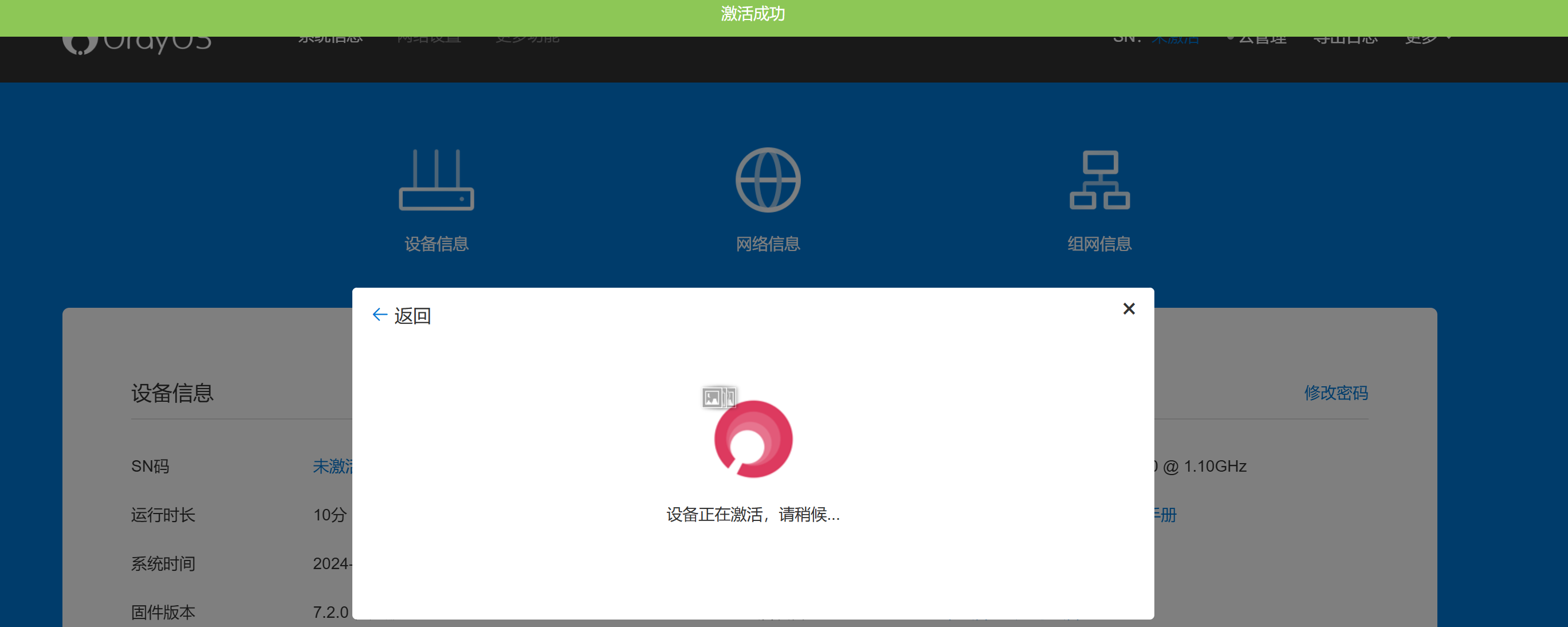
安装完成后显示未激活
输入账号密码进行激活
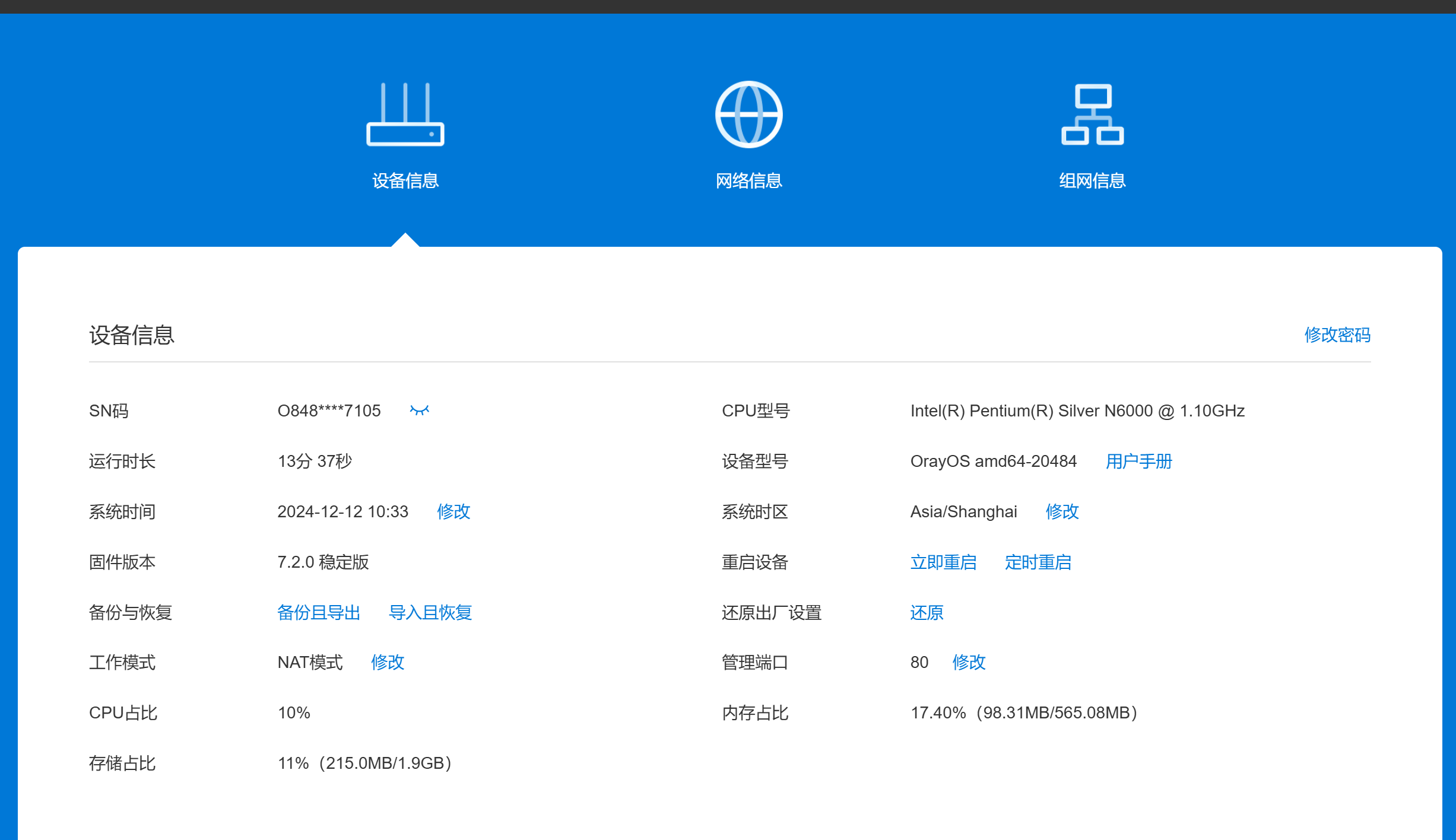
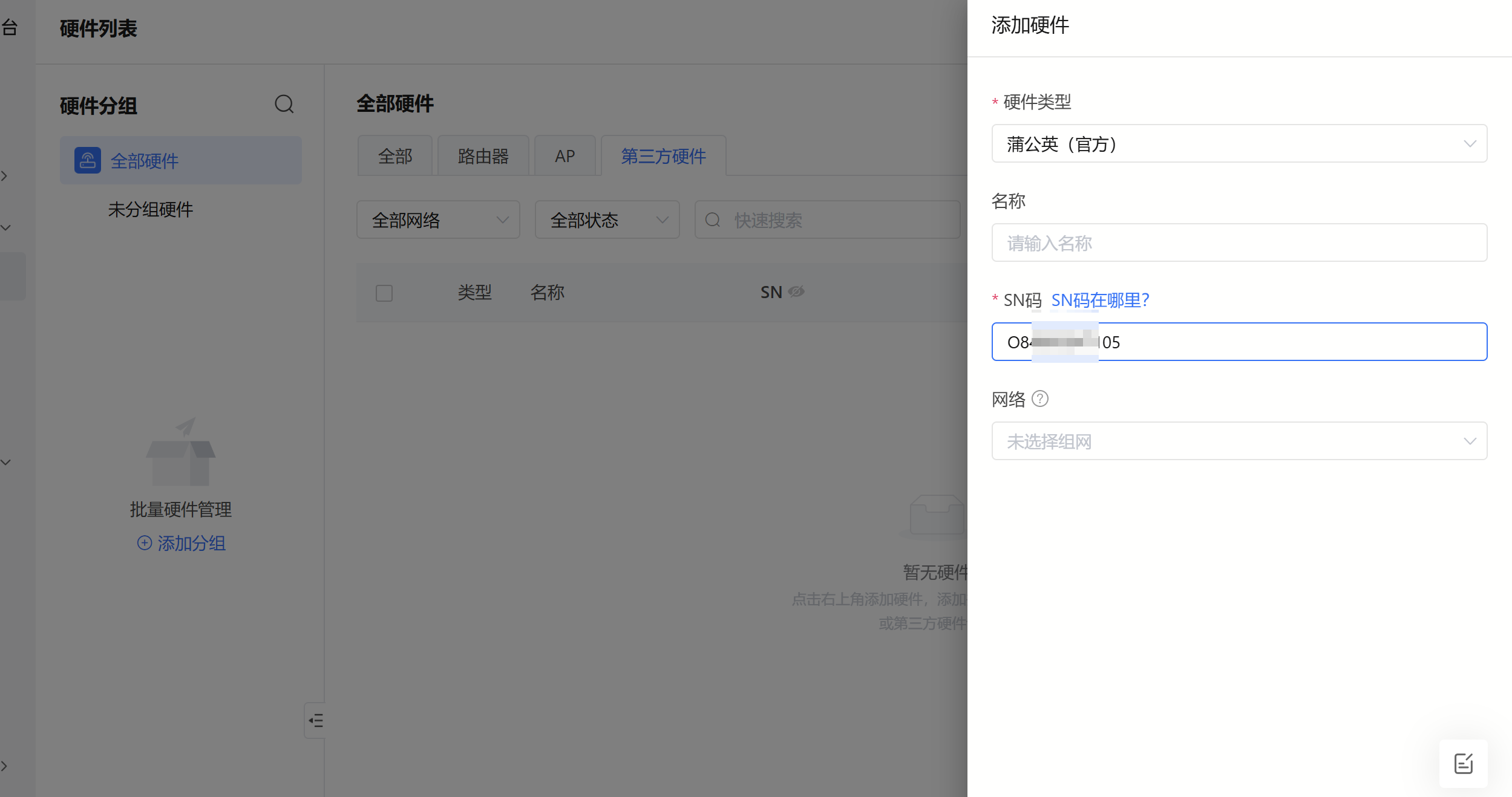
激活后将sn添到硬件列表中,并选择类型为蒲公英(官方)
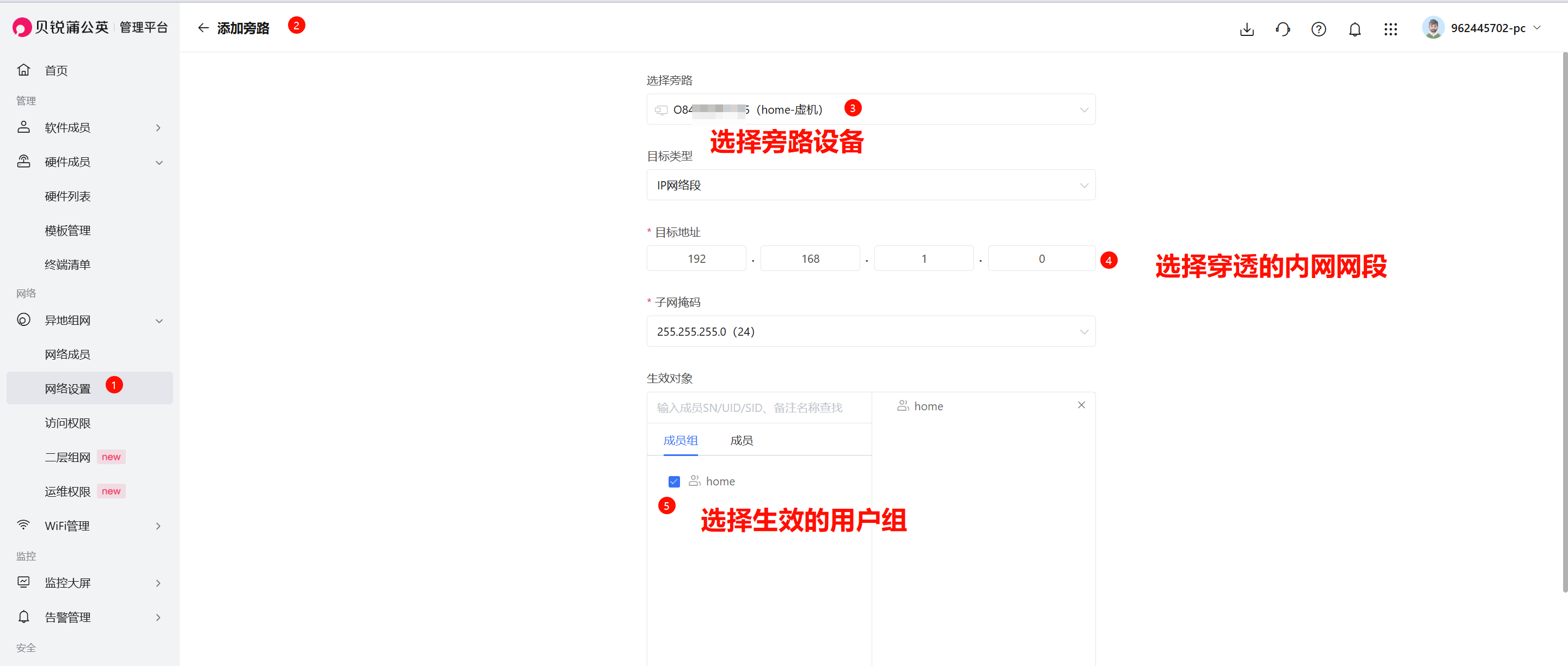
重点来了:设置旁路组网
设置成功后登录pc或手机客户端,三个客户端名额足够使用了
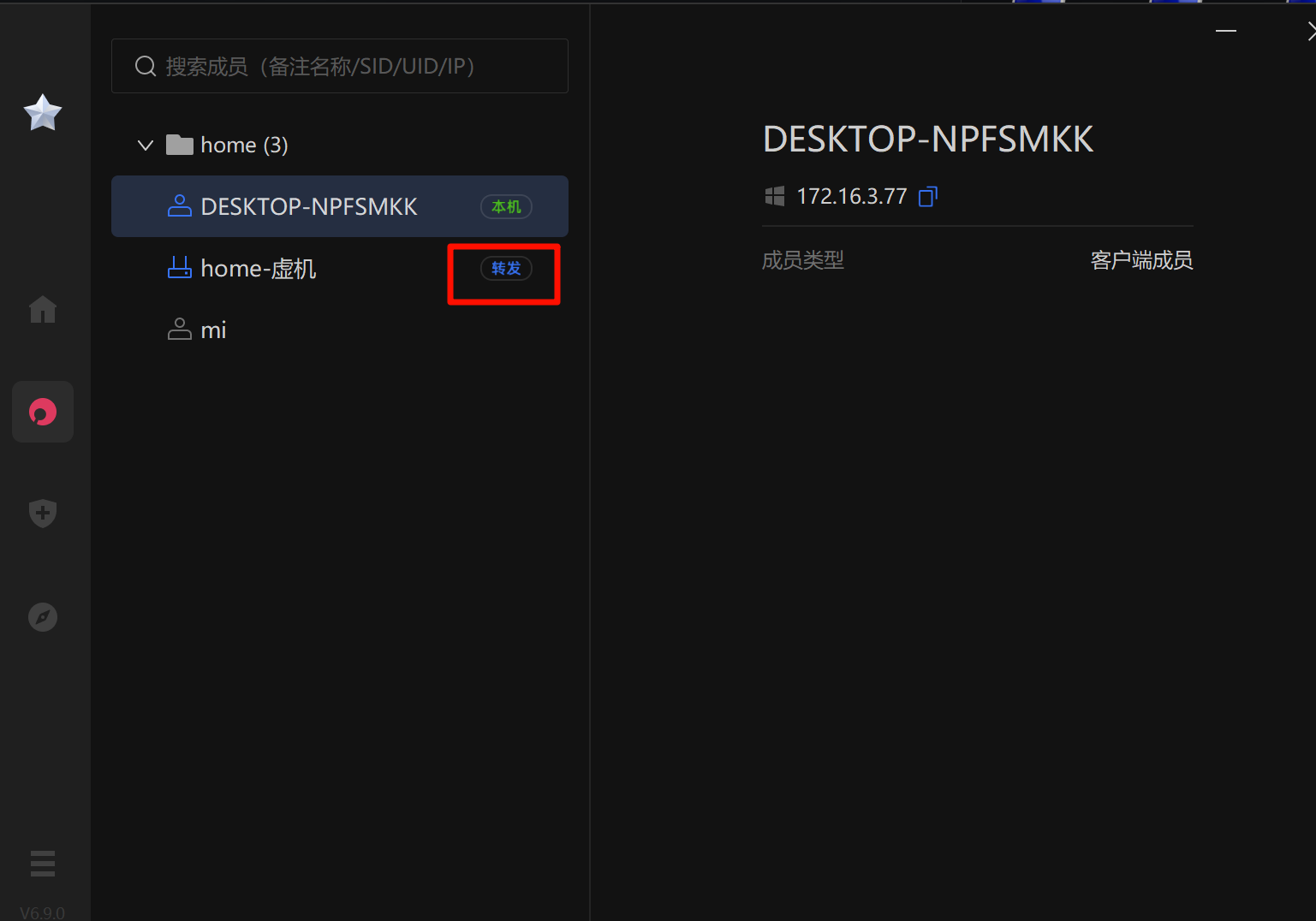
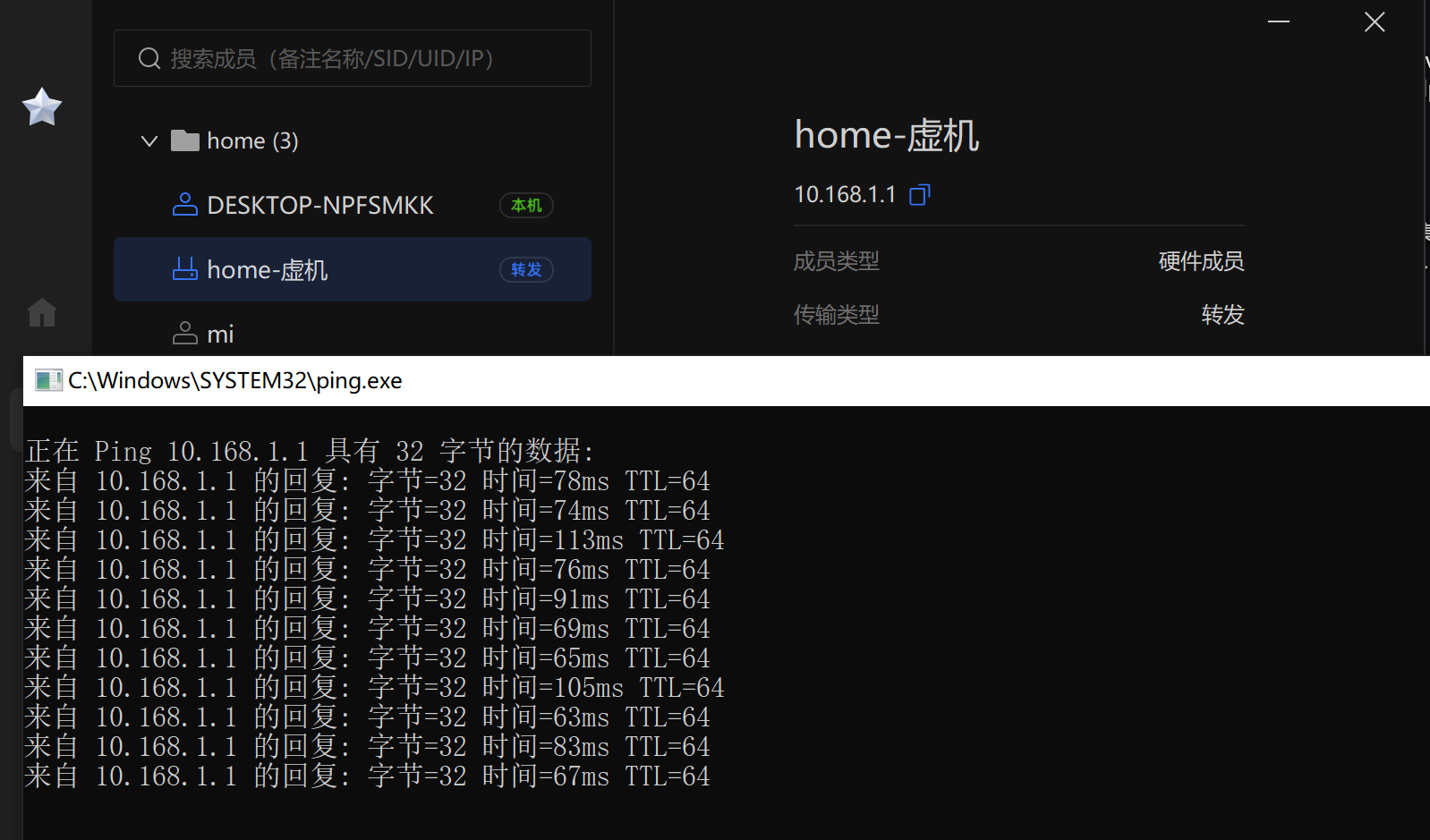
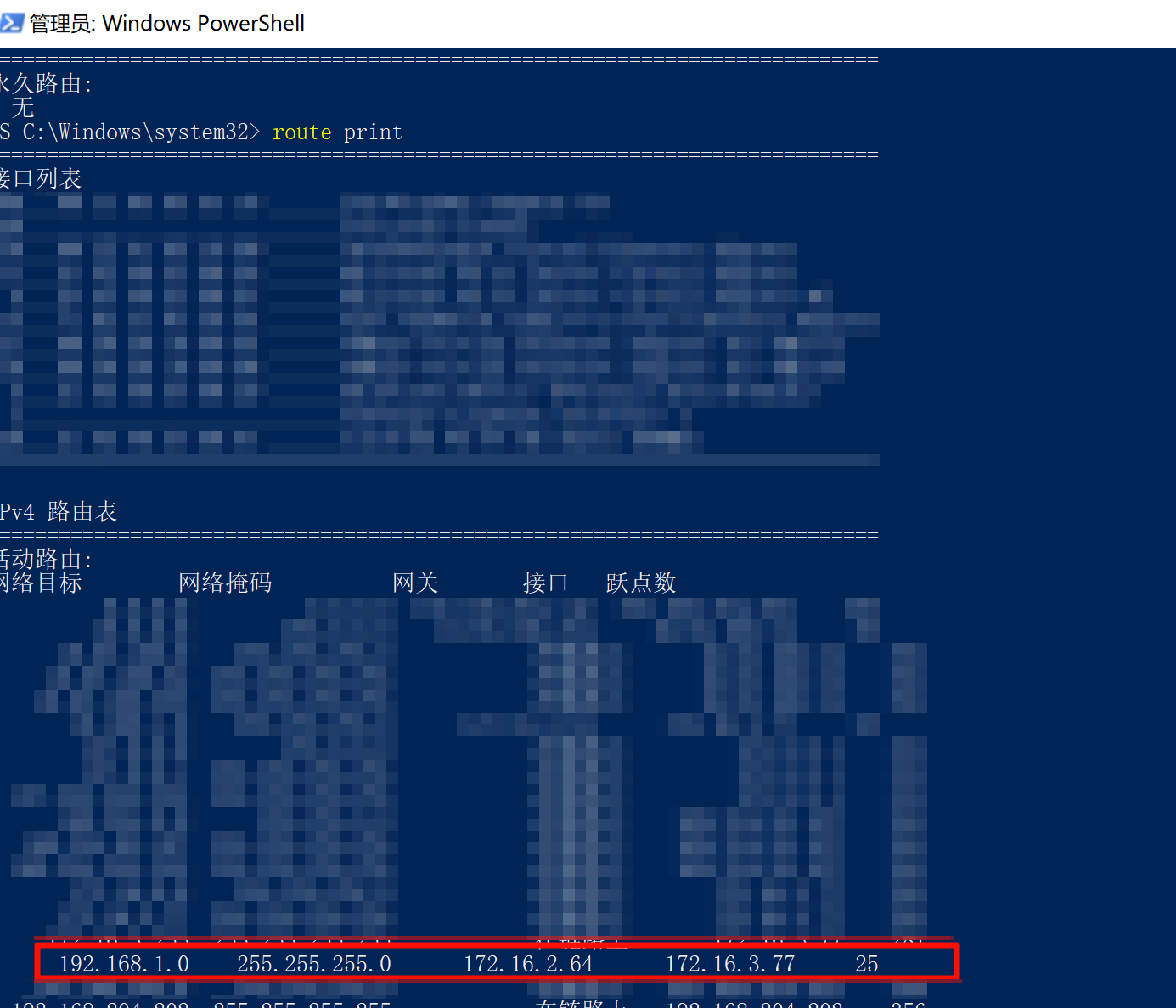
客户端登录后检查一下系统路由
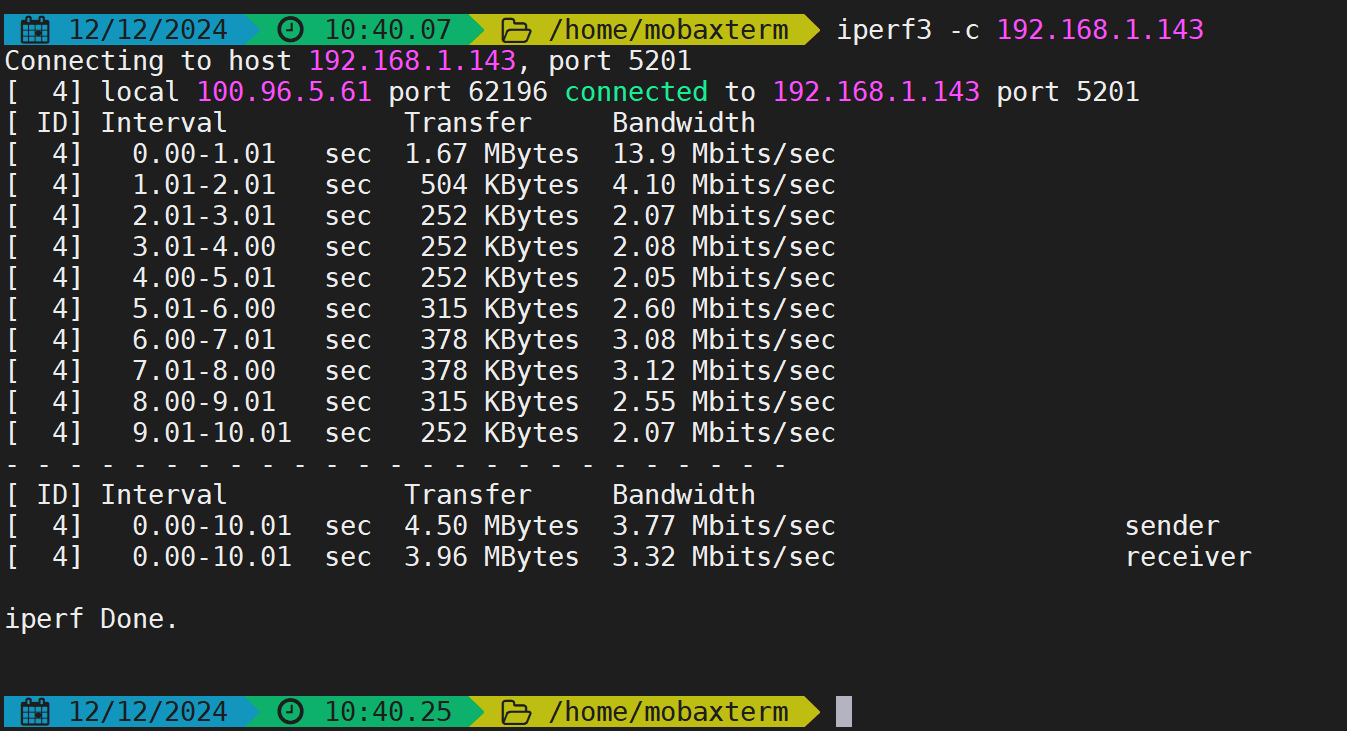
最后,测一下穿透速度,刚刚跑满蒲公英个人免费版的2m转发带宽,延迟也能接受,,爆赞蒲公英哈哈
参考文档
https://service.oray.com/question/35401.html
标签:翻墙,旁路,爆赞,设置,组网,蒲公英,客户端 From: https://www.cnblogs.com/vivovox/p/18602370