本食用方法以[NOIP2024] 树上查询为例
一、题目
仅介绍洛谷食用方法
在洛谷页面
-
首先确保你有洛谷账号 (非常重要,没有账号测试样例无法下载!)
-
在左侧侧边栏点击“题库”,进入洛谷主题库
-
进入题目
P11364 -
请点击题面右上角
复制Markdown标签
-
查看并记住

-
随后翻到题面最下方,点击
*.zip超链接下载测试样例

在思卡奇OJ页面
-
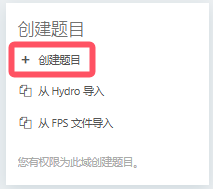
随后转到思卡奇OJ,打开题库,在右侧区块选择
创建题目标签
-
框内为必填项,其他选填

-
填完后点击
创建按钮会自动转到文件配置页 -
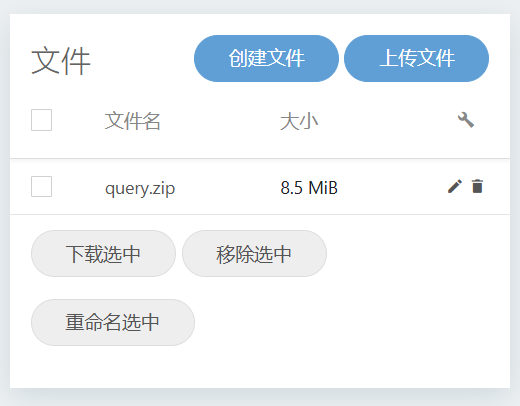
在右侧文件
上传文件上传刚刚下载的zip文件
-
请按下右侧区块选择
评测配置标签 ,在左侧文本编辑区块中填写以下信息:
,在左侧文本编辑区块中填写以下信息:
冒号左右必须跟一个空格
time : 2s // 对应 时间限制
memory : 1g // 对应 内存限制

二、数据
仅介绍Loj食用方法
在Loj页面
-
转到题面页面(和洛谷大差不差),点击右侧
文件标签

-
全选测试数据,打包下载


警告:等待全部下载完成再关闭文件页面,否则会导致下载失败。
在思卡奇OJ页面
-
文件->测试数据

-
在弹出的窗口中,右键下载的文件,重命名为
#后面的一串数字,随后上传,等待上传完成即可。

注:hydro不能识别`#`字符文件,所以要重命名
附:推荐网站
| 网站名 | 网站地址 | 推荐度(1~10) | 能否复制题目格式 | 能否下载测试数据 | 其他 |
|---|---|---|---|---|---|
| 洛谷 | https://www.luogu.com.cn/ | 10 | 可以完整复制题目格式 | 不能下载测试数据 | 带宽高,下载快 |
| Hydro | https://hydro.ac/ | 5 | 可以完整复制题目格式,但比洛谷稍微麻烦 | 不能下载测试数据 | 麻烦 |
| LibreOJ | https://loj.ac/ | 3 | 不能复制题目原格式 | 可以下载测试数据。 | 稍微慢点 |
| UOJ | https://uoj.ac/ | 2 | 不能复制题目原格式 | 不能下载测试数据。 | 不如lg |