PFC(Priority-based Flow Control) PFC是一种基于优先级的流量控制技术,如图所示,DeviceA发送接口被分成了8个优先级队列,DeviceB接收接口则存在8个接收缓存,二者一一对应。DeviceB接收接口上某个接收缓存发生拥塞时,会发送一个反压信号“STOP”到DeviceA,DeviceA则停止发送对应优先级队列的流量。流量控制只针对某一个或几个优先级队列,而不是整个接口的流量全部中断。每个队列都能单独暂停或重启流量发送,而不影响其他队列,真正实现多种流量共享链路。
RoCEv2:RDMA over Converged Ethernet standard
是一种基于以太网的远程直接内存访问协议,旨在通过以太网网络实现高性能、低延迟的数据传输。
RDMA(remote direct memory access):是一种数据传输方式,它允许数据在不涉及主机CPU的情况下从一台计算机的内存传输到另一台计算机的内存。这种方式降低了传统TCP/IP协议栈的开销,提高了数据传输效率。
PAUSE帧:最基本的流量控制技术是IEEE 802.3定义的以太Pause机制:当网络中的下游设备发现其流量接收能力小于上游设备的发送能力时,会主动发Pause帧给上游设备,要求上游设备暂停流量发送,等待一段时间后再继续发送。
DCQCN算法:DCQCN全称为Data Center Quantized Congestion Notification,是目前在RoCEv2网络中使用最广泛的拥塞控制算法,它融合了QCN算法和DCTCP算法
工作原理: 在DCQCN中,当网络设备(如交换机)检测到其缓冲队列长度超过预设的阈值时,它会在数据包上设置一个标志(如ECN位),指示拥塞的存在。 发送方接收到带有拥塞标志的数据包后,会根据该反馈调整其发送速率。通常采用的方法是减小其拥塞窗口大小。 DCQCN还包含了一种机制,使得发送方可以根据拥塞反馈来动态调整其发送速率,而不是简单地减少速率,从而优化了网络资源的使用效率。
QCN(Quantized Congestion Notification,量化拥塞通知)算法:是它提供了一种方式来量化地通知发送者网络中的拥塞程度。与传统的TCP拥塞控制方法相比,QCN允许网络设备(如交换机)在检测到拥塞时,通过特定的标志位来标记数据包,并将拥塞信息量化地反馈给发送方。这样,发送方可以根据接收到的具体拥塞信息来调整其发送速率,而不是简单地依赖于丢失重传或基于延迟的机制。
具体来说,QCN机制包括以下几个方面:
-
拥塞信号的量化:网络设备可以在检测到拥塞时,用不同的级别来标记数据包,表示当前的拥塞状态。
-
接收端反馈:接收端会收集这些标记的信息,并将其反馈给发送端。
-
发送端反应:发送端根据收到的反馈信息调整其发送速率,以减少拥塞。
队头阻塞(Head-of-line blocking或缩写为HOL blocking)在计算机网络的范畴中是一种性能受限的现象。 它的原因是一列的第一个数据包(队头)受阻而导致整列数据包受阻。
FCT通常代表"Flow Completion Time"(流完成时间)。Flow Completion Time是指一个数据流从开始到完全传输完毕所需的时间。
“Backpressure”(反压或背压)是一个网络术语,指的是一种流量控制机制,当接收端无法处理发送端传来的数据时,它会通知发送端减慢发送速度或暂时停止发送数据,以此来防止数据溢出或丢包。
ECN(Explicit Congestion Notification,明确拥塞通知)
-
标记而非丢弃:当路由器检测到拥塞时,它不会简单地丢弃数据包,而是修改数据包的IP头部中的ECN字段。通常情况下,ECN字段会被设置为“CE”(Congestion Experienced,经历了拥塞)。
-
发送端的响应:当接收端(如接收主机或中间路由器)收到带有CE标记的数据包时,它会在返回给发送端的ACK(确认)报文中反映这一情况。发送端在收到这样的ACK后,就会知道网络中存在拥塞,并相应地减少其发送速率。
cnp(Congestion Notification Packet) :拥塞通知方式,是在转发设备上发现队列拥塞后,由转发设备向宿端服务器发送ECN拥塞标记报文。 宿端服务器收到ECN拥塞标记报文后,向源端服务器发送CNP拥塞通知报文,以通知源端服务器降低发包速率。
ECMP(Equal-cost multi-path)
ECMP是一个逐跳的基于流的负载均衡策略,当路由器发现同一目的地址出现多个最优路径时,会更新路由表,为此目的地址添加多条规则,对应于多个下一跳。可同时利用这些路径转发数据,增加带宽。
下面四种数据中心网络拓扑架构
CLOS Networking
CLOS 网络的核心思想是:用多个小规模、低成本的单元构建复杂,大规模的网络。简单的 CLOS 网络是一个三级互连架构,包含了输入级,中间级,输出级。
下图中,m 是每个子模块的输入端口数,n 是每个子模块的输出端口数,r 是每一级的子模块数,经过合理的重排,只要满足 r2≥max(m1,n3),那么,对于任意的输入到输出,总是能找到一条无阻塞的通路。

Switch Fabric
Switch Fabric 指交换机内部连接输入输出的端口,最简单的 Switch Fabric 架构是 Crossbar 模型,这是一个开关矩阵,每一个 Crosspoint(交点)都是一个开关,交换机通过控制开关来完成输入到特定输出的转发。一个 Crossbar 模型如下所示:

胖树(Fat-Tree)型网络架构

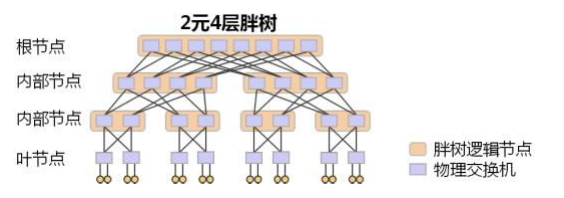
每一层的物理交换机数量一样,所以能保证其带宽是无收敛的。
叶脊(Leaf-Spine)架构
二层结构,简化了传统的clos三层结构。它的特点是无阻塞(non-blocking)和对称性,可以提供高性能的数据中心内部通信。
describe: There are four ToRs (T1-T4),four leaves (L1-L4) and two spines (S1-S2). Each ToR represents a different IPsubnet.

各个名词解释:
-
ToRs (Top-of-Rack switches): 这里提到有四个ToR交换机。ToR交换机通常是位于机架顶部的交换机,用于连接同一个机架内的服务器到外部网络。
-
Leaves: 这里提到有四个叶子节点(Leaves。在数据中心网络架构中,“叶子”通常指的是那些直接与ToR交换机相连的交换机,它们构成了网络的边缘部分。
-
Spines: 这里提到有两个脊节点(Spines)。脊节点处于网络的核心位置,负责连接所有的叶子节点,提供高带宽、低延迟的数据交换路径。
RPC,全称为Remote Procedure Call,即远程过程调用,是一种计算机通信协议,它允许程序调用位于不同计算机或网络环境中的另一程序或服务,就像调用本地程序一样.
BDP stands for "Bandwidth-Delay Product.“带宽延迟乘积”,代表了可用带宽(单位时间内能传输的最大数据量)与往返时间(RTT,数据包从发送方到接收方再返回所需的时间)的乘积。
parking lot problem
因为就像停车场中的车辆一样,当一个入口处的车辆较少时,它可以更快地进入停车场(即获得更高的吞吐量),而其他入口处的车辆较多时,则会导致更多的等待时间(即较低的吞吐量)。这个问题突显了在网络设计和流量控制机制中需要考虑公平性和效率之间的平衡。
Congestion Control for Large-Scale RDMA Deployment
1.解决了什么?
使用DCQCN采用钝而快速的PFC流控制,及时防止丢包;采用细粒度的慢端到端拥塞控制,调整发送速率,避免持久触发PFC。实现低延时,高吞吐和低cpu利用率的实现
2.方法核心思想是什么?
3.设计细节和评价.
Credit-Scheduled Delay-Bounded Congestion Control
1.解决了什么? ExpressPass解决了数据中心网络中由于小的往返时间(RTTs)、突发流量到达和大量并发流(数千个)带来的拥塞控制难题。
方法核心:ExpressPass的核心思想是使用信用包在发送数据包之前就控制拥塞,从而实现受限的延迟和快速收敛。系统优雅地处理突发的流到达,并在多瓶颈情况下避免低链路利用率问题。信用包被速率限制,确保在任何时刻不会超过链路容量的一定比例(如5%),剩余的95%用于数据包传输。通过精细设计的信用反馈环路,系统确保了高利用率、公平性和快速收敛,同时限制队列增长以防止数据丢失。
设计细节:
-
信用与数据包调度:确保数据包的调度不会因为不同路径的RTT差异而中断,导致队列积压。
-
公平性与多瓶颈处理:解决多瓶颈问题,确保所有流公平分享带宽,同时维持高链路利用率。
评价:
-
性能表现:ExpressPass相比DCTCP在10Gbps链路上的收敛速度快80倍,且随着链路速度增加,性能优势更加明显。
-
负载均衡与流完成时间:在重载入工作负载下性能显著提升,特别是对于小和中型流,与RCP、DCTCP、HULL和DX相比,流完成时间大幅减少。
Bolt
-
解决什么问题? Bolt解决的问题是针对数据中心网络中由于带宽增加至200Gbps及以上所带来的挑战,尤其是更大的带宽延迟乘积(BDP)导致的网络传输对拥塞更加敏感,以及对拥塞控制(CC)算法提出更高要求的问题。
-
方法核心思想是:
子RTT控制(SRC):比基于RTT的控制环路更快地对拥塞做出反应,减少了控制决策的延迟。
主动增涨(PRU):预见未来流完成情况,迅速占用释放的带宽,避免带宽未充分利用。
供需匹配(SM):明确匹配带宽需求与供应,以最大化利用率。
-
设计细节和评价
最小化反馈延迟:在交换机上生成拥塞通知并直接反射给发送者,减少反馈时间。
流完成事件预示:发送者提前发出流完成信号,隐藏增涨延迟,避免欠利用。
快速稳定:每次收到反馈后更新cwnd,最多每数据包更新一次,以抵抗观测噪声。
实现亚RTT级的精确拥塞控制是可行的,显著提升了网络性能
标签:数据中心,人门,网络,带宽,发送,拥塞,交换机,数据包 From: https://www.cnblogs.com/shangguanhao/p/18551853