压缩包明文攻击
1.工具:ARCHPR
下载链接:点击下载
2.明文攻击特征:
①已知加密压缩包中的一个文件
确定相同文件就是比对crc32的值(可以把得到与压缩包内名称相同的文件进行压缩,观察crc32的值)
初步判断可以是比对文件大小,和文件name,这个文件一定要保证完全一致。
攻击需要至少12字节的已知明文,其中至少8个必须是相连的,连续的已知明文越大,攻击越快。
②在进行明文攻击时,压缩算法一定要相同
比如可能提示你存储,快速啥的,这就要在压缩已知文件时的压缩方式选存储等等,还有就是算法(这里可以多种压缩软件都试试, 比如winrar、7-z、好压等)使用ZipCrypto的加密条目容易受到已知明文攻击。
以上算是完成了明文攻击的准备条件,接下来上工具!
举个例子:
比如这里有个压缩包,但是我不知道密码
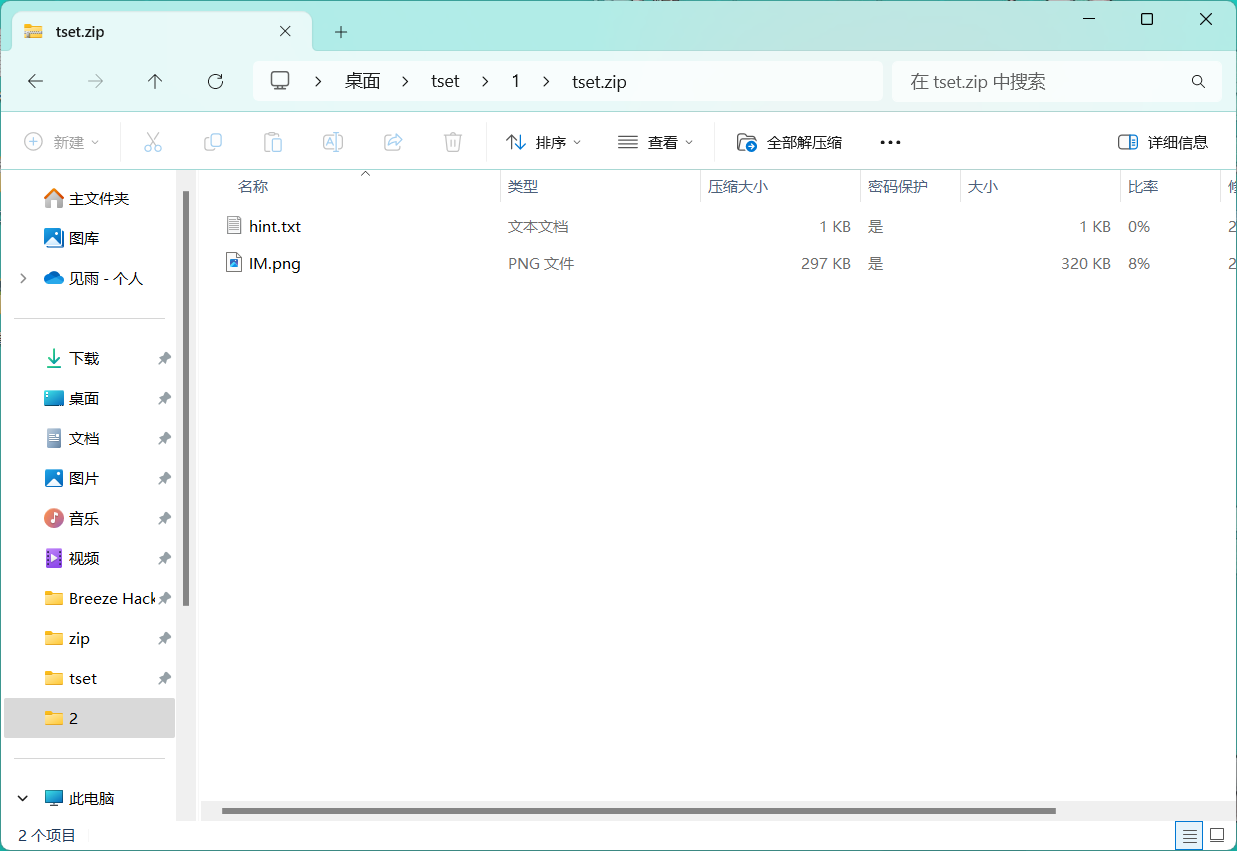
但是假设我们得到了压缩包里面的hint.txt文件,并且得知该文件的内容与压缩包内的一致,然后可以打开压缩包观察里面的CRC值和压缩算法,我们需要将已知的hint.txt文件压缩为相同的值
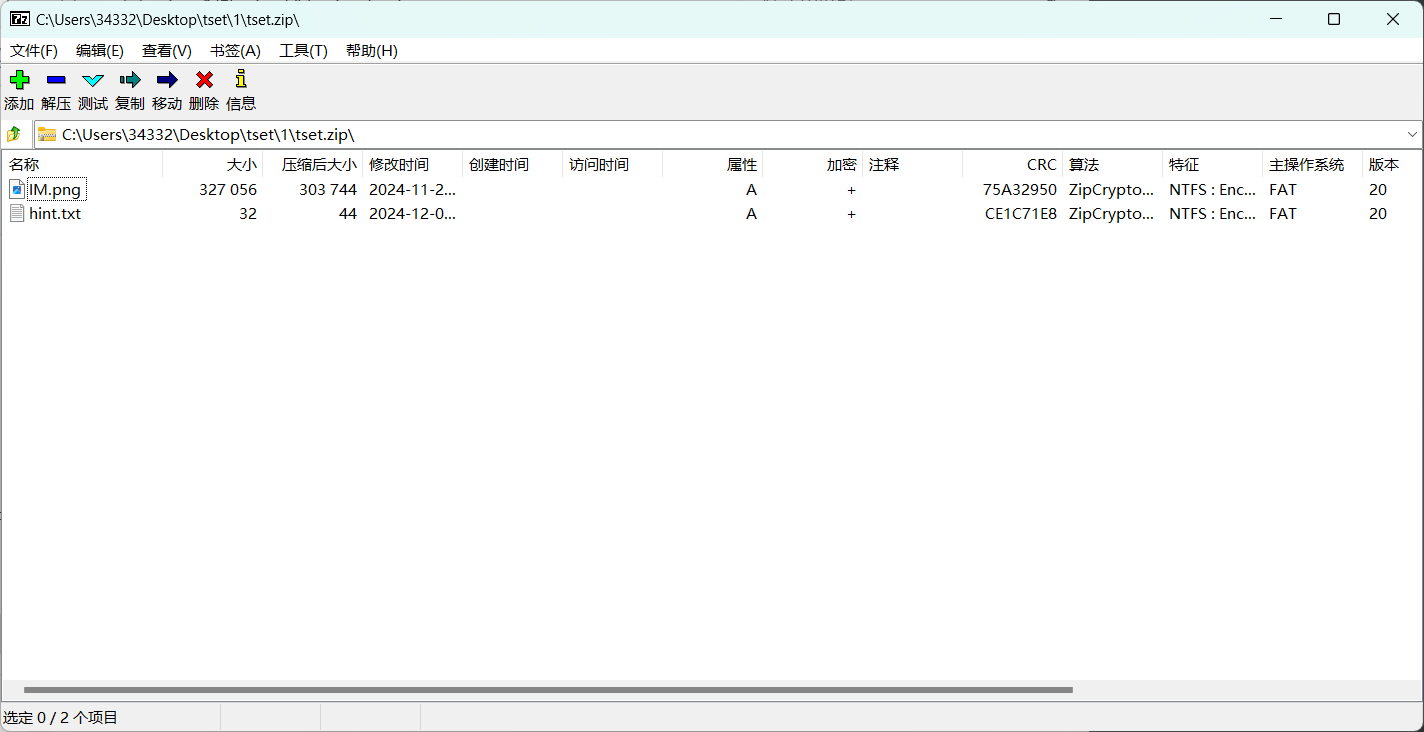
经过压缩hint.txt文件后得到了一个CRC值和压缩算法与加密压缩包相同的压缩包
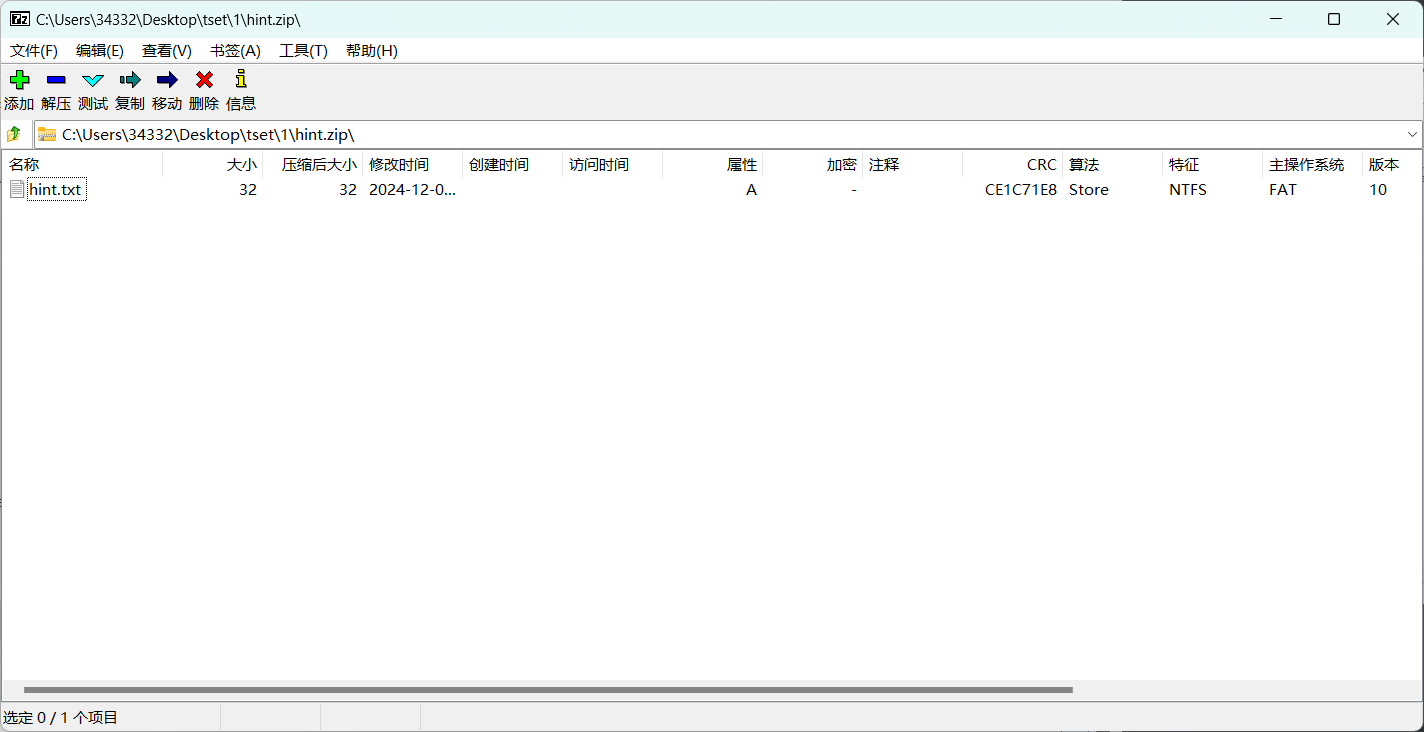
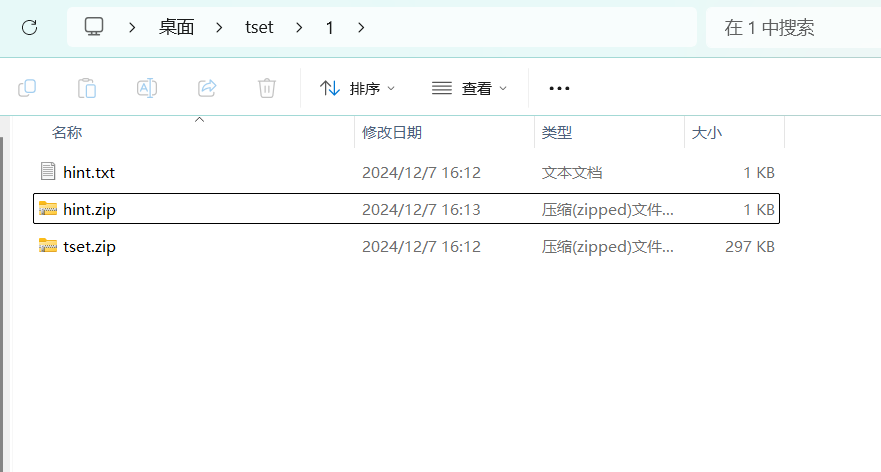
然后我们就可以尝试进行明文攻击了
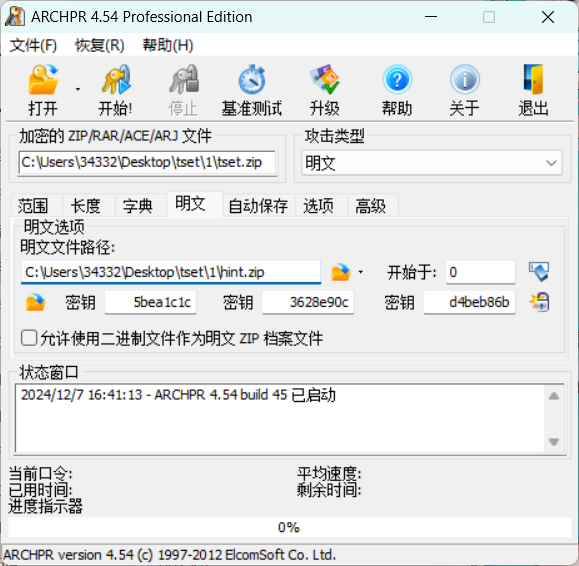
开始之后我们等待一会就可以的到这个压缩包的密码了,如果等待时间太长(比如要几个小时甚至几天)可能说明你构造的明文压缩包不正确
最后可以得到压缩包密码为:asdfghjk
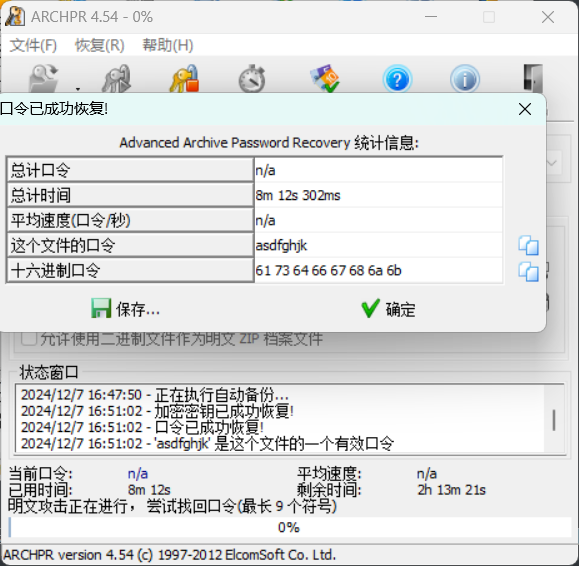
用密码解压后可以看到被加密的文件
 标签:文件,攻击,明文,已知,压缩算法,压缩包
From: https://www.cnblogs.com/start1/p/18592457
标签:文件,攻击,明文,已知,压缩算法,压缩包
From: https://www.cnblogs.com/start1/p/18592457