在大语言模型(LLM)快速发展的背景下,研究者们越来越关注如何通过多代理系统来增强模型性能。传统的多代理方法虽然避免了大规模再训练的需求,但仍面临着计算效率和思维多样性的挑战。本文提出的稀疏代理混合(Sparse Mixture-of-Agents, SMoA)框架,通过借鉴稀疏专家混合(Sparse Mixture-of-Experts, SMoE)的设计理念,有效解决了这些问题。
基础架构:MoA模型
在介绍SMoA之前,需要先了解基础的混合代理(Mixture-of-Agents, MoA)架构。在MoA中,系统包含l层,每层包含n个提议者(proposer)。其核心运算可以通过以下公式表示:
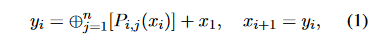
其中:
- P_i,j 表示第i层的第j个提议者
- x_i 是输入文本
- ⊕ 表示聚合-综合提示操作
- y_i 是第i层的输出
最终输出通过聚合器(Aggregator)生成:
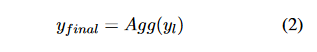
SMoA架构解析
SMoA(Sparse Mixture-of-Agents)的架构设计融合了多层级代理交互和稀疏化处理,主要包含以下核心组件:
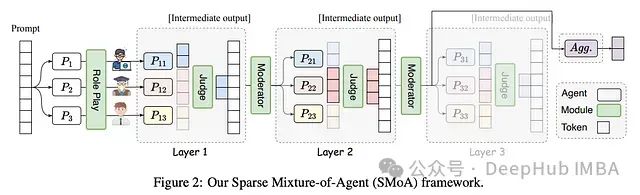
- 输入层:接收初始提示(Prompt)
- 处理层:包含多个并行的代理模块
- 输出层:生成最终响应
https://avoid.overfit.cn/post/ace63f7d197a44d6b0ce7086d0e5ba15
标签:Mixture,架构,稀疏,代理,Agents,MoA,SMoA From: https://www.cnblogs.com/deephub/p/18543204