专业写代码的开发者有很多,相比之下有自己的服务器的开发者绝对是寥寥无几。原因无非以下几点:
- 不知道云服务器有哪些用途。
- 以为云服务器很贵(实际上也不便宜,毕竟服务器本身就不是很大众的东西)。
本文就详细介绍一下个人购买云服务器有哪些用途、怎么只花99元/年就购买一台2核2G 40G SSD的云服务器(续费也是永久99元/年)、以及怎么部署自己的第一个网站。
99元/年购买一台2核2G 40G SSD的云服务器,续费永久不涨价,且拥有公网ipv4地址,3Mbps外网带宽,新人更是首年79元。这绝对是你能买到的最便宜、性价比最高的服务器。年轻人的第一台云服务器,你值得拥有!!!通过本文分享的专属链接,新用户可以再享8.5折,即
85元/年 !!!,指定新人专享服务器只需要79元/年,优惠后只需要67元/年 !!!
云服务器的用途
1. 部署个人博客
利用云服务器,你可以通过安装博客程序(例如WordPress、Hexo等)快速搭建属于自己的博客,记录技术、生活或兴趣点。再花几块钱买一个域名,你就有了一个完全属于自己的网站,上传上自己的简历,面试官绝对会高看好几眼。
2. 部署中小型Web应用
开发者可以将自己开发的小型应用程序部署到云服务器上,方便他人访问和使用。比如:管理系统、小型商城等。一个正规的web应用要部署到生产环境,一般包含nginx、数据库、后端服务(一般是java),2核2G的配置绰绰有余。
3. 内网穿透
所谓内网穿透就是可以通过互联网访问到你家里/公司里的网络。通过工具(如frp或ngrok),云服务器可以作为桥梁,实现家庭网络内设备的远程访问。
例如,你家里有一台NAS,或者存储空间很大的电脑,通过内网穿透,你可以通过手机就把照片、视频上传到自己家里的电脑上,也可以在线浏览,完全可以当一个网盘使用。就不用再花25¥/月的钱购买某度网盘会员了。
但是内网穿透需要服务器拥有一个公网IPV4地址和外网带宽(带宽越大,上传下载越快),由于IPV4地址越来越稀缺,IPV4的价格越来越高,单独购买一个公网IPV4地址和3Mbps的外网带宽的价格都已经超过了99/年!所以如果你搜索内网穿透产品,会发现几乎所有的内网穿透都是需要会员的,且每年费用绝对超过这个价格。即使是免费的,也会有各种限制,带宽小得可怜,简直就是鸡肋。
4. Linux学习
如果你想成为一个高级开发,无论是前端还是后端,对于Linux的学习和了解都是不可忽略的一关。如果一个开发不了解Linux或者不会使用Linux系统,那么可以断定他的技术不会好到哪里去。
云服务器提供一个长期可用的Linux环境,非常适合用来学习命令行操作、服务器管理、开发运维等技能。
5. 静态服务器
将服务器作为静态资源服务器,存储并分发如图片、文档、文件等静态资源,适合前端开发者测试静态页面或作为CDN源站。非常适合用于不追求高可用的中小型应用。这种场景下,如果使用OSS服务,每月的访问费用可能都会让你破产。
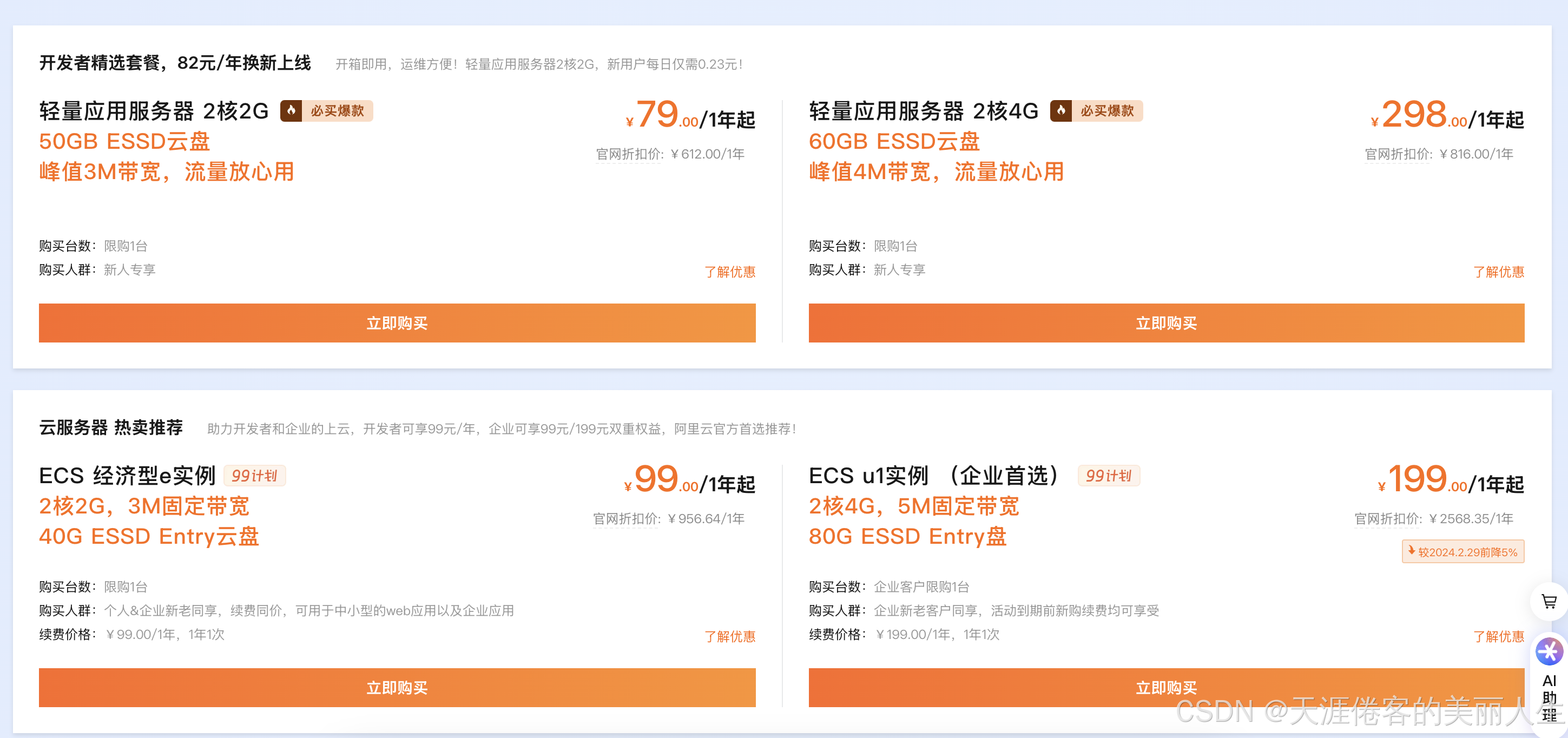
购买云服务器
说了那么多,那么怎么去购买云服务器呢?接下来一定要按照以下的步骤去操作,否则无法享受优惠,再后悔也没用了。
1. 点击专属链接
如果你没有阿里云账号,先进行注册。注册完成后,登录账号。
2. 下单购买
回到第1步的专属链接页面,新用户领取8.5折优惠券。
然后点击对应服务器下方的立即购买按钮进入下单页面:
4. 初始化服务器
点击立即购买后,右侧会弹出服务器初始化页面,镜像建议选择Ubuntu/Ubuntu 24.04 64位,其余默认即可。
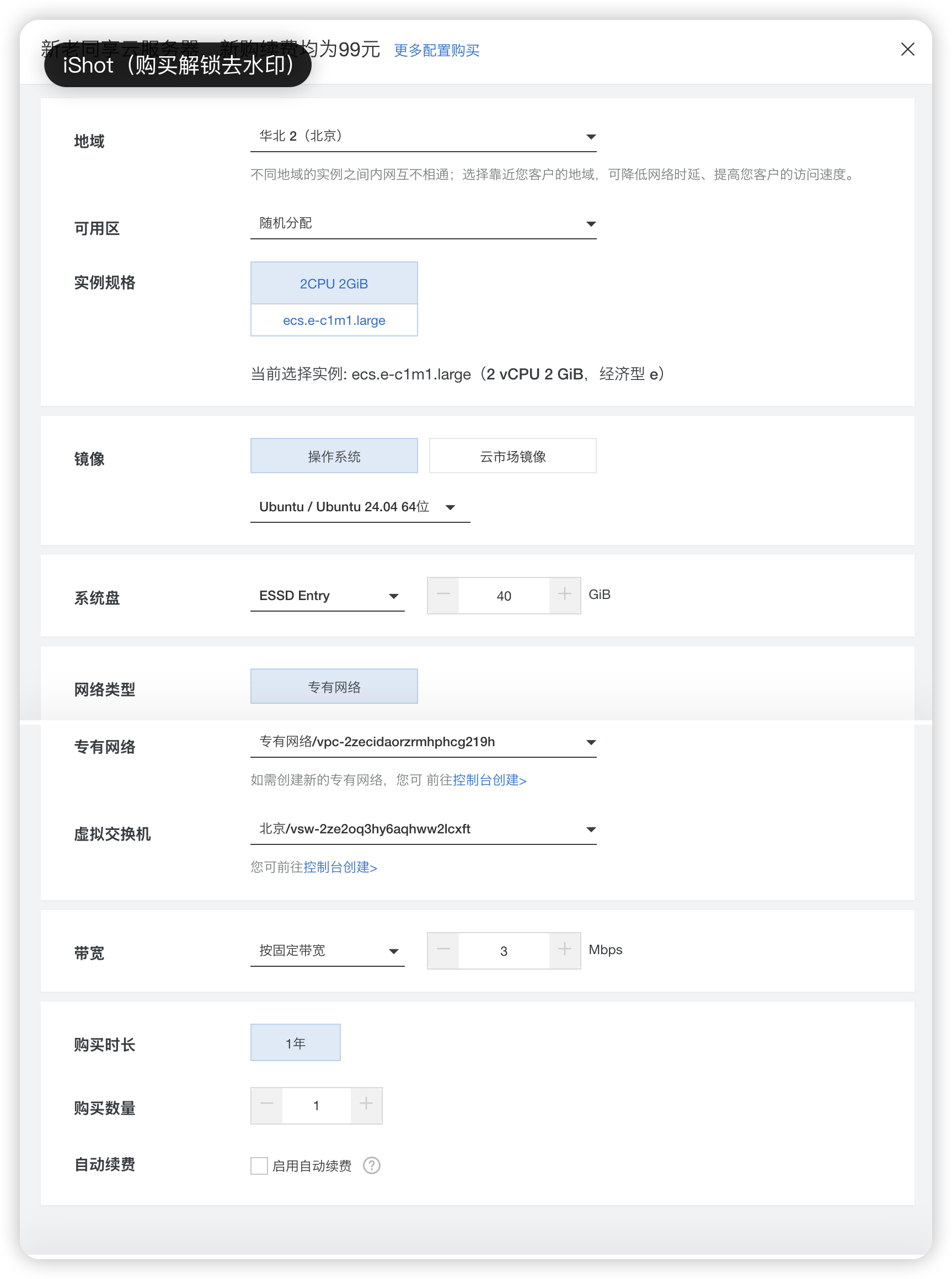
点击右下角的立即购买按钮,跳转到下单页面。下单完成后可以在阿里云控制台首页看到自己有了一台ECS服务器,在这里可以查看服务器的状态,也可以直接登录服务器。下一步的部署操作就需要我们先登录服务器。
部署网站
1. 安装Nginx
登录云服务器后,执行以下命令安装Nginx:
sudo apt update
sudo apt install nginx
安装完成后,可以通过以下命令启动Nginx服务:
sudo systemctl start nginx
确认Nginx正常运行:在浏览器中访问服务器公网IP,应该能看到默认的Nginx欢迎页面。
2. 配置反向代理
编辑Nginx配置文件,为你的网站创建反向代理。命令如下:
sudo tee /etc/nginx/conf.d/default.conf <<-'EOF'
server {
listen 80;
server_name localhost;
location /speed {
alias /usr/share/nginx/html/;
index index.html index.htm;
}
}
EOF
3. 编写静态页面
在/usr/share/nginx/html目录下创建一个index.html文件,命令如下:
mkdir -p /usr/share/nginx/
sudo tee /usr/share/nginx/index.html <<-'EOF'
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>我的第一个网站</title>
</head>
<body>
<h1>欢迎访问我的第一个网站
标签:教程,nginx,sudo,99,Nginx,购买,服务器
From: https://www.cnblogs.com/haws/p/18582641/aliyun79