作者:Cartman
文章:多智能体 AI 搜索引擎 点击链接,更多实践案例等你探索~

#智谱 BigModel 研习社 是专业的大模型开发者交流平台,欢迎在评论区与我们互动!
传统搜索引擎如今的问题在于输出很多不相关结果(大量垃圾信息 + SEO 操纵的标题党内容),大模型也面临着幻觉问题。
在网上找到有用的答案并非易事。往往需要多次搜索并沿着链接挖掘以找到高质量信息源和正确信息。
但如果用大模型的智力来尝试过滤网络中的无用信息,或许搜索引擎的体验就会变得焕然一新。
现在,聊天就能得到更好的答案:用更自然的对话式方式提问,大模型可以选择使用网络上的信息进行回复。如果更深入地追问,则大模型还能根据聊天的完整上下文来提供更好的答案。
下面我们来看看,如何用智谱 BigModel 开放平台提供的免费模型和产品,搭建自己的AI搜索引擎!

案例概述
当前热门的 AI 搜索,能够深度搜索并总结内容,并生成思维导图,对于各类调研分析工作非常实用。例如:

如果我们也希望在自己的系统中集成类似的能力,可以通过多智能体协作来实现(搜索和思维导图智能体)。
AI 搜索框架
实际场景中,比如用户需要深度调研开源技术方案,生成报告的同时制作成思维导图。AI 搜索方案可以这样设计:
以下是一个实际场景:用户需要 深度调研 开源技术方案,生成报告的同时制作成思维导图。

第一步,快速搜索补充参考信息
首先需要根据用户的任务<调研市场上主流的开源搜索引擎技术架构>,使用搜索工具补充更多的信息。这里我们使用工具 API Web-Search-Pro,具体参考文档。
请求代码
from zhipuai import ZhipuAI
api_key = "API Key"
url = "https://open.bigmodel.cn/api/paas/v4"
client = ZhipuAI(api_key=api_key, base_url=url)
###### Step 1 使用搜索工具来拓展信息
response = client.chat.completions.create(
model="web-search-pro", # 填写需要调用的模型名称
messages=[
{"role": "user", "content": "调研市场上主流的开源搜索引擎技术架构"}
],
top_p=0.7,
temperature=0.1,
stream=False
)
results = response.choices[0].message.tool_calls[1].search_result
print(results)
搜索结果
[{
'content': 'OpenSearch 是一个由社区驱动的开源搜索和分析套件,源于 A9 公司的搜索结果分享格式,现已发展成为具有数据存储、搜索引擎、可视化和用户界面组件的平台。它的特性包括分布式架构、开源性质、强大的安全功能、高性能、可扩展性以及支持插件的系统。OpenSearch 适用于实时应用程序监控、日志分析、网站搜索和数据分析等多种应用场景。此外,OpenSearch 具有活跃的社区支持,并与其他开源工具兼容。它的商业版本,如阿里云的 OpenSearch 服务,提供了额外功能和支持。技术上,OpenSearch 的核心组件包括 OpenSearch Server 和 OpenSearch Dashboards,支持多种索引管理功能、查询语言以及分片和复制机制来提高性能和可靠性。安全性方面,它支持 HTTPS 传输加密和身份验证、授权机制。在日志分析、实时监控、网站搜索、业务分析和机器学习等方面,OpenSearch 都有广泛的应用。它还提供了官方文档、论坛、在线课程和认证计划来支持用户的学习和技能提升。',
'icon': 'https://sfile.chatglm.cn/searchImage/blog_csdn_net_icon.jpg',
'index': 0,
'link': 'https://blog.csdn.net/weixin_41850878/article/details/140689738',
'media': 'CSDN博客',
'refer': 'ref_1',
'title': 'OpenSearch开源搜索和分析套件(发布时间:2024-07-26 09:00:00)'
}, {
'content': '全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选,相信大家多多少少的都听说过它。它可以快速地储存、搜索和分析海量数据。就连维基百科、Stack Overflow、Github 都采用它选择作为自己的搜索引擎今天就让我们来了解了解 Elasticsearch 为什么这么快。\n文章目录\n引入\n一、Elastic Search简介\n二、Elastic Search的特点\n支持分布式集群\n支持将全文检索、数据分析以及分布式\n开箱即用的,非常简单\n三、Elastic Search的应用场景\n四、Elastic Search的使用\n4.1 安装\n4.2修改配置文件\n4.3 启动\n4.51 安装图形化插件\n结论\n一、Elastic Search简介\nElastic Search(简称ES)是一个基于Lucene构建的开源搜索引擎。Lucene是一个强大的全文搜索库,但ES在Lucene的基础上增加了分布式、RESTful API和实时搜索等功能。这使得ES成为一个适用于各种应用场景的强大搜索引擎。\n二、Elastic Search的特点\n支持分布式集群\n可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司\nES可以在多个服务器上运行,从而实现横向扩展。这意味着你可以根据需求增加更多',
'icon': 'https://sfile.chatglm.cn/searchImage/blog_csdn_net_icon.jpg',
'index': 0,
'link': 'https://blog.csdn.net/qq_57761637/article/details/139916744',
'media': 'CSDN博客',
'refer': 'ref_3',
'title': '探索Elastic Search:强大的开源搜索引擎,详解及使用(发布时间:2024-06-24 10:33:44)'
}, {
'content': 'Perplexica 是一个开源的 AI 搜索引擎,旨在作为像 Perplexity AI 等专有搜索引擎的隐私保护替代品。这个项目运用大型语言模型(LLMs)和人工智能技术,提供精确的搜索结果和来源明确的回答。它的架构集成了基于 Web 的用户界面、预测下一步的代理和链、执行 Web 搜索的 SearXNG、理解内容并生成回答的 LLMs,以及通过嵌入模型重新排序搜索结果的系统。Perplexica 的工作流程是:用户的查询被发送到后端服务器,触发搜索链,确定是否需要进行 Web 搜索。如果需要,查询会被发送到 SearXNG 进行常规搜索,然后将搜索结果转换成嵌入形式,通过相似性搜索找到最相关的来源。这些来源会传递给响应生成器,生成准确答案,返回给用户界面。Perplexica 有两种模式:"Copilot 模式"(开发中)通过生成多个查询来寻找更相关的 Web 来源,而 "Normal 模式" 负责处理查询并进行 Web 搜索。此外,它还提供了六种专注模式,针对不同类型问题提供最佳答案,比如 "全模式"、"写作助手"、"学术搜索"、"YouTube 搜索"、"Wolfram Alpha 搜索" 和 "Reddit 搜索"。Perplexica 推荐使用 Docker 进行安装,但也可以在没有 Docker 的环境中部署。用户可以将 Perplexica 设置为浏览器的',
'icon': 'https://sfile.chatglm.cn/searchImage/www_chinaz_com_icon.jpg',
'index': 0,
'link': 'https://www.chinaz.com/2024/0611/1622623.shtml',
'media': '站长之家',
'refer': 'ref_4',
'title': 'Perplexica 是 Perplexity.ai 的开源 AI 搜索引擎替代品(发布时间:2024-06-11 14:02:55)'
},... {
'content': '随着移动互联网、物联网、云计算等信息技术蓬勃发展,数据量呈爆炸式增长。如今我们可以轻易得从海量数据里找到想要的信息,离不开搜索引擎技术的帮助。\n作为开源搜索引擎领域排名第一的 Elasticsearch,能够让我们无需深入了解背后复杂的信息检索原理,就可实现基本的全文检索功能,在数据量达到十亿,百亿规模仍然可以秒级返回检索结果。\n对于系统容灾、数据安全性、可扩展性、可维护性等用户关注的实际问题,在Elasticsearch 上也能得到有效解决。\n二、Elasticsearch 介绍\nElasticsearch(ES)是一个基于 Lucene 构建的开源分布式搜索分析引擎,可以近实时的索引、检索数据。具备高可靠、易使用、社区活跃等特点,在全文检索、日志分析、监控分析等场景具有广泛应用。\n由于高可扩展性,集群可扩展至百节点规模,处理PB级数据。通过简单的 RESTful API 即可实现写入、查询、集群管理等操作。\n除了检索,还提供丰富的统计分析功能。以及官方功能扩展包 XPack 满足其他需求,如数据加密、告警、机器学习等。\n另外,可通过自定义插件,如 COS 备份、QQ 分词等满足特定功能需求。\n1. Elasticsearch 架构与原理\n基本概念 :\nCluster「集群」:由部署在多个机器的ES节点组成,以处理',
'icon': 'https://sfile.chatglm.cn/searchImage/blog_csdn_net_icon.jpg',
'index': 0,
'link': 'https://blog.csdn.net/wypblog/article/details/108301796',
'media': 'CSDN博客',
'refer': 'ref_8',
'title': '开源搜索引擎排名第一,Elasticearch是如何做到的?(发布时间:2020-08-29 20:58:00)'
}, {
'content': '以下是对AI日报内容的中立总结:今日AI日报聚焦于多项人工智能领域的最新动态。以下是几个关键更新:1. 清华大学和生数科技发布了中国首个长时长、高一致性、高动态性视频大模型Vidu,采用U-ViT架构,能生成16秒长、1080P高清视频内容。2. 通义千问团队开源了首个千亿参数模型Qwen1.5-110B,表现优秀,采用Transformer解码器架构,支持多种语言。3. Kimi Chat移动端应用进行了重大更新,版本1.2.1带来了界面重构和新功能,提高用户体验。4. Domo AI新增了四种风格,并提供15个点数免费试用,增强用户创作视频的多样性。5. 苹果计划与OpenAI合作,加强iPhone的人工智能功能,可能会在全球开发者大会前推出新的生成式AI产品。6. 谷歌推出了AI语音对话练习功能,让用户可以通过手机与对话机器人进行英语会话练习。7. 元象公司开源了首个多模态大模型XVERSE-V,在多个权威评测中表现突出。8. Perplexica是一个开源的AI驱动搜索引擎,提供多种搜索模式,旨在提供更精准、智能的搜索体验。9. Meta推出LayerSkip技术,提升大型语言模型的推理速度,减少计算资源消耗。10. 一项调查显示,AI技术对创意产业产生了深远影响,导致一些',
'icon': 'https://sfile.chatglm.cn/searchImage/blog_csdn_net_icon.jpg',
'index': 0,
'link': 'https://blog.csdn.net/AIbase2024/article/details/138280815',
'media': 'CSDN博客',
'refer': 'ref_9',
'title': 'AI日报:当前最强国产Sora大模型Vidu发布;Kimi Chat移动端升级;通义千问开源首个千亿参数模型;苹果计划与 OpenAI 合作(发布时间:2024-07-31 10:13:19)'
}]
第二步,用模型规划和分解子任务
然后我们需要使用大模型来帮助我们规划,把用户问题拆分成若干子搜索任务,并转换为 JSON 格式。这里我们通过 GLM-4-0520 的模型来分析,参考 API文档。JSON 格式处理,我们参考JSON 工具。
请求代码
import re
import json
from zhipuai import ZhipuAI
api_key = "API Key"
url = "https://open.bigmodel.cn/api/paas/v4"
client = ZhipuAI(api_key=api_key, base_url=url)
def parsejson(input):
result = None
try:
# Try parse first
result = json.loads(input)
except json.JSONDecodeError:
print(" decoding faulty json, attempting repair")
if result:
return input, result
_pattern = r"\{(.*)\}"
_match = re.search(_pattern, input)
input = "{" + _match.group(1) + "}" if _match else input
# Clean up json string.
input = (
input.replace("{{", "{")
.replace("}}", "}")
.replace('"[{', "[{")
.replace('}]"', "}]")
.replace("\\", " ")
.replace("\\n", " ")
.replace("\n", " ")
.replace("\r", "")
.strip()
)
# Remove JSON Markdown Frame
if input.startswith("```json"):
input = input[len("```json"):]
if input.endswith("```"):
input = input[: len(input) - len("```")]
try:
result = json.loads(input)
except json.JSONDecodeError:
print("error parse json,failed repairment")
finally:
return input, result
if __name__ == '__main__':
###### Step 2 拆分若干子问题
sprompt = "# 以下是来自互联网的信息:\n"+"..." #来自 Step 1 的搜索结果
usrprompt = """
# 任务
你的任务是参考已有信息来解决用户问题。
通过将用户问题拆分成能够通过搜索回答的多个子问题,每个搜索的问题应该是一个单一问题。
再根据每个子问题衍生1-3个提问,用于更好的补充子问题。
输出为以下的JSON格式:
{
[
"query":<子问题描述>,
"reference1":<衍生提问1>,
"reference2":<衍生提问2>,
"reference3":<衍生提问3>
]
}
# 用户问题:
<调研市场上主流的开源搜索引擎技术架构>
# 输出JSON:
"""
response = client.chat.completions.create(
model="glm-4-0520", # 填写需要调用的模型名称
messages=[
{"role": "system", "content": sprompt},
{"role": "user", "content": usrprompt}
],
top_p=0.7,
temperature=0.1,
stream=False
)
print(response)
##### 解析和修复json 格式
text,jsonobj = parsejson(response.choices[0].message.content)
print(jsonobj)
拆分问题(格式可解析成 JSON OBJECT)
[\n {\
n "query": "Elasticsearch的技术架构特点是什么?", \n "reference1": "Elasticsearch是如何支持分布式存储和搜索的?", \n "reference2": "Elasticsearch的RESTful API是如何工作的?", \n "reference3": "Elasticsearch如何处理PB级数据?"\
n
}, \n {\
n "query": "OpenSearch的技术架构有哪些核心组件?", \n "reference1": "OpenSearch与Elasticsearch的技术架构有何异同?", \n "reference2": "OpenSearch的分布式架构是如何实现的?", \n "reference3": "OpenSearch的数据存储和索引管理功能是如何进行的?"\
n
}, \n {\
n "query": "Havenask作为阿里巴巴的开源搜索引擎,其架构有哪些特色?", \n "reference1": "Havenask如何支持千亿级别数据的实时检索?", \n "reference2": "Havenask的消息系统Swift是如何处理大规模数据流的?", \n "reference3": "Havenask的索引系统是如何保证高时效性写入和毫秒级查询延迟的?"\
n
}, \n {\
n "query": "Perplexica的开源AI搜索引擎架构包含哪些主要部分?", \n "reference1": "Perplexica如何利用大型语言模型提高搜索精度?", \n "reference2": "Perplexica的搜索链和响应生成器是如何工作的?", \n "reference3": "Perplexica与传统的搜索引擎相比,有哪些创新之处?"\
n
}\
n
]
第三步,用搜索智能体完成子任务
AI搜索智能体不仅具备联网搜索的能力,还能够自主分析并进行多轮搜索任务。智能体API的调用方式,具体参考文档。

智能体 id:659e54b1b8006379b4b2abd6
简介:连接全网内容,精准搜索,快速分析并总结的智能助手。
请求代码
from zhipuai import ZhipuAI
api_key = "API Key"
url = "https://open.bigmodel.cn/api/paas/v4"
client = ZhipuAI(api_key=api_key, base_url=url)
##### Step 3 使用AI搜索智能体深度搜索
resp = client.assistant.conversation(
assistant_id="659e54b1b8006379b4b2abd6", #AI搜索智能体
conversation_id=None,
model="glm-4-assistant",
messages=[
{
"role": "user",
"content": [{
"type": "text",
"text": """
搜索最新的联网信息,详细回答问题:Elasticsearch的技术架构特点是什么?
同时搜索并回答以下问题:Elasticsearch是如何支持分布式存储和搜索的?Elasticsearch的RESTful API是如何工作的?Elasticsearch如何处理PB级数据?
按照以下的markdown格式回答:
#问题
##回答
###分析点
""" ####来自 Step 2 的子问题
}]
}
],
stream=True,
attachments=None,
metadata=None
)
##### 子问题的深度搜索结果
text = ""
for chunk in resp:
print(chunk)
try:
if chunk.choices[0].delta.content is not None:
text += chunk.choices[0].delta.content
except:
pass
print(text)
子问题搜索结果
# Elasticsearch的技术架构特点是什么?
## 回答
Elasticsearch(以下简称为ES)是一款基于Lucene的分布式全文搜索引擎。它的技术架构具有以下特点:
### 分析点
1. **分布式实时文档存储引擎**:ES是一个分布式的实时文档存储引擎,每个字段都可以被索引与搜索【7†source】【8†source】。
2. **分布式实时分析搜索引擎**:ES支持各种查询和聚合操作,能够胜任上百个服务节点的扩展,并可以支持PB级别的结构化或者非结构化数据【7†source】【9†source】。
3. **使用倒排索引**:ES使用倒排索引来加速搜索过程,并支持实时索引和搜索、分布式搜索与聚合等功能【10†source】。
# Elasticsearch是如何支持分布式存储和搜索的?
## 回答
Elasticsearch通过以下方式支持分布式存储和搜索:
### 分析点
1. **数据分布式存储**:在Elasticsearch中,数据是分布式存储的,即数据会被分散到多个节点上。这种分布式存储的方式可以提高数据的可靠性和可扩展性【11†source】。
2. **分片存储**:Elasticsearch通过将数据分散到多个分片中实现分布式存储。每个分片都独立地存储在集群中的不同节点上,从而提高了数据存储的扩展性和容错性【12†source】。
# Elasticsearch的RESTful API是如何工作的?
## 回答
Elasticsearch的RESTful API基于HTTP协议,其工作原理如下:
### 分析点
- **基于HTTP协议**:通过各种端点(Endpoints)提供对索引、文档、集群等的操作。通过REST API,可以实现数据的增删改查、聚合分析等操作【13†source】。
...
第四步,总结子任务生成思维导图
智能体能调用各种插件,除了思维导图以外,还有流程图、PPT工具等,你可以根据工作需要选择。智能体API的调用方式,具体参考文档。

智能体 id:664e0cade018d633146de0d2
简介:告别整理烦恼,任何复杂概念秒变脑图。
请求代码
from zhipuai import ZhipuAI
api_key = "API Key"
url = "https://open.bigmodel.cn/api/paas/v4"
client = ZhipuAI(api_key=api_key, base_url=url)
####### Step 4 把全部子问题的结果整理成脑图
subtext1,subtext2,subtext3 = "..." ###来自 Step 3 的子问题结果
prompt = "把以下输入内容,整理成思维导图:\n'''"+subtext1+"\n''''"+"\n'''"+subtext2+"\n''''"+"\n'''"+subtext3+"\n''''"
resp = client.assistant.conversation(
assistant_id="664e0cade018d633146de0d2", # 思维导图智能体
conversation_id=None,
model="glm-4-assistant",
messages=[
{
"role": "user",
"content": [{
"type": "text",
"text": prompt
}]
}
],
stream=True,
attachments=None,
metadata=None
)
# 总结并生成思维导图
text = ""
for chunk in resp:
print(chunk)
try:
if chunk.choices[0].delta.content is not None:
text += chunk.choices[0].delta.content
except:
pass
print(text)
总结并生成脑图
根据您提供的内容,我将整理并创建一个思维导图,以更清晰地展示Elasticsearch、OpenSearch和Perplexica的技术架构和特点。
### Elasticsearch 技术架构特点
- 分布式实时文档存储
- 支持各种查询和聚合操作
- 高可扩展性
- 面向文档的存储和搜索
- 基于Apache Lucene
- 支持PB级别数据
### Elasticsearch 分布式存储和搜索
- 数据分布式存储
- 提高数据可靠性和可扩展性
- 文档分配到多个节点
- 集中存储数据
- 支持分布式部署和扩展
...
### Perplexica 创新之处
- 本地大型语言模型支持
- 多种搜索模式
- 使用SearxNG作为元搜索引擎
- 支持图像和视频搜索
- 强调搜索的灵活性和智能化
- 注重用户隐私保护
现在,我将使用这些信息来生成一个思维导图。这是根据您提供的信息生成的思维导图,展示了Elasticsearch、OpenSearch和Perplexica的技术架构和特点。您可以通过点击下面的图片链接查看和下载思维导图。
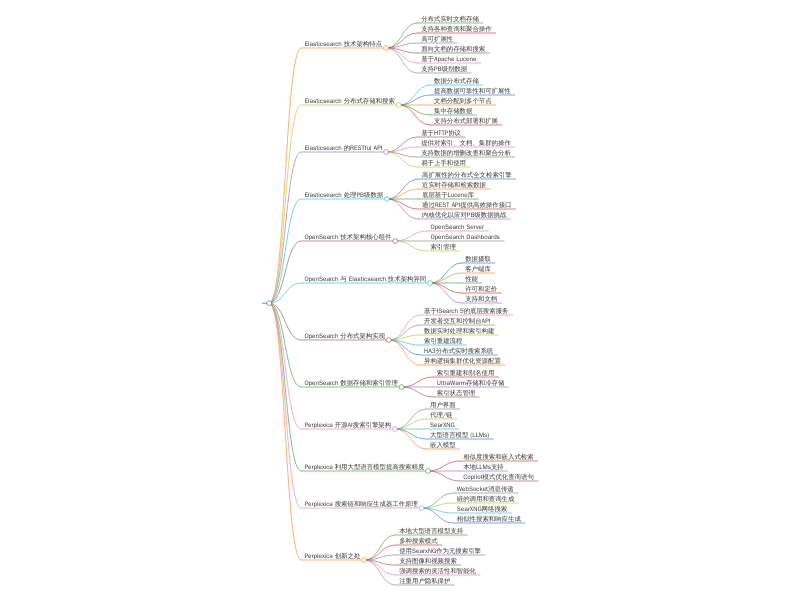
进一步优化框架
这个案例中,我们搭建了一个粗糙但能用的 AI 搜索引擎框架,实际业务使用还有进一步优化的空间:
- 快速搜索前可以使用较小规模的模型,提取用户意图中的目标和类型,让背景的补充更完善;
- 拆解搜索子任务时,也可以进一步采用知识图谱的框架,能够围绕问题展开更深层的搜索;
- AI 搜索智能体比较耗时,实际业务使用需要调整成并发任务,否则一个问题可能要几分钟。
欢迎大家在评论区与我们交流,关于 AI 搜索引擎的更多思路!

#智谱 BigModel 研习社 是专业的大模型开发者交流平台,欢迎在评论区与我们互动!
多智能体 AI 搜索引擎 点击链接,更多实践案例等你探索~
