1 简介
随着深度学习应用的广泛使用,量化模型作为一种有效的模型压缩技术,能够在保持模型精度的同时减少模型的计算和存储开销。本文将介绍如何在 TVM 上为 Paddle 深度学习框架中的量化模型提供解析支持。
2 量化方法
目前主流的的量化方法主要分为 QOperator 和 QDQ(Quantize and DeQuantize) 两种方法,ONNX 中对这两个量化模型的表示方式表述为:
There are two ways to represent quantized ONNX models:
Operator-oriented (QOperator). All the quantized operators have their own ONNX definitions, like QLinearConv, MatMulInteger and etc.
Tensor-oriented (QDQ; Quantize and DeQuantize). This format inserts DeQuantizeLinear(QuantizeLinear(tensor)) between the original operators to simulate the quantization and dequantization process. In Static Quantization, the QuantizeLinear and DeQuantizeLinear operators also carry the quantization parameters. In Dynamic Quantization, a ComputeQuantizationParameters function proto is inserted to calculate quantization parameters on the fly. Models generated in the following ways are in the QDQ format:
Models quantized by quantize_static or quantize_dynamic API, explained below, with quant_format=QuantFormat.QDQ.
Quantization-Aware training (QAT) models converted from Tensorflow or exported from PyTorch.
Quantized models converted from TFLite and other frameworks.
For the latter two cases, you don’t need to quantize the model with the quantization tool. ONNX Runtime can run them directly as a quantized model.
两种量化格式的在模型结构上的区别可以由下图直观展示(左边为 QOperator,右边为 Quantize and DeQuantize)
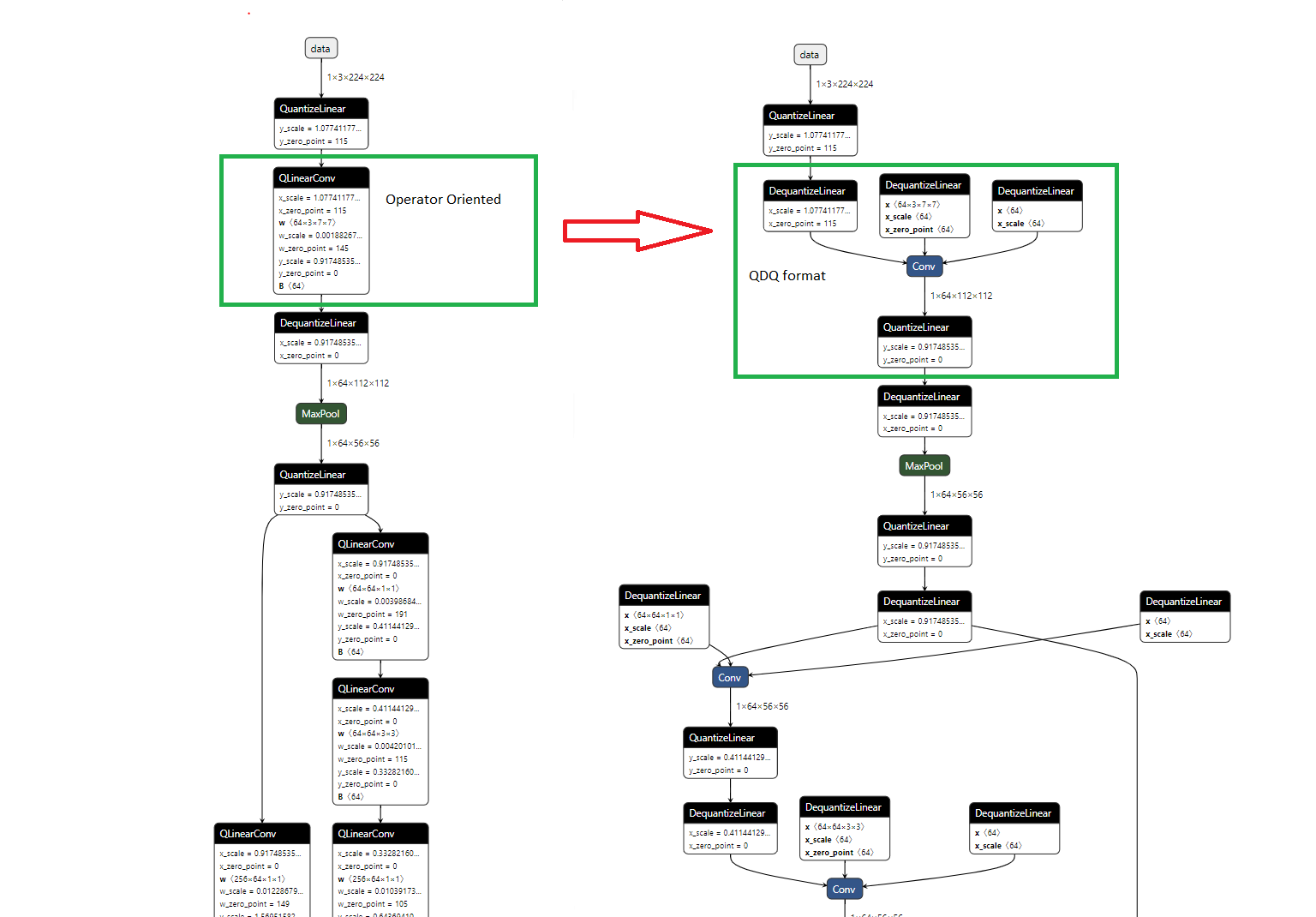
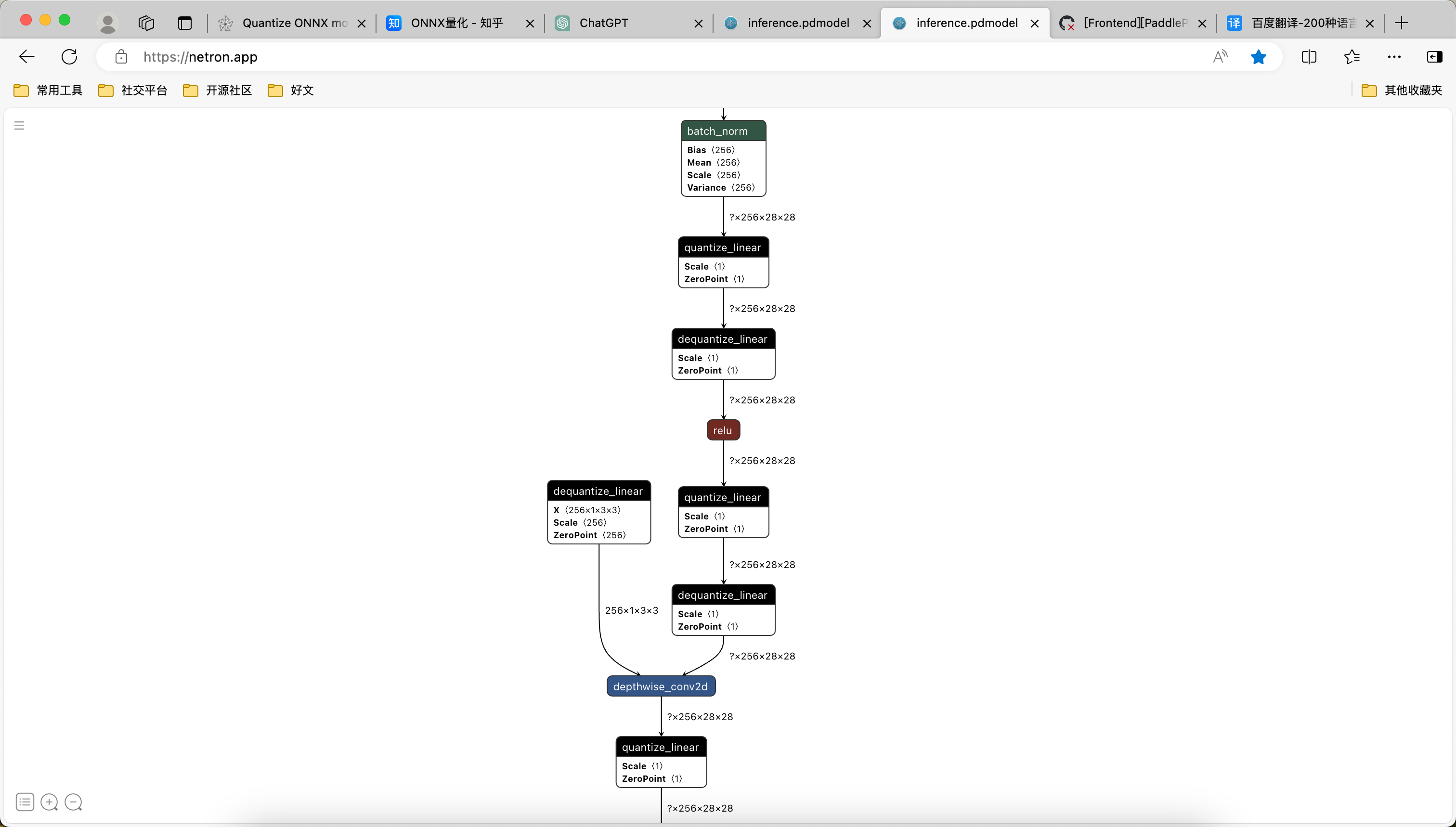
Paddle 的量化模型格式与 ONNX 的 QDQ 量化格式类似,类似通过类似的方法储存量化信息节点,Paddle 量化模型可视化后结果如下:
3 在 TVM 中注册并实现对量化 OP
TVM 的 Python 源代码文件 paddlepaddle.py 中记录了读取 Paddle 模型的全过程,其中 _convert_map 这个字典变量记录了当前支持的 OP 名字以及 OP 转换为 TVM relay 的方法。通过阅读可以发现,该字典未添加对 dequantize_linear 和 quantize_linear 这两个算子的转换方法,我们需要手动添加他,我们可以在字典末尾添加对应格式的代码,添加后代码如下:
_convert_map = {
"abs": convert_unary_op,
......
"where_index": convert_where_index,
# Quantized
"dequantize_linear": convert_dequantize_linear,
"quantize_linear": convert_quantize_linear,
}
接下来我们需要完成 convert_dequantize_linear 和 convert_quantize_linear 函数,上文提到 Paddle 量化模型的格式和 ONNX 量化模型类似,因此我们可以参考一下 ONNX 的写法,ONNX 中转换算子的关键代码如下:
class QuantizeLinear(OnnxOpConverter):
"""Operator converter for QuantizeLinear."""
@classmethod
def _impl_v13(cls, inputs, attr, params):
data, scale, zp = inputs
out_dtype = infer_type(zp).checked_type.dtype
axis = attr.get("axis", 1)
if len(infer_shape(data)) < 2:
axis = 0
return _qnn.op.quantize(data, scale, _op.cast(zp, "int32"), axis, out_dtype)
class DequantizeLinear(OnnxOpConverter):
"""Operator converter for QuantizeLinear."""
@classmethod
def _impl_v13(cls, inputs, attr, params):
data, scale, zp = inputs
axis = attr.get("axis", 1)
if len(infer_shape(data)) <= 1:
axis = 0
return _qnn.op.dequantize(data, scale, _op.cast(zp, "int32"), axis)
我们针对 Paddle 模型也添加类似的代码:
def convert_quantize_linear(g, op, block):
"""Operator converter for dequantize_linear."""
data_node_name = op.input("X")[0]
data_node = g.get_node(data_node_name)
tvm_quantize_scale = g.get_params(op.input("Scale")[0]).asnumpy()
tvm_quantize_zp = g.get_params(op.input("ZeroPoint")[0]).asnumpy()
tvm_quantize_axis = op.attr("quant_axis")
if tvm_quantize_axis == -1:
tvm_quantize_axis = 0
out = _qnn.op.quantize(
data=data_node,
output_scale=_op.const(tvm_quantize_scale, "float32"),
output_zero_point=_op.const(tvm_quantize_zp, "int32"),
axis=tvm_quantize_axis,
)
g.add_node(op.output("Y")[0], out)
def convert_dequantize_linear(g, op, block):
"""Operator converter for dequantize_linear."""
data_node_name = op.input("X")[0]
data_node = g.get_node(data_node_name)
tvm_quantize_scale = g.get_params(op.input("Scale")[0]).asnumpy()
tvm_quantize_zp = g.get_params(op.input("ZeroPoint")[0]).asnumpy()
tvm_quantize_axis = op.attr("quant_axis")
if tvm_quantize_axis == -1:
tvm_quantize_axis = 0
if len(infer_shape(data_node)) < 2:
tvm_quantize_axis = 0
out = _qnn.op.dequantize(
data=data_node,
input_scale=_op.const(tvm_quantize_scale, "float32"),
input_zero_point=_op.const(tvm_quantize_zp, "int32"),
axis=tvm_quantize_axis,
)
g.add_node(op.output("Y")[0], out)
为了测试我们编写的代码是否正常,我们可以编写以下测试脚本,该脚本对 TVM、Paddle、ONNX 模型的推理结果进行了相互的比较。
import paddle
import tvm
from tvm import relay
from tvm.contrib import graph_executor
import numpy as np
import onnx
import onnxruntime as rt
# Model Attr
input_shape = [1, 3, 224, 224]
input_name = "inputs"
def infer_by_paddlepaddle(temp_prefix, temp_input_data):
paddle.enable_static()
exe = paddle.static.Executor(paddle.CPUPlace())
temp_prog, feed_target_names, fetch_targets = paddle.static.load_inference_model(temp_prefix, exe)
temp_output, = exe.run(temp_prog, feed={feed_target_names[0]: temp_input_data}, fetch_list=fetch_targets)
return temp_prog, temp_output
def infer_by_onnx(temp_model_path, temp_input_data):
sess = rt.InferenceSession(temp_model_path, None)
temp_input_name = sess.get_inputs()[0].name
out_name = sess.get_outputs()[0].name
temp_onnx_output = sess.run([out_name], {temp_input_name: temp_input_data})[0]
temp_onnx_model = onnx.load_model(temp_model_path)
return temp_onnx_model, temp_onnx_output
def infer_by_tvm(temp_model, temp_input_data):
if isinstance(temp_model, paddle.static.Program):
# model is loaded by `paddle.static.load_inference_model`
mod, params = relay.frontend.from_paddle(temp_model, shape_dict={input_name: input_shape})
else:
mod, params = relay.frontend.from_onnx(temp_model, shape={input_name: input_shape})
with tvm.transform.PassContext(opt_level=5):
lib = relay.build(mod, target="llvm", params=params)
# tvm inference
ctx = tvm.cpu()
tvm_model = graph_executor.GraphModule(lib['default'](ctx))
tvm_model.set_input(input_name, temp_input_data)
tvm_model.run()
tvm_output = tvm_model.get_output(0).asnumpy()
return tvm_output
log_file = "tune.json"
if __name__ == "__main__":
np.random.seed(520)
# create input data
input_data = np.random.randn(1, 3, 224, 224).astype(np.float32)
paddle_prefix = "MobileNetV1_QAT/inference"
paddle_model, paddle_output = infer_by_paddlepaddle(paddle_prefix, input_data)
onnx_model_path = "MobileNetV1_QAT/inference.onnx"
onnx_model, onnx_output = infer_by_paddlepaddle(paddle_prefix, input_data)
# 对比测试Paddle模型和ONNX模型的输出(通过测试)
np.testing.assert_allclose(paddle_output[0], onnx_output[0], rtol=1e-5, atol=1e-5)
# 测试TVM_Paddle模型和TVM_ONNX模型的输出(通过测试)
tvm_paddle_result = infer_by_tvm(paddle_model, input_data)
tvm_onnx_result = infer_by_tvm(onnx_model, input_data)
np.testing.assert_allclose(tvm_paddle_result[0], tvm_onnx_result[0], rtol=1e-5, atol=1e-5)
# 测试Paddle模型和TVM_Paddle模型的输出
np.testing.assert_allclose(tvm_paddle_result[0], paddle_output[0], rtol=1e-5, atol=1e-5)
# 测试ONNX模型和TVM_ONNX模型的输出
np.testing.assert_allclose(tvm_onnx_result[0], onnx_output[0], rtol=1e-5, atol=1e-5)
通过运行测试代码,我们会发现以下三个现象,这有助于帮助我们分析代码的现状:
- Paddle 和 ONNX 模型的输出是一致的
- Paddle 模型和 TVM 模型的输出大面积不一致
- ONNX 模型和 TVM 模型的输出不一致,但是在可控的范围内
该测试 ONNX 模型是 Paddle 量化模型使用 Paddle2ONNX 导出后的模型
4 分析现状并修复代码
Paddle 模型和 ONNX 模型的输出一致说明 ONNX 模型的导出是没有问题的,ONNX 模型和 TVM 模型输出相近说明当前 ONNX 模型的转换基本上是没有问题的,Paddle 模型和 TVM 模型的输出大面积不一致说明 Paddle 模型的转换出现了问题。
一般来说,算子的运算结果出现错误是由于对参数的读取导致的。于是我们可以阅读 Paddle 模型是如何转换为 ONNX 模型的来帮助我们发现当前转换方式存在的问题。在 Paddle2ONNX中,我们可以发现在将 Paddle 的 dequantize_linear 和 quantize_linear 这两个算子进行转换时,对 scale 的处理过程如下:
void QuantizeLinearMapper::Opset10() {
std::vector<float> scales;
Assert(TryGetInputValue("Scale", &scales),
"Failed to read tensor value of `Scale`.");
std::vector<float> onnx_scales;
onnx_scales.reserve(scales.size());
for (auto &i : scales) {
onnx_scales.push_back(i / 127);
}
}
void DequantizeLinearMapper::Opset10() {
std::vector<float> scales;
Assert(TryGetInputValue("Scale", &scales),
"Failed to read tensor value of `Scale`.");
std::vector<float> onnx_scales;
onnx_scales.reserve(scales.size());
for (auto &i : scales) {
onnx_scales.push_back(i / 127);
}
}
由上述代码我们发现,在将 Paddle 算子转换为 ONNX 算子的过程中, scale 是要除127的。我们可以用同样的逻辑来在 TVM 读取 Paddle 模型时对scale做同样的操作,代码如下:
def convert_dequantize_linear(g, op, block):
"""Operator converter for dequantize_linear."""
data_node_name = op.input("X")[0]
data_node = g.get_node(data_node_name)
# paddle_scale = tvm_scale * 127
paddle_quantize_scale = g.get_params(op.input("Scale")[0]).asnumpy()
tvm_quantize_scale = paddle_quantize_scale / 127.0
tvm_quantize_zp = g.get_params(op.input("ZeroPoint")[0]).asnumpy()
tvm_quantize_axis = op.attr("quant_axis")
if tvm_quantize_axis == -1:
tvm_quantize_axis = 0
if len(infer_shape(data_node)) < 2:
tvm_quantize_axis = 0
out = _qnn.op.dequantize(
data=data_node,
input_scale=_op.const(tvm_quantize_scale, "float32"),
input_zero_point=_op.const(tvm_quantize_zp, "int32"),
axis=tvm_quantize_axis,
)
g.add_node(op.output("Y")[0], out)
def convert_quantize_linear(g, op, block):
"""Operator converter for dequantize_linear."""
data_node_name = op.input("X")[0]
data_node = g.get_node(data_node_name)
# paddle_scale = tvm_scale * 127
paddle_quantize_scale = g.get_params(op.input("Scale")[0]).asnumpy()
tvm_quantize_scale = paddle_quantize_scale / 127.0
tvm_quantize_zp = g.get_params(op.input("ZeroPoint")[0]).asnumpy()
tvm_quantize_axis = op.attr("quant_axis")
if tvm_quantize_axis == -1:
tvm_quantize_axis = 0
out = _qnn.op.quantize(
data=data_node,
output_scale=_op.const(tvm_quantize_scale, "float32"),
output_zero_point=_op.const(tvm_quantize_zp, "int32"),
axis=tvm_quantize_axis,
)
g.add_node(op.output("Y")[0], out)
再次运行第一次测试的代码,发现此时 Paddle 模型与 TVM 模型的误差与 ONNX 模型和 TVM 模型的误差一致,说明移植已经成功。
TVM 对算子推理有着自己的运算机制,运算结果出现一定的误差是正常的
5 参考资料
- Quantize ONNX Models
- Paddle2ONNX dequantize_linear.cc
- Paddle2ONNX quantize_linear.cc
- [Frontend][PaddlePaddle] PaddlePaddle model with NCHW data format that supports quantization