【论文精读】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
作者: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
发表会议: NAACL 2019
论文地址: arXiv:1810.04805
目录BERT是近年来NLP领域影响最大的模型。
在CV领域,很早的时候就可以实现迁移学习。在一个大的数据集上面,例如ImageNet上,预先训练好一个模型,对于一般的CV任务,在预训练模型的基础上稍微改一改,就可以得到很好的效果。
而在NLP领域,很长一段时间内,都需要研究者自己构造神经网络,从零开始训练。
BERT的出现,使得我们终于可以事先训练好一个模型,然后将这个模型应用在各种NLP任务上。既简化了模型训练,也提升了任务性能。
也是就说,BERT出现之后,NLP领域终于也可以用迁移学习了。
1. Introduction
1.1 语言模型预训练方法
现有的语言模型预训练方法主要分为两类:
- 基于特征的方法(Feature-based):
- 代表模型:ELMo
- 需要针对具体任务设计特定的神经网络架构
- 预训练模型的输出仅作为任务模型的额外特征输入
- 预训练参数在下游任务中保持固定不变
- 基于微调的方法(Fine-tuning):
- 代表模型:OpenAI GPT
- 不需要针对具体任务设计特定架构
- 在预训练模型的基础上添加简单的输出层
- 在下游任务训练时微调全部参数
1.2 BERT的改进和优势
相比传统方法,BERT的改进和优势在于:
-
使用了双向注意力:
- ELMo采用两个单向LSTM(前向和后向),但仅仅将前向表示和后向表示进行简单拼接
- GPT使用Transformer,但使用单向注意力
- BERT使用双向Transformer,使用双向注意力机制。
-
Bert是基于微调的方法,也是第一个超过特定任务架构表现的微调方法。
"BERT is the first fine-tuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outper-forming many task-specific architectures."
-
BERT在11个NLP任务中表现良好。
2. BERT
2.1 BERT训练的两个阶段
BERT的训练过程分为两个阶段:预训练(pre-training)和微调(fine-tuning)。
在预训练阶段:模型使用大量的无标注数据,在不同的预训练任务上进行训练。
在微调阶段,首先用预训练好的参数对 BERT 模型进行初始化,然后使用下游任务中的标注数据对BERT中的参数进行微调。
值得注意的是,尽管不同下游任务共享相同的预训练参数,但最终,每个任务都会得到一个独立的微调模型,以适应其特定的目标。
2.2 BERT基础架构
BERT有两个版本。\(BERT_{BASE}\)用来和GPT做比较,\(BERT_{LARGE}\)用来冲榜。
BERT的基础架构是双向Transformer Encoder:
- \(BERT_{BASE}\): L=12, H=768, A=12, 参数量110M
- \(BERT_{LARGE}\): L=24, H=1024, A=16, 参数量340M
其中:
- L: Transformer层数
- H: 隐藏层维度
- A: 多头注意力头数
2.3 输入
BERT的输入很灵活,可以是单句输入,也可以同时输入一个句子对。
单句输入和句子对输入分别对应不同的预训练任务。
BERT的输入表示由三部分Embedding相加得到:
- Token Embeddings: WordPiece 分词后的词向量
- Segment Embeddings: 区分不同句子的Embedding
- Position Embeddings: 位置编码
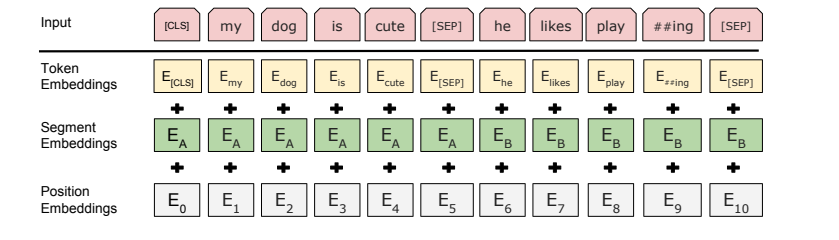
Token Embeddings:首先,使用WordPiece进行分词。然后,在输入的最前方加一个特殊标记[cls] 。此外,在句子和句子之间,用特殊标记[sep]分割。
Segment Embeddings:除了用[sep]分割句子之外,BERT还使用了Segment Embeddings来分割句子。例如,输入一个句子对:句子A和句子B。那么对于句子A的全部token,Segment Embedding取相同的值\(E_A\);对句子B的所有token,Segment Embedding取另一个相同的值\(E_B\)。
Position Embeddings:和Transformer不同,Transformer采用的是位置编码,即人为的设定好了位置和编码之间的映射关系。而BERT使用Embedding,让模型自己学习位置和编码之间的映射关系。
2.4 预训练阶段
使用两个预训练任务,对BERT进行预训练
-
任务1,
Masked LM(MLM):随机mask(遮盖)一定比例的tokens(输入词元),BERT需要预测这些被mask的token。具体来说,需要随机mask 15%的token;在这15%的token中
- 80%替换为[MASK]标记
- 10%随机替换为其他词
- 10%保持不变
目标是:预测这些被mask的原始token。
【例】输入是:my dog is hairy,假设我们选中了第四个token进行mask,那么
有80%的概率:将第四个token替换为[MASK],例如, my dog is hairy \(\rightarrow\) my dog is [MASK]
有10%的概率:将第四个token随机替换为其他词,例如, my dog is hairy \(\rightarrow\) my dog is apple
有10%的概率:第四个token保持不变,例如,my dog is hairy \(\rightarrow\) my dog is hairy
-
任务2,
Next Sentence Prediction (NSP):给BERT输入一个句子对。其中,50%是真实的连续句子对(IsNext),50%是随机组合的句子对(NotNext)。目标是:判断输入的句子对是否是连续的。
【例】

-
两个预训练任务,MLM和NSP的作用不同:其中MLM负责让BERT捕捉token和token之间的关系;NSP负责让BERT捕捉句子和句子间的关系
2.5 微调阶段
在微调阶段,只需要:
- 在预训练的BERT后加一个输出层。(例如,可以在BERT后面加一个线性层)
- 调整BERT的输入格式,把BERT的部分输出送入输出层
- 微调参数
[CLS] representation表示BERT输出中,对应[CLS]的那部分;token representation表示BERT完整的输出序列。【例】
- 情感分析任务
- 输入形式: text-∅ 对。text部分为待分析的目标句子,∅表示第二部分为空
- 输出层: 将
[CLS] representation送入输出层。
- 问答任务
- 输入形式: question-passage 对。question: 输入的问题文本,passage: 包含答案的上下文段落
- 输出层: 将
token representation送入输出层。
- 序列标注任务
- 输入形式: text-∅ 对。text: 需要进行标注的文本序列,∅表示第二部分为空
- 输出层: 将
token representation送入输出层。
3. 实验
3.1 GLUE
GLUE:包括判断两句话是蕴含/矛盾/中性关系、判断两个问题是否语义等价、判断句子是否包含问题的答案、情感判断等9个子任务
微调阶段的模型架构:
flowchart TB A["BERT"]-->B["[CLS] representation"] B-->C[分类层] C-->output性能:
- \(BERT_{BASE}\)和\(BERT_{LARGE}\)在GLUE的所有任务上都显著优于之前的所有系统
- 相比之前最好的结果,平均准确率分别提升了4.5%和7.0%
- 在最大规模的MNLI任务上,获得了4.6%的绝对准确率提升
- 在官方GLUE排行榜上,\(BERT_{LARGE}\)获得了80.5分,而OpenAI GPT为72.8分
3.2 SQuAD
SQuAD :给定一个问题和一段文本,要求从文本中找出问题的答案。
微调阶段的模型架构:
flowchart TD A["输入: 问题和段落文本"] --> B["BERT模型处理"] B --> C["得到每个token的表示Ti"] C --> D["起始向量 S"] C --> E["结束向量 E"] D --> F["计算起始位置得分"] subgraph 得分计算 F --> G["Pi = exp(S·Ti) / Σj exp(S·Tj)"] end E --> H["计算结束位置得分"] subgraph 结束得分 H --> I["Pj = exp(E·Tj) / Σk exp(E·Tk)"] end G --> J["寻找最优得分片段"] I --> J J --> K["使得S·Ti + E·Tj最大,且j ≥ i"] K --> L["输出答案片段"]性能:
- SQuAD v1.1上F1分数达到93.2,超过之前最好成绩1.5个点
- SQuAD v2.0上F1分数达到83.1,超过之前最好成绩5.1个点
3.3 SWAG
SWAG数据集:给定1句话,和4个可能的后续句子,要求从4个选项中选择最合理的那一个。
微调阶段的模型架构:
flowchart TD A["输入: 给定句子 + 4个候选延续句"] --> B["构建4个输入序列"] B --> C1["BERT #1"] B --> C2["BERT #2"] B --> C3["BERT #3"] B --> C4["BERT #4"] subgraph 每个候选项的处理 C1 --> D1["[CLS]表示"] C2 --> D2["[CLS]表示"] C3 --> D3["[CLS]表示"] C4 --> D4["[CLS]表示"] end D1 & D2 & D3 & D4 --> E["得分向量计算层"] E --> F["Softmax归一化"] F --> G["选择得分最高的候选项作为答案"] style C1 fill:#e0f7fa style C2 fill:#e0f7fa style C3 fill:#e0f7fa style C4 fill:#e0f7fa性能:
- \(BERT_{LARGE}\)比baseline提高27.1%,比OpenAI GPT提高8.3%
4. 消融实验
4.1 调整预训练任务
结论:MLM和NSP两个预训练任务缺一不可
使用与\(BERT_{BASE}\)相同的设置,评估了两种预训练目标:
- No NSP:去掉"下一句预测"任务,只保留"掩码语言模型"(MLM)
- LTR & No NSP:使用传统的从左到右语言模型,而不是MLM,同时也去掉NSP任务
实验结果显示:
- No NSP vs. \(BERT_{BASE}\) :移除NSP任务显著降低了QNLI、MNLI和SQuAD的性能
- LTR & No NSP vs. No NSP:从双向MLM改为单向LTR,模型在所有任务上表现都变差,在MRPC和SQuAD上性能下降特别明显。
- 即使在LTR模型上添加BiLSTM层也无法弥补性能差距
4.2 调整模型大小
对基于微调的模型(如BERT)来说,几乎不存在过拟合问题,更大即更好。
通过改变层数(L)、隐藏单元数(H)和注意力头数(A)来测试不同规模的模型:
-
发现更大的模型在所有任务上都能带来持续的性能提升。即使在只有3600训练样本的MRPC任务上,大模型仍然更有效
-
当基于微调的预训练语言模型(如BERT)得到充分预训练后,增大模型规模(如增加层数、扩大隐藏层维度)能够持续提升模型性能。即使在训练样本极其稀少的任务上,更大的预训练模型依然能带来更好的效果。
PS:对基于特征的预训练方法(feature-based)来说,一味增大模型规模确实不会带来太多效果。但是对基于微调的预训练方法(fine-tuning)来说,模型越大,效果越好。
4.3 把BERT当作基于特征的方法(feature-based)使用
BERT既可以看作基于特征的预训练方法,也可以看作基于微调的预训练方法
- 两种方法都能取得很好的效果
- 最佳的特征提取方法与微调方法的效果相差很小
- BERT既可以用作特征提取器,也可以直接微调
5. 结论
- BERT是一个深度双向的预训练模型。
- 使用BERT,可以很好的处理很多NLP任务。