docker搭建私有仓库
一、为什么要搭建私有的仓库?
因为在国内,访问:https://hub.docker.com/ 会出现无法访问页面。。。。(已经使用了魔法)
 当然现在也有一些国内的镜像管理网站,比如网易云镜像服务、DaoCloud镜像服务、阿里云镜像服务等。但是有些收费的。戛然而止了。我们可以自己手动的在我们的服务器上进行搭建私有的仓库。Docker Registry,在企业中自己的镜像最好是采用私有Docker Registry来实现。
当然现在也有一些国内的镜像管理网站,比如网易云镜像服务、DaoCloud镜像服务、阿里云镜像服务等。但是有些收费的。戛然而止了。我们可以自己手动的在我们的服务器上进行搭建私有的仓库。Docker Registry,在企业中自己的镜像最好是采用私有Docker Registry来实现。
二、搭建私有镜像仓库(ubuntu版)
https://github.com/Joxit/docker-registry-ui/tree/2.0.0进行了解
1、检查docker
查看服务器上的docker 是否已经安装,使用docker -v进行检查,显示对应的版本号证明已经安装完

2、配置镜像
国内使用docker官方镜像会出现超时的问题,配置我们国内的镜像既可。执行下方命令。
cd /etc/docker
ls

进行编辑这个文件。
vim daemon.json
在文件中增加镜像源
"registry-mirrors": [
"https://docker.1panel.live"
]
重启服务,执行下方命令
systemctl daemon-reload
systemctl restart docker
查看是否配置成功
docker info
显示如下信息,就证明配置成功

4、部署私有仓库–无UI界面
(1).无UI的简化版镜像仓库
Docker官方的Docker Registry是一个基础版本的Docker镜像仓库,具备仓库管理的完整功能,但是没有图形化界面。
docker run -d \
--restart=always \
--name registry \
-p 5000:5000 \
-v registry-data:/var/lib/registry \
registry
命令中挂载了一个数据卷registry-data到容器内的/var/lib/registry 目录,这是私有镜像库存放数据的目录。
访问http://你的IP地址:5000/v2/_catalog 可以查看当前私有镜像服务中包含的镜像
5、部署私有仓库–有UI界面
当然也有有图形化界面的私有仓库,但是我们需要配置一些东西。
5.1、配置docker 信任的地址
- 私服采用的是http协议,默认不被Docker信任,所以需要做一个配置:
# 打开要修改的文件
vi /etc/docker/daemon.json
# 添加内容:
# 需要将 http://192.168.175.128 替换为你自己的 ip
"insecure-registries":["http://192.168.175.128:8080"]
# 重加载
systemctl daemon-reload
# 重启docker
systemctl restart docker

注意:一定要加上逗号
拓展:如果遇见错误:Job for docker.service failed because start of the service was attempted too often. See "systemctl status docker.service" and "journalctl -xe" for details. To force a start use "systemctl reset-failed docker.service" followed by "systemctl start docker.service" again.
好多人碰到这个问题了,解决办法如下:
进入目录下修改配置文件名称,路径:cd /etc/docker 查看当前目录的配置文件,输入:ls 把daemon.json配置文件改成daemon.conf即可,命令:mv daemon.json daemon.conf 重新启动服务,命令:sudo service docker restart 然后再docker ps, 运行ok了 等运行成功后再改回来,不然推送镜像时推送不上去
5.2、创建docker-compose.yml 文件
Docker官方的Docker Registry因为带有图形化界面版本的镜像仓库不是官方提供的,而是由第三方个人基于 Docker 官方的 Docker Registry 进行开发的,所以部署时需要两个静像,我们使用 compose 文件进行部署
2.1执行下方命令创建yml 文件
mkdir /tmp/registry-ui
cd /tmp/registry-ui/
touch docker-compose.yml
填写如下内容
version: '3.0'
services:
registry:
image: registry
volumes:
- ./registry-data:/var/lib/registry
ui:
image: joxit/docker-registry-ui:static
ports:
- 8080:80
environment:
- REGISTRY_TITLE=私有仓库
- REGISTRY_URL=http://registry:5000
depends_on:
- registry
depends_on: - registry 表明 ui 依赖于 registry,所以这样就会先启动registry
5.3、启动
docker-compose up -d
查看启动状态
docker ps

说明已经启动成功。在浏览器输入ip地址加上8080端口就可以
http://192.168.175.128:8080/

6、测试
我们先测试一下镜像是否能够正常推上去。查看自己本地的镜像都有什么,docker images

其中镜像源:192.168.175.128:8080/redis 是测试时候用的镜像源。不用在意。我们拉取一个新的镜像源,使用docker pull nginx

查看存在的镜像源。docker images

可以看到我们的nginx镜像源已经拉取下来了。
6.1推送镜像源
前置条件,推送镜像到私有镜像服务必须先tag(就是将本地镜像重命名一下,他们的镜像 ID 都是一样的,本质上还是同一个镜像)所以我们先重新tag本地镜像,名称前缀为私有仓库的地址:这里我的地址为:192.168.175.128:8080,以 nginx 镜像为例,将 nginx:latest 镜像重命名为 192.168.175.128:8080/nginx:1.0
docker tag nginx:latest 192.168.175.128:8080/nginx:1.0

查看镜像源 docker images

可以进行推送了,往自己的私有仓库中
docker push 192.168.175.128:8080/nginx:1.0
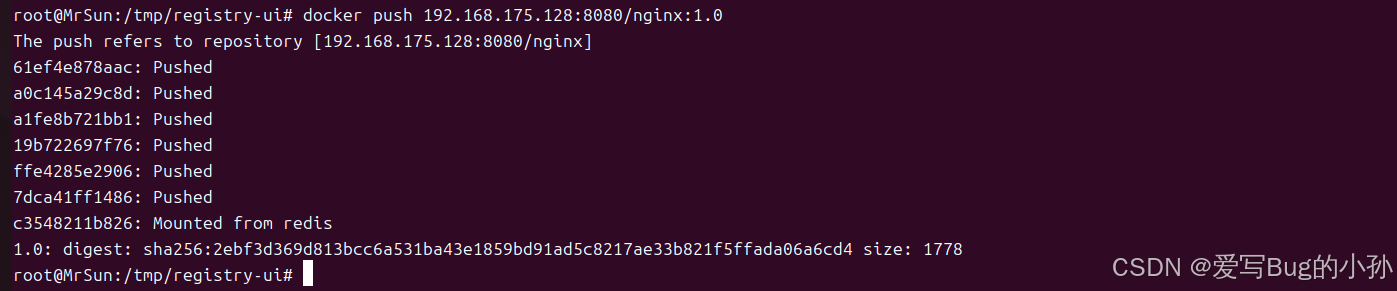
此时已经推送成功。
6.2拉取镜像
我们将本地的nginx 镜像都删除。查看一下拉取的效果。
docker rmi 192.168.175.128:8080/nginx:1.0
docker rmi nginx:latest
注意:如果镜像正在被容器使用,可以使用 -f 选项进行强制删除

使用docker images 查看是否已经成功删除

进行拉取镜像。
docker pull 192.168.175.128:8080/nginx:1.0
显示如下信息,证明已经拉取到了。

再次查看镜像源。docker images
