三重时空变化模式的视频协调
5.4.1 三重时空变化模式的视频协调概述
视频协调是一项重要而具有挑战性的任务,旨在通过自动调整前景的外观以与背景协调,从而获得视觉上逼真的合成视频。受手动协调的短期和长期逐步调整过程的启发,提出了一个视频三重变换器框架,用于模拟视频中的三种时空变化模式,即短期空间以及长期全局和动态,用于视频协调等视频到视频任务。
具体来说,为了短期协调,根据相邻帧调整前景外观,使其在空间维度上与背景一致;为了长期协调,不仅探索全局外观变化以提高时间一致性,还减轻运动偏移约束以动态对齐相似的上下文外观。广泛的实验和消融研究证明了方法的有效性,在视频协调、视频增强和视频演示任务中实现了最先进的性能。还提出了一种时间一致性度量,以更好地评估协调后的视频。代码可在以下网址获得https://github.com/zhenglab/VideoTripletTransformer。
5.4.2 三重时空变化模式的视频协调技术分析
视频合成是一种典型的操作,涉及从一个视频剪辑中提取所需的区域(作为前景),并将其粘贴到另一个视频(作为背景)中,以创建独特的视觉效果。然而,由于前景和背景之间的外观差异,如颜色、亮度和对比度,合成视频不可避免地会出现视觉不一致。手动创建视觉上自然的合成视频是一项劳动密集型和专家级的工作,需要逐帧仔细调整像素强度。因此,视频协调(VH)已成为一项关键且具有挑战性的任务,旨在自动将合成视频中的前景外观与背景对齐。
将图像协调方法应用于合成视频会导致不希望的帧间填充,如图1所示,其中HT+在协调视频中表现出明显的亮度差异(雷达图中标记为HT+的粉红色区域)。事实上,视频捕捉场景中物体的运动和外观变化,这些连续的时空变化为大多数视频任务提供了关键的指导和约束,例如视频动作识别和修复。
因此,对视频中的时空变化模式进行建模对于VH来说是基础和合理的。与图像中观察到的局部和全局特性类似,视频也表现出短期和长期的时间特征。各种视频处理技术(例如,慢速、TDN和TSN)已经证明了在时间维度上考虑这些不同的多帧变化运动的优点。然而,与视频分类和动作识别等依赖于检测运动变化的高级任务不同,视频协调等视频到视频任务主要关注外观变化,同时保持其语义特征不变。
实际上,人类将视频协调视为一个渐进的优化过程,该过程基于相邻帧处理短期差异,并逐步扩展到长期帧。这个迭代过程涉及将前景外观从粗略调整到模糊,以实现整个视频的整体时空一致性。受这种直觉的启发,将手动协调中的迭代调整描述为三重联合协调机制,该机制在内部捕获不同数量或位置的帧内的时空变化模式,逐渐优化合成视频。
从技术上讲,利用Transformer构建了一个创新的框架,即视频三重转换器(VTT)。Triplet Transformer由短期空间、长期全局和长期动态Transformer模块组成,每个模块都旨在捕捉和处理不同帧间的时空变化模式
视频中的计数或位置。具体来说,在短期空间模块中,利用空间全局特征和相邻帧之间的时间细微变化来提高视频的空间一致性;在长期全局模块中,探索了时空外观变化趋势,以增强视频中的全局时间一致性,此外,受BERT和MAE在捕获序列数据中内在关系方面的强大表示能力的启发,引入了一种掩码预测策略,以激发其建模长期变化模式的潜力;在长期动态模块中,利用动态空间特征匹配来减轻运动偏移效应,确保相似上下文元素(如对象和纹理)的外观在不同的空间位置和帧之间对齐。
人类视觉系统对视频中的填充现象高度敏感,这可能是由单个帧的像素强度突然变化引起的。然而,之前的时间一致性度量往往无法捕捉到这些突然的变化,因为它们依赖于对所有帧的平均结果。因此,提出了一种针对视频到视频任务(特别是视频协调)量身定制的时间一致性度量,该度量可以使用锚值检测和放大异常值对最终评估结果的影响。
主要创新包括如下:
(1)构建了一个视频三重小波变换器框架,可以有效地探索不同长度和位置的帧之间的时空变化模式;
(2)提出了一种适用于视频到视频任务的时间一致性度量。
(3)提供了全面的实验来证明框架的有效性,在视频协调和两个相关任务(即视频增强和视频演示)方面实现了最先进的性能。
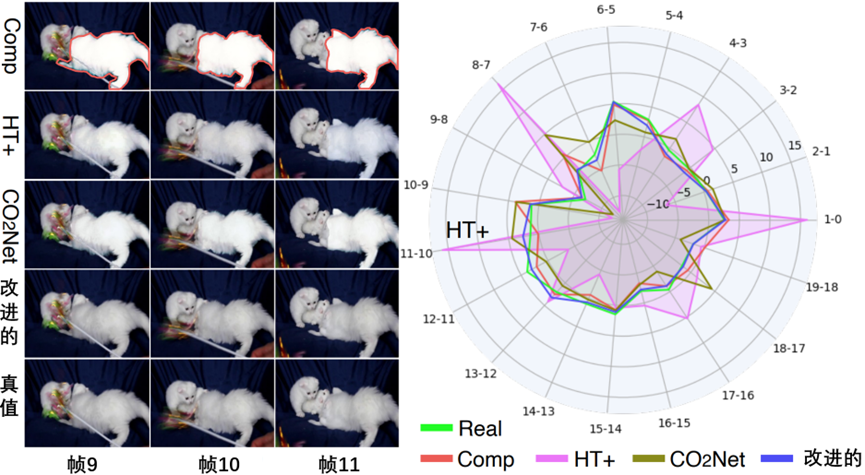
HT+图像、视频、帧间亮度差异,如图5-10所示。
 添加图片注释,不超过 140 字(可选)
图5-10 HT+图像、视频、帧间亮度差异
在图5-10中,展示了基于图像(HT+)和基于视频(CO2Net和改进方法)方法的协调结果(左),以及视频中的帧间前景亮度差异(右)。在雷达图中,与真实相差较大的值表示潜在的重叠,与现实的重叠越近,视觉效果越好。HT+和CO2Net表现出卡顿现象,而方法与真实视频非常相似。
视频三重转换器(VTT)框架,如图5-11所示。
添加图片注释,不超过 140 字(可选)
图5-10 HT+图像、视频、帧间亮度差异
在图5-10中,展示了基于图像(HT+)和基于视频(CO2Net和改进方法)方法的协调结果(左),以及视频中的帧间前景亮度差异(右)。在雷达图中,与真实相差较大的值表示潜在的重叠,与现实的重叠越近,视觉效果越好。HT+和CO2Net表现出卡顿现象,而方法与真实视频非常相似。
视频三重转换器(VTT)框架,如图5-11所示。
 图5-11 视频三重转换器(VTT)框架
在图5-11中,视频三重转换器(VTT)框架由补丁嵌入、带短期空间转换器(ST-ST)的多层三重转换器、长期全局转换器(LT-GT)和长期动态转换器(LTDT)模块以及解码器组成。三个Transformer模块旨在模拟视频中的三种时空变化模式:空间、全局和动态。LT-GT通过掩码预测策略提高了其增强全局外观一致性的能力,LT-DT通过使用引用令牌和上下文的采样令牌来对齐动态上下文中的外观。
LT-DT模块的实现过程,如图5-12所示。
图5-11 视频三重转换器(VTT)框架
在图5-11中,视频三重转换器(VTT)框架由补丁嵌入、带短期空间转换器(ST-ST)的多层三重转换器、长期全局转换器(LT-GT)和长期动态转换器(LTDT)模块以及解码器组成。三个Transformer模块旨在模拟视频中的三种时空变化模式:空间、全局和动态。LT-GT通过掩码预测策略提高了其增强全局外观一致性的能力,LT-DT通过使用引用令牌和上下文的采样令牌来对齐动态上下文中的外观。
LT-DT模块的实现过程,如图5-12所示。
 图5-12 LT-DT模块的实现过程
HYouTube数据集上不同协调方法的定性比较,如图5-13所示。
图5-12 LT-DT模块的实现过程
HYouTube数据集上不同协调方法的定性比较,如图5-13所示。
 图5-13 HYouTube数据集上不同协调方法的定性比较
在图5-13中,白色和绿色数字表示fMSE↓和帧间亮度差(越接近真实越好)。合成帧中的红框标记前景。
比较协调视频和真实视频帧间关系之间的差异
图5-13 HYouTube数据集上不同协调方法的定性比较
在图5-13中,白色和绿色数字表示fMSE↓和帧间亮度差(越接近真实越好)。合成帧中的红框标记前景。
比较协调视频和真实视频帧间关系之间的差异

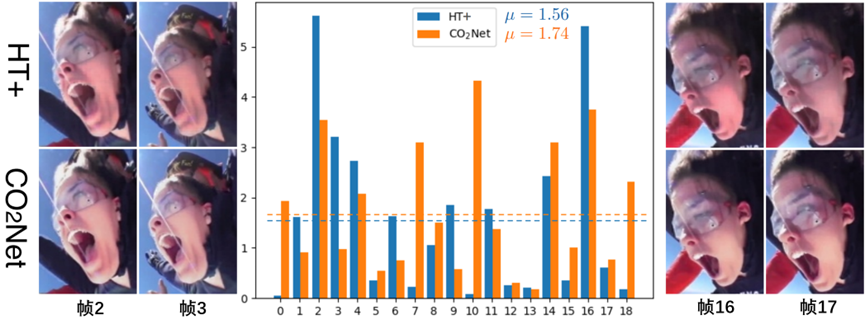
,以及协调帧的示例,如图5-14所示。
 添加图片注释,不超过 140 字(可选)
图5-14 比较协调视频和真实视频帧间关系之间的差异µ,以及协调帧的示例
在图5-14中,µ是
添加图片注释,不超过 140 字(可选)
图5-14 比较协调视频和真实视频帧间关系之间的差异µ,以及协调帧的示例
在图5-14中,µ是
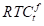 添加图片注释,不超过 140 字(可选)
的平均值。
5.4.3结论
构建了一个新的视频协调框架,对三元组时空变化模式进行建模,以解决空间不协调和时间不一致的问题。
进行了全面的实验来证明频三重Transformer框架的有效性,并将方法用于视频协调、视频增强和视频演示任务,实现了最先进的性能。此外,提出了一种新的时间一致性度量,它更符合人类的视觉感知。希望工作为进一步研究视频到视频任务开辟了新的途径。
标签:视频,外观,协调,三重,时空,变化
From: https://www.cnblogs.com/wujianming-110117/p/18519317
添加图片注释,不超过 140 字(可选)
的平均值。
5.4.3结论
构建了一个新的视频协调框架,对三元组时空变化模式进行建模,以解决空间不协调和时间不一致的问题。
进行了全面的实验来证明频三重Transformer框架的有效性,并将方法用于视频协调、视频增强和视频演示任务,实现了最先进的性能。此外,提出了一种新的时间一致性度量,它更符合人类的视觉感知。希望工作为进一步研究视频到视频任务开辟了新的途径。
标签:视频,外观,协调,三重,时空,变化
From: https://www.cnblogs.com/wujianming-110117/p/18519317