此前,我们已经简单介绍了TextIn团队开发的开源acge_text_embedding模型及其下载和使用方法。本篇将展开讨论Embedding模型中使用的技术框架。
Huggingface地址:https://huggingface.co/aspire/acge_text_embedding 模型API调用:https://www.textin.com/market/detail/acge_text_embeddingEmbedding在自然语言处理和机器学习中起着关键作用,是基础、核心且经典的建模任务,对于各种不同的下游NLP任务是必不可少的,如分类、聚类、检索、句子相似性判断等[1]。 从Word2Vec到BERT表征模型、再到现如今的大模型,Embedding 建模方法在不断创新迭代。不论在传统的搜索[2]、问答场景,还是如今大语言模型(LLM)驱动的检索增强生成(Retrieval-Augmented Generation, RAG)场景中[3],Embedding 技术一直扮演着语义理解的核心角色。
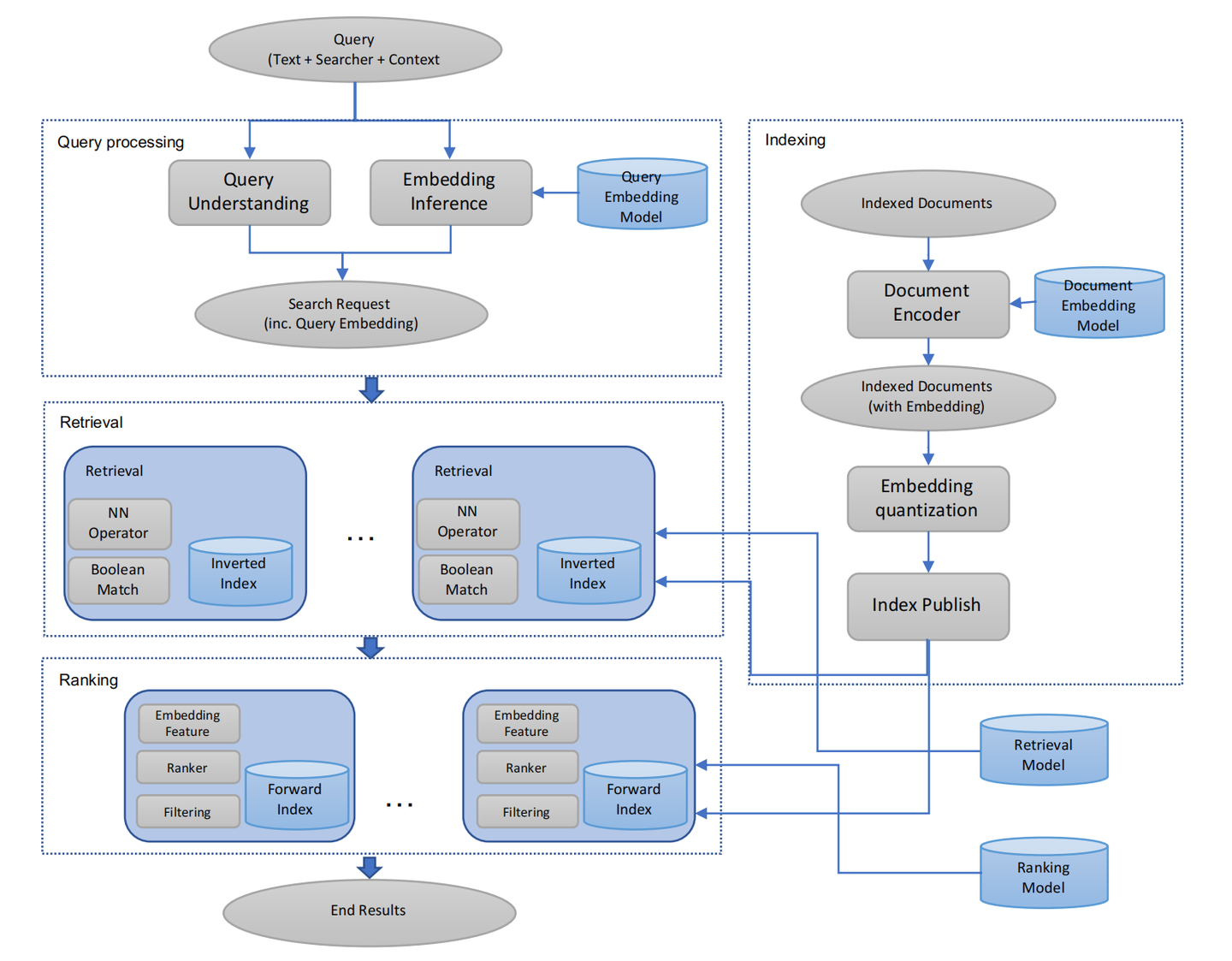 图1 基于embedding的检索系统流程图[2]
在这款曾登顶C-MTEB榜首Embedding模型的研发过程中,TextIn团队采用并结合了多种技术框架:概括来讲,为提高整体召回效果,使用对比学习技术[4],通过最小化正对之间的距离和最大化负对之间的距离来呈现文本语义表示;重视数据挖掘,构造多场景、数量庞大的数据集提升模型泛化能力,挑选高质量数据集加快模型收敛。技术开发过程中,采用多任务混合训练,多loss适配场景,适应各种下游任务,避免模型“偏科”;引入持续学习训练方式[5],改善引入新数据后模型灾难性遗忘问题;同时运用MRL技术[6],训练可变维度的嵌入,提高处理速度,降低了存储需求。
SimCSE: 对比学习技术
对比学习是一种自监督学习方法,它通过拉进语义相似样本的距离和推远语义不相似样本的距离来学习数据的有效表示。 在句子嵌入中,对比学习通过构建正负例对来优化模型。正例对通常是语义上相似的句子,比如同一句子的不同表述或通过数据增强得到的句子变体;负例对则是语义不相似的句子。 正负例对的构建:
图1 基于embedding的检索系统流程图[2]
在这款曾登顶C-MTEB榜首Embedding模型的研发过程中,TextIn团队采用并结合了多种技术框架:概括来讲,为提高整体召回效果,使用对比学习技术[4],通过最小化正对之间的距离和最大化负对之间的距离来呈现文本语义表示;重视数据挖掘,构造多场景、数量庞大的数据集提升模型泛化能力,挑选高质量数据集加快模型收敛。技术开发过程中,采用多任务混合训练,多loss适配场景,适应各种下游任务,避免模型“偏科”;引入持续学习训练方式[5],改善引入新数据后模型灾难性遗忘问题;同时运用MRL技术[6],训练可变维度的嵌入,提高处理速度,降低了存储需求。
SimCSE: 对比学习技术
对比学习是一种自监督学习方法,它通过拉进语义相似样本的距离和推远语义不相似样本的距离来学习数据的有效表示。 在句子嵌入中,对比学习通过构建正负例对来优化模型。正例对通常是语义上相似的句子,比如同一句子的不同表述或通过数据增强得到的句子变体;负例对则是语义不相似的句子。 正负例对的构建:
- 无监督方法:在SimCSE中,通过在同一个句子上应用不同的随机掩码来生成两个略有不同的嵌入向量,这两个向量构成一个正例对。而同一个mini-batch中的其他句子的嵌入则被视为负例。
- 有监督方法:使用自然语言推理(NLI)数据集中的蕴含对作为正例,矛盾对作为负例(硬负例),来构建正负例对。
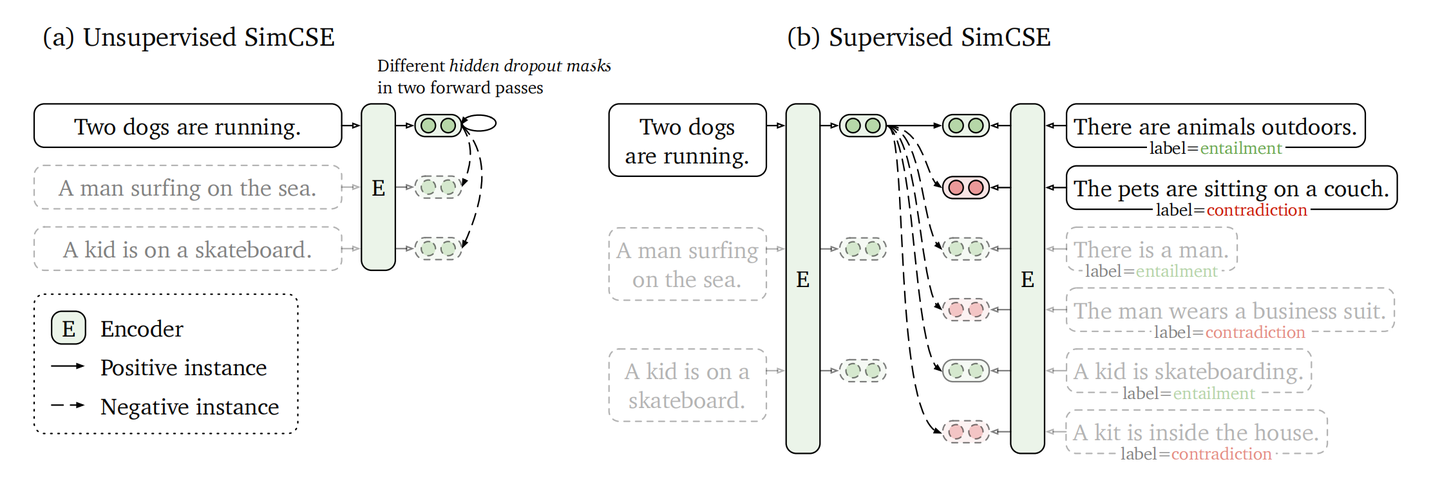 图2 无监督与有监督方法[4]
对比学习的价值在于它能够学习到区分不同语义的句子嵌入,这对于提升下游任务如语义文本相似性(STS)的性能至关重要。通过最小化对比损失函数,模型成功捕捉到句子语义信息的嵌入表示。这种表示不仅能够捕捉句子的表面形式,还能够捕捉其深层含义,从而在各种NLP任务中发挥作用。
EWC:弹性权重固化算法
弹性权重固化(EWC)算法是一种用于解决神经网络在连续学习任务中遭受灾难性遗忘问题的方法。在神经网络学习一系列任务时,通常会遇到这样一个问题:当网络学习新任务时,它往往会迅速遗忘之前学到的任务,这种现象被称为灾难性遗忘。
EWC算法通过保护对旧任务重要的权重参数,减缓这些参数在新任务学习过程中的更新速度,从而减轻了这种遗忘现象。EWC的核心思想是在新任务学习中引入一个二次惩罚项,这个惩罚项会对于那些对旧任务有较大影响的权重参数施加更大的约束。具体来说,EWC通过以下几个关键步骤防止灾难性遗忘:
图2 无监督与有监督方法[4]
对比学习的价值在于它能够学习到区分不同语义的句子嵌入,这对于提升下游任务如语义文本相似性(STS)的性能至关重要。通过最小化对比损失函数,模型成功捕捉到句子语义信息的嵌入表示。这种表示不仅能够捕捉句子的表面形式,还能够捕捉其深层含义,从而在各种NLP任务中发挥作用。
EWC:弹性权重固化算法
弹性权重固化(EWC)算法是一种用于解决神经网络在连续学习任务中遭受灾难性遗忘问题的方法。在神经网络学习一系列任务时,通常会遇到这样一个问题:当网络学习新任务时,它往往会迅速遗忘之前学到的任务,这种现象被称为灾难性遗忘。
EWC算法通过保护对旧任务重要的权重参数,减缓这些参数在新任务学习过程中的更新速度,从而减轻了这种遗忘现象。EWC的核心思想是在新任务学习中引入一个二次惩罚项,这个惩罚项会对于那些对旧任务有较大影响的权重参数施加更大的约束。具体来说,EWC通过以下几个关键步骤防止灾难性遗忘:
- 重要性评估:EWC首先需要确定哪些权重对于已经学习过的任务(旧任务)是重要的。这通常是通过计算Fisher信息矩阵来完成的,该矩阵反映了参数对损失函数的敏感度,从而可以评估每个参数对当前任务的重要性。
- 二次惩罚:在新任务的学习过程中,EWC引入了一个二次惩罚项(也称为弹性约束)。这个惩罚项会对那些对旧任务重要的参数施加更大的约束,减缓这些参数的学习速度,而对不那么重要的参数则允许更自由的学习。
- 权重更新:在每次权重更新时,除了正常的梯度下降步骤外,还会加上这个二次惩罚项。这意味着,如果更新后的权重导致旧任务性能下降太多,那么这个更新会受到惩罚,从而使得模型在保持旧任务性能的同时,学习新任务。
- 平衡新旧任务:EWC通过一个超参数λ来平衡旧任务和新任务的重要性。这个参数决定了旧任务的保护程度,以及新任务学习的速度。
- 持续学习:通过这种方式,EWC允许模型在学习新任务的同时,保持对旧任务的记忆,从而实现持续学习。
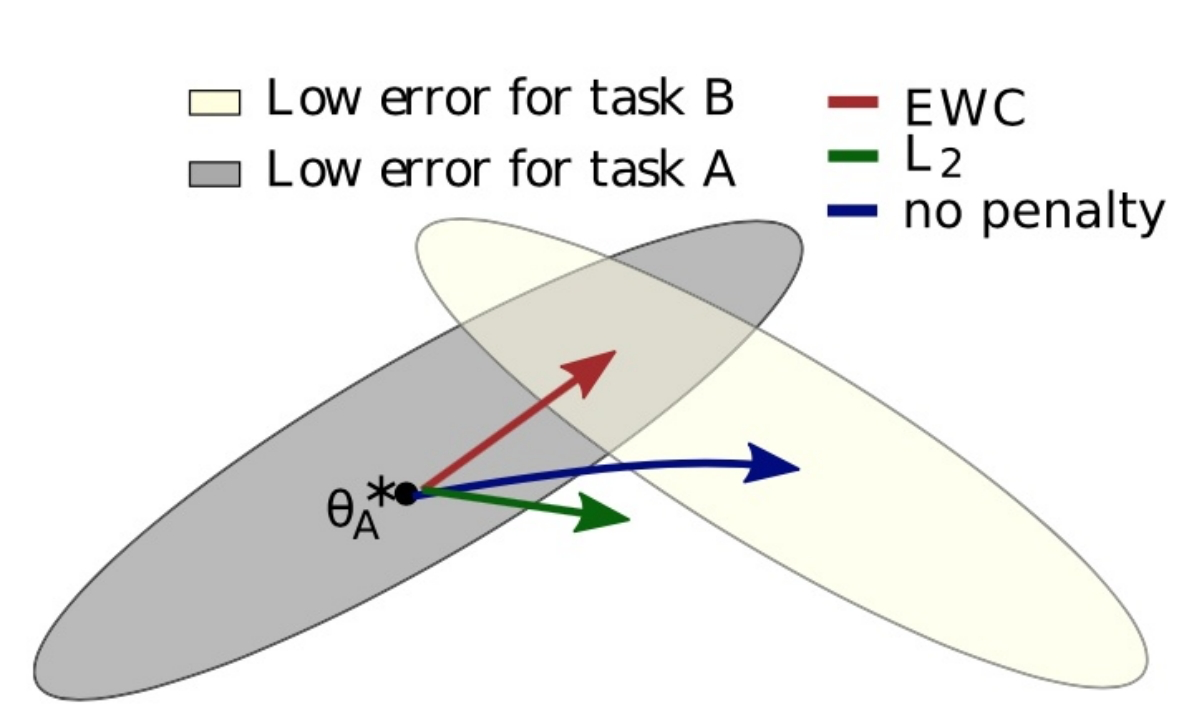 图3 EWC训练策略
在Embedding模型中,EWC算法的引入能够起到不错的效果。Embedding模型在自然语言处理、推荐系统、图像识别等领域中扮演着重要角色,它们需要捕捉和记忆大量的特征和模式。例如,在自然语言处理中,句子或词的嵌入向量需要捕捉足够的语义信息,以便在各种下游任务中使用。当模型需要连续学习多个任务,如文本分类、情感分析等时,EWC算法可以帮助模型在不遗忘先前任务的情况下,学习新的任务。
实际应用中,EWC算法通过在训练过程中动态调整学习率,为不同权重参数设置不同的更新速度。对于那些对旧任务影响较大的参数,EWC会减小其学习率,从而在更新这些参数时更加谨慎。这种方法不仅提高了模型在新任务上的学习效率,还保持了对旧任务的高性能,实现模型的持续学习,构建出鲁棒性更强的通用模型。
MRL:俄罗斯套娃表征学习
"Matryoshka Representation Learning (MRL)" 中的 "Matryoshka" 一词来源于俄罗斯传统的套娃(Matryoshka doll)。在MRL方法中,"Matryoshka" 用来形象地描述这种表示学习框架的一个核心特点:嵌套性和层次性。
俄罗斯套娃是由一系列尺寸逐渐缩小的娃娃组成的,每个大娃娃打开后都包含着一个小娃娃,这些娃娃可以层层嵌套。类似地,MRL框架学习的是一系列不同粒度的表征,每个表征可以看作是嵌套在更高维表示中的“小娃娃”。这种设计允许模型能够根据下游任务的计算资源需求,灵活地选择不同粒度的表示,从而实现对资源的高效利用。
在ML系统中,学习到的表征是执行各种下游任务的核心组件。这些表征通常是在训练阶段生成,并且一旦完成就会被冻结,用于后续的任务。然而,在实际部署时,每个下游任务可能面对不同的计算和统计约束条件,这使得固定容量的表示方法往往不是最佳选择。 作为应对这个问题的方法,MRL具有几项显著优势:
图3 EWC训练策略
在Embedding模型中,EWC算法的引入能够起到不错的效果。Embedding模型在自然语言处理、推荐系统、图像识别等领域中扮演着重要角色,它们需要捕捉和记忆大量的特征和模式。例如,在自然语言处理中,句子或词的嵌入向量需要捕捉足够的语义信息,以便在各种下游任务中使用。当模型需要连续学习多个任务,如文本分类、情感分析等时,EWC算法可以帮助模型在不遗忘先前任务的情况下,学习新的任务。
实际应用中,EWC算法通过在训练过程中动态调整学习率,为不同权重参数设置不同的更新速度。对于那些对旧任务影响较大的参数,EWC会减小其学习率,从而在更新这些参数时更加谨慎。这种方法不仅提高了模型在新任务上的学习效率,还保持了对旧任务的高性能,实现模型的持续学习,构建出鲁棒性更强的通用模型。
MRL:俄罗斯套娃表征学习
"Matryoshka Representation Learning (MRL)" 中的 "Matryoshka" 一词来源于俄罗斯传统的套娃(Matryoshka doll)。在MRL方法中,"Matryoshka" 用来形象地描述这种表示学习框架的一个核心特点:嵌套性和层次性。
俄罗斯套娃是由一系列尺寸逐渐缩小的娃娃组成的,每个大娃娃打开后都包含着一个小娃娃,这些娃娃可以层层嵌套。类似地,MRL框架学习的是一系列不同粒度的表征,每个表征可以看作是嵌套在更高维表示中的“小娃娃”。这种设计允许模型能够根据下游任务的计算资源需求,灵活地选择不同粒度的表示,从而实现对资源的高效利用。
在ML系统中,学习到的表征是执行各种下游任务的核心组件。这些表征通常是在训练阶段生成,并且一旦完成就会被冻结,用于后续的任务。然而,在实际部署时,每个下游任务可能面对不同的计算和统计约束条件,这使得固定容量的表示方法往往不是最佳选择。 作为应对这个问题的方法,MRL具有几项显著优势:
- 减少嵌入大小:对于ImageNet-1K分类任务,使用MRL可以将嵌入大小减小至原来的1/14,同时保持相同的精度水平。
- 加速大规模检索:在处理像ImageNet-1K这样的大型数据集时,MRL可以提供高达14倍的实际加速,而检索准确性与常规方法相当。
- 提升长尾分类性能:MRL还能够在少样本长尾分类任务上带来最高2%的准确率提升,同时保持原有的鲁棒性。
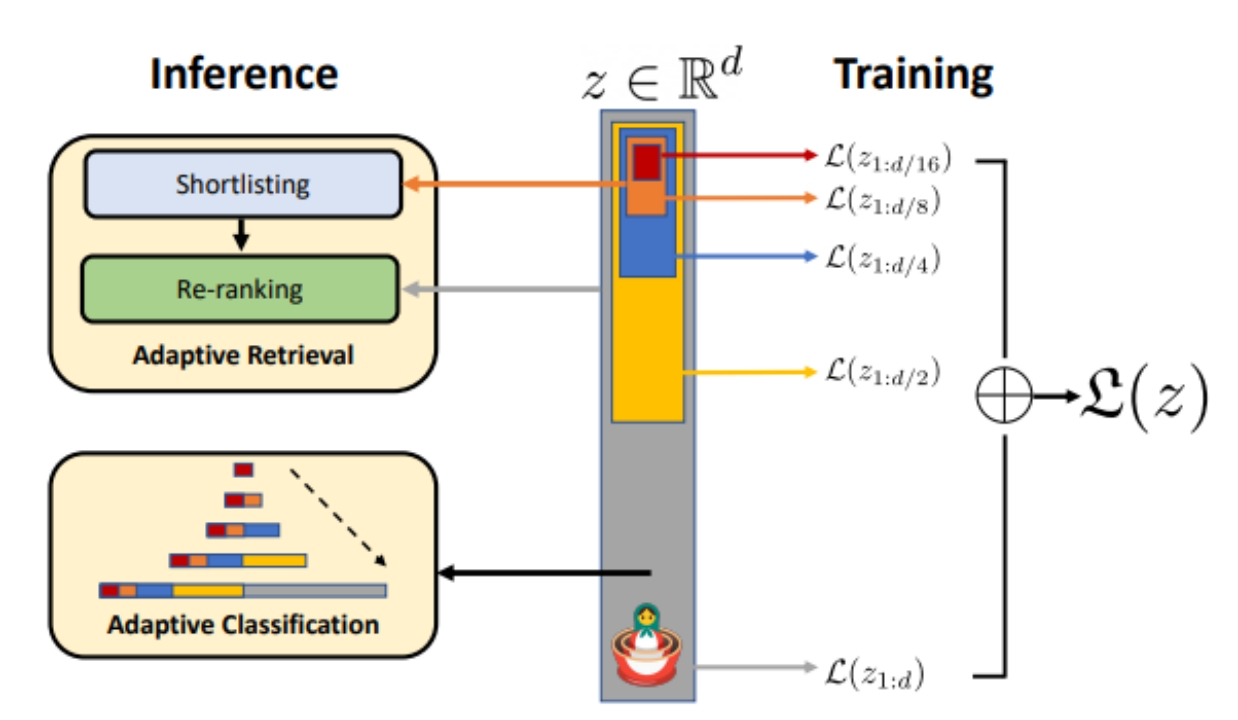 图4 MRL训练和推理
与目前C-MTEB榜单上排名前列的开源模型相比,acge模型体量较小,占用资源少;模型输入文本长度为1024,满足绝大部分场景的需求。此外,acge模型还支持可变输出维度,使应用者能够根据具体场景去合理分配资源。 随着NLP技术的不断进步,Embedding模型正朝着更高效的方向发展,包括轻量化模型以适应更多场景、增强可解释性以及通过多任务学习提升泛化能力。同时,开源社区的活跃促进了模型创新与应用落地,细分领域RAG的开发也不断取得进展,在需求的推动下,Embedding模型始终处于算法研究前沿。
[1] Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence em_x0002_beddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, 2019.
[2] Huang, Jui-Ting, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano and Linjun Yang. “Embedding-based Retrieval in Facebook Search.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2020): n. pag.
[3] Gao, Yunfan, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang and Haofen Wang. “Retrieval-Augmented Generation for Large Language Models: A Survey.” ArXiv abs/2312.10997 (2023): n. pag.
[4] Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, 2021.
[5] Kirkpatrick, James, Razvan Pascanu, Neil C. Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran and Raia Hadsell. “Overcoming catastrophic forgetting in neural networks.” Proceedings of the National Academy of Sciences 114 (2016): 3521 - 3526.
[6] Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. Matryoshka representation learning. Advances in Neural Information Processing Systems, 35:30233–30249, 2022.
标签:MRL,EWC,模型,语义,开源,学习,任务,Embedding
From: https://www.cnblogs.com/intsig/p/18516317
图4 MRL训练和推理
与目前C-MTEB榜单上排名前列的开源模型相比,acge模型体量较小,占用资源少;模型输入文本长度为1024,满足绝大部分场景的需求。此外,acge模型还支持可变输出维度,使应用者能够根据具体场景去合理分配资源。 随着NLP技术的不断进步,Embedding模型正朝着更高效的方向发展,包括轻量化模型以适应更多场景、增强可解释性以及通过多任务学习提升泛化能力。同时,开源社区的活跃促进了模型创新与应用落地,细分领域RAG的开发也不断取得进展,在需求的推动下,Embedding模型始终处于算法研究前沿。
[1] Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence em_x0002_beddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, 2019.
[2] Huang, Jui-Ting, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano and Linjun Yang. “Embedding-based Retrieval in Facebook Search.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2020): n. pag.
[3] Gao, Yunfan, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang and Haofen Wang. “Retrieval-Augmented Generation for Large Language Models: A Survey.” ArXiv abs/2312.10997 (2023): n. pag.
[4] Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, 2021.
[5] Kirkpatrick, James, Razvan Pascanu, Neil C. Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran and Raia Hadsell. “Overcoming catastrophic forgetting in neural networks.” Proceedings of the National Academy of Sciences 114 (2016): 3521 - 3526.
[6] Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. Matryoshka representation learning. Advances in Neural Information Processing Systems, 35:30233–30249, 2022.
标签:MRL,EWC,模型,语义,开源,学习,任务,Embedding
From: https://www.cnblogs.com/intsig/p/18516317