正在某学习平台做题,想着把题目复制出来和搜索娘深入探讨一下,却发现:
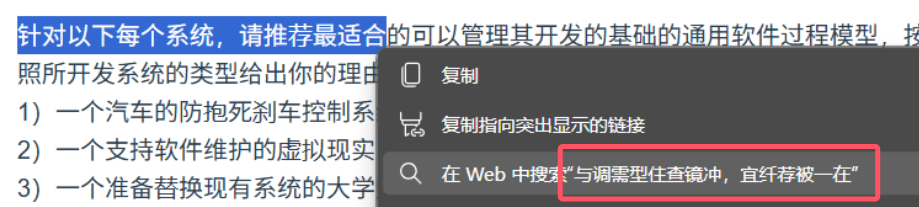
嗯?怎么是一坨火星文?
实际上有好几个学习平台都引入了这种字体混淆机制以防止复制,打乱了部分汉字 Unicode 码点和字形的对应关系。这回咱就来折腾折腾,看看这是怎么个事儿。

1. 怎么个混淆法
来到某课堂平台,打开一份作业题。
1.1. 找到字体
鉴于混淆机制很有可能是在字体上执行的,咱们先找一下网页载入时是不是顺带载入了一些额外的字体文件。
在浏览器开发者工具的“网络”面板中对“字体”类型的数据进行筛选:
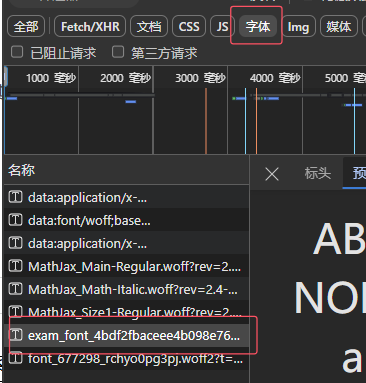
很快就能找到这个可疑的字体文件 exam_font_*.ttf,下载下来盘一盘。
1.2. 寻找字体的异常之处
以“针”字为例,其原本的 Unicode 码点为 0x9488。
'针'.codePointAt(0).toString(16)
// '9488'
查看网页中相应的 DOM 元素,可以发现元素文本内容的首个字符为汉字“户”,但是页面中渲染出来的却是“针”字:

“户”字的 Unicode 码点为 0x6237:
'户'.codePointAt(0).toString(16)
// 6237
这里采用一个开源的字体编辑器 (https://github.com/ecomfe/fonteditor/) ,来查看刚才下载的字体 exam_font_*.ttf 的情况。
- 搜索码点
$9488对应的字形:
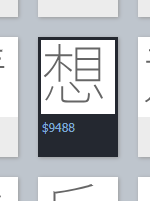
找到的字形并不是“针”。
2. 再搜索码点 $6237 对应的字形:
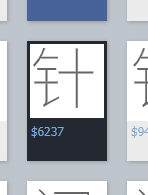
虽然用的是“户”字的码点,但找到的字形却是“针”的。
另外对比了几对码点和字形,发现都是这种情况:
- “母” (
0x6bcd) - 对应exam_font_*.ttf中的字形为 “对”

- “自” (
0x81ea) - 对应exam_font_*.ttf中的字形为 “统”

1.3. 可能的混淆实现方式
到这里,大致就可以猜出混淆的基本原理了:
- 定义原字形为 glpsglps,其字符码点为 unisunis
- 定义混淆后字符码点为 unitunit,unitunit 原本对应的字形为 glptglpt
对于某个字符,混淆的操作就是把字体文件中 unitunit 对应的字形(glptglpt)篡改为 glpsglps,且在网页中用字符码点 unitunit 取代 unisunis。
这样一来虽然文本内容上是 unitunit 对应的字符,但是网页中渲染出来的字形却是 glpsglps。
那么问题来了,这之中有什么规律吗?
咱首先猜测 unisunis 和 unitunit 之间存在一个固定的偏移,即 |unis−unit|=offset|unis−unit|=offset,以上面几对码点和字形为例来检验一下:
- “户” (
0x6237) - “针” (0x9488),计算得到 offset=0x3251offset=0x3251 - “母” (
0x6bcd) - “对” (0x5bf9),计算得到 offset=0x0fd4offset=0x0fd4 - “自” (
0x81ea) - “统” (0x7edf),计算得到 offset=0x030boffset=0x030b
看上去混淆并不只是给 unisunis 加上一个偏移...果然这玩意没有这么容易折腾哇!
2. 反混淆的突破口

在混淆前和混淆后有啥没变呢?没错,就是字形,即文字看上去的样子。如果我能根据字形找到其原本对应的码点 unisunis,问题不就迎刃而解了!大概思路表示如下:
unitexam_font_*.ttf−−−−−−−−−−−→glpsOriginal Font−−−−−−−−→unisunit→exam_font_*.ttfglps→Original Fontunis要找到字形和原码点的对应关系,那么就必须要找到原字体。
2.1. 找到原字体
从 exam_font_*.ttf 这个被混淆的 TrueType 字体入手,TrueType 字体在结构上主要由几张表组成,其中就包含有一张 name 表,记录有字体的版权声明、字体标识名等元数据。在这张表里咱们应该能找到些有用的信息。
采用 opentype.js 库来读取字体的 name 表:
const opentype = require('opentype.js');
const { readFileSync } = require('fs');
// 载入字体
let ttfBuffer = readFileSync('./exam_font_4bdf2fbaceee4b098e767a8149a1b21b.ttf');
const font = opentype.parse(
// Buffer 转换为 ArrayBuffer
ttfBuffer.buffer.slice(ttfBuffer.byteOffset, ttfBuffer.byteOffset + ttfBuffer.byteLength)
);
console.log(font.names)
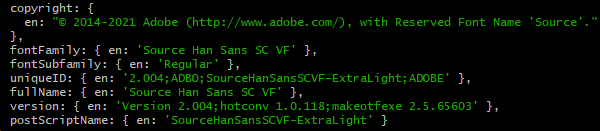
幸运的是,字体的几个重要元数据都被被保留下来了。能看到字体名是 Source Han Sans SC VF,即思源黑体,版本 2.004。
实际上 Source Han Sans 字体是基于 SIL 开源字体许可的,其也要求保留版权声明。
这字体可太出名了。很快啊!嗖的一下我就找到了其发布页,最新版本正好是 2.004:
 :蓝猫机场
:蓝猫机场
下载 VF (Variable Font, 可变字体) 版本,解压后正好能找到 SourceHanSansSC-VF.ttf
2.2. 检查字形是否一致
字形是某个字符的混淆后码点 unitunit 和原码点 unisunis 的桥梁,只有 exam_font_*.ttf 中 unitunit 对应的字形和 SourceHanSansSC-VF.ttf 中 unisunis 对应的字形(glpsglps)一致,咱们才有办法把 unitunit 还原到 unisunis。
以“针”这个字形为例,其在 exam_font_*.ttf 中对应 unit=0x6237unit=0x6237,在 SourceHanSansSC-VF.ttf 中对应 unis=0x9488unis=0x9488,通过 opentype.js 分别读取两个码点在两个文件中各自对应的字形:
// 此处略去两个字体 examFont, originalFont 的载入代码
// path.commands 决定了字形的绘制方式,因此可以通过对比 path.commands 是否一致来对比字形是否一致
let examCommands = examFont.charToGlyph(String.fromCodePoint(0x6237)).path.commands;
let originalCommands = originalFont.charToGlyph(String.fromCodePoint(0x9488)).path.commands;
// examCommands 和 originalCommands 都是 Object,作为无序结构,没法保证相同的对象能被序列化为相同的 JSON 字串,因此这是不严谨的比较。
// 但是,如果这种情况下输出 true,说明两个对象肯定是相同的
console.log(JSON.stringify(examCommands) === JSON.stringify(originalCommands))
// true
除了上面这个例子外,我还对多对码点 (unit,unis)(unit,unis) 进行了验证,此处不多赘述。
经过比较,可以发现每一对码点在两个字体文件中对应的两个字形都是相同的,也就是说混淆过程并没有在字形上动手脚。

这下算是验证了上面的猜测了,可让我找着突破口了。
3. 一些挑战
咱希望能在浏览器页面中就地对这些文字进行反混淆处理,但这样一来肯定会遇到下面的几个问题。
3.1. 每次刷新页面,采用的字体文件都不同
如果混淆字体 exam_font_*.ttf 只有一份,我可以直接在本地处理出一个 Unicode 映射表,在网页中直接把被混淆的字符码点按映射表全部映射回原本的 Unicode 码点即可。
但平台在这点上也挺鸡贼,每次刷新页面后,都会随机取出一个 exam_font_*.ttf ,对应混淆后的字符码点 unitunit 也都不同。

因此我必须要能在页面中截获字体文件 exam_font_*.ttf 的 URL 并就地将字体读取出来进行处理。
3.2. 如何唯一地标识字形
上面提到,反混淆的突破口是字形。
在拿到 exam_font_*.ttf 后,我应当能用其中的每一个字形在原字体 SourceHanSansSC-VF.ttf 中找到字符的原码点 unisunis,为此要建立字形到原码点的映射。而要建立这种映射,我需要能唯一地标识每个字形。
4. 字符大恢复术
4.1. 获取混淆字体的 URL
被混淆部分的字符只有通过基于特定字体的渲染后才能变成咱们所看到的样子,因此在这些被混淆部分的 DOM 元素上肯定能找到些幺蛾子:
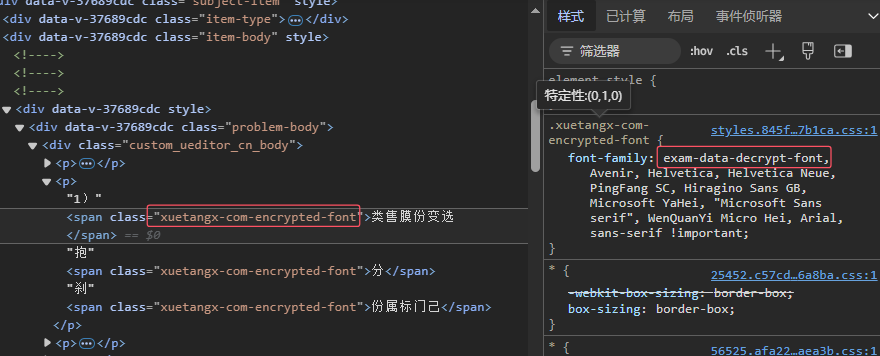
可以看到这些文本被混淆的元素都有一个特定的 class,顺着 class 对应的样式能找到一个很显眼的字体族 exam-data-decrypt-font,这个肯定就是这个平台自定义的一个字体族了。
字体族中的值要么是本机的字体族名,要么是在 CSS 中使用 @font-face 指定的自定义字体。这里明显是后者,采用 @font-face 载入了字体 exam_font_*.ttf。
回到开发者工具-网络面板,搜索 "exam_font",看看这个字体是怎么被载入的:
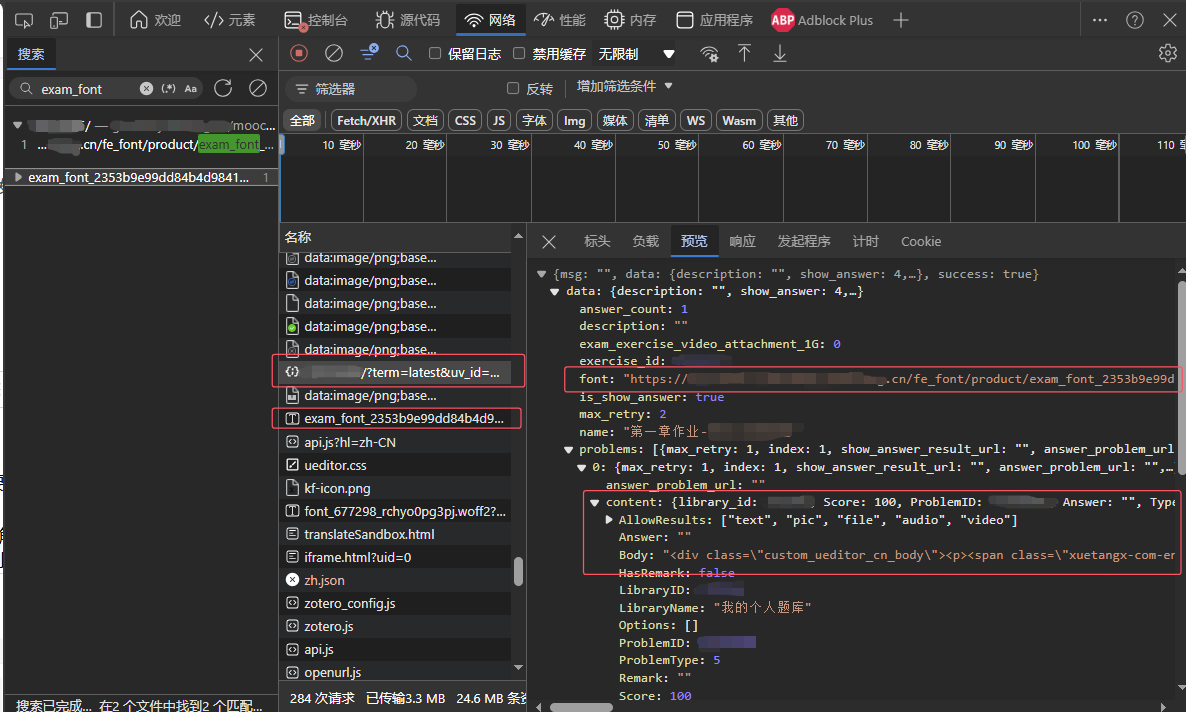
可以发现这个学习平台的页面中的被混淆段落是动态载入的,响应的 JSON 中还包含 font 这个字段,其中正好就是 exam_font_*.ttf 的 URL。在拿到了字体 URL 后才有办法建立基于 @font-face 的样式,因此字体族相关的样式表肯定也是动态载入页面的,也就是说我应该能在 DOM 中找到相应的元素。
在开发者工具-元素面板中搜索字体族名 "exam-data-decrypt-font":
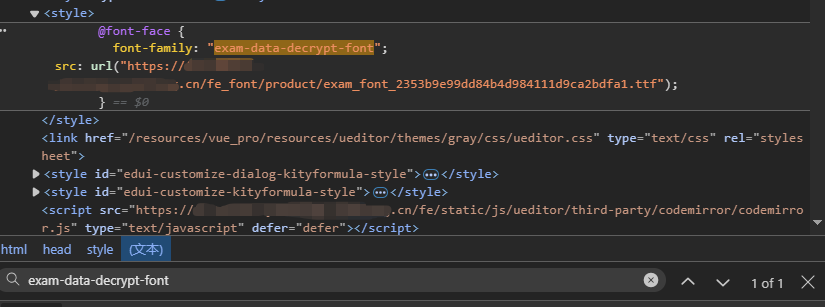
嘿,老伙计,瞧瞧咱们发现了什么!果然相关的样式是通过内部样式表 来动态插入的,这样一来我就可以在 JavaScript 中定位到这个元素,并获取到字体 URL 了:
const styleElems = document.querySelectorAll('style');
// 和混淆字体相关的样式
let fontStyle = '';
for (let s of styleElems) {
// 正则表达式,小子!
if (/font-family:\s*\"exam-data-decrypt-font\"/.test(s.innerHTML)) {
// 先找到和 exam-data-decrypt-font 相关的 font-face 样式
fontStyle = s.innerHTML;
break;
}
}
let matches = fontStyle.match(/url\("(.+?)"\)/);
// 被混淆字体的 URL
let obfuscatedFontUrl = matches[1];
就算找不到这样的元素,也可以枚举所有引入的样式表 document.styleSheets 来找到 @font-face 规则。
4.2. 唯一地标识每个字形
接下来要解决的问题就是如何唯一地标识每个字形。
TTF 字体中,决定字形的是一个轮廓(contour)序列,相同的字形的 contour 序列应当是一致的。
而在 opentype.js 库中, contour 序列被大致表示成了一种易于与 SVG 进行转换的绘制命令序列 glyph.path.commands,相同的字形的绘制命令应当也是一致的。咱们的目标就是唯一地标识这个序列。
要唯一地标识这种序列,首先能想到的就是为每个序列计算一个在数万(一个字体文件内可能有数以万计的字形)的规模下唯一的散列值,比如计算较快的 SHA-1 值。
用散列值唯一标识字形还可以大大减少最终生成的映射表(字形→原码点)的体积,基于散列值进行存储和运算操作也开销较小,使得反混淆操作在浏览器中实际可行。
对于相同的字形要计算出相同的散列值,需要保证用于散列计算的输入在相同字形下总是一致的。glyph.path.commands 是有序的数组结构,但是 commands 中每一项是无序的 JavaScript 键值对对象 (Object),为了转无序为有序,可以先按照固定的排序规则进行处理,然后按序拼接为字串:
let strToBeHashed = '';
for (let i = 0; i < pathCommands.length; i++) {
// entries 枚举对象的 [键, 值],组成一个数组,转换为有序结构。
let sortedCommand = Object.entries(pathCommands[i]).sort((a, b) => {
if (a[0] != b[0]) {
// 先按键排
return a[0] - b[0];
} else {
// 键相同就按值排
return a[1] - b[1];
}
});
for (let kv of sortedCommand) {
// 顺序拼接起来成为字串
strToBeHashed += (kv[0].toString() + kv[1].toString());
}
}
相同字形下的 strToBeHashed 是一致的,将这个字串转换为字节串,就可以计算出这个字形对应的 SHA-1 值了:
let hash = Array.from(
new Uint8Array(
await crypto.subtle.digest('SHA-1',
new TextEncoder().encode(strToBeHashed)
)
)
).map(b => b.toString(16).padStart(2, '0')).join('');
// 最终把输出的字节串转换为 16 进制表示,两位表示一个字节
这里用了
Crypto这个 Web API。
4.3. 烘焙映射表
已知要还原字符,需要建立的映射是:
unitexam_font_*.ttf−−−−−−−−−−−→hash(glps)SourceHanSansSC-VF.ttf−−−−−−−−−−−−−−−−→unisunit→exam_font_*.ttfhash(glps)→SourceHanSansSC-VF.ttfunis上面提到过,每次页面载入的 exam_font_*.ttf 是不同的,即 unitunit 至 hash(glps)hash(glps) 的映射关系是在变动的,因此必须实时在浏览器中进行处理。
而在找到原字体 SourceHanSansSC-VF.ttf 后, hash(glps)hash(glps) 到原码点 unisunis 的映射是固定不变的,因此我可以在本地预先建立二者的映射表,在浏览器中执行处理时只用载入映射表进行映射即可,能大大减小开销。
检查发现 exam_font_*.ttf 似乎只对汉字字符进行了混淆,因此我可以只导出汉字字形和原码点的映射关系,以减小映射表文件体积。
由于一些历史原因,在不同的 Unicode 码点区间可能有看上去相同的汉字,字体设计者可能让这些码点共用一个字形。比如 SourceHanSansSC-VF.ttf 字体中 “一” 这个字形就对应有 0x2F00 和 0x4E00 两个码点。
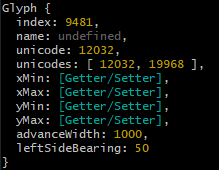
上图为
opentype.js获取的 “一” 对应的字形信息,在unicodes属性中可以看到有两个码点。
- 因此在这里咱依赖于
glyph.unicodes这个数组来对汉字进行筛选。
筛选汉字字符时往往会采用 [0x4E00, 0x9FFF][0x4E00, 0x9FFF] 这个码点区间,这部分子字符集被称作 CJK Unified Ideographs(中日韩统一表意文字):
const isChineseChar = (unicodeArr) => {
for (let u of unicodeArr) {
if (u >= 0x4E00 && u <= 0x9FFF)
return true;
}
return false;
}
建立映射表的过程实际上就是遍历字体中的字形表的每个字形,并拿到其对应的 Unicode 码点,然后将计算得到的字形的唯一标识(SHA-1)和码点对应起来:
// opentype.js Font 对象的 Glyph 列表(其实也是一个 Object)
const glyphs = font.glyphs.glyphs;
let glyphsToUni = {};
for (let i in glyphs) {
if (isChineseChar(glyphs[i].unicodes)) {
// 设 hashGlyph 为字形的 SHA-1 值计算函数
let [glyphHash, _] = await hashGlyph(glyphs[i].path.commands);
if (Object.hasOwn(glyphsToUni, glyphHash)) {
// 字形哈希发生碰撞,一般不会有这种情况。
// pass
}
glyphsToUni[glyphHash] = glyphs[i].unicode;
}
}
// 序列化得到 原字形 glp_s 至原码点 uni_s 的映射表
writeFileSync('./original_glyph_to_uni.json', JSON.stringify(glyphsToUni), {
encoding: "utf-8"
});
4.4. 在页面中将混淆后的码点映射回原码点
在页面中抓取到混淆字体 exam_font_*.ttf 并解析后,就可以建立以下的映射关系了:
unitexam_font_*.ttf−−−−−−−−−−−→hash(glps)unit→exam_font_*.ttfhash(glps)遍历混淆字体中的每一个字形 glpsglps,其码点就是 unitunit 了。
再辅以上面映射表 original_glyph_to_uni.json 提供的映射关系:
hash(glps)SourceHanSansSC-VF.ttf−−−−−−−−−−−−−−−−→unishash(glps)→SourceHanSansSC-VF.ttfunis就可以根据传递性得到映射关系:
unit→unisunit→unis代码实现的片段如下:
// loadFont: 载入字体数据后用 opentype.js 解析为 Font 对象
const obfuscatedFont = await loadFont(obfuscatedFontUrl);
// 混淆字体的所有字形
let obfuscatedGlyphs = obfuscatedFont.glyphs.glyphs;
// hash(glp_s) 至 uni_s 的映射表
const originalGlyphToUni = await fetch('original_glyph_to_uni.json').then(res => res.json());
// 混淆后的 uni_t 至原 uni_s 的映射
const obfuscatedToOriginal = {};
for (let i in obfuscatedGlyphs) {
let { unicode, path } = obfuscatedGlyphs[i];
if (unicode === undefined) // 跳过未知码点的
continue;
// 设 hashGlyph 为字形的 SHA-1 值计算函数
// 即 glyphHash = hash(glp_s)
let [glyphHash, _] = await hashGlyph(path.commands);
// 先寻找映射表中是否有键 glyphHash
if (Object.hasOwn(originalGlyphToUni, glyphHash)) {
// uni_t -> glyphHash -> uni_s
obfuscatedToOriginal[unicode] = originalGlyphToUni[glyphHash];
} else {
// 没有找到字形对应的 uni_s
}
}
你可能好奇这里我为什么没用
glyph.unicodes,不是说一个字形可能对应多个码点吗?其实是因为我发现这样写其实就已经能达成目的了 (・ω<)。
4.5. 临门一脚
最后根据上一小节得到的映射 obfuscatedToOriginal 把页面中的被混淆段落的字符全部还原即可。
在上面 4.1 节中咱们发现被混淆段落的元素都有一个特定的 class,因此只需要将这些元素的文本内容进行替换即可。
const obfuscatedElems = document.querySelectorAll('.xuetangx-com-encrypted-font');
for (let elem of obfuscatedElems) {
let resultHtml = '';
for (let chr of elem.innerHTML) {
if (/[\u4e00-\u9fff]/g.test(chr)) {
// 仅处理汉字字符
let uni_t = chr.codePointAt(0);
if (Object.hasOwn(obfuscatedToOriginal, uni_t)) {
let realChr = String.fromCodePoint(obfuscatedToOriginal[uni_t]);
resultHtml += realChr;
} else {
// 没有映射成功
}
} else {
resultHtml += chr;
}
}
elem.innerHTML = resultHtml;
// 取消掉 class,以用原字体渲染字符
elem.classList.remove('xuetangx-com-encrypted-font');
}
把上面这些代码片段结合起来,在页面中执行一次后,蹬蹬蹬~ 现在每个汉字都“字如其貌”了!

5. 写在最后

咱这回写这篇笔记主要也是为了记录一下解决这类问题的思路,事实上也有很多网站采用了类似的混淆方法来实现反爬机制。
可以发现整个反混淆过程中最关键的一步就是找到原字体,如果没有原字体,建立码点映射关系就没有那么容易了。
但...也不是没有办法。最容易能想到的手段就是 OCR 了,也就是让映射关系变成下面这样:
unitexam_font_*.ttf−−−−−−−−−−−→glpsOCR−−−→unisunit→exam_font_*.ttfglps→OCRunis然而这样一来,开销就会变大很多了。
无论是防止文本被复制,还是抵御爬虫抓取,这类防御手段的核心意图就在于:“虽然无法完全杜绝此类行为,但我可以提高门槛,增加你实施这些行为的成本。”
标签:混淆,dm,字形,探探,字体,码点,font,ttf,小记 From: https://www.cnblogs.com/westworldss/p/18508243