目录
CRUSH Map 功能简介
把一组 osd 组合起来,决定数据如何分布。默认以主机为单位进行分布
数据在集群中怎么样进行分配的
数据在集群中的容灾级别是怎么样进行控制的
CRUSH Maps
The CRUSH algorithm
determines how to store and retrieve data by computing storage locations.
CRUSH empowers Ceph clients to communicate with OSDs directly rather than
through a centralized server or broker. With an algorithmically determined
method of storing and retrieving data, Ceph avoids a single point of failure, a
performance bottleneck, and a physical limit to its scalability.
CRUSH uses a map of your cluster (the CRUSH map) to pseudo-randomly
map data to OSDs, distributing it across the cluster according to configured
replication policy and failure domain. For a detailed discussion of CRUSH, see
CRUSH - Controlled, Scalable, Decentralized Placement of Replicated Data
CRUSH maps contain a list of OSDs, a hierarchy
of ‘buckets’ for aggregating devices and buckets, and
rules that govern how CRUSH replicates data within the cluster’s pools. By
reflecting the underlying physical organization of the installation, CRUSH can
model (and thereby address) the potential for correlated device failures.
Typical factors include chassis, racks, physical proximity, a shared power
source, and shared networking. By encoding this information into the cluster
map, CRUSH placement
policies distribute object replicas across failure domains while
maintaining the desired distribution. For example, to address the
possibility of concurrent failures, it may be desirable to ensure that data
replicas are on devices using different shelves, racks, power supplies,
controllers, and/or physical locations.
When you deploy OSDs they are automatically added to the CRUSH map under a
host bucket named for the node on which they run. This,
combined with the configured CRUSH failure domain, ensures that replicas or
erasure code shards are distributed across hosts and that a single host or other
failure will not affect availability. For larger clusters, administrators must
carefully consider their choice of failure domain. Separating replicas across racks,
for example, is typical for mid- to large-sized clusters.
Types and Buckets
A bucket is the CRUSH term for internal nodes in the hierarchy: hosts,
racks, rows, etc. The CRUSH map defines a series of types that are
used to describe these nodes. Default types include:
osd(ordevice) # 默认叶子节点为 osdhost# 主机chassis# 机架rack# 机架row# 行pdupodroom# 房间datacenter# 数据中心zone# 地区region# 区域root# 根
Most clusters use only a handful of these types, and others
can be defined as needed.
The hierarchy is built with devices (normally type osd) at the
leaves, interior nodes with non-device types, and a root node of type
root. For example,
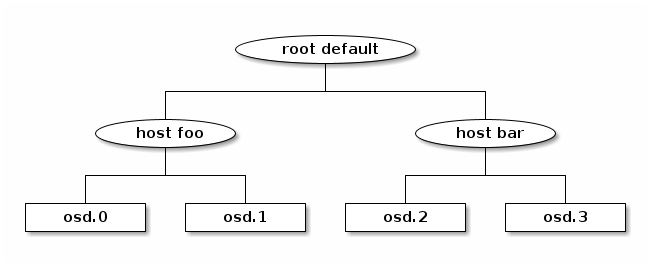
Each node (device or bucket) in the hierarchy has a weight
that indicates the relative proportion of the total
data that device or hierarchy subtree should store. Weights are set
at the leaves, indicating the size of the device, and automatically
sum up the tree, such that the weight of the root node
will be the total of all devices contained beneath it. Normally
weights are in units of terabytes (TB).
You can get a simple view the of CRUSH hierarchy for your cluster,
including weights, with:
ceph osd tree
CRUSH Map 规则解析
CRUSH Map 规则查看
- 查看命令
[root@node0 ~]# ceph osd crush tree
ID CLASS WEIGHT TYPE NAME
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0
3 hdd 0.04880 osd.3
-5 0.09760 host node1
1 hdd 0.04880 osd.1
4 hdd 0.04880 osd.4
-7 0.09760 host node2
2 hdd 0.04880 osd.2
5 hdd 0.04880 osd.5
- 其他查看方式
[root@node0 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
# 当前是以 host 为单位的 bucket,bucket 里面包含 osd,每个 osd 有一个分类(CLASS) hdd,每个盘都有一个权重 reweight
- 详细查看 crush
[root@node0 ceph-deploy]# ceph osd crush dump
{
"devices": [
{
"id": 0,
"name": "osd.0",
"class": "hdd"
},
{
"id": 1,
"name": "osd.1",
"class": "hdd"
},
{
"id": 2,
"name": "osd.2",
"class": "hdd"
},
{
"id": 3,
"name": "osd.3",
"class": "hdd"
},
{
"id": 4,
"name": "osd.4",
"class": "hdd"
},
{
"id": 5,
"name": "osd.5",
"class": "hdd"
}
],
"types": [ # types 类型以及对应的 type_id
{
"type_id": 0,
"name": "osd"
},
{
"type_id": 1,
"name": "host"
},
{
"type_id": 2,
"name": "chassis"
},
{
"type_id": 3,
"name": "rack"
},
{
"type_id": 4,
"name": "row"
},
{
"type_id": 5,
"name": "pdu"
},
{
"type_id": 6,
"name": "pod"
},
{
"type_id": 7,
"name": "room"
},
{
"type_id": 8,
"name": "datacenter"
},
{
"type_id": 9,
"name": "zone"
},
{
"type_id": 10,
"name": "region"
},
{
"type_id": 11,
"name": "root"
}
],
"buckets": [
{
"id": -1,
"name": "default",
"type_id": 11, # default type_id 为 11,所以 default 默认使用 type 为 root 根
"type_name": "root",
"weight": 19188,
"alg": "straw2",
"hash": "rjenkins1",
"items": [ # 关联的节点 id -3 ,-5, -7
{
"id": -3,
"weight": 6396,
"pos": 0
},
{
"id": -5,
"weight": 6396,
"pos": 1
},
{
"id": -7,
"weight": 6396,
"pos": 2
}
]
},
{
"id": -2,
"name": "default~hdd",
"type_id": 11,
"type_name": "root",
"weight": 19188,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": -4,
"weight": 6396,
"pos": 0
},
{
"id": -6,
"weight": 6396,
"pos": 1
},
{
"id": -8,
"weight": 6396,
"pos": 2
}
]
},
{
"id": -3, # 关联的节点 id -3 , 关联 node0 主机的 0, 3 osd 磁盘
"name": "node0",
"type_id": 1,
"type_name": "host",
"weight": 6396,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 0,
"weight": 3198,
"pos": 0
},
{
"id": 3,
"weight": 3198,
"pos": 1
}
]
},
{
"id": -4,
"name": "node0~hdd",
"type_id": 1,
"type_name": "host",
"weight": 6396,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 0,
"weight": 3198,
"pos": 0
},
{
"id": 3,
"weight": 3198,
"pos": 1
}
]
},
{
"id": -5, # 关联的节点 id -5 , 关联 node1 主机的 1, 4 osd 磁盘
"name": "node1",
"type_id": 1,
"type_name": "host",
"weight": 6396,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 1,
"weight": 3198,
"pos": 0
},
{
"id": 4,
"weight": 3198,
"pos": 1
}
]
},
{
"id": -6,
"name": "node1~hdd",
"type_id": 1,
"type_name": "host",
"weight": 6396,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 1,
"weight": 3198,
"pos": 0
},
{
"id": 4,
"weight": 3198,
"pos": 1
}
]
},
{
"id": -7, # 关联的节点 id -7 , 关联 node2 主机的 2, 5 osd 磁盘
"name": "node2",
"type_id": 1,
"type_name": "host",
"weight": 6396,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 2,
"weight": 3198,
"pos": 0
},
{
"id": 5,
"weight": 3198,
"pos": 1
}
]
},
{
"id": -8,
"name": "node2~hdd",
"type_id": 1,
"type_name": "host",
"weight": 6396,
"alg": "straw2",
"hash": "rjenkins1",
"items": [
{
"id": 2,
"weight": 3198,
"pos": 0
},
{
"id": 5,
"weight": 3198,
"pos": 1
}
]
}
],
"rules": [
{
"rule_id": 0,
"rule_name": "replicated_rule",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
],
"tunables": {
"choose_local_tries": 0,
"choose_local_fallback_tries": 0,
"choose_total_tries": 50,
"chooseleaf_descend_once": 1,
"chooseleaf_vary_r": 1,
"chooseleaf_stable": 1,
"straw_calc_version": 1,
"allowed_bucket_algs": 54,
"profile": "jewel",
"optimal_tunables": 1,
"legacy_tunables": 0,
"minimum_required_version": "jewel",
"require_feature_tunables": 1,
"require_feature_tunables2": 1,
"has_v2_rules": 0,
"require_feature_tunables3": 1,
"has_v3_rules": 0,
"has_v4_buckets": 1,
"require_feature_tunables5": 1,
"has_v5_rules": 0
},
"choose_args": {}
}
Rules
CRUSH Rules define policy about how data is distributed across the devices
in the hierarchy. They define placement and replication strategies or
distribution policies that allow you to specify exactly how CRUSH
places data replicas. For example, you might create a rule selecting
a pair of targets for two-way mirroring, another rule for selecting
three targets in two different data centers for three-way mirroring, and
yet another rule for erasure coding (EC) across six storage devices. For a
detailed discussion of CRUSH rules, refer to CRUSH - Controlled,
Scalable, Decentralized Placement of Replicated Data, and more
specifically to Section 3.2.
CRUSH rules can be created via the CLI by
specifying the pool type they will be used for (replicated or
erasure coded), the failure domain, and optionally a device class.
In rare cases rules must be written by hand by manually editing the
CRUSH map.
You can see what rules are defined for your cluster with:
ceph osd crush rule ls
You can view the contents of the rules with:
ceph osd crush rule dump
# 查看集群 crush rule 规则
[root@node0 ceph-deploy]# ceph osd crush rule ls
replicated_rule
# 查看 pool 对于的 crush rule 规则
[root@node0 ceph-deploy]# ceph osd pool get ceph-demo crush_rule
crush_rule: replicated_rule
[root@node0 ceph-deploy]# ceph osd crush rule dump
[
{
"rule_id": 0,
"rule_name": "replicated_rule",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
]
定制 CRUSH 拓扑架构
CRUSH Map 规则定制分为2种,一种配置文件手动编辑,一种命令行命令编辑
配置文件手动编辑步骤
To edit an existing CRUSH map:
- Get the CRUSH map.
- Decompile the CRUSH map.
- Edit at least one of Devices, Buckets and Rules.
- Recompile the CRUSH map.
- Set the CRUSH map.
1、获取配置文件
2、反编译配置文件
3、编写新的 CRUSH Map 规则
4、编译为 CRUSH Map 配置文件
5、应用的 ceph 集群
命令行编辑步骤
Add a Bucket
To add a bucket in the CRUSH map of a running cluster, execute the
ceph osd crush add-bucket command:
ceph osd crush add-bucket {bucket-name} {bucket-type}
Move a Bucket
To move a bucket to a different location or position in the CRUSH map
hierarchy, execute the following:
ceph osd crush move {bucket-name} {bucket-type}={bucket-name}, [...]
Move a OSD
ceph osd crush move {osd-name} {bucket-type}={bucket-name}, {bucket-type}={bucket-name}, [...]
Creating a rule for a replicated pool
To create a replicated rule:
ceph osd crush rule create-replicated {name} {root} {failure-domain-type} [{class}]
CRUSH 拓扑架构

手动编辑 CRUSH Map
获取 crushmap 信息
[root@node0 ceph-deploy]# mkdir crushmap
[root@node0 ceph-deploy]# cd crushmap/
[root@node0 crushmap]# ls
[root@node0 crushmap]# ceph osd getcrushmap -o crushmap.bin
18
[root@node0 crushmap]# ls
crushmap.bin
查看文件属性为二进制文件
[root@node0 crushmap]# file crushmap.bin
crushmap.bin: MS Windows icon resource - 8 icons, 1-colors
反编译 crushmap.bin 为文本文件
[root@node0 crushmap]# crushtool -d crushmap.bin -o crushmap.txt
查看 crushmap 规则文件
[root@node0 crushmap]# cat crushmap.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices ## osd id 名称以及 class 归类
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
# types ## 类型定义,数据组织类型
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets ## buckets 中 osd 如何进行数据存放
host node0 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.049
item osd.3 weight 0.049
}
host node1 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.1 weight 0.049
item osd.4 weight 0.049
}
host node2 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.049
item osd.5 weight 0.049
}
## root 放入 host buckets
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.293
alg straw2
hash 0 # rjenkins1
item node0 weight 0.098
item node1 weight 0.098
item node2 weight 0.098
}
# rules ## rules 规则,采用 replicated
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush map
编写新的 CRUSH rule 规则
[root@node0 crushmap]# cp crushmap.txt crushmap_new.txt
[root@node0 crushmap]# cat crushmap_new.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host node0 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.049
}
host node1 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.1 weight 0.049
}
host node2 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.049
}
## 新定义的 buckets,同时需要从原有的 buckets 中删除 osd.3-5
host node0-ssd {
id -13 # do not change unnecessarily
id -14 class ssd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.049
}
host node1-ssd {
id -15 # do not change unnecessarily
id -16 class ssd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.4 weight 0.049
}
host node2-ssd {
id -17 # do not change unnecessarily
id -18 class ssd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.5 weight 0.049
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.293
alg straw2
hash 0 # rjenkins1
item node0 weight 0.049 # 权重需要修改
item node1 weight 0.049
item node2 weight 0.049
}
## 新增加 root
root ssd {
id -11 # do not change unnecessarily
id -12 class ssd # do not change unnecessarily
# weight 0.293
alg straw2
hash 0 # rjenkins1
item node0-ssd weight 0.049 # 权重需要修改
item node1-ssd weight 0.049
item node2-ssd weight 0.049
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
## 新增加 rules 规则
rule demo_rule {
id 10
type replicated
min_size 1
max_size 10
step take ssd
step chooseleaf firstn 0 type host
step emit
}
# end crush map
编译新配置文件 crushmap_new.txt 为二进制文件
[root@node0 crushmap]# crushtool -c crushmap_new.txt -o crushmap_new.bin
应用规则
- 查看当前 crush map 规则
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
- 应用新的规则
# 应用规则
[root@node0 crushmap]# ceph osd setcrushmap -i crushmap_new.bin
22
# 查看规则
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-11 0.14699 root ssd
-13 0.04900 host node0-ssd
3 hdd 0.04900 osd.3 up 1.00000 1.00000
-15 0.04900 host node1-ssd
4 hdd 0.04900 osd.4 up 1.00000 1.00000
-17 0.04900 host node2-ssd
5 hdd 0.04900 osd.5 up 1.00000 1.00000
-1 0.14699 root default
-3 0.04900 host node0
0 hdd 0.04900 osd.0 up 1.00000 1.00000
-5 0.04900 host node1
1 hdd 0.04900 osd.1 up 1.00000 1.00000
-7 0.04900 host node2
2 hdd 0.04900 osd.2 up 1.00000 1.00000
验证新的 ssd 规则
- 设置 pool 为新规则
# 查看 ceph-demo 的 crushmap 规则
[root@node0 crushmap]# ceph osd pool get ceph-demo crush_rule
crush_rule: replicated_rule
# 查看当前集群的 crushmap 规则
[root@node0 crushmap]# ceph osd crush rule ls
replicated_rule
demo_rule
# 设置 ceph-demo crush_rule 为新规则
[root@node0 crushmap]# ceph osd pool set ceph-demo crush_rule demo_rule
set pool 1 crush_rule to demo_rule
# 验证 ceph-demo crush_rule
[root@node0 crushmap]# ceph osd pool get ceph-demo crush_rule
crush_rule: demo_rule
- 验证 pool 资源映射关系是否为 osd.3-5
# 创建 rdb
[root@node0 crushmap]# rbd create ceph-demo/crush-demo.img --size 1G
# 查看资源映射关系
[root@node0 crushmap]# ceph osd map ceph-demo crush-demo.img
osdmap e414 pool 'ceph-demo' (1) object 'crush-demo.img' -> pg 1.d267742c (1.2c) -> up ([4,3], p4) acting ([4,3], p4)
# 修改 pool size 为 3
[root@node0 crushmap]# ceph osd pool get ceph-demo size
size: 2
[root@node0 crushmap]# ceph osd pool set ceph-demo size 3
set pool 1 size to 3
# 重新查看资源映射关系是否只在 osd.3-5 上
[root@node0 crushmap]# ceph osd map ceph-demo crush-demo.img
osdmap e416 pool 'ceph-demo' (1) object 'crush-demo.img' -> pg 1.d267742c (1.2c) -> up ([4,3,5], p4) acting ([4,3,5], p4)
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-11 0.14699 root ssd
-13 0.04900 host node0-ssd
3 hdd 0.04900 osd.3 up 1.00000 1.00000
-15 0.04900 host node1-ssd
4 hdd 0.04900 osd.4 up 1.00000 1.00000
-17 0.04900 host node2-ssd
5 hdd 0.04900 osd.5 up 1.00000 1.00000
-1 0.14699 root default
-3 0.04900 host node0
0 hdd 0.04900 osd.0 up 1.00000 1.00000
-5 0.04900 host node1
1 hdd 0.04900 osd.1 up 1.00000 1.00000
-7 0.04900 host node2
2 hdd 0.04900 osd.2 up 1.00000 1.00000
- 验证老的 pool 资源映射是否只在 osd.0-2 上
[root@node0 crushmap]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_metadata
9 cephfs_data
[root@node0 crushmap]# rbd create cephfs_data/demo.img --size 1G
[root@node0 crushmap]# ceph osd map cephfs_data demo.img
osdmap e418 pool 'cephfs_data' (9) object 'demo.img' -> pg 9.c1a6751d (9.d) -> up ([1,0,2], p1) acting ([1,0,2], p1)
回滚 CRUSH Map 规则
# 使用 crushmap.bin 配置信息回滚配置
[root@node0 crushmap]# ceph osd setcrushmap -i crushmap.bin
Error EINVAL: pool 1 references crush_rule 10 but it is not present
# 回滚报错,因为有 pool 使用 dome_rule 新规则,修改 ceph-demo crush_rule 规则
[root@node0 crushmap]# ceph osd pool set ceph-demo crush_rule replicated_rule
set pool 1 crush_rule to replicated_rule
# 再次回滚 crushmap 规则
[root@node0 crushmap]# ceph osd setcrushmap -i crushmap.bin23
23
# 查看 crushmap
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
命令行调整 CRUSH Map
添加一个 type = root bucket
[root@node0 crushmap]# ceph osd crush add-bucket ssd root
added bucket ssd type root to crush map
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 0 root ssd
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
添加一个 3 个 type = host bucket
[root@node0 crushmap]# ceph osd crush add-bucket node0-ssd host
added bucket node0-ssd type host to crush map
[root@node0 crushmap]# ceph osd crush add-bucket node1-ssd host
added bucket node1-ssd type host to crush map
[root@node0 crushmap]# ceph osd crush add-bucket node2-ssd host
added bucket node2-ssd type host to crush map
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-12 0 host node2-ssd
-11 0 host node1-ssd
-10 0 host node0-ssd
-9 0 root ssd
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
移动 type = host bucket 到 root 下
[root@node0 crushmap]# ceph osd crush move node0-ssd root=ssd
moved item id -10 name 'node0-ssd' to location {root=ssd} in crush map
[root@node0 crushmap]# ceph osd crush move node1-ssd root=ssd
moved item id -11 name 'node1-ssd' to location {root=ssd} in crush map
[root@node0 crushmap]# ceph osd crush move node2-ssd root=ssd
moved item id -12 name 'node2-ssd' to location {root=ssd} in crush map
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 0 root ssd
-10 0 host node0-ssd
-11 0 host node1-ssd
-12 0 host node2-ssd
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
往 type = host bucket 中填充 osd 数据
[root@node0 crushmap]# ceph osd crush move osd.3 host=node0-ssd root=ssd
moved item id 3 name 'osd.3' to location {host=node0-ssd,root=ssd} in crush map
[root@node0 crushmap]# ceph osd crush move osd.4 host=node1-ssd root=ssd
moved item id 4 name 'osd.4' to location {host=node1-ssd,root=ssd} in crush map
[root@node0 crushmap]# ceph osd crush move osd.5 host=node2-ssd root=ssd
moved item id 5 name 'osd.5' to location {host=node2-ssd,root=ssd} in crush map
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 0.14639 root ssd
-10 0.04880 host node0-ssd
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-11 0.04880 host node1-ssd
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-12 0.04880 host node2-ssd
5 hdd 0.04880 osd.5 up 1.00000 1.00000
-1 0.14639 root default
-3 0.04880 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
-5 0.04880 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
创建 crush_rule 规则和 root=ssd 关联
# 查看创建规则命令帮助
[root@node0 crushmap]# ceph osd crush rule create-replicated
Invalid command: missing required parameter name(<string(goodchars [A-Za-z0-9-_.])>)
osd crush rule create-replicated <name> <root> <type> {<class>} : create crush rule <name> for replicated pool to start from <root>, replicate across buckets of type <type>, use devices of type <class> (ssd or hdd)
Error EINVAL: invalid command
# 创建 crush_rule 规则
[root@node0 crushmap]# ceph osd crush rule create-replicated demo_rule ssd host hdd
# 查看 rule 详细信息
[root@node0 crushmap]# ceph osd crush rule dump
[
{
"rule_id": 0,
"rule_name": "replicated_rule",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
},
{
"rule_id": 1,
"rule_name": "demo_rule",
"ruleset": 1,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -16,
"item_name": "ssd~hdd"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
]
# 查看 crush rule 规则
[root@node0 crushmap]# ceph osd crush rule ls
replicated_rule
demo_rule
验证新的 ssd 规则
# 设置 ceph-demo 规则为 demo_rule
[root@node0 crushmap]# ceph osd pool set ceph-demo crush_rule demo_rule
set pool 1 crush_rule to demo_rule
# 查看规则
[root@node0 crushmap]# ceph osd pool get ceph-demo crush_rule
crush_rule: demo_rule
# 查看 rbd
[root@node0 crushmap]# rbd -p ceph-demo ls
crush-demo.img
rdb-demo.img
# 查看 pool 映射是否在 osd.3-5
[root@node0 crushmap]# ceph osd map ceph-demo crush-demo.img
osdmap e586 pool 'ceph-demo' (1) object 'crush-demo.img' -> pg 1.d267742c (1.2c) -> up ([3,5,4], p3) acting ([3,5,4], p3)
[root@node0 crushmap]# ceph osd map ceph-demo rdb-demo.img
osdmap e586 pool 'ceph-demo' (1) object 'rdb-demo.img' -> pg 1.651743f6 (1.76) -> up ([4,5,3], p4) acting ([4,5,3], p4)
定制 CRUSH Map 注意事项
注意事项
- 1、每次扩容,或者删除,修改的 crushmap.bin 文件最好进行保存和备份,编辑之前进行备份等
- 2、如果需要做一些类似上面这块层次化的规则,最后在集群初期进行规划和调整,后续运行业务后不在调整
- 3、调整 crushmap 的一些隐患,例如:重启 osd 后,可以导致配置失效,osd层级发生变化,数据进行重分布,或者 ssd 层级没有osd,进而集群挂掉
调整 crushmap 的一些隐患
重启 osd.3 查看层级结构是否变化
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 0.14639 root ssd
-10 0.04880 host node0-ssd
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-11 0.04880 host node1-ssd
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-12 0.04880 host node2-ssd
5 hdd 0.04880 osd.5 up 1.00000 1.00000
-1 0.14639 root default
-3 0.04880 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
-5 0.04880 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
[root@node0 crushmap]# systemctl restart ceph-osd@3
[root@node0 crushmap]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 0.09760 root ssd
-10 0 host node0-ssd
-11 0.04880 host node1-ssd
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-12 0.04880 host node2-ssd
5 hdd 0.04880 osd.5 up 1.00000 1.00000
-1 0.19519 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000 # osd.3 层级变化了
-5 0.04880 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
修改 ceph.conf 配置
# 修改 ceph.conf 配置
[root@node0 ceph-deploy]# vim ceph.conf
[global]
fsid = 97702c43-6cc2-4ef8-bdb5-855cfa90a260
public_network = 192.168.100.0/24
cluster_network = 192.168.100.0/24
mon_initial_members = node0
mon_host = 192.168.100.130
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
mon_max_pg_per_osd=1000
mon_allow_pool_delete = true
[client.rgw.node0]
rgw_frontends = "civetweb port=80"
[osd]
osd crush update on start = false # 新增配置
# 同步到集群服务配置中
[root@node0 ceph-deploy]# ceph-deploy --overwrite-conf config push node0 node1 node2
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy --overwrite-conf config push node0 node1 node2
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : True
[ceph_deploy.cli][INFO ] subcommand : push
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f5eba6443b0>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] client : ['node0', 'node1', 'node2']
[ceph_deploy.cli][INFO ] func : <function config at 0x7f5eba65fc80>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.config][DEBUG ] Pushing config to node0
[node0][DEBUG ] connected to host: node0
[node0][DEBUG ] detect platform information from remote host
[node0][DEBUG ] detect machine type
[node0][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.config][DEBUG ] Pushing config to node1
[node1][DEBUG ] connected to host: node1
[node1][DEBUG ] detect platform information from remote host
[node1][DEBUG ] detect machine type
[node1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.config][DEBUG ] Pushing config to node2
[node2][DEBUG ] connected to host: node2
[node2][DEBUG ] detect platform information from remote host
[node2][DEBUG ] detect machine type
[node2][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
重启 ceph-osd 服务
# 重启 ceph-osd 服务
[root@node0 ceph-deploy]# ansible all -m shell -a "systemctl restart ceph-osd.target"
node0 | CHANGED | rc=0 >>
node1 | CHANGED | rc=0 >>
node2 | CHANGED | rc=0 >>
[root@node0 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 0.09760 root ssd
-10 0 host node0-ssd
-11 0.04880 host node1-ssd
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-12 0.04880 host node2-ssd
5 hdd 0.04880 osd.5 up 1.00000 1.00000
-1 0.19519 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.04880 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
手动移动 osd.3 层级结构
[root@node0 ceph-deploy]# ceph osd crush move osd.3 host=node0-ssd root=ssd
moved item id 3 name 'osd.3' to location {host=node0-ssd,root=ssd} in crush map
[root@node0 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 0.14639 root ssd
-10 0.04880 host node0-ssd
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-11 0.04880 host node1-ssd
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-12 0.04880 host node2-ssd
5 hdd 0.04880 osd.5 up 1.00000 1.00000
-1 0.14639 root default
-3 0.04880 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
-5 0.04880 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
再次重启 osd.3 层级不会变化
[root@node0 ceph-deploy]# systemctl restart ceph-osd@3
[root@node0 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 0.14639 root ssd
-10 0.04880 host node0-ssd
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-11 0.04880 host node1-ssd
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-12 0.04880 host node2-ssd
5 hdd 0.04880 osd.5 up 1.00000 1.00000
-1 0.14639 root default
-3 0.04880 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
-5 0.04880 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
查看 ceph-osd socket 配置
[root@node0 ceph-deploy]# ceph daemon /var/run/ceph/ceph-osd.3.asok config show | grep update
"filestore_update_to": "1000",
"mds_task_status_update_interval": "2.000000",
"mon_health_log_update_period": "5",
"osd_class_update_on_start": "true",
"osd_crush_update_on_start": "false", # osd 发生变化时,不会自动更新 crush
"osd_crush_update_weight_set": "true",
"osd_deep_scrub_update_digest_min_age": "7200",
"rbd_atime_update_interval": "60",
"rbd_config_pool_override_update_timestamp": "0",
"rbd_mirror_image_policy_update_throttle_interval": "1.000000",
"rbd_mirror_sync_point_update_age": "30.000000",
"rbd_mtime_update_interval": "60",
"rgw_sync_trace_servicemap_update_interval": "10",
标签:Map,ceph,1.00000,08,CRUSH,host,hdd,node0,root From: https://www.cnblogs.com/evescn/p/16836316.html后续新增 osd 节点,不会自动新增到 crushmap 中,需要手动调整,比如上面的 move 命令
这样配置后对集群扩容 osd 节点,不会自动新增到 crushmap,导致数据重分布,可以手动控制数据重分布