这篇文档主要介绍《基于YOLOv8的农田病虫害检测与分析》的代码实现部分,整篇论文的目的主要是改进YOLOv8的网络结构,使其在检测病虫害的精度和实时性上有所提升。接下来,我将介绍如何从零开始搭建起本项目。
安装Python
到python的官方网站:https://www.python.org/下载,安装

安装完成后,在命令行窗口运行:python,查看安装的结果,如下图:
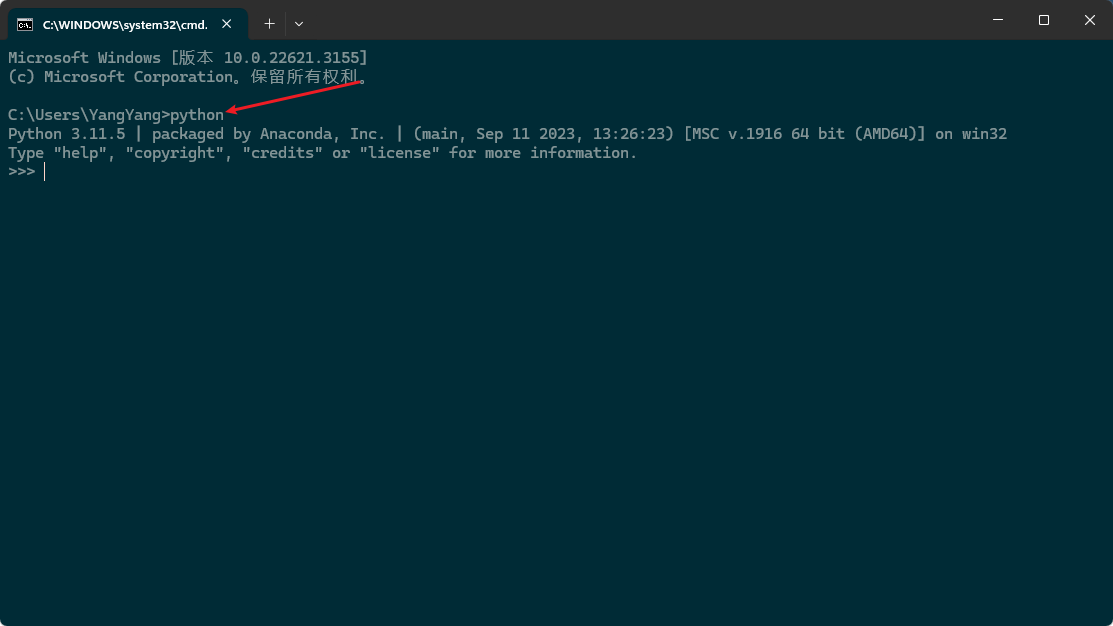
至此,Python安装完成,接下来还需要安装anaconda,这是一个python虚拟环境,特别适合管理python的环境。
安装anaconda
到anaconda的官方网站:https://www.anaconda.com/download/success下载,并安装:
安装成功后,会在开始菜单出现如下图所示:

anaconda安装完成,接下来安装pycharm,主要用来编写代码。
安装Pycharm
学生可以申请教育版

支持,所有的软件安装完成。
YOLOv8目录结构介绍
首先介绍整个项目的目录:
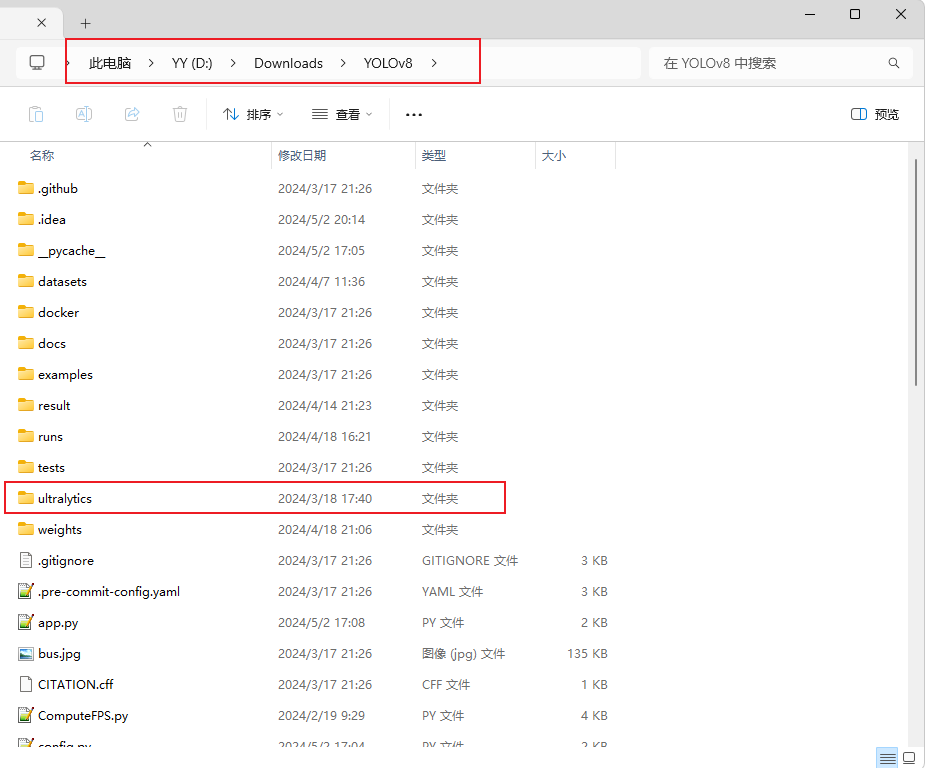
和原来的YOLOv8相比,根目录新增一些训练的脚本和测试的脚本,比如train.py和Detect.py,当然也可以直接通过命令行的方式来实现,两者效果都是一样的。
重点是ultralytics/nn目录,所有的改进模块都是在这里进行,在这里我新建了一个Addmodules的目录,里面是改进的各种模块,包括主干网络,颈部网络和检测头的改进。
需要修改的部分我都已经作了修改,不用再做其他的改动
还有一个重要的目录:ultralytics/cfg/models/Add,这里面放的都是yaml文件,其中改进的yaml文件都已经写好,不需要改动。
以下是一个yaml文件的示例,其它的都是类似的结构,只是参数不同:
安装项目的环境(非常重要)
环境配置非常重要,我当时配环境换了一周左右的时间,中间经历了各种报错,软件包不兼容的问题和显卡驱动匹配的问题,总之就是不好搞。为了方面复现工作,我已经把anaconda的环境导出为environment.yml,位于项目的根目录里面,创建虚拟环境的时候直接使用就可以
anaconda虚拟环境
再anaconda prompt终端输入conda env create -f environment.yml,就可以根据environment.yml文件创建虚拟环境,创建好后,通过conda env list查看环境是否存在,如下图所示就表明创建成功:
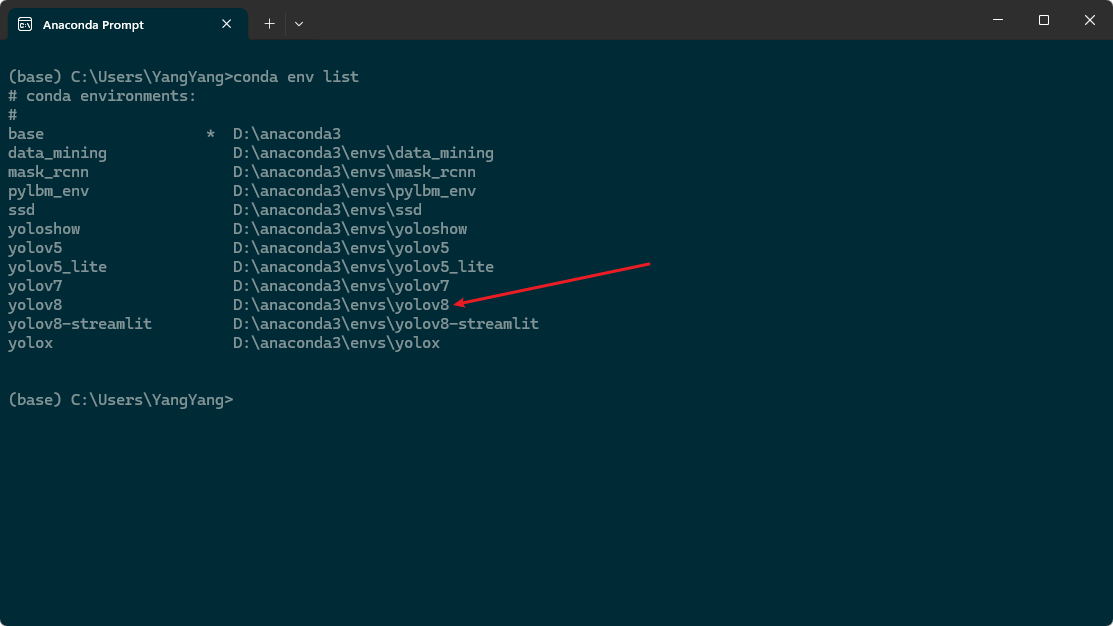
如果安装的时候出现torch相关的错误,大概率是你的显卡驱动和这里面的torch包版本不匹配,这个问题需要自行修改即可,网上关于这方面的资料很多。
使用虚拟环境
虚拟环境创建完成之后,就可以在pycharm中使用,点击右下角,切换conda环境,选择刚才创建的虚拟环境。如果到了这一步还没有报错的话,恭喜你,已经完成了80%的工作。
运行Detect.py脚本,测试检测效果,如果没有报错,接下来就是训练模型。
训练脚本train.py
找到根目录的train.py文件,注释已经写的很清楚,如下图:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolov8-HSFPN.yaml')
# model.load('yolov8n.pt') # 是否加载预训练权重,科研不建议大家加载否则很难提升精度
model.train(data=r'D:/Downloads/YOLOv8/datasets/data.yaml',
# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, pose
cache=False,
imgsz=640,
epochs=150,
single_cls=False, # 是否是单类别检测
batch=4,
close_mosaic=10,
workers=0,
device='0',
optimizer='SGD', # using SGD
# resume='runs/train/exp21/weights/last.pt', # 如过想续训就设置last.pt的地址
amp=True, # 如果出现训练损失为Nan可以关闭amp
project='runs/train',
name='exp',
)
model = YOLO('yolov8-HSFPN.yaml'),把里面的yaml文件换成自己的yaml文件,我这里用的是yolov8-HSFPN.yaml,data=r'D:/Downloads/YOLOv8/datasets/data.yaml,同理,换成自己数据集的yaml文件,我这里的数据集是yolo格式。其它的参数可以按照自己的任务自行调整。
还有一个检测的脚本,Detect.py:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('D:/Downloads/YOLOv8/result/result_8_HSFPN/train/exp/weights/best.pt') # select your model.pt path
model.predict(source='D:/Downloads/YOLOv8/ultralytics/assets',
imgsz=640,
project='runs/detect',
name='exp',
save=True,
)
同理,把best.pt换成你自己训练好的模型,source里面输入检测图片的路径,运行该脚本就可以开始检测,结果保存在runs/detect目录。
开始训练
准备好数据集,最好是yolo格式的,我的数据集项目里自带了,不需要重新下载:
datasets目录里面就是我的数据集:有train,test,valid三个目录,分别存放训练集,测试集和验证集的图像和标签:
准备这些之后,运行train.py文件,开始训练。如果报错的话,请自行上网查找,无非就是找不到数据集,某个包的版本不对,或者是GPU用不了,只能用CPU。
训练结果
训练结果会保存在runs/train目录下,exp1,exp2,exp3的顺序,表示每一次的训练结果。
上图就是训练完成后目录的结构,weights目录里面就是我们需要的模型:best.pts是效果最好的,最后也是需要这个,last.pt是最后一次的训练结果。
总结
整个项目的改进工作我已经做好,复现的话只需装好对应的环境,修改train.py的参数,运行train.py就可以开始训练;修改Detect.py的参数,就可以检测。目前项目只针对检测任务,对于分割和分类没有做改进。
经验之谈
(1)以下为两个重要库的版本,必须对应下载,否则会报错
python == 3.9.7
pytorch == 1.12.1
timm == 0.9.12 # 此安装包必须要
mmcv-full == 1.6.2 # 不安装此包部分关于dyhead的代码运行不了以及Gold-YOLO
(2)mmcv-full会安装失败是因为自身系统的编译工具有问题,也有可能是环境之间安装的有冲突
推荐大家离线安装的形式,下面的地址中大家可以找找自己的版本,下载到本地进行安装。
https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
https://download.openmmlab.com/mmcv/dist/index.html
(3)basicsr安装失败原因,通过pip install basicsr 下载如果失败,大家可以去百度搜一下如何换下载镜像源就可以修复
针对一些报错的解决办法在这里说一下
(1)训练过程中loss出现Nan值.
可以尝试关闭AMP混合精度训练.
(2)多卡训练问题,修改模型以后不能支持多卡训练可以尝试下面的两行命令行操作,两个是不同的操作,是代表不同的版本现尝试第一个不行用第二个
python -m torch.distributed.run --nproc_per_node 2 train.py
python -m torch.distributed.launch --nproc_per_node 2 train.py
(3) 针对运行过程中的一些报错解决
1.如果训练的过程中验证报错了(主要是一些形状不匹配的错误这是因为验证集的一些特殊图片导致)
找到ultralytics/models/yolo/detect/train.py的DetectionTrainer class中的build_dataset函数中的rect=mode == 'val'改为rect=False
2.推理的时候运行detect.py文件报了形状不匹配的错误
找到ultralytics/engine/predictor.py找到函数def pre_transform(self, im),在LetterBox中的auto改为False
3.训练的过程中报错类型不匹配的问题
找到'ultralytics/engine/validator.py'文件找到 'class BaseValidator:' 然后在其'__call__'中
self.args.half = self.device.type != 'cpu' # force FP16 val during training的一行代码下面加上self.args.half = False
(4) 针对yaml文件中的nc修改
不用修改,模型会自动根据你数据集的配置文件获取。
这也是模型打印两次的区别,第一次打印出来的就是你选择模型的yaml文件结构,第二次打印的就是替换了你数据集的yaml文件,模型使用的是第二种。
(5) 针对环境的问题
环境的问题每个人遇见的都不一样,可自行上网查找。